Stable Diffusion扩散模型作为生成高质量图像的先进模型,却伴随着对训练数据的记忆化倾向,引发了隐私和安全性的担忧。AIGCer分享一篇分析该现象的文章,通过两个案例研究深入挖掘了文本复制现象,旨在为未来生成模型的改进提供重要的指导。
基于扩散模型,如Stable Diffusion模型,以其生成高质量、高分辨率图像的能力,已经在文本到图像合成领域引起了革命。这些进展推动了图像生成和编辑任务的显著进展。然而,这些模型也引发了一些担忧,因为它们有记忆和潜在复制训练样本的趋势,从而带来隐私风险并可能导致对抗性攻击。在训练数据集中的重复被认为是导致记忆的主要因素,迄今为止已经研究了各种形式的记忆。本文关注于两种不同且鲜为人知的复制类型,这些类型在扩散模型中在推断过程中导致了复制,特别是在Stable Diffusion模型中。通过两个案例研究深入探讨了这些较少研究的复制现象及其影响,旨在为生成模型在各种应用中的更安全、更负责任的使用做出贡献。
引言
基于扩散的模型展示了在生成高质量图像方面的出色能力,无条件生成和有条件生成皆如此。Stable Diffusion模型作为一种有条件扩散模型,与其他生成模型如DALLE-3和Midjourney一同,显著推动了文本到图像生成领域的发展。这些模型在创建高分辨率图像和图像编辑方面表现出色。
机器学习模型中的记忆化已经得到广泛研究。这种记忆化可能带来隐私风险,潜在地可能导致成员关系推断或数据提取等攻击。尽管扩散模型,包括Stable Diffusion模型,具有生成高质量图像的能力,它们有时表现出对精确训练样本或其重要部分的记忆和复制的趋势。Somepalli等(2023b)指出,与仅包含图像的上下文相比,文本条件更容易导致记忆。先前的研究表明,在推断过程中,训练样本的复制可能是这种复制的一个重要原因。
