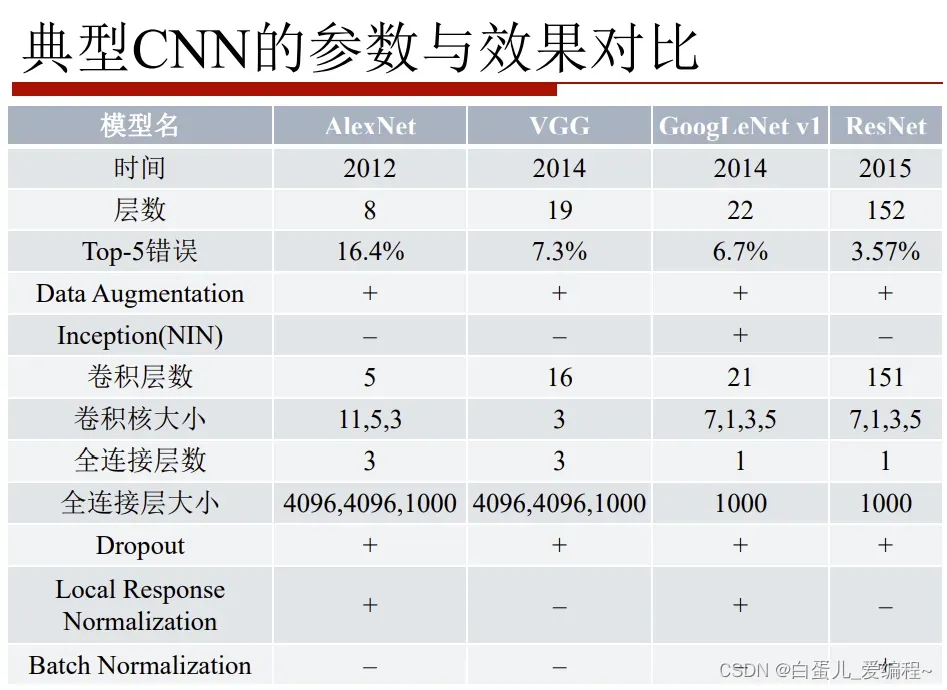
一.图像分类简单介绍
1.什么是图像分类
判断图片中是否有某个物体
一个图对应一个标签
性能指标
(1)Top1 error —-前1中1
(2)Top5 error —-前5中1
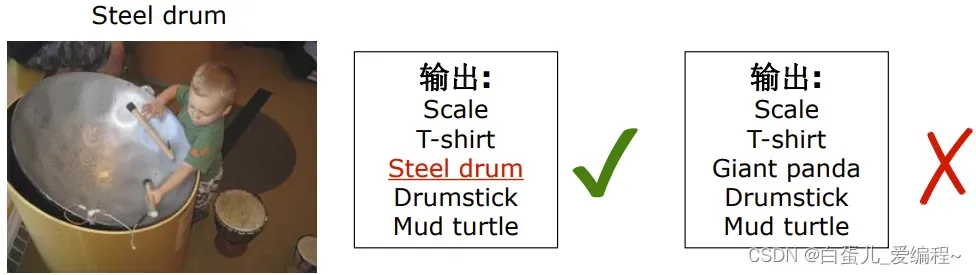
2.ILSVRC竞赛
ILSVRC全称为ImageNet Large ScaleVisual Recongnition Chalenge
竞赛的内容有:
(1)图像分类
1000个分类
训练集(1.2M),验证集(50K),测试集(150K)
(2)场景分类
来自MIT的Places2数据集(图片10M+,分类400+)
365个场景分类
训练集(8M),验证集(36K),测试集(328K)
(3)物体检测
(4)物体定位
(5)场景解析
ImageNet数据集:
根据WordNet组织的图片集
100,000+个词/词组(sysnsets)
8000+个名词
为一个名词提供平均1000张图片
总共14,197,122张图片
支持21,841个synsets
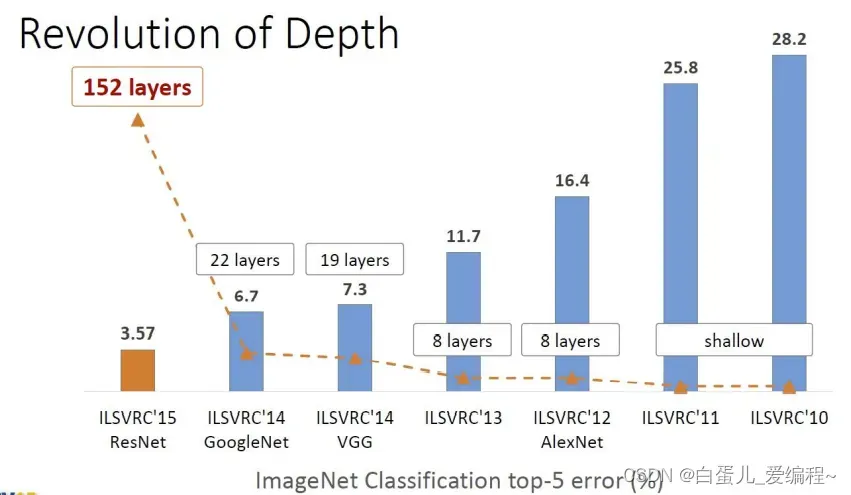
