安装yolov5
安装命令如下下所示,包含了下载yolov5-6.1,及相关包安装命令。yolov5项目目前已经更新到6.2,支持对图像数据的分类,但使用较为麻烦,因此仅以6.1为例进行说明。安装yolov5后,切记不要安装wandb,使用该库会将自己的训练过程数据(loss和评价指标)上传到wandb.ai网站中,登录wandb.ai可以看到这些指标的可视化界面。而且,安装wandb后,运行项目都要先登录wandb,很麻烦。
git clone https://github.com/ultralytics/yolov5/tree/v6.1 # clone
cd yolov5
pip install -qr requirements.txt # install
测试数据
测试数据前要先准备好预训练模型(或者由代码自动下载相应的预训练模型),模型存储在项目的根目录下。
基本测试命令
这里的source是文件路径,支持测试文件、文件夹、http文件、glob通配符。
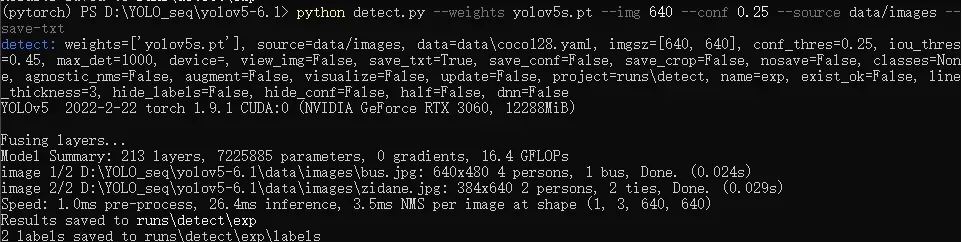
python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source (file/dir/URL/glob)
使用以下命令测试模型,测试结果
python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images --save-txt
程序执行输出如下所示,运行结果存储在runs\detect\exp中,保护可视化的图片和txt结果

测试数据的参数
如果想使用更多的控制参数,可以查看以下详细列表
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
模型训练
模型训练使用train.py。yolov5中常用的训练参数有:
--weights 预训练模型
--cfg 模型配置文件【models下的yaml文件】
--data 数据配置
--hyp 超参数配置
--epochs epoch设置
--resume 训练恢复
--device 训练设备 cuda device, i.e. 0 or 0,1,2,3 or cpu
--label-smoothing 标签平滑参数
--evolve 验证周期
--optimizer 优化器参数
--workers 数据加载器的数量(主要是占用内存)
--patience early stop的耐心参数
接下来将与coco128数据集为示例,进行训练。coco128是yolov5作者从coco数据集中挑选128个数据建立的子数据集,使用的也是coco 80类的标签。如果模型训练出来意外,请使用pip uninstall wandb,卸载掉wandb库,使用该库会将训练过程数据上传到https://wandb.ai/ 中。
使用官方预训练模型
–weights参数如果是[‘yolov5n.pt’, ‘yolov5s.pt’, ‘yolov5m.pt’, ‘yolov5l.pt’, ‘yolov5x.pt’,
‘yolov5n6.pt’, ‘yolov5s6.pt’, ‘yolov5m6.pt’, ‘yolov5l6.pt’, ‘yolov5x6.pt’]等默认名称,则会从ultralytics的官方仓库下载预训练模型
python train.py --img 640 --batch 16 --workers 2 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cfg models/yolov5s.yaml
部分训练过程输出,如下图所示
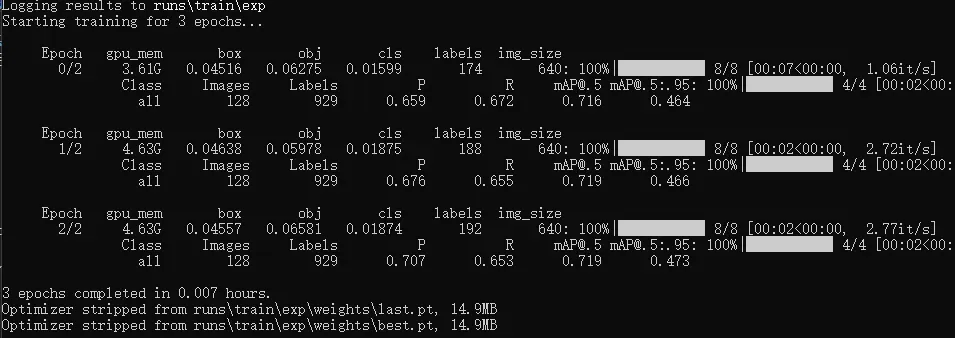
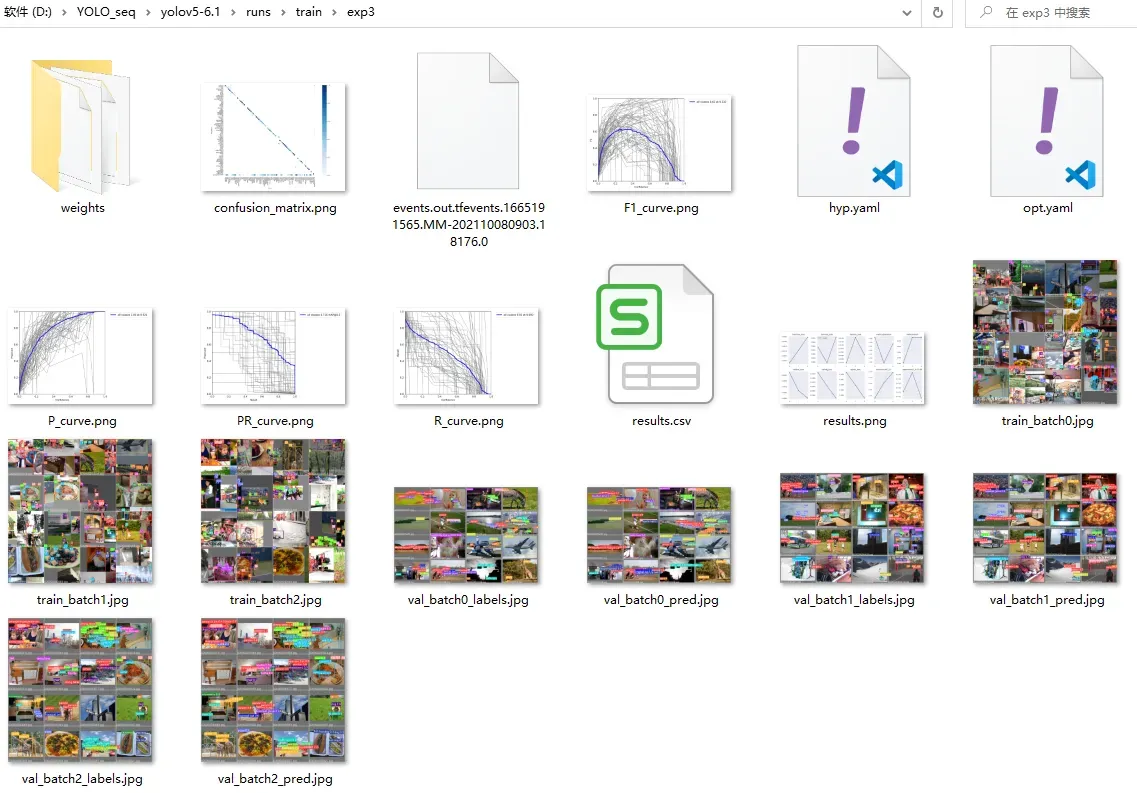
训练节省后保存的结果信息包含任务的超参数(opt.yaml中,数据集配置、模型、是否多卡训练、early stoping参数等等)、训练模型的超参数(hyp.yaml中)、训练过程中的loss信息(result.csv)、训练过程中的指标曲线等等信息。模型权重只保存了best和last两个,在weights目录下。
使用本地预训练模型
–weights参数如果是[‘yolov5n.pt’, ‘yolov5s.pt’, ‘yolov5m.pt’, ‘yolov5l.pt’, ‘yolov5x.pt’,
‘yolov5n6.pt’, ‘yolov5s6.pt’, ‘yolov5m6.pt’, ‘yolov5l6.pt’, ‘yolov5x6.pt’]等默认名称,则会在项目的root路径下加载预训练模型