本文深入研究了两种特定类型的文本条件训练样本复制:第一种涉及图像及其相应文本(包含特定关键词)的复制;第二种涉及图像-文本对的复制,其中图像包含特定对象,而文本包含特定关键词。这种微妙的复制形式可能加剧模型对各种攻击的脆弱性。随着文本到图像生成模型的日益普及,详细审查它们的记忆倾向变得越来越重要。通过分析两个案例研究,本文探讨了这两种复制类型,以揭示它们的动态和影响。
相关工作
「大型语言模型中的记忆化」
在大语言模型(LLMs)领域,由于无意中泄露了导致模型记忆的机密信息,因此面临着越来越大的挑战。Carlini等通过定量方法进行深入分析,之前利用定性技术进行研究。导致这种情况的一个关键因素是训练数据集中固有的复制,可能导致语言模型生成与已存在内容相似的文本。Biderman等(2023)最近的贡献表明,这种记忆化是由于训练数据集的平均值,而Biderman等(2023)则说明其发生在特定的训练数据点上。
「扩散模型中的记忆化」
最近的研究展示了使用有条件和无条件扩散模型创建相似或几乎相同图像的技术。具体而言,Somepalli等(2023a)强调,扩散模型可以生成具有与训练数据中相似对象的图像,这个过程被称为“复制”。与此同时,Carlini等(2023)展示了模型通过分析生成样本的聚类,从训练集中检索几乎相同的图像的能力。Somepalli等(2023b)最近的研究认为,在无条件扩散模型中,由于复制而导致的数据复制可能较少,而文本条件可能显著增加模型记忆化的可能性。在重复发生这种记忆化的前期研究中,Webster等(2023)引入了一种算法方法来检测这种重复。
背景
「扩散模型」
在深度生成模型的背景下,去噪扩散概率模型,通常称为无条件扩散模型,通过迭代进行噪声添加(正向过程)和随后的噪声移除(反向过程)来生成图像。
正向阶段采用马尔可夫链结构,逐渐向数据()注入高斯噪声,直到达到完全受噪声影响的图像()。相反,反向过程采用去噪机制,系统地去除前一时间步存在的噪声,遵循马尔可夫链。