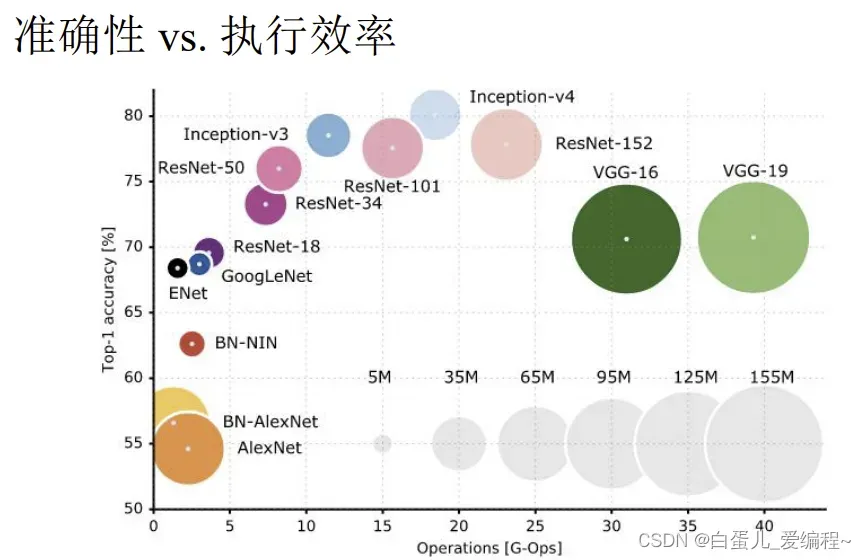
3.ImageNet的性能进化
从有竞赛开始,分类的性能,每年都会有显著提升,其中几个变革性的分类模型如下图。
4.CIFAR-10数据集
该数据集共有60000张彩色图像,这些图像分辨率是32*32,分为10个类,每类6000张图
其中有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批
测试批的数据里,取自10类中的每一类,每一类随机取1000张

二.分类模型
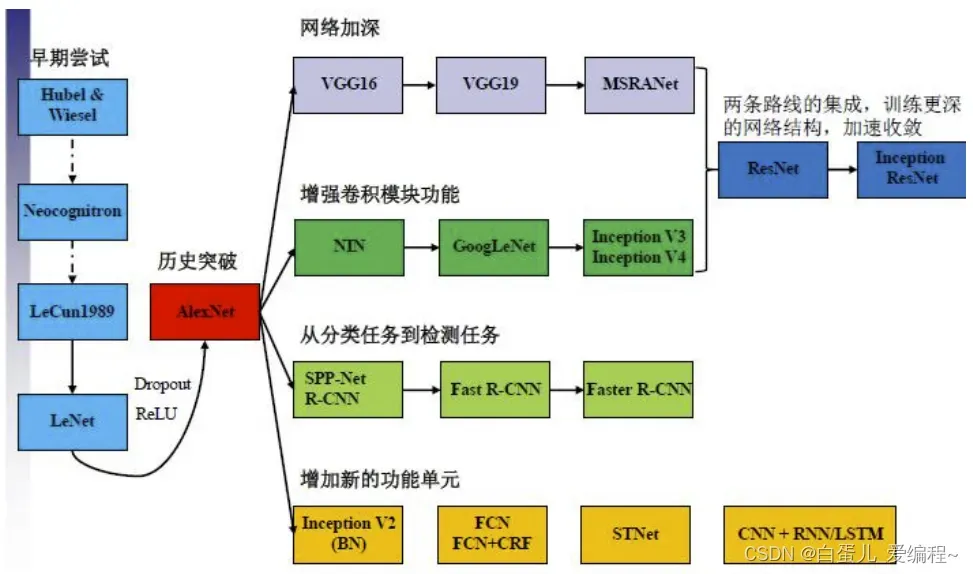
1.网络进化
网络:AlexNet→VGG→GoogLeNet→ResNet
深度:8→19→22→152
VGG结构简洁有效
容易修改,迁移到其他任务中去
高层任务的基础网络
性能竞争网络
GoogleNet:Inception v1 → v4
Split-transform-merge
ResNet:ResNet1024→ResNeXt
深度,宽度,基数
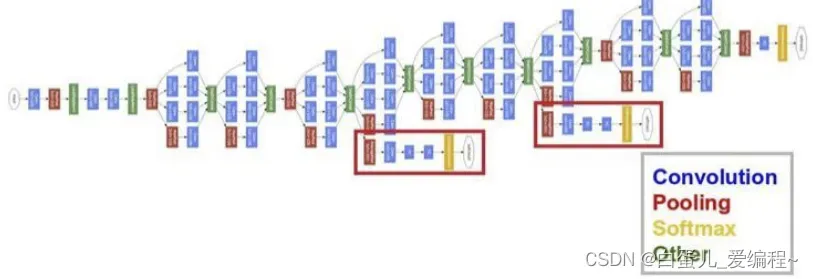
2.CNN结构的演化
3.AlexNet网络
(1)ImageNet-2012竞赛第一
标志着DNN深度学习革命的开始
