前言
环境搭建
Anaconda
本地环境 Anaconda
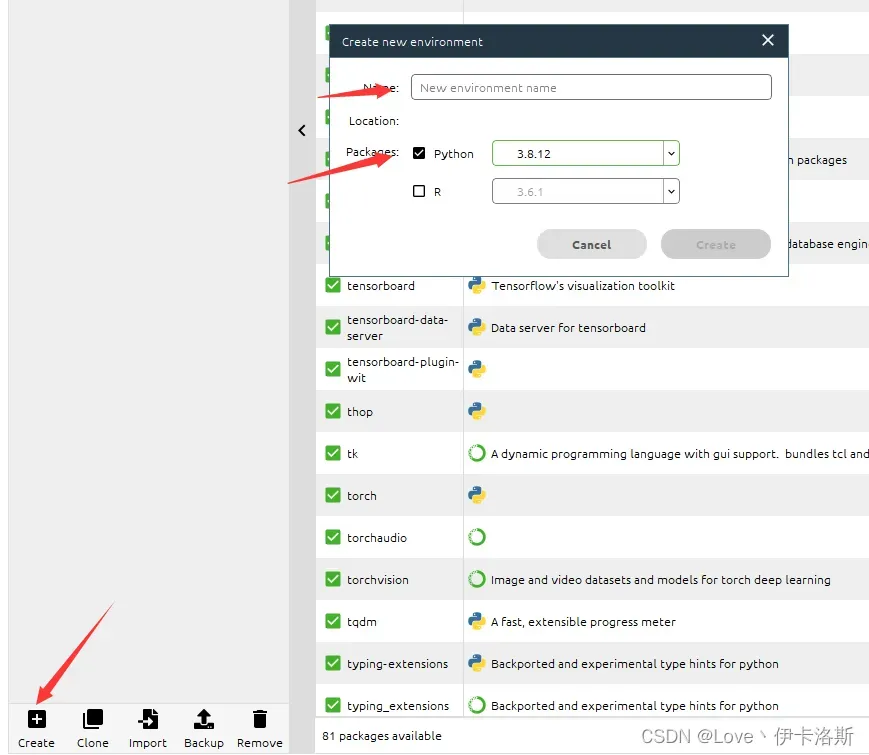
python版本选的 python3.8.12,创建环境
yolov5克隆到本地
我这采取的方案是fork了仓库 同步到了gitee,然后clone
安装相关依赖库
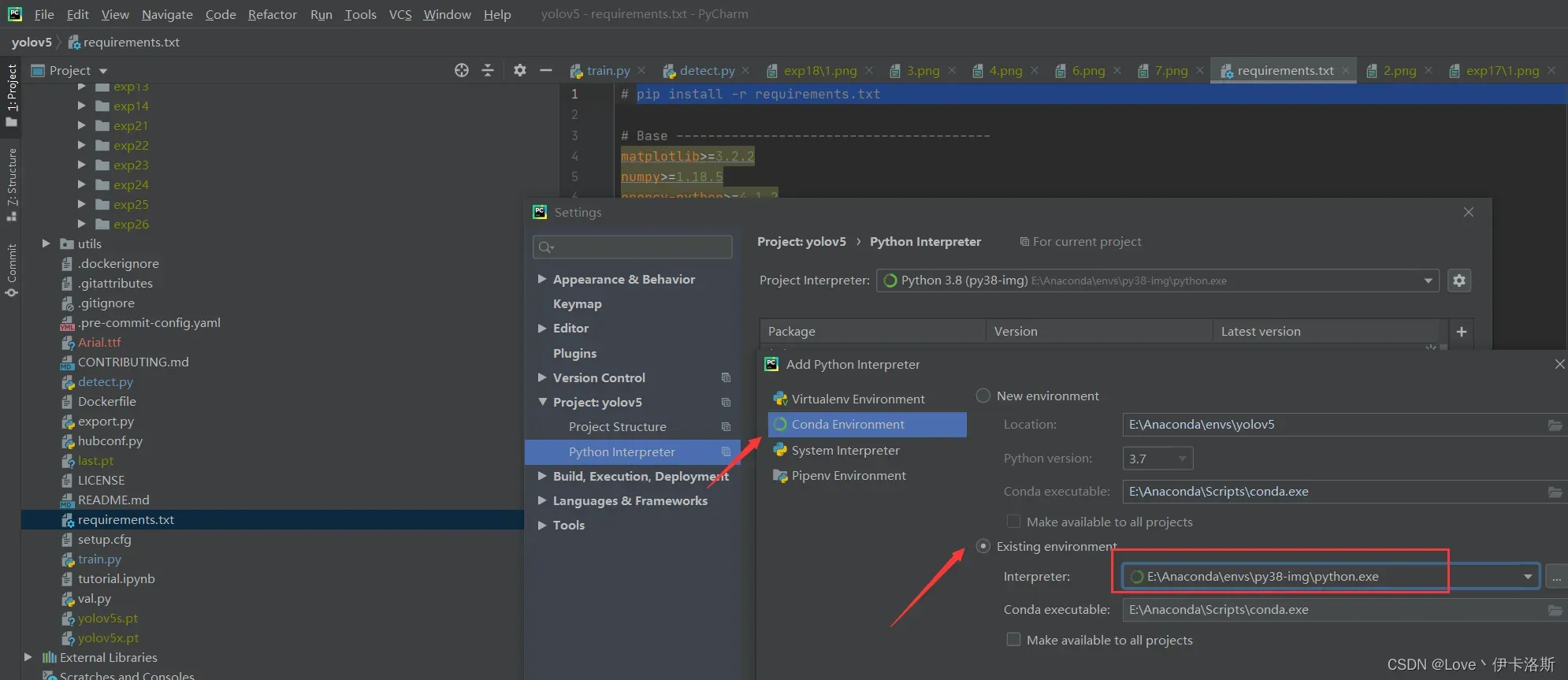
采用pycharm打开工程,配置为 conda的环境
根据官方说明文档进行安装
激活我们刚才创建的环境 py38-img

执行pip命令 pip install -r requirements.txt
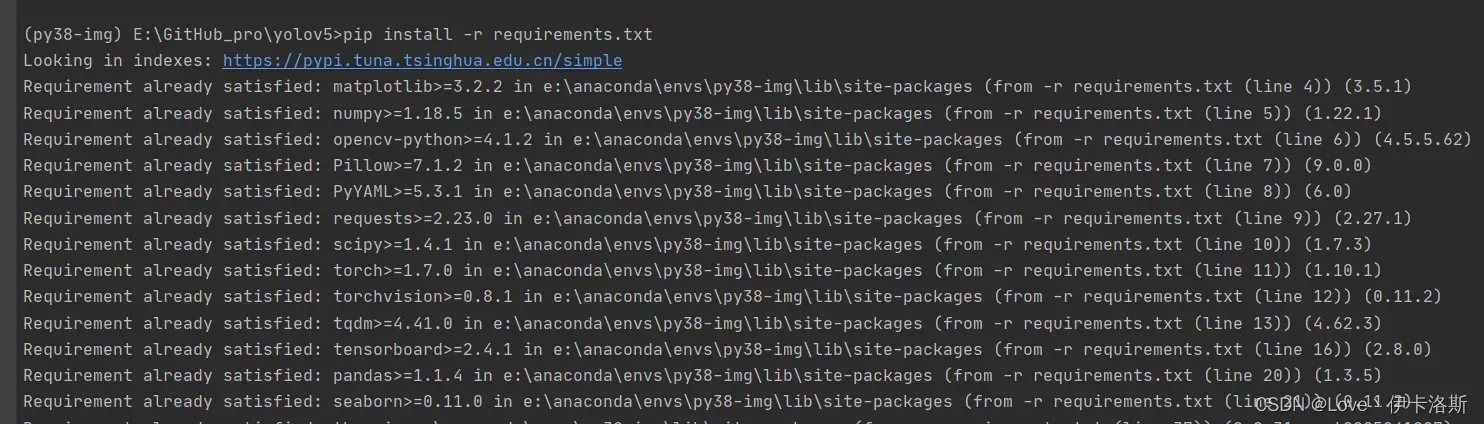
完成安装。
ps:我这已经换了源
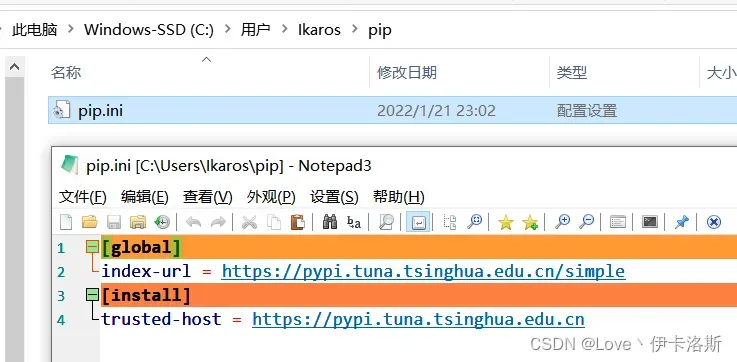
路径:C:\Users\用户名\pip
pip.ini 内容为:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
安装CUDA和cuDNN(有显卡需求的话)
ps:我的显卡是RTX2060
参考文章:win10安装CUDA和cuDNN的正确姿势