python train.py --img 640 --batch 16 --workers 0 --epochs 3 --data coco128.yaml --weights yolov5s_local.pt
完整训练参数
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=2, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
训练超参数配置
支持对学习率(动量、衰减、预热等参数)、训练过程(各种loss、iou、anchor等参数)、数据增强过程(hsv变化参数、仿射变换参数、镜像翻转参数、mosaic、muxup、copy_paster参数)的控制。只需要将超参数存储为yaml格式,在命令行即可使用
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.3 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 0.7 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.9 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.1 # image mixup (probability)
copy_paste: 0.1 # segment copy-paste (probability)
模型评估
模型测试使用val.py实现,测试模型前要有模型、数据集,然后测试时还有iou、img_sie等参考需要设置。
基本评估命令
命令中–data是用于设置数据集、–task是用于指定评估训练集(train)、验证集(val)、测试集(test)。特别说明coco128,作者只是简单的划分了训练集和验证集,且训练集与验证集的数据是一模一样的。
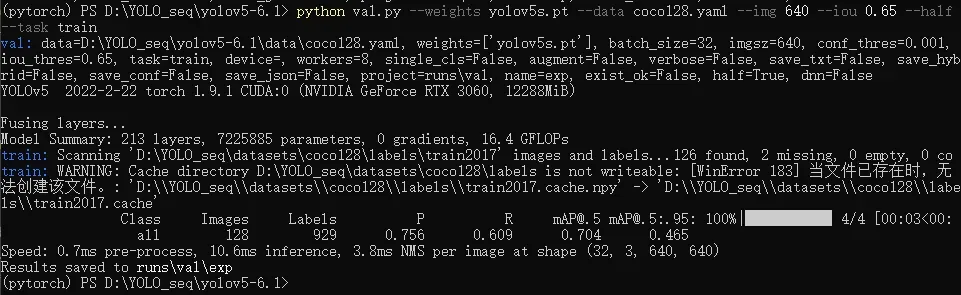
python val.py --weights yolov5s.pt --data coco128.yaml --img 640 --iou 0.65 --half --task train
测试结果存储在runs\val\目录下,包含指标曲线和部分可视化数据
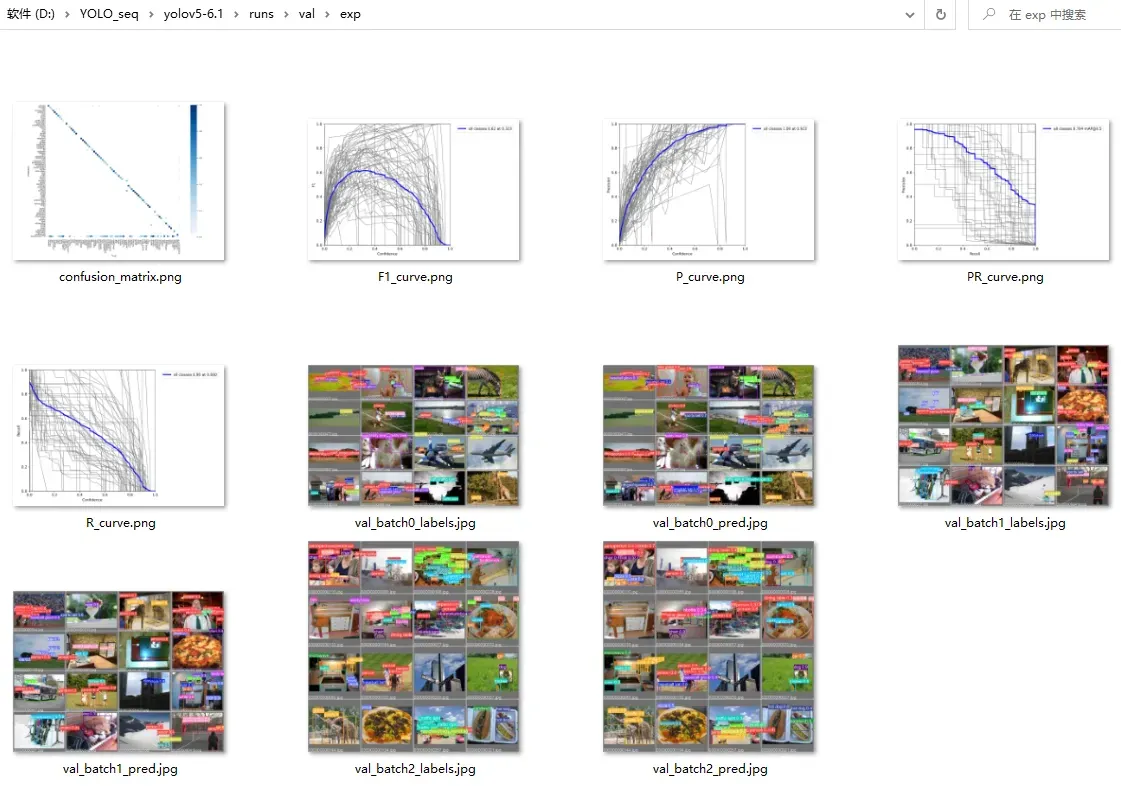
完整的评估参数
完整详细的评估参数如下所示,包含环境参数(模型、数据、gpu、half、dnn)、过程参数(iou-thres、conf-thres)、结果保存参数(save系列)
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--batch-size', type=int, default=32, help='batch size')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
parser.add_argument('--task', default='val', help='train, val, test, speed or study')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
模型转换
进行模型部署前需要使用export.py将模型进行导出(将模型转换为其他推理框架支持的格式,如onnx、openvino和engine等),如果是用libtorch部署,则可以使用pt文件进行部署。
导出的格式支持
yolov5项目支持绝大多数的推理框架,具体如下所示。
Format | `export.py --include` | Model
--- | --- | ---
PyTorch | - | yolov5s.pt
TorchScript | `torchscript` | yolov5s.torchscript
ONNX | `onnx` | yolov5s.onnx
OpenVINO | `openvino` | yolov5s_openvino_model/
TensorRT | `engine` | yolov5s.engine
CoreML | `coreml` | yolov5s.mlmodel
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
