文章目录
- 背景
- Conv1d() 计算过程
- Conv1d() 计算过程图示
- Conv1d() 代码举例
- Linear() 的原理
- Linear() 动图
- Conv1d() 和 Linear() 的区别
- 卷积核
背景
一维卷积的运算过程网上很多人说不清楚,示意图画的也不清楚。因此,本人针对一维卷积的过程,绘制了计算过程,以我的知识量解释一下 pytorch 中 Conv1d() 函数的机理。
Conv1d() 计算过程
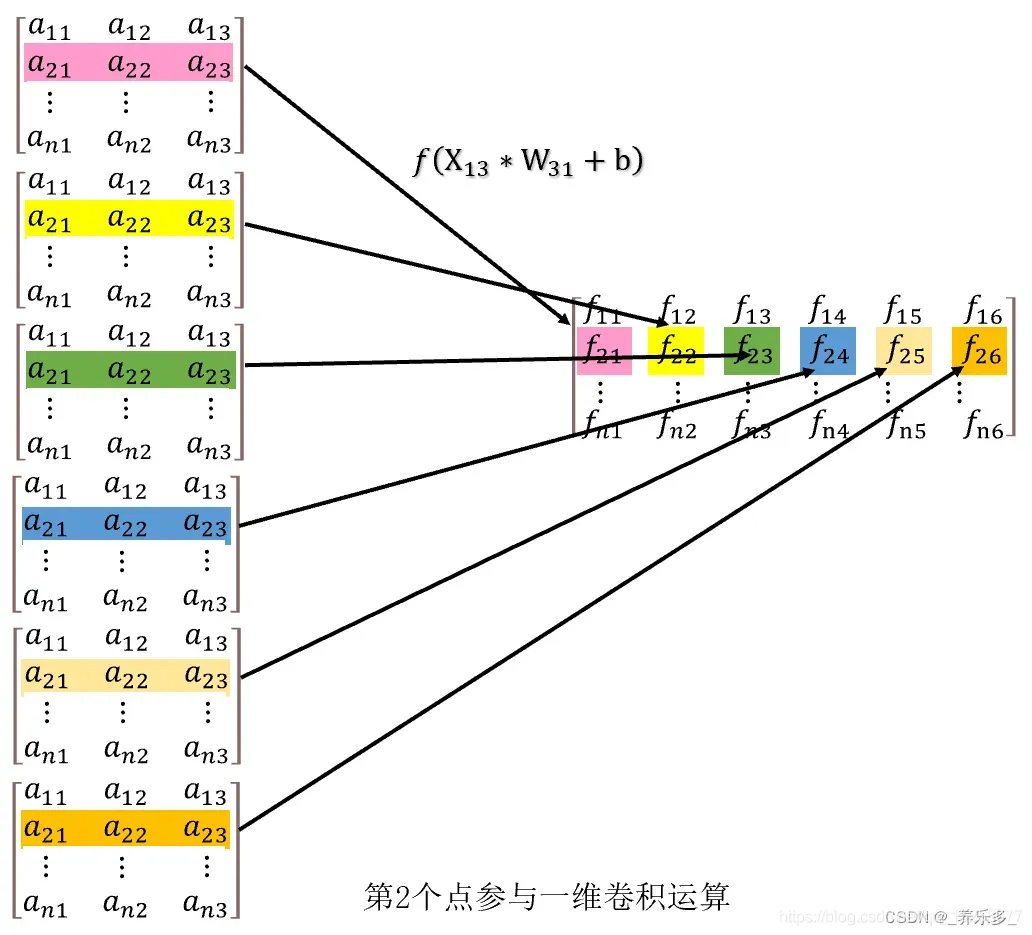
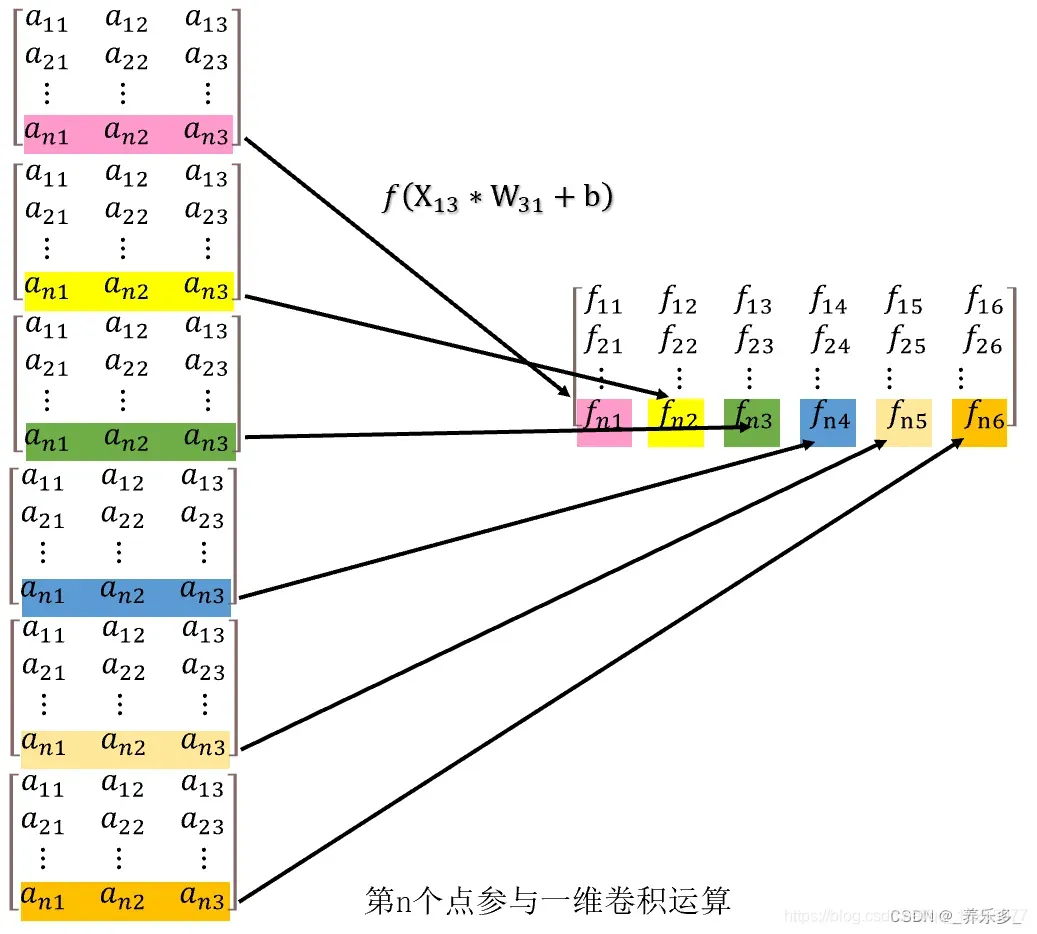
假设我们现在有 n 行,3列数据。n 行可以是 n 个点,也可以是 n 个样本数据。3列可以视为3列特征,即特征向量。我们想要通过 MLP 将其从3列升维度为6维度,就需要用 Conv1d() 函数。具体过程就是让每一行数据点乘一个卷积核,得到一个数,6个卷积核就是6个数,这样就把一个点的3列变成了6列。然后逐行遍历每个点,就可以得到新的得分矩阵。
备注: 从6列变成12列,就点乘12个卷积核。从12列变成6列,就点乘6个卷积核。
Conv1d() 计算过程图示
①、第1行数据参与卷积(这里的 a 是样本数据,W 是卷积核,f 是结果。)
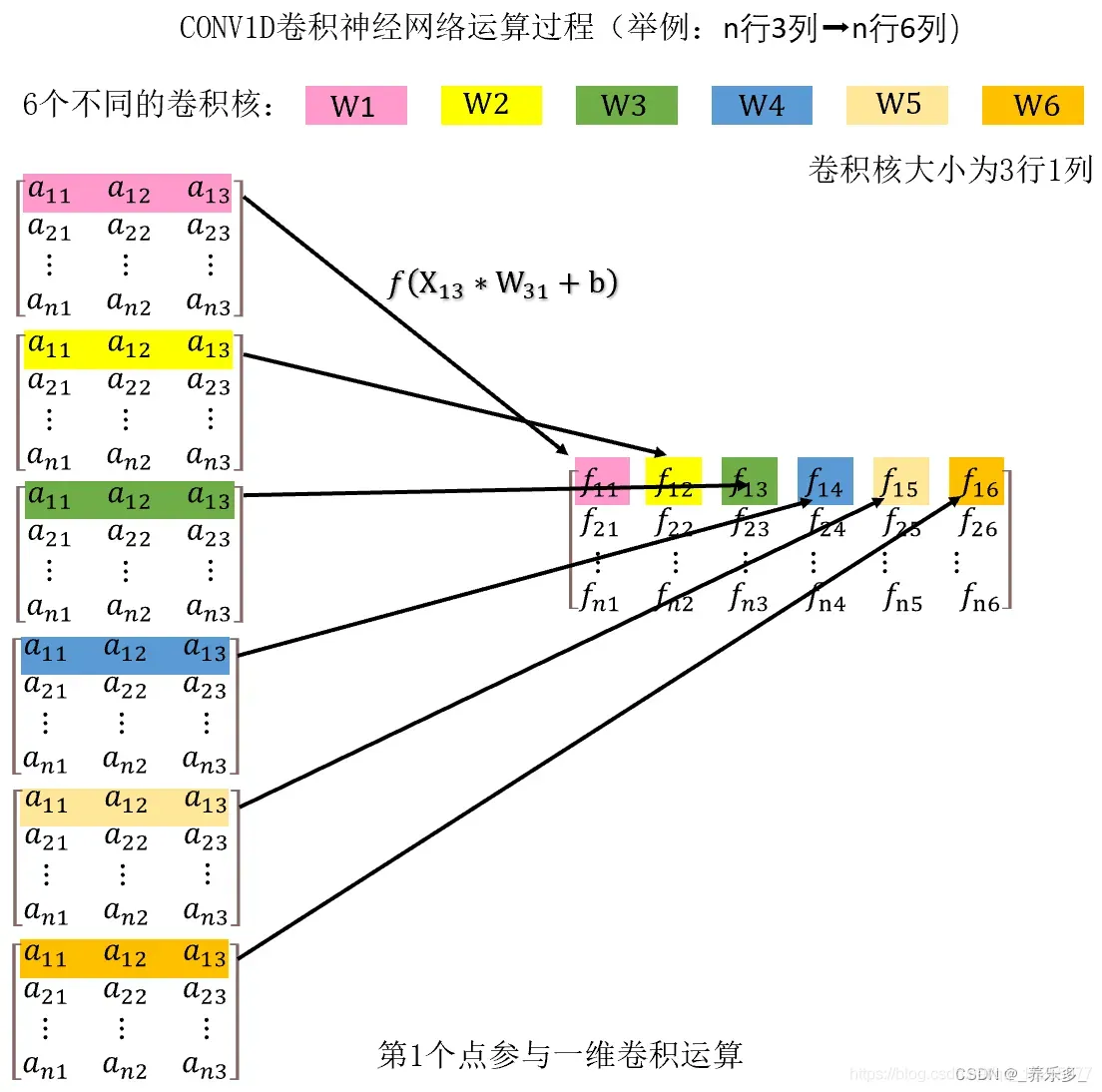
