Transformer是什么呢?
Transformer最早起源于论文Attention is all your need,是谷歌云TPU推荐的参考模型。
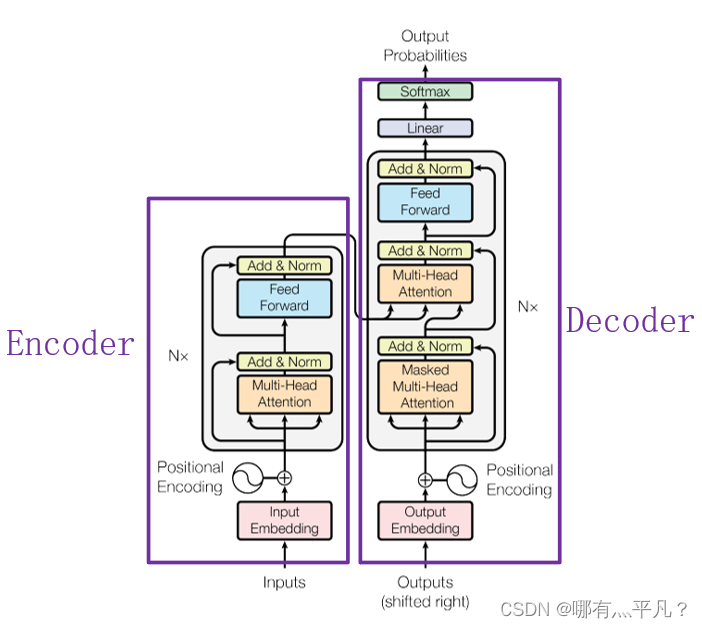
目前,在NLP领域当中,主要存在三种特征处理器——CNN、RNN以及Transformer,当前Transformer的流行程度已经大过CNN和RNN,它抛弃了传统CNN和RNN神经网络,整个网络结构完全由Attention机制以及前馈神经网络组成。首先给出一个来自原论文的Transformer整体架构图方便之后回顾。

self attention
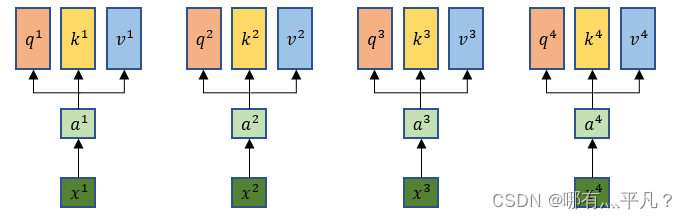
self attention模型输入的xi先做embedding得到ai,每一个xi都分别乘上三个不同的w得到q、k、v。
接下来把
与对应的
分别做乘积最后求和得出第一个输出
,同理可得到所有
。
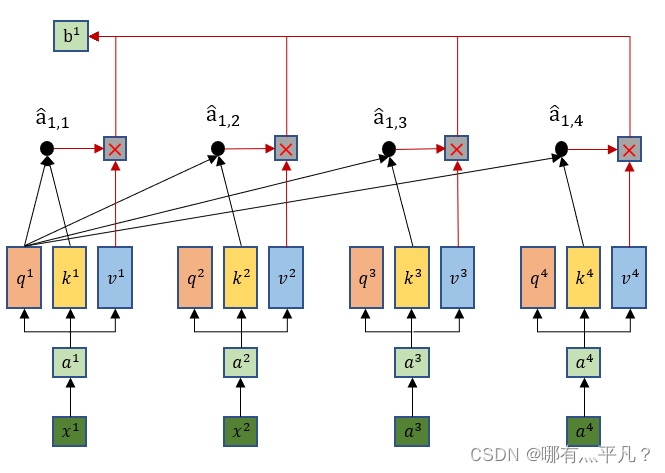
那么到这里就可以看出输出b1是综合了所有的输入xi信息,同时这样做的优势在于——当b1只需要考虑局部信息的时候(比如重点关注x1,x2就行了),那么它可以让
和
输出的值为0就行了。
那么self attention是这么做平行化的呢?
