软件环境:
– pytorch 1.10
– pycharm
支持代码下载地址:
gitee-pytorch
基础知识:
要训练网络,必须了解梯度。我们先介绍一些渐变的基本概念。
1、多元函数求偏导
一元函数,即只有一个参数。类似于
一个多元函数,即有多个自变量。类似于
在求多元函数偏导的过程中:取一个自变量的导数,把其他自变量当作常数。
例1:
例2:
实践:
已知,求a,b,c各自的偏导数。
2、方向导数:
简单地说方向导数形容的是满足某个关系下(Y=KX+B),对于各个方向上本关系数值变化率(Y的变化率)的量化表达式。
数学推导:
你可以参考:
方向导数1 第一章
方向导数2
设L是平面(笛卡尔坐标系)上以
为始点的一条射线,
是与 L 同方向的单位向量。
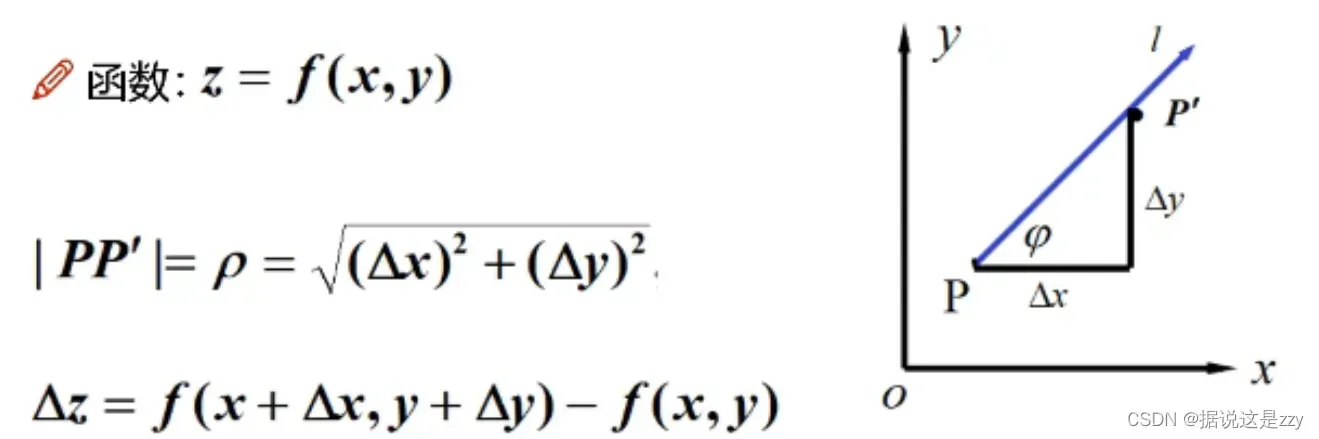
射线L的参数方程为
假设沿
方向增加,函数增量为
所以方向导数有如下定义:
定理:
其中是方向
的方向余弦。
3、梯度:
梯度是方向导数的一个特例:
已知一点有方向导数,关系如下:
在方向L上满足如下单位向量:
那么方向导数可以转化为:
点积相当于一个投影,方向导数与梯度(做点积)保持一定的角度,形成各个方向的方向导数。方向向量何时最大?很容易认为没有夹角的时候可以满足,因为此时的最大点积满足以下条件:
函数在某一点的梯度是一个向量,其方向与方向导数最大值的方向相同,其大小正好是最大方向导数。
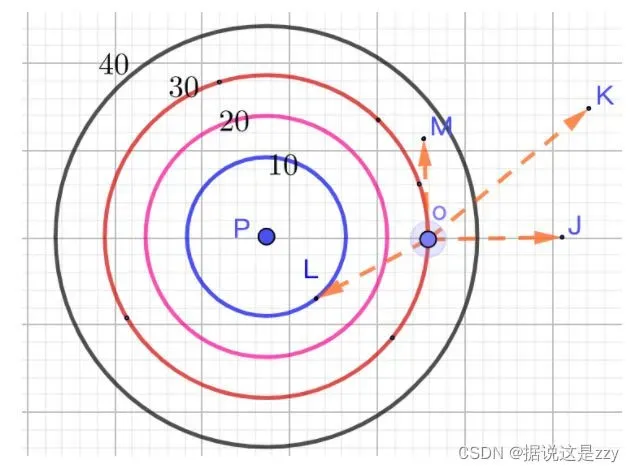
