YOLOV5—数据集格式转化及训练集和验证集划分
本教程详细介绍了 VOC 格式数据集的制作方法。
1、目录结构
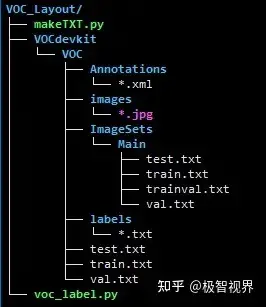
其中 makeTXT.py 用于生成 VOCdevkit/VOC/ImageSets/Main/*.txt,voc_label.py 根据 VOCdevkit/VOC/Annotations/* 、VOCdevkit/VOC/images/* 和 VOCdevkit/VOC/ImageSets/Main/*.txt 生成 VOCdevkit/labels/*.txt、VOCdevkit/VOC/test.txt(train.txt、val.txt)
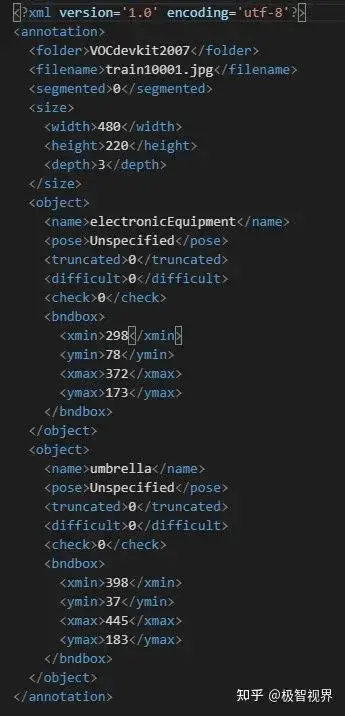
2、Annotations
可以用 LabelImg 对训练图片进行标注,会得到 *.xml,看起来像这样:
3、images
这个没啥好说的,就是训练的图片。
4、ImageSets/Main
由 makeTXT.py 生成 VOCdevkit/VOC/ImageSets/Main/*.txt 文件,包括 test.txt、train.txt、trainval.txt、val.txt。各文件里面的内容看起来差不多,像这样:
5、labels
由 voc_label.py 生成,来看一下 labels/*.txt 里的文件内容,像这样:

6、makeTXT.py
这个脚本用于生成 VOCdevkit/voc/ImageSets/Main 下的 *.txt。
来看一下 makeTXT.py 脚本的内容:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'VOCdevkit/VOC/Annotations'
txtsavepath = 'VOCdevkit/VOC/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('VOCdevkit/VOC/ImageSets/Main/trainval.txt', 'w')
ftest = open('VOCdevkit/VOC/ImageSets/Main/test.txt', 'w')
ftrain = open('VOCdevkit/VOC/ImageSets/Main/train.txt', 'w')
fval = open('VOCdevkit/VOC/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()7、voc_label.py
这个脚本主要用于生成 VOCdevkit/VOC/labels/*.txt 以及 最终训练要用的 VOCdevkit/VOC/train.txt、VOCdevkit/VOC/test.txt 和 VOCdevkit/VOC/val.txt。
来看一下 voc_label.py 脚本的内容:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train",
"tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC/Annotations/%s.xml' % (image_id))
out_file = open('VOCdevkit/VOC/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
if obj.find('difficult'):
difficult = obj.find('difficult').text
else:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('VOCdevkit/VOC/labels/'):
os.makedirs('VOCdevkit/VOC/labels/')
image_ids = open('VOCdevkit/VOC/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('VOCdevkit/VOC/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('VOCdevkit/VOC/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()VOC标签格式转yolo格式并划分训练集和测试集
yolov5训练所需要的文件格式是txt格式的,基于labelimage标注的格式有VOC(xml格式),同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。
