本文仅供学习使用
18. 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
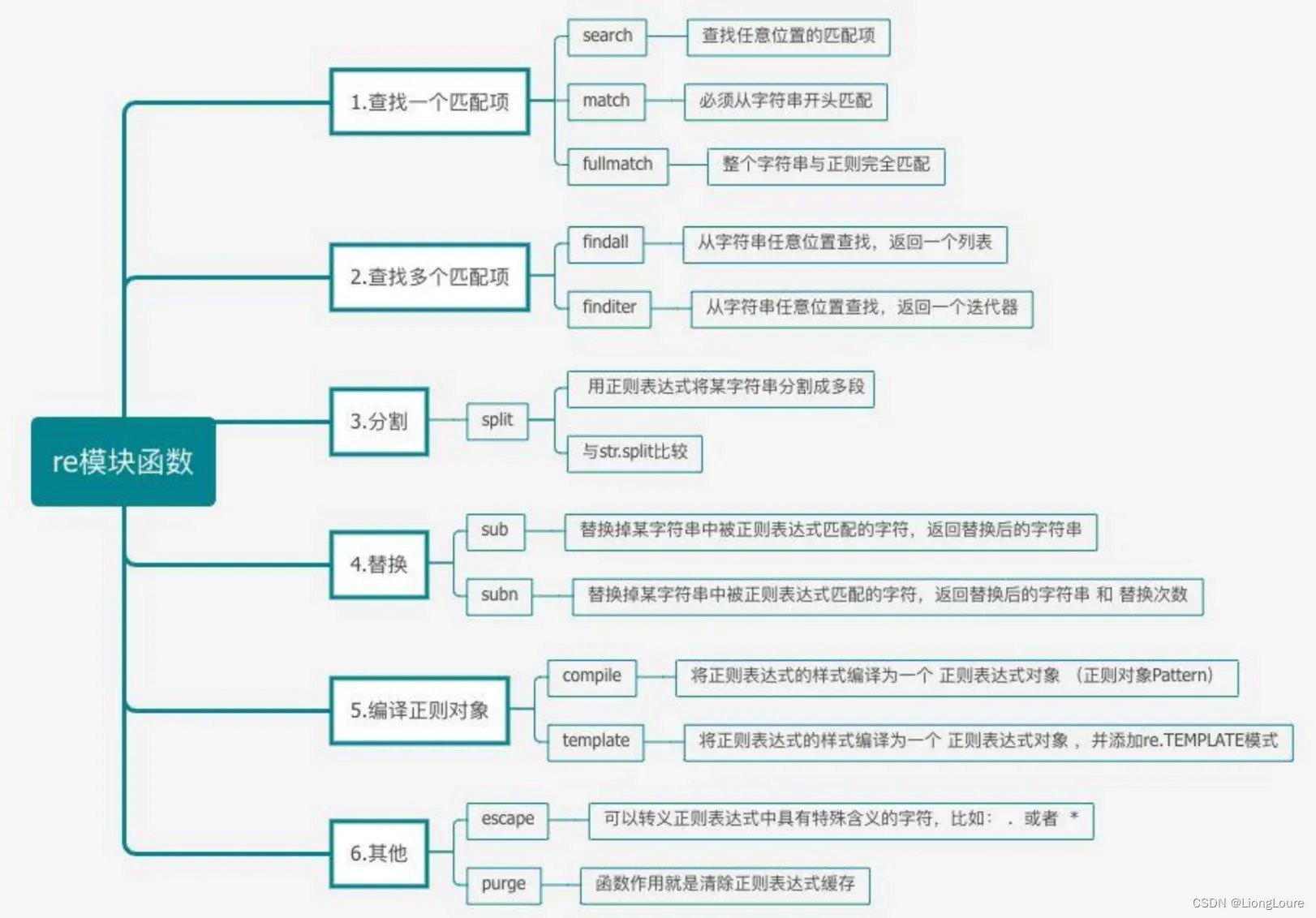
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
18.1 re 模块
正则表达式修饰符 – 可选标志:
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标
志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

Python的正则表达式模块re,有一个re.DOTALL的参数。默认情况下,正则表达式中的dot(.),表示所有除了换行的字符,加上re.DOTALL参数后,就是真正的所有字符了,包括换行符(\n)
当使用re.MULTILINE时,^和$这两个符号的含义发生了一点变化,原来这两个符号表示整个字符串(可以有\n换行符的字符串)的开始和结束,加上re.MULTILINE参数后,含义变为每行的开始和结束。re.M是这个参数的简写。
re.VERBOSE 或简写为 re.X:详细模式,可以在正则表达式中加注解!——允许为传入re.compile()的字符串添加空格和注释
18.1.1 re.match 函数
re.match(pattern, string, flags=0)
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回 none。
· pattern 匹配的正则表达式
· string 要匹配的字符串。
· flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
· 匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
18.1.2 re.search 方法
re.search(pattern, string, flags=0)
re.search 扫描整个字符串并返回第一个成功的匹配。
· pattern 匹配的正则表达式
· string 要匹配的字符串。
· flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
· 匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
re.match 与 re.search 的区别:
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回
None;而 re.search 匹配整个字符串,直到找到一个匹配。
print(res) # 匹配
import re
s = 'http://www.runoob.com.com'
sub_s = '.' # . 代表任意字符,除了换行符
res = re.findall(sub_s, s)
print(res) # ['h', 't', 't', 'p', ':', '/', '/', 'w', 'w', 'w', '.', 'r', 'u', 'n', 'o', 'o', 'b', '.', 'c', 'o', 'm', '.', 'c', 'o', 'm']
s = '\nhttp://www.runoob.com.com'
res = re.match(sub_s, s)
print(res) # None
res = re.match(sub_s, s, re.S) # 可以使 . 匹配换行符
print(res) # <re.Match object; span=(0, 1), match='\n'>
sub_s = '\.'