梯度概念理解:如下图所示,在P点放一个热源的等温线,则热源的辐射从里到外为10°、20°、30°、40°,若一个小蚂蚁在o点,要最快逃离热源,应该往OJ方向逃离,若往OM方向逃离则热源的变化率为0,即一直都是20°,也就是说蚂蚁一旦确定了某个逃离方向(0°,90°)方向角逃离,只要一直沿着该方向一直走,就是最快的热源降低的方向
各种函数的梯度与导数的关系:
函数梯度
更详细的解释可以参考参考链接。
Tensor的梯度与反向传播
回顾机器学习
收集数据,建立机器学习模型
,得到
如何判断模型的好坏?如何判断模型好坏:
通过最终的输出,利用反向传播计算梯度大小,然后调整参数大小,达到最优解。
如图所示,满足时
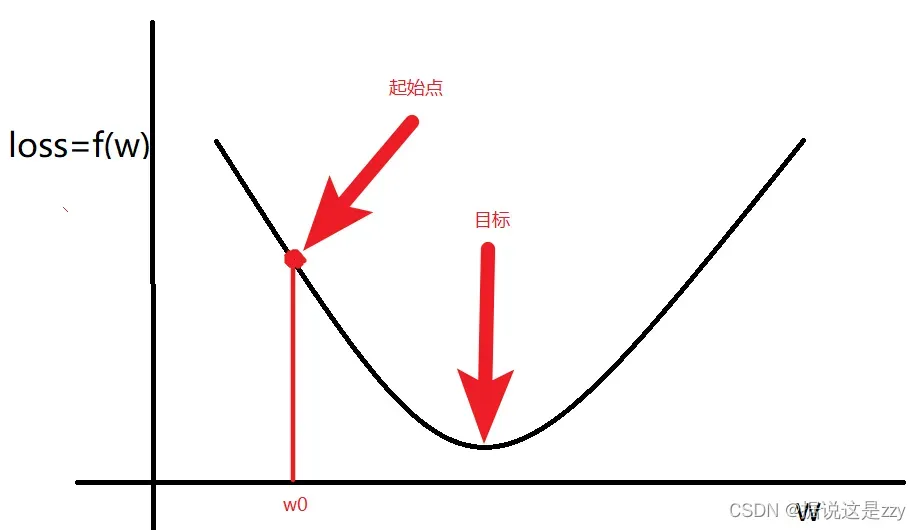
梯度计算后:在梯度变化的方向上操作,随机选择一个起点,调整
使
函数取最小值。
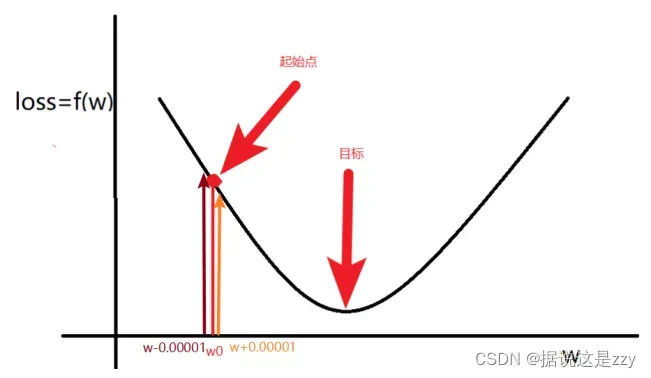
更新方法:
- 计算
的梯度(导数)
- 更新
在:
,意味着w将增大
,意味着w将减小
总结:梯度是多元函数的参数变化趋势(参数学习的方向)。当自变量只有一个时,称为导数;当自变量不止一个时,称为偏导数。
反向传播?
计算图
为了描述的方便,功能以图表的方式进行描述。
,可表示为:
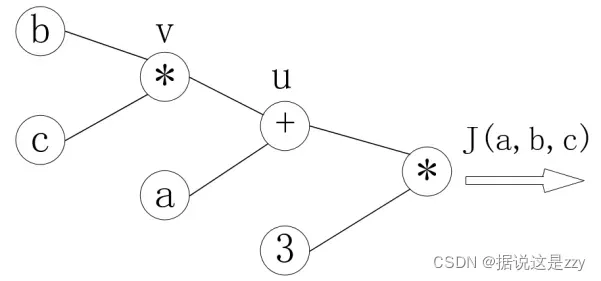
每个节点的偏导数可以是: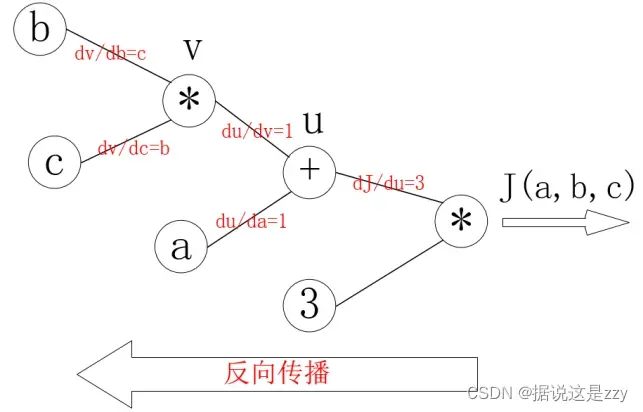
反向传播的过程是一个从右到左的过程,如上图所示。自变量各自的偏导数是连接线上的梯度的乘积:
为什么要计算反向传播?