CUDA下载页面:https://developer.nvidia.com/cuda-downloads
cuDNN下载页面:https://developer.nvidia.com/rdp/cudnn-download
根据教程 安装和配置好环境, cudnn里面的文件 需要复制到 cuda的对应文件夹下。这里访问比较困难
我这同步到了阿里云盘:「cuda_11.6.0_511.23_windows.exe」https://www.aliyundrive.com/s/6Q4yRH9nJ8Q

环境变量的配置
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64

安装完后的测试 nvcc -V
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\extras\demo_suite执行测试程序
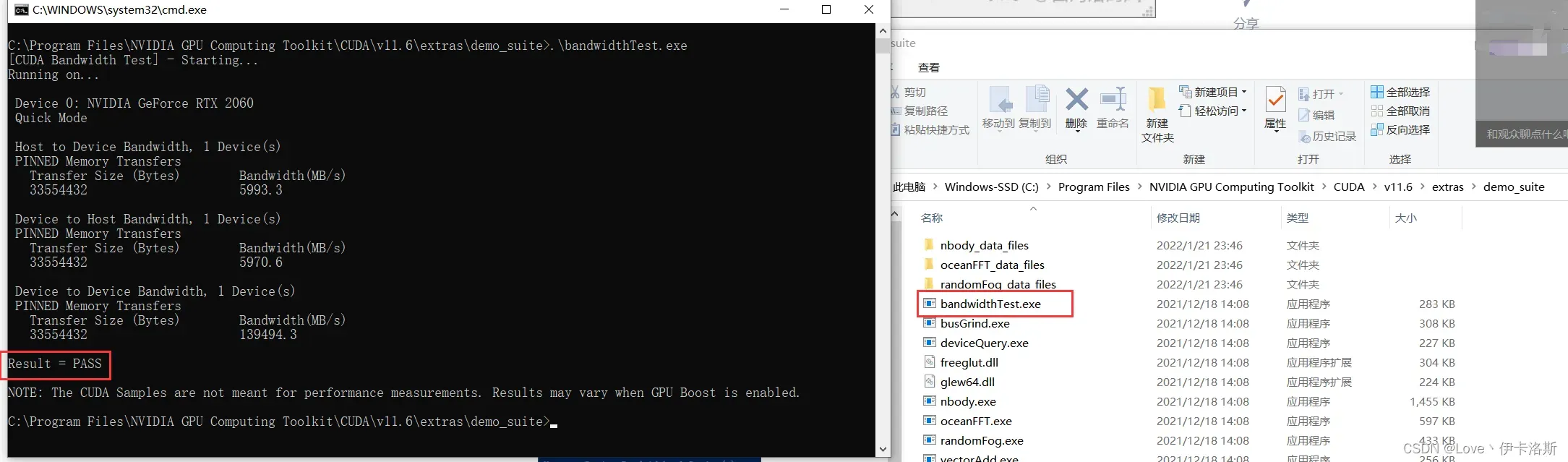
这是我的相关参数
pytorch单独再次安装
因为pytorch这块安装有 cpu only的版本 所以我掉了很多次坑
参考:Windows环境下Anaconda3安装配置pytorch详细步骤(踩坑汇总)
Pytorch版本、CUDA版本与显卡驱动版本的对应关系
注意版本是否对应!
