controlNet模块使用
-
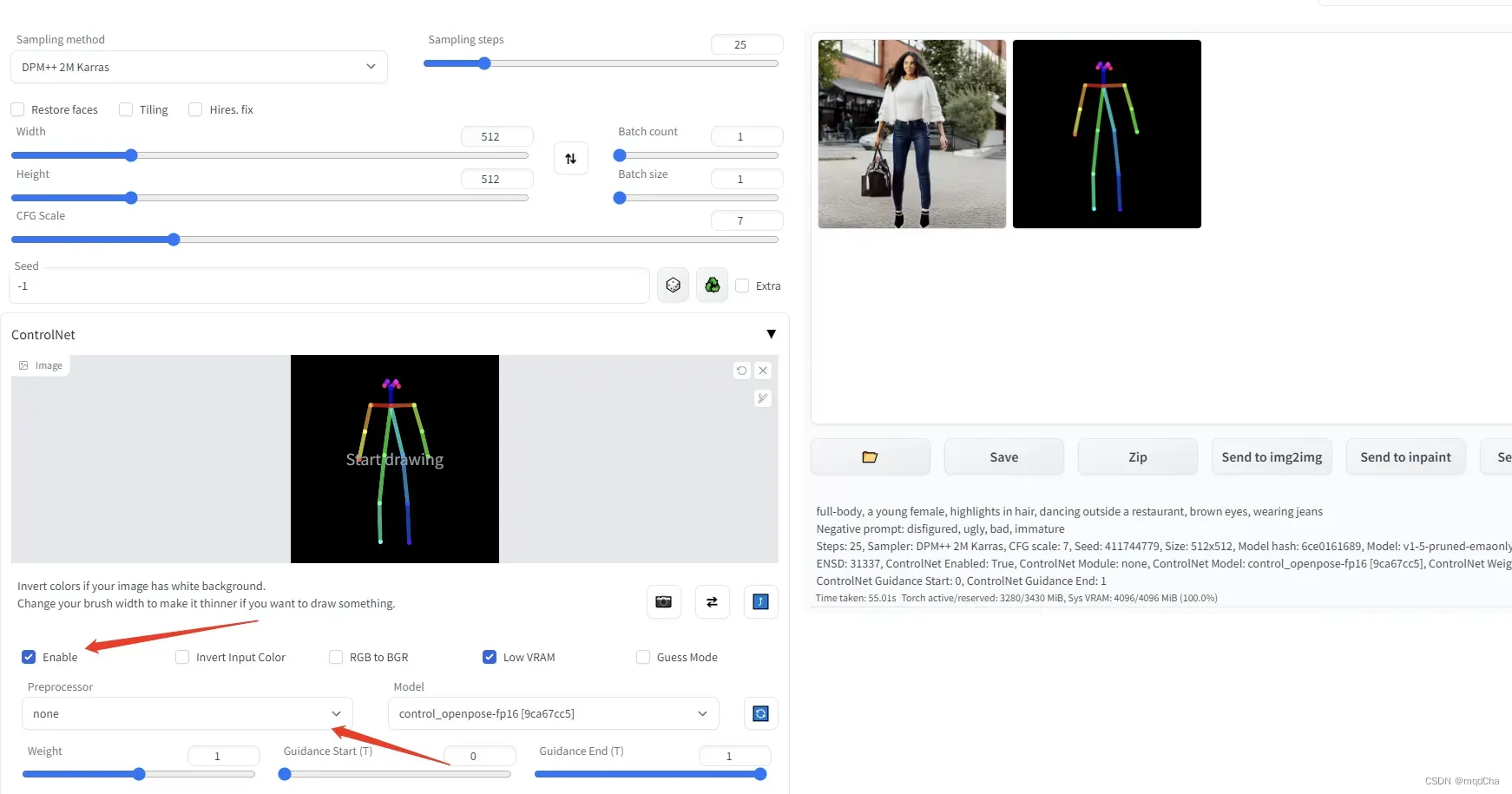
Enable选项启用,使用Openpose Edito中姿势生成需要将Openpose Editor指定为none状态。 - 上面骨骼图是通过Openpose Editor调整姿势然后send to txt2img到这里的,使用Openpose Edito中姿势生成需要将Openpose Editor指定为none状态。
Preprocessor选项:
Canny edge — 黑色背景上带有白色边缘的单色图像。 将图片变成线稿。
Depth/Shallow areas — 灰度图像,黑色代表深区域,白色代表浅区域。
Normal map — 法线贴图图像。