「Stable Diffusion」
在Rombach等人的研究中(2022),”Stable Diffusion”模型专门用于文本到图像合成任务。该模型通过扩散图像的潜在向量表示。它首先接收文本输入,然后通过冻结的CLIP文本编码器将其转换为文本embedding。随后,一个文本条件的潜在U-Net迭代地去噪潜在向量,其方式是根据生成的文本embedding进行条件化。最后,一个变分自编码器(VAE)解码这个潜在向量,生成相应的图像。
word级复制
Carlini等人(2023)提出了记忆化的定义,其中将一个示例x从扩散模型中提取的条件是,存在一种有效算法A,使得满足条件,该定义强调产生与原始图像几乎相同的图像的复制。然而,关注更广泛的记忆化理解,将其称为部分复制。这涉及到图像内的特定对象或特征。Carlini的度量标准可能并不总是捕捉到这种记忆化;即使在图像中存在可识别的记忆化,它可能表明较高的距离。
Somepalli等人(2023b)研究了LAION数据集中更广泛范围的复制,涵盖比以前的研究更多的情况。他们考虑了字幕和图像的复制,甚至深入研究了部分字幕的复制。然而,对于他们的方法存在一些担忧。他们从LAION数据集中筛选出两个子集,用于对Stable Diffusion模型进行微调。在其原始预训练数据集的子集上对Stable Diffusion进行微调可能导致意外的记忆化增加。
在文本条件的扩散模型中,文本起着关键作用。基于这一观点,对这些应用的主要关注应围绕文本条件的记忆化。虽然数据集中可能存在图像的复制,但如果文本与图像之间没有关联,那么在推断时,在提供提示时不太可能出现相关的复制。这一观察引导我们考虑更现实类型的复制。
