文章目录
多目标检测
前言
yolo网络模型详解,请看博主这篇文章:三万字硬核详解:yolov1、yolov2、yolov3、yolov4、yolov5、yolov7
本篇文章主要分四部分:(1)环境配置与文件配置(2)检测(3)训练(4)测试
- 其中,检测和训练都是可以独立进行的。检测是依赖于权重文件即可运行(可官网下载),而训练是基于自定义训练数据集和超参数生成权重文件。
- 请仔细阅读文章目录,了解整体框架与设计流程后,能让你更快上手!
一、环境与文件准备
1.1、环境配置
详细请看博主这篇文章:【深度学习环境配置】详细教程(资源已上传)
1.2、源码下载
- 项目路径中不可以有中文(否则会异常报错,找原因找到奔溃)
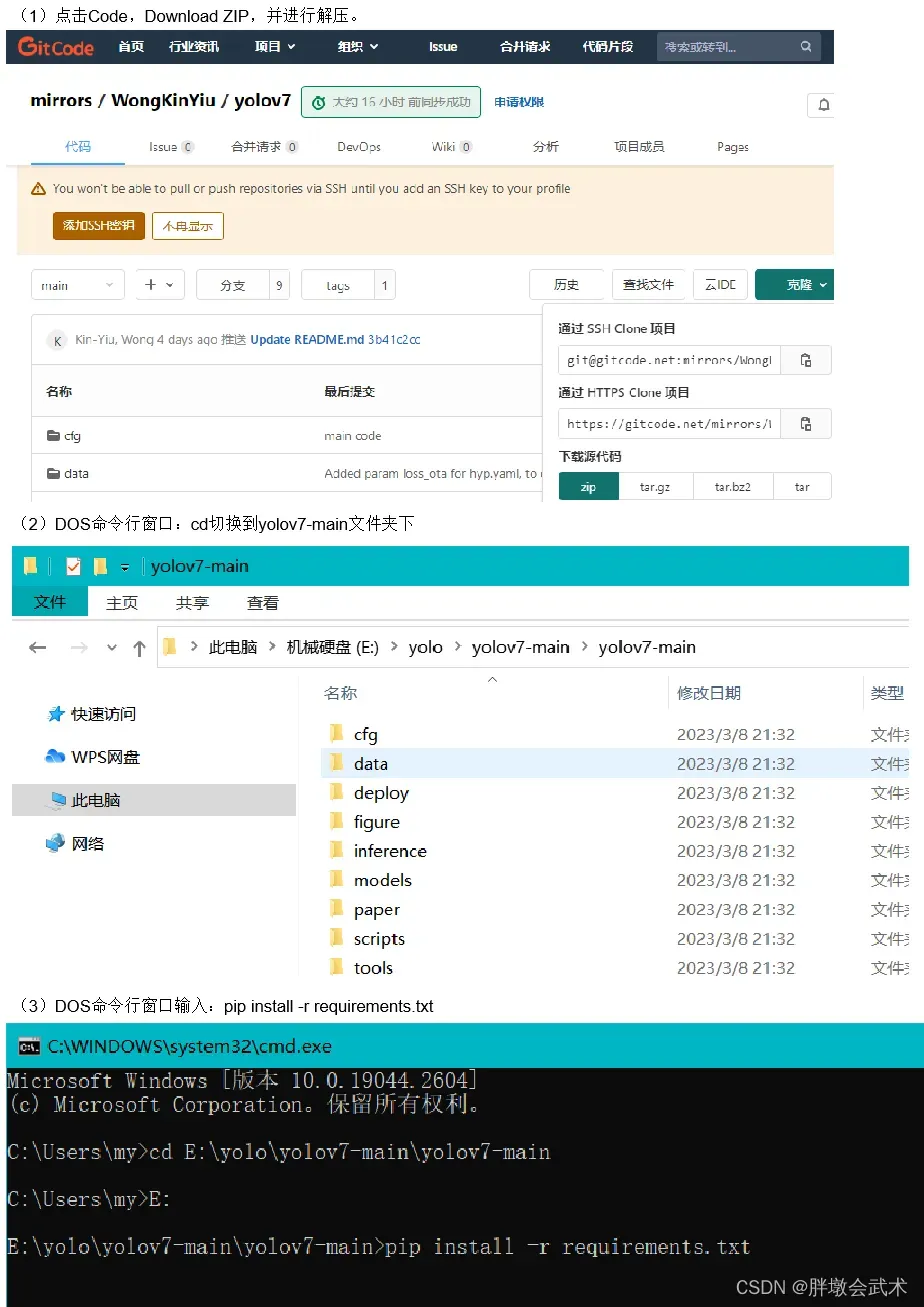
1.3、权重文件下载
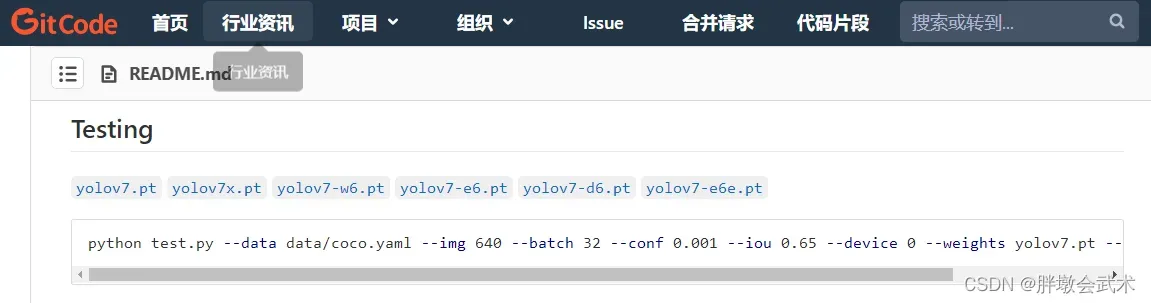
(1)测试权重文件下载:进入官网,下载Test用的权重文件:yolov7.pt
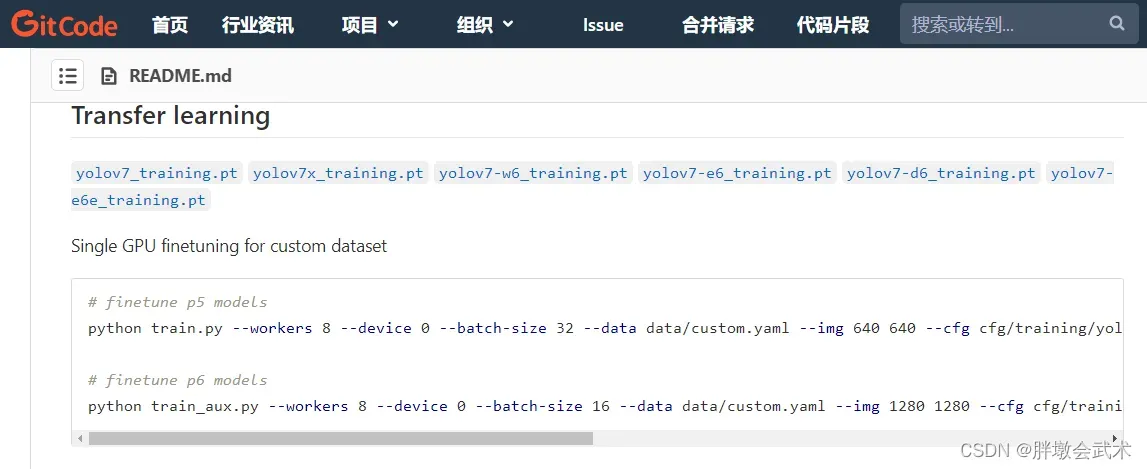
(2)训练权重文件下载:进入官网,下载Train用的权重文件:yolov7_training.pt
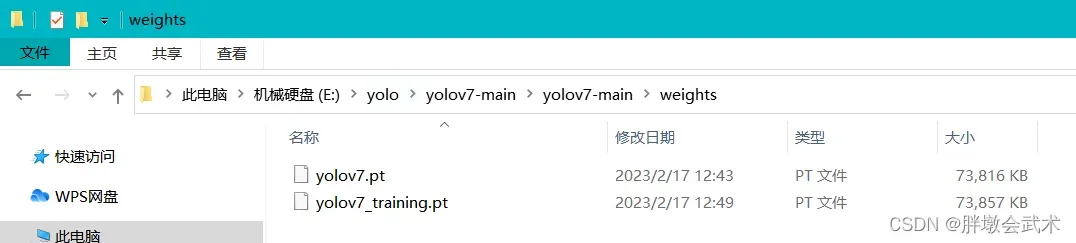
(3)在yolov7-main文件夹下新建一个weights文件夹,然后将下载好的两个权重文件放进去。
1.4、详解源码中的文件夹与文件
(1)下载后自带的文件夹及文件
文件夹
cfg:存放训练所需要的网络结构文件(.yaml)data:存放4个超参数配置文件、数据集配置文件(coco.yaml)inference:存放检测的图像与视频数据models:存放4个脚本文件:(__ init __.py)初始化脚本、(common.py)模型组件定义脚本、(experimental.py)实验脚本、(yolo.py)网络模型脚本paper:存放论文(yolo.pdf)scripts:文件下载脚本(get_coco.sh)tools:存放多个ipynb文件utils:yolov7的python工具文件夹:activations.py激活函数脚本、autoanchor.py自动锚框脚本、datasets.py定义数据加载 / 预处理 / 标注等函数、general.py通用函数脚本、loss.py损失函数脚本、metrics.py性能指标计算脚本、plots.py画图工具脚本、torch_utils.py定义基于torch的实用工具脚本文件
