CVPR 2021
论文链接:https://arxiv.org/abs/2102.08318
个人理解:物体检测的预训练进步,训练前集成边界框,可以促进迁移学习中更好的任务对齐和架构对齐。提出了一种用于边界框的增强方法以进一步增强特征对齐。
论文思路:通过对比学习区分前景和背景实现更准确的定位建模,增强定位的真实框的清晰标签,微调网络,整个方法强调边界框信息.
提出问题:在迁移学习中,针对新任务对网络进行微调,而不是对目标框区域进行显式建模,使得模型不适合检测任务
方法:首先描述对比学习框架,然后描述图像增强方法,最后使用不同的主干和检测器进行检测。
实验:对比实验表明,它优于当前其他方法,在小数据集上增益更大。消融实验证明了该模块的有效性。
结果:获得了更好的传输优化,更适合检测任务的空间建模,具有更好的泛化性和更高的数据传输效率(?)。
介绍
在计算机视觉中,深度网络的训练主要是通过预训练和微调。预训练就是找到数据的统一特征,得到迁移优化。使用图像级标签的监督预训练模型和通过对比学习的自监督预训练模型都可以很好地转移到许多任务中,但作者发现了两点,一是自监督可能无法赋予它优势在图像分类转化为对象检测时,第二个是高级特征在转化为检测和分割时并不重要。
在迁移学习中,针对新任务对网络进行微调,而不是明确地对区域进行建模以使其不适合空间推理任务,这是导致迁移效率低下的两个问题。
因此,作者提出了一种自监督的实例定位方法,适用于目标检测的下游任务,在实例定位的特征学习中考虑了定位框信息。
创建训练数据集:将不同纵横比的前景图粘贴到背景图的不同位置。
输入:合成图像和边界框。
自监督预训练和定位建模:使用边界框提取RoI特征,并使用实例标签进行对比学习,使得网络可以保持前后结构一致,卷积特征和前景区域之间的明确对齐。作者发现,特征对齐可以通过在边界框坐标上诱导增广来加强。
结果:分类性能降低,但检测精度提高,更有利于小数据下的目标检测。
相关工作
- 自我监督学习
- 图像合成
- 使用不平衡数据进行自我训练
先决条件 – 实例位置
