0. 摘要
(1)该论文基于CNN、RNN和提出新颖的Attention建立的神经网络模型,在FSNS数据集上准确率达到84.2%,而之前最先进的方法的准确率为72.46%;另外,在Google的Street View 数据集上也表现良好。
(2)本论文的模型具有以下特点:更简单、更通用、更快速
(3)研究了不同深度的CNN特征提取器,权衡其速度和准确性
1. 引言
1.1 现状分析
(1)传统OCR侧重于从扫描文档中提取文本
(2)自然场景中提取文本更具有挑战性,其原因在于:自然场景容易产生视觉伪影、图片失真等情况
1.2 本文模型与之前模型的效果对比
本文模型在FSNS上实现了84.2%的准确率,显著优于之前最优的72.46%。
之前的模型是:将不同视图转移到批量维度,然后使用多层LSTM,旨在处理每一行文本,并使用CTC损失训练模型。
1.3 CNN特征提取器
本文研究了3种基于CNN的特征提取器: inception-V2, inception-V3, inception-resent-V2,将这三个的输出,作为注意力机制的输入。
1.4 此文贡献
(1)提出了一种新颖的基于注意力的文本识别架构,以端到端的方式进行训练
(2)展示该模型在更新的、更具有挑战性的数据集上提供了更为出色的结果
(3)研究了使用不同深度的CNN模型的速度/准确率的权衡,并推荐了一种准确高校的配置
2. 方法
该文使用CNN特征提取器处理图像,然后通过新颖的注意力机制进行加权,再将加权后的数据传递给RNN.模型结构如图:
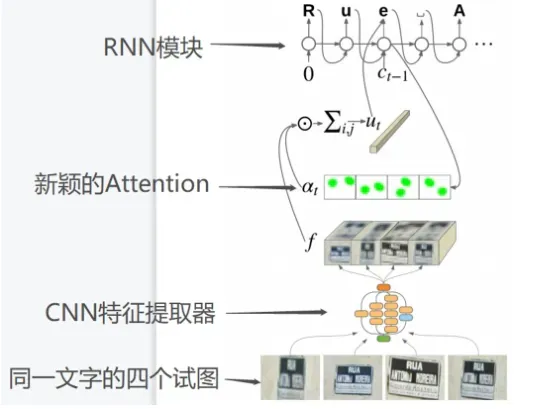
2.1 基于CNN的特征提取器
考虑了Inception-V2、Inception-V3和Inception-resent-V2三种特征提取器,后两种性能相当,且都由于第一种。记:
表示图像x通过CNN特征提取器后输出的特征图,其中: 表示图中的像素位置,
表示通道。
2.2 RNN
文本识别的主要挑战是将特征图转换为单个文本字符串。RNN所做如下:
Step1: 令 为RNN在时间
的隐藏状态。RNN的输入是由空间加权组合确定的,设空间注意力(即上文提到的由该文提出的新颖的注意力机制)掩码
(即权值)表示如下,其计算过程会在后面展示出来:
Step2: 计算了空间注意力掩码后,就可以计算特征的加权组合,其计算如下:
其中, 表示加权后的特征向量,
是上面CNN特征提取器的输出图。
Step3: 在时间 ,将RNN的总输入定义为:
其中 是前一个字符的索引,
猜测是关于前一个字符的权重,
表示上面的加权求和,
猜测是关于
的权重。
Step4: 然后计算RNN的输出和下一个状态,计算如下:
其中,表示输出,
表示下一个状态。
Step5: 给定时间时,字符的最终预测分布为
表示为权重,其余的在上面公式中可以找到。
Step6: 计算可能的字母
称之为:贪婪解码。
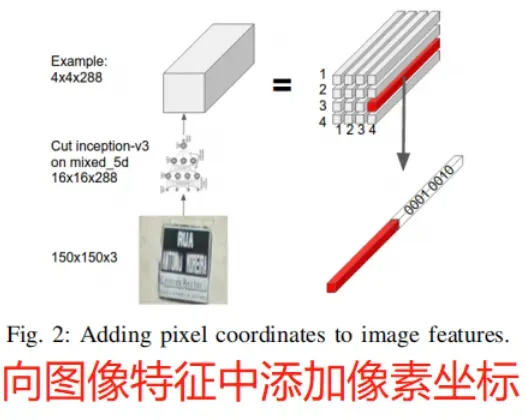
2.3 空间注意力
大多数使用空间注意力进行OCR的先前工作是根据当前的RNN状态预测掩码,如下:
其中,是一个向量,本文将
中的内容替换成了:
其中,是坐标
的one-hot编码,
是
的one-hot编码,这相当于给原来的
添加了一个空间变化的偏置项。
2.4 处理多个视图
在FSNS数据集中,每个符号有4个视图,每个视图的大小为150 x 150。通过相同的基于CNN的特征提取器(共享参数)独立处理每一个视图,然后将他们水平的连接起来。
eg: 四个视图每个视图的大小为16 x 16 x 320,连接后的=64 x 16 x 320.