因为要计算梯度。
实际演示:
接下来尝试计算一个简单结构的梯度,问题描述如下:
假设我们的基础模型就是y = wx+b,其中w和b均为参数,我们使用y = 3x+0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8。
简单的来说就是拟合出满足y = 3x+0.8这个曲线。
步骤分为四个步骤:
# 1 构造数据
# 2 设计正向传播 和 反向传播函数 来训练网络
# 3 训练
# 4 画图画出拟合出来的曲线
过程如下:
从左到右是前向传播部分
从右到左是反向传播部分
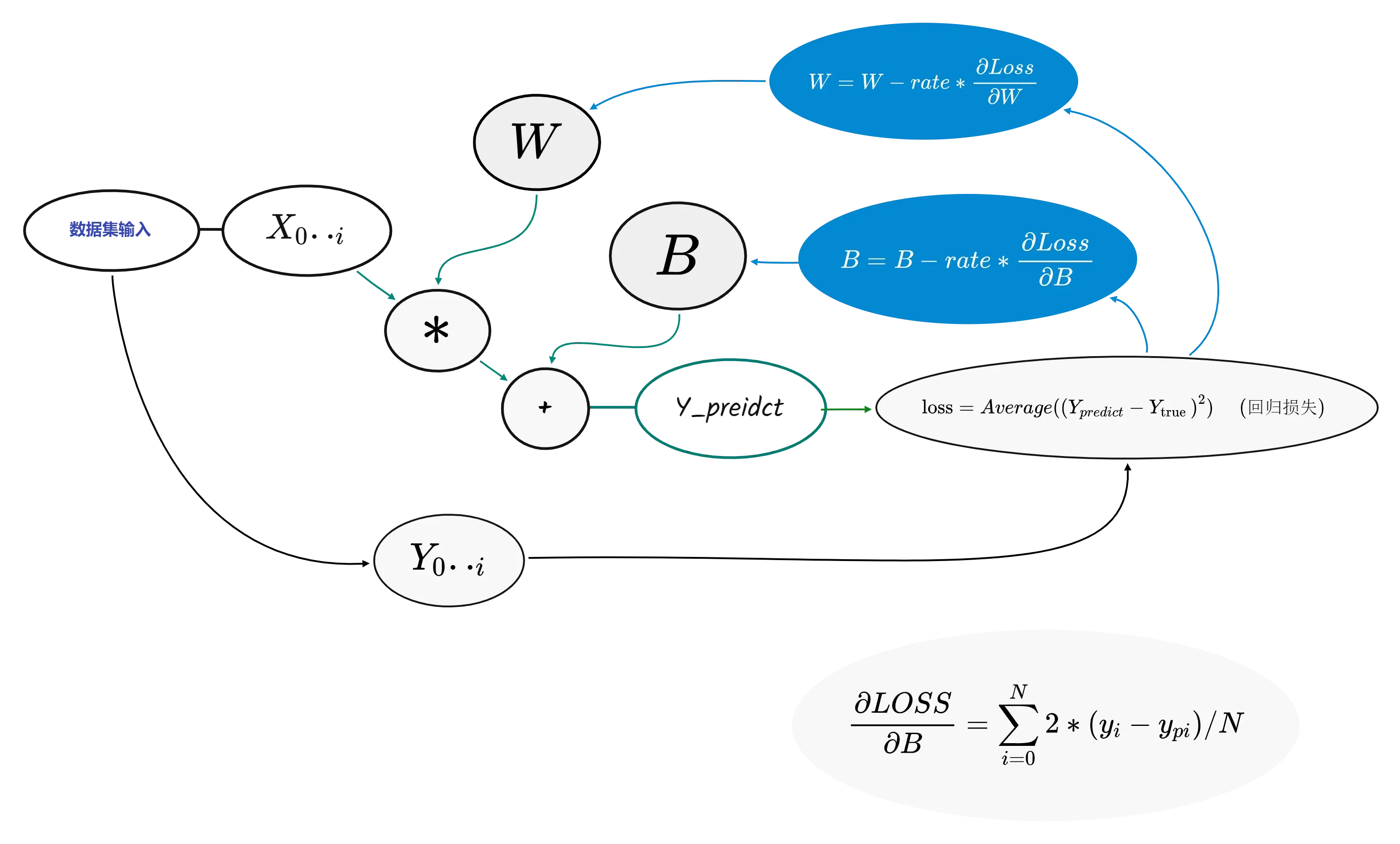
对于W和B其计算类似,这里单独说B即可
对于B的梯度满足下式,值得注意的是这里的Loos求取的是平均值实际上出来的是一个标量,对于标量的梯度计算实际上也是一个平均值(这里值得思考一下)。
反向传播后对B进行梯度下降:
梯度下降以后再次进行正向传播即可,计算出来Y_p,最后计算出来Loss。
前向传播满足以下公式:
代码显示如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
# 1 构造数据
x_number = 50
x = torch.rand([x_number, 1])
y = 3 * x + 0.8
rate = 0.01
study_time = 3000
# 2 正向传播 和 反向传播
w = torch.rand([1, 1], requires_grad=True, dtype=torch.float32)
b = torch.rand(1, requires_grad=True, dtype=torch.float32)
y_preidct = torch.matmul(x, w) + b
def forward_propagation():
global x, w, b, y_preidct
y_preidct = torch.matmul(x, w) + b
# 计算 loss
loss = (y - y_preidct).pow(2).mean()
return loss