5个卷积层+3个全连接层
60M个参数+650K个神经元
2个分组→2个GPU(3GB)
使用两块GTX 580 GPU训练了5-6天
新技术
ReLU非线性激活
Max pooling池化
Dropout regularization
还包括后来不被认可的LRN
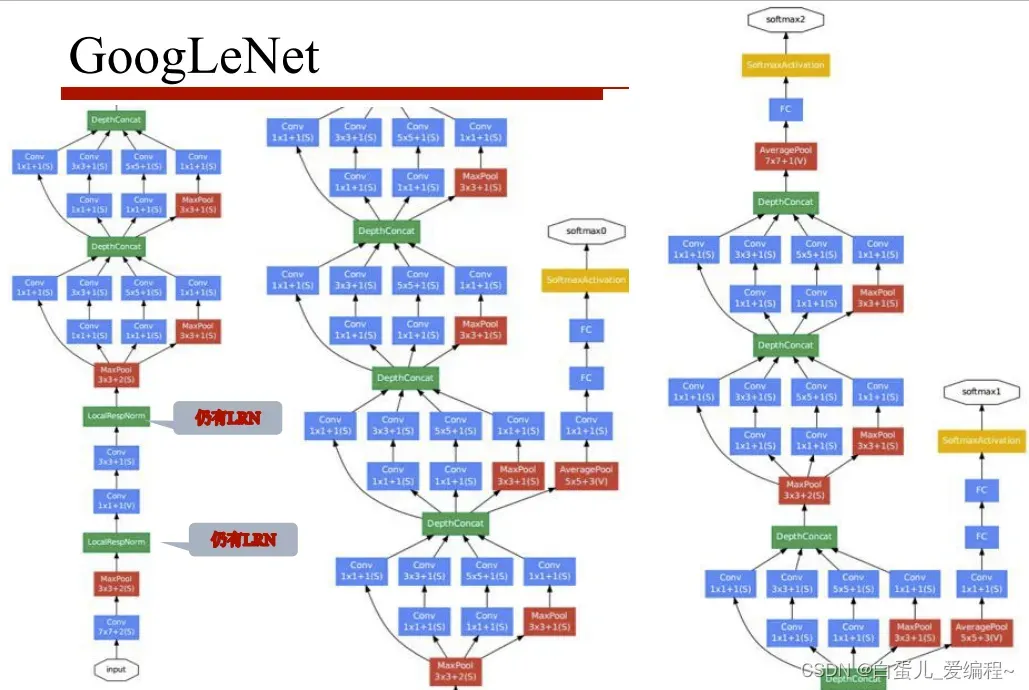
(2)模型示意图
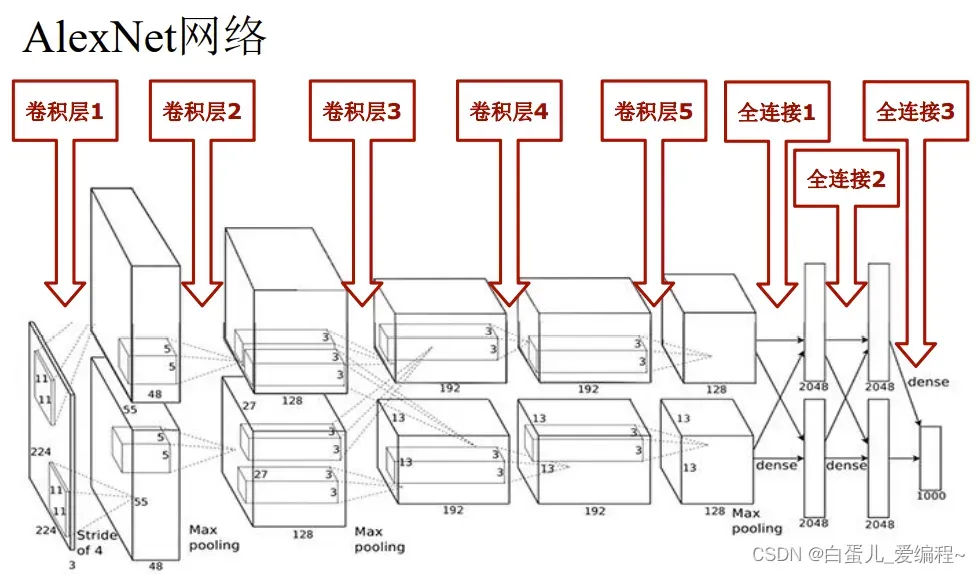
(3)网络解析
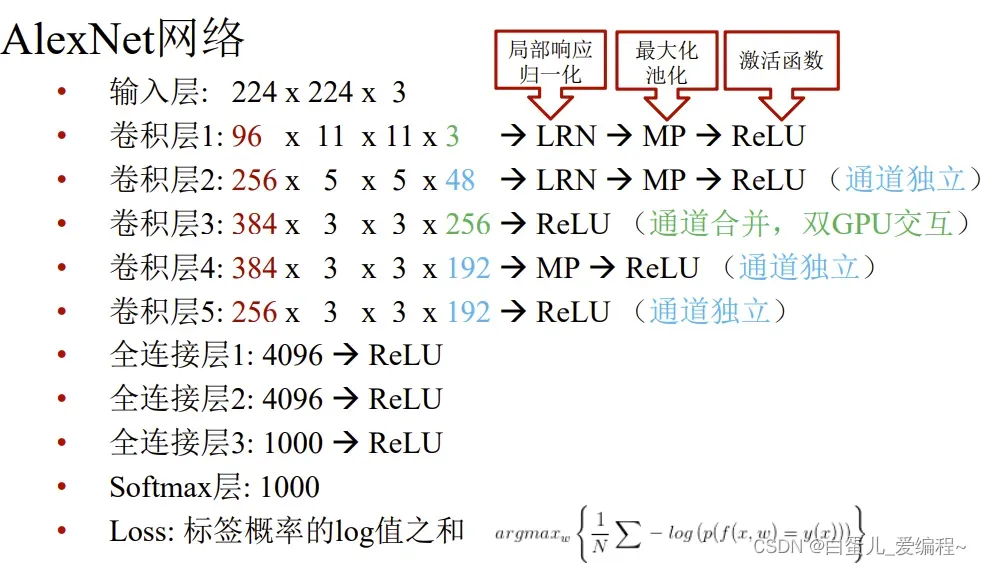

(6)局部响应归一化(LRN)
Local Response Normalization
后面被证实作用性不大,了解一下就可以了
神经元的侧抑制机制
某个位置(x,y)上沿通道方向上的归一化
n为邻域值,N为通道数
超参数:k=2,n=5,α=0.0001,β=0.75

(7)Network-in-Network网络(NiN)
提高CNN的局部感知区域的非线性
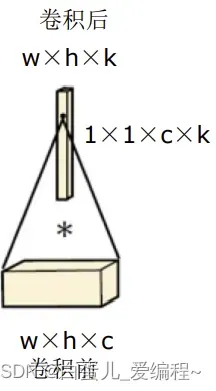
卷积层→1×1卷积层→Max池化层
NiN源自2014年ICLR的一篇论文,Alexnet网络参数大小是230M,采用NiN的算法才变为29M.