与先前的研究不同,作者的重点是单word 级的复制。具体而言,目标是识别在复制中关键词和图像之间是否存在关联。作者质疑在数据集中是否一致复制了某些关键词和图像集。在这种情况下,字幕不一定表现出高语义相似性;它们可能只共享共同的关键词。因此,在推断时,当模型遇到这些特定关键词的组合时,它可能会尝试复制在训练期间观察到的相应特征或对象。在实验结果中,通过对LAION数据集进行详细案例研究进一步探讨了这种类型的复制。
「定义记忆化的更现实方法」
先前的研究通常依赖于单一随机初始化进行生成。然而,无论使用何种记忆化定义,更现实的检查方法涉及使用多个随机初始化。实际设置中,如果模型在不同初始化中始终生成相同的特征、对象或甚至整个图像,就会出现对记忆化和复制的担忧。因此,基于单一种子进行的记忆化或复制评估可能无法提供全面的理解。
对象级复制
在这一部分,介绍了一种称为对象级复制的独特复制类型。当在训练数据集中出现一对特定图像中的对象和相应文本中的某些关键词时,即使对象的名称在文本中没有出现,也会发生对象级复制。这种复制可能导致在推断时,当提示中存在相关关键词时,这些特定对象的复制。这种复制模式引发了各种可信度问题,尤其是隐私和公平性。基本上,它意味着模型不论在用户提供的输入中是否提及或缺失,都会持续生成特定对象,这可能与用户的期望或意图不符。
这种现象的一个可能解释是图像中的某些关键词和对象之间的隐含关联。也就是说,在训练数据集中可能不会复制整个图像,但是特定对象可能经常出现在与包含特定单词的字幕相关的图像中。将在实验部分通过一项专门的案例研究深入探讨这一现象。
实验结果
在这一部分,展示两个案例研究,分别对应之前讨论的两种复制类型,并在每个研究中加入多个示例。对于所有实验,使用了LAION-400M(Schuhmann等人,2021),这是较大的LAION-5B(Schuhmann等人,2022)数据集的一个子集。选择这个子集是因为它在规模上更易管理。实验使用了在LAION-5B数据集上训练的Stable Diffusion v1.4模型。
