目录
模型简称:DPL
ACL Findings
Author: Yiming Zhang, Min Zhang, Sai Wu, Junbo Zhao
Institutions: Zhejiang University(浙江大学)
Abstract
ABSA(Aspect-Based Sentiment Analysis)是细粒度的情感分析任务,其旨在识别句子中目标属性词对应的情感极性。ABSA的发展受阻于缺乏大量已标注的数据。为了解决这个问题,已有的工作利用SA (Sentiment Analysis)数据集协助训练ABSA模型,主要是通过预训练或多任务学习。
本文,遵循这条主线,并且,我们第一次设法应用伪标签 (Pseudo-Label, PL) 方法来合并这两个同构 (homogeneous)任务。虽然使用生成的伪标签来处理两个高度相关的任务的标签粒度统一的情况似乎很简单,但我们在本文中确定了它的主要挑战,并提出了一个新的框架,称为双粒度伪标记(Dual-granularity Pseudo Labeling, DPL)。此外,与PL类似,我们认为DPL是一个能够结合其他文献中的先前方法的通用框架。通过广泛的实验,DPL已经在标准基准上取得了最先进的性能,大大超过了之前的工作。
1 Introduction
1.1 Aspect-based Sentiment Analysis
本节核心思想:通过实例(图1)给出ABSA和SA任务各自定义及其区别。

SA是粗粒度的句子级情感分析(粗粒度),不同于SA任务,ABSA是属性级的情感分析(细粒度)。现有的SA数据集量大,且易获取。ABSA细粒度数据集量少,人工标注耗时费力,所以,可用的ABSA数据集很少。例如,常见的ABSA数据集之一的SemEval 2014样本数量少于5,000, SA常见的数据来源于Amazon Review,其样本量大于4,000,000。
由于SA任务和ABSA任务的相似性,因此,很自然的想到使用SA数据集作为ABSA任务的辅助数据集。
1.2 Pseudo-Labels
伪标签方法在多个领域都取得了广泛的成功。其核心是“信任”生成的假标签,通过一个教师网络(teacher model),使用有限数量的标签样本进行训练,然后将生成的标记样本与原始的监督数据集相结合,并输入最终的模型训练。在本文中,我们的核心任务是将大规模数据集合并到ABSA任务中。
实际上,图2描述了一个非常简单的技术解决方案。
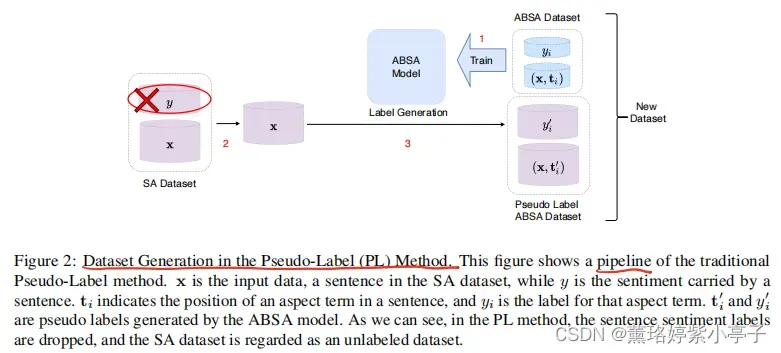
我们可以应用传统的伪标签方法从SA甚至是未标记的数据集中生成一堆基于伪属性的情感标签。然而,其结果是完全放弃和浪费了所提供的粗粒度标签。虽然看起来可以接受,但我们认为由于ABSA和SA任务的同质根,句子级粗粒度情绪标签的充分利用不足是次优的。 如果传统的框架丢弃了包含细粒度任务相关信息的粗粒度标签,那就不必要了。