1×1卷积,实现的是“同一个像素点上”的各个通道的值的线性组合
这里的“全连接”指的是卷积前通道数与卷积后通道数之间的。
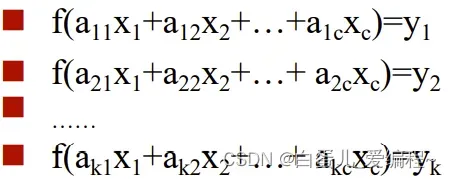
1×1卷积有两个方面的作用
实现跨通道的交互和信息整合
进行卷积核通道数的降维和升维
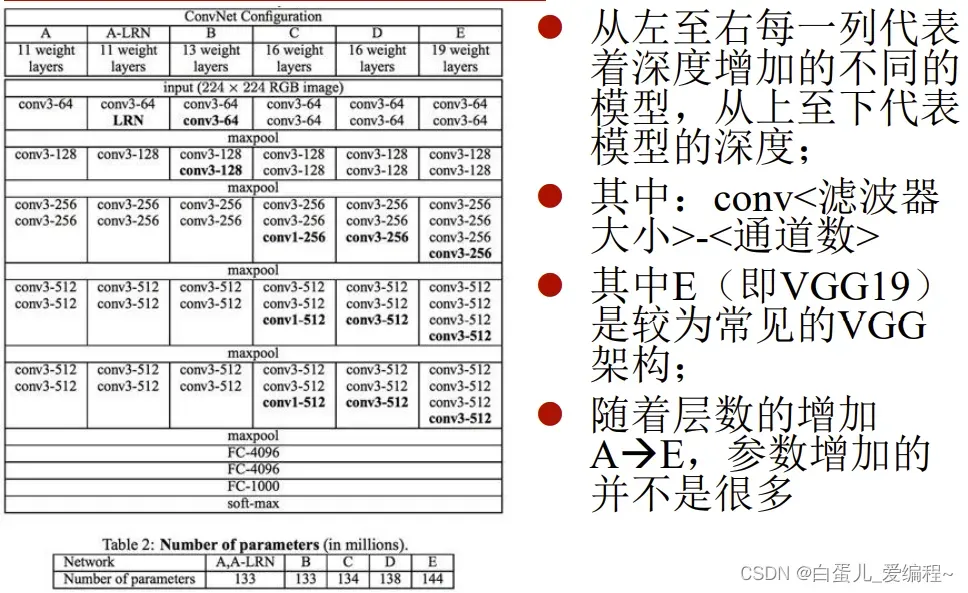
4.VGG网络
(1)简介:
VGG提出的目的是为了探究在大规模图像识别任务中,卷积网络深度对模型精确度有何影响。
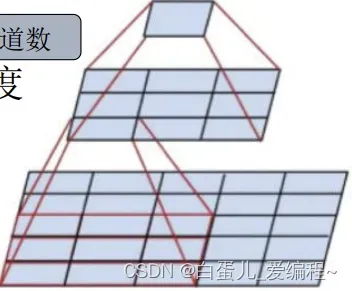
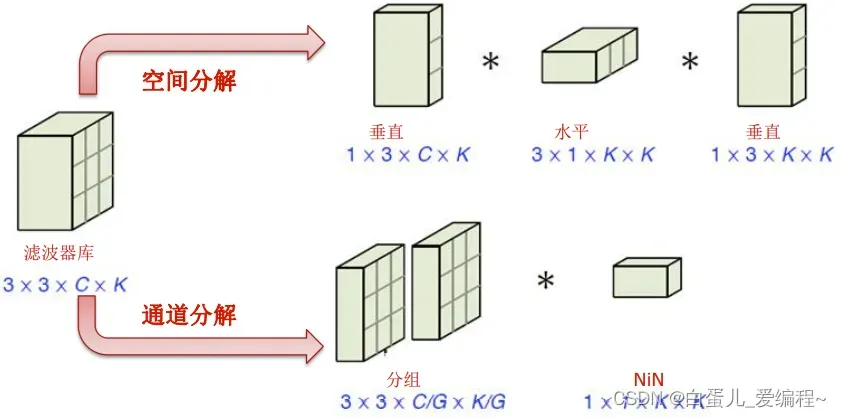
一个大卷积核分解成连续多个小卷积核
核分解:7×7核→3个3×3核(由ReLU连接)
参数数量:49C**2 →27C**2 (C为通道数)
减少参数,降低计算,增加深度
ImageNet-2014竞赛第二
网络改造的首选基础网络
5.GoogLeNet
(1)简介:
GoogLeNet出现之前,主流的网络结构突破大致是网络更深(层数),网络更宽(神经元数),但现在看来这纯粹是增大网络的缺点。
ImageNet-2014竞赛第一
进化顺序:
Inception V1 → V2 → V3 →V4
为了提升性能:
减少参数,降低计算
增加宽度,深度
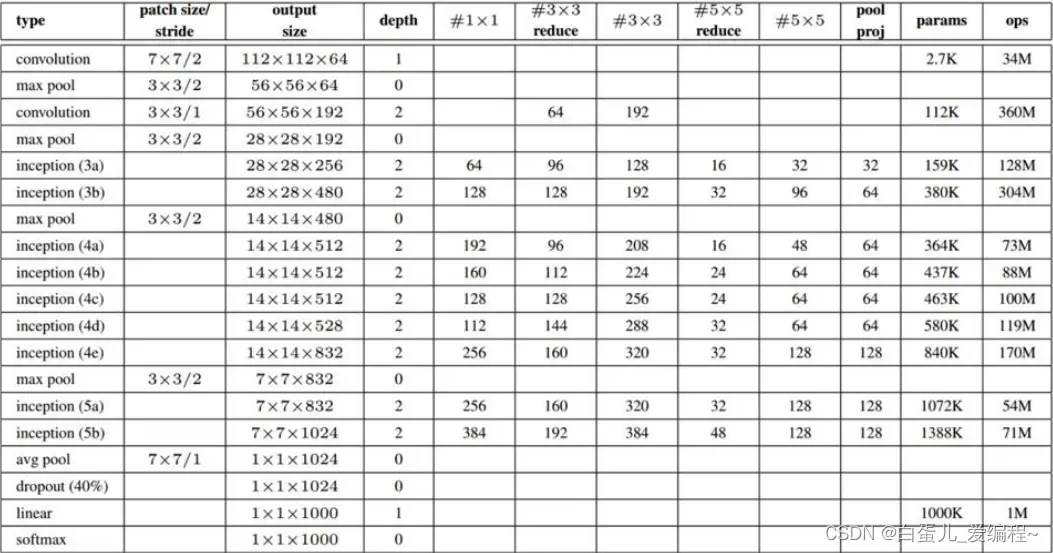
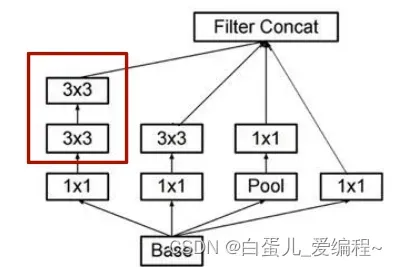
(2)Inception V1网络
1)核心组件Inception Architecture
split-Merge→1×1卷积,3×3卷积,5×5卷积,3×3池化
增加网络对多尺度的适应性
增加网络深度
Bottleneck Layer→使用NiN的1×1卷积进行特征降维
大幅降低计算量
2)取消全连接
参数量大,减负
3)辅助分类器
解决前几层的梯度消失问题
1)核心组件Inception Architecture(稀疏连接结构)
1*1,3*3,5*5的卷积和3*3的pooling组合在一起