「案例研究1:梵高」
在初始案例研究中,深入研究了单word 级记忆化。为此,关注了带有包含术语“梵高”字幕的样本。大约有90,000个样本的字幕中包含这个术语。继续排除带有无效URL的样本。此外,考虑到CLIP模型的文本编码器接受的文本长度不超过77个标记,超过这个标记数的字幕样本也被省略。在经过这些过滤步骤后,剩下大约70,000个样本。此外,使用CLIP模型的图像编码器获取了这些样本的图像embedding。
在下一步中,对图像embedding进行聚类,利用余弦相似度来识别一组几乎相同的图像。然后根据它们的大小对聚类进行排序,并在每个聚类中,找出最频繁出现的单词。应注意,最大的聚类由于包含与其他聚类不太相关的无关图像,已经被省略在分析之外。下表1呈现了最大的聚类以及它们对应的频率单词。

演示这些关键词如何影响每个聚类中生成的图像。对于每组关键词,考虑以下字幕:
• 仅由关键词组成的字幕。
• 包含关键词的简短相关字幕。
• 包含关键词的长相关字幕。
• 包含关键词的无关字幕。
• 不包含术语“van gogh”的长字幕。
使用ChatGPT(OpenAI 2023)获得所有这些字幕。下图3中展示了聚类1的所有字幕及其相应生成的图像。
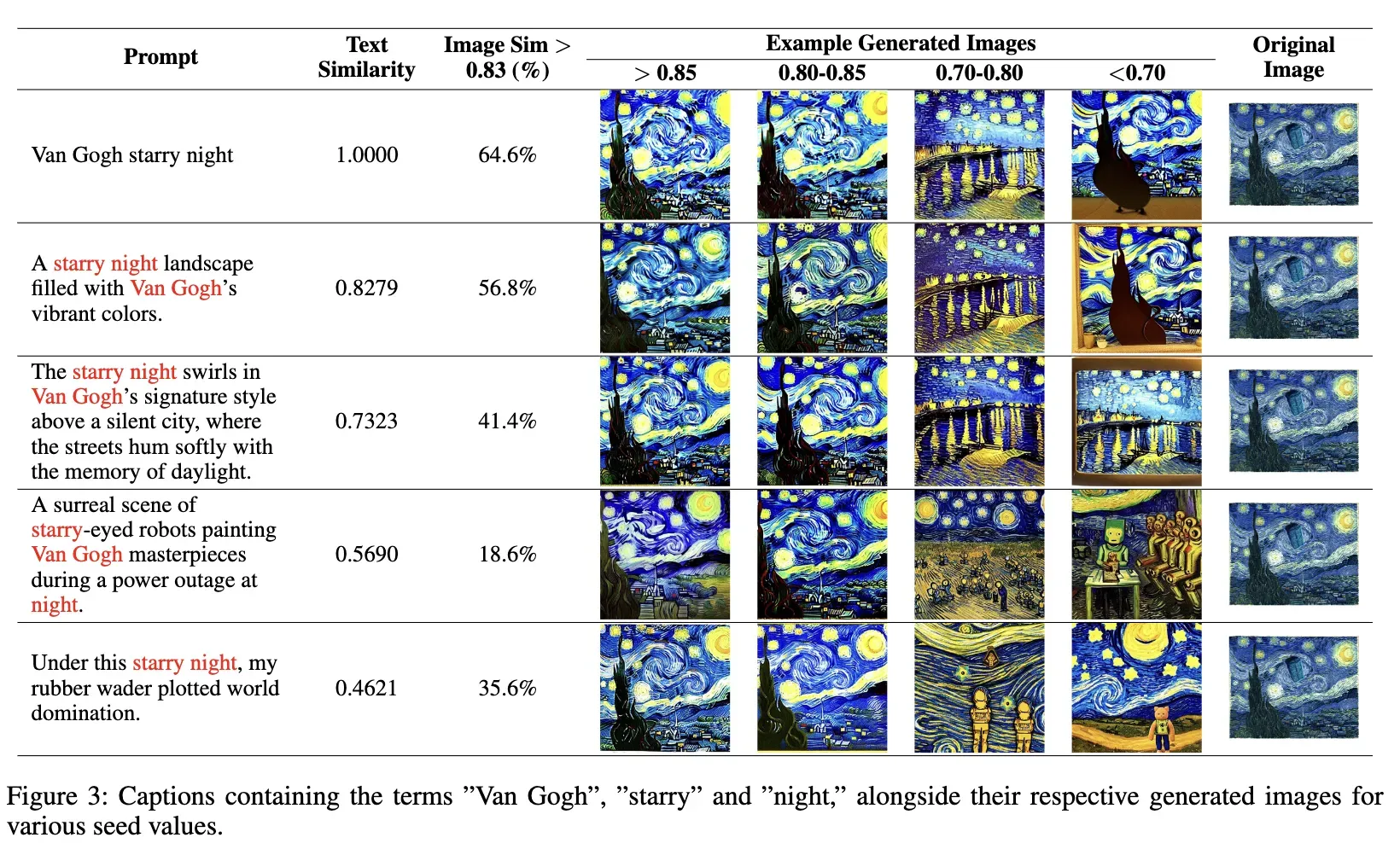
为了更好地说明复制的概念,对于每个提示,作者使用不同的随机初始化生成500张图像。提供演示与训练数据集中原始图像相似程度不同的示例。此外,对于每个聚类,都建立了一个唯一的图像相似性阈值,以确定与训练数据集中原始图像相似的生成的百分比。这个阈值在聚类之间变化,并需要根据每个聚类的特定特征进行手动设置。
