AIGC的风最近终于吹到了语音生成领域。上面视频中”孙燕姿”翻唱周杰伦的《七里香》,该歌是AI歌唱,并非孙燕姿本人。背后核心技术来自声音转换,voice convertion,而不是之前我们讲过的声音克隆,voice clone。
语音转换
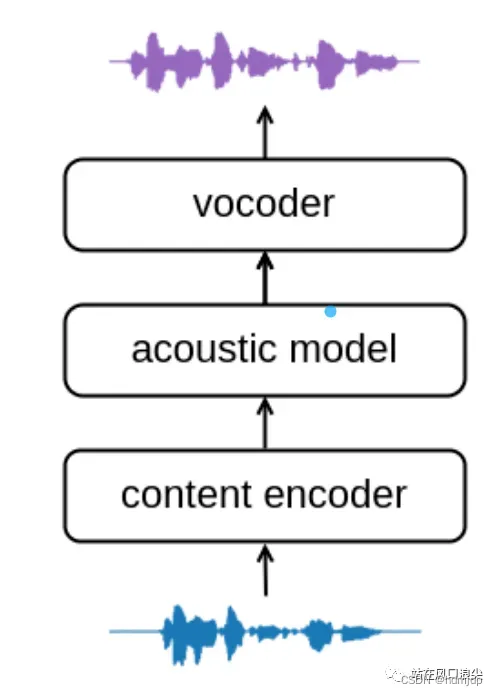
语音转换,voice convertion,简称VC。简单来说,就是把一个人的声音转换成另一个人的声音,保留说话或者歌唱的内容。可见模型的输入是音频,而不像TTS任务,输入为文本。一般VC任务都包含以下三个模块,从音频中提取信息的content encoder,常用特征PPG,现在也有自监督模型去提特征如Hubert;第二个模型是声学模型,这层主要是将音频的特征信息,进一步编码成声学特征,比如mel特征;第三个模块,声码器将声学特征上采样成音频。
基于hubert和vits的声音转换so-vits-svc
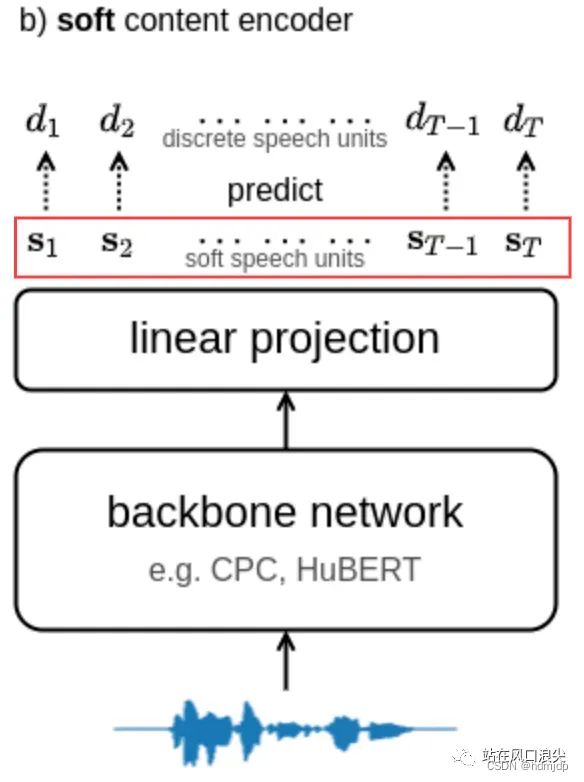
下面介绍AI孙燕姿背后的核心技术,so-vits-svc全称SoftVC VITS Singing Voice Conversion。该技术是一个声音爱好者基于softVC和vits修改而来。核心的改动是将以前的PPG换成了hubert的soft编码,然后将该信息送到了vits中。该soft hubert编码,能够很好的去除发音人信息,而保留内容信息。本质是网络的某一层的输出,但是在训练时增加了一些约束,以削弱发音人信息。下图中红线框出的就是soft content编码。
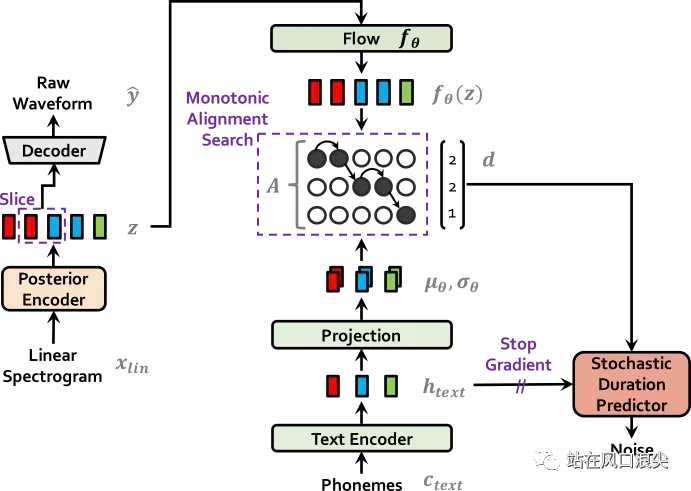