TensorFlow GraphDef | `pb` | yolov5s.pb
TensorFlow Lite | `tflite` | yolov5s.tflite
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
TensorFlow.js | `tfjs` | yolov5s_web_model/
在导出对应的推理框架格式时,需要安装相应的库。这里按照个人训练安装即可,并不用完全安装以下命令进行安装(就比如其中的tensorflow、openvino就可以不用安装)。
pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
模型导出
导出命令如下所示,–weights用于设置模型路径;–include用于设置导出的格式,支持一次性导出多种格式。
python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
使用命令 python export.py –weights yolov5s.pt –include torchscript onnx,用于导出libtorch(torchscript)、onnxruntime(onnx)所支持的模型。运行输出如下所示
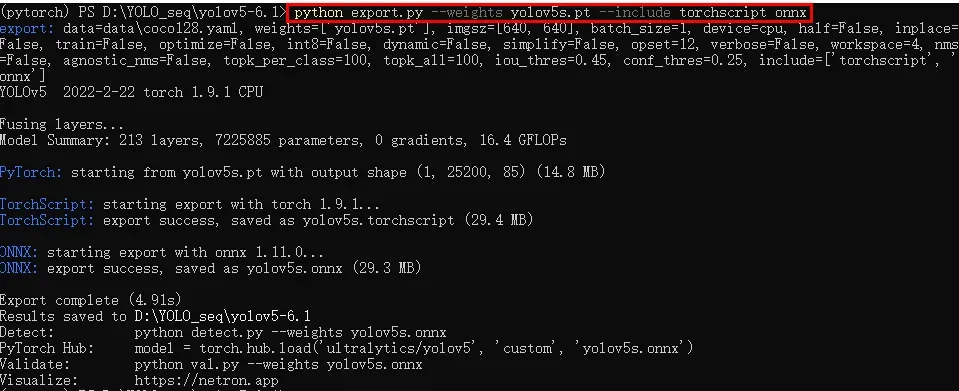
此时,模型保存在项目的根目录下。
带nms的导出命令如下所示,目前只支持tensorflow
python export.py --weights yolov5s.pt --include tensorflow --nms --iou-thres 0.7 --conf-thres 0.5
完整的模型导出参数
完整的导出参数如下所示,支持设置模型输入的size、动态size、int8量化、nms及nms参数等。
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include', nargs='+',
default=['torchscript', 'onnx'],
help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
训练数据格式
了解yolov5训练数据的格式,有利于用yolov5训练自己的数据。yolov5在训练时仅支持yolo格式的标注数据,标注格式为’classId’,‘xmin’, ‘xmax’, ‘ymin’, ‘ymax’,其中xy的坐标都是进行了归一化的数值。
yolo标注的数据格式如下所示:
45 0.479492 0.688771 0.955609 0.5955
45 0.736516 0.247188 0.498875 0.476417
50 0.637063 0.732938 0.494125 0.510583
45 0.339438 0.418896 0.678875 0.7815
49 0.646836 0.132552 0.118047 0.0969375
49 0.773148 0.129802 0.0907344 0.0972292
49 0.668297 0.226906 0.131281 0.146896
49 0.642859 0.0792187 0.148063 0.148062
内置的数据集配置
目前在yolov5的data目录下有Argoverse、coco、coco128、GlobalWheat2020、Objects365、SKU-110K、VisDrone、VOC、xView等配置项。对于coco数据集,其yaml文件中的download配置项中为url,下载解压存储到相应目录即可;而对于非coco数据,例如VOC数据,其yaml文件中的download配置项为代码块,其代码块实现了将VOC数据转yolo数据。
数据集配置解析
yolov5的数据集配置代码存储在data目录下,一个yaml文件对应一个数据集配置项。如coco128的配置项如下所示
其中path用于设置数据集的根路径、train用于设置训练集图像的路径、val用于设置验证集图像的路径、test用于设置验证集图像的路径(可以为空)。
nc用于设置类别数、names用于设置类别对应的标签名称。download用于设置数据不存在时的下载url或者预处理代码(可以为空)。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
这里图像都是存储在images目录下,而标签都是存储在labels目录下,images目录与labels目录是平级的。