如上面图3所示,实验从简短的提示开始,逐渐发展到更长、更多样的字幕。尽管在文本变化的情况下,图像始终保持原始艺术品的风格和元素。在第四个例子中,即使“starry”和“night”分开,图像仍然共同代表这些主题。有趣的是,最后的字幕省略了“Van Gogh”,但他独特的风格在图像中无疑地被捕捉到。此外,使用CLIP的文本编码器embedding计算给定提示与训练数据集中最接近的文本之间的余弦相似度。
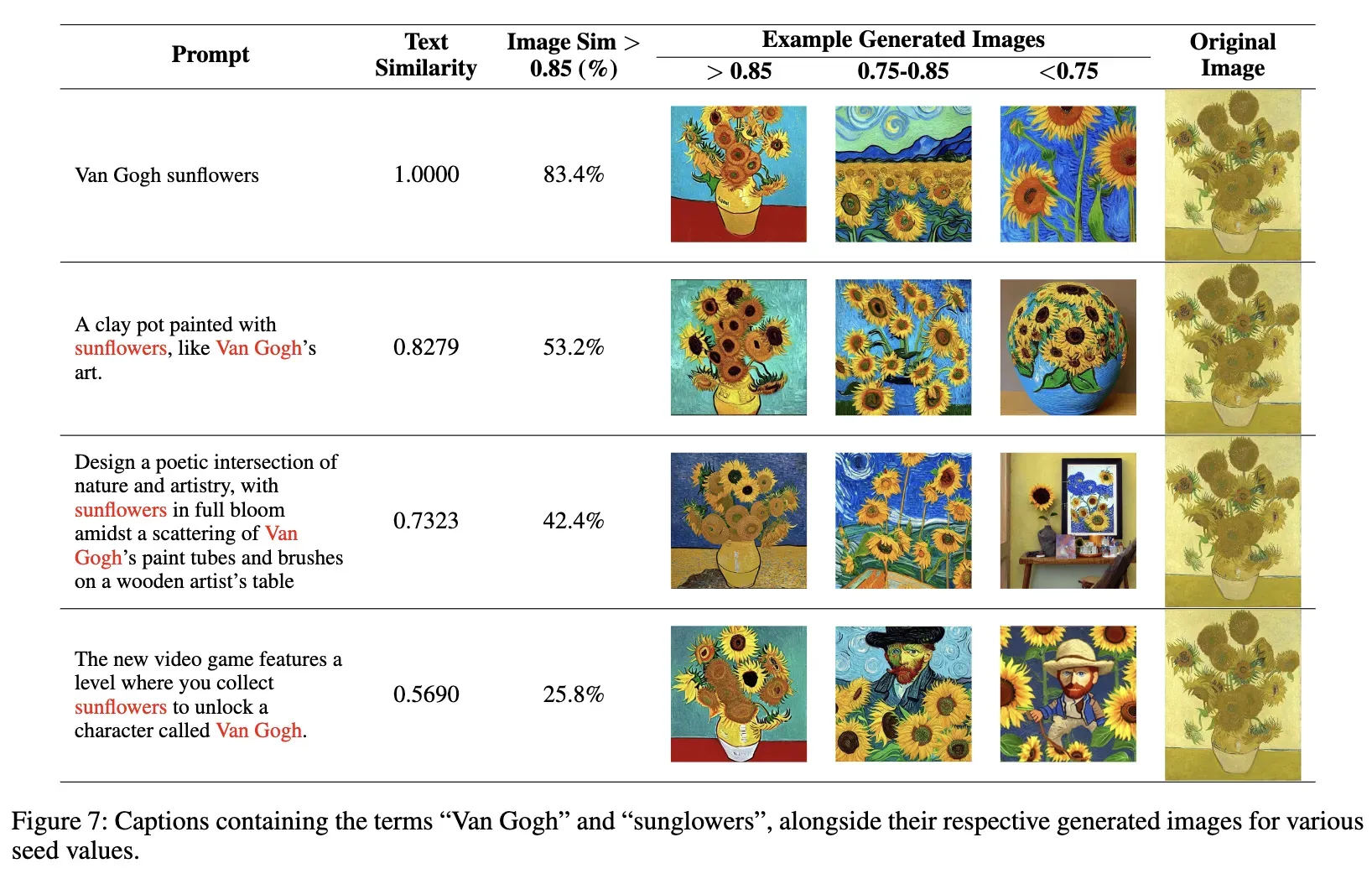
除了图3中显示示例的聚类外,还有另一个具有引人入胜结果的聚类。在前面表1中显示的Cluster 3中,关键词包括“van gogh”、“almond”和“blossoming”。有关此聚类的所有字幕及其相应生成的图像在下图6中说明。图6中的最后一个例子说明,即使没有明确提到“van gogh”,生成的图像仍与与Van Gogh的作品相关的训练数据集中的图像相似。此外,可以在下图7中找到Cluster 4的字幕和相应生成的图像。
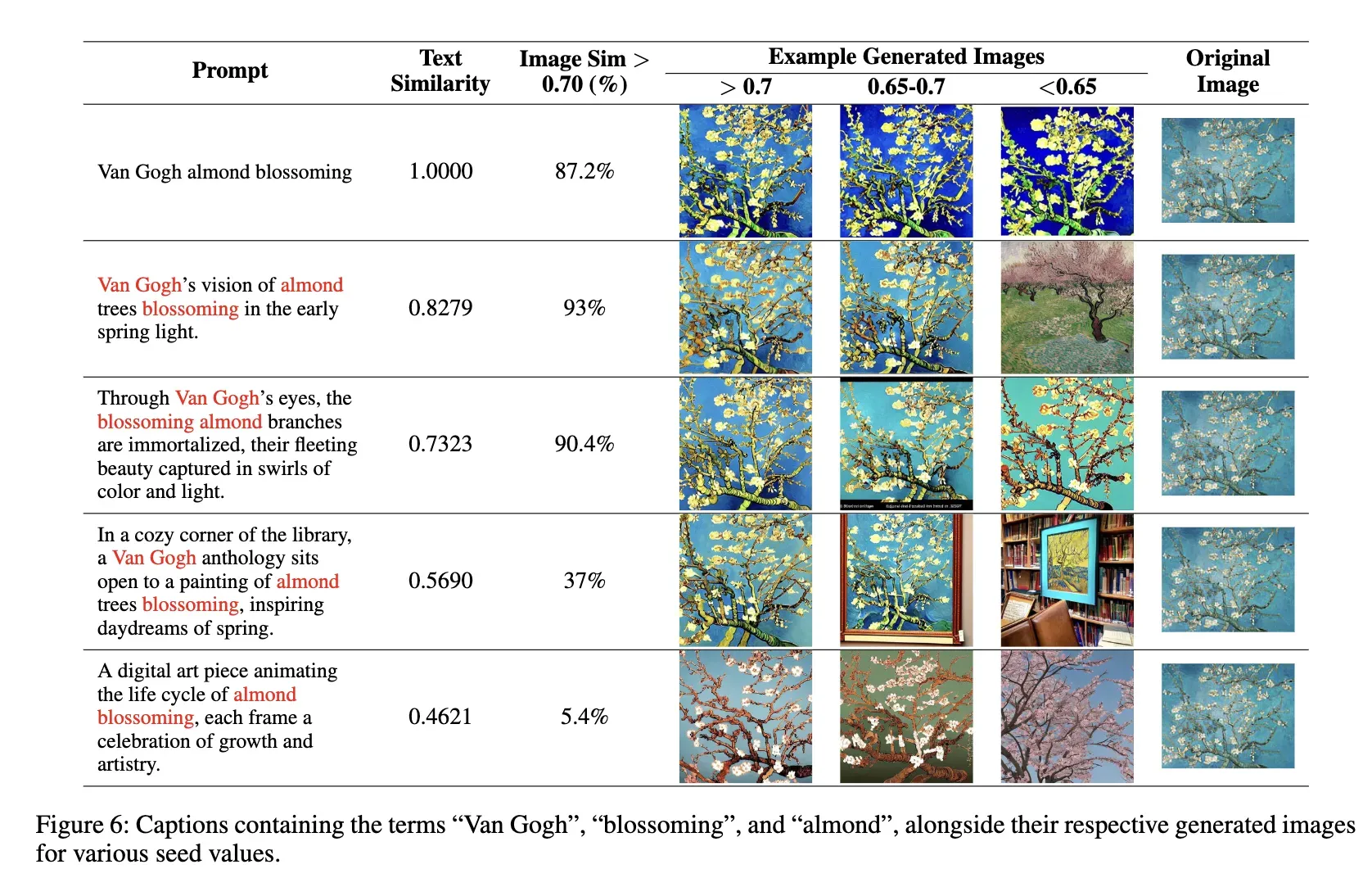
为了理解这一现象,分析了“almond”和“blossoming”这两个词在带有“van gogh”的字幕中有多频繁。通过过滤带有“almond”和“blossoming”的字幕的数据集,然后使用图像embedding对图像进行聚类,发现这两个描述性词语占据了与Van Gogh的作品相关的主导聚类,约占带有这两个描述性词语的条目的52%。
「频率至关重要」。在推断过程中,影响训练图像复制可能性的两个主要因素。第一个因素是数据集中特定关键词的频率。观察表明,当图像与频繁出现的关键词相关联时,它们更有可能复制。例如,“almond”和“blossoming”以及“Van Gogh”,这几个词具有更高的复制倾向。
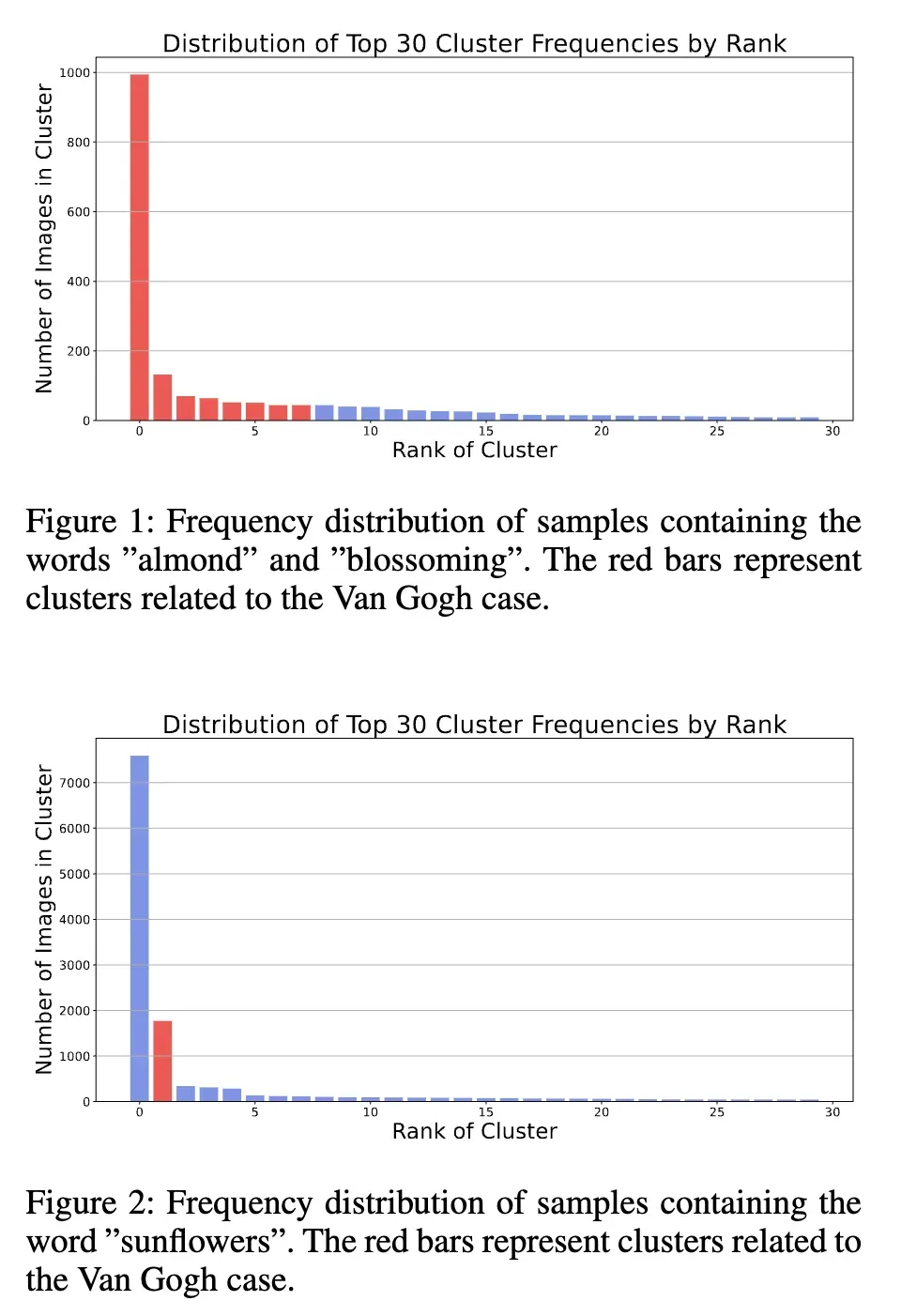
