目录
一.引言
上篇 Word2vec 的文章中指出每次计算词库 N 个单词的 Softmax 计算量很大,可以通过负采样和层次 Softmax 进行计算优化,其中层次 Softmax 中用到了 Huffman Tree,下面简单介绍下霍夫曼树以及其 python 代码实现。
二.Huffman Tree 理论
1.定义
给定 N 个带权对象作为 N 个叶子节点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为霍夫曼树(Huffman Tree)。霍夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
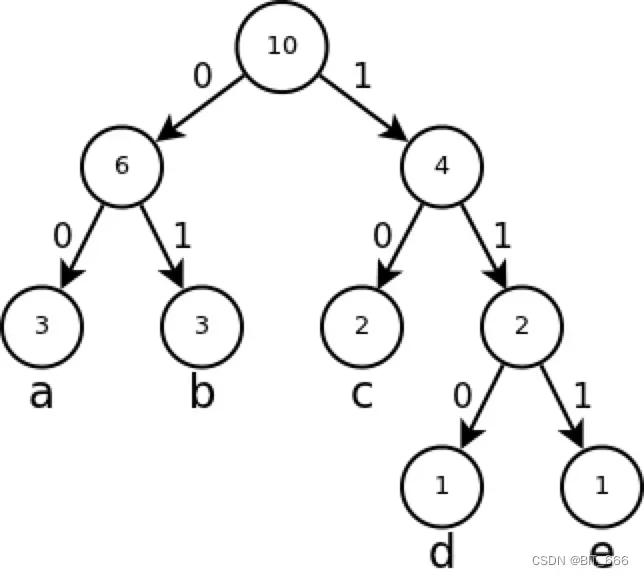
2.结构
霍夫曼树也可以简称最优树,根据定义我们可以得到几个关键词:
– 路径
路径即树中节点到另一个节点所经历的树分支,称为节点路径。如上图所示,我们将每个节点的左右分支分别标识为路径 0 和路径 1,以 d 点为例,则其路径为 110,而这个路径编码我们也称为霍夫曼编码,用来唯一标识根节点到对应节点的路径。以 Word2vec 为例,每一个叶子节点可以表示词库中的一个单词。
– 长度
路径上的分支总数称为路径长度,以 d 点为例,其编码 110 代表根节点通过三步走到达 d,所以其路径长度为 3。
– 权值
定义中 N 个带权对象可以理解为每个二叉数 Node 节点有一个 Freq 变量标识其权重或频率,例如 Word2vec 中每个单词可以看做是每个叶子节点,而每个单词出现的频率就可以作为权值。
– 节点带权路径长度
以 d 点为例,其霍夫曼编码为 110,路径长度为3,权值为1,则带权路径长度 3×1 = 3。
– 树带权路径长度
将所有叶子节点的带权路径长度相加即为树的带权路径长度,假设有 N 个点:
3.构造
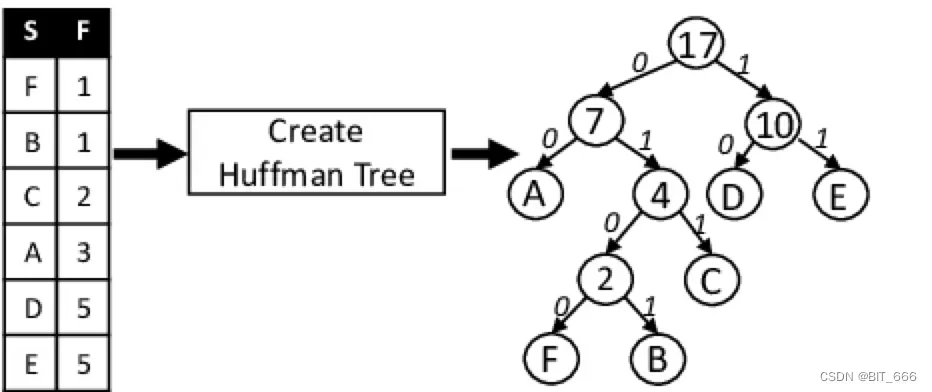
S 代表 String 即字符,F 代表 Freq 即频率,根据霍夫曼树的定义,其要求树的带权路径长度最小,所以出现频率越低的单词路径越长,出现频率越高的单词路径越短,这样 ∑ W x L 才会最小。
– 排序与合并
首先将字符列表按频次进行排序,并 pop 弹出最小的两个 Node 构成一个新的 NewNode,其中 NewNode 的左子树为权值较小的 Node,右子树为权值较大的 Node,且 NewNode 权值为左右子树权值之和。
– 循环合并
将新合并的 NewNode 加入剩余 Node 的列表中,继续执行上一步排序与合并的逻辑。直到列表中只剩一个 Node,此时该 Node 为顶节点,霍夫曼树也构造完成。
– 生成示例
P1 [1,1,2,3,5,5], B-1、F-1 权值最小首先合并为权值为 1+1 = 2 的 新节点
P2 [2,2,3,5,5] New-2 与 C-2 是最小的两个节点,二者合并新节点,新节点权值为 4
P3 [3,4,5,5] 将 A-3 和 New-4 构成权值为 7 的新节点
P4 [5,5,7] 将 D-5 和 E-5 构成 新节点为 New-10
P5 [7,10] 构成新的节点 New-17,小的在左即 7 在左,大的在右即 10 在右
P6 [17] 此时列表只有一个元素,迭代完成
三.Huffman Tree 实现
class Node:
def __init__(self, freq, char=None):
self.left = None
self.right = None
self.freq = freq
self.char = char
def __lt__(self, other):
return self.freq < other.freq首先定义二叉树节点 Node 类,添加 freq 变量代表对应字符 char 的出现频次。
1.生成霍夫曼树
def create_tree(nodes):
while len(nodes) > 1:
nodes.sort()
left_node = nodes.pop(0)
right_node = nodes.pop(0)
new_node = Node(left_node.freq + right_node.freq)
new_node.left = left_node
new_node.right = right_node
nodes.append(new_node)
return nodes[0]循环条件为 Nodes 长度大于1,所以 Nodes 长度为1时构造完成,可以参考上面构造的实例,这里可以使用最小堆优化排序的耗时。