与分类不同,对象检测的特征应该保留和反映有关对象大小和位置的信息。因此,需要专门的建模。在对比学习中,平移和尺度方差是为图像分类而设计的技术,它们通过学习图像的两个随机视图的一致性来做到这一点。因此,实例判别的前置任务太适合整体分类,而不是空间推理。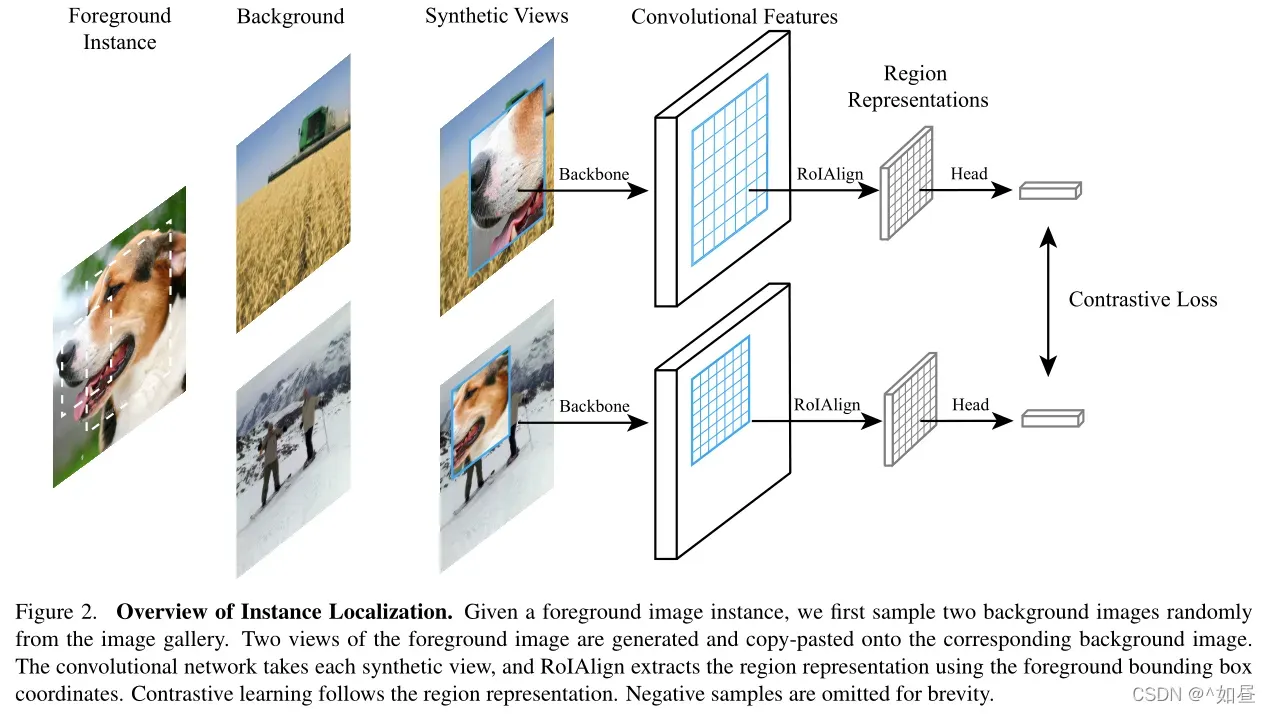
作者提出了实例定位(InsLoc)作为实例判别的扩展。如图3所示,通过将前景实例叠加到背景上来合成图像组合。目标是利用边界框信息区分前景和背景。图2是实例定位的流程,为了实现这个任务,必须首先定位前置实例,然后提取前置特征。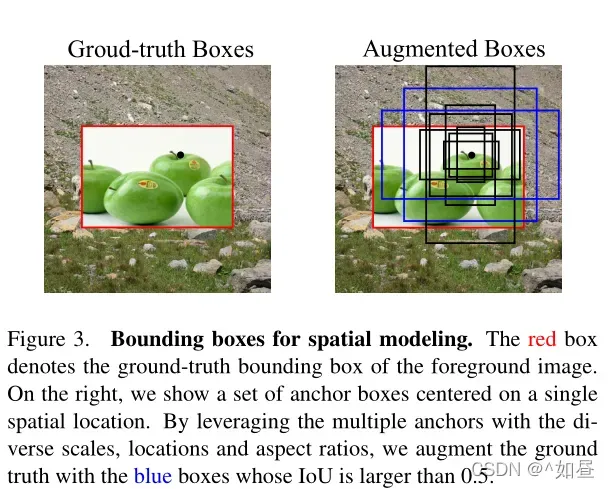
根据下式,对于合成图像和对应的边界框
,通过任务
得到对应的实例标签
。
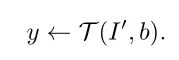
方法
作者的目标是学习语义上稳健和尺度等变的表示。首先描述了对比学习框架,然后是图像增强,最后是使用不同的主干和检测器进行检测。
1. 边界框的实例区分
实例区分:使用不同强化下的两个随机视图进行比较,包括query 和key
,它们来自同一张图像。通过主干网络
提取其对应的特征,然后通过检测头投影到每个像素单元,(?)对应的对比度损失为
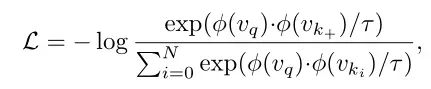
使用边界框建模:增强输入区域和特征之间的对齐和实例对比学习。首先选择一张背景图片,将指定图片
以随机比例和随机位置随机剪切粘贴到
上,合成
和边框信息
。
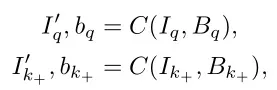
其中,为综合运算。
在这里使用了两张不同的背景图像,否则模型可能会被背景欺骗,在实践中,前景图像是用随机的宽高比3和128到256像素之间的随机比例来调整大小的。使用包围框参数b,应用RoIAlign来提取前景特征值。
在对比学习后,得到对应的 loss(公式2)。