多个路径设置
当train、val、test要设置多个路径时可以使用以下方法
train: # train images (relative to 'path') 16551 images
- images/train2012
- images/train2007
- images/val2012
- images/val2007
val: # val images (relative to 'path') 4952 images
- images/test2007
- images/val2012
test: # test images (optional)
- images/test2007
设置download代码块
设置download代码块的规范如下所示,用’|’和换行表示接下来输入的是script。
download: |
from utils.general import download, Path
# Download
dir = Path(yaml['path']) # dataset root dir
urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
download(urls, dir=dir)
# Make Directories
for p in 'annotations', 'images', 'labels':
(dir / p).mkdir(parents=True, exist_ok=True)
# Move
for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
(dir / p).rename(dir / 'images' / p) # move to /images
f = (dir / p).with_suffix('.json') # json file
if f.exists():
f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
自定义数据集
数据集定义代码
将以下代码保存到yolov5的data目录下,文件名为mycoco.yaml。其中的images/train下为训练集图像,images/val为验证集图像
# Example usage: python train.py --img 640 --batch 16 --workers 0 --epochs 3 --data mycoco.yaml --weights yolov5s.pt --cfg models/yolov5s.yaml
# parent
# ├── yolov5
# └── datasets
# └── mydata ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/mydata # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
# Download script/URL (optional)
download:
数据集的存储结构
D:\YOLO_SEQ\datasets/mydata
├─images (存储图像)
│ ├─train
│ └─val
└─labels (存储txt标签)
├─train
└─val
训练自定义数据集
训练代码为:
python train.py --img 640 --batch 16 --workers 0 --epochs 3 --data mycoco.yaml --weights yolov5s.pt --cfg models/yolov5s.yaml
``
训练过程中的部分输出为:
```bash
train: weights=yolov5s.pt, cfg=models/yolov5s.yaml, data=mycoco.yaml, hyp=data\hyps\hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=0, project=runs\train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
YOLOv5 2022-2-22 torch 1.9.1 CUDA:0 (NVIDIA GeForce RTX 3060, 12288MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 270 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs
