
目录
- 深度学习的基本概念
- 张量的基本概念
- 张量的基础操作
- 张量与存储
- 尺寸、存储偏移与步长
- 克隆操作
- 转置操作
- contiguous方法
- 每文一语

深度学习的基本概念
深度学习是一种人工神经网络的学习方法。它通过模仿人脑的学习方式来处理信息。深度学习的网络有很多层,每层都能学习到更抽象的概念。这种方法在语音识别、计算机视觉、自然语言处理等领域有很好的应用。
深度学习也有许多应用,这些应用往往包括以某种形式获取数据(例如图像或文本),并以另一种形式生成数据(例如标签,数字或更多文本)。
从这个角度来看,深度学习包括构建一个将数据从一种表示转换为另一种表示的系统。这种转换是通过从一系列样本中提取的共性来驱动的,这些共性能够反映期望的映射关系。
这个过程的第一步是将输入转换为浮点数,因为网络使用浮点数来处理信息,所以我们需要对真实世界的数据进行编码,使其成为网络可理解的形式,然后再将输出解码回我们可以理解并用于某种用途的形式。
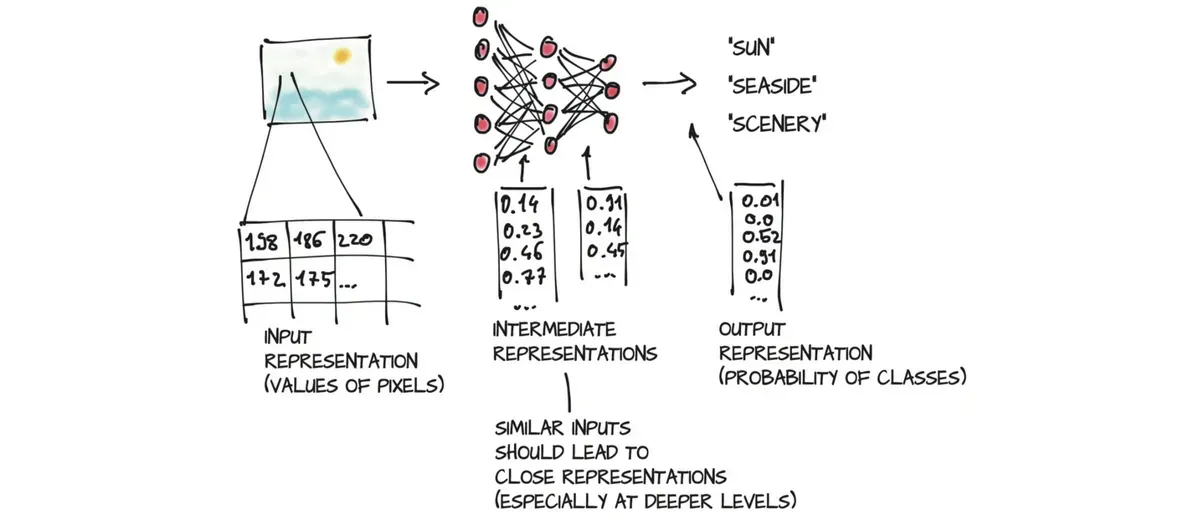
从一种数据形式到另一种数据形式的转换通常是由深度神经网络分层次学习的,这意味着我们可以将层次之间转换得到的数据视为一系列中间表示(intermediate representation)。以图像识别为例,浅层的表示可以是特征(例如边缘检测)或纹理(例如毛发),较深层次的表征可以捕获更复杂的结构(例如耳朵、鼻子或眼睛)。
通常,这种中间表示形式是浮点数的集合,这些浮点数表征输入并捕获数据中的结构,从而有助于描述输入如何映射到神经网络的输出。这些浮点数的集合及其操作是现代AI的核心。
这些中间表示(例如上图中的第二步所示)是将输入与前一层神经元权重相结合的结果,每个中间表示对于之前的输入都是唯一的。
在开始将数据转换为浮点输入之前,我们必须对PyTorch如何处理和存储数据(输入、中间表示以及输出)有深刻的了解,由此就引出了Pytorch中的数据结构——tensor(张量)的概念
张量的基本概念
Pytorch 中的张量是一种多维数组,与 Numpy 数组类似。张量在 PyTorch 中是一种基本的数学概念,可以代表标量、向量和矩阵。
张量的优点:
- 支持 GPU 计算,可以加速模型的训练过程。
- 易于使用和扩展,Pytorch 提供了丰富的 API 和工具,方便开发人员创建和使用神经网络模型。
- 提供自动求导功能,可以方便地计算反向传播。
PyTorch 应用场景主要是深度学习,可以用于图像分类、语音识别、自然语言处理等多领域的任务。
对于来自数学、物理学或工程学的人来说,张量一词是与空间、参考系以及它们之间的转换的概念是捆绑在一起的。对于其他人来说,张量是指将向量(vector)和矩阵(matrix)推广到任意维度,如图下图所示。与张量相同概念的另一个名称是多维数组(multidimensional array)。
张量的维数与用来索引张量中某个标量值的索引数一致。
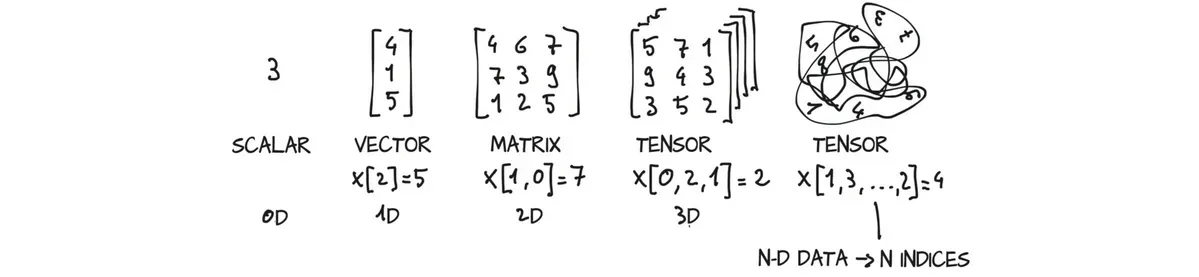
例如:一个二维张量,其中包含四个数字,可以用两个索引(行和列)来索引其中的某个标量值。因此,这个二维张量的维数与用于索引其中某个标量值的索引数相同,即两者都是2维。
