TextCNN模型通过CNN卷积的思想对文本数据做处理,整个处理流程如下图所示:
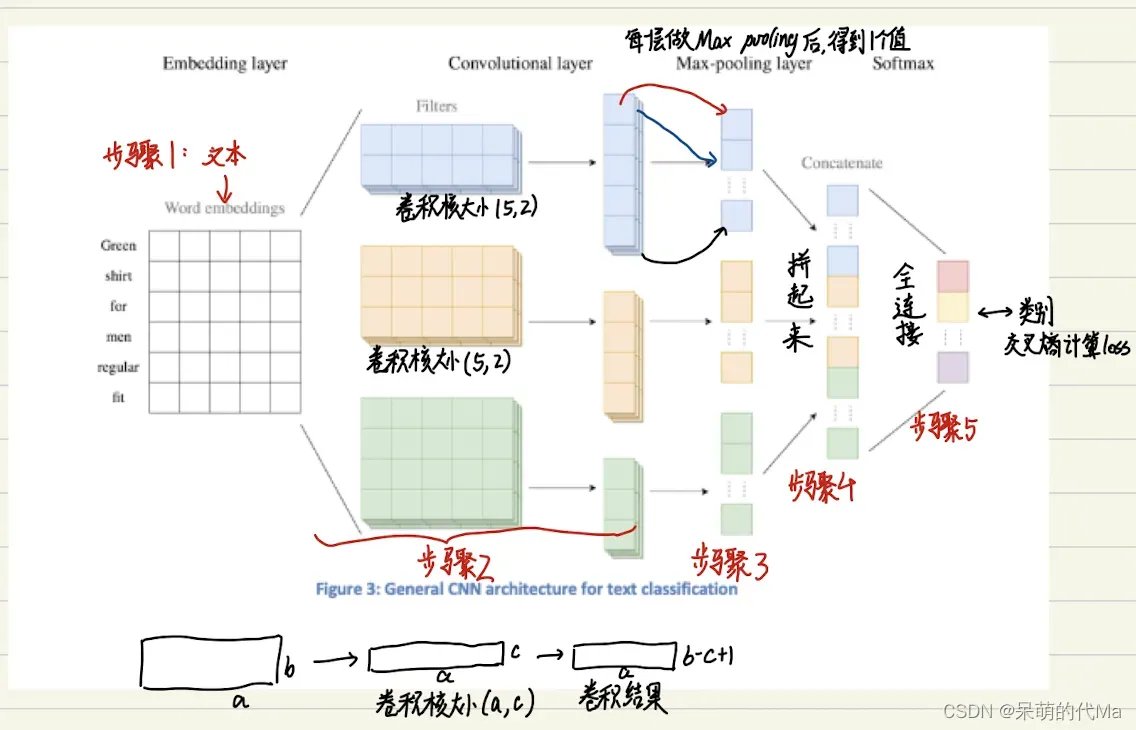
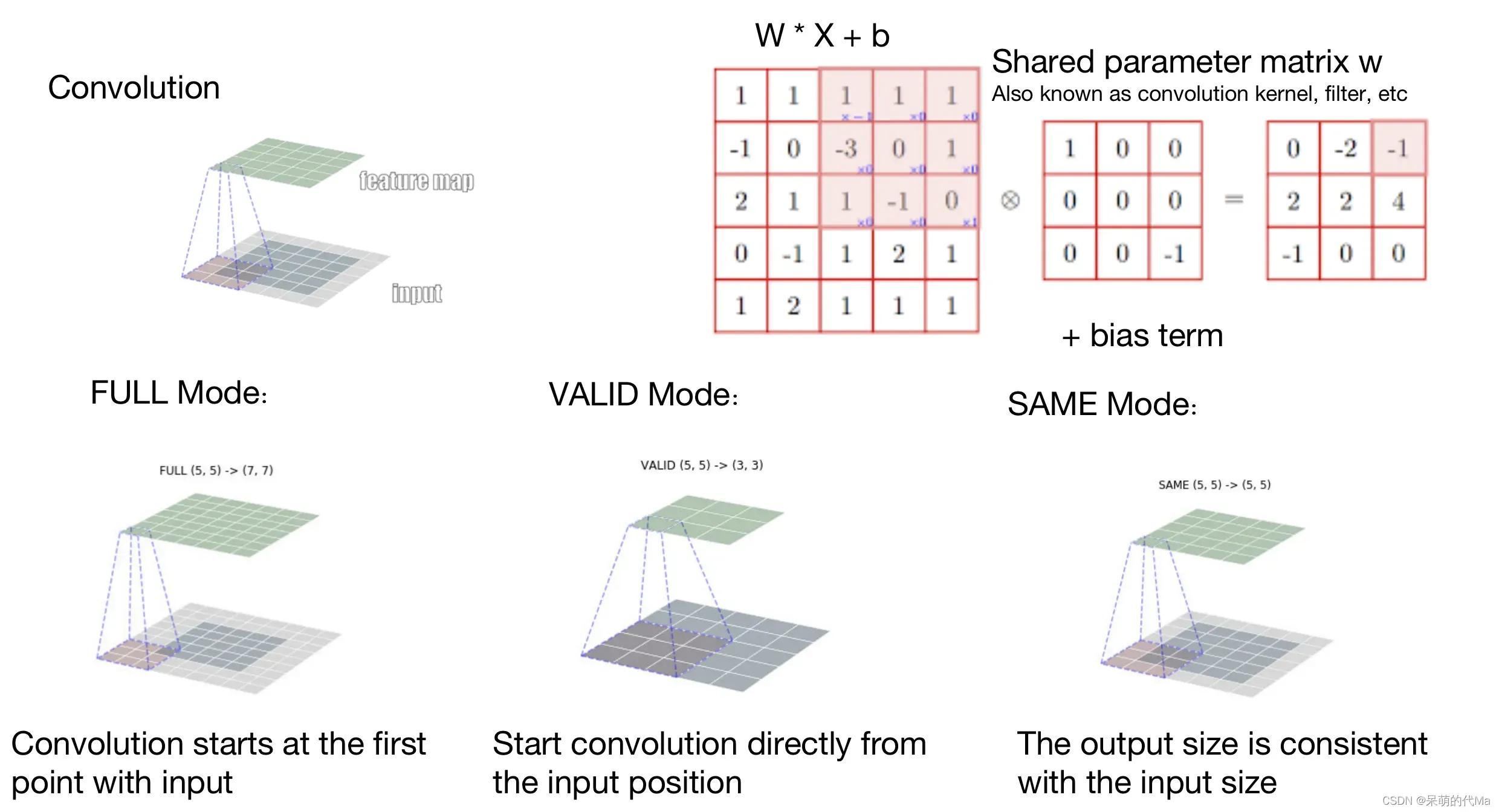
卷积层:
卷积层是通过一个卷积核,滑过整个平面,然后得到卷积后的特征图。
卷积层的目的是提取局部特征,2维卷积一般有以下三种:
- Full Mode:以卷积层最下角对齐输入的最上角,最后会导致输入维度 < 输出维度,其中浅色的地方一般是补0
- Valid Mode:从输入的最上角开始,最后输入维度 > 输出维度
- Same Mode:自适应匹配位置,使最终的输入维度 = 输出维度
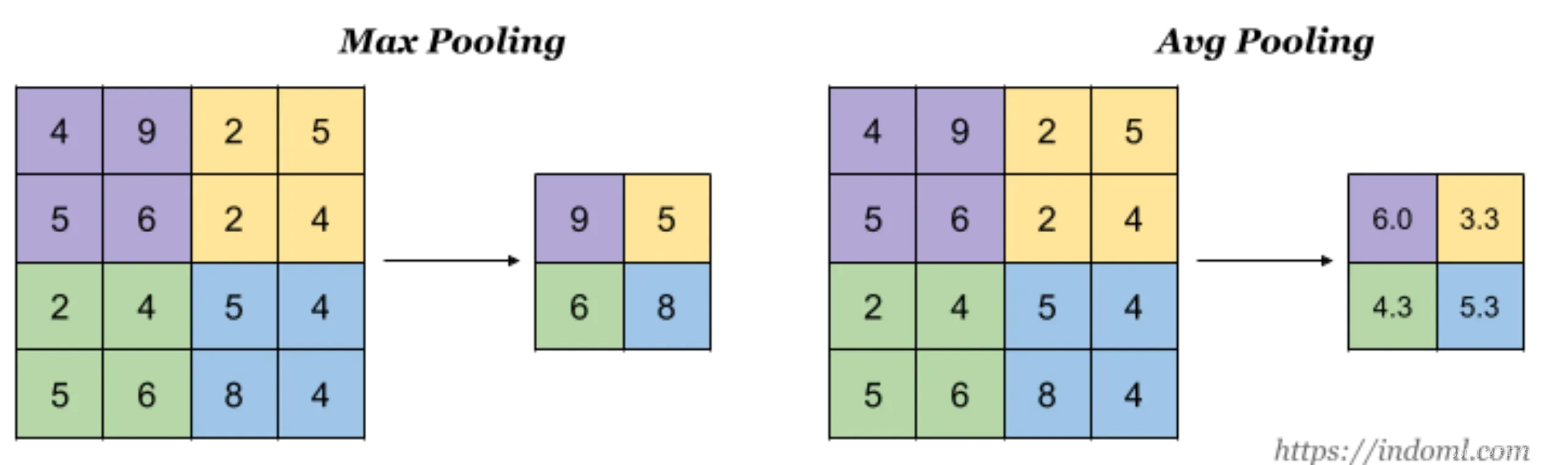
池化层
池化层是以特征筛选为手段的特征提取,常见的有以下两种:
- Max Pooling:最大池化,相同颜色选择最大的输出
- Avg Pooling:均值池化,相同颜色求均值输出
Pytorch复现
"""
TextCNN
"""
import numpy as np
from torchtext.vocab import vocab
from collections import Counter, OrderedDict
from torch.utils.data import Dataset, DataLoader
from torchtext.transforms import VocabTransform # 注意:torchtext版本0.12+
import torch
from torch import nn
from torch.nn import functional as F
from torchtext.data.utils import ngrams_iterator
def get_text():
# TextCNN是有监督的构造预训练模型,因此训练数据既有语料,也有label
# 这里复现时我们的label设置为分类问题
sentence_list = [ # 假设这是全部的训练语料
"nlp drives computer programs that translate text from one language to another",
