ConVIRT论文详解(医疗图片) – 潘登同学的深度学习笔记
前言
ConVIRT全称是(contrastive learning of medical visual representations from paired images and text),也是对比学习的一篇工作,但是结合了多模态;是在CLIP之前的工作了;
- 学习医学图像的视觉表示是医学图像的核心了解,但它的进展一直受到手工标签的小尺寸数据集的阻碍;
- 现有工作通常依赖于从 ImageNet 预训练的模型,由于图像特征完全不同,表现并不好;
- 或从与医疗配对的文本报告数据中提取基于规则的标签图像,标签不准确且难以概括;
医学领域打标签的方式
- 请专家打高质量的标签,这样就导致数量很少;
- 使用某种规则从报告中提取标签,在医疗系统里面有很多这样的文本图像对;
- 但是提取规则通常不好用,有时候很难提取出某些标签;
- 因为每个医生的写作方式不同,这种规则也很难跨医院进行使用;
整体架构
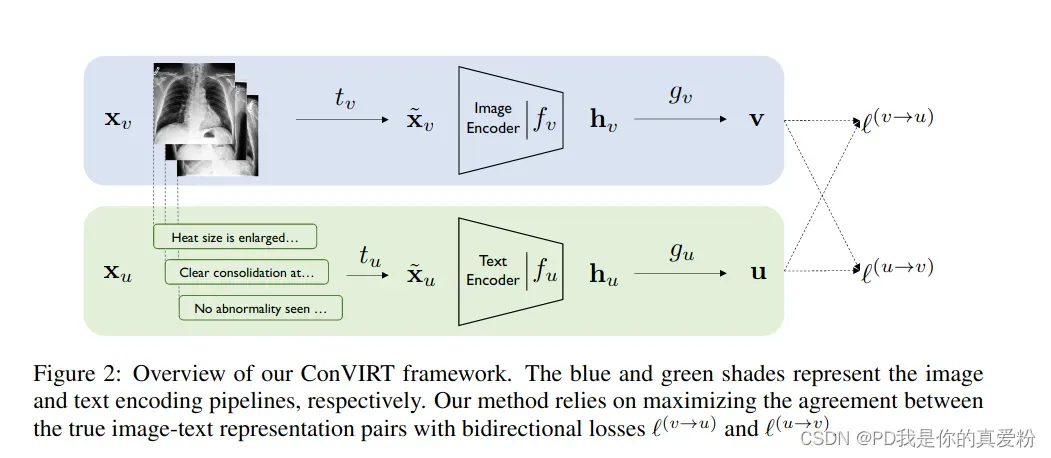
- 一张图片先做随机裁剪,再接一个数据增强,然后进入Image Encoder(ResNet50),最后接一个MLP得到512维的特征表示;
- 与这张图片配对的一段话,随机采样其中一部分(几句话,或者不完整的几句),然后进入text Encoder(Bert),最后接一个MLP得到512维的特征表示;
- 因为一个batch中有N个图片文本对,所以可以理解为有N-1个负例,只有一个正例,然后分别对图片和文本计算infoNCE loss;

数据集
- 公共 MIMIC-CXR 数据库的第 2 版,这是一组胸部 X 光片图像与其文本报告配对,并且由于它的发布已成为研究医学图像多模态建模的标准资源。预处理后,该数据集共包含约 217k 图像-文本对,每对平均包含 1.7 张图片和 6.0 个句子;