Transferred 348/349 items from yolov5s.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 57 weight (no decay), 60 weight, 60 bias
albumentations: Blur(always_apply=False, p=0.01, blur_limit=(3, 7)), MedianBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), ToGray(always_apply=False, p=0.01), CLAHE(always_apply=False, p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning 'D:\YOLO_seq\datasets\mydata\labels\train.cache' images and labels... 98 found, 2 missing, 0 empty, 0 c
val: Scanning 'D:\YOLO_seq\datasets\mydata\labels\val' images and labels...28 found, 0 missing, 0 empty, 0 corrupt: 100
val: New cache created: D:\YOLO_seq\datasets\mydata\labels\val.cache
module 'signal' has no attribute 'SIGALRM'
AutoAnchor: 4.26 anchors/target, 0.993 Best Possible Recall (BPR). Current anchors are a good fit to dataset
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\train\exp7
Starting training for 3 epochs...
Epoch gpu_mem box obj cls labels img_size
0/2 3.61G 0.04189 0.06684 0.01805 73 640: 100%|██████████| 7/7 [00:08<00:00, 1.14s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 1/1 [00:00<00:
all 28 173 0.652 0.717 0.794 0.552
Epoch gpu_mem box obj cls labels img_size
1/2 4.32G 0.04362 0.06261 0.01831 35 640: 100%|██████████| 7/7 [00:04<00:00, 1.58it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 1/1 [00:00<00:
all 28 173 0.639 0.725 0.792 0.556
Epoch gpu_mem box obj cls labels img_size
2/2 4.32G 0.04605 0.06589 0.01804 25 640: 100%|██████████| 7/7 [00:04<00:00, 1.59it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 1/1 [00:00<00:
all 28 173 0.641 0.726 0.781 0.548
3 epochs completed in 0.005 hours.
Optimizer stripped from runs\train\exp7\weights\last.pt, 14.9MB
Optimizer stripped from runs\train\exp7\weights\best.pt, 14.9MB
Validating runs\train\exp7\weights\best.pt...
Fusing layers...
Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 1/1 [00:00<00:
all 28 173 0.639 0.724 0.793 0.556
