从23年初,ChatGPT火遍全球,通过其高拟人化的回答模式,大幅提升了人机对话的体验和效率,让用户拥有了一个拥有海量知识的虚拟助手,根据UBS发布的研究报告显示,ChatGPT在1月份的月活跃用户数已达1亿,成为史上用户数增长最快的应用软件。表面上看,ChatGPT是一个受欢迎的聊天机器人,但我们认为其背后的GPT大模型能称得上是一个技术爆炸,并且目前处于飞速的进化过程中。
图:各大热门平台突破1亿月活用户所用的时间

当用户逐渐开始熟悉这款“无所不知”的对话机器人的时候,ChatGPT的母公司OpenAI又在3月14日发布了新一代的GPT4,这是一款支持多模态(大量文字+图片)输入的对话机器人。它的强大智能在几个月时间内又一次进化了一大步,例如:它可以根据一个草图在很短时间内生成做出这个网站所需要的HTML代码。若这样的功能放在几个月前,估计也很少有人相信会在2023年就能出现。
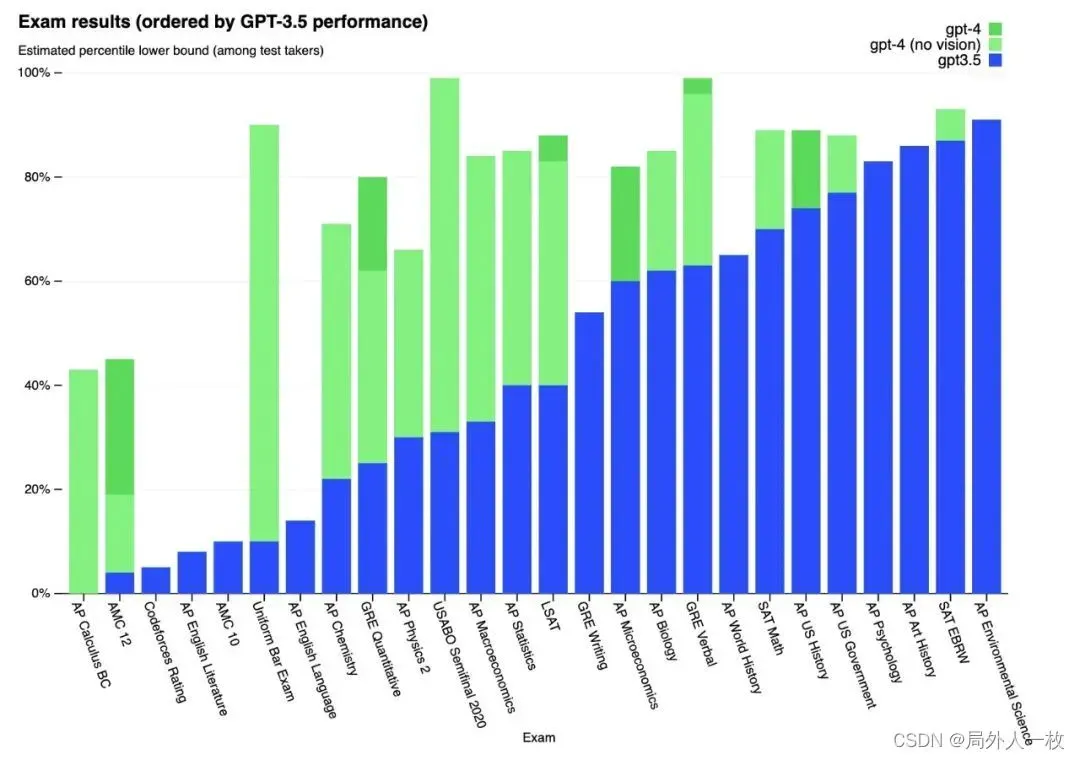
GPT不只是在对话领域有巨大的成功,而且它在众多人类的标准化的测试中,也是非常的厉害。它在多个学术和职业考试中超过人类,比如在美国律师考试中,GPT4的分数打败了90%的人类;在美国高考SAT中拿到700+的分数(满分800),这样的分数远高于美国顶级大学-常青藤八校录取新生的平均分数。当笔者看到了GPT4在众多考试中的得分后,也陷入了沉思:未来的AI会在绝大多数领域都超过我们人类,它的出现必将改变社会对于我们知识技能结构的需求。所以理解GPT,也能帮助我们去判断,未来积累什么样的知识,培养什么样的技能才是有价值的。
(GPT-4,https://openai.com/research/gpt-4)
首先,我们先简单的介绍一下ChatGPT和AIGC:
他们都是人工智能的应用场景。
-
ChatGPT:Chat Generative Pretrained
Transformer,即可生成式预训练对话系统,ChatGPT是由OpenAI开发的一种基于自然语言处理的人工智能技术,它是一种大型预训练语言模型,使用了GPT(Generative
Pretrained
Transformer)的架构,并使用深度学习算法进行训练。ChatGPT可以生成高质量、连贯的自然语言对话,它可以对话生成、问答系统、文本摘要、语言翻译等自然语言处理任务进行处理。 -
AIGC:Artifical Intelligence Generated
Content,即人工智能所生成的内容。可以看出,两者都是人工智能应用的场景,而AIGC的范畴比ChatGPT更广,ChatGPT是AIGC的在文字和语言类内容的子领域。
这样令人惊奇的技术背后最重要的原理是什么呢?