res = re.findall(sub_s, s)
print(res) # ['.', '.', '.']
res = re.findall(sub_s, s)
18.1.3 findall 函数
findall(pattern, string[, pos[, endpos]])
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
· pattern 匹配的正则表达式
· string : 待匹配的字符串。
· pos : 可选参数,指定字符串的起始位置,默认为 0。
· endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
注意: match 和 search 是匹配一次, findall 匹配所有。
import re
s = 'http://www.runoob.com.com'
sub_s = 'com'
res = re.findall(sub_s, s)
print(res) # ['com', 'com']
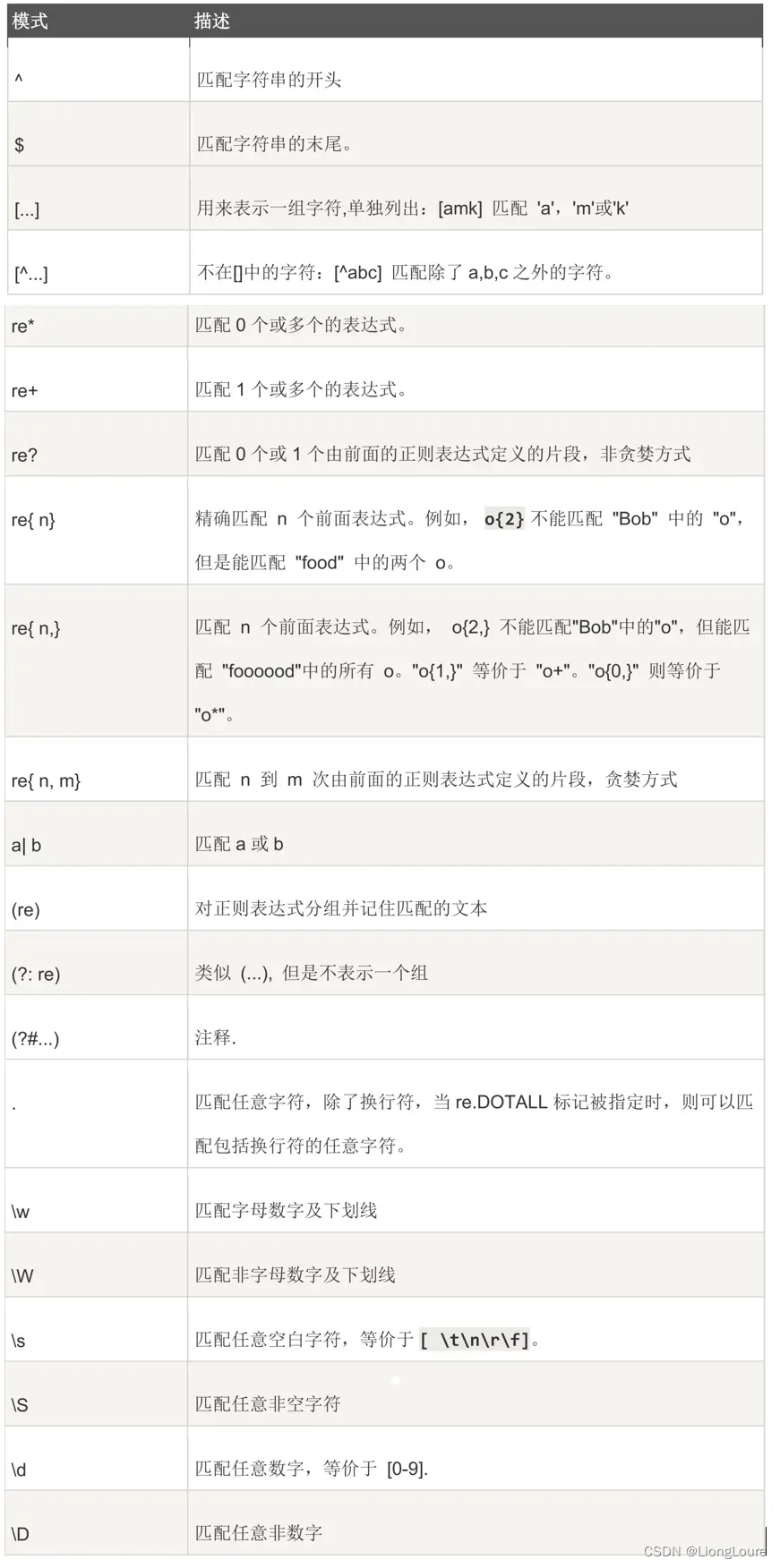
18.2 正则表达式模式
18.2.1 正则表达式中的字符
正则表达式是一种字符串,正则表达式字符串是由 普通字符串 和 元字符(Metacharacters) 组成。
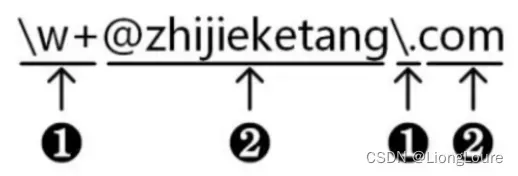
普通字符:按照字符字面意义表示的字符、如 ② 所示,都表示字符本身的字面意义
元字符:预先定义好的一些特定字符,如 ① 所示
引号前加 r 的说明:
向 re.compile()传递原始字符串
回忆一下,Python中转义字符使用倒斜杠(\)。字符串’\n’表示一个换行字符,而不是倒斜杠加上一个小写的n。你需要输入转义字符 \\,才能打印出一个倒斜杠。所以’\\n’表示一个倒斜杠加上一个小写的n。但是,通过在字符串的第一个引号之前加上r,可以将该字符串标记为原始字符串,它不包括转义字符。