person 28 43 0.663 0.791 0.793 0.479
bicycle 28 1 0.382 1 0.995 0.895
car 28 15 0.656 0.533 0.669 0.29
motorcycle 28 3 0.479 0.667 0.755 0.636
airplane 28 1 0.652 1 0.995 0.895
train 28 1 0.642 1 0.995 0.895
truck 28 4 0.621 0.431 0.634 0.255
stop sign 28 1 0.672 1 0.995 0.796
bench 28 6 0.504 0.51 0.679 0.223
dog 28 3 1 0.866 0.995 0.844
horse 28 2 0.706 1 0.995 0.673
elephant 28 2 0.738 1 0.995 0.597
zebra 28 1 0.621 1 0.995 0.995
giraffe 28 6 0.921 1 0.995 0.797
umbrella 28 4 0.742 0.75 0.787 0.539
handbag 28 2 0.949 0.5 0.497 0.397
skateboard 28 3 0.117 0.0777 0.29 0.149
bottle 28 1 0.22 1 0.497 0.398
cup 28 15 0.822 0.733 0.875 0.565
fork 28 2 0.566 0.5 0.499 0.449
knife 28 8 0.615 0.875 0.849 0.66
spoon 28 1 0.384 1 0.995 0.895
bowl 28 4 0.569 0.673 0.828 0.507
banana 28 1 0.704 1 0.995 0.398
sandwich 28 1 1 0 0.497 0.298
orange 28 4 0.774 1 0.995 0.726
broccoli 28 1 0.46 1 0.995 0.895
pizza 28 1 0.429 1 0.497 0.0498
cake 28 3 0.818 1 0.995 0.768
chair 28 6 0.821 0.771 0.726 0.367
potted plant 28 4 0.662 0.983 0.849 0.525
bed 28 1 1 0 0.497 0.298
dining table 28 7 0.682 0.618 0.596 0.294
microwave 28 1 0.624 1 0.995 0.497
oven 28 2 0.232 0.5 0.502 0.502
sink 28 1 1 0 0.497 0.398
refrigerator 28 1 0.589 1 0.995 0.697
book 28 4 0.382 0.25 0.462 0.197
clock 28 3 0.432 0.667 0.83 0.747
vase 28 2 0.36 1 0.995 0.895
teddy bear 28 1 1 0 0.995 0.398
python onnx部署
加载模型
import onnxruntime
import numpy as np
session = onnxruntime.InferenceSession("yolov5s.onnx", providers=['CUDAExecutionProvider'])
inputs=session.get_inputs()
print("Input_node_name:")
for ins in inputs:
print('\t ',ins.name,ins.shape)
outputs=session.get_outputs()
print("Output_node_name:")
for outs in outputs:
print('\t ',outs.name,outs.shape)
Input_node_name:
images [1, 3, 640, 640]
Output_node_name:
output [1, 25200, 85]
345 [1, 3, 80, 80, 85]
403 [1, 3, 40, 40, 85]
461 [1, 3, 20, 20, 85]
推理图像
import numpy as np
from PIL import Image
import cv2
from einops import rearrange
ipath='D:/YOLO_seq/yolov5-6.1/data/images/zidane.jpg'