def back_propagation():
global x, w, b, loss, rate, y_preidct
test = 0.0
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
# 反向传播
loss.backward()
w.data -= w.grad * rate
b.data -= b.grad * rate
#此处为了验证b的梯度进行计算
# for j in range(x_number):
# test += ((y[j] -y_preidct[j].item()) * 2)
# print("b:", b.grad)
# print("b_t:", test/x_number)
# 3 训练部分
for i in range(study_time):
loss = forward_propagation()
back_propagation()
if i % 10 == 0:
print("w,b,loss", w.item(), b.item(), loss.item())
# 4 画图部分
predict = x * w + b # 使用训练后的w和b计算预测值
plt.scatter(x.data, y.data, c="r")
plt.plot(x.data.numpy(), predict.data.numpy())
plt.show()
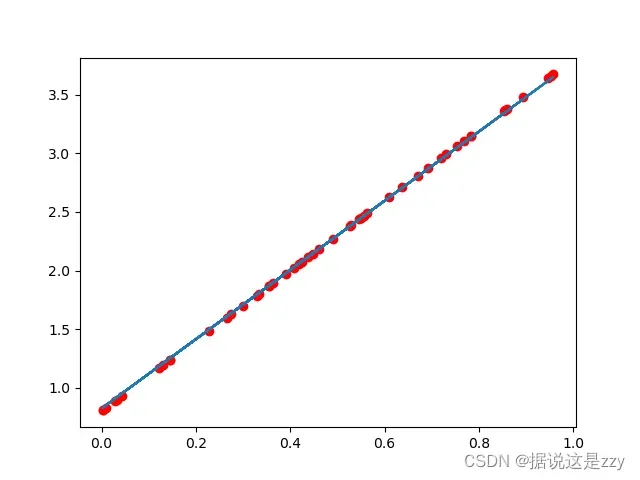
红色是数据集结果,蓝色是训练结果:
训练次数较少时,拟合曲线不正确:
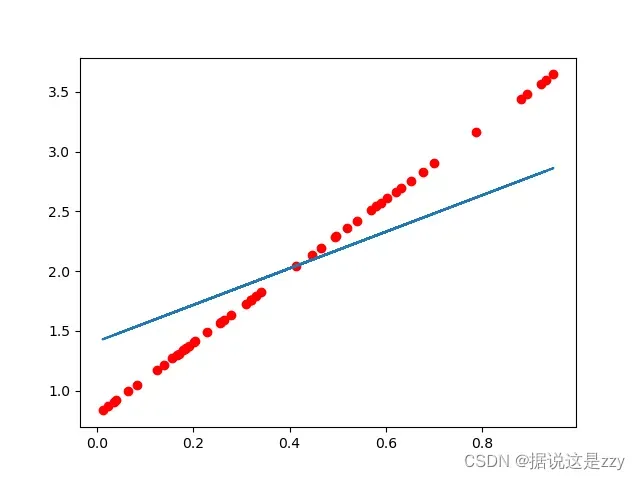
当学习率降低(变化范围缩小)时,增加学习次数可以得到很好的效果:
参考:
国内教程 偏理论 (10 -13 节)
youtobe教程 (第三节)(需要科学上网)有需要搬运联系我
方向导数1
方向导数2
版权声明:本文为博主据说这是zzy原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_20540901/article/details/123157368