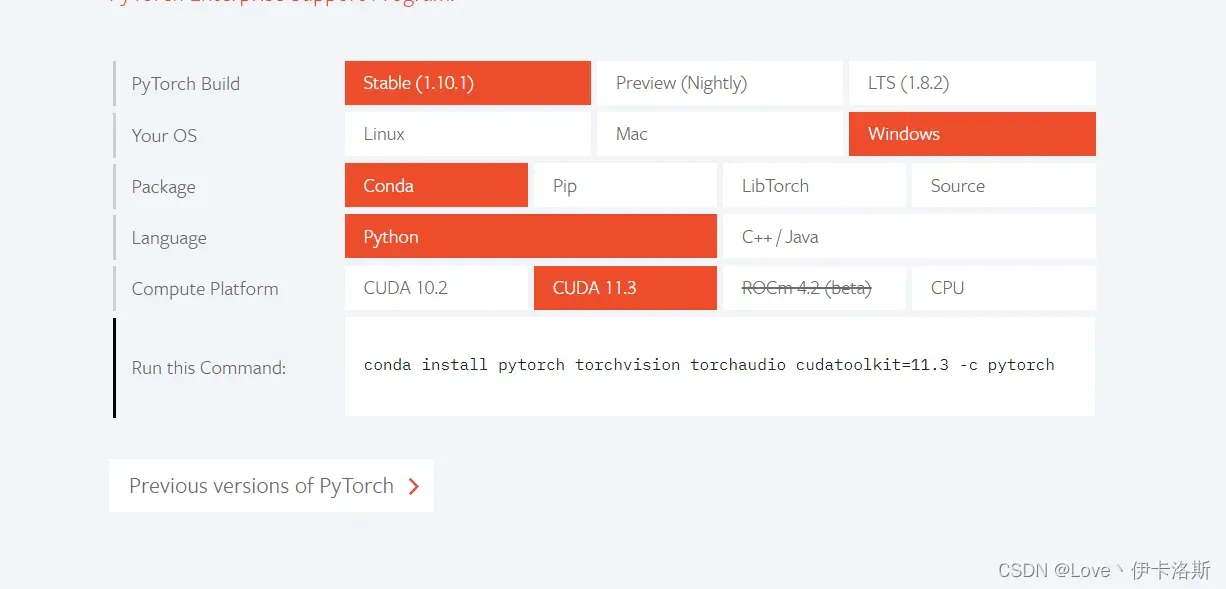
pytorch官网:https://pytorch.org/
根据你的需求生成安装命令, 后缀的 -c pytorch删掉
conda install pytorch torchvision torchaudio cudatoolkit
查看 安装的相关库 conda list ,没有带 cpuonly 对头

测试官方demo
detect.py识别 bus.jpg
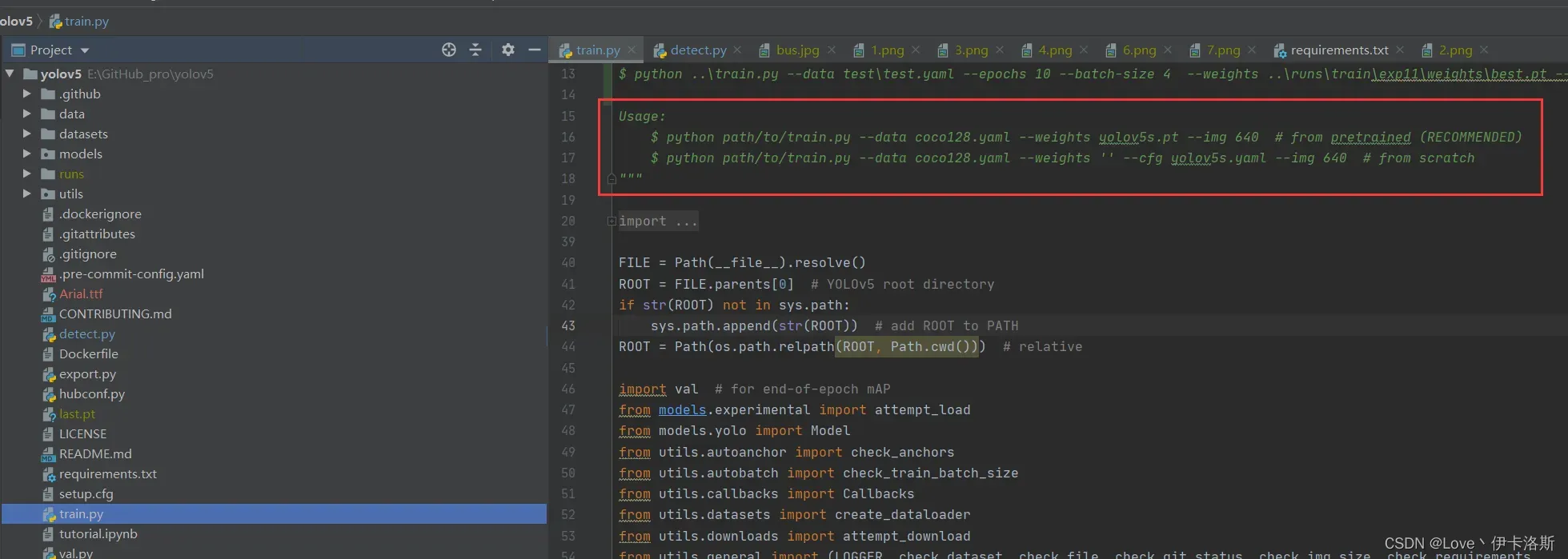
源码里面写了相关的使用命令和传参,当然直接跑多半会报错
正常情况运行命令 python detect.py --weights yolov5s.pt --source data\images\bus.jpg,可以完成图片识别,显示结果到runs下的exp里

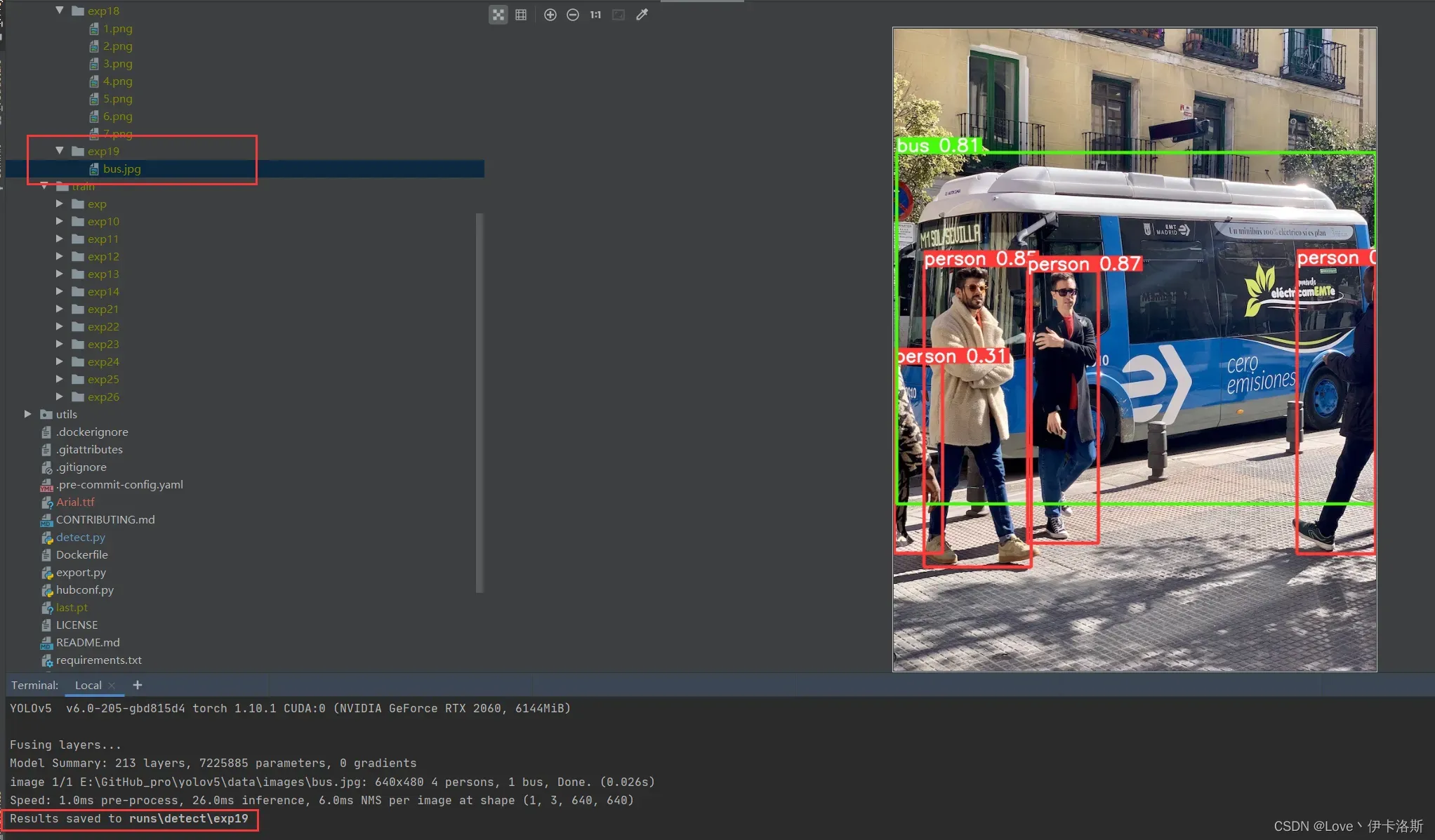