Semantic segmentation map——ADE20K 的分割图像。
HED edge — 黑色背景上带有白色软边缘的单色图像。
Scribbles — 黑色背景上带有白色轮廓的手绘单色涂鸦图像。
OpenPose (姿势关键点)— OpenPose 骨骼图像。
M-LSD — 仅由黑色背景上的白色直线组成的单色图像
Preprocessor部分选项使用教程
官方教程链接:Control human pose in Stable Diffusion Stable Diffusion Art (stable-diffusion-art.com)
1. canny图像生成线稿
先加载对应的模块吗,然后点击生成。
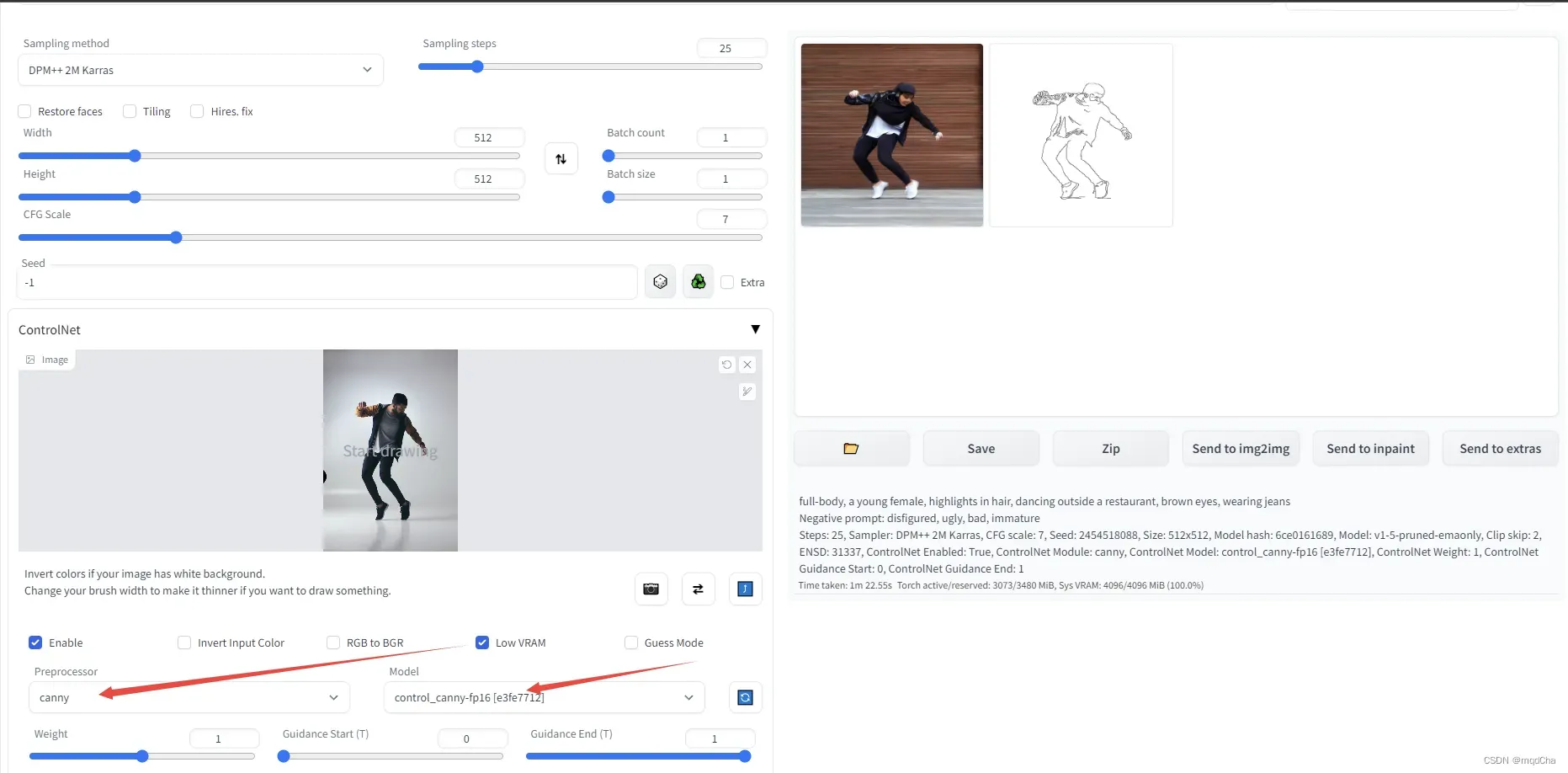