requirement.txt:训练和测试所需要下载的库export.py:模型转换脚本detect.py:测试脚本train.py:训练脚本test.py:测试脚本
(2)训练时需要新建的文件夹
weights:存放训练与检测的权重文件:yolov7.pt、yolov7_training.ptdatasets:存放用户自定义数据集(yolo格式)
(3)训练或测试后自动生成的文件夹
runs:存放训练和测试的结果(权重文件和相关信息)
1.5、详解配置参数
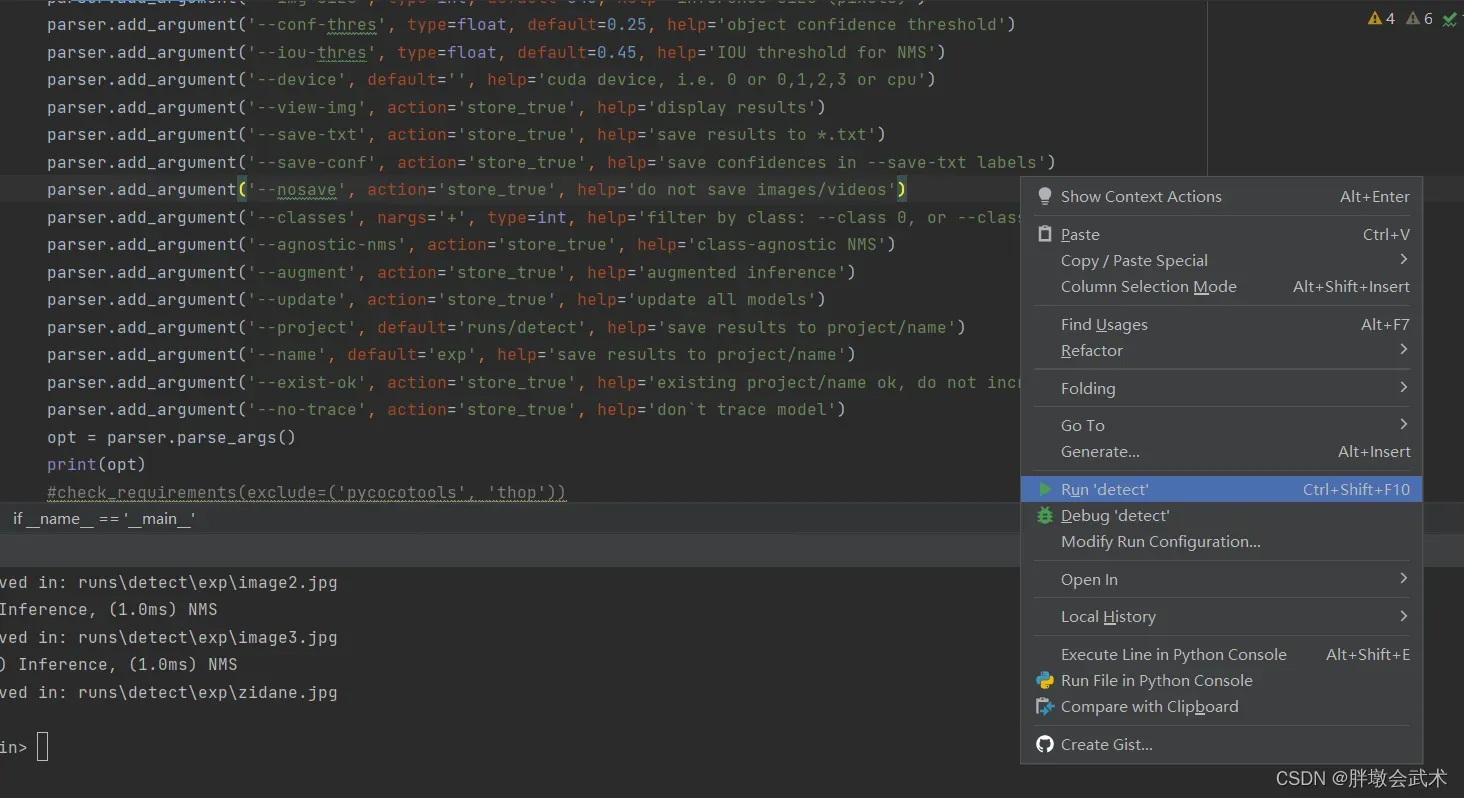
配置参数请看detect.py,如下图。
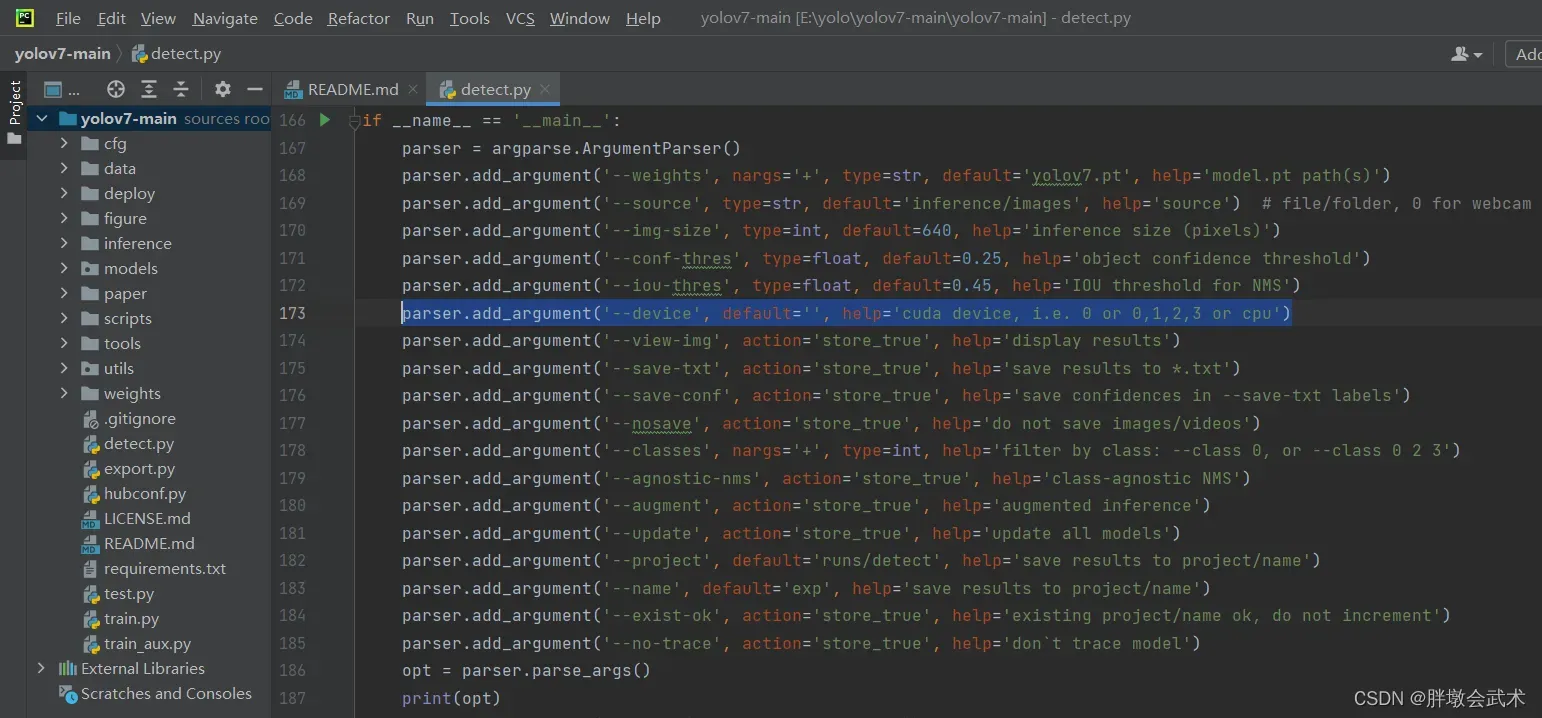
举例说明:权重参数(
'--weights')是字符串类型(type=str),故在默认值default中输入字符串,并指定权重文件的默认地址(default='yolov7.pt')。help是自定义描述文档。详细用法请参考argparse。
| 配置参数 | 说明 |
|---|---|
--weights | 权重文件 |
--cfg | 模型配置文件 |
--data | 数据集配置文件 |
-hyp | 超参数文件 |
--epochs | 训练总轮次 |
--batch-size | 一次训练所选取的样本数 |
--img-size | 输入图片分辨率大小 |
--rect | 是否采用矩形训练,默认False |
--resume | 接着上次训练的中途结果继续训练 |
--nosave | 是否只保存最终的模型,默认False |
--notest | 是否只测试最后一个epoch,默认False |
--noautoanchor | 是否不自动调整anchor,默认False |
--evolve | 是否进行超参数进化,默认False |
--bucket | 谷歌云盘bucket,一般不会用到 |
--cache images | 是否提前缓存图片到内存,以加快训练速度,默认False |
--image-weights | 是否使用加权图像进行训练,默认False |
--device | 指定训练设备:[cpu默认值,0表示一个gpu设备,[0,1,2,3]表示多个gpu设备] |
--multi-scale | 是否进行多尺度训练,默认False |
--single-cls | 数据集是否只有一个类别,默认False |
--adam | 选择优化器adam |