然而,仅有频率并不是唯一的决定因素。另一个有影响力的因素是数据集的初始聚类。当对带有特定关键词的图像进行聚类时,比如“almond”和“blossoming”,而不包括“Van Gogh”时,发现最大的聚类仍然与梵高的作品相关,约占样本的52%。尽管如此,有显著的48%的聚类与之无关。这种分布表明,在训练集中的关键词频率在一定程度上可以预测模型的复制行为。关键词“向日葵”进一步证明了这一点;尽管它与梵高经常相关,但在仅考虑数据集中的“向日葵”时,它仅占聚类的2%。这强调了为什么除非明确提到梵高的名字,否则梵高的艺术风格可能不会被复制。下图1展示了当对包含“almond”和“blossoming”这两个词的样本的图像进行聚类时,30个最大聚类的分布大小。下图2展示了同样的情况,但是对于词汇“sunflower”。
「案例研究2:宇航员」
在这一部分,通过一个专注的案例研究探讨对象级复制的概念。对象级复制指的是尽管与相关的文本提示中缺少这些对象,但特定对象在图像中经常出现的现象。这意味着在数据集中,特定关键词与重复出现的视觉元素之间存在强烈的相关性。为了研究这一现象,作者关注包含关键词“astronaut”的LAION数据集中的样本。作者应用与初始案例研究相同的方法框架来策划数据集的这个子集,并生成相应的图像embedding。这个过程产生了大约48,000个样本,对关键词-对象相关性的调查提供了实质性的基础。下图5呈现了一些这些训练样本,它们的字幕包含词语“astronaut”,相应的图像中包含美国国旗。

在这个案例研究中,作者关注美国国旗。对大约1000个带有提到“astronaut”字幕的训练数据样本的分析显示,即使没有明确指定“US”或“flag”这两个词,有10%的样本包含美国国旗的图像。为了进一步探讨这一现象,首先使用ChatGPT创建了一系列包含词语“astronaut”的随机提示。然后,使用这些提示在Stable Diffusion模型中生成图像,导致在输出中频繁复制美国国旗。