检测面临的问题是前景和背景对应的深度特征之间的差异。深度特征上下文信息丰富,但容易受到区域框外其他图像内容的影响,定位困难。通过实例定位将边界框与周围内容区分开来,并学习有效的边界框范围,可以以数据驱动的方式解决这个问题。卷积特征与其有效感受野之间的这种明确对应有助于通过学习表示进行精确定位。
2. 边界框增强
图像增强有助于对比学习定位的准确性。真实框的错误定位可能包括背景区域,因此可以增强表示以在空间上忽略背景并获得定位能力。
预定义锚点增强:对真实框进行移动增强,利用区域提议网络(RPN)中的锚点覆盖得到的增强框的多样性。作者对所有锚进行计算,筛选出重叠度的锚点,并随机选择一个锚点作为增广框。由此,可得到一个动态范围的锚定框建议集合。将这种增强方式运用到 RoIAlign 这个模型上。
3. 架构调整
迁移学习中,网络结构调整会导致任务错位。通过附加区域操作和头网络,预先训练的网络需要被重新用于检测网络。作者提出的实例定位最小化了预训练和微调之间的架构差异。在预训练中,对区域引入 RoIAlign 操作,能够模仿精细调优中的检测行为。
- R50-C4:在标准的 ResNet50 架构上在第四个 residual block 的输出上加入 RoI 操作,然后使用边界框提取区域特征,将第五个 residual block 作为检测头进行区域分类。
- R50-FPN:使用横向连接在 ResNet50 上形成一个4层特征的结构。每个层次都按照对应比例得到对象特征,在 FPN 的每个层插入 RoI 操作,则实例定位可以在4层上同时进行,每一层维护一个单独的队列,这样可以对 ResNet50 和 FPN 层都进行预训练。
实验
数据集:PASCAL VOC 和 MSCOCO
预训练:采用 MoCo-v2 官方的超参数。8个 GPU 上同步 SGD优化模型,每个 GPU 批次为32,优化200-400轮,配置权值衰减为0.0001,初始学习率为0.03,进行余弦消减。采用双层 MLP 头进行对比学习,温度参数设置为0.2。
数据强化:同 MoCo-v2 。随机调整大小的裁剪,颜色抖动,灰度变换,高斯模糊和水平翻转。
微调:在 MoCo-v2 后,在所有层中同步的批处理规范化,检测头使用 detectron2 并微调。