当然 细心的你会发现缺少了 对应的权重文件 yolov5s.pt,相应的权重文件可以在官方github仓库下载:https://github.com/ultralytics/yolov5/releases
当然如果你没有下载,例程也会自动帮你运行下载程序,不过网络不好的情况下多半会出现443等报错然后下载失败。
另外你例程会下载字体包 Arial.ttf,如果下载失败可以自行去提示的官网下载,然后存放在指定路径下 C:\Users\用户名\AppData\Roaming\Ultralytics,并安装字体包。
我这阿里云盘也上传了:https://www.aliyundrive.com/s/xzgh5fr6yLU
train.py训练模型
训练官方提供的coco128
源码里也同样提供了 参考的命令 当然直接跑也是运行不了的啦
当然我这提供了运行命令,先创建文件夹 datasets,然后将coco128数据集下载后解压进去(当然例程会自己下载,不过我这下载还是失败了)
$ cd datasets
$ python ..\train.py --data ..\data\coco128.yaml --img 128
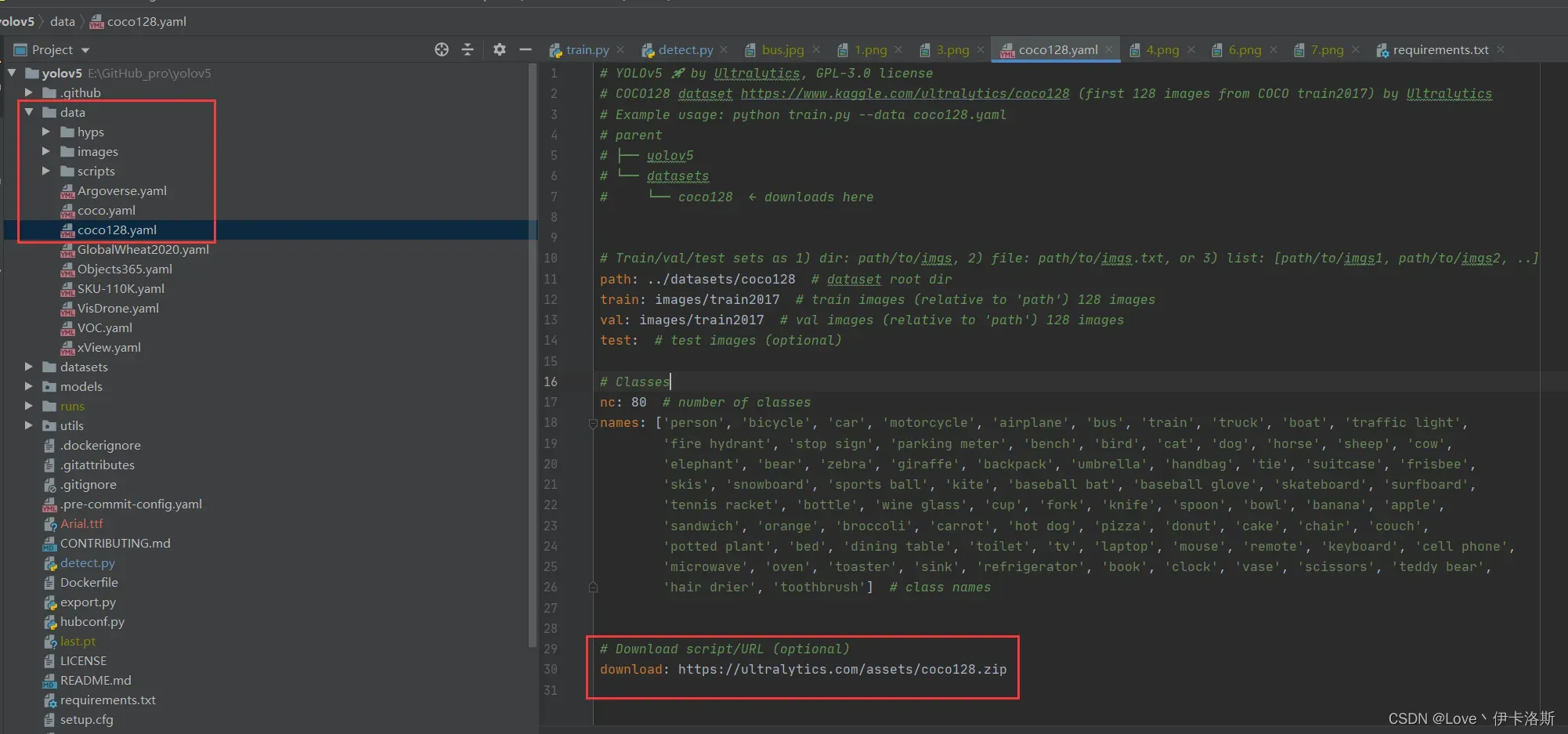
例程会读取 data\coco128.yaml 文件,yaml里面写了下载的数据集路径,你可以手动下载然后解压到datasets里面
https://ultralytics.com/assets/coco128.zip
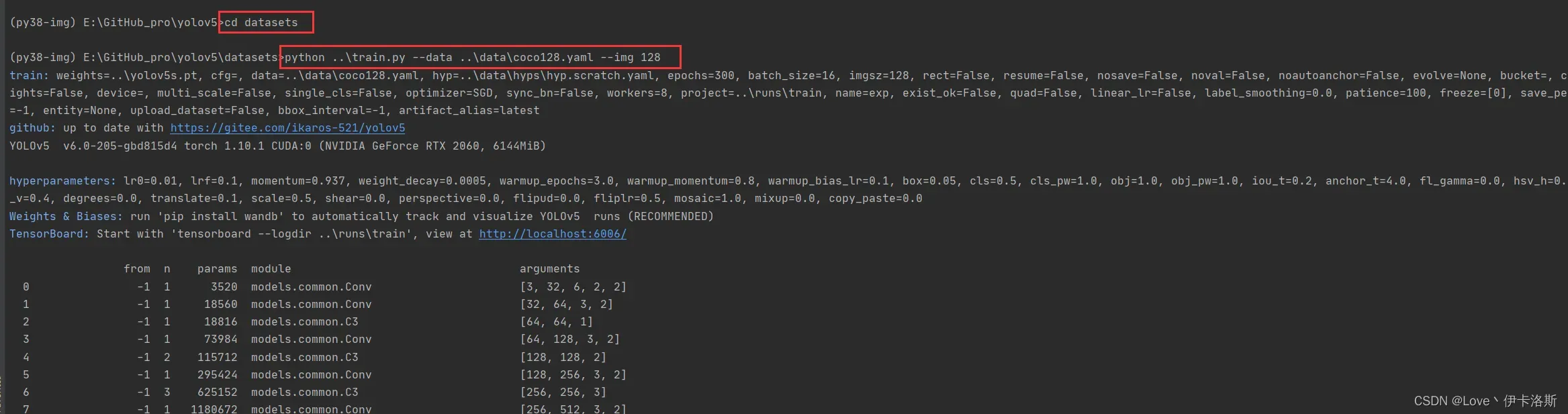
再次执行我们的训练命令 ,开始训练(默认训练300轮 可以通过–epochs 修改轮数,另外默认配置还是比较吃电脑配置的,如果只是测个程序而已,可以使用我这提供的第3条命令)
(如果报错:DefaultCPUAllocator: not enough memory,内存不足,就需要调小配置 更多报错参考文章末尾的目录 报错相关)
