前言
《End-to-End Object Detection with Transformers》
论文地址:https://arxiv.org/pdf/2005.12872.pdf
DEtection withTRansformers是在2020年ECCV上发表的,性能虽然不是很能打,尤其是在小目标上的精度不太行;但是作为Transformer用在目标检测领域的开山之作,还是有很多可以借鉴的地方。
在这之前建议可以先看一下ViT的工作,Vision Transformer(ViT)及后续工作,关于之前的细节就不会赘述,把内容放在这篇新的方法上。
网络结构
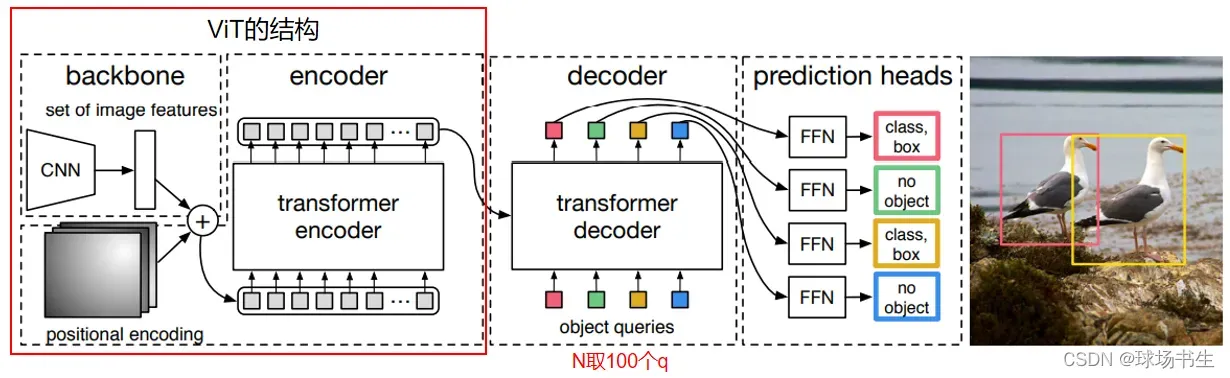
前面就是一个ViT的结构(不过这里不需要[CLS] Token),位置编码稍微不一样,作者做了如下实验: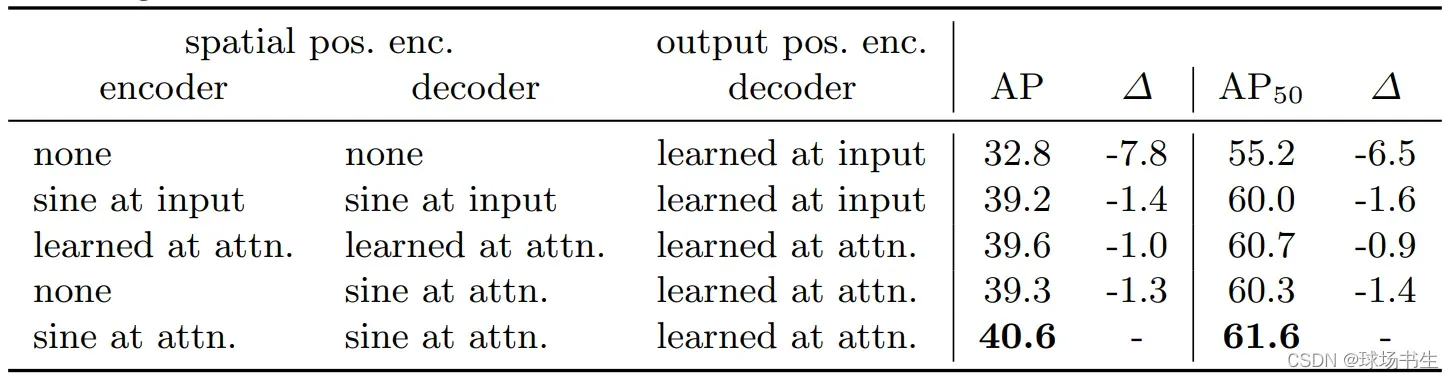