本文基于python,实现了将xml格式的标签文件转换为txt文件,同时按比例划分为训练集和验证集的功能。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["hat", "person"]
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
首先数据集的格式结构必须严格按照如图的样式 。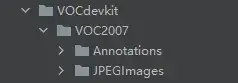
Annotations里面存放着xml格式的标签文件
JPEGImages里面存放着照片数据文件
特别要注意的是,classes里面必须正确填写xml里面已经标注好的类,要不然生成的txt的文件是不对的。TRAIN_RATIO是训练集和验证集的比例,当等于80的时候,说明划分80%给训练集,20%给验证集。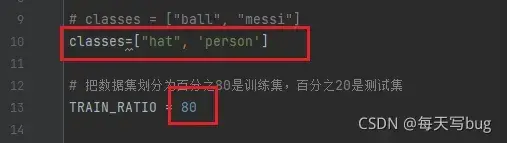
将代码和数据在同一目录下运行,得到如下的结果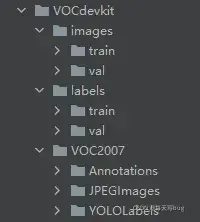
- 在VOCdevkit目录下生成images和labels文件夹,文件夹下分别生成了train文件夹和val文件夹,里面分别保存着训练集的照片和txt格式的标签,还有验证集的照片和txt格式的标签。images文件夹和labels文件夹就是训练yolov5模型所需的训练集和验证集。
- 在VOCdevkit/VOC2007目录下还生成了一个YOLOLabels文件夹,里面存放着所有的txt格式的标签文件。
至此,xml格式的标签文件转换为txt格式的标签文件并划分为训练集和测试集就讲完了。
标签为yolo格式数据集划分训练集和验证集
由于yolov5训练需要的数据标签格式为txt格式,所以大家在利用labelimg标注的时候会用yolo格式(标注生成的标签为txt格式)。标注好的数据集训练的时候就要划分为训练集和验证集,因此就需要有划分为训练集和测试集的代码。这里需要讲的是我写的脚本代码可以成功将数据集划分为训练集和验证集,但是在训练模型的时候,加载数据集一直会出现问题。因此我就想到了,先把txt格式的数据集替换成xml格式的数据集,然后再按上述将xml格式标签转化为txt格式标签并划分为训练集和验证集的方法划分就好了。但是这里建议大家以后标注的时候就标注为voc格式(xml格式),因为该格式的标签里面有图片标注的具体内容,例如标注类别,图片大小,标注坐标。但是yolo格式(txt格式)里面是用数字来代表类别,这样很不直观,而且标注的坐标也是经过转化归一化的,坐标信息更加不直观。先上yolo转voc的代码。
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {
'0': "hat", # 创建字典用来对类型进行转换
'1': "person", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "VOCdevkit/VOC2007/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "VOCdevkit/VOC2007/YOLO/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "VOCdevkit/VOC2007/Annotations/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
首先讲一下数据的格式,要严格按照下图的目录结构来。为了后续数据集的划分做出统一数据集目录结构。且数据目录要和代码在同一目录下,这样就可以一键运行了。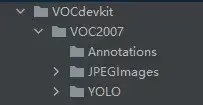
JPEGImages为图片数据所在的目录
YOLO为yolo格式的标签数据所在目录
Annotations为生成的voc格式数据标签目录(程序运行前这是一个空目录)
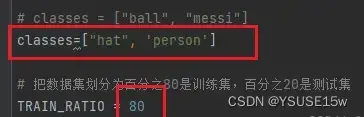
如下图这里要对应好,且顺序要一致,例如我这里是0对应hat,1对应person。

特别要注意的是,classes里面必须正确填写xml里面已经标注好的类,要不然生成的txt的文件是不对的。TRAIN_RATIO是训练集和验证集的比例,当等于80的时候,说明划分80%给训练集,20%给验证集。
将代码和数据在同一目录下运行,得到如下的结果
- 在VOCdevkit目录下生成images和labels文件夹,文件夹下分别生成了train文件夹和val文件夹,里面分别保存着训练集的照片和txt格式的标签,还有验证集的照片和txt格式的标签。images文件夹和labels文件夹就是训练yolov5模型所需的训练集和验证集。