因为正则表达式常常使用倒斜杠,向 re.compile((函数传入原始字符串就很方便,而不是输入额 外得到斜杠。输入r’\d\d\d-\d\d\d-\d\d\d\d’,比 输入”\\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d’要容易得多。
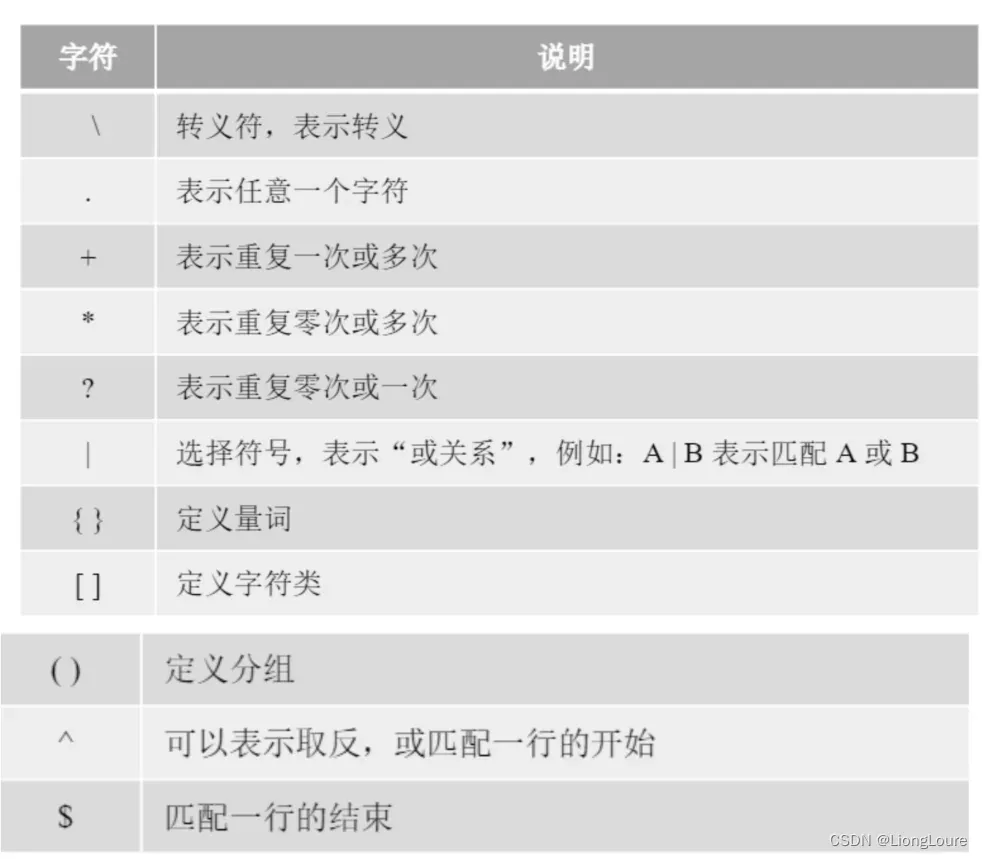
18.2.1.1 元字符
元字符(Metacharacters) : 是用来描述其他字符的特殊字符,由 基本元字符 + 普通字符 构成
# 量词
import re
s = 'http://www.runoob.com.com'
sub_s = 't+' # 贪婪模式
res = re.search(sub_s, s)
print(res) # <re.Match object; span=(1, 3), match='tt'>
sub_s = 'a+' # 重复1次或多次
res = re.search(sub_s, s)
print(res) # None
sub_s = 'a*' # 重复0次或多次
res = re.search(sub_s, s)
print(res) # <re.Match object; span=(0, 0), match=''>
sub_s = 'h?' # 重复0次或1次
res = re.search(sub_s, s)
print(res) # <re.Match object; span=(0, 1), match='h'>
sub_s = 't+?' # 非贪婪模式
res = re.search(sub_s, s)
print(res) # <re.Match object; span=(1, 2), match='t'>
# sub_s = 't?+' # 不合法
# res = re.search(sub_s, s)
# print(res) # baocuo
s = 'ttpptttp'
sub_s = 't??' # 第一个?为量词,第二个表示使用非贪婪模式
res = re.findall(sub_s, s)
print(res) # ['', 't', '', 't', '', '', '', 't', '', 't', '', 't', '', '']
sub_s = 't*?'