我们认为伪标签家族的方法只能适合均匀粒度的情况。它们应该进化并进一步适应标签空间中的粒度差异。(We argue that the Pseudo-Label family of approaches is limited to fit a uniform granularity situation. They ought to evolve and further adapt to the discrepancy of granularity in the label space)
1.3 Dual-granularity Pseudo Labels
为了解决粗粒度和细粒度的问题,我们提出一个双粒度伪标记框架 (Dual-granularity Pseudo Labels, DPL)。DPL能够增强原始的PL框架,且能够更好的利用两种粒度的信息。
简单地说,DPL分别依赖于从两个粒度的数据集中获得的两个教师模型,然后为两边生成伪标签。因此,来自两个粒度级别的数据集可以合并成一个整体,每个句子样本都被更精细和更粗的标签集进行标记。为了方便这两套标签的使用,我们设置了一些标准条件作为DPL的设计原则。更具体地说,DPL建立了两个独立的途径,从而可以预测这两个粒度。这两条路径一起在表示空间中相互作用,理想情况下可以拥有可控的信息流,分别对应于和只对应于所考虑的粒度。我们设计了一个对抗性模块来完成这个功能。
本文贡献:
1)在这些解决ABSA任务中缺乏标记数据问题的工作中,我们率先采用并增强了一个伪标签框架来利用粗粒度的SA标签。
2)我们提出一个新颖的通用框架DPL。与常用的PL方法一样,DPL是 作为一个通用的框架建立的。我们验证了DPL也与之前在这方面的工作兼容,如预训练或多任务学习(MTL)。DPL在SemEval2014等标准化的ABSA基准测试上取得了优异的性能,这明显优于之前的工作。
2 Related Works
2.1 Aspect-based Sentiment Analysis (ABSA)
核心思想:介绍ABSA定义,伪标签的应用,已有的一些解决ABSA任务的方法。
2.2 Using Extra Dataset for ABSA
核心思想:已有的一些从增强数据角度解决ABSA任务的方法。
2.3 Pseudo-Label
伪标签是一个半监督学习方法,通常与自我训练有关。PL已被许多研究所利用和进一步发展。PL应用于许多领域。然而,这些PL方法在不均匀粒度(也就是说,有大量的粗粒度数据集用于细粒度任务。)的情况下不适用。这些现有的方法只能丢弃粗粒度标签,将它们视为未标记的数据集。因此,我们认为这些PL方法会导致信息的丢失,而且绝对是不合理的。
3 Preliminary
3.1 Pseudo-Labels
传统的PL方法通常包括一个标注的数据集D和一个未标注的数据集。使用交叉熵损失函数在标注数据集上训练教师模型:

在下面,在未标记的数据集上,可以通过教师模型的推理过程运行未标记的输入来获得相应的标签。在
数据上产生的标记形成了伪标签,该伪标签可以于原始已标注数据集数据相结合。学生模型在新产生的数据集(新标注的伪标签数据集+原始已标注数据集)上训练。

4 Dual-granularity Pseudo Labeling
简而言之,我们的工作重点是扩展传统的PL方法来利用粗粒度的数据集。为了实现这一目标,我们从多任务学习社区中汲取灵感,并通过不同的建模路径来增强PL方法。因此,我们获得了一个框架,其中两个单独的路径是协同训练针对两个粒度的标签。
4.1 Setup
本文的工作基于两个数据集:相同领域的粗粒度和细粒度数据集。
使用和
对粗粒度数据集,
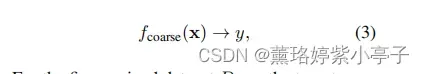
对细粒度数据集,

传统的PL方法只能适应均匀粒度的情况。解决这一限制的第一步是将粗粒度数据集与细粒度数据集合并。与传统的PL方法一样,我们在一个数据集上训练一个教师模型,并为另一个数据集生成伪标签。
我们设定 是粗粒度数据集中每一个
的抽取结果。伪标签生成之后,产生两个数据集,分别记为
和
。新数据集
是取两个数据集的并集∪:
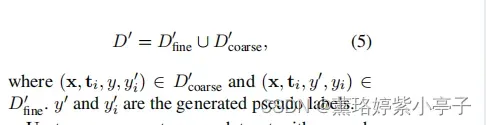
到目前为止,我们得到了一个具有更大规模的新数据集。我们的目标转化为获得一个由新数据集
训练的在细粒度任务上具有高性能的模型。换句话说,与传统的PL方法相比,关键问题是:如何利用粗粒度的标签来提高模型在细粒度任务上的性能。
4.2 DPL Skeleton
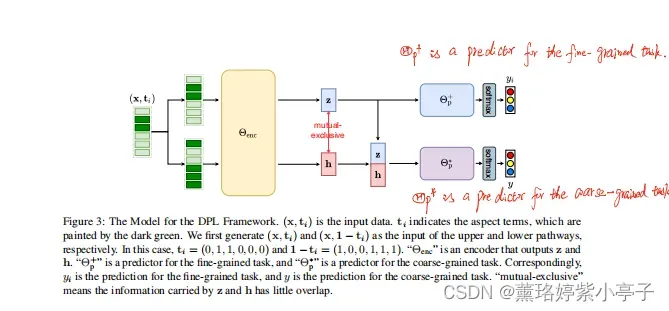
正如图3所示,为不同的粒度,我们设置双路径。每一条路径都由一个基于softmax的分类器结束。使用z和h分别表示两条路径的表示向量,我们将DPL的设计理念分解为以下三个条件:
- z携带足够的信息来确定细粒度级别上的标签。更正式地说,在整个函数空间中存在一个函数
,它能够将z映射到yi。
- h和z的并集能够在粗水平上确定标签。在整个函数空间中存在另一个函数
,它足以将[z◦h]映射到y
- h和z在所携带的信息方面是互斥的。这意味着我们不能训练一个将h隐射到
的函数
4.2.1 Fine-and Coarse-grained Tasks
如图3所示,模型由一个编码器和两个预测器
,
组成。
编码器编码每一个输入数据(x,
)成两种结果z和h。在图3,上面的一条路径是细粒度信息流,,而底线h是细粒度任务无关信息流的路径。

4.2.2 对抗训练
当前版本的DPL仍然可以作为两个独立的系统工作,这被认为是一个退化的情况。因此,为了保证h和z之间的互斥性,我们引入了一个对抗训练损失,最大化细粒度信息流带来的信息h:

4.2.3 Loss Function

5 Experiments
5.1 Experimental Setup
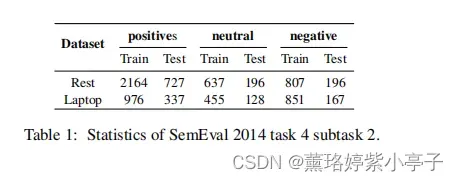
粗细粒度两个数据统计情况如下表所示:
5.2 Main Results

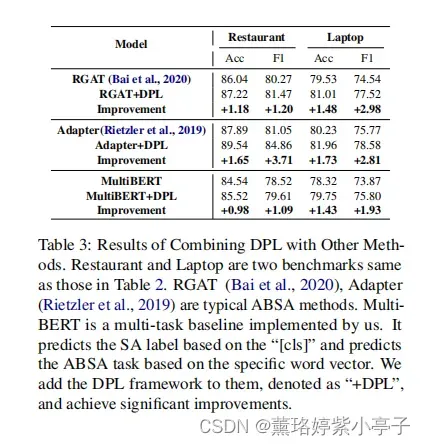
5.3 DPL as a General Framework
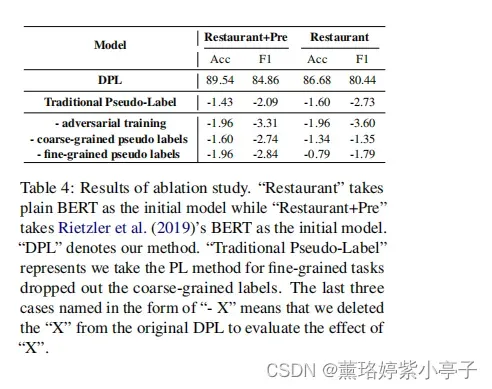
5.4 Ablation Study
主要是验证对抗训练和伪标签的作用。
6 Conclusion
本文提出了一个双粒度伪标签(Dual-granularity Pseudo Labeling)。 DPL从普通的伪标签方法扩展出来,并将其扩展到一个双路径系统。此外,它还强制对指向不同注释粒度下的数据的信息流进行强控制。结果表明了DPL在数据稀缺的ABSA任务上的SOTA性能。作为一个开创性的框架设计,我们还证明了DPL与之前发表的预训练和多任务学习方法相兼容。
未来,我们期望将DPL应用于其他的领域,比如CV。
文章出处登录后可见!