②、第2行数据参与卷积
③、第n行数据参与卷积
Conv1d() 代码举例
我们以 PointNet 中分类的主干模型 (多层感知机,MLP) 来说,Conv1d(64, 128, 1) 其实就是用 128 个 64 行 1 列的卷积核和前面 n 行 64 列的矩阵逐行点积,升维到 128 列。
class STNkd(nn.Module):
def __init__(self, k=64):
super(STNkd, self).__init__()
self.conv1 = torch.nn.Conv1d(k, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k*k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.k = k
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1,self.k*self.k).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x
Linear() 的原理
就是解 Y = X · A.T + b。其中的 A.T 是权重矩阵的转置矩阵,b 为偏置矩阵。nn.Linear(1024, 512) 就是将 n 行 1024 列的 X 矩阵降维到 n 行 512 列的矩阵。只要 A.T 为 1024 行 512 列的矩阵,和 X 点乘,就可以得到 n 行 512 列的矩阵,达到降维的目的。
①、Linear() 计算 (忽略偏置矩阵)

Linear() 动图

Conv1d() 和 Linear() 的区别
已经有人比较了在相同输入数据的条件下两者之间的区别:(1)Linear() 比 conv1d() 的计算速度快;(2)Conv1d() 的精度比 Linear() 的高;(3)在反向传播更新梯度的时候,数值有差异。
那么为什么这么设计呢?查了大量资料以后,我觉得这个答案最靠谱。当你必须保留语义分割中的空间信息时,使用卷积 Conv1d() 。当你不需要做任何与空间信息相关的事情时,比如在基本分类(mnist、猫狗分类器)中,使用线性层 Linear() 。
| Conv1d | Linear | |
|---|---|---|
| 先验知识 | 有 | 无 |
| 共享参数 | 有 | 无 |
| 运行速度 | 慢 | 快 |
| 空间信息 | 有 | 无 |
| 作用 | 特征工程 | 分类器 |
卷积核
以 PointNet 为例,将卷积核打印出来查看卷积核的形状,请看本人的另一篇文章。链接如下,
https://blog.csdn.net/qq_35591253/article/details/127671790
文章出处登录后可见!