2. hed轮廓生成图像,跟上面操作一样只需要更换对应的Preprocessor选项和model为hed,也需要根据添加描述来生成
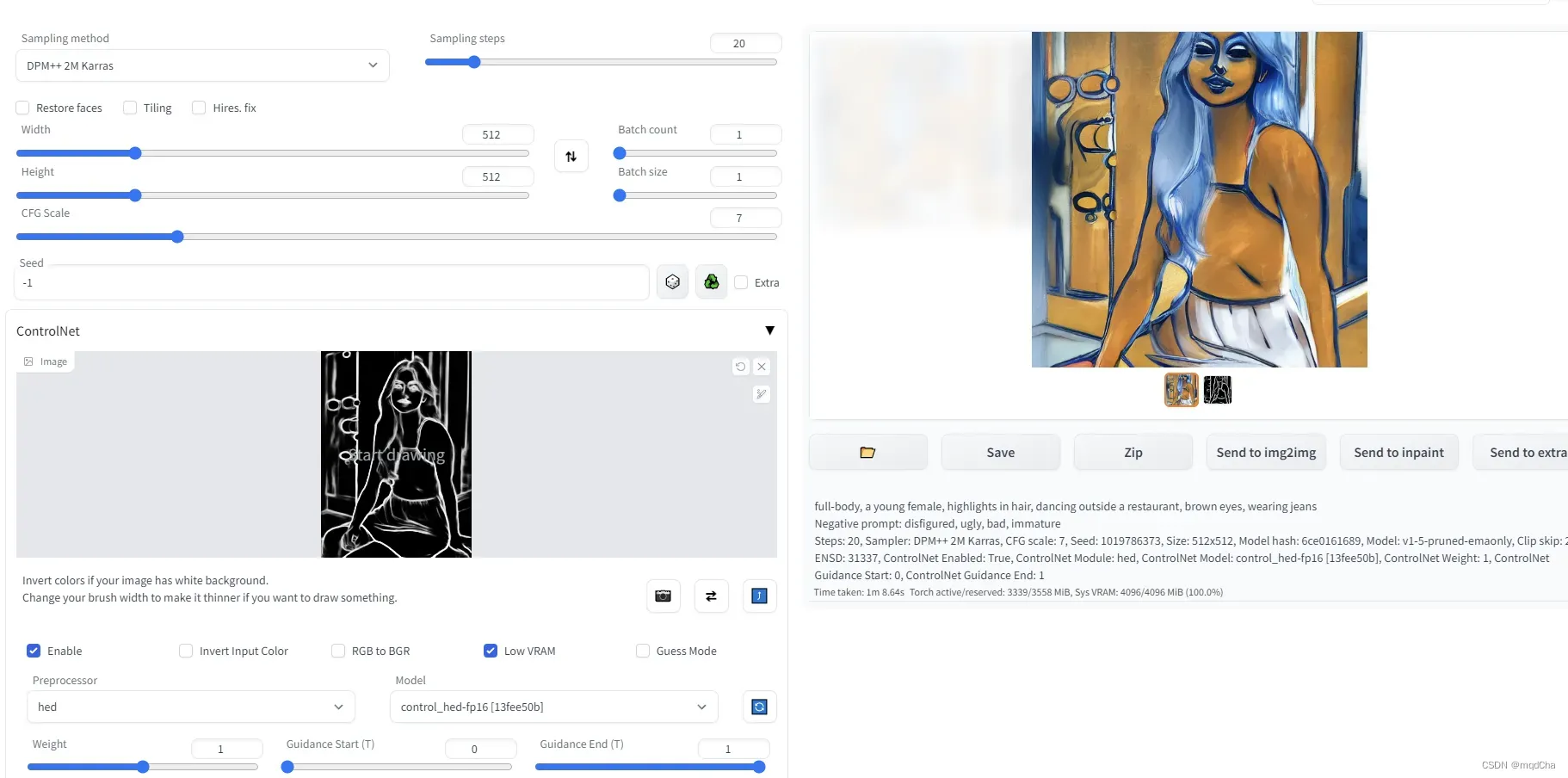
3.scribble涂鸦生成
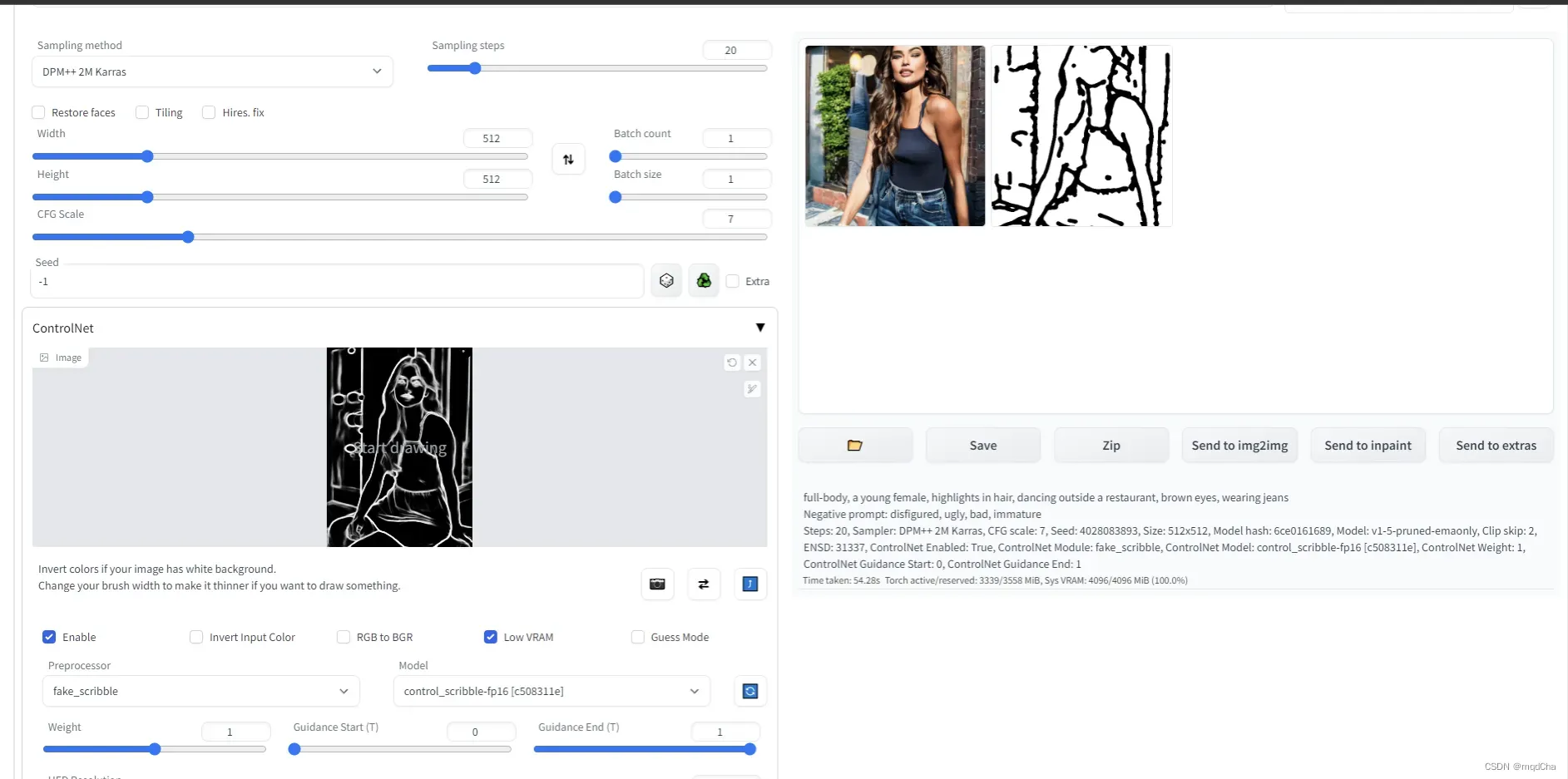
以上推图片生成的风格内容都是需要根据底层模型来获取内容。跟换底层模型在
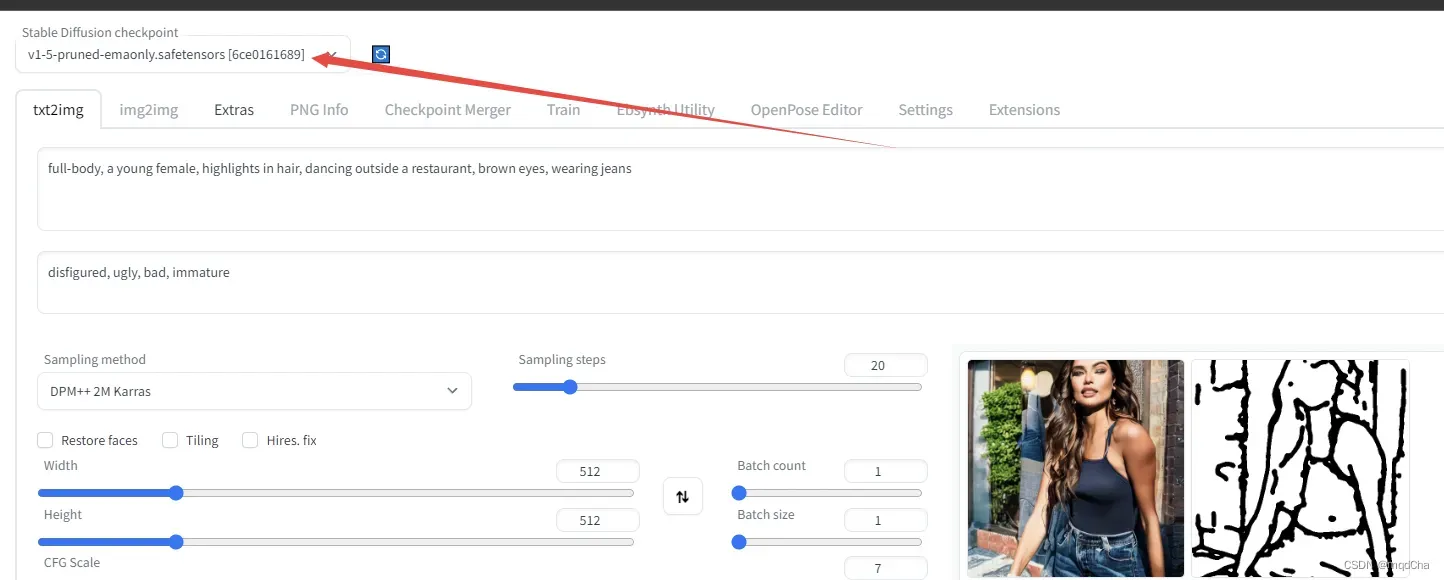
图生图img2img
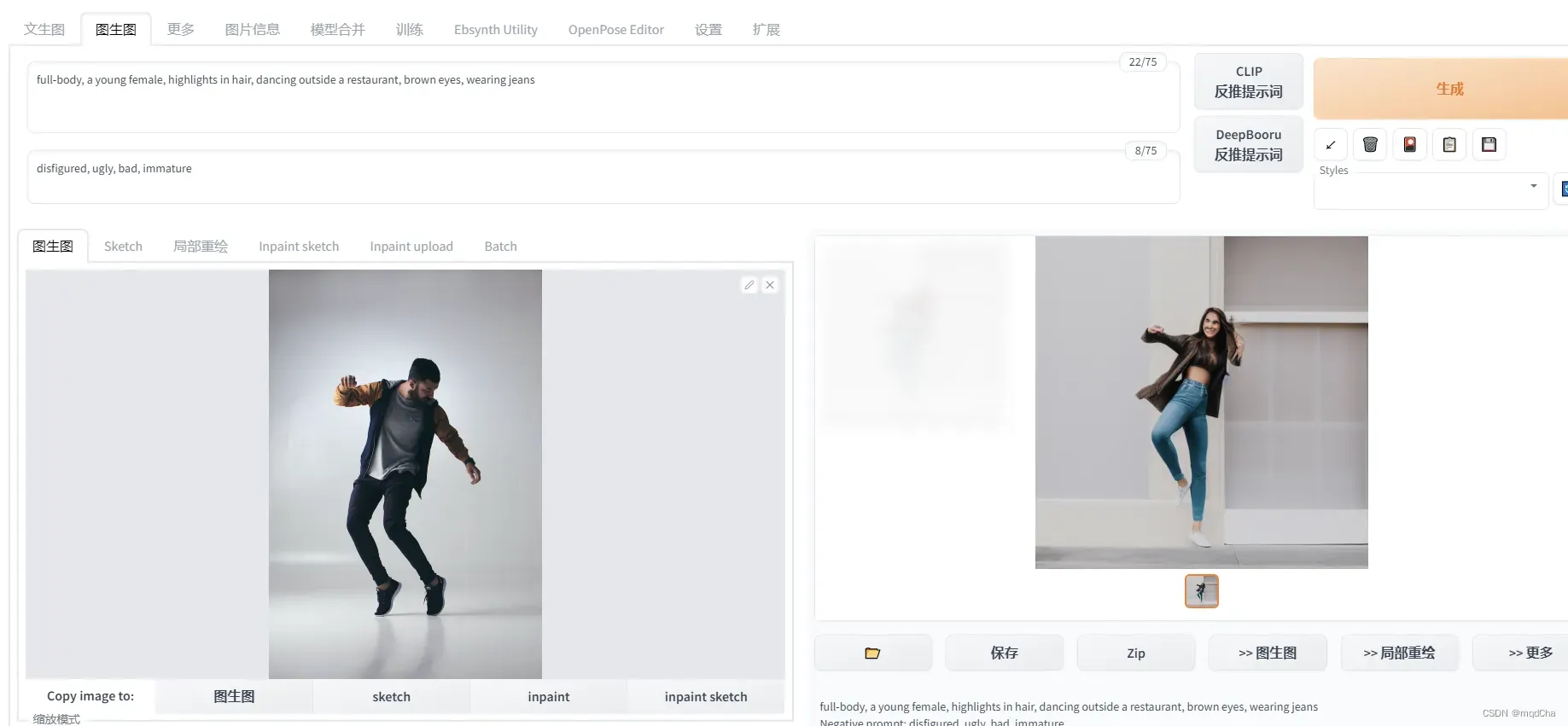
对于生成出来的图片局部不满意可以进行局部重绘,涂黑需要修改的地方,不满意就send to inpaint在修改好一点的基础上继续修改,一直到满意为止