- 骨骼图像:从罗德岛医院系统获得一组肌肉骨骼图像-文本对。 继胸部图像之后,肌肉骨骼图像构成典型医院中第二常见的放射线图像类型。 该数据集总共包含 48k 图像-文本对,每对平均包含 2.5 个图像和 8.0 个句子。
实验
分类任务
- RSNA Pneumonia Detection: 是否肺炎的二分类任务;
- CheXpert image classification: 对肺部的多标签分类任务;
- COVIDx image classificatio: 是否新冠肺炎,普通肺炎,正常的三分类任务;
- MURA bony abnormality detection: 判断骨骼肌肉是否正常的二分类任务;
两种方式: linear probe只训练分类头,fine-tuning
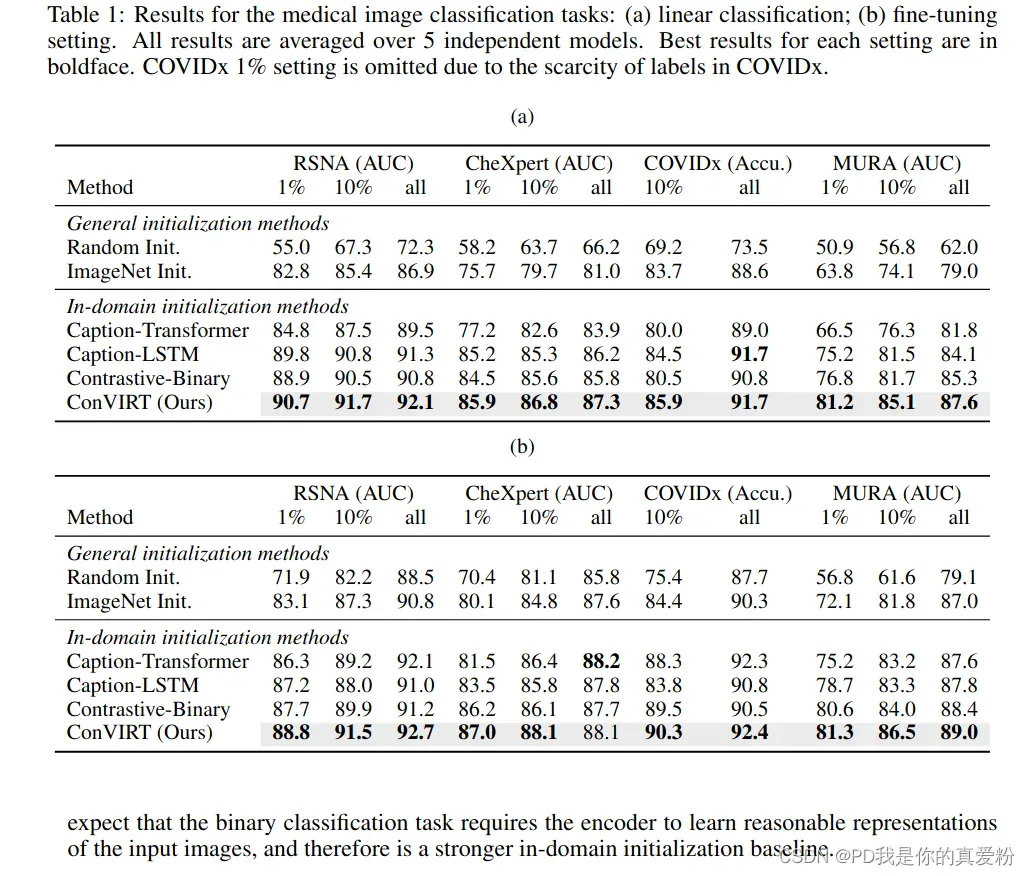
- 从上到下依次是:
- 随机初始化;
- ResNet50在ImageNet上预训练的;
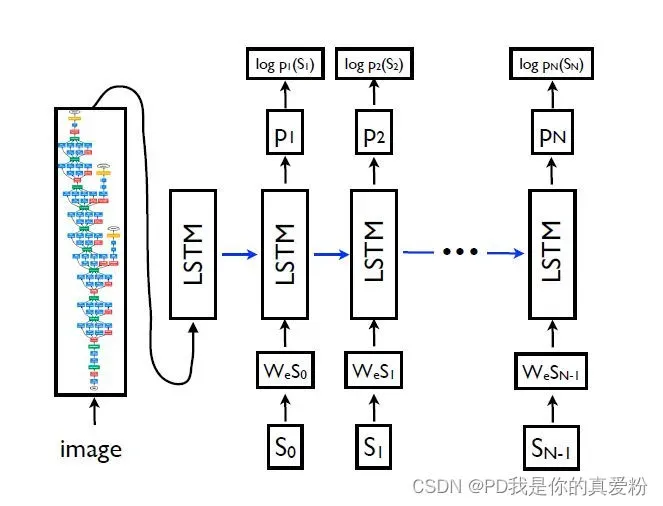
- Caption-LSTM是看图说话的一个网络(在下图中显示其架构);
- Caption-Transformer与上一个一样,但是用Transformer取代了LSTM(是COCO image captioning benchmar);
- Contrastive-Binary也是对比学习的一个网络,就是将一组配对输入,判断其是否属于一对,来当作预训练任务;
- 因为COVIDx的数据没那么多,所以没有做1%层面上的测试;
下图是特征空间的可视化,左边是在ImageNet上预训练的,右图是ConVIRT

Zero-shot任务
像CLIP一样,多模态最强的还是Zero-shot,不需要微调,通过图片的提示进行分类;