$ cd datasets
$ python ..\train.py --data ..\data\coco128.yaml --img 128
$ python ..\train.py --data ..\data\coco128.yaml --epochs 3 --batch-size 1 --workers 1 --img 128
训练自己的模型
当然可以不训练这个了,自己随便搞个test训练训练(这个test训练集 由labelimg 工具协助生成) labelimg相关使用可以参考下面的部分 传送门
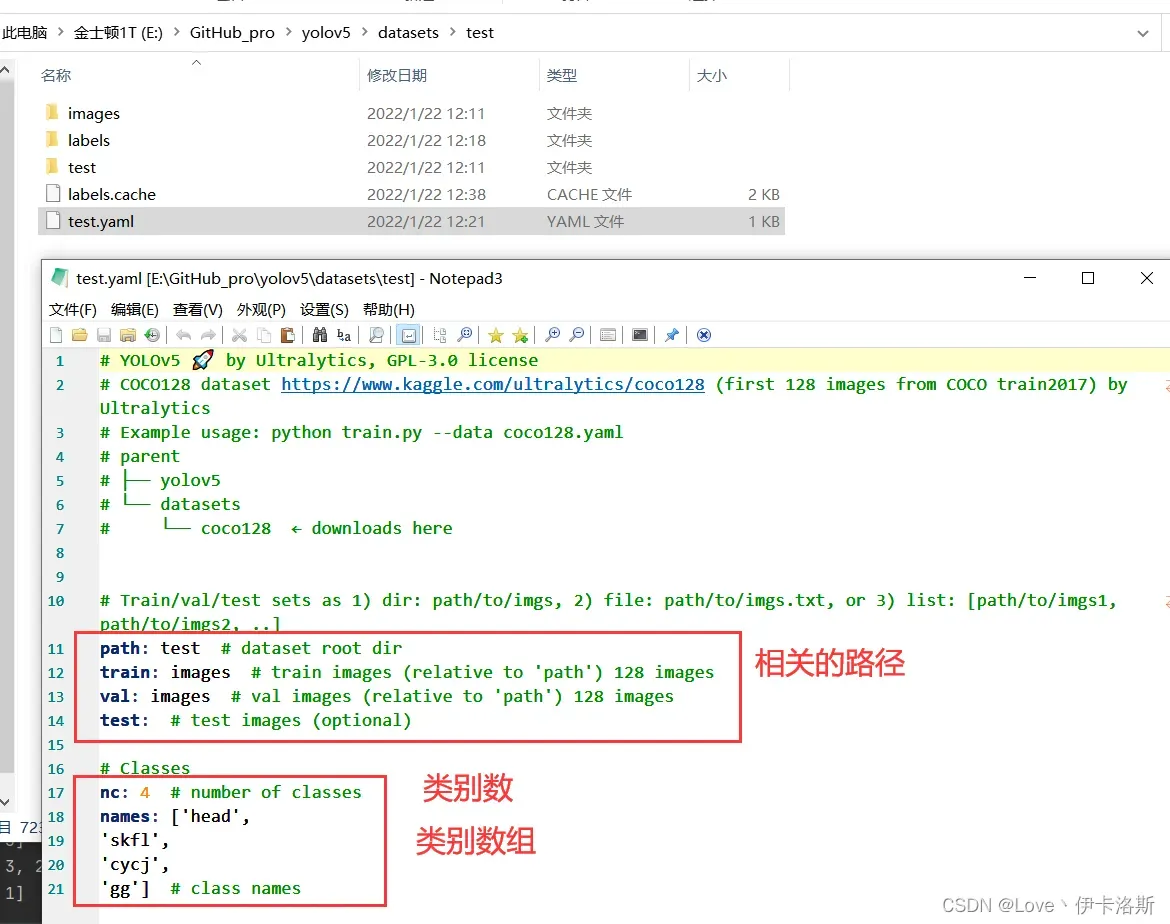
开始训练 python ..\train.py --data test\test.yaml --epochs 3 --batch-size 2 --weights ..