res = re.findall(sub_s, s)
print(res) # ['', 't', '', 't', '', '', '', 't', '', 't', '', 't', '', '']
sub_s = '.*?'
res = re.findall(sub_s, s)
print(res) # ['', 't', '', 't', '', 'p', '', 'p', '', 't', '', 't', '', 't', '', 'p', '']
sub_s = '.??'
res = re.findall(sub_s, s)
print(res) # ['', 't', '', 't', '', 'p', '', 'p', '', 't', '', 't', '', 't', '', 'p', '']
'''
?? 与 *?
'''
18.2.1.2 字符转义
不仅可以对普通字符进行转义,还可以对基本元字符进行转义。如域名中的点(.)字符希望按照点(.)字面意义使用,作为 .com 域名的一部分,而不是作为基本元字符使用,所以要加反斜杠“\”进行转义。即‘ \ . ’。
import re
s = 'http://www.runoob.com.com'
sub_s = '.' # 代表任意字符,除了换行符
res = re.findall(sub_s, s)
print(res) # ['h', 't', 't', 'p', ':', '/', '/', 'w', 'w', 'w', '.', 'r', 'u', 'n', 'o', 'o', 'b', '.', 'c', 'o', 'm', '.', 'c', 'o', 'm']
sub_s = '\.'
res = re.findall(sub_s, s)
print(res) # ['.', '.', '.']
18.2.1.3 开始与结束字符
当以^开始时,要求一行字符串的开始位置匹配;当以$结束时,要求一行字符串的结束位置匹配。所以正则表达式 \w+@zhijieketang.com与 ^ \ w+@zhijieketang.com $ 是不同的
即:可以在正则表达式的开始处使用插入符号(^),表明匹配必须发生在被查找文本开始处。类似地,可以再正则表达式的末尾加上美元符号( $ ),表示该字符串必须以这个正则表达式的模式结束。可以同时使用^和$,表明整个字符串必须匹配该模式,也就是说,只匹配该字符串的某个子集是不够的。
^ 匹配字符串的开头
$ 匹配字符串的结尾
import re
email = r'koko@dlut.com'
m = re.search('dlut',email)
print(m) # <re.Match object; span=(5, 9), match='dlut'>
m = re.search('dlut$',email)
print(m) # None
m = re.search('^dlut','We know dlut is a school')
print(m) # None
m = re.search('^dlut$','dlut') # 整个字符串都要符合
print(m) # <re.Match object; span=(0, 4), match='dlut'>
import re
rule = 't*'
string = 'stt'
res = re.findall(rule,string,re.I)
print(res) # ['', 'tt', '']
res = re.fullmatch(rule,string,re.I) # 必须要全部符合,相当于 '^... $'
print(res) # None
18.2.2 字符类