2.编码霍夫曼编码
def huffman_encoding(text):
# 1.构建字典
freq_dict = {}
for char in text:
if char in freq_dict:
freq_dict[char] += 1
else:
freq_dict[char] = 1
# 2.构造霍夫曼树
nodes = [Node(freq_dict[char], char) for char in freq_dict]
root = create_tree(nodes)
# 3.递归获取每个char的霍夫曼编码
huffman_codes = {}
traverse(root, "", huffman_codes)
# 4.获取原 Text 的霍夫曼编码
encoded_text = ""
for char in text:
encoded_text += huffman_codes[char]
return encoded_text, huffman_codes根据给定的 text 首先进行分词和词频统计,随后构造 Nodes 数组并创建霍夫曼,最后利用递归获取每个 char 对应的霍夫曼编码,这里 traverse 函数逻辑如下:
def traverse(node, code, huffman_codes):
if node.char:
huffman_codes[node.char] = code
else:
traverse(node.left, code + '0', huffman_codes)
traverse(node.right, code + '1', huffman_codes)只有 char 字符的节点即叶节点才会触发向 map 保存霍夫曼编码的行为,其余新生成的节点只会传递调用。
3.解码霍夫曼编码
def huffman_decoding(encoded_text, huffman_codes):
decoded_text = ""
code = ""
for bit in encoded_text:
code += bit
for char in huffman_codes:
if huffman_codes[char] == code:
decoded_text += char
code = ""
break
return decoded_text不断向 code 增加 bit 并判断是否在前面构造的 char – hufuman_code 的 map 中,发现后重置 code 并继续新的解码。
4.霍夫曼树编码解码实践
if __name__ == '__main__':
text = "Hello BitDDD"
encoded_text, huffman_codes = huffman_encoding(text.lower())
decoded_text = huffman_decoding(encoded_text, huffman_codes)
print("Original text:", text)
print("Encoded text:", encoded_text)
print("Huffman codes:", huffman_codes)
print("Decoded text:", decoded_text)– 原始文案
('Original text:', 'Hello BitDDD')– 编码后文案
('Encoded text:', '0001110101101001110011011111100010101')– 编码字典
('Huffman codes:', {' ': '1100', 'b': '1101', 'e': '1110', 'd': '01', 'i': '1111', 'h': '000', 'l': '101', 'o': '001', 't': '100'})– 解码文字
('Decoded text:', 'hello bitddd')四.总结
上面介绍了 霍夫曼树 的基本概念与构造方法,这里简单分析下 霍夫曼树 如何应用于 word2vec 的层次 softmax,更详细的可以参考:Gensim Word2Vec 实践。
– 优化计算次数
通过对词库的 N 个单词构造霍夫曼树,计算每个单词的概率只需关注其二叉树路径即霍夫曼编码的长度次计算即可,计算量由 N 缩减为 LogN。
– 路径缩减
由于霍夫曼树构建是根据单词词频,所以高频的单词越靠上其路径也越短,所以针对高频的单词计算量相对来说更少。
文章出处登录后可见!