\runs\train\exp26\weights\last.pt --nosave --cache (注意我这里传了不少参数,如果你不需要可以不加 –epochs是训练轮数,因为测试所以先调小点,节约时间。具体各个参数的含义可以看下面的参考图或直接看源码)
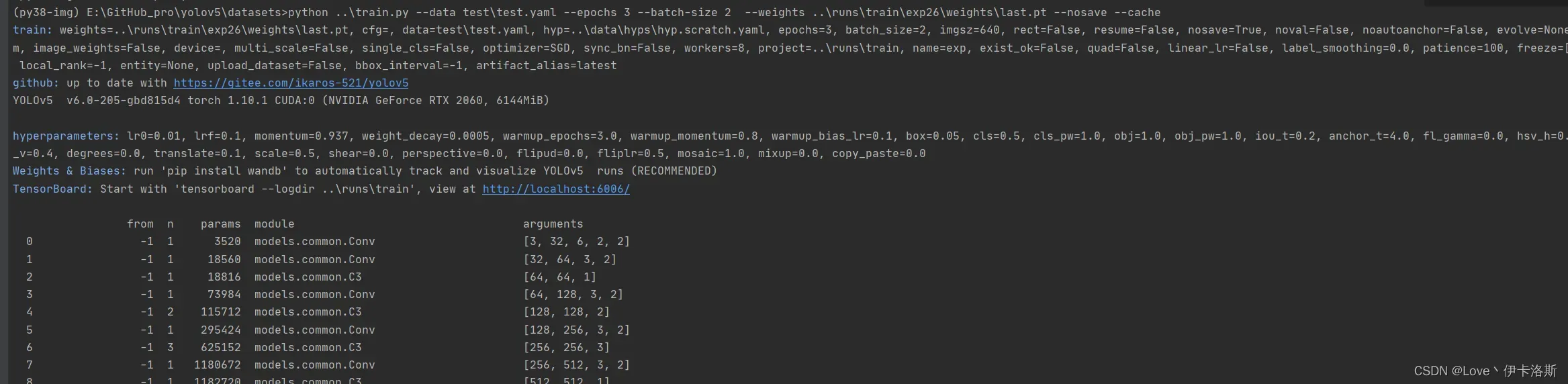
报错 OSError: [WinError 1455] 页面文件太小,无法完成操作。你可以调小 –batch-size
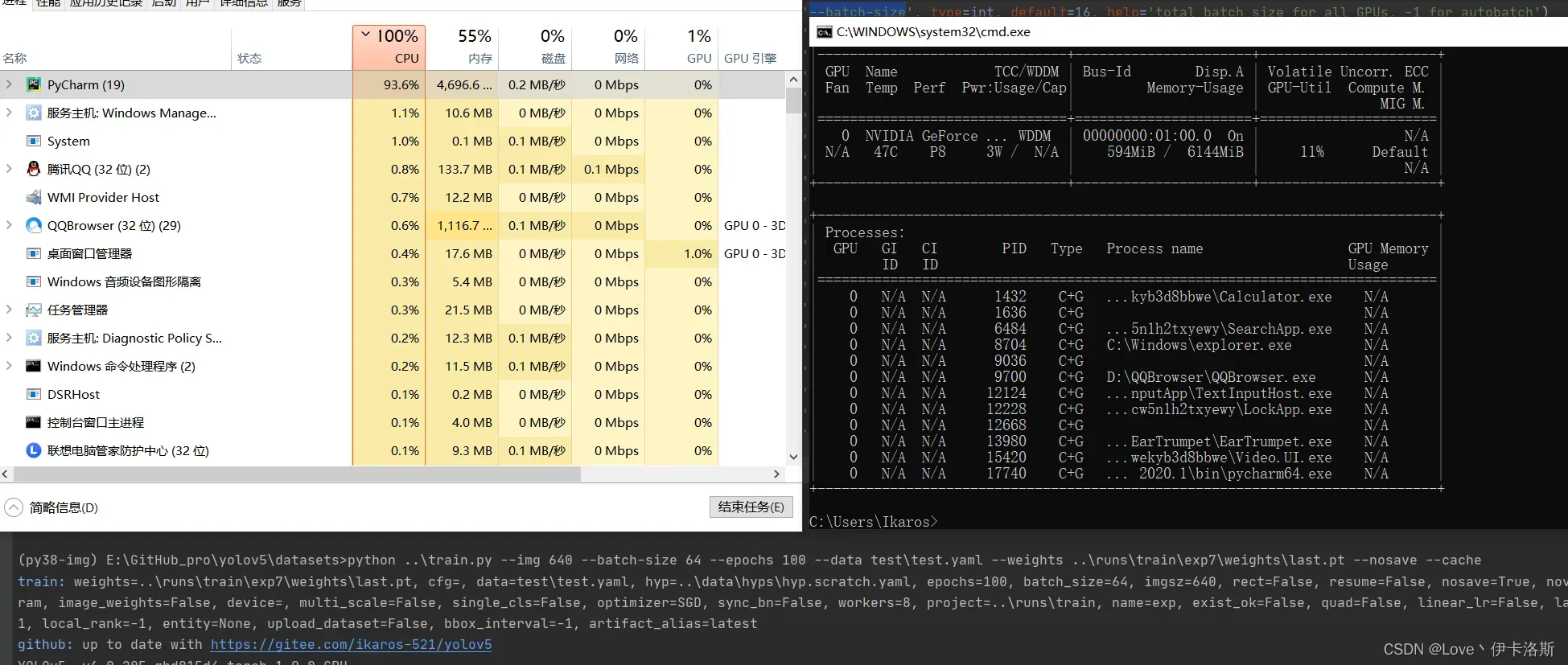
配合 命令 nvidia-smi,查看显卡信息
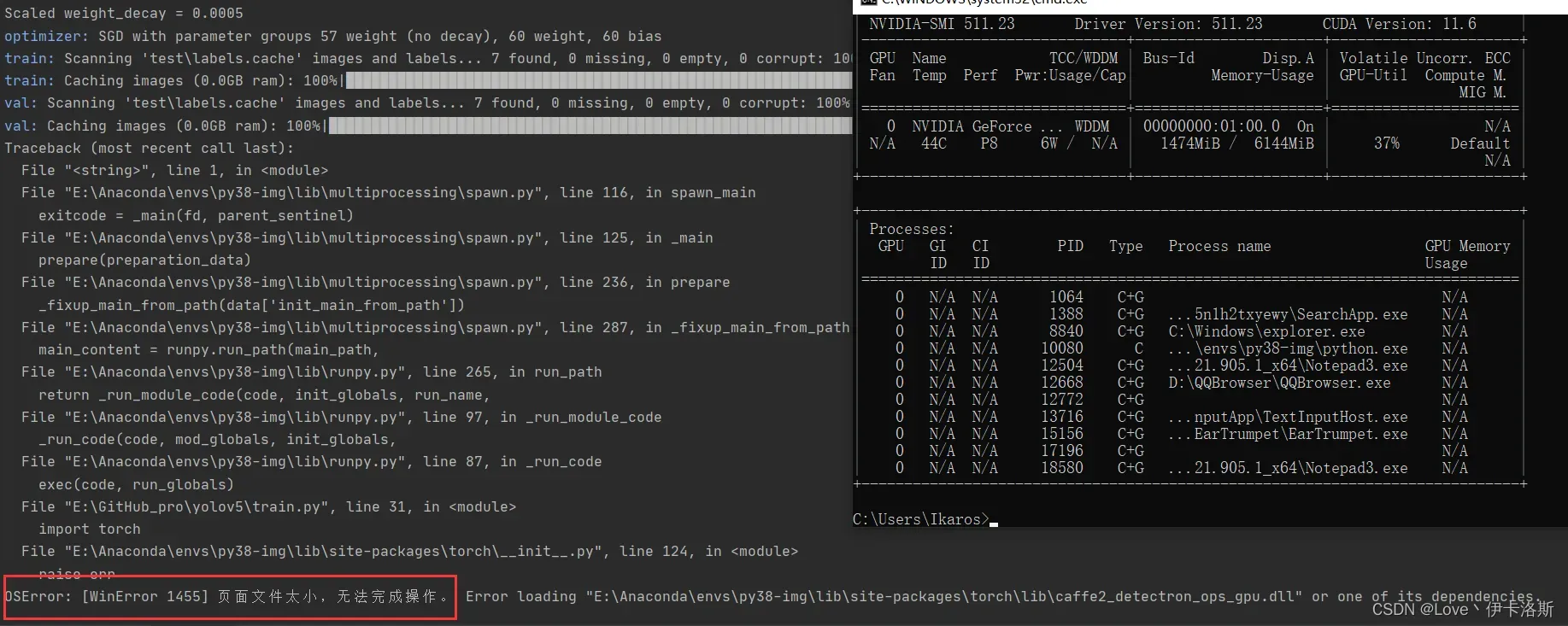
下图转自 yolov5训练相关参数解释

相关训练参数可参考:yolov5训练相关参数解释
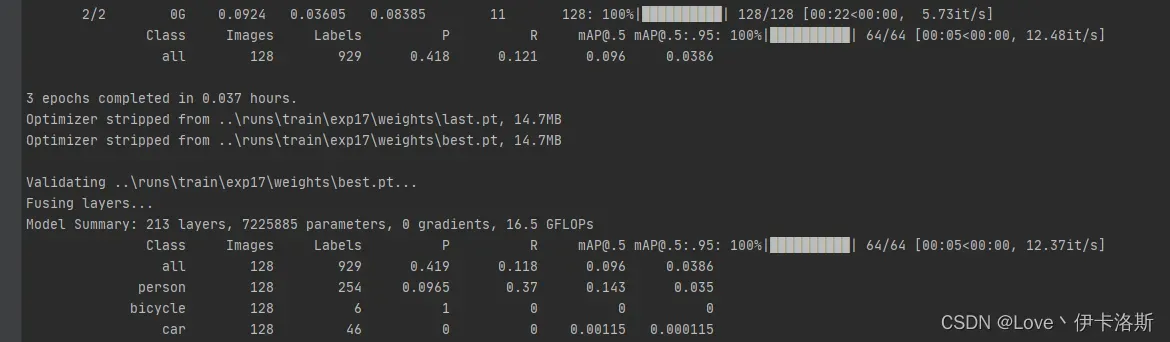