原理一:全域知识
拥有在其巨大数据库和互联网中几乎所有的知识,目前千亿量级的,未来会随着模型的进化,进一步变多,变得更加“无所不知”。它把所有领域的知识都看做语言的模式,这里的语言不是狭义我们说的语言,而是统一了代码,公式,符号等所有人类传输信息的语言。所以当用户与之交谈的时候,ChatGPT让用户感觉到的是一个无所不知的系统。
原理二:大语言模型
ChatGPT通过背后的GPT大语言模型(Large Language Model, LLM)回答问题的时候,会逐字打出答案。它是根据前面的文字来输出后面的文字,所以它所输出的答案并不是由检索数据库中的已有答案来生成的, 也不像搜索引擎中按照引用次数来判断关联性,而是数学计算的结果 – 他是通过计算上一段文字后续会出现的文字的条件概率来生成答案。
这个原理的深刻意义:人类产生的所有文本,无论是一种科学原理,历史知识还是程序代码,他们都可以用大语言模型来表达。
所以只要拥有足够好的语言模型,那么现实生活中的任何信息都是完美语言模型的一种采样结果。大语言模型不直接掌握知识,它的本质是一个拥有几千亿参数的超大公式。它输出的回答是概率模型判定后的随机答案,不是人类大脑那种通过analog形态来积累(经验,归纳,建模的过程),所以它的回答不可回溯(traceability);但由于它读取了世界上公开的全部知识,所以他通过条件概率得出的不同组合的回答往往能看起来合理,也有了类似人类的创作力。它是通过“隐性”的方式积累知识,然后“显性”的表达知识。
那么ChatGPT的局限在哪呢?由于它积累的“知识”是来自于历史和公开数据,且它没有人类的推理能力,所以如果我们问它关于预测未来或者某些细分专业问题的时候,ChatGPT大概率会给出一个看似一本正经,实际胡说八道的答案。
也正因为大模型上述的局限性,拥有细分领域数据和知识的公司可以通过大模型的API接口来训练拥有内部数据和知识的小模型,专门提供给内部员工和客户使用。所以从商业的角度来看,GPT这样的超级大模型会成为技术底座,它可以赋能各个行业的公司去开发它们内部的小模型,而拥有这样的小模型可以极大的提高公司内部和上下游伙伴的效率。Open AI等拥有这样大模型的公司最终会形成类似苹果和安卓的生态体系,有无数的公司围绕这个生态进行生产和开发。
原理三:训练路径
使用时,我们会发现ChatGPT会说人话,有普世价值观,很多时候能做到知之为知之,并且能给出推理过程。那么他是怎么练成的的呢?为了让ChatGPT懂得与人类对话,大语言模型都需要经过训练。
- 首先需要标注的数据进行监督学习,缺点是这种监督学习体量有限;
- 第二步是用人工做微调(fine-tuning),对第一步产生的回答进行打分,得到奖励模型;
- 第三步用第二步得出的模型进行大量的无监督训练,自动让模型自我做调整。用的人越多,也会让模型得到更好的训练结果。经过了千亿规模参数训练后的模型,就变成了呈现在我们面前,那个无所不知,对答如流的聊天机器人。
综上来说,Open AI找到了一种在当下技术的基础设施所能支持的情况下,最适合AI去积累“知识”和输出结果的算法,和我们聊天的ChatGPT其实只是它应用场景的一部分。它最具革命意义的产品是在ChatGPT这个聊天机器人背后的大语言模型,它相当于构建出了一个人类和机器之间的无缝桥梁。我们之前为了让机器执行我们的命令,需要通过软件工程师进行大量的编程来实现,实际上是我们在“迁就”不懂人类语言的机器,而现在有了大语言模型,机器可以“无障碍”的听懂我们的语言,并很快的用机器执行我们的命令,这样的功能会极大的提升人类社会的生产力和发展速度,所以我们将其称为一个技术爆炸也不为过。
在不久的未来,随着这种技术的成熟应用,几乎所有行业都会发生巨大的变化。类似于30年前的互联网对我们所带来的变化。从90年代到现在,随着互联网的普及,它逐渐成为了我们生活中不可缺少的一部分,我们在网上进行办公,购物,学习,娱乐等方方面面的事。而接下来的几十年,随着大语言模型的普及,它给我们生活所带来的变化将绝不小于互联网在上一个30年给我们的变化。
文章出处登录后可见!