与NumPy数组相比,PyTorch的张量具有一些更强大功能,例如能够在GPU进行快速运算、在多个设备或机器上进行分布式操作以及跟踪所创建的计算图。所有这些功能对于实现现代深度学习库都很重要。
张量的基础操作
张量是一个数组,即一种存储数字集合的数据结构,这些数字可通过索引单独访问,也可通过多个索引进行索引。这和我们python里面的numpy差不多的,多维数组如何索引,以及相关的概念,如果拥有线性代数的基础,你可以知道什么叫做矩阵,以及这一系列的相关操作,就可以理解这些概念。
import torch
a = torch.ones(3,device='cuda')
print(a)
print(a[1])
print(float(a[1]))
a[2] = 2.0
print(a)
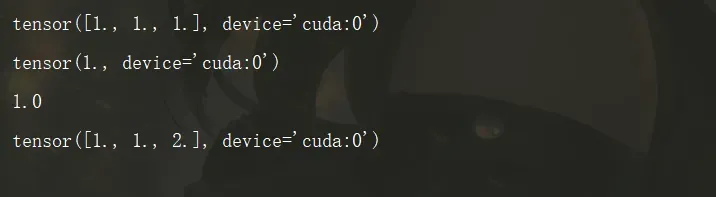
导入torch模块后,我们调用了一个函数,该函数创建了大小为3的(一维)张量,并填充值为1.0。你可以使用从0开始的索引来访问元素,也可以为其分配新的值。
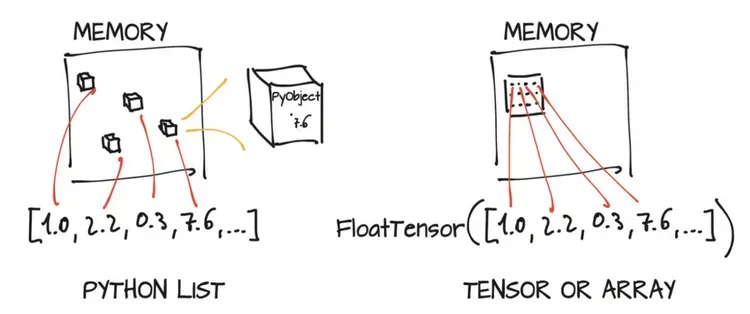
尽管从表面上看,此示例与Python列表并没有太大区别,但实际上情况完全不同。Python列表或数字元组(tuple)是在内存中单独分配的Python对象的集合,如下图左侧所示。然而,PyTorch张量或NumPy数组(通常)是连续内存块上的视图(view),这些内存块存有未封装(unboxed)的C数值类型,在本例中,如下图右侧所示,就是32位的浮点数(4字节),而不是Python对象。因此,包含100万个浮点数的一维张量需要400万个连续字节存储空间,再加上存放元数据(尺寸、数据类型等)的少量开销。
# 使用.zeros是获取适当大小的数组的一种方法
points = torch.zeros(6)
print(points)
# 用所需的值覆盖这些0
points[0] = 1.0
points[1] = 4.0
points[2] = 2.0
points[3] = 1.0
points[4] = 3.0
points[5] = 5.0
print(points)
points = torch.tensor([1.0, 4.0, 2.0, 1.0, 3.0, 5.0])
print(points)
# 获取第一个点的坐标
print(float(points[0]), float(points[1]))
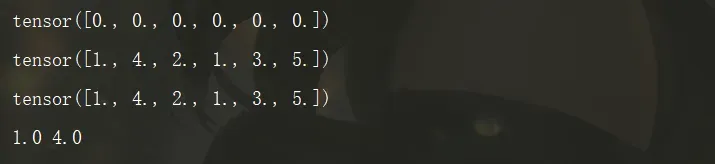
# 创建一个5乘5的张量
point=torch.ones(5,5)
print(point.shape)#获取其维度大小
point[0][0]=2.0
# 使用索引来访问张量
print(point[0][0])#获取第一行第一列的元素

points = torch.FloatTensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
points
>>>
tensor([[1., 4.],
[2., 1.],
[3., 5.]])
points[0, 1]
>>>
tensor(4.)