- 在VOCdevkit/VOC2007目录下还生成了一个YOLOLabels文件夹,里面存放着所有的txt格式的标签文件。
至此,xml格式的标签文件转换为txt格式的标签文件并划分为训练集和测试集就讲完了。
运行如上的代码,就可以将yolo格式的标签转化为voc格式,并保存在 Annotations目录中,最后可以按照上述1的方法,将voc转为yolo再划分数据集就可以了。
至此yolo格式数据集划分训练集和验证集就结束了
————————————————
版权声明:本文为CSDN博主「炮哥带你学」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:CSDN博主「炮哥带你学」的原创文章
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
yolov5根目录下创建文件夹visdronedata及其附属目录
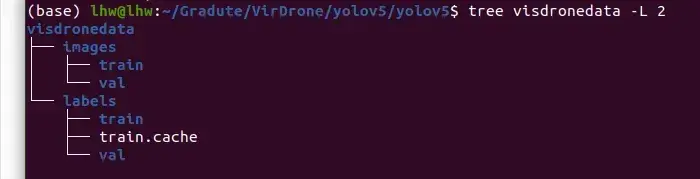
将visdrone的images文件夹里面的图片全部复制到images/train和iamges/val里面,上面程序生成的labels文件夹,将里面的所有txt复制到labels/train和labels/val里面
然后安装yolov5环境,要在Python3.8的环境下安装,如果使用conda可以使用
conda create -n py38 python=3.8 # 创建虚拟环境
conda activate py38 # 激活虚拟环境,如果成功激活环境则在命令行用户名前面有虚拟环境名称的括号
pip install -r requirements.txt # 在yolov5根目录下安装需要的包
安装完环境之后,修改data/voc.yaml
# download command/URL (optional)
# download: bash data/scripts/get_voc.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: visdronedata/images/train/ # 16551 images
val: visdronedata/images/train/ # 4952 images
# number of classes
nc: 10
# class names
names: ['pedestrian','people','bicycle','car','van','truck','tricycle','awning-tricycle','bus','motor']
修改models/yolov5l.yaml
# parameters
nc: 10 # number of classes #只修改这个类别数
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
在这里的v1部分下载预训练模型yolov5l.pt,由于使用的yolov5l.yaml,所以使用yolov5l.pt。使用其他的训练配置文件可以下载相应的预训练模型,在github有对应关系。
将下载好的预训练模型放到weights文件夹下
然后在命令段运行
python train.py --data data/voc.yaml --cfg models/yolov5l.yaml --weights weights/yolov5l.pt --batch-size 1
内存足够时可以增大
batch-size:1、8、16、32、64
也可直接在train.py直接修改默认参数,然后直接运行
python train.py
然后进行训练,在训练的过程中会产生过程文件及训练模型,会保存在runs/文件夹中
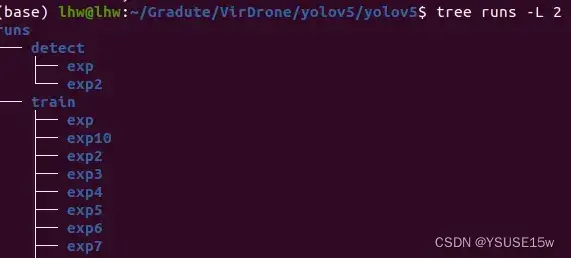
在exp里面会有保存的中间临时权重,可以拿出来放到yolov5/根目录下进行预测测试,预测的结果也会放到runs/detect文件夹下
python decect.py --source file.jpg --weight best.pt --conf 0.25
python decect.py --source file.mp4 --weight best.pt --conf 0.25
yolov5训练的文档Train Custom Data · ultralytics/yolov5 Wiki · GitHub
本文链接:YOLOV5—数据集格式转化及训练集和验证集划分_深海的yu的博客-CSDN博客_yolov5数据集格式
文章出处登录后可见!