--sync-bn | 是否使用跨卡同步BN,在DDP模式使用 |
--local_rank | 自动单机多卡训练,一般不改动 |
--workers | dataloader的最大worker数量 |
--project | 保存到项目/名称 |
--entity | W&B实体类 |
---name | 保存到项目/名称 |
--exist-ok | 现有项目/名称确定,不递增,默认False |
--quad | 是否使用四元数据加载器,默认False |
--linear-lr | 是否使用线性学习率,默认False |
--label-smoothing | 标签平滑 |
--upload_dataset | 是否更新数据集,默认False |
--bbox_interval | 设置W&B的边界框图像记录间隔 |
--save-period | 每一个epoch记录训练日志信息 |
--artifact_alias | 保存到项目结果地址 |
--freeze | 冻结层数,默认False |
--v5-metric | 是否假设AP计算中的最大召回率为1.0,默认False |
二、检测模型(detect.py)
2.1、自定义检测数据准备
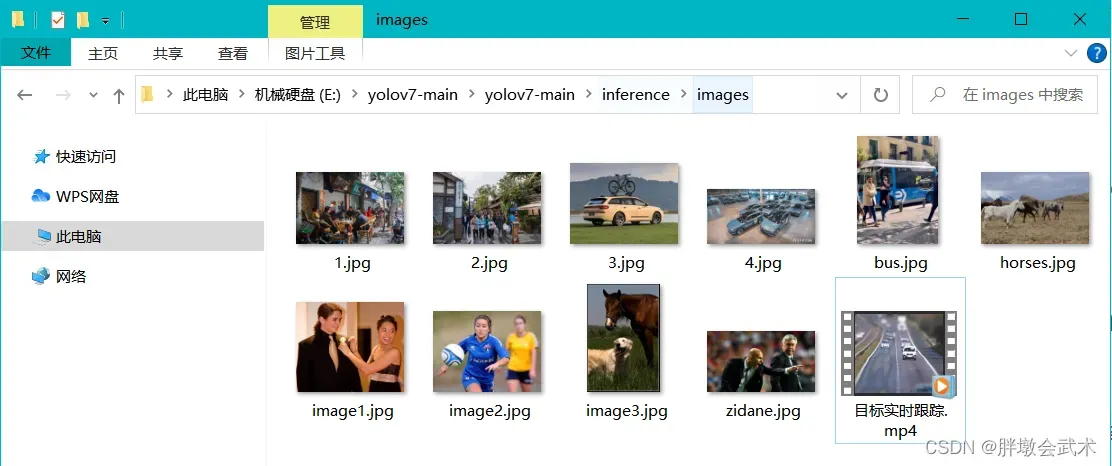
如下图:
- 个人新增了几张图片(1.jpg、2.jpg、3.jpg、4.jpg)。
- 个人新增了一个视频(目标实时跟踪.mp4)。
- 其余皆为下载源码时自带的图片。
2.2、配置参数
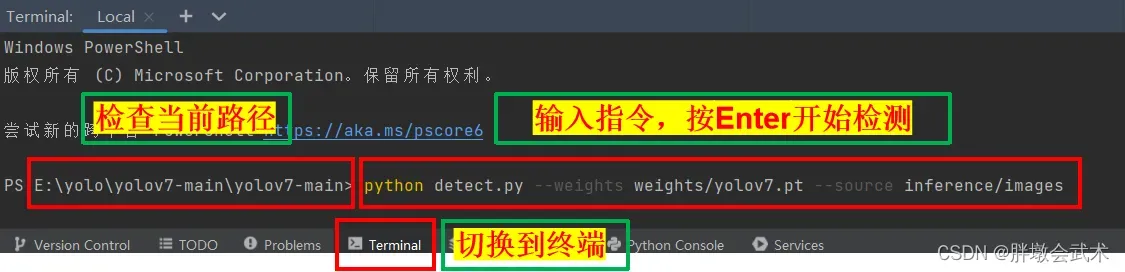
2.2.1、方式一:打开Pycharm,进入Terminal,输入指令开始检测
python detect.py --weights weights/yolov7.pt --source inference/images
11、具体操作如下图:
需确认当前项目工作路径,必须在yolov7-main文件夹下运行。若路径错误,cd到指定路径下。
- (1) –weights:表示权重文件路径
- (2) –source:表示检测图像和视频路径
- (3) –device:表示选用设备类型。
- ( –device 0/1/2/3:分别表示选择1/2/3/4个GPU)
- ( –device cpu:表示选择CPU,(不输入)默认选择CPU。)
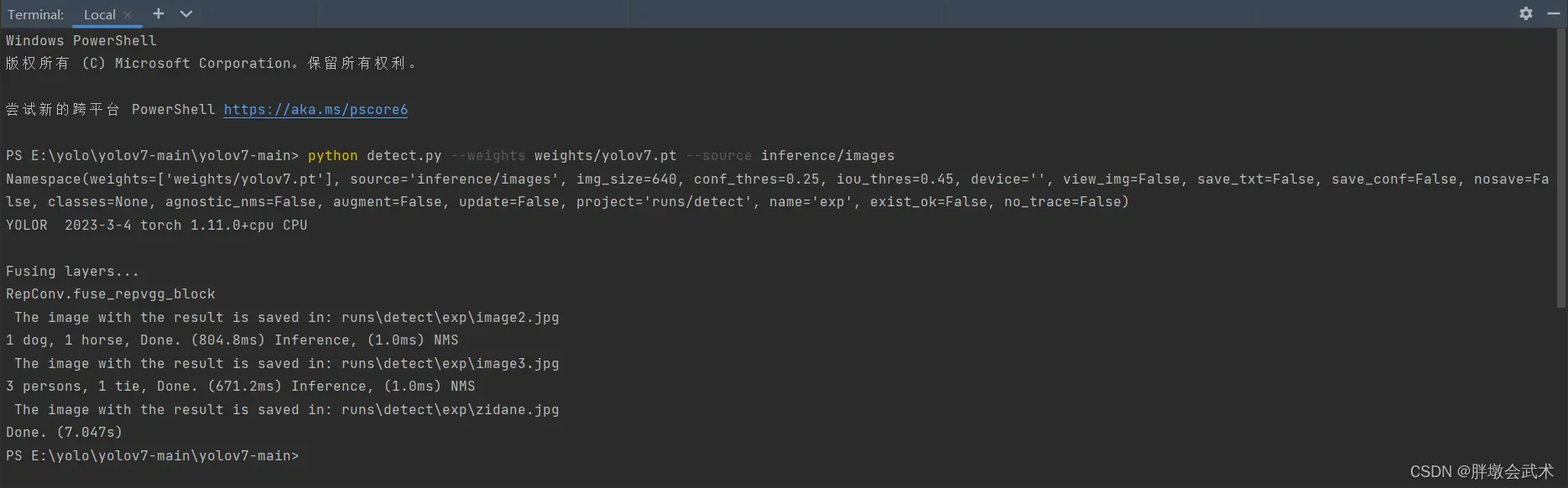
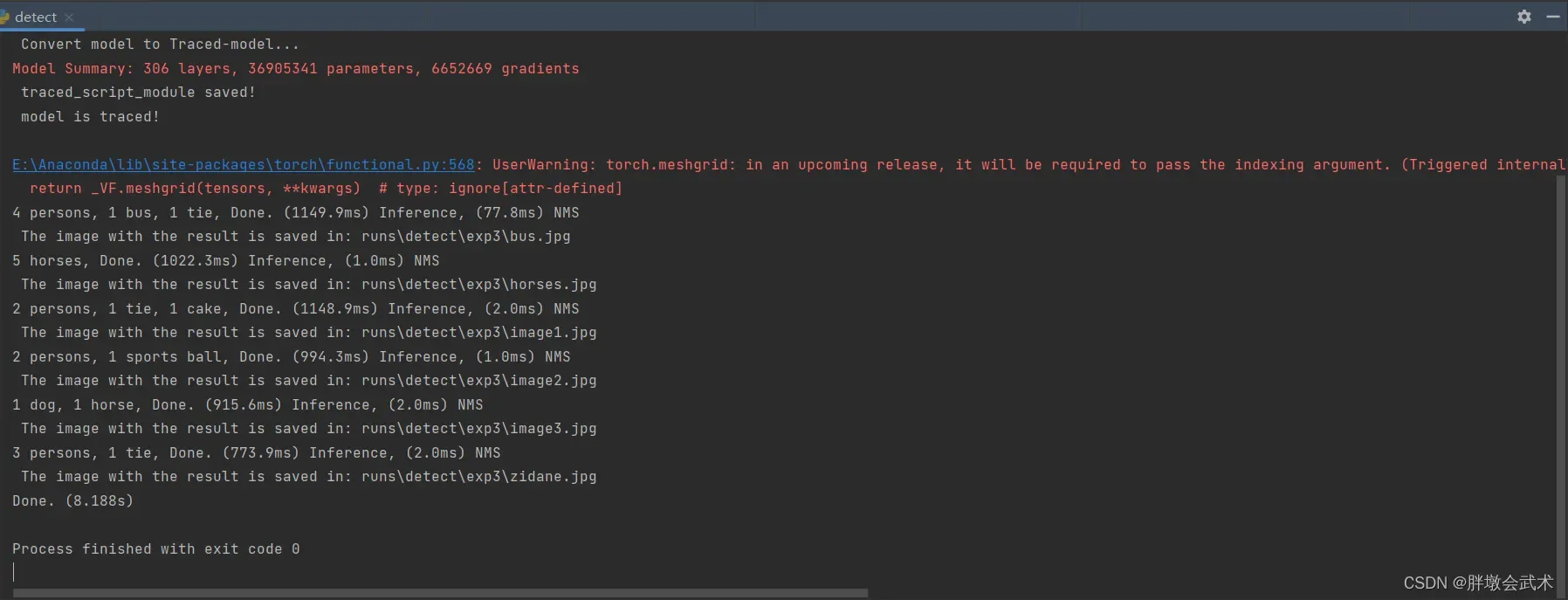