points[0]
>>>
tensor([1., 4.])
请注意,输出结果是另一个张量,它是大小为2的一维张量,包含了points的第一行中的值。上述输出是否将值复制到了新分配的内存块并将新的内存封装在新的张量对象中?答案是不,因为这样效率不高,尤其是如果有数百万个点数据。与之相反,上述输出是相同数据块的仅限于第一行的视图(view)。
张量与存储
数值分配在连续的内存块中,由torch.Storage实例管理。存储(Storage)是一个一维的数值数据数组,例如一块包含了指定类型(可能是float或int32)数字的连续内存块。PyTorch的张量(Tensor)就是这种存储(Storage)的视图(view),我们可以使用偏移量和每一维的跨度索引到该存储中。
多个张量可以索引同一存储,即使它们的索引方式可能不同,如图所示。 实际上,当你在上节最后一个代码片段中获取points[0]时,你得到的是另一个张量,该张量与points索引相同的存储,只是不是索引该存储的全部并且具有不同的维数(一维与二维)。由于基础内存仅分配一次,所以无论Storage实例管理的数据大小如何,都可以快速地在该数据上创建不同的张量视图。
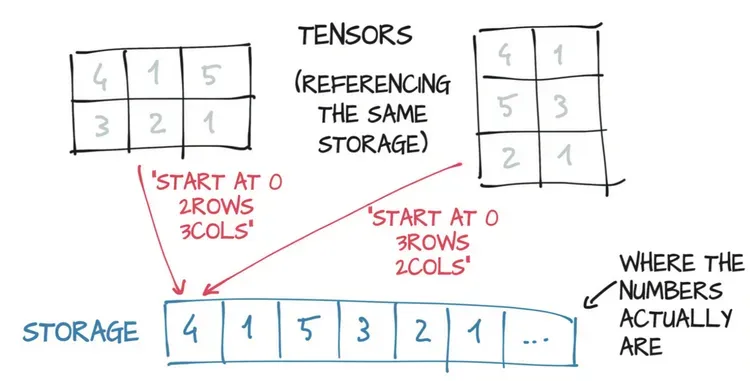
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
print(points.storage())
points_storage = points.storage()
print(points_storage[0])
print(points.storage()[1])
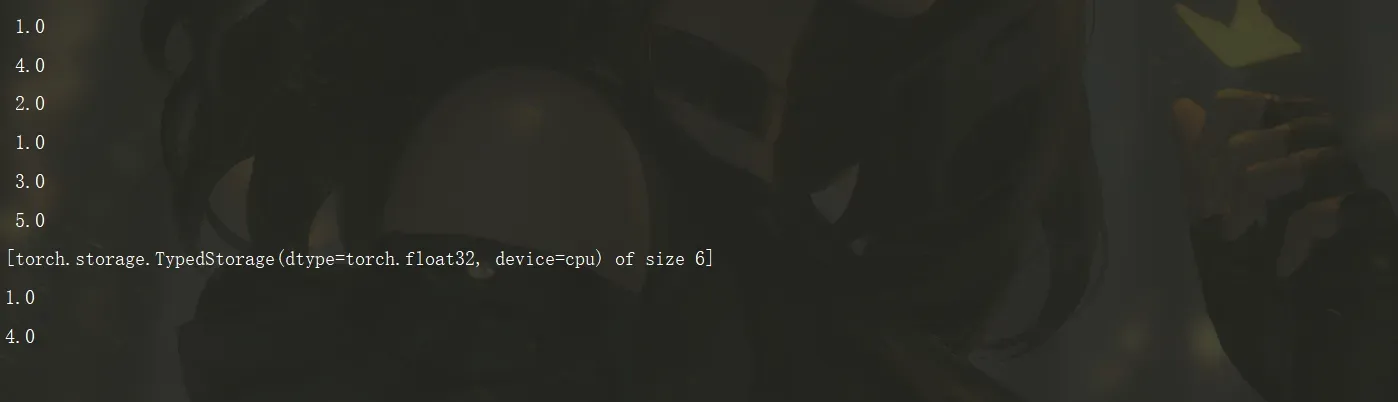
无法使用两个索引来索引二维张量的存储,因为存储始终是一维的,与引用它的任何张量的维数无关。
因此,更改存储的值当然也会更改引用它的张量的内容:
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
points_storage = points.storage()
points_storage[0] = 100.0#重新赋值
print(points)

尺寸、存储偏移与步长
除了存放存储外,为了索引存储,张量依赖于几条明确定义它们的信息:尺寸(size)、存储偏移(storage offset)和步长(stride)。
尺寸(或按照NumPy中的说法:形状shape)是一个元组,表示张量每个维度上有多少个元素。
存储偏移是存储中与张量中的第一个元素相对应的索引。
步长是在存储中为了沿每个维度获取下一个元素而需要跳过的元素数量。
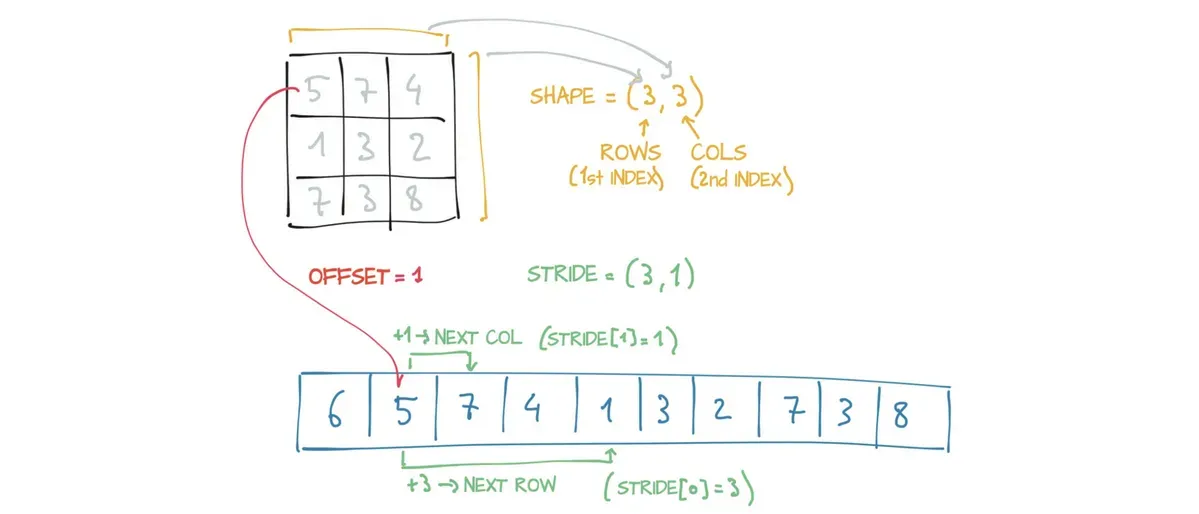
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
second_point = points[2]
print(second_point.storage_offset())#输出4
为什么是4,因为我们获取的是二维数组里面的第二个元素[3.0,5.0],然后对于3.0在存储在存储中的对应索引就是4