后面decoder细节如下:
decoder的输入是100个queries,这里作者认为一张图片里的物体不会超过100个,所以设置为100,区别于之前产生大量候选框或者anchor(因此在训练的时候,可以不用NMS)。在decoder中,K和V的值来自于encoder,Q是decoder自己产生的。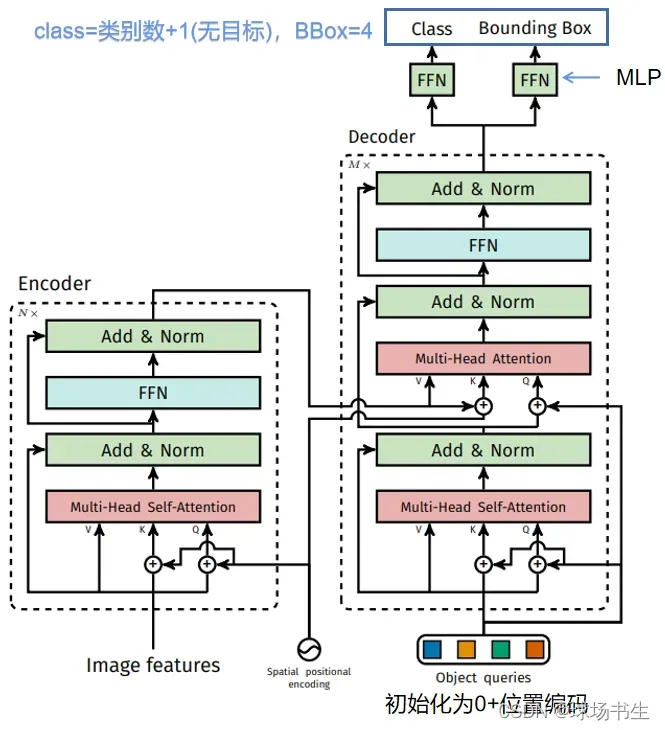
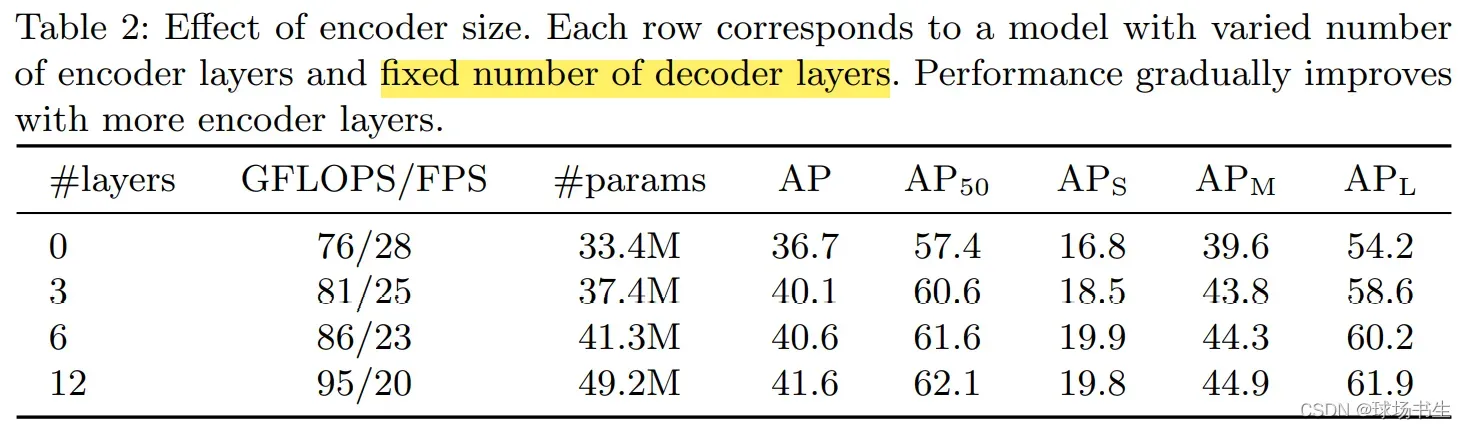
考虑到参数量和计算量,作者选择6个transformer和6个decoder layers of width 256 with 8 attention
heads。
训练:上面我们介绍了decoder会生成100个预测框,那怎么和GT对应呢?