亮点是从NIN中引入了1*1卷积核
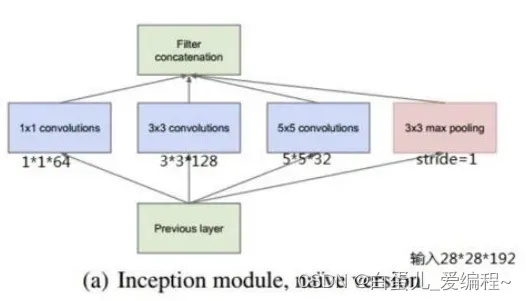
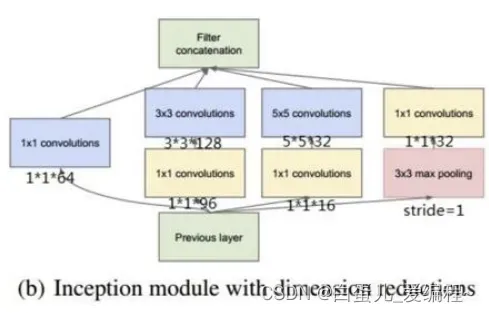
上图中:假设前一层的输出为28*28*192,则:
a的weights数量为:
1*1*192*64 + 3*3*192*128 + 5*5*192*32 = 387072
a的输出feature map大小为:
28*28*64 + 28*28*128 + 28*28*32 + 28*28*192 = 28*28*416
b的weights数量为:
1*1*192*64 + (1*1*192*96 + 3*3*96*128)+ (1*1*192*16 + 5*5*16*32)+ 1*1*192*32 = 163328
b的输出feature map大小为:
28*28*64 + 28*28*128 + 28*28*32 + 28*28*32 = 28*28*256
可以看出1*1 conv一方面减少了weights,另一方面降低了dimension
2)取消全连接层
本质上是一个全尺寸的卷积层
全连接层占用了大量参数
AlexNet: 58.6M(6×6×256×4096 + 4096×4096 + 4096×1000)
VGG: 72M(7×7×256×4096 + 4096×4096 + 4096×1000)
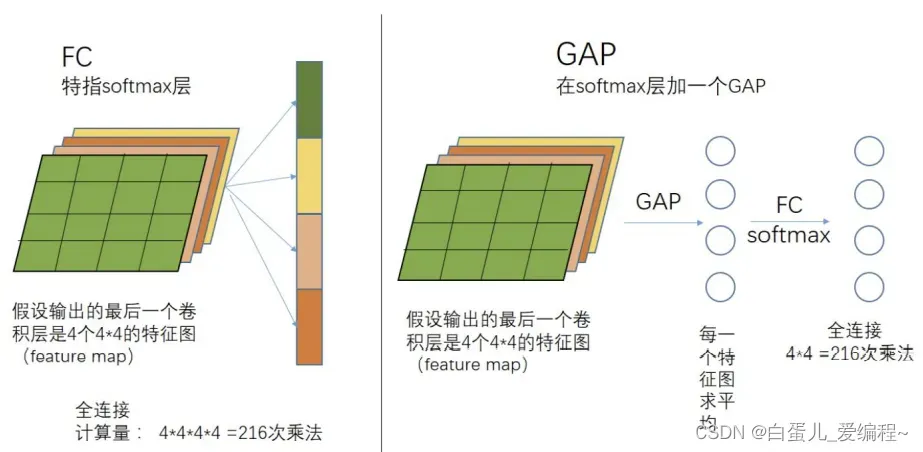
GoogleNet由全局平均池化替代
输入:7×7×1024
输出:1×1×1024
一大趋势
全局平均池化介绍:
全局平均池化就没有size,它针对的是整张feature map
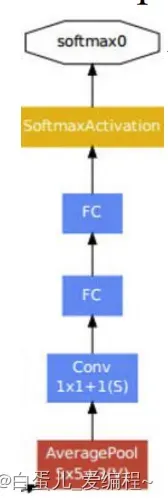
3)2个辅助分类器
深网络中,梯度回传到最初几层,存在严重消失问题
有效加速收敛
测试阶段不使用
(3)Inception V2网络
核心组件
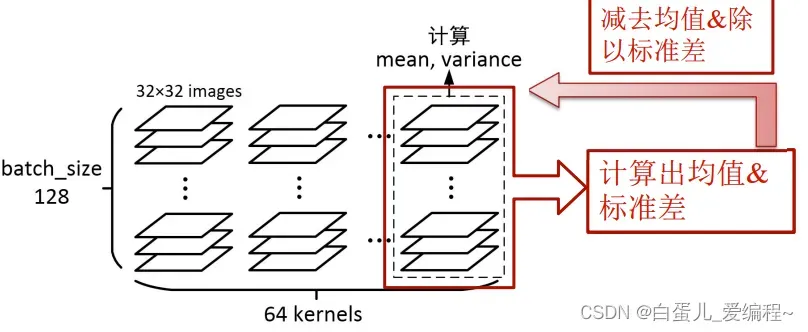
Batch Normalizatio(批归一化)