正则表达式中可以使用字符类(Character class),一个字符类定义一组字符,其中的任一字符出现在输入字符串中即匹配成功。注意每次匹配只能匹配字符类中的一个字符。
18.2.2.1 定义字符类
定义一个普通的字符类需要使用” [ “和” ] “元字符类。
18.2.2.2 字符类取反
有时需要在正则表达式中指定不想出现的字符,可以在字符类前加“^”符号。
[…] 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’
[^…] 不在[]中的字符:[^abc] 匹配除了 a,b,c 之外的字符。
18.2.2.3 区间
区间是用连字符(-)表示的,[0123456789]采用区间表示为[0-9],[^ 0123456789]采用区间表示为[^0-9]。区间还可以表示连续的英文字母字符类,例如[a-z]表示所有小写字母字符类,[A-Z]表示所有大写字母字符类。
[A-Za-z0-9]表示所有因为字母和数值字符类,[0-25-7]表示0、1、2、5、6、7几个字符组成的字符类。
import re
m = re.search(r'[A-Za-z0-9]','A10.3')
print(m) # <re.Match object; span=(0, 1), match='A'>
m = re.search(r'[0-7308]','A3489C')
print(m) # <re.Match object; span=(1, 2), match='3'>
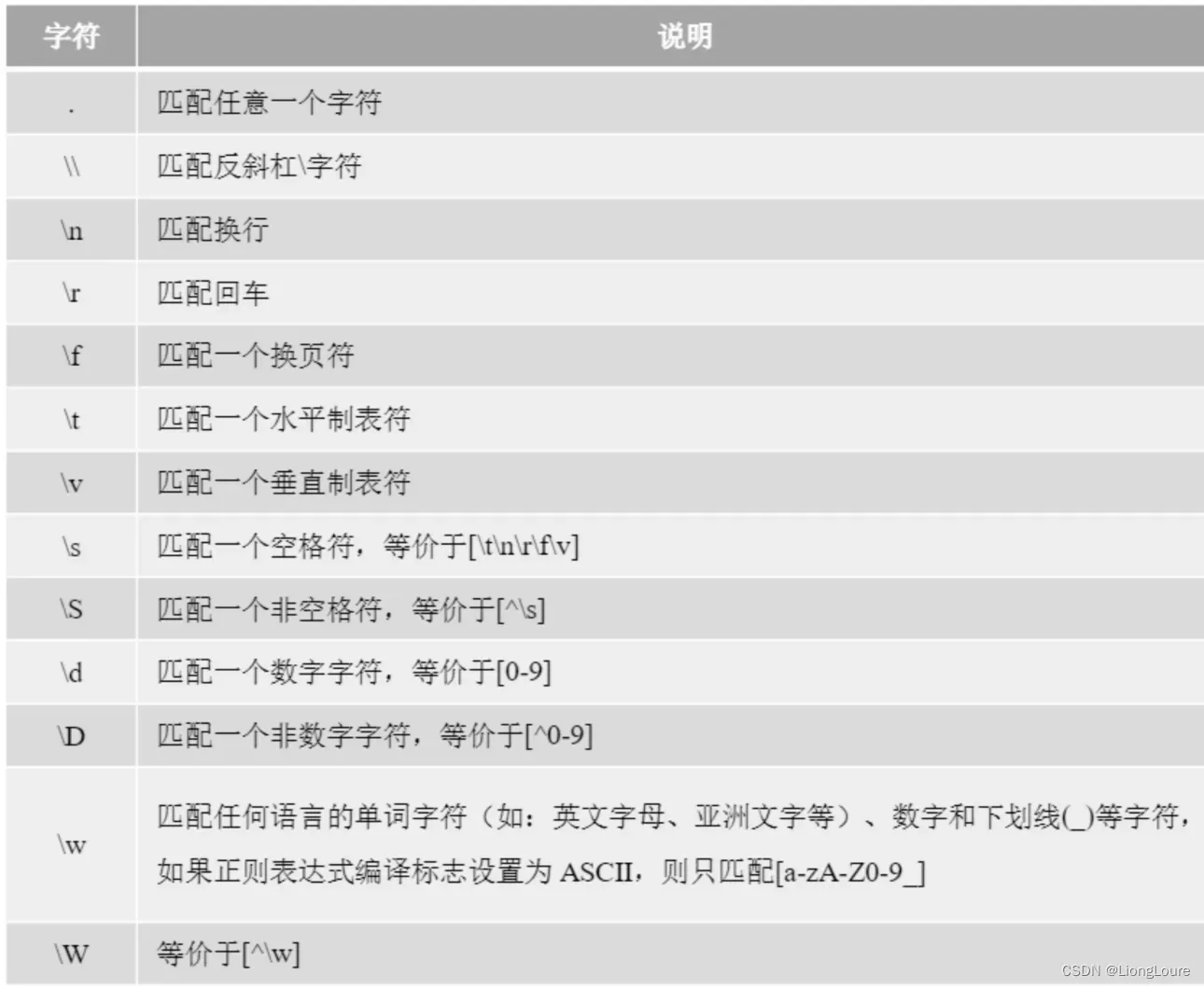
18.2.2.4 预定义字符类
有些字符类很常用,例如[0-9]等,为了书写方便正则表达式提供了预定义的字符类,例如预定义字符类\d等价于[0-9]字符类。
import re
p = r'\d' # [0-9]
m = re.search(p, '1000')
print(m) # <re.Match object; span=(0, 1), match='1'>
m = re.search(p, 'Pyhon 3')
print(m) # <re.Match object; span=(6, 7), match='3'>
m = re.search(p, 'A_你好Hello')
print(m) # None
p = r'\w' # 任意语言的单词字符 数字 下划线
m = re.search(p, ' A_你好Hello')
print(m) # <re.Match object; span=(0, 1), match='A'>
#与量词结合
p = r'\d+' # 任意语言的单词字符 数字 下划线
m = re.search(p, ' A_你好33Hello')
print(m) # <re.Match object; span=(5, 7), match='33'>
p = r'\d{1}' # 任意语言的单词字符 数字 下划线
m = re.search(p, ' A_你好33Hello')
print(m) # <re.Match object; span=(5, 6), match='3'>
18.3 量词
18.3.1 使用量词
量词是表示字符或者字符串重复的次数
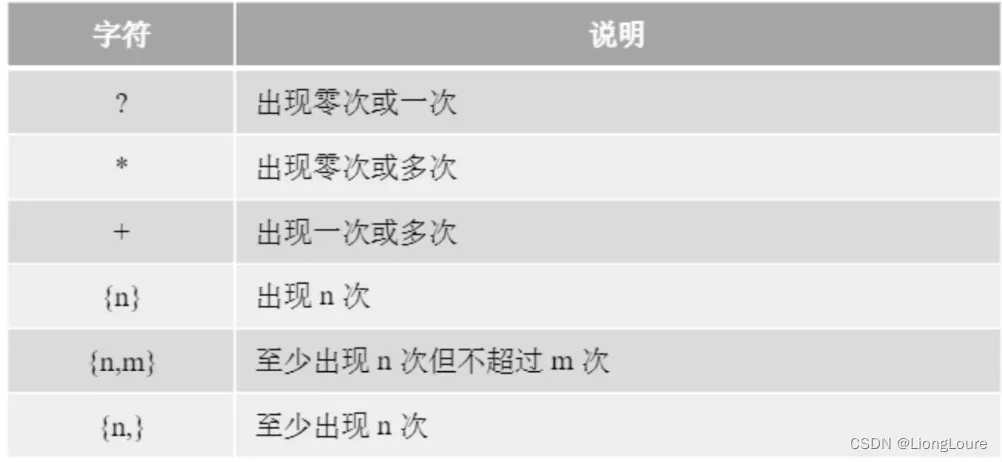
18.3.2 贪婪量词和懒惰量词
量词还可以细分为贪婪量词和懒惰量词,贪婪量词会尽可能多地匹配字符,懒惰量词会尽可能少地匹配字符。大多数计算机语言的正则表达式量词默认是贪婪的,要想使用懒惰量词(非贪婪量词)可以在量词后面加”?”即可
18.4 分组
在此之前学习量词只能重复显示一个字符,如果想让一个字符串作为整体使用量词,可将这个字符串放到一对小括号中,这就是分组(也称子表达式)。
18.4.1 使用分组
对正则表达式进行分组不仅可以对一个字符串整体使用量词,还可以在正则表达式中引用已经存在的分组。
