前言
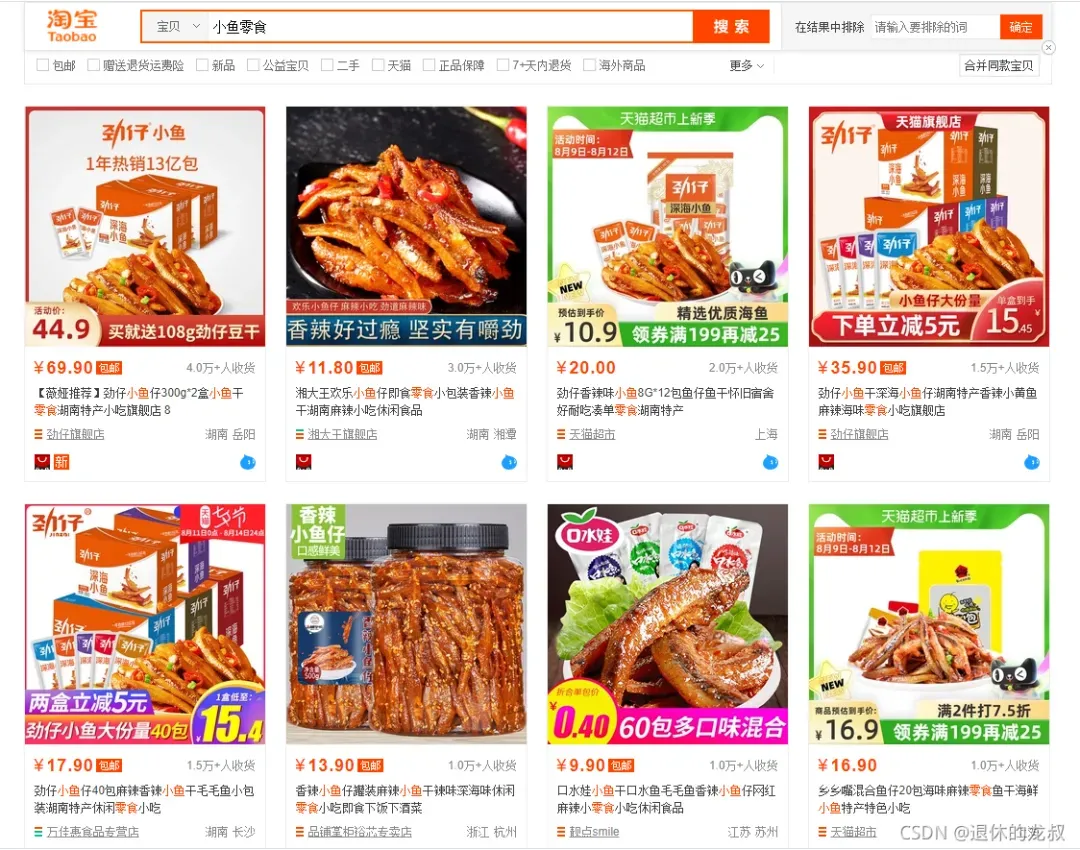
是这样的,之前接了一个金主的单子,他想在淘宝开个小鱼零食的网店,想对目前这个市场上的商品做一些分析,本来手动去做统计和分析也是可以的,这些信息都是对外展示的,只是手动比较麻烦,所以想托我去帮个忙。
一、 项目要求:
具体的要求如下:
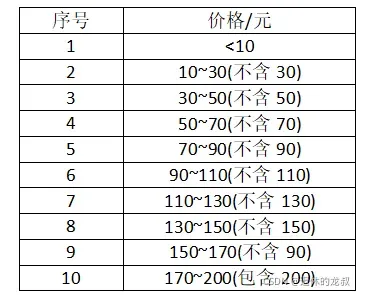
1.在淘宝搜索“小鱼零食”,想知道前10页搜索结果的所有商品的销量和金额,按照他划定好的价格区间来统计数量,给我划分了如下的一张价格区间表:
2.这10页搜索结果中,商家都是分布在全国的哪些位置?