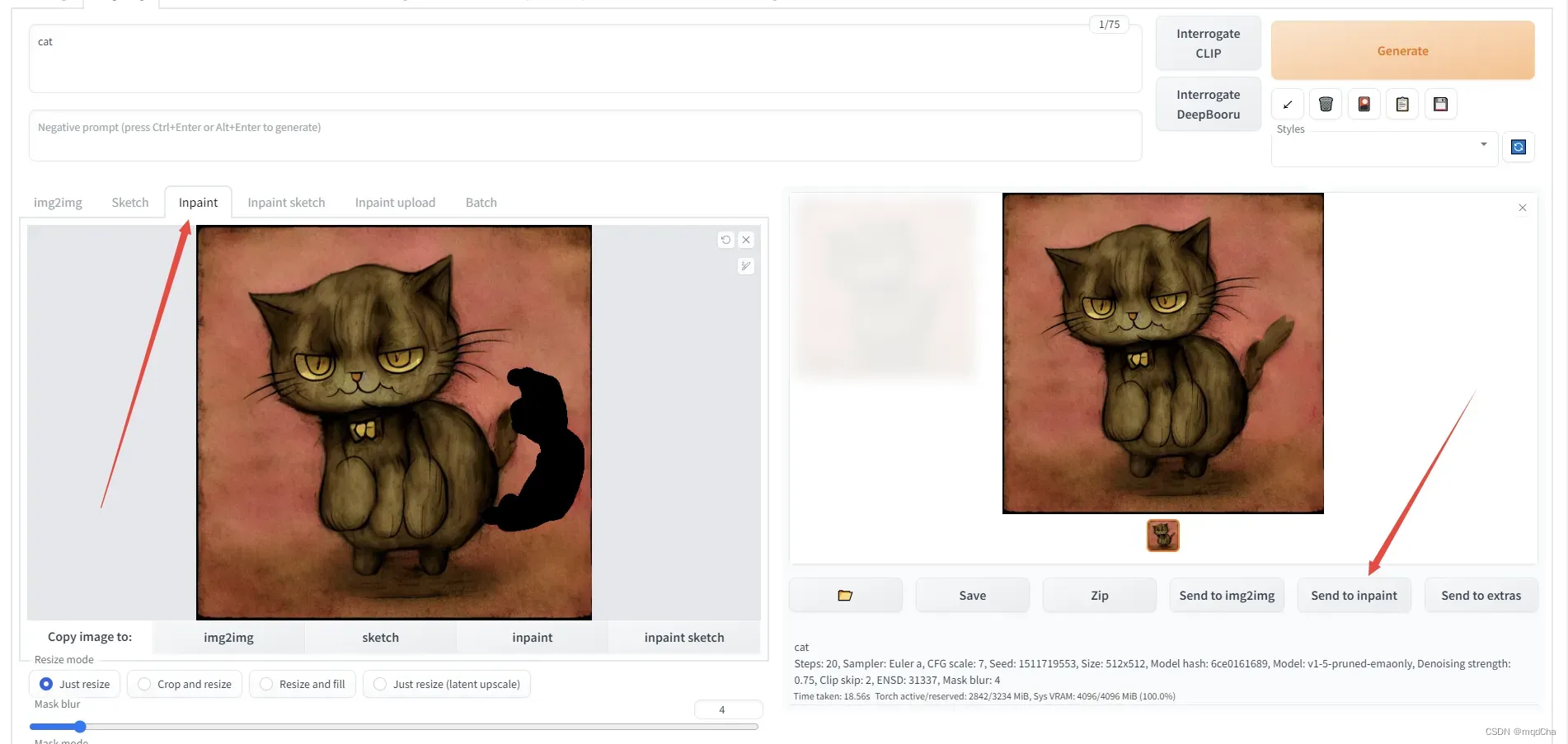
协同创作,根据你的手绘和提示词然后图生图生成不同内容
使用技巧
tag提示词:
线稿:((line art, white and black))
漫画风:((monochrome, screentone))
生成原则
- 一般原则:
一般来说越靠前的词汇权重就会越高,所以多数情况下的提示词格式是:质量词,媒介词,主体,主体描述,背景,背景描述,艺术风格和作者 - 权重调节: 最直接的权重调节就是调整词语顺序,越靠前权重越大,越靠后权重越低,可以通过下面的语法来对关键词设置权重,一般权重设置在0.5~2之间,可以通过选中词汇,按ctrl+↑↓来快速调节权重,每次步进为0.1,(best quality:1.3)
- 词条组合:
几个词用括号合起来并不会让ai把他们视为一体,即使打上权重也不行,比如以下两者实际上是完全等价的
○ (car, rockt, gun:1.3)
○ (car:1.3), (rocket:1.3), (gun:1.3)
词条组合的方式和自然语言差不多,要使用介词,比如and,with,of 等等,比如(car with guns and rockets)
采样方法
采样方法有很多,但是目前常用的基本只有几种:
- Euler a:速度最快的采样方式,对采样步数要求很低,同时随着采样步数增加并不会增加细节,会在采样步数增加到一定步数时构图突变,所以不要在高步数情景下使用
- DPM++2S a Karras 和 DPM++ SDE Karras:这两个差不太多,似乎SDE的更好,总之主要特点是相对于Euler a来说,同等分辨率下细节会更多,比如可以在小图下塞进全身,代价是采样速度更慢
- DDIM: 很少会用到,但是如果想尝试超高步数可以使用,随着步数增加可以叠加细节
采样步数
一般来说大部分时候采样部署只需要保持在20~30之间即可,更低的采样部署可能会导致图片没有计算完全,更高的采样步数的细节收益也并不高,只有非常微弱的证据表明高步数可以小概率修复肢体错误,所以只有想要出一张穷尽细节可能的图的时候才会使用更高的步数
输出大小
大致的输出大小和内容关系参考:
• 约30w像素,如512512,大头照和半身为主
• 约60w像素,如768768,单人全身为主,站立或躺坐都有
• 越100w像素,如1024*1024,单人和两三人全身,站立为主
• 更高像素,群像,或者直接画面崩坏
提示词相关性(CFG)