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
print(points)
second_point = points[2]
print(second_point.storage_offset())#输出4
print(second_point)
print(points.size())
print(second_point.size())#这里打印为:2,不要理解为2行。
# second_point是一个一维的数组,里面涵盖的是2个元素,
# 相对于我们的points里面也存在3个元素,但是每一个元素里面又包含2个元素
张量尺寸信息与张量对象的shape属性中包含的信息相同
步长是一个元组,表示当索引在每个维度上增加1时必须跳过的存储中元素的数量。例如,上例
points张量的步长:(2, 1)
用下标i和j访问二维张量等价于访问存储中的storage_offset + stride[0] * i + stride[1] * j元素。偏移通常为零,但如果此张量是一个可容纳更大张量的存储的视图,则偏移可能为正值。
张量Tensor和和存储Storage之间的这种间接操作会使某些操作(例如转置或提取子张量)的代价很小,因为它们不会导致内存重新分配;相反,它们(仅仅)分配一个新的张量对象,该对象具有不同的尺寸、存储偏移或步长。
刚刚我们已经看到了通过索引特定点来提取子张量,并且也看到了存储偏移增加了。现在来看看尺寸和步长发生了什么:
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
second_point = points[1]
print(second_point.size())
print(second_point.storage_offset())
print(second_point.stride())

结果是,子张量减少了一个维度(正如我们期望的那样),同时索引的是与原始点张量相同的存储。
这里我们捋一捋到底这个stride()是如何计算出来的。根据最原始的定义:步长是在存储中为了沿每个维度获取下一个元素而需要跳过的元素数量
官方文档是这样描述的:stride是在指定维度dim中从一个元素跳到下一个元素所必需的步长。当没有参数传入时,返回所有步长的元组。否则,将返回一个整数值作为特定维度dim中的步长。
>>> b
tensor([[0, 1, 2],
[3, 9, 5]])
>>> b.stride()
(3, 1)
>>> b.stride(0)
3
>>> b.stride(1)
1
上面的3指的是第0个维度中的一个元素[0, 1, 2]到下一个元素[3, 9, 5]所需要的步长为3,也可以理解从第一个的第一个索引到下一个元素第一个索引跨度是3。而1指的是第1个维度[0, 1, 2]中的一个元素0到下一个元素1所需要的步长为1。
更改子张量同时也会对原始张量产生影响:
我们知道当我们用索引修改张量的某一个固定的值的时候,我们不想让这些都发生改变,这个时候我们就可以选择克隆其张量。
克隆操作
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
second_point = points[1]