3.这10页的商品下面,用户评论最多的是什么?
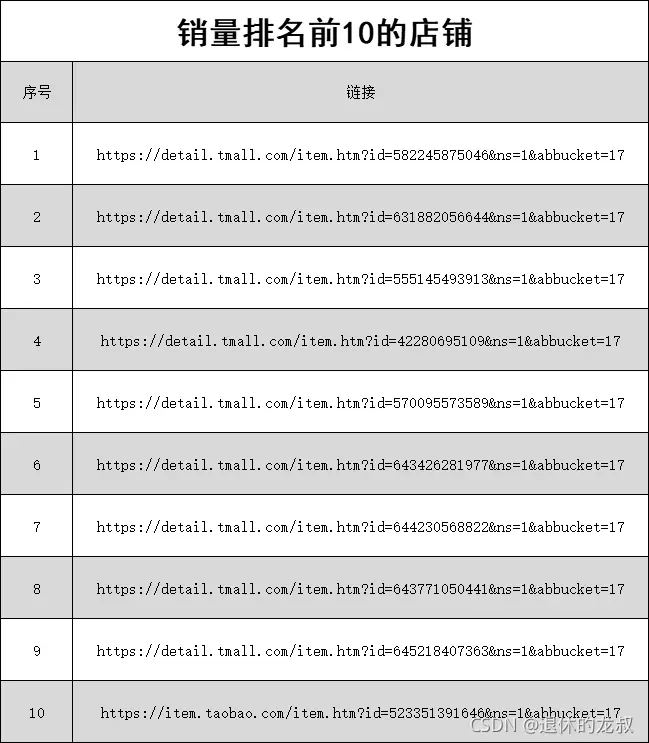
4.从这些搜索结果中,找出销量最多的10家店铺名字和店铺链接。
从这些要求来看,其实这些需求也不难实现,我们先来看一下项目的效果。
二、效果预览
获取到数据之后做了下分析,最终做成了柱状图,鼠标移动可以看出具体的商品数量。

在10~30元之间的商品最多,越往后越少,看来大多数的产品都是定位为低端市场。
然后我们再来看一下全国商家的分布情况:

可以看出,商家分布大多都是在沿海和长江中下游附近,其中以沿海地区最为密集。
然后再来看一下用户都在商品下面评论了一些什么:

字最大的就表示出现次数最多,口感味道、包装品质、商品分量和保质期是用户评价最多的几个方面,那么在产品包装的时候可以从这几个方面去做针对性阐述,解决大多数人比较关心的问题。
最后就是销量前10的店铺和链接了。
在拿到数据并做了分析之后,我也在想,如果这个东西是我来做的话,我能不能看出来什么东西?或许可以从价格上找到切入点,或许可以从产品地理位置打个差异化,又或许可以以用户为中心,由外而内地做营销。
越往深想,越觉得有门道,算了,对于小鱼零食这一块我是外行,不多想了。
三、爬虫源码
由于源码分了几个源文件,还是比较长的,所以这里就不跟大家一一讲解了,懂爬虫的人看几遍就看懂了,不懂爬虫的说再多也是云里雾里,等以后学会了爬虫再来看就懂了。
测试淘宝爬虫数据 apikey secret
import csvimport osimport timeimport wordcloudfrom selenium import webdriverfrom selenium.webdriver.common.by import By
def tongji(): prices = [] with open('前十页销量和金额.csv', 'r', encoding='utf-8', newline='') as f: fieldnames = ['价格', '销量', '店铺位置'] reader = csv.DictReader(f, fieldnames=fieldnames) for index, i in enumerate(reader): if index != 0: price = float(i['价格'].replace('¥', '')) prices.append(price) DATAS = {'<10': 0, '10~30': 0, '30~50': 0, '50~70': 0, '70~90': 0, '90~110': 0, '110~130': 0, '130~150': 0, '150~170': 0, '170~200': 0, } for price in prices: if price < 10: DATAS['<10'] += 1 elif 10 <= price < 30: DATAS['10~30'] += 1 elif 30 <= price < 50: DATAS['30~50'] += 1 elif 50 <= price < 70: DATAS['50~70'] += 1 elif 70 <= price < 90: DATAS['70~90'] += 1 elif 90 <= price < 110: DATAS['90~110'] += 1 elif 110 <= price < 130: DATAS['110~130'] += 1 elif 130 <= price < 150: DATAS['130~150'] += 1 elif 150 <= price < 170: DATAS['150~170'] += 1 elif 170 <= price < 200: DATAS['170~200'] += 1
for k, v in DATAS.items(): print(k, ':', v)
def get_the_top_10(url): top_ten = [] # 获取代理 ip = zhima1()[2][random.randint(0, 399)] # 运行quicker动作(可以不用管) os.system('"C:\Program Files\Quicker\QuickerStarter.exe" runaction:5e3abcd2-9271-47b6-8eaf-3e7c8f4935d8') options = webdriver.ChromeOptions() # 远程调试Chrome options.add_experimental_option('debuggerAddress', '127.0.0.1:9222') options.add_argument(f'--proxy-server={ip}') driver = webdriver.Chrome(options=options) # 隐式等待 driver.implicitly_wait(3) # 打开网页 driver.get(url) # 点击部分文字包含'销量'的网页元素 driver.find_element(By.PARTIAL_LINK_TEXT, '销量').click() time.sleep(1) # 页面滑动到最下方 driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(1) # 查找元素 element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]') items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]') for index, item in enumerate(items): if index == 10: break # 查找元素 price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').text paid_num_data = item.find_element(By.XPATH, './div[2]/div[1]/div[@class="deal-cnt"]').text store_location = item.find_element(By.XPATH, './div[2]/div[3]/div[@class="location"]').text store_href = item.find_element(By.XPATH, './div[2]/div[@class="row row-2 title"]/a').get_attribute( 'href').strip() # 将数据添加到字典 top_ten.append( {'价格': price, '销量': paid_num_data, '店铺位置': store_location, '店铺链接': store_href })