咱们复习一下前面说到的q、k、v的计算:
因为
,那么根据矩阵运算原理,我们将
串起来作为一个矩阵I与
相乘可以得到
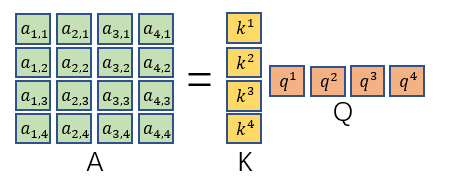
构成的矩阵Q。同理可得
的矩阵K、V。
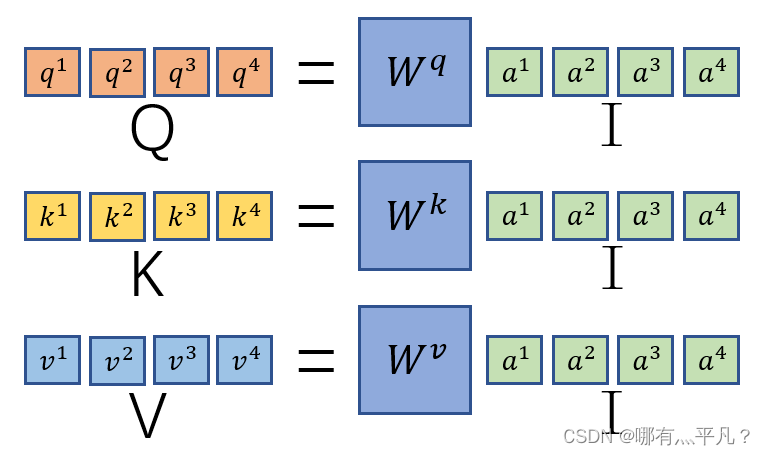
然后我们再回忆观察一下的计算过程(为方便理解,此处省略
):
我们可以发现计算都是用
去乘以每个
得出
,那么我们将
叠加起来与
相乘得到一列向量
(i=1,2,3,4)。然后你再加上所有的
就可以得到整个
矩阵。最后对
的每一列做一个soft-max就得到
矩阵。
最后再把与所有
构成的矩阵V相乘即可得到输出。
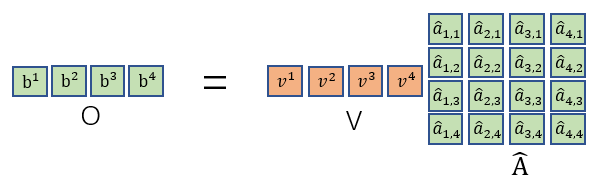
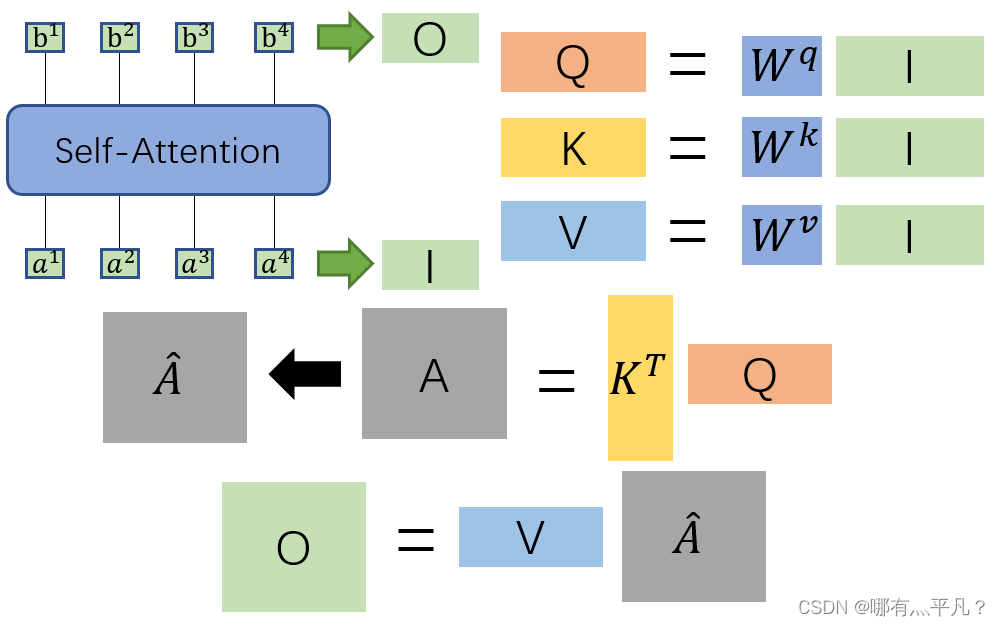
在这里我们对输入I到输出O之间做的事情做一个总结:我们先用I分别乘上对应的
得到矩阵Q,K,V,再把Q与
相乘得到矩阵A,再对A做soft-max处理得到矩阵KaTeX parse error: Expected group after '^' at position 7: \hat A^̲,最后再将KaTeX parse error: Expected group after '^' at position 7: \hat A^̲与V相乘得到输出结果O。整个过程都是进行矩阵乘法,都可以使用GPU加速。
