分类目录:《机器学习中的数学》总目录
相关文章:
· 距离定义:基础知识
· 距离定义(一):欧几里得距离(Euclidean Distance)
· 距离定义(二):曼哈顿距离(Manhattan Distance)
· 距离定义(三):闵可夫斯基距离(Minkowski Distance)
· 距离定义(四):切比雪夫距离(Chebyshev Distance)
· 距离定义(五):标准化的欧几里得距离(Standardized Euclidean Distance)
· 距离定义(六):马氏距离(Mahalanobis Distance)
· 距离定义(七):兰氏距离(Lance and Williams Distance)/堪培拉距离(Canberra Distance)
· 距离定义(八):余弦距离(Cosine Distance)
· 距离定义(九):测地距离(Geodesic Distance)
· 距离定义(十): 布雷柯蒂斯距离(Bray Curtis Distance)
· 距离定义(十一):汉明距离(Hamming Distance)
· 距离定义(十二):编辑距离(Edit Distance,Levenshtein Distance)
· 距离定义(十三):杰卡德距离(Jaccard Distance)和杰卡德相似系数(Jaccard Similarity Coefficient)
· 距离定义(十四):Ochiia系数(Ochiia Coefficient)
· 距离定义(十五):Dice系数(Dice Coefficient)
· 距离定义(十六):豪斯多夫距离(Hausdorff Distance)
· 距离定义(十七):皮尔逊相关系数(Pearson Correlation)
· 距离定义(十八):卡方距离(Chi-square Measure)
· 距离定义(十九):交叉熵(Cross Entropy)
· 距离定义(二十):相对熵(Relative Entropy)/KL散度(Kullback-Leibler Divergence)
· 距离定义(二十一):JS散度(Jensen–Shannon Divergence)
· 距离定义(二十二):海林格距离(Hellinger Distance)
· 距离定义(二十三):α-散度(α-Divergence)
· 距离定义(二十四):F-散度(F-Divergence)
· 距离定义(二十五):布雷格曼散度(Bregman Divergence)
· 距离定义(二十六):Wasserstein距离(Wasserstei Distance)/EM距离(Earth-Mover Distance)
· 距离定义(二十七):巴氏距离(Bhattacharyya Distance)
· 距离定义(二十八):最大均值差异(Maximum Mean Discrepancy, MMD)
· 距离定义(二十九):点间互信息(Pointwise Mutual Information, PMI)
Wasserstein距离也被称为推土机距离(Earth Mover’s Distance,EMD),用来表示两个分布的相似程度。Wasserstein距离衡量了把数据从分布移动成”分布
时所需要移动的平均距离的最小值。Wasserstein距离是2000年IJCV期刊文章《The Earth Mover’s Distance as a Metric for Image Retrieval》提出的一种直方图相似度量。如果两个分布
和
离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味这这一点的梯度为0,即梯度消失,而Wasserstein距离可以解决这个问题。
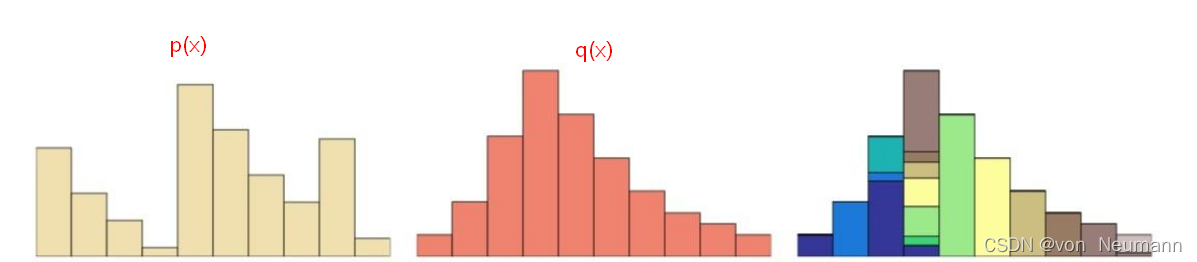
我们将两个分布和
看成两堆土,如下图所示,希望把其中的一堆土移成另一堆土的位置和形状,有很多种可能的方案。推土代价被定义为移动土的量乘以土移动的距离,在所有的方案中,存在一种推土代价最小的方案,这个代价就称为两个分布的Wasserstein距离。
其中, 表示分布
和
组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布
可以从中采样
得到一个样本
和
y,并计算出这对样本的距离
,所以可以计算该联合分布
下,样本对距离的期望值
。在所有可能的联合分布中能够对这个期望值取到的下界就是Wasserstein距离。用推土的方式理解就是,
是在
这种路径规划下,把
这堆土,移成
的样子的消耗,而Wasserstein距离就是在”最优路径规划“下的最小消耗。
文章出处登录后可见!