for i in top_ten: print(i)
def get_top_10_comments(url): with open('排名前十评价.txt', 'w+', encoding='utf-8') as f: pass # ip = ipidea()[1] os.system('"C:\Program Files\Quicker\QuickerStarter.exe" runaction:5e3abcd2-9271-47b6-8eaf-3e7c8f4935d8') options = webdriver.ChromeOptions() options.add_experimental_option('debuggerAddress', '127.0.0.1:9222') # options.add_argument(f'--proxy-server={ip}') driver = webdriver.Chrome(options=options) driver.implicitly_wait(3) driver.get(url) driver.find_element(By.PARTIAL_LINK_TEXT, '销量').click() time.sleep(1) element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]') items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]') original_handle = driver.current_window_handle item_hrefs = [] # 先获取前十的链接 for index, item in enumerate(items): if index == 10: break item_hrefs.append( item.find_element(By.XPATH, './/div[2]/div[@class="row row-2 title"]/a').get_attribute('href').strip()) # 爬取前十每个商品评价 for item_href in item_hrefs: # 打开新标签 # item_href = 'https://item.taobao.com/item.htm?id=523351391646&ns=1&abbucket=11#detail' driver.execute_script(f'window.open("{item_href}")') # 切换过去 handles = driver.window_handles driver.switch_to.window(handles[-1])
# 页面向下滑动一部分,直到让评价那两个字显示出来 try: driver.find_element(By.PARTIAL_LINK_TEXT, '评价').click() except Exception as e1: try: x = driver.find_element(By.PARTIAL_LINK_TEXT, '评价').location_once_scrolled_into_view driver.find_element(By.PARTIAL_LINK_TEXT, '评价').click() except Exception as e2: try: # 先向下滑动100,放置评价2个字没显示在屏幕内 driver.execute_script('var q=document.documentElement.scrollTop=100') x = driver.find_element(By.PARTIAL_LINK_TEXT, '评价').location_once_scrolled_into_view except Exception as e3: driver.find_element(By.XPATH, '/html/body/div[6]/div/div[3]/div[2]/div/div[2]/ul/li[2]/a').click() time.sleep(1) try: trs = driver.find_elements(By.XPATH, '//div[@class="rate-grid"]/table/tbody/tr') for index, tr in enumerate(trs): if index == 0: comments = tr.find_element(By.XPATH, './td[1]/div[1]/div/div').text.strip() else: try: comments = tr.find_element(By.XPATH, './td[1]/div[1]/div[@class="tm-rate-fulltxt"]').text.strip() except Exception as e: comments = tr.find_element(By.XPATH, './td[1]/div[1]/div[@class="tm-rate-content"]/div[@class="tm-rate-fulltxt"]').text.strip() with open('排名前十评价.txt', 'a+', encoding='utf-8') as f: f.write(comments + '\n') print(comments) except Exception as e: lis = driver.find_elements(By.XPATH, '//div[@class="J_KgRate_MainReviews"]/div[@class="tb-revbd"]/ul/li') for li in lis: comments = li.find_element(By.XPATH, './div[2]/div/div[1]').text.strip() with open('排名前十评价.txt', 'a+', encoding='utf-8') as f: f.write(comments + '\n') print(comments)
def get_top_10_comments_wordcloud(): file = '排名前十评价.txt' f = open(file, encoding='utf-8') txt = f.read() f.close()