1. 主要结果
- PASCAL VOC:Faster RCNN 作为检测器,R50-C4 作为主干网络。与基线 MoCo-v2 相比,模型在200和800轮时分别提高了+0.9和+1.0 AP,无需使用强大的数据增强而优于所有以前的方法,该预训练模型在这个基准上获得了最先进的结果。
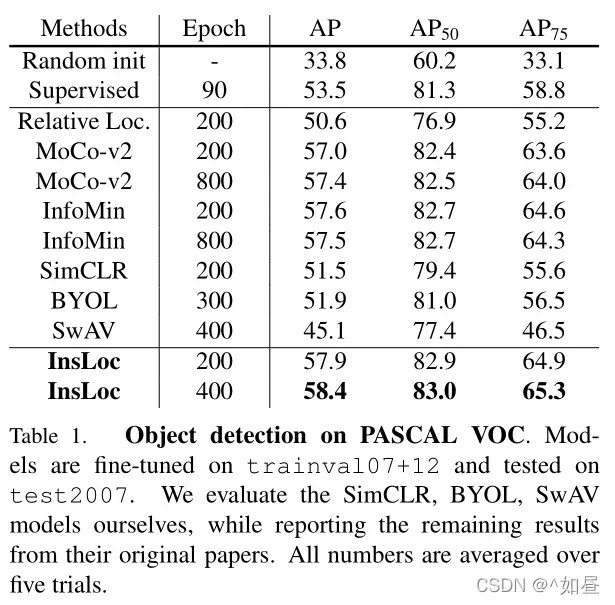
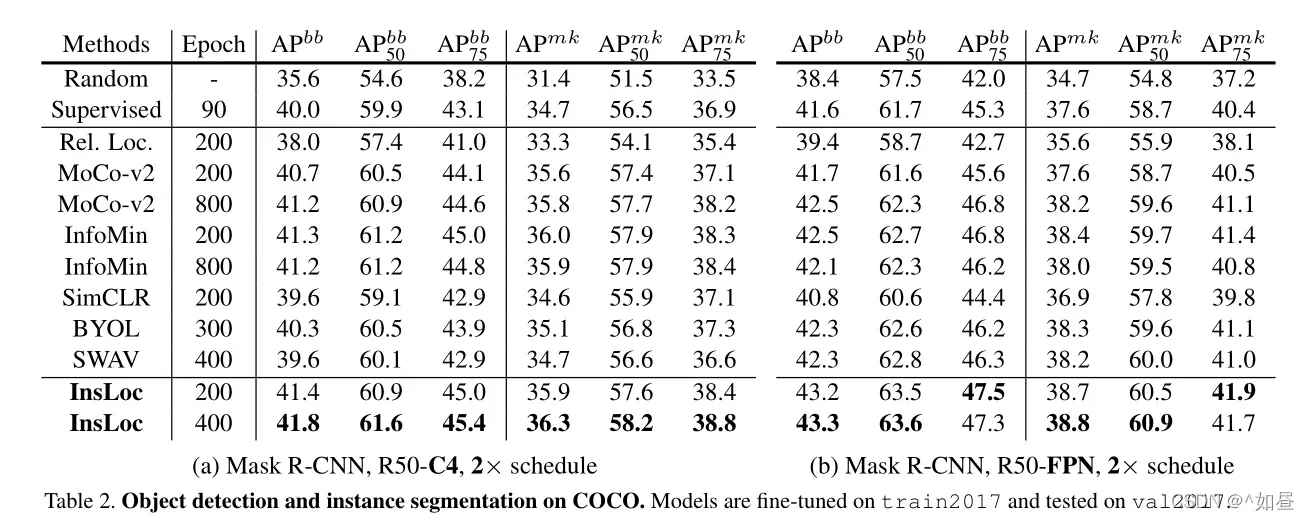
- COCO:采用 Mask RCNN 作为检测器,使用 R50-C4 和R50-FPN 作为主干。预训练200轮后,相比基线 MoCo-v2 ,R50-C4 和 R50-FPN 分别+0.7和+1.5 AP。400轮后,InsLoc达到了新的最先进的性能,超越了所有先前的自我监督模型与强大的图像增强。InsLoc在完全监督的ImageNet前训练有+1.8和+1.7AP 的改进。然而,当模型的预训练时间越长,InfoMin的传输性能越差。相比 R50-C4 ,BYOL 和 SwAV 下,在 R50- FPN中更具有竞争力。
2. 消融实验
为了进一步了解实例本地化的优势,我们进行了一系列消融研究,包括测试语义和本地化的权衡、新借口任务的影响、随时间的微调以及更多优化时期下的预训练。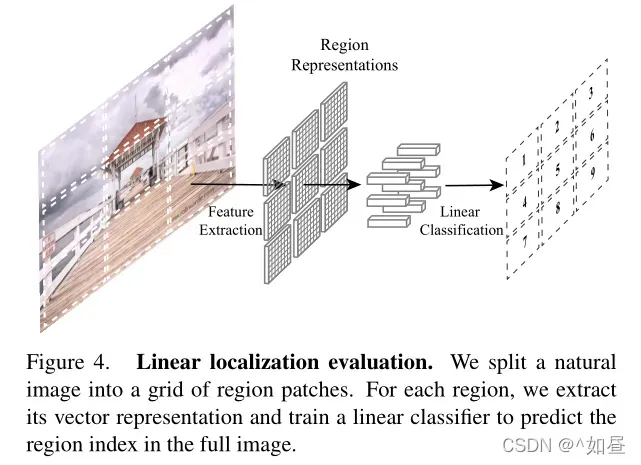
这种改进是否由于更强的语义特征:对于给定的输入图像,分割为个 patch,预测基于每个块的区域特征并进行线性分类,如图4,(
)。作者的评估考虑了每一块对弈征途图像的空间排列,对于每一个块,通过主干网络提取特征表示,提取 RoI 特征,再输入检测头,在其中附加了一个线性分类器进行分类预测,这反应了图像的定位能力。
表3a显示了语义化和局部化准确度的比较。实例定位为线性定位任务带来了2.3%的明显改进。这表明,目标检测的整体改善主要是由于更好的空间定位,而不是更强的语义。同样,在自监督的预训练中低级和中级的语义比高级语义更加重要。