(re) 对正则表达式分组并记住匹配的文本
import re
p = r'\w\d{2}' # [0-9]
m = re.search(p, 'F1000_光轮')
print(m) # <re.Match object; span=(0, 3), match='F10'>
p = r'(\w\d){2}' # [0-9]
m = re.search(p, 'F1000_光轮')
print(m) # <re.Match object; span=(0, 4), match='F100'>
p = r'(0){2}' # [0-9]
m = re.search(p, 'F1000_光轮')
print(m) # <re.Match object; span=(2, 4), match='00'>
18.4.2 命名分组
在 Python 程序中访问分组时,除了可以通过组编号进行访问,还可以通过组名进行访问,前提是要在正则表达式中为组命名。组命名语法是在分组的左小括号后添加 ?P<分组名> 实现。
import re
p = r'(\w+).*\1'
m = re.search(p, 'title>abc<title')
print(m) # <re.Match object; span=(0, 15), match='title>abc<title'>
p = r'(\w+)\d{3}\1'
m = re.search(p, 'title123title')
print(m) # <re.Match object; span=(0, 13), match='title123title'>
p = r'(\w+).*\1'
m = re.search(p, 'title>123<title')
print(m) # <re.Match object; span=(0, 13), match='title123title'>
m = re.search(p, 'aa>123<ab')
print(m) # <re.Match object; span=(0, 8), match='aa>123<a'>
#findall使用分组
#返回的结果为组内容,如果想要整个表达式的匹配字符串,需要非捕获分组
p = r'(\w\d)123'
m = re.search(p, 'aa1123<ab')
print(m) # <re.Match object; span=(1, 6), match='a1123'>
m = re.findall(p, 'aa1123<ab')
print(m) # ['a1']
p = r'(\w\d)(123)'
m = re.findall(p, 'aa1123<ab')
print(m) # [('a1', '123')]
p = r'(?:\w\d)(?:123)'
m = re.findall(p, 'aa1123<ab')
print(m) # ['a1123']
p = r'(\d{3,4})-(\d{7,8})'
m = re.search(p, '0411-84708110')
print(m.group(0)) # 0411-84708110
# 0 或者 空,表示获取匹配到的整个结果
print(m.group(1)) # 第一组 0411
print(m.group(2)) # 第二组 84708110
result = re.findall(r'(\w+)=(\d+)','set width=20 and height=10')
print(result) # ['width=20', 'height=10']
result = re.search(r'(?P<left>\w+)=(\1)','set width=width1 and height=height')