Zero-shot任务
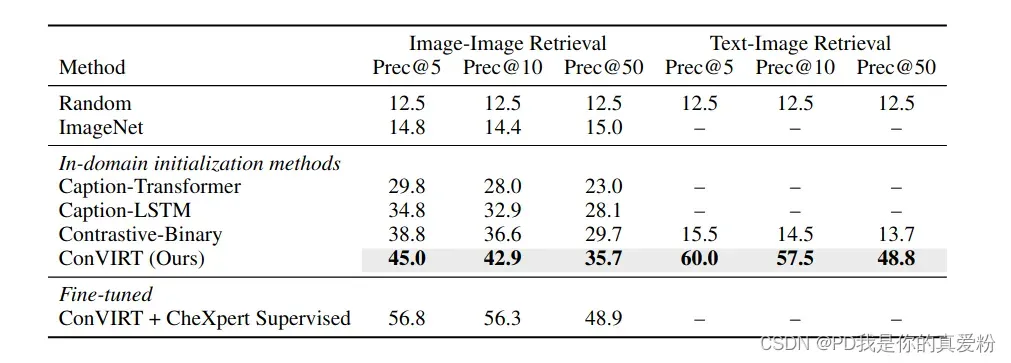
- Image-Image: 将所有图片传入Image-Encoder,与所有求相似,聚为一堆;(一张图片做query去与其他所有图片求相似度,就是对比学习特征空间的相似度问题)
- 还是CheXpert数据集,但这个数据集不是一个多标签分类任务嘛,作者将只有一个标签的那些图片抽出来当作query(经过专家处理筛选之后,每个类别留了10张);
- 用这些query去与其他求相似度,得到结果,如果那个图片也有query这个标签就是正例,否则就是负例;
- Text-image: 叫专家写了CheXpert中每个标签的症状(写了5份),然后进入text Encoder,与所有进入Image-Encoder的特征求相似(当然这些特征都要过MLP层);判别正负例的方法与上面的一样;
超参设置
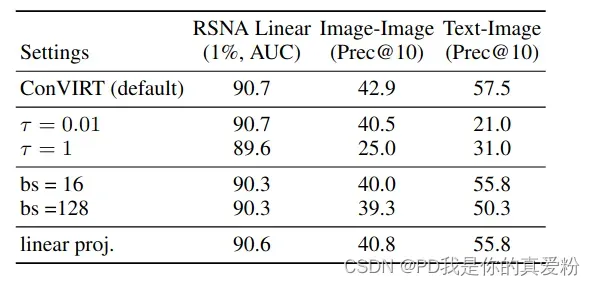
- 大的batch反而不利于Image-Image和Text-Image,因为有可能本身那些负例就是潜在的正例;
- 将最后的MLP去掉激活函数,对Image-Image和Text-Image的表现都有所下降;
- 上述的两个问题不影响分类;
与对比学习的其他模型进行比较,但是因为SimCLR与MoCo都是图片自己的对比,所以只能比较Image-Image
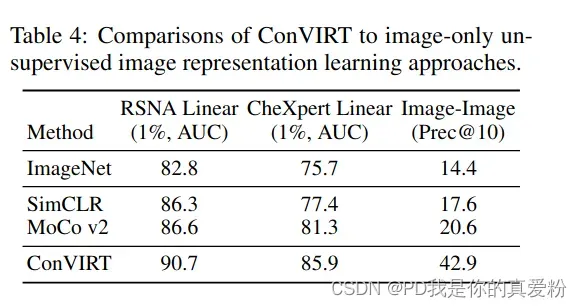
- 都是用MIMIC-CXR数据集,SimCLR都没用v2版本,自然比不过,但是MoCo v2明明用了更大更一致的字典,为什么还是比不过;
- 我认为有几个原因:超参没调好(因为是直接搬过来的),用了文本的数据更能提高模型的学习效率,提供模型的准确度;
文章出处登录后可见!
已经登录?立即刷新