实例定位的有效性:表3b给出了架构对齐、实例定位和提出的边界框增强的消融实验。首先提取了整体表征,然后采用了对比学习,同时在 FPN 层次上应用了多个对比损失,得到了+0.4 AP bb的改进。这样的改进证明了调整架构的有效性。然后,应用实例定位任务到合成图像上,性能达到41.1 AP bb,比 MoCo- v2 明显高出1.3倍。最后,对边界框增强达到41.4 AP bb。说明了方法的有效性。
微调的影响:随着测试次数的增加,对检测任务进行微调,可以提高对象检测性能。我们检查如何微调计划影响相对改进的预训练模型。表4表明,较长的微调可能不会显著削弱相对的改进,证明了预训练模型对迁移学习的实用性。
多轮次预训练的效果:ImageNet 的线性分类准确性因为更多轮次的预训练而变得更高。然而,对于目标检测,多伦预训练不一定有利,如InfoMin[38]所示。在表4中,对比了200、400和800轮预训练在COCO上的迁移性能。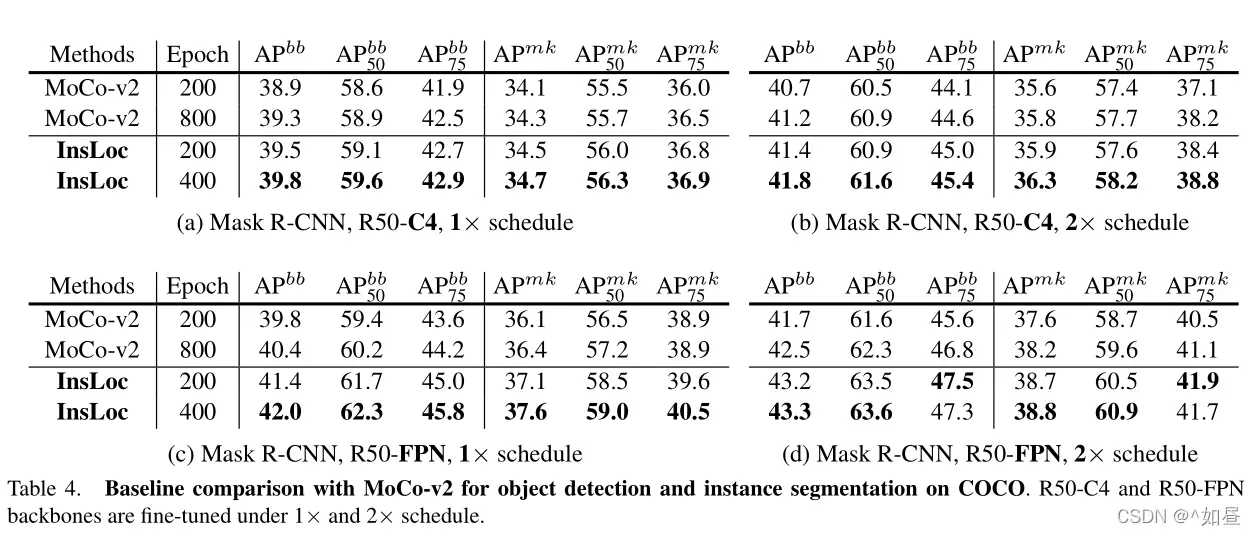
3. mini COCO上的评估
为证明预训练模型在少量标记数据下的泛化能力,因此作者在 mini COCO 上进行了实验。
数据集:随机选取10%的来自于 mini COCO 2017数据集的图片。其检测目标在比例和宽高比方面有巨大差异。验证集为完整的 val2017。
微调:使用R50-C4作为主干网并调为12轮,在最后一个剩余块之后插入一个 normalization 层。
结果:如表5,相对监督方法,得到了较大改进,证明了较好的泛化和迁移能力,同时也具有更高的数据效率。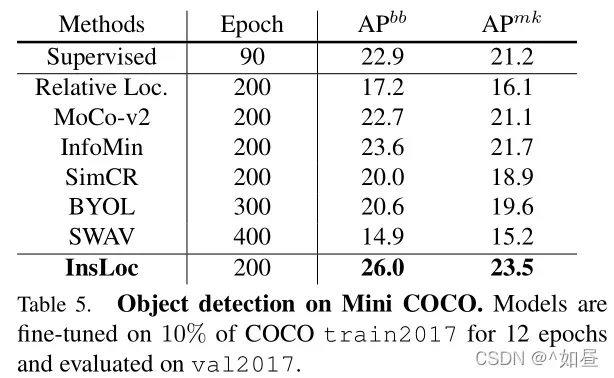
总结
作者提出了实例定位框架、边界框增强,并介绍了对象框在自监督表示学习中的应用。训练后的模型对整体图像分类效果较差,但对局部图像定位效果更好。当转换为目标检测时,可以获得更好的目标检测结果。在作者提出的方法中,小数据集可以获得更大的增益,同时,改进任务对齐可以提高目标检测的迁移性能。
文章出处登录后可见!