print(result) # <re.Match object; span=(4, 15), match='width=width'>
print(result.group('left')) # width
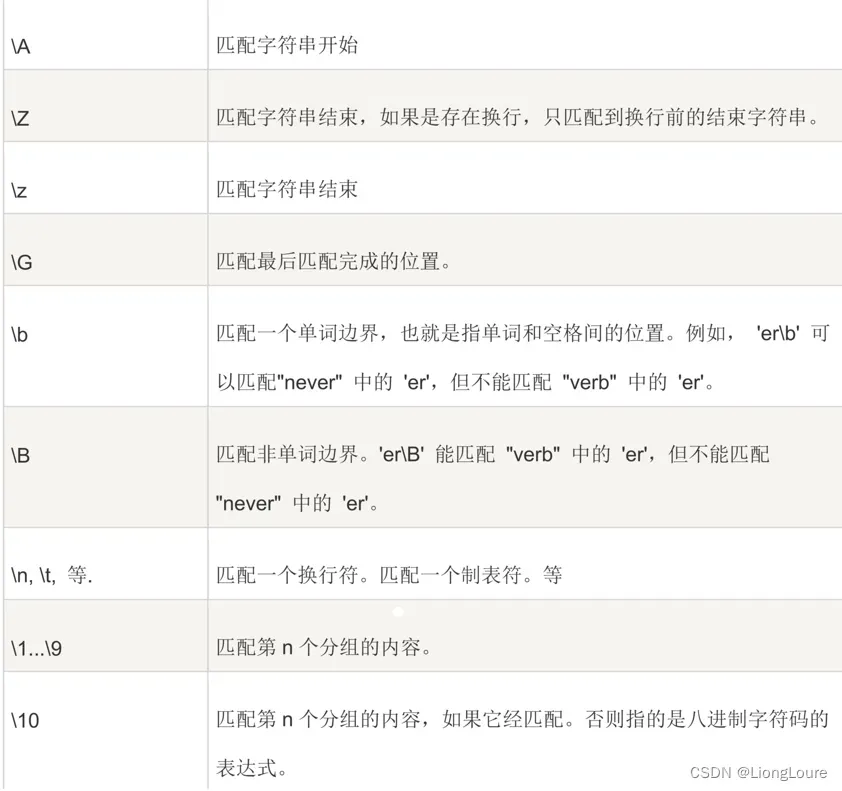
18.4.3 反向引用分组
除了可以在程序代码中访问正则表达式匹配之后的分组内容,还可以在正则表达式内部引用之前的分组。
\1…\9 匹配第 n 个分组的内容。
\10 匹配第 n 个分组的内容,如果它经匹配,否则指的是八进制字符码的表达式。
import re
result = re.findall(r'(\w+)=(\d+)','set width=20 and height=10')
print(result) # [('width', '20'), ('height', '10')]
result = re.findall(r'(?:\w+)=(?:\d+)','set width=20 and height=10')
print(result) # ['width=20', 'height=10']
result = re.findall(r'(\w+)=(\d+)','set width=20 and height=10')
print(result) # [('width', '20'), ('height', '10')]
result = re.findall(r'(\w+)=(\1)','set width=width1 and height=height')
print(result) # [('width', 'width'), ('height', 'height')]
'''
使用正则表达式将电话号码13811119999变成138****9999
'''
str1 = '13811119999'
p = r'(\d{3})(\d{4})(\d{3})'
print(re.sub(p,r'\1****\3',str1)) # 引用分组
18.4.4 非捕获分组
前面介绍的分组称为捕获分组,就是匹配子表达式结果被暂时保存到内存中,以备表达式或其他程序引用,这称之为”捕获”,捕获结果可以通过组编号或组名进行引用。但是有时并不想引用子表达式的匹配结果,不想捕获匹配结果,只是将小括号作为一个整体进行匹配,此时可以使用非捕获分组,非捕获分组在组开头使用”?∶”实现。
p = r'(\d{3,4})-(\d{7,8})'
m = re.findall(p, '0411-84708110')
print(m) # [('0411', '84708110')]
p = r'(?:\d{3,4})-(?:\d{7,8})'
m = re.findall(p, '0411-84708110')
print(m) # ['0411-84708110']
# print(m.group(1)) # baocuo
注意:作为 findall()方法的返回结果的总结,请记住下面两点:
- 如果调用在一个没有分组的正则表达式上,例如\d\d\d-\d\d\d-\d\d\d\d,方法 findall()将返回一个匹配字符串的列表,例如[‘415-555-9999’, ‘212-555-0000’]。
- 如果调用在一个有分组的正则表达式上,例如(\d\d\d)-(\d\d\d)-(\d\d\d\d),方法 findall()将
返回一个字符串的元组的列表(每个分组对应一个字符串),例如[(‘415’, ‘555’, ‘1122’), (‘212’,
‘555’, ‘0000’)]。
phoneNumRegex.findall(‘Cell: 415-555-9999 Work: 212-555-0000’)