白化:使每一层的输出都规范到N(0,1)
解决Internal Covariate Shift问题
允许较高学习率
取代部分Dropout
5×5卷积核→2个3×3卷积核
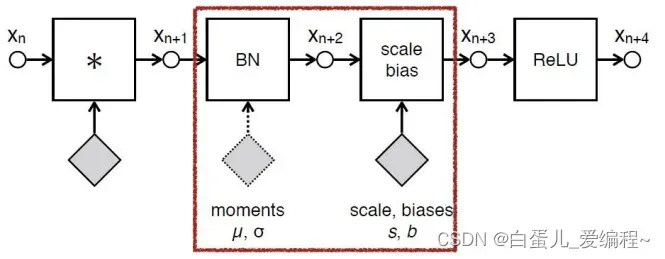
1)Batch Normalization批归一化
在batch范围内,对每一个特征通道分别进行归一化
所有图片,所有像素点
训练阶段→实时计算
测试阶段→使用固定值(对训练求平均)
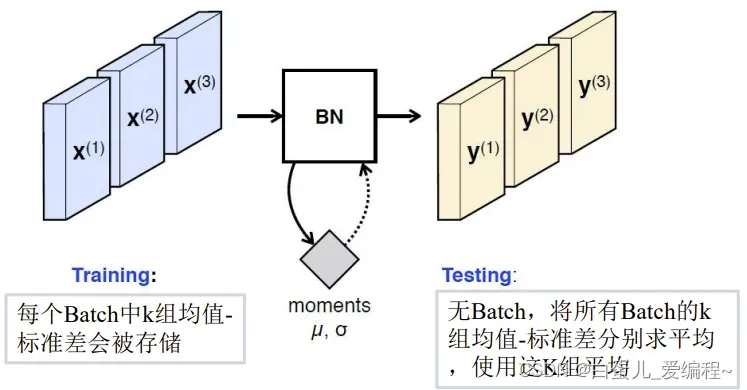
位置:卷积→BN→ReLU
配对使用scale&shift
添加一组逆算子:scale乘子,bias偏置
这组参数需要学习 y**(k)= γ**(k)x**(k) + β**(k)
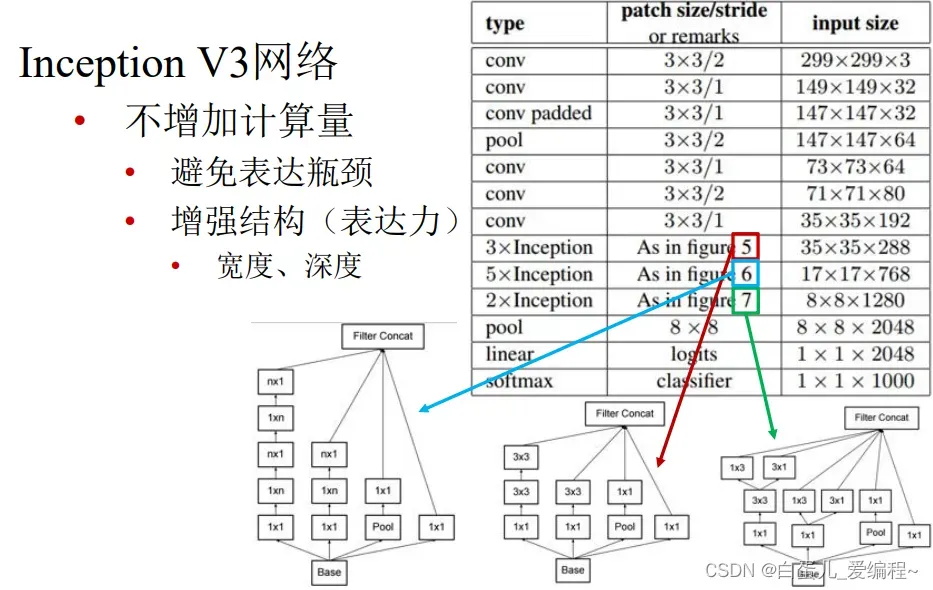
(4)Inception V3网络
核心组件
非对称卷积:
N×N分解成1×N→N×1
降低参数数量和计算量
在中度大小的feature map 上使用效果才会更好,对于m*m大小的feature map,建议m在12道20之间。
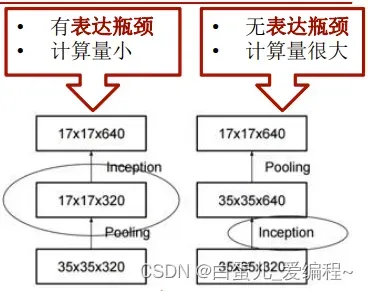
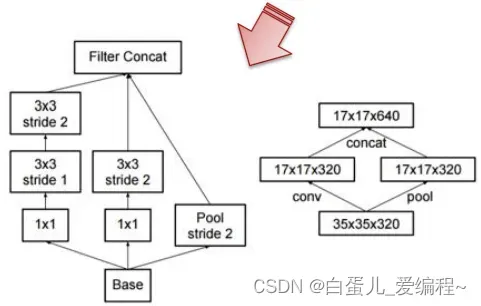
Inception V3 优化了Inception Module的结构,V3有三种不同的结构,如下图。
这些Inception Module只在网络的后部出现,前部还是普通的卷积层
高效的降尺寸
避免表达瓶颈
降尺寸前增加特征通道
2个并行分支
卷积分支+池化分支
串接分支结果
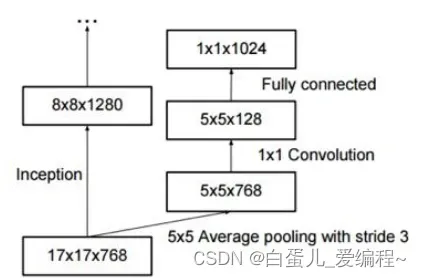
取消浅层的辅助分类器
完全无用
深层辅助分类器只在训练后期有用
加上BN和Dropout,主分类器Top1性能提升0.4%
正则化作用
用在最后一层17×17后
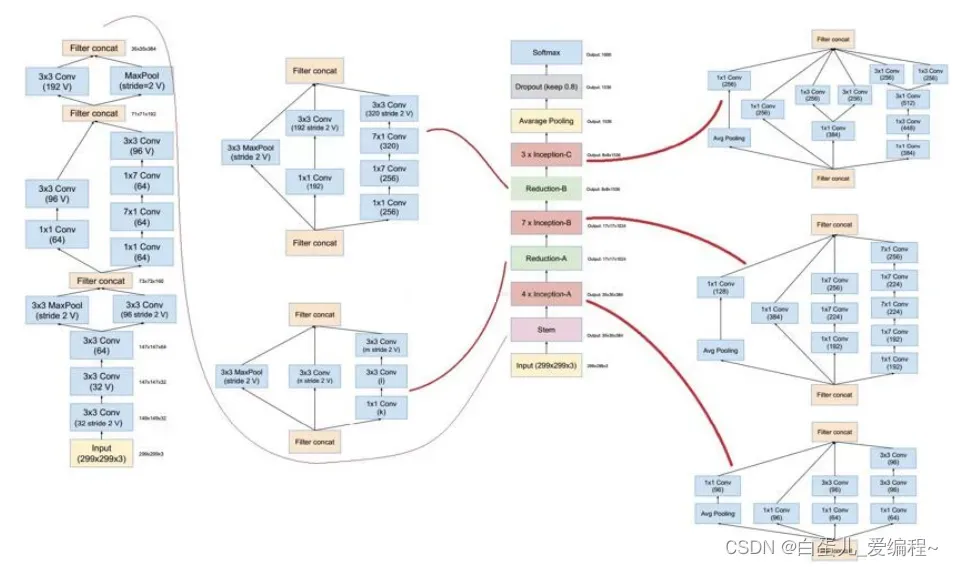
(5)Inceoption V4网络
(6)总结Iception