"nlp combines computational linguistics rule based modeling of human language with statistical",
"nlp model respond to text or voice data and respond with text",
"nlp model for sentiment analysis are provided by human",
"nlp drives computer programs that translate text from one language to another",
"nlp combines computational linguistics rule based modeling of human language with statistical",
"nlp model respond to text or voice data and respond with text",
"nlp model for sentiment analysis are provided by human",
]
sentence_label = [0, 1, 1, 0, 0, 1, 1, 0]
return sentence_list, sentence_label
def pad_or_cut(value: np.ndarray, target_length: int):
"""填充或截断一维numpy到固定的长度"""
data_row = None
if len(value) < target_length: # 填充
data_row = np.pad(value, [(0, target_length - len(value))])
elif len(value) > target_length: # 截断
data_row = value[:target_length]
return data_row
class TextCnnDataSet(Dataset):
def __init__(self, text_list, text_label, max_length=20):
"""
构造适用于TextCNN的采样Dataset
:param text_list: 语料文本内容
:param text_label: 语料的标签
:param max_length: 文本的最长长度,超过就截断,不足就补充
"""
super(TextCnnDataSet, self).__init__()
text_vocab, vocab_transform = self.reform_vocab(text_list)
self.text_list = text_list # 原始文本
self.text_label = text_label # 有监督的label
self.text_vocab = text_vocab # torchtext的vocab
self.vocab_transform = vocab_transform # torchtext的vocab_transform
self.train_data = self.generate_train_data()
self.max_length = max_length
def __len__(self):
return len(self.train_data)
def __getitem__(self, idx):
data_row = self.train_data[idx] # 得到训练数据token,作为x
data_row = pad_or_cut(data_row, self.max_length) # 将训练数据切分到固定长度
data_label = self.text_label[idx] # 训练文本的 y
return data_row, data_label
def reform_vocab(self, text_list):
"""根据语料构造torchtext的vocab"""
total_word_list = []
for _ in text_list: # 将嵌套的列表([[xx,xx],[xx,xx]...])拉平 ([xx,xx,xx...])
total_word_list += list(ngrams_iterator(_.split(" "), 2)) # 这里使用n-gram处理原始单词
counter = Counter(total_word_list) # 统计计数
sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True) # 构造成可接受的格式:[(单词,num), ...]