second_point[0] = 10.0
points
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
second_point = points[1].clone()#克隆方法
second_point[0] = 10.0
points
转置操作
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
print(points)
points_t = points.t()
print(points_t)
# 验证两个张量共享同一存储:
print(id(points.storage()) == id(points_t.storage()))
# 它们的仅仅是尺寸和步长不同
print(points.stride())
# 与,4之间的差距为1,与2之间的差距为2,这一切都是在存储的索引上解释的,也就是说还没有发生转置的时候
print(points_t.stride())
print(points_t.storage())#虽然转置,但是存储的顺序没有改变

上述结果告诉我们,在points中将第一个索引增加1(即,从points[0,0]到points[1,0])会沿着存储跳过两个元素,将第二个索引从points[0,0]到点points[0,1]会沿存储跳过一个元素。
换句话说,存储将points张量中的元素逐行保存着。
你可以按照图那样将points转置为points_t。你更改了步长中元素的顺序。这样一来,增加行(张量的第一个索引)就会沿着存储跳过1个元素,就像points沿着列移动一样,这就是转置的定义。(这个过程)没有分配新的内存:仅通过创建一个步长顺序与原始张量不同的新的张量实例来实现转置。
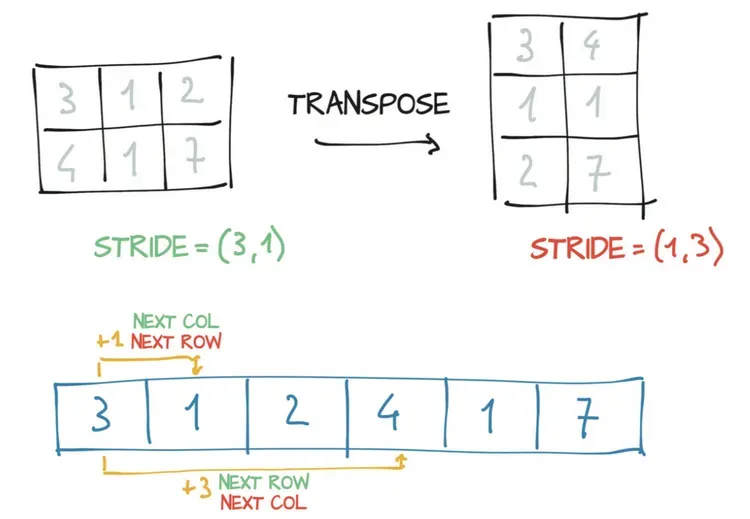
在PyTorch中进行转置不仅限于矩阵(即二维数组)。以翻转三维数组的步长和尺寸为例,你可以通过指定应需要转置的两个维度来转置多维数组:
some_tensor = torch.ones(3, 4, 5)
print(some_tensor)
a =some_tensor.shape, some_tensor.stride()
print(a)
some_tensor_t = some_tensor.transpose(0, 2)
print(some_tensor_t)
b =some_tensor_t.shape, some_tensor_t.stride()
print(b)
import torch
a=torch.Tensor([[[1,2,3],[2,3,4]],[[3,4,5],[4,5,6]]])
b=a.transpose(1,2)
c=a.transpose(2,1)
print(a.shape)
print(b.shape)
print(c.shape)
print(a)
print(b)
print(c)
输出:
torch.Size([2, 2, 3])
torch.Size([2, 3, 2])
torch.Size([2, 3, 2])
tensor([[[1., 2., 3.],
[2., 3., 4.]],
[[3., 4., 5.],
