前言
《An Image is Worth 16×16 Words:Transformer for Image Recognition at Scale》
论文地址:https://arxiv.org/pdf/2010.11929.pdf
Transformer最开始是用于NLP的, Vision Transformer (ViT)借鉴该思路将其用在了视觉任务上。Transformer就不仔细介绍了,这里有一篇讲得非常好的博客The Illustrated Transformer。
Vision Transformer网络结构
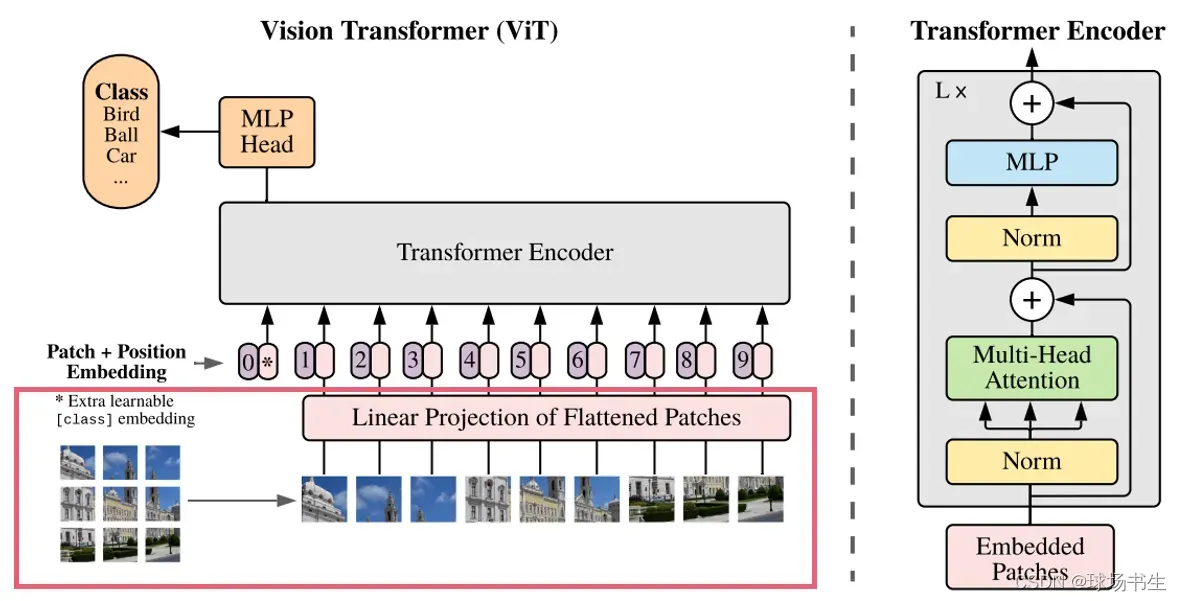
首先是把图片“裁剪”为16×16的patch,这样一张图就变成了sequence。然后将patch进行编码,再加入位置编码,最后送进网络。整个思路和Bert一致,不过还是有些不一样的需要注意下,下面就来讲解各个部分的细节。
Embeding层
上图中红框部分:
以ViT-B/16为例,图片需要分成16×16的,这里其实采用的是kernel size为16×16,步长为16的卷积核,一共768个(即输出通道数为728维),然后展平。维度变化如下所示:
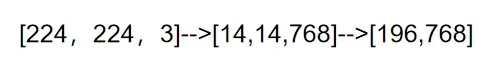
此外,还需要增加一个[class]token,这个是可学习的参数,拼接在一起:
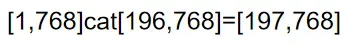
至于position embeding,与Bert有所不同。这里是在每个位置(0,1,2…)使用一个1D可学习的参数,与Words embeding进行相加。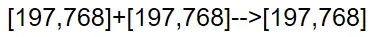