vits是TTS中一个非常重要的一个模型,该模型将声学模型和vocoder绑定到一个训练框架中,不再需要训练多次。VITS采用了FLOW引入幅度谱作为后验信息,采用MAS自动对齐出音素时长。模型的训练目标是希望从文本中直接学习出隐变量z的分布。推理时flow模型是可逆的。直接就从文本合成wav,推理是不需要posterior encoder。
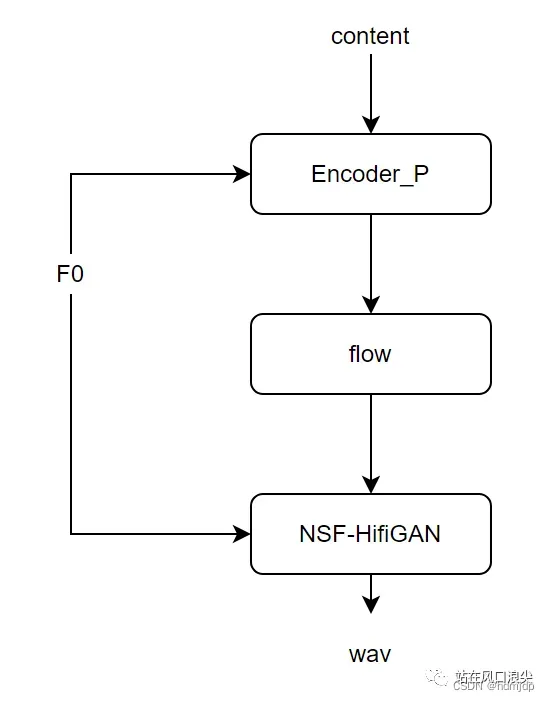
在so-vits-svc中,vits中的音素变成了hubert特征。由于hubert编码长度跟声学特征长度是有固定的比例关系,因此不需要时长模型,也不需要MAS;VC中任务模型变得更加简单。当然,由于歌曲的f0,相比于人声的f0,在频谱上持续时间更长,更难建模,因此作者将f0显式的引入到了vits中。
定制流程
定制一个AI孙燕姿,github有教程,且写出了GUI,更加方便操作。大概讲下流程,
- 获取孙燕姿的歌曲,大概1小时左右。通过人声分析程序,将伴奏和背景去除,只保留清唱的音频(干音);
- 特征预处理,提取f0和hubert特征,以及幅度谱spec;
- 加载base模型,finetune上述的特征以及音频wav,获得最终的推理模型;
- 推理时,也需要输入音频,比如用周杰伦的《七里香》,先进行人声分离,获取干音,作为输入,送入VC模型中,获得孙燕姿演唱的《七里香》清唱音频,最后将伴奏与清唱音频进行混合,得到一首AI翻唱歌曲。
https://github.com/voicepaw/so-vits-svc-fork
请关注 vx 公众号
站在风口浪尖
文章出处登录后可见!