1)代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层
2) 不需要人为的决定使用哪个过滤器,是否需要池化层等,有网络自行决定这些参数
3)即:预先给网络添加所有可能值,将输出连接起来,让网络自己学习它需要什么的参数
4)Iception网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般
6.ResNet残差网络
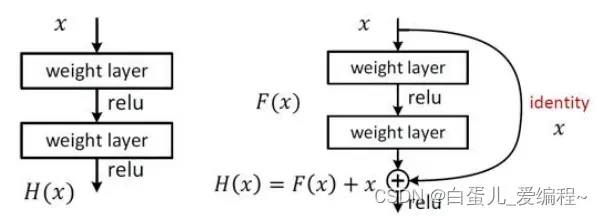
(1)介绍:
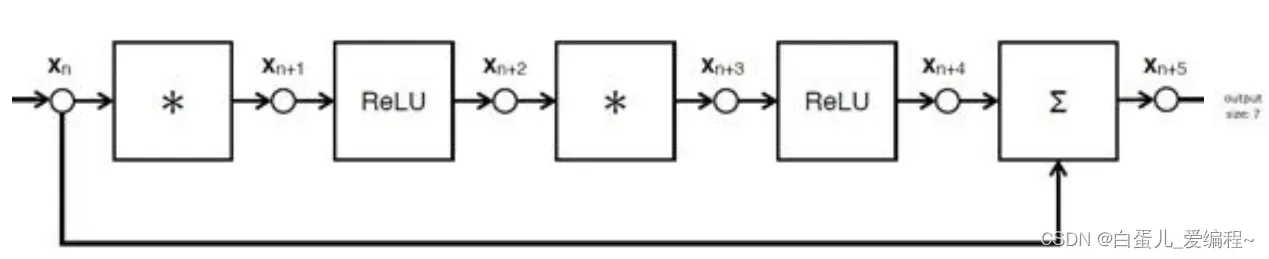
核心组件Skip/shortcut connection
Plain net:可以拟合出任意目标映射H(x)
Residual net
可以拟合出任意目标映射F(x),H(x) = F(x) + x
F(x)是残差映射,相对于identity来说
其他设计
全是3×3卷积核
卷积步长2取代池化
使用Batch Normalization
取消
Max池化
全连接层
Dropout
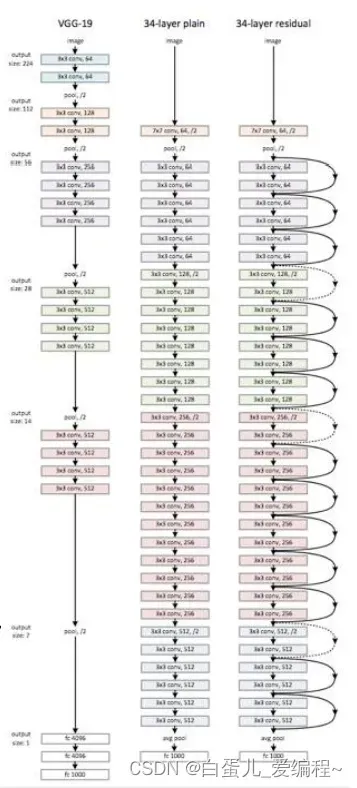
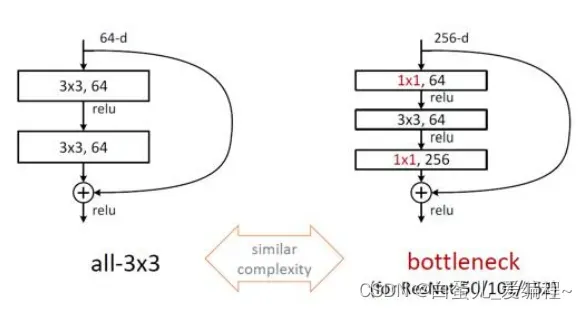
ResNet残差网络,使用了更深的网络,根据BootLeneck优化残差映射网络
原始残差映射网络:3×3×256×256→3×3×256×256
优化后的残差映射网络:1×1256×64→3×3×64×64→1×1×64×256
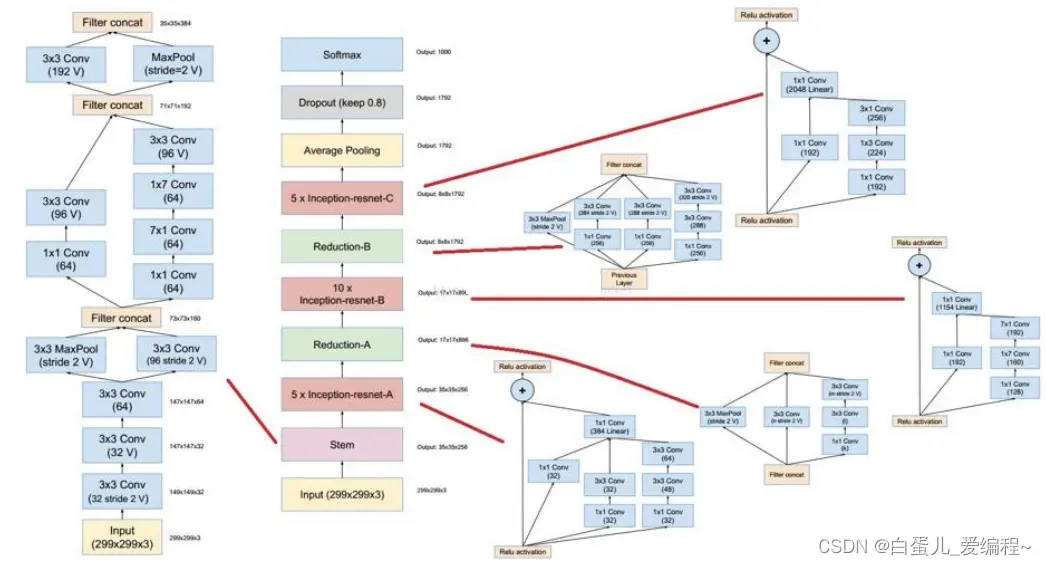
Inception-ResNet网络(如下图)
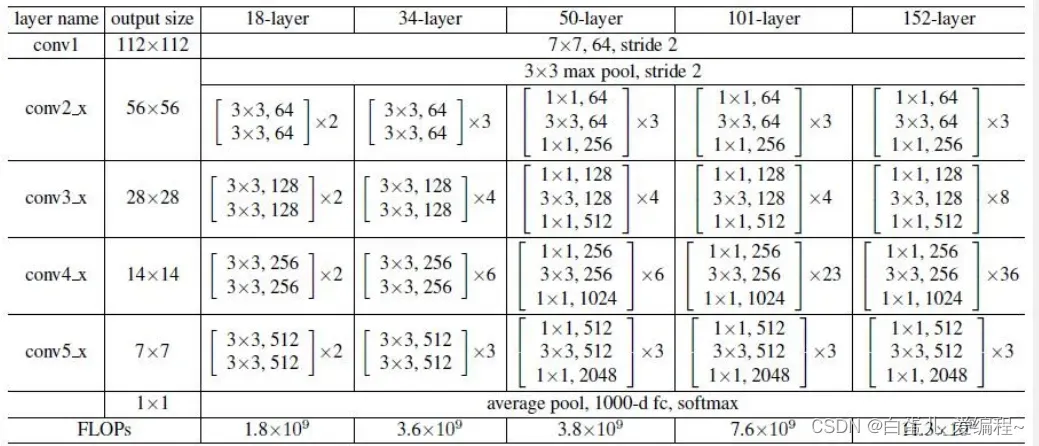
7.ResNeXt网络
(1)介绍
1)提出“深”和“宽”之外的第三个维度
2)cardinality(基数)
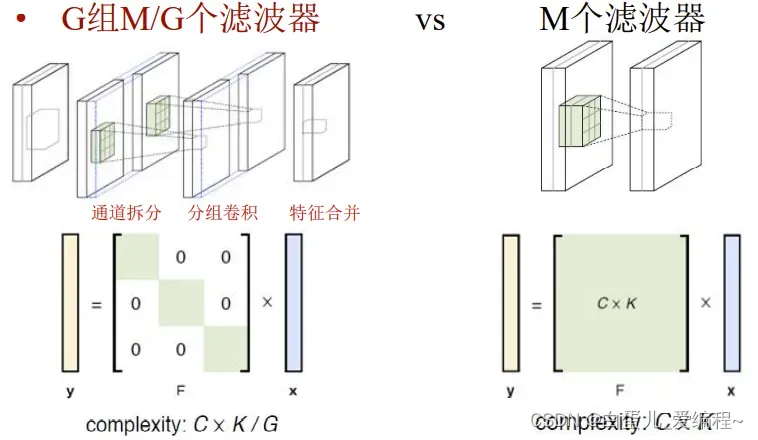
采用Split-Transform-Aggregate策略