至于position embeding为什么这么做,作者的实验表明加入位置编码比没有加会好很多,但是加入后1D,2D,Rel并没有太大的差别,干脆就选个最简单的1D方式。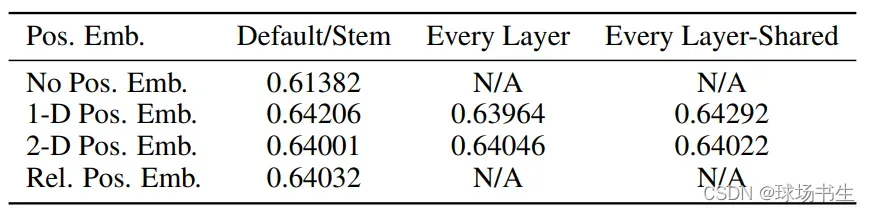
Encoder
Encoder其实就是重复堆叠Encoder Block L次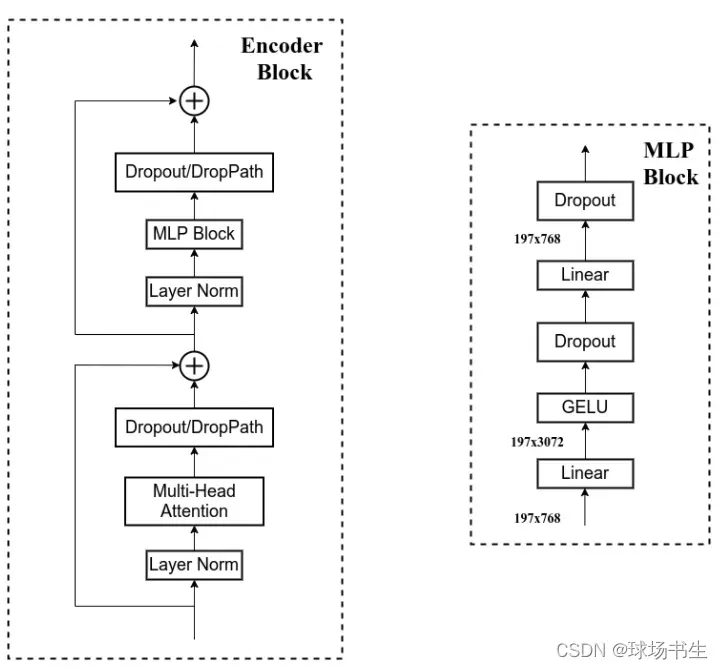
- LayerNorm:实际就是对隐含层做层归一化,即对某一层的所有神经元的输入进行归一化。(每hidden_size个数求平均/方差)
1、它在training和inference时没有区别,只需要对当前隐藏层计算mean and variance就行。不需要保存每层的moving average mean and variance。
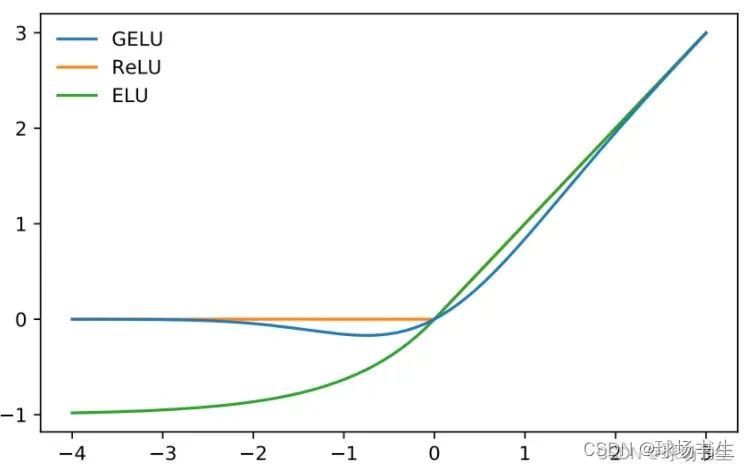
2、不受batch size的限制。 - 高斯误差线性单元GELU:该激活函数在NLP领域中被广泛应用,BERT、RoBERTa、ALBERT等模型都使用了这种激活函数。
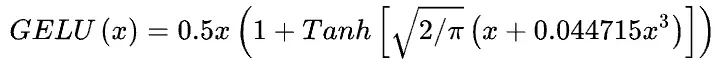
- Linear
第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
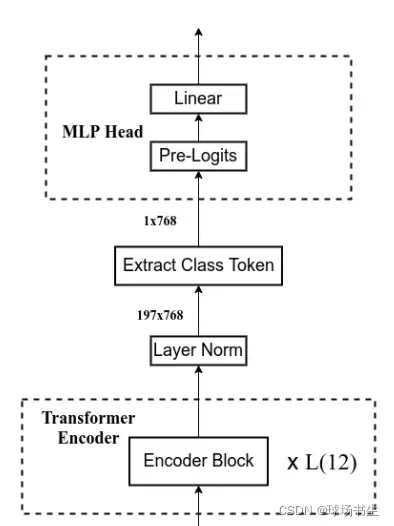
MLP Head
Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。最后Extract class token,取出第一个[1,768]用于进行训练分类器。原论文中说在ImageNet21K上预训练时MLP Head是由Linear+tanh激活函数+Linear组成。
Hybrid网络结构
Hybrid混合模型,就是将传统CNN特征提取和Transformer进行结合。ViT是通过卷积将图片类似分成16×16的patch得到Words,而混合模型是利用CNN网络来提取Words。比如利用Resnet50,把BatchNorm层替换成GroupNorm层(也有助于减少batch的影响),同时减少网络的stage使得达到
16的下采样比。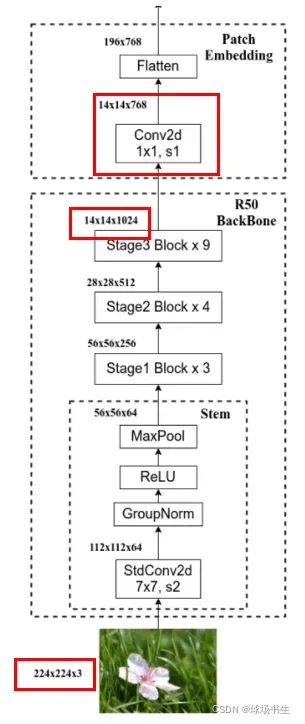
实验结果
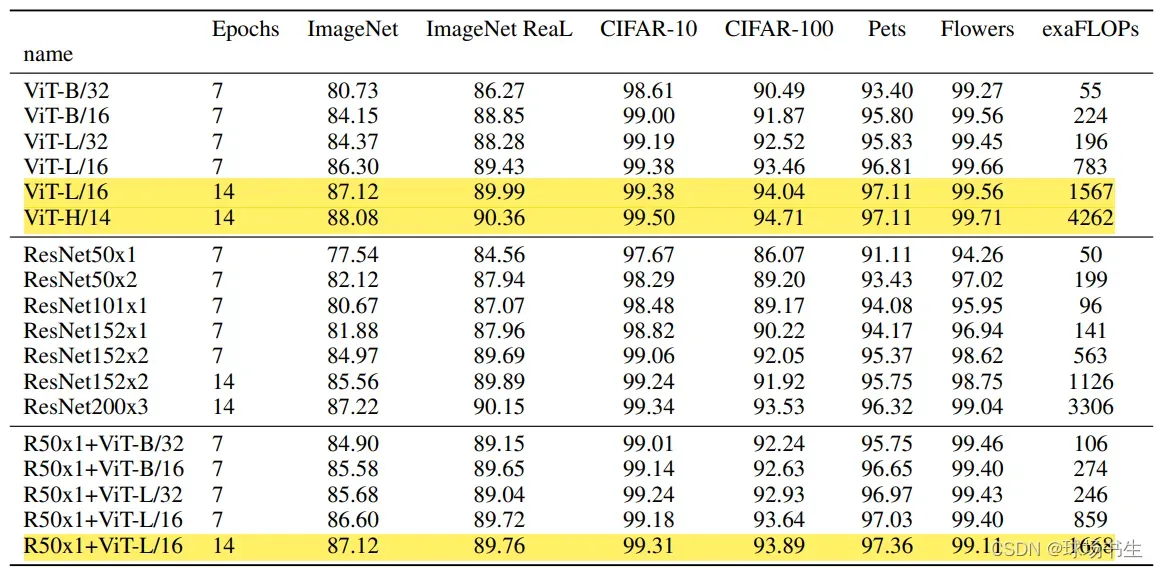
三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16×16的外还有32×32的:
图源:https://blog.csdn.net/qq_37541097/article/details/118242600
弱点和改进
ViT论文当中,训练的次数比较少的时候,混合模型的精度会更高一点,那随着迭代训练更多epoch数之后,ViT的精度就会慢慢超过混合模型。如下图所示: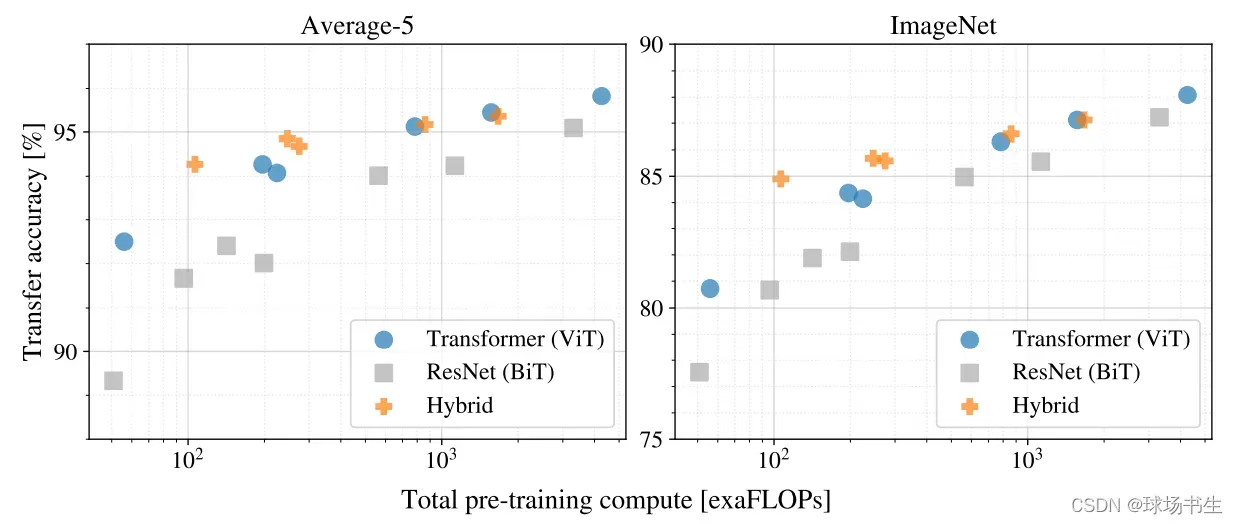
- 不足1
值得注意的一点是,ViT在大规模的数据集(JFT-300M)上进行预训练效果才更明显: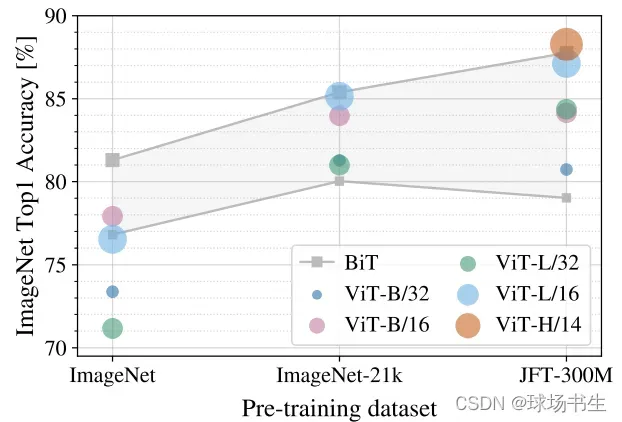
