已解决magic_number = pickle_module.load(f, **pickle_load_args)
EOFError: Ran out of input
文章目录
- 报错问题
- 报错翻译
- 报错原因
- 解决方法
- 千人全栈VIP答疑群联系博主帮忙解决报错
报错问题
粉丝群里面的一个小伙伴遇到问题跑来私信我,想用python,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错代码如下所示:
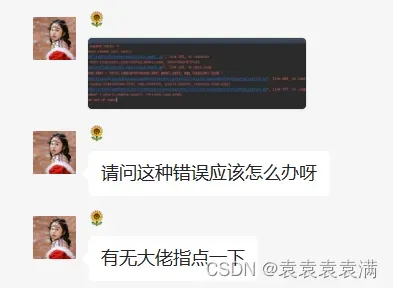
报错信息内容截图如下所示:
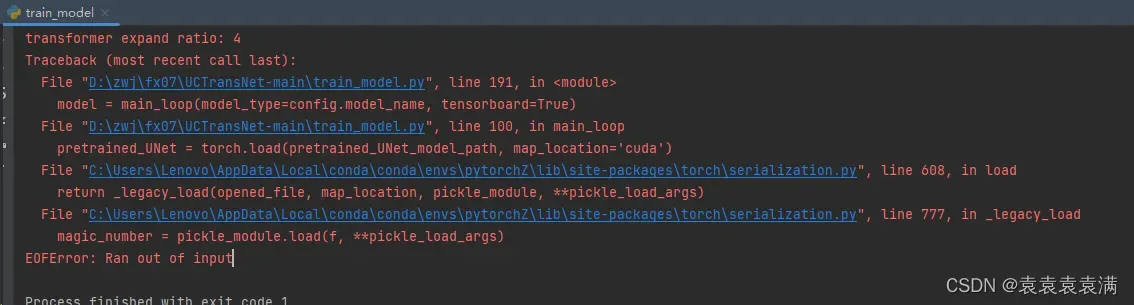
报错信息内容如下所示:
UCTransNet_pretrain
transformer head num: 4
transformer layers num: 4
transformer expand ratio: 4
Traceback (most recent call last):
File "D:\zwj\fx07\UCTransNet-main\train_model.py", line 191, in <module>
model = main_loop(model_type=config.model_name, tensorboard=True)
File "D:\zwj\fx07\UCTransNet-main\train_model.py", line 100, in main_loop
pretrained_UNet = torch.load(pretrained_UNet_model_path, map_location='cuda')
File "C:\Users\Lenovo\AppData\Local\conda\conda\envs\pytorchZ\lib\site-packages\torch\serialization.py", line 608, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\Lenovo\AppData\Local\conda\conda\envs\pytorchZ\lib\site-packages\torch\serialization.py", line 777, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
EOFError: Ran out of input
报错翻译
报错信息内容翻译如下所示:
UCTransNet_再培训
变压器头数量:4
变压器层数:4
变压器膨胀比:4
追踪(最近一次通话):
中的文件“D:\zwj\fx07\UCTransNet main\train_model.py”,第191行
model=main_loop(model_type=config.model_name,tensorboard=True)
文件“D:\zwj\fx07\UCTransNet main\train_model.py”,第100行,在main_loop中
预训练UNet=火炬加载(预训练UNet-model_path,map_location=‘uda’)
文件“C:\Users\Lenovo\AppData\Local\conda\conda\envs\pytorchZ\lib\site packages\torch\serialization.py”,第608行,加载中
return _legacy_load(打开文件、映射位置、pickle_module、**pickle_load_args)
文件“C:\Users\Lenovo\AppData\Local\conda\conda\envs\pytorchZ\lib\site packages\torch\serialization.py”,第777行,在_legacy_load中
magic_number=pickle_module.load(f,**pickle_load_args)
EOF错误:输入不足
报错原因
报错原因:
这个错误通常是由于pickle模块在读取文件时发现文件结束符(EOF)而引起的。
小伙伴们按下面的方法解决即可!!!