假如GT有两个物体,此时预测出了100个结果,这个时候就会用匈牙利算法(匈牙利算法多用于指派问题中,保证实现最优分配)来选择2个接近GT的预测框作为正样本,其他的98个作为背景。如何衡量找到了合适的分配方案?这里需要一个cost函数,满足cost最小时即为合适的分配方案。cost函数如下: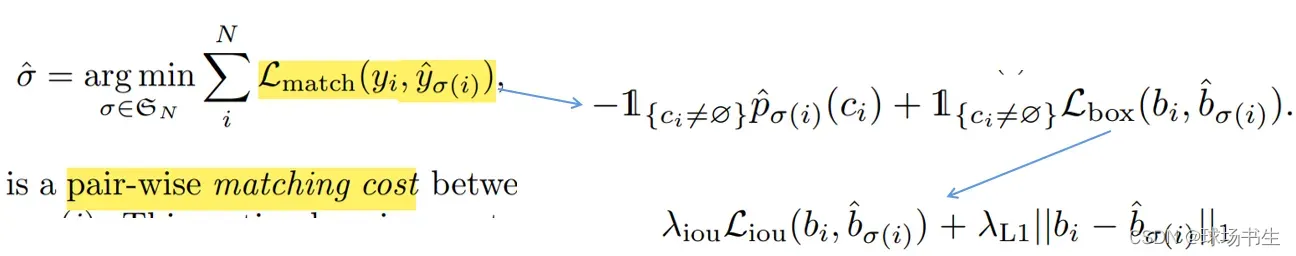
这里选择正负样本就没有用到NMS。接下来就是计算神经网络的损失函数Loss: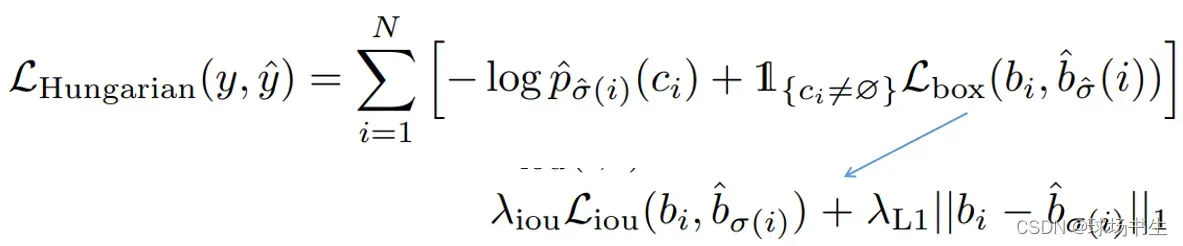

值得注意的是,这里并没有像YOLO那样取预测偏移,直接的回归坐标位置。
推理测试:在测试的时候当然也可以用NMS做后处理
def filter_boxes(scores, boxes, confidence=0.7, apply_nms=True, iou=0.5):
#筛选出真正的置信度高的框
keep = scores.max(-1).values > confidence
scores, boxes = scores[keep], boxes[keep]
if apply_nms:
top_scores, labels = scores.max(-1)
keep = batched_nms(boxes, top_scores, labels, iou)
scores, boxes = scores[keep], boxes[keep]
return scores, boxes
上一篇:Vision Transformer(ViT)及后续工作
下一篇:Swin-Transformer
版权声明:本文为博主球场书生原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_41917697/article/details/123020245