ordered_dict = OrderedDict(sorted_by_freq_tuples)
# 开始构造 vocab
special_token = ["<UNK>", "<SEP>"] # 特殊字符
text_vocab = vocab(ordered_dict, specials=special_token) # 单词转token,specials里是特殊字符,可以为空
text_vocab.set_default_index(0)
vocab_transform = VocabTransform(text_vocab)
return text_vocab, vocab_transform
def generate_train_data(self):
"""生成Text的训练数据"""
data_list = []
for sentence in self.text_list:
sentence_words = sentence.split(' ') # 切分句子
sentence_id_list = np.array(self.vocab_transform(sentence_words))
data_list.append(sentence_id_list)
return data_list
def get_vocab_transform(self):
return self.vocab_transform
def get_vocab_size(self):
return len(self.text_vocab)
class TextCnnModel(nn.Module):
def __init__(self, vocab_size, embedding_dim=100, output_dim=2, out_channels=66, filter_sizes=(2, 3, 4)):
"""
TextCNN 模型
:param vocab_size: 语料大小
:param embedding_dim: 每个词的词向量维度
:param output_dim: 输出的维度,由于咱们是二分类问题,所以输出两个值,后面用交叉熵优化
:param out_channels: 卷积核的数量
:param filter_sizes: 卷积核尺寸
:param dropout: 随机失活概率
"""
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
conv_list = []
for conv_size in filter_sizes:
# 由于是文本的embedding,所以in_channels=1,常见的如图像的RGB,则in_channels=3
conv_list.append(nn.Conv2d(1, out_channels, (conv_size, embedding_dim)))
# nn.Conv2d 的使用:
# (batch_size, 特征图个数, 特征图长, 特征图宽) -> 经过nn.conv2d(特征图个数,输出的特征图个数,卷积核的长,卷积核的宽) ->
# (batch_size, 输出的特征图个数, a-b+1, ∂-ß+1)
self.conv_model = nn.ModuleList(conv_list)
# 最后的FC
self.linear = nn.Linear(out_channels * len(filter_sizes), output_dim)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, text_token):
# 步骤1:把文本转为 word embeddings
word_embeddings = self.embedding(text_token)
emb_out = word_embeddings.unsqueeze(1)
# 步骤2:使用多种shape的卷积核进行卷积操作
conv_result_list = []
for conv in self.conv_model:
# 过一层卷积,然后把最后一个维度(值=1)剔除掉
conv_out = F.relu(conv(emb_out)).squeeze(3) # shape=(batch_size, 66 out_channels, 19)
# 步骤3:对每一层做最大池化,然后拼接起来
max_conv_out = F.max_pool1d(conv_out, conv_out.size(2)).squeeze(2) # shape = (batch_size, 66 out_channels)
conv_result_list.append(max_conv_out)
# 步骤4:拼接起来
concat_out = torch.cat(conv_result_list, dim=1) # 这里要指定第二个维度(dim=0对应第一个维度)
# 步骤5:
model_out = self.linear(concat_out)
return model_out
def get_embedding(self, token_list: list):
return self.embedding(torch.Tensor(token_list).long())
def main():
batch_size = 3
# ========== 开始处理数据 ==========
sentence_list, sentence_label = get_text()
data_set = TextCnnDataSet(sentence_list, sentence_label) # 构造 DataSet
data_loader = DataLoader(data_set, batch_size=batch_size) # 将DataSet封装成DataLoader
# =========== 开始训练 ==========
model = TextCnnModel(data_set.get_vocab_size(), output_dim=np.unique(sentence_label).size)
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
for _epoch_i in range(100):
loss_list = []
for text_token, text_label in data_loader:
# 开始训练
optimizer.zero_grad()
model_out = model(text_token)
loss = criterion(model_out, text_label)
loss.backward()
optimizer.step()
loss_list.append(loss.item())
print("训练中:", _epoch_i, "Loss:", np.sum(loss_list))
# ================== 最后测试 =====================
# 得到: nlp can translate text from one language to another 的词向量
sentence = "nlp can translate text from one language to another"
vocab_transform = data_set.get_vocab_transform()
# sentence_ids = vocab_transform(sentence.split(' '))
all_sentence_words = list(ngrams_iterator(sentence.split(' '), 2))
sentence_id_list = pad_or_cut(np.array(vocab_transform(all_sentence_words)), target_length=20)
sentence_embedding = model.get_embedding(sentence_id_list)
# 句向量的特征图对应着 sentence_embedding
print("这个是句向量的特征图的维度:", sentence_embedding.shape)
# =================== 直接用TextCnn分类 =====================
text_tensor = torch.Tensor(sentence_id_list).long()
text_tensor = text_tensor.unsqueeze(0) # 整理输入
_, predicted = torch.max(model(text_tensor).data, 1) # 得到预测结果
print("直接用TextCnn得到的分类结果:", predicted)
if __name__ == '__main__':
main()
文章出处登录后可见!
已经登录?立即刷新