解决方法
我们来问问gpt呢:
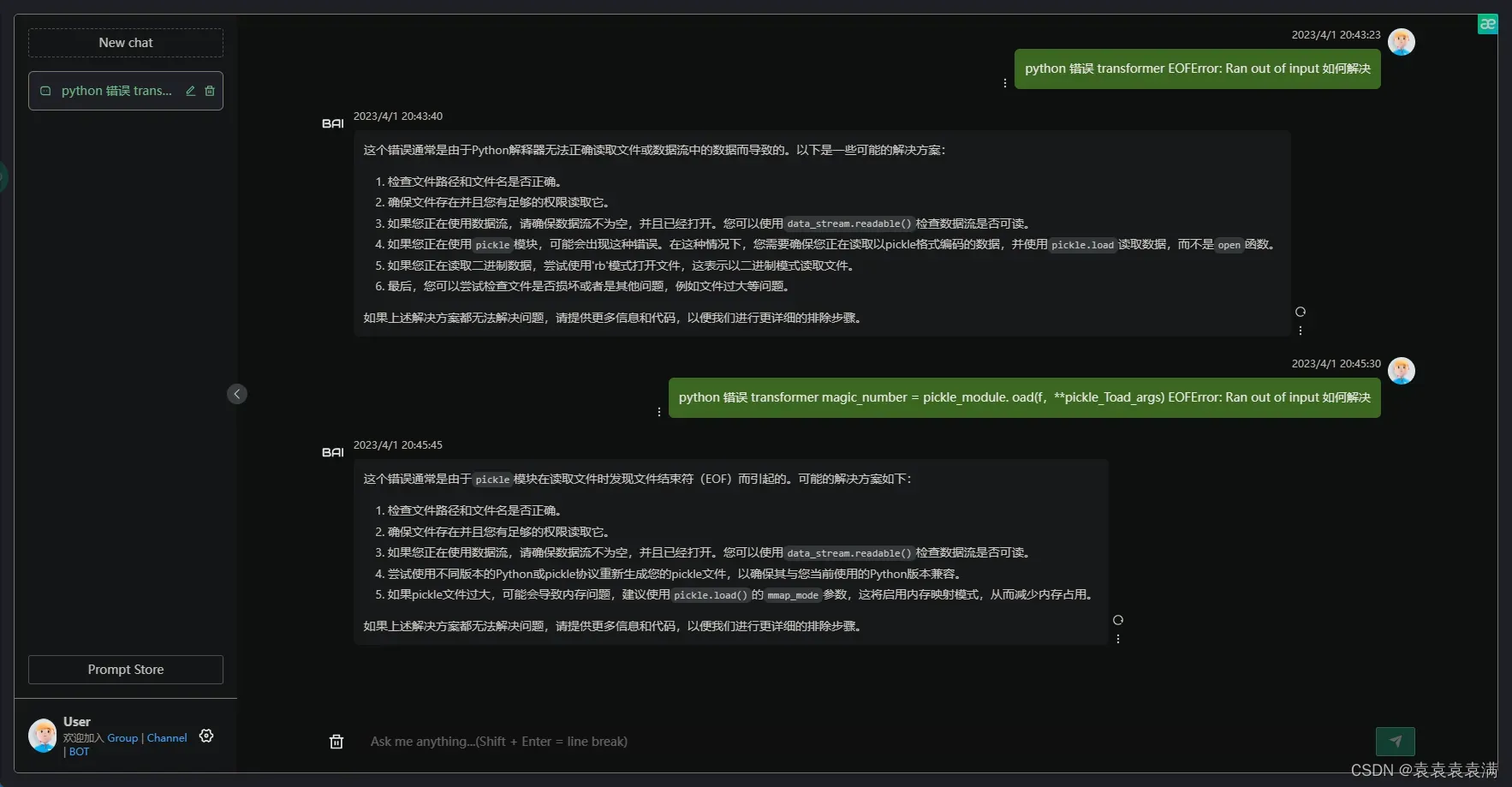
这个错误通常是由于pickle模块在读取文件时发现文件结束符(EOF)而引起的。可能的解决方案如下:
- 检查文件路径和文件名是否正确。
- 确保文件存在并且您有足够的权限读取它。
- 如果您正在使用数据流,请确保数据流不为空,并且已经打开。您可以使用
data_stream.readable()检查数据流是否可读。 - 尝试使用不同版本的Python或pickle协议重新生成您的pickle文件,以确保其与您当前使用的Python版本兼容。
- 如果pickle文件过大,可能会导致内存问题,建议使用
pickle.load()的mmap_mode参数,这将启用内存映射模式,从而减少内存占用。
如果上述解决方案都无法解决问题,请提供更多信息和代码,以便我们进行更详细的排除步骤。
以上是此问题报错原因的解决方法,欢迎评论区留言讨论是否能解决,如果有用欢迎点赞收藏文章谢谢支持,博主才有动力持续记录遇到的问题!!!
千人全栈VIP答疑群联系博主帮忙解决报错
由于博主时间精力有限,每天私信人数太多,没办法每个粉丝都及时回复,所以优先回复VIP粉丝,可以通过订阅限时9.9付费专栏《100天精通Python从入门到就业》进入千人全栈VIP答疑群,获得优先解答机会(代码指导、远程服务),白嫖80G学习资料大礼包,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
-
优点:作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会),此专栏文章是专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试!
-
专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
-
注意:如果希望得到及时回复,和大佬们交流学习,订阅专栏后私信博主进千人VIP答疑群

版权声明:本文为博主作者:袁袁袁袁满原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/yuan2019035055/article/details/129908697