img=Image.open(ipath)
img=img.resize((640,640))
#img.save('D:/YOLO_seq/yolov5-6.1/data/images/bus2.jpg')
im=np.array(img)
im=rearrange(im, 'h w c -> 1 c h w')
im=im.astype(np.float32)
im=im/255
onnx_data={session.get_inputs()[0].name:im}
outputs = session.run(None,onnx_data)
#结果解码
def postprocess(outs,objThreshold=0.1,confThreshold=0.06,nmsThreshold=0.1):
confidences = []
boxes = []
classIds = []
for detection in outs:
if detection[4] > objThreshold:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId] * detection[4]
if confidence > confThreshold:
center_x = int(detection[0] )#如果图像有pad,则需要减去pad/2
center_y = int(detection[1] )#如果图像有pad,则需要减去pad/2
width = int(detection[2])
height = int(detection[3])
left = int(center_x - width * 0.5)
top = int(center_y - height * 0.5)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
classIds.append(classId)
indices = cv2.dnn.NMSBoxes(boxes, confidences, confThreshold,nmsThreshold).flatten()
print(len(boxes),boxes,indices)
boxes=np.array(boxes)
classIds=np.array(classIds)
confidences=np.array(confidences)
return boxes[indices],classIds[indices],confidences[indices]
boxes,cls_ids,cls_confs=postprocess(outputs[0][0])
#绘图展示
from PIL import Image, ImageDraw, ImageFont
boxs=boxes
clss=cls_ids
confs=cls_confs
print(boxs.shape,clss.shape)
coco_labels=['person', 'bicycle', 'car', 'motorbike', 'aeroplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'sofa', 'pottedplant', 'bed',
'diningtable', 'toilet', 'tvmonitor', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
font = ImageFont.truetype(r'arial.ttf',16)
img=Image.open(ipath)
img=img.resize((640,640))
image=img#Imageromarray(img_base)
i=0
for box,cls_,conf in zip(boxs,clss,confs):
draw = ImageDraw.Draw(image)
x,y,w,h=box
location=[x,y,x+w,y+h]
draw.rectangle(location,width=1,outline=(255,0,0))
text=coco_labels[cls_]+' '+str(conf)
draw.text(location[:2],text,fill=(255,255,255),font=font)
#print(location)
i+=1
del draw
image.show()

文章出处登录后可见!