为了使得小规模的数据集上预训练的模型也能有较好的迁移能力,DeiT使用知识蒸馏来提升模型性能(其实作者还加了一些数据增强)。1)提出了基于token蒸馏的策略,这种针对transformer的蒸馏方法可以超越原始的蒸馏方法。
2)Deit发现使用Convnet作为教师网络能够比使用Transformer架构取得更好的效果。
论文:《Training data-efficient image transformers& distillation through attention》
论文地址:https://export.arxiv.org/pdf/2012.12877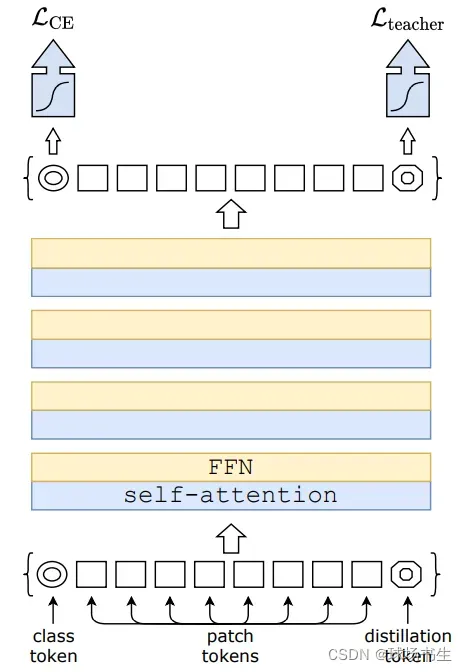
- 不足2
此外,ViT中提到像Bert那样去mask图片(用了50%patch和l2损失),从而进行self-supervision,但是发现实验结果不是特别好。不过,最近何凯明的MAE也是这个思路,但取得了良好的效果!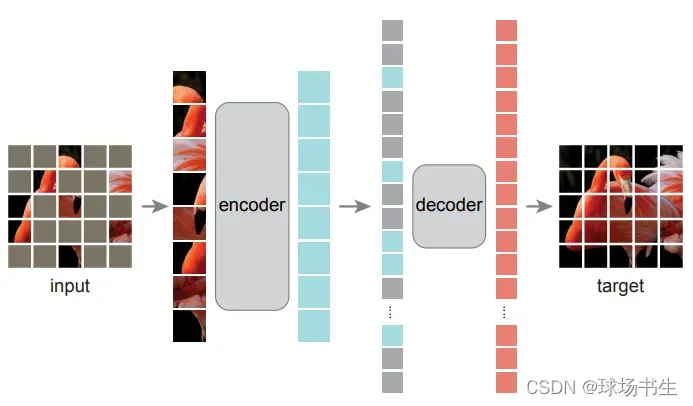
论文:《Masked Autoencoders Are Scalable Vision Learners》
论文地址:https://arxiv.org/pdf/2111.06377.pdf
上一篇:CNN卷积神经网络之EfficientNet V2
版权声明:本文为博主球场书生原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_41917697/article/details/122813924