请注意,由于预训练的Stable Diffusion模型生成质量较低,我们对该模型进行了微调,使用Midjourney API的一小部分提示和相应的高分辨率生成的图像,以提高生成示例的质量。下图4显示了ChatGPT生成的提示和Stable Diffusion模型生成的相应图像。

通过使用不同的随机种子生成500张图像,评估模型从提示中复制美国国旗的倾向。随后,计算并报告包含美国国旗的图像的百分比。
未来方向
尽管本文的研究集中在两个特定的案例研究上,但已经证明了在Stable Diffusion模型中发生了word 级复制的现象。对于未来的工作,作者建议在word 级复制的背景下进行更广泛的实验,并进行更全面的分析。此外,开发新的缓解技术,减少记忆而保留模型效用,具有至关重要的意义。本文研究中发现的复制特征还可能带来潜在的隐私风险,可能使模型容易受到各种攻击,包括成员关系推断和后门攻击。解决这些问题将是未来研究的一个关键方面。
结论
在生成模型的记忆过程中,训练数据中的复制是一个重要的促成因素。本文确定了两种在推断中导致复制的复制类型。通过两个LAION数据集的案例研究对这些进行了调查。本文的工作强调了对训练数据中不同复制形式的警惕性以及需要有效缓解策略的重要性。希望这项工作能够激发更加慎重的数据管理,并促使开发既强大又保护隐私的生成模型。
参考文献
[1] Memory Triggers: Unveiling Memorization in Text-To-Image Generative Models through Word-Level Duplication
链接:https://arxiv.org/pdf/2312.03692
更多精彩内容,请关注公众号:AI生成未来

版权声明:本文为博主作者:AI生成未来原创文章,版权归属原作者,如果侵权,请联系我们删除!