[4., 5., 6.]]])
tensor([[[1., 2.],
[2., 3.],
[3., 4.]],
[[3., 4.],
[4., 5.],
[5., 6.]]])
tensor([[[1., 2.],
[2., 3.],
[3., 4.]],
[[3., 4.],
[4., 5.],
[5., 6.]]])
如果不是很理解这个,transpose(,2)和transpose(2,1)都是差不多的,互换维度,这里的互换维度到底是什么意思。举一个简单的例子:
x = torch.randn(2, 3)
>>> x
tensor([[ 1.0028, -0.9893, 0.5809],
[-0.1669, 0.7299, 0.4942]])
>>> torch.transpose(x, 0, 1)
tensor([[ 1.0028, -0.1669],
[-0.9893, 0.7299],
[ 0.5809, 0.4942]])
最开始的张量我们可以看到它是一个,一个数组里面包含2个数组,而这个单独的2个数组里面又包含3个蛋到户的数,那么现在互换维度就是,原来的一个大数组里面包含3个数组,这三个单独的数组里面又包含2个数。
contiguous方法
从最右边的维开始将其值存放在存储中的张量(例如沿着行存放在存储中的二维张量)定义为连续(Contiguous)张量。连续张量很方便,因为你可以高效且有序地访问它们的元素而不是在存储中四处跳跃访问。
(由于现代CPU中内存访问的工作原理,改善数据局部性可提高性能。即连续张量满足局部性原理)
contiguous方法从非连续张量获得新的连续张量。 张量的内容保持不变,但步长发生变化,存储也是如此:
points.is_contiguous(), points_t.is_contiguous()
(True, False)
你可以使用contiguous方法从非连续张量获得新的连续张量。
张量的内容保持不变,但步长发生变化
存储也是如此:
points = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 5.0]])
points_t = points.t()
points_t
tensor([[1., 2., 3.],
[4., 1., 5.]])
points_t.storage()
1.0
4.0
2.0
1.0
3.0
5.0
[torch.FloatStorage of size 6]
points_t.stride()
(1, 2)
改变情况
内容保持不变,但是步长和存储发生改变
points_t_cont = points_t.contiguous()
points_t_cont
tensor([[1., 2., 3.],
[4., 1., 5.]])
points_t_cont.stride()
(3, 1)
points_t_cont.storage()
1.0
2.0
3.0
4.0
1.0
5.0
[torch.FloatStorage of size 6]
新的存储对元素进行了重组以便逐行存放张量元素。步长也已改变以反映新的布局

每文一语
也许时间会冲淡一切,但记住那些美好才能砥砺前行
文章出处登录后可见!