22、运行成功显示如下:
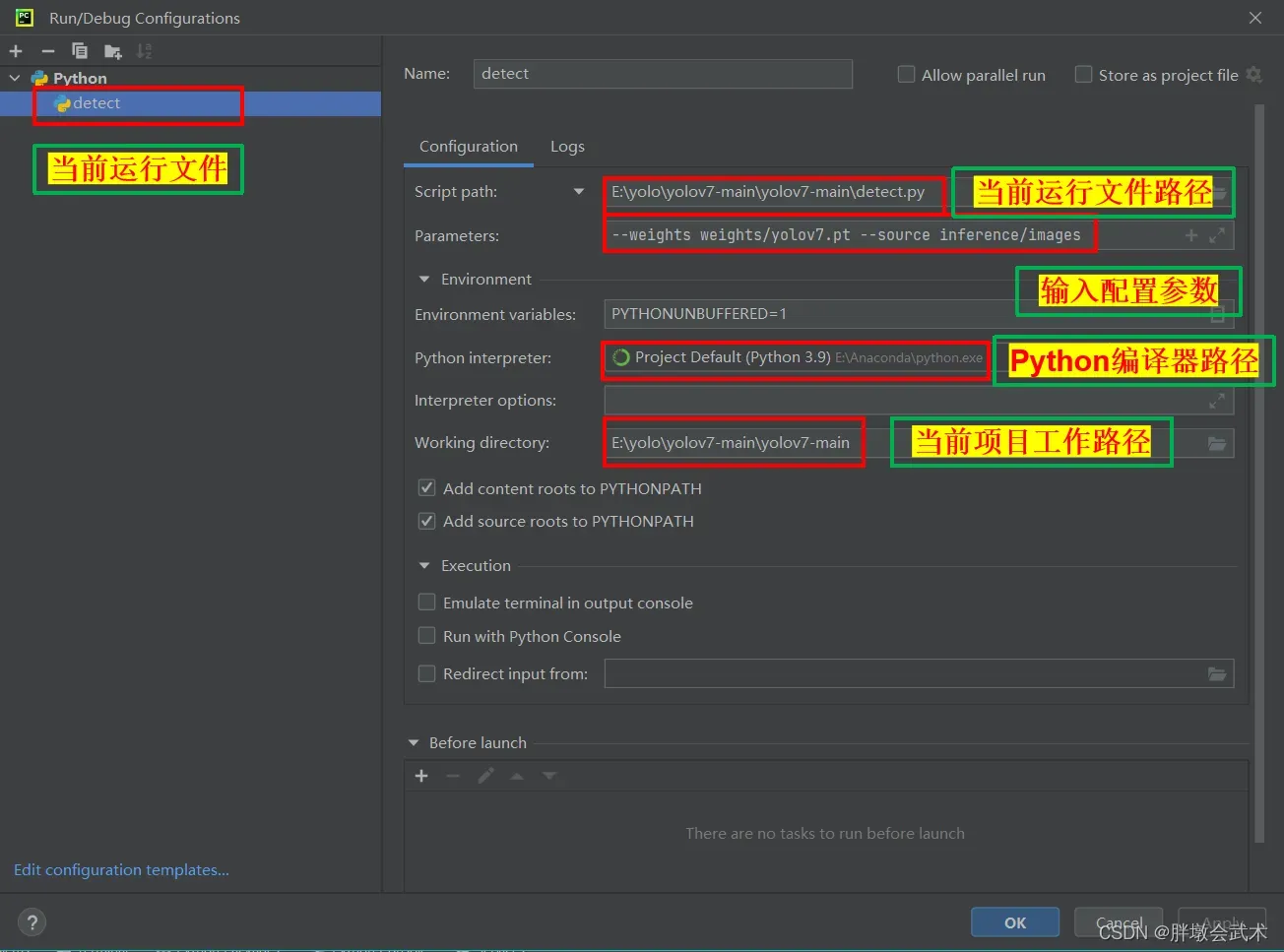
2.2.2、方式二:点击Edit Configuration,输入配置参数,开始检测。
若出现的不是当前运行文件,可打开detect.py运行一次之后再取消,就自动生成了。
11、具体操作如下图:
22、运行成功显示如下:
2.3、查看检测结果
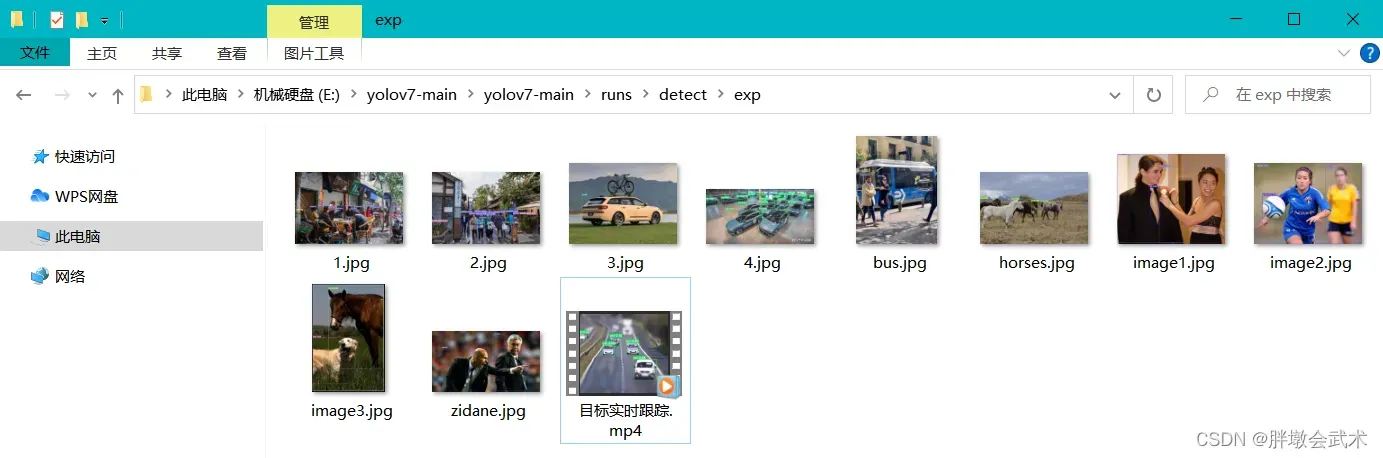
进入runs -> detect -> exp,里面存放所有检测好的图片和视频。且每运行一次,都将新增一个exp文件夹。(运行失败也会新增)
如下图:
- 个人新增了几张图片(1.jpg、2.jpg、3.jpg、4.jpg),识别效果很精确。
- 个人新增了一个视频(目标实时跟踪.mp4),识别效果很精确。
- 其余皆为下载源码时自带的图片。

三、训练模型(train.py)
3.1、自定义训练数据准备(yolo格式)
在当前项目路径下,新建 datasets 文件夹。训练与测试数据集的存放格式根据 yolov7 的要求详细如下:
- (1)在 datasets 文件夹下,新建 Helmet 文件夹:Helmet是自定义文件名:通常命名为当前项目的检测物体名称(如:检测车,命名为car)
- (2)在 Helmet 文件夹下,新建 images 和 labels 文件夹,以及存放训练和验证每一张图像的绝对路径的两个( .txt )文本。该文本详解如下/font>
- (2.1)在 images 文件夹下,新建 train 和 val 两个文件夹,分别存放训练与验证的图片数据集。依据数据集数量来划分,通常训练与验证的比例是三七分。
- (2.2)在 labels 文件夹下,新建 train 和 val 两个文件夹。分别存放训练与验证数据的标注文件( .txt ),每个数据对应一个标准文件。该文件通过
labelImg制作而成,详解如下。/font>
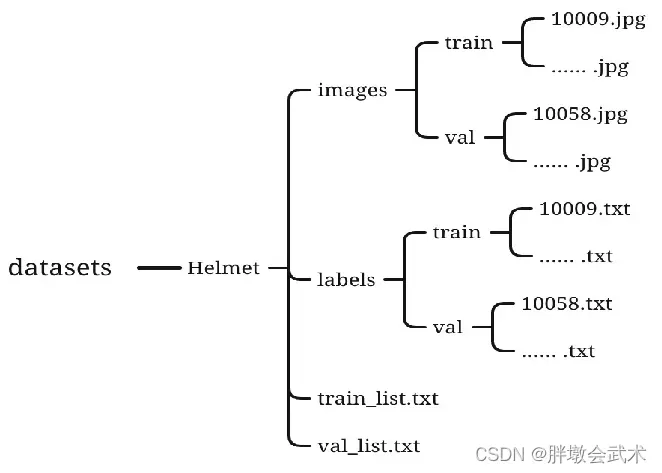
按上述要求构建好符合yolo格式的数据集后,进入datasets/Helmet文件夹下,新建两个文本文件:train.txt、val.txt。该两个文件分别写入在 images/train 和 images/val 下,所有图片的绝对路径。

3.2、labelImg制作图像标签