2.5 训练
Step1: 使用(惩罚)最大似然估计训练模型,即我们需要最大化:
其中,是输入图像,
是位置t的预测标签;对于FSNS数据集来说,T=37,因为该数据集中的图片最多37个字符。注:之前的方法一般都是使用CTC损失来进行训练的。
Step2: 使用随机梯度下降进行优化参数,初始化 ,衰减因子=0.1,经过120万Step后进行学习率的变化,且其动量因子为0.75。
注:120万Step的意思是模型的参数更新120万次,模型每训练一个batch的样本后才会更新参数。
Step3: 对每一个图像进行以下增强过称:
1)对每个视图进行随机裁剪,要求覆盖原图的80%区域,且其纵横比在0.8—1.2之间;
2)裁剪后,使用随机选择的插值方法(如:双线性插值法,最近邻插值法等)将裁剪后的图片进行插值,将其调整为原图大小;
3)然后,应用随机图像扭曲:改变其对比度、色相、亮度和饱和度;
4)为了模型的正则化,设权重衰减0.00004,标签平滑因子(标签平滑详情),LSTM值裁剪到10,LSTM的单元大小设置为256,batch_size=32; 对于Inception-resent-v2,由于GPU的内存限制,其batch_size=12。并应用decay=0.9999的Polyak平均来推导出推断的权值。
3.数据集介绍
记录本文使用的数据集。
3.1 FSNS数据集
train: 965917 张
validation(验证集):38633 张
test: 42839张
每张图片最多有4个图块(即:每张图有4个不同视图),每个图块大小为150 x 150,每个图块最多有37个字符,数据集总的字符类别为134种,图片如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6dqynRBE-1652934168824)(F:/typorasetups/image/image-20220518234049897.png)]](https://aitechtogether.com/wp-content/uploads/2022/05/82e35b67-4e13-4168-86d7-1d8945f2abb5.webp)
3.2 Street View Business Names Dataset
约100万张商业方面的单视图图像,图片大小352 x 352,单张图片最多有33个符号,全部图片的字符类别共128个字符。
4. 实验结果
4.1 FSNS的准确性
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ebAT1Mi6-1652934168832)(F:/typorasetups/image/image-20220519104759149.png)]](https://aitechtogether.com/wp-content/uploads/2022/05/cca2df5e-4b05-4cb9-b32e-23188ce40f8e.webp)
图中的Standard Attention表示传统的注意力机制,Location Attention表示本文提出的空间注意力机制。
4.2 CNN提取器的深度对FSNS的影响
精度可能会随着CNN深度的增加而增加而下降。
原因分析:
(1)字符识别不能从图像分类的高级功能中收益;
(2)每次最大池化后的图像像素的空间分辨率会降低,这限制了特定字符注意力掩码的精度。
4.3 FSNS在注意力机制上的可视化
使用该文文献[25]提出的 过程:
Step1: 对每个, 计算其
相对于输入图像
的偏导数;
Step2: 然后使用公式计算其显著性和范数
:
Step3: 为获得噪声较小的显著性映射,该文通过添加少量的高斯噪声创建了16个轻微扰动的图像版本,然后对结果进行平均。此外,通过最近邻插值法进行上采样来可视化注意力图,如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cWbR4qWI-1652934168834)(F:/typorasetups/image/image-20220519120307097.png)]](https://aitechtogether.com/wp-content/uploads/2022/05/92fe68de-05cd-487c-945f-bbdf0eae8942.webp)
4.4 FSNS数据集的错误分析
分析了100个随机抽样的错误预测,以更好地理解我们的模型的弱点。
48%的“错误”是由于不正确的ground truth。表V给出了更详细的细分情况。最常见的错误是由于字母e上的重音错误(应该是‘e或`e);有趣的是,这也是ground truth转录中最常见的错误。在图4中,我们展示了一些测试用例,其中我们的模型与地面真相有不同的预测。(在最后一个例子中,这是由于地面真相中的一个错误。)
![![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LUQpun8i-1652934168837)(F:/typorasetups/image/image-20220519121419439.png)]](https://img-blog.csdnimg.cn/0ed3e6a3246b4b899f750e4c1501fe3a.png](https://aitechtogether.com/wp-content/uploads/2022/05/c9970055-cdcb-49f8-9845-038ca3e310cc.webp)
5. 结论与展望
在未来,我们希望研究更复杂的RNN训练方法,如计划抽样[26]或混合ML/RL方法[27]。我们还希望将该系统扩展到从店面中完全结构化地提取业务信息。
6. 论文和代码以及数据
注: 其github的代码有改动,ocr的代码在此目录下:models-master\research\attention_ocr
文章出处登录后可见!