self-attention的变形——Multi-head Self-attention
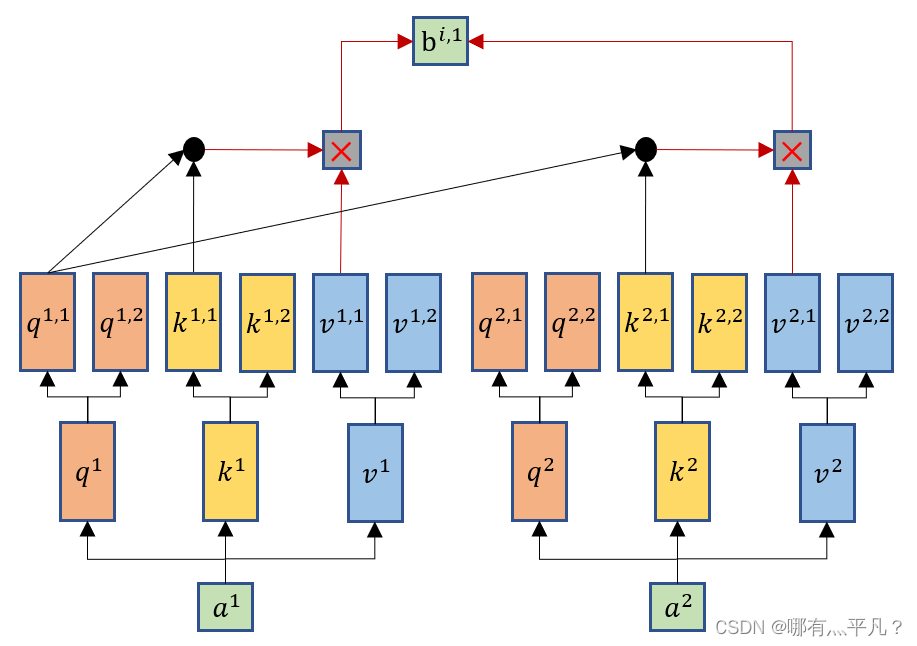
Multi-head Self-attention跟self-attention一样都会生成q、k、v,但是Multi-head Self-attention会再将q、k、v分裂出多个
(这里举例分裂成两个),然后它也将q跟k去进行相乘计算,但是只跟其对应的k、v进行计算,比如
只会与
、
进行运算,然后一样的乘以对应的v得到输出
。
那么这个Multi-head Self-attention设置多个q,k,v有什么好处呢?
举例来说,有可能不同的head关注的点不一样,有一些head可能只关注局部的信息,有一些head可能想要关注全局的信息,有了多头注意里机制后,每个head可以各司其职去做自己想做的事情。
Positional Encoding
根据前面self-attention介绍中,我们可以知道其中的运算是没有去考虑位置信息,而我们希望是把输入序列每个元素的位置信息考虑进去,那么就要在
这一步还有加上一个位置信息向量
,每个
都是其对应位置的独特向量。——
是通过人工手设(不是学习出来的)。

文章出处登录后可见!