在上述自定义数据准备中,提到的 labels 文件夹下的训练与验证数据的标注文件,需要通过labelImg软件去处理生成。就是通过将 images 文件夹下的训练和验证数据,一对一的生成yolo格式的标准文件,并保存在 labels文件夹下的对应路径。
3.2.1、labelImg的环境配置
参考博客:labelImg使用教程
(1)进入DOS命令窗口,输入指令进行安装:
pip install labelImg。下载过程比较痛苦,费了九牛二虎之力,反反复复下载失败后,终于成功。
(2)下载完成后,输DOS命令窗口入指令启动软件:labellmg

3.2.2、基于labelImg开始标注
(1)加载和保存路径:加载图片路径并选择保存路径,这样我们对image的每张图片的处理都会储存进label中,之后val也是同理。
- Open Dir(选择图片路径):选择
datasets/Helmet/images/train。- Change Save Dir(选择保存路径):选择
datasets/Helmet/labels/train。注意:因为使用cv2.imread读取图像,所有路径中不能有中文。否则导致失败。
(2)开始标注检测目标:首先选择YOLO格式类型(yolov7只支持YOLO格式类型的数据),点击Create RectBox,在当前图片手动标注检测目标(ROI),并自命名检测目标的类别。然后点击Save,即完成了一张图片的标注。最后通过Next Image或Prev Image将所有图片分别标注并保存。
YOLO/CreateML/PascalVOC:生成标注文件的格式类型,共提供三种类型。Create RectBox(创造矩形框):加载图片路径之后才可选。- Save:保存当前操作并生成标注文件到指定路径。
- Next Image(下一张图片):在选择的图片路径下,切换当前图片的下一张图片。
- Prev Image(上一张图片):在选择的图片路径下,切换当前图片的上一张图片。
快捷键:W(创建矩形框),A(上一张图片),D(下一张图片)
(3)查看标注文件与标签文件
- 每一张图像都会生成对应的
(num.txt)标注文件,按输入图像的顺序自动排序。在标注文件中,每一行表示一个目标的信息,共有五个参数:目标类别class、矩形框的位置信息(x_center, y_center, width, height),N行表示当前图像标注了N个矩形框。 - 并会生成一个
(classes.txt)标签文件,里面包括所有目标类别。
下图是 labels/train 的举例,labels/val 同理:



3.3、配置文件
需要配置两个文件:
- 一个是模型的配置文件:/yolov7/cfg/training/yolov7.yaml
- 一个是数据集的配置文件:/yolov7/data/coco.yaml
3.3.1、模型配置文件
具体操作如下:
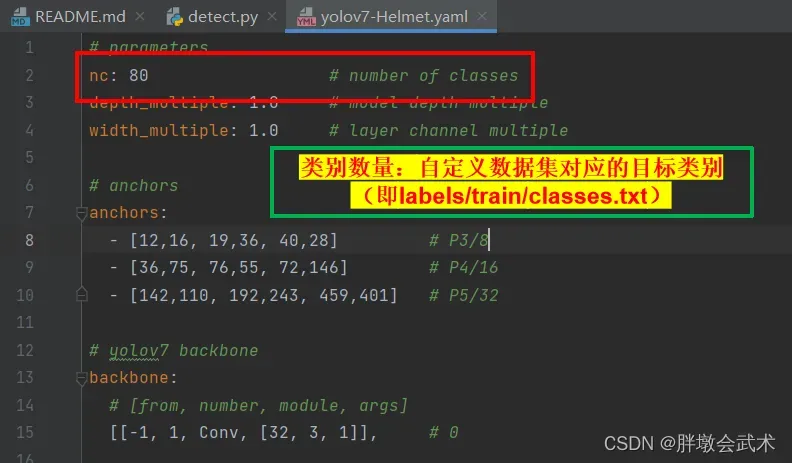
- 第一步,复制yolov7.yaml文件到相同的路径下,然后重命名为yolov7-Helmet.yaml。(可自定义名称,训练时会指定该文件路径。)在复制文件上修改参数的意义是为了保存先验文件
- 第二步,在Pycharm中,打开yolov7-Helmet.yaml文件,修改参数。该文件只需要修改 1 个地方,就是类别数量。需要对应自定义数据集的目标类别。
3.3.2、数据集配置文件
具体操作如下:
- 第一步,复制coco.yaml文件到相同的路径下,然后重命名为Helmet.yaml。(可自定义名称,训练时会指定该文件路径。)在复制文件上修改参数的意义是为了保存先验文件
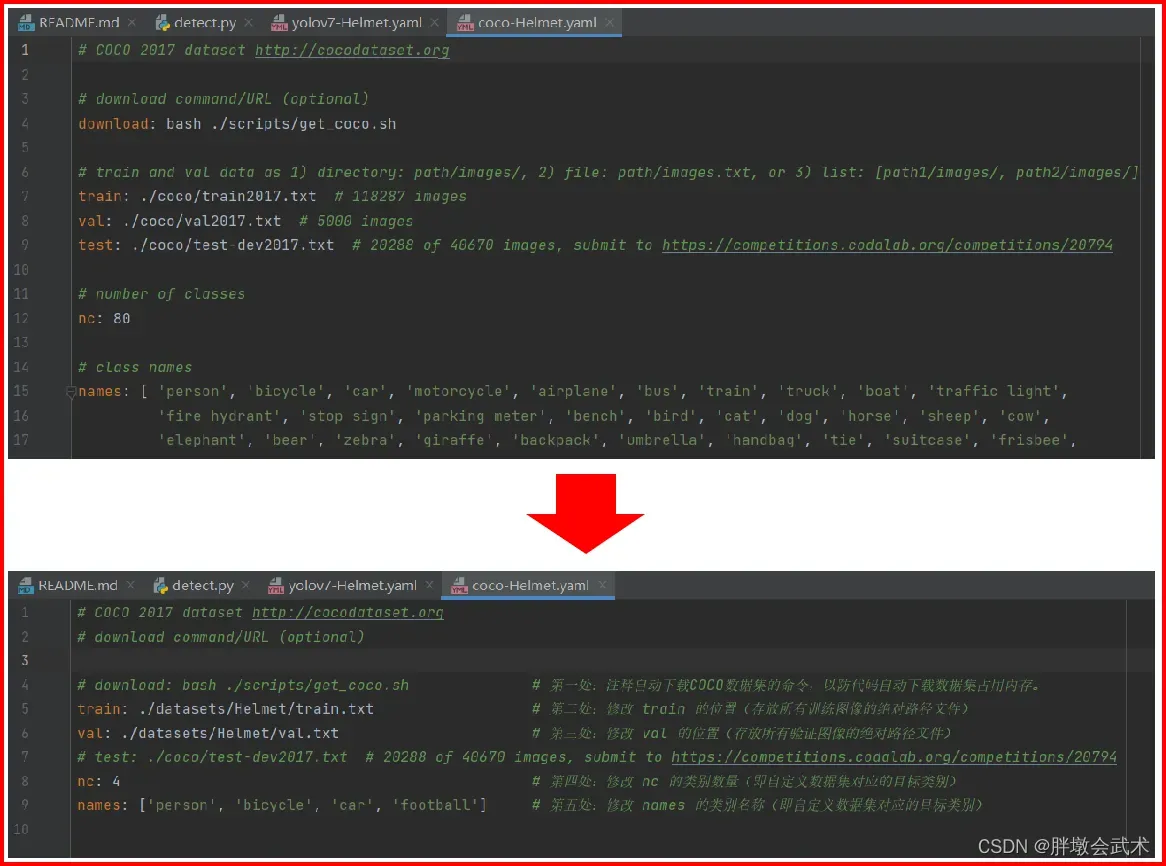
- 第二步,在Pycharm中,打开Helmet.yaml文件,修改参数。该文件需要修改 5 个地方。
- 第一处:注释自动下载COCO数据集的命令,以防代码自动下载数据集占用内存。
- 第二处:修改 train 的位置(存放所有训练图像的绝对路径文件)
- 第三处:修改 val 的位置(存放所有验证图像的绝对路径文件)
- 第四处:修改 nc 的类别数量(即自定义数据集对应的目标类别)
- 第五处:修改 names 的类别名称(即自定义数据集对应的目标类别)
3.4、开始训练
3.4.1、训练权重文件
(1)输入指令
- 详细教程请看第二章检测中的参数配置:
2.1.1方式一、2.1.2方式二。
以方式一进行演示: 打开Pycharm,进入Terminal,输入指令开始训练
python train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7-Helmet.yaml --data data/Helmet.yaml --device cpu --batch-size 8 --epoch 1
参数说明:
(1)train.py:当前运行文件
(2) –weights:训练的权重文件
(3) –cfg:模型的配置参数文件
(4) –data:数据的配置参数文件
(5) –device 0:表示指定一块GPU
(6) –batch-size:表示batch数
(7) –epoch:表示迭代训练次数