将卷积核按照通道分组,形成32个并行分支
低纬度卷积进行特征变换
加法合并
3)同参数规模下,增加结构,提高模型表达力
100层ResNeXt = 200层ResNet
ILSVRC-2016竞赛第二
4)ResNeXt实际上就是将AlexNet中的group convolution引进了ResNet中,以获得更少的参数。
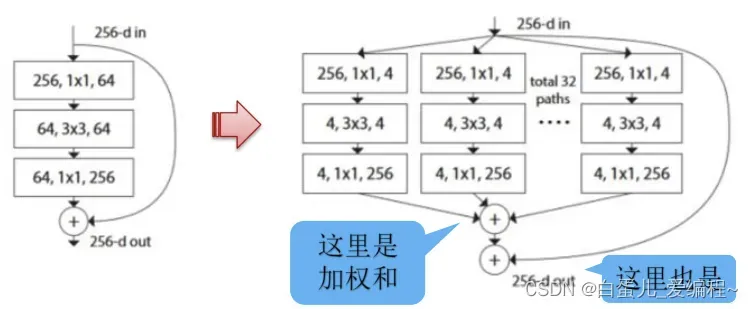
这里的group convolution用了32×4d块结构。
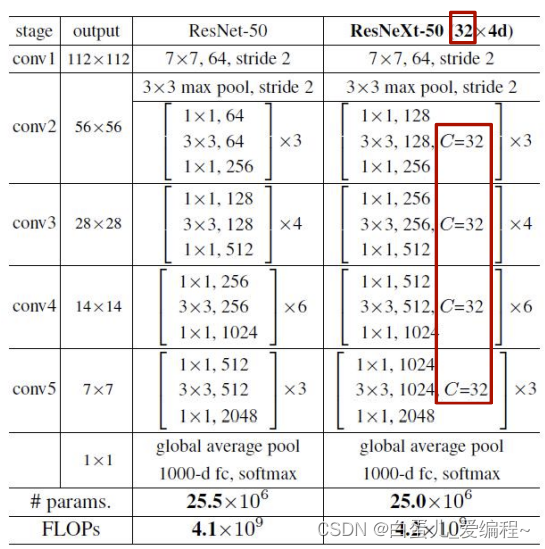
resnet的参数量为:
256*64 + 3*3*64*64 + 64*256 = 70k
ResNeXt的参数量为:
C*(256*d + 3*3*d*d + d*256)
当C取32,d=4时,上式也等于70k
5)ResNeXt网络打破或deeper,或wider的常规思路,ResNeXt则认为可以引入一个新维度,称之为cardinality。增加cardinality基数可以不断提高性能。

(2)32×4d结构参数
1)32个分支
2)每个分支4通道
8.CNN设计准则
(1)避免信息瓶颈
卷积过程中
空间尺寸H×W逐渐变小
输出通道数C逐渐变多
H×W×C要缓慢变小
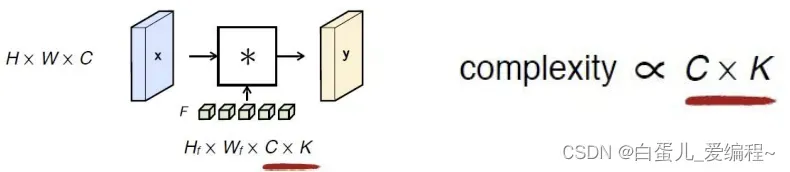
(2)通道(卷积核)数量保持在可控范围内
输入通道数量C
输出通道数量K
参数数量Hf × Wf ×C × K
操作数量[(H×Hf)/ stride ] × [ (W×Wf)/ stride ] × C × K
从上式,可看出卷积核的大小对总计算量的影响
 (3)感受野要足够大
(3)感受野要足够大
卷积时基于局部图片的操作
捕捉大尺寸内容
多个小尺寸卷积核 VS 一个大尺寸卷积核
参数少,计算快
多个非线性激活
(4)分组策略→降低计算量
(5)低秩分解→降低参数&计算量
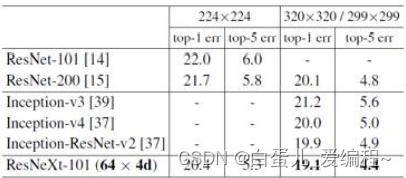
最后,放上ImageNet竞赛分类组的各模型性能示意图
文章出处登录后可见!