18.5 模式汇总
中文正则模式[\u4E00-\u9FA5]
'''
使用正则表达式将字符串中的标点符号、数字和字母删除
string=”据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。”
'''
# string = '据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。'
# p = r'[,()、。0-9a-zA-Z]'
# print(re.sub(p, '', string))
string = '据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。'
p = r'[^\u4E00-\u9FA5]'
print(re.sub(p, '', string))
'''
判断以下字符是否全是中文(中文正则模式[\u4E00-\u9FA5])
str='广东省广州市'
'''
# p = r'^[\u4E00-\u9FA5]$'
# str='广东省广州市'
# print(re.findall(p, str))
string='广东省广州市'
pattern = r'[\u4E00-\u9FA5]'
sub_str = re.sub(pattern, '', string)
result = False
if not sub_str:
result = True
print('%s是否是中文的结果:%s'%(string, result))
18.6 编译正则表达式
但是为了提高效率,还可以对Python 正则表达式进行编译。编译的正则表达式可以重复使用,减少正则表达式解析和验证,提高效率。
在 re模块中的compile() 函数可以编译正则表达式,compile() 函数语法如下∶
re.compile(pattern[, flags=0])
18.6.1 已编译正则表达式对象
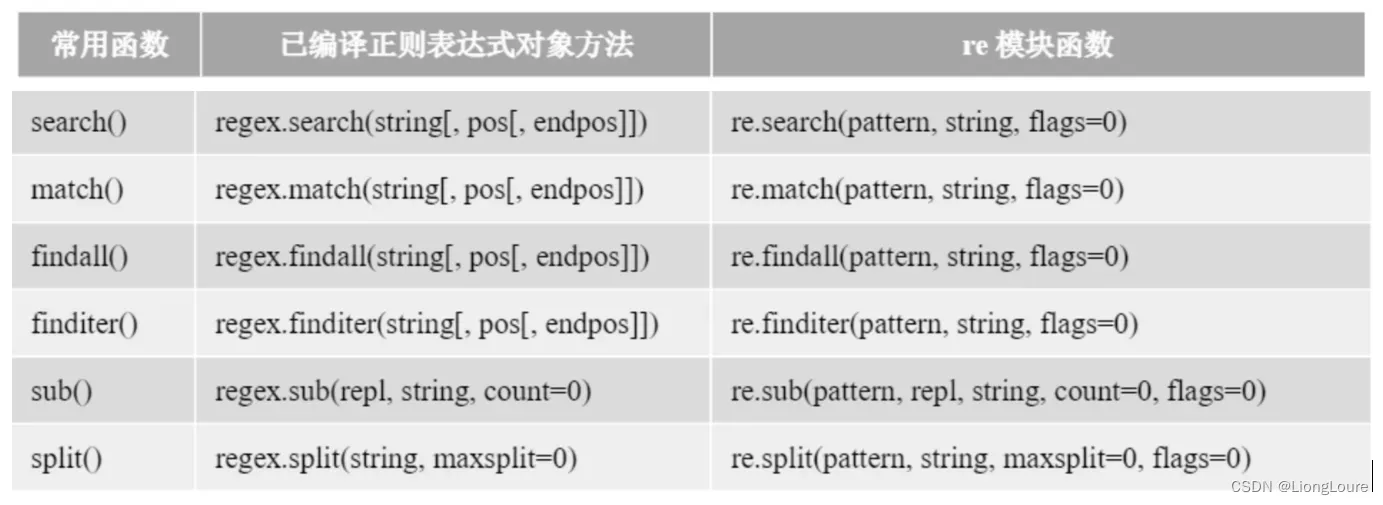
regex.sub
(function)
sub(pattern: str | Pattern[str], repl: str | ((Match[str]) -> str), string: str, count: int = …, flags: _FlagsType = …) -> str
返回通过替换 repl 替换字符串中最左侧的模式的非重叠实例而获得的字符串。repl 可以是字符串,也可以是可调用的;如果字符串,则处理其中的反斜杠转义。如果它是可调用的,则它传递 Match 对象,并且必须返回要使用的替换字符串。
import re
p = r'(\d{3,4})-(\d{7,8})'
m = '0411-84708110'
regx = re.compile(p) # 表达式重复编译的次数较多,可以提前编译成一个对象,再使用
regx.search(m)
result = re.findall(r'(\w+)=(\d+)','set width=20 and height=10')
print(result) # [('width', '20'), ('height', '10')]
result = re.findall(r'(?:\w+)=(?:\d+)','set width=20 and height=10')
print(result) # ['width=20', 'height=10']
18.6.2 编译标志
compile() 函数编译正则表达式对象时,还可以设置编译标志。编译标志可以改变正则表达式引擎行为。本节详细介绍几个常用的编译标志。
- ASCII和 Unicode
- 忽略大小写
- 点(.)元字符匹配换行符
- 多行模式
- 详细模式
文章出处登录后可见!