(2)查看训练结果
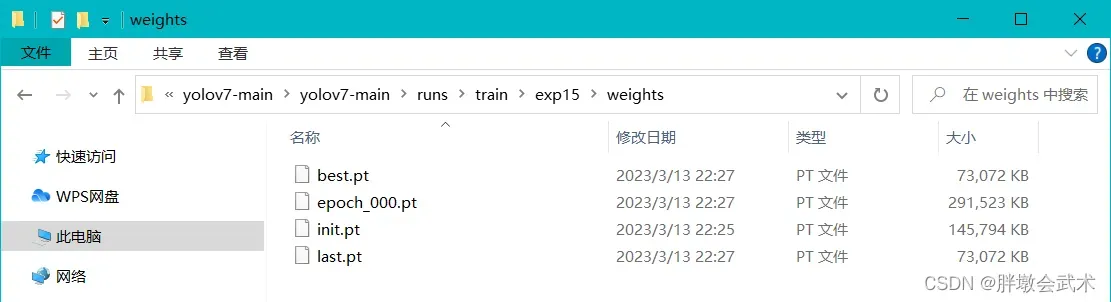
训练成功会得到两个权重文件:
last.pt、best.pt。
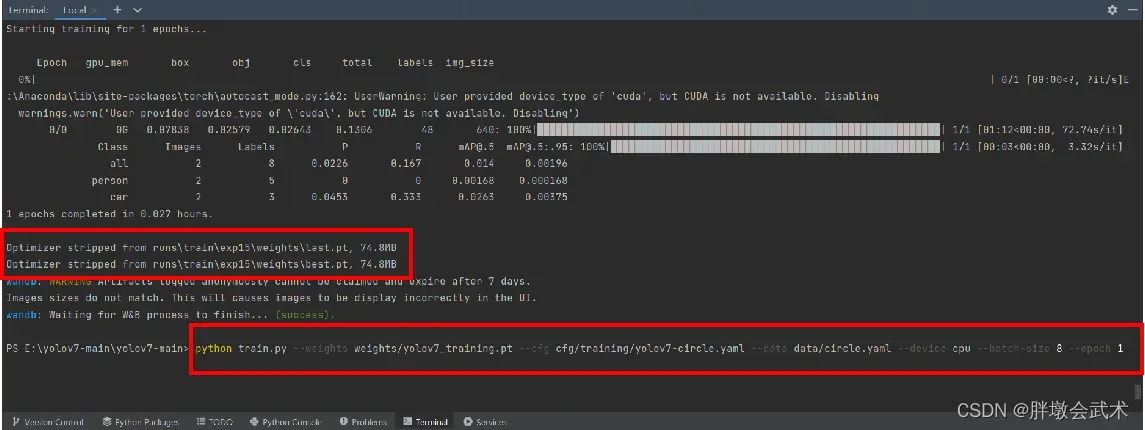
进入runs -> train -> exp,里面存放训练的过程日志与权重文件。且每运行一次,都将新增一个exp文件夹。(运行失败也会新增)
3.4.2、常见BUG汇总
- BUG:
"UnicodeDecodeError: 'gbk' codec can't decode byte 0xxx in position XX"- 解决方法:打开文本文件时,使用encoding参数指定编码格式。
- 例如:
with open(r'trainers.txt') as f:更换为with open(r'trainers.txt', encoding='utf-8') as f:- 参考文章:读取文件被提示“UnicodeDecodeError”
- BUG:
"org.yaml.snakeyaml.parser.ParserException: while parsing a block mapping"- 解决方法:可能原因是在yaml文件中,冒号之后忘记空格(或其他不符合yolo格式问题)。
- 例如:在【3.3、配置文件】中,共需要对两个yaml文件进行参数修改,请详细核对是否有误。分别是
模型配置文件:/yolov7/cfg/training/yolov7.yaml、数据集配置文件/yolov7/data/coco.yaml。- 参考文章:学习YAML的时候遇到的问题
3.4.3、加载训练权重文件,开始检测
- 步骤一:提取
runs\train\exp15\weights\best.pt权重文件。- 步骤二:与博文中第二章【二、检测(detect.py)】的检测流程是一样的,只是替换了权重文件和自定义检测图片 。
四、测试模型(test.py)
模型评估:将训练模型移植到有标注的测试集或验证集上,进行模型效果的评估。在目标检测中,最常使用的评估指标为mAP。
- 博文的前述教程只准备了训练与检测的数据准备与搭建,故若需要使用测试模型,需按照上述流程进行测试数据准备与搭建。
- 在 test.py 文件中指定数据集配置文件和训练结果模型。详细流程如下:打开Pycharm,进入Terminal,输入指令开始训练:
python test.py --data Helmet.yaml --weights runs/train/exp15/weights/best.pt --augment