w = wordcloud.WordCloud(width=1000, height=700, background_color='white', font_path='msyh.ttc') # 创建词云对象,并设置生成图片的属性
w.generate(txt) name = file.replace('.txt', '') w.to_file(name + '词云.png') os.startfile(name + '词云.png')
def get_10_pages_datas(): with open('前十页销量和金额.csv', 'w+', encoding='utf-8', newline='') as f: f.write('\ufeff') fieldnames = ['价格', '销量', '店铺位置'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() infos = [] options = webdriver.ChromeOptions() options.add_experimental_option('debuggerAddress', '127.0.0.1:9222') # options.add_argument(f'--proxy-server={ip}') driver = webdriver.Chrome(options=options) driver.implicitly_wait(3) driver.get(url) # driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]') items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]') for index, item in enumerate(items): price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').text paid_num_data = item.find_element(By.XPATH, './div[2]/div[1]/div[@class="deal-cnt"]').text store_location = item.find_element(By.XPATH, './div[2]/div[3]/div[@class="location"]').text infos.append( {'价格': price, '销量': paid_num_data, '店铺位置': store_location}) try: driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click() except Exception as e: driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click() for i in range(9): time.sleep(1) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]') items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]') for index, item in enumerate(items): try: price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').text except Exception: time.sleep(1) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').text paid_num_data = item.find_element(By.XPATH, './div[2]/div[1]/div[@class="deal-cnt"]').text store_location = item.find_element(By.XPATH, './div[2]/div[3]/div[@class="location"]').text infos.append( {'价格': price, '销量': paid_num_data, '店铺位置': store_location}) try: driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click() except Exception as e: driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click() # 一页结束 for info in infos: print(info) with open('前十页销量和金额.csv', 'a+', encoding='utf-8', newline='') as f: fieldnames = ['价格', '销量', '店铺位置'] writer = csv.DictWriter(f, fieldnames=fieldnames) for info in infos: writer.writerow(info)
if __name__ == '__main__': url = 'https://s.taobao.com/search?q=%E5%B0%8F%E9%B1%BC%E9%9B%B6%E9%A3%9F&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.21814703.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=4&ntoffset=4&p4ppushleft=2%2C48&s=0' # get_10_pages_datas() # tongji() # get_the_top_10(url) # get_top_10_comments(url) get_top_10_comments_wordcloud()通过上面的代码,我们能获取到想要获取的数据,然后再Bar和Geo进行柱状图和地理位置分布展示,这两块大家可以去摸索一下。
文章出处登录后可见!