CFG很难去用语言去描述具体的作用,很笼统的来说,就是给你所有的正面和反面提示词都加上一个系数,所以一般CFG越低,画面越素,细节相对较少,CFG越高,画面越腻,细节相对较多
• 二次元风格CFG可以调的高一些以获得更丰富的色彩和质感表达,一般在712,也可以尝试1220
• 写实风格CFG大都很低,一般在4~7,写实模型对CFG很敏感,稍微调多一点可能就会古神降临,可以以0.5为步进来细微调节
随机种子
• 点击筛子按钮可以将随机种子设为-1,也就是随机
• 点击回收按钮可以将随机种子设为右边图片栏里正在看的那张图片的随机种子
面部修复
面部修复在早期模型生成的的写实图片分辨率不高的时候有一定价值,可以在低分辨率下纠正错误的写实人脸,但是现在的模型的脸部精度已经远超早期模型,而面部修复功能会改变脸部样貌,所以只要无视这个功能就好
VAE设置
VAE的作用是修正最终输出的图片色彩,如果不加载VAE可能会出现图片特别灰的情况,设置位置:
• 设置-StabelDiffusion-模型的VAE
设置之后记得点击上方的保存设置,VAE是通用的,可以和任何模型组合
解决方案
修复手部姿势
tag提示词网站
https://aitag.top/
https://tags.novelai.dev/
https://www.wujieai.com/tag-generator
教学文档
https://stable-diffusion-art.com/automatic1111
模型库
模型下载:
https://civitai.com/
https://huggingface.co/lora-library
文章出处登录后可见!