参考文献
针对每一篇文章,都标注了可参考的部分内容。
1、YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等
将xml文件转换成YOLO系列标准读取的txt文件,提供.py文件
2、YoloV7实战:手把手教你使用Yolov7进行物体检测(附数据集)
将json数据转为yolov7格式的txt数据
,提供make_yolo_data.py文件完成数据集搭建:
(1)使用train_test_split方法切分出训练集、验证集和测试集。
(2)调用change_2_yolo5方法将json里面的数据转为yolov5格式的txt数据,返回训练集、验证集和测试集的图片list。
(3)创建数据集文件夹,然后将图片和txt文件copy到对应的目录下面。
将VOC数据集转换为YOLO数据集
(1)通过split_train_val.py文件,在dataSet 文件夹下,新建训练集、验证集、测试集。
(2)通过voc_label.py文件,将训练集、验证集、测试集生成label标签(训练中要用到),同时将数据集路径导入txt文件中。
(3)训练、测试、检测
4.1、YOLOv7(目标检测)入门教程详解—检测,推理,训练
4.2、yolov7训练自己的数据集
手把手教你搭建检测与训练所需要的环境、配置文件、yolo数据准备、labellmg使用、
5、睿智的目标检测61——Pytorch搭建YoloV7目标检测平台
(1)将yolov7分模块化进行原理分析以及代码注释。
(2)模块化包括:Backbone,FPN以及Yolo Head、预测框、非极大值抑制、loss、正样本的匹配过程。
6、YOLO系列 — YOLOV7算法(一):使用自定义数据集跑通YOLOV7算法
YOLOV7算法(一):使用自定义数据集跑通YOLOV7算法(包括对整个项目文件作用的解读)
YOLO系列 — YOLOV7算法(二):YOLO V7算法detect.py代码解析
YOLO系列 — YOLOV7算法(三):YOLO V7算法train.py代码解析
YOLO系列 — YOLOV7算法(四):YOLO V7算法网络结构解析
训练过程中的重要代码解析
YOLO系列 — YOLOV7算法(六):YOLO V7算法onnx模型部署
YOLO系列 — YOLOV7算法(七):YOLOV7算法总结
(1)YOLOV7训练自己的yolo数据集
(2)YOLOv7训练自己的VOC数据集
文章出处登录后可见!