我们调小 –batch-size python ..\train.py --data test\test.yaml --epochs 3 --batch-size 2 --weights ..\runs\train\exp26\weights\last.pt --nosave --cache,成功完成训练。训练结果默认存储在 runs\train\exp 等下面,我们的权重文件 生成了2个 last.pt, best.pt 。当然可能你只会生成1个last.pt,问题不大,继续练。
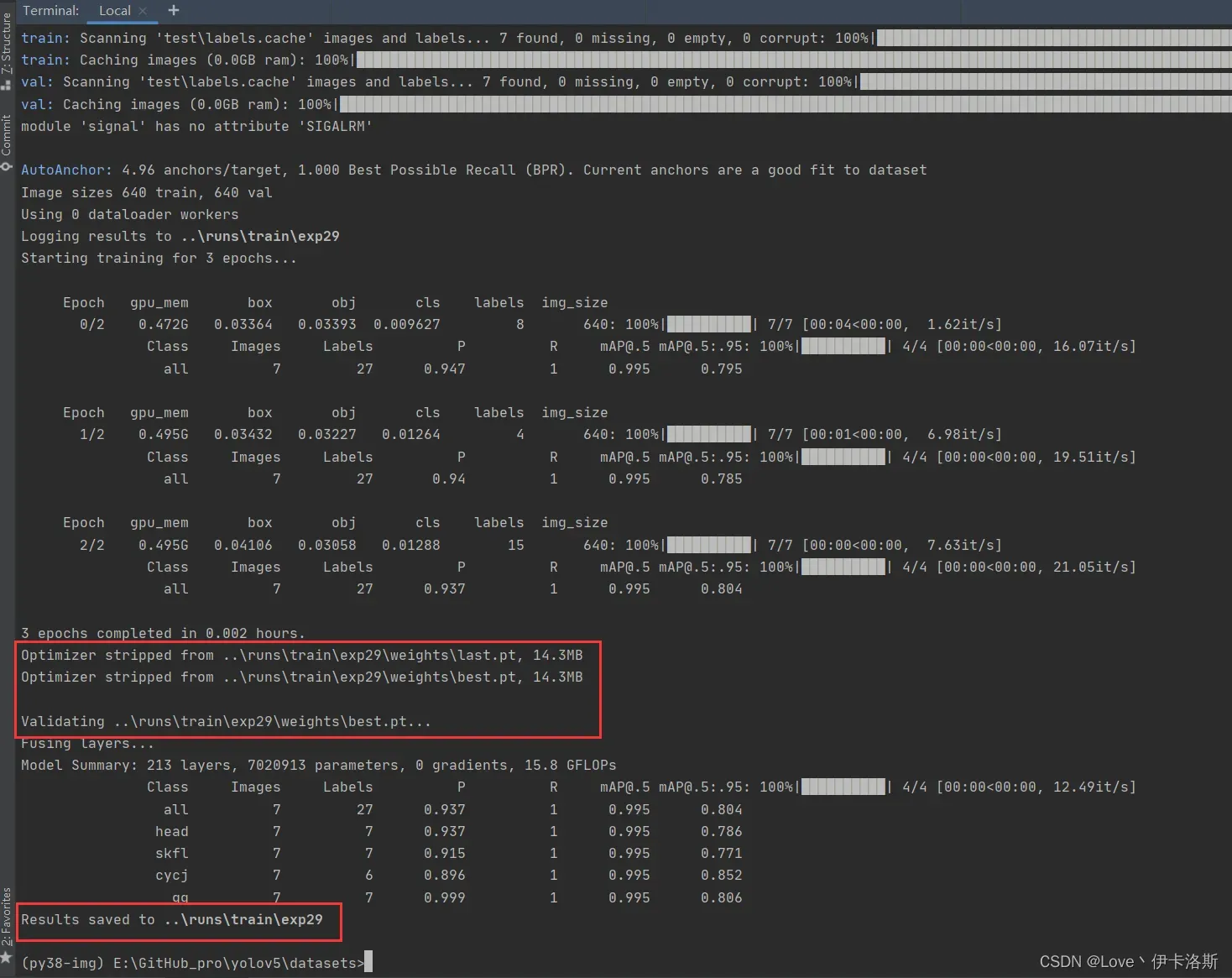
训练好后的权重 pt拿去 再次detect.py识别
相关命令
$ cd datasets
$ python ..\detect.py --weights ..\runs\train\exp29\weights\best.pt --source test\test --conf-thres 0.5
源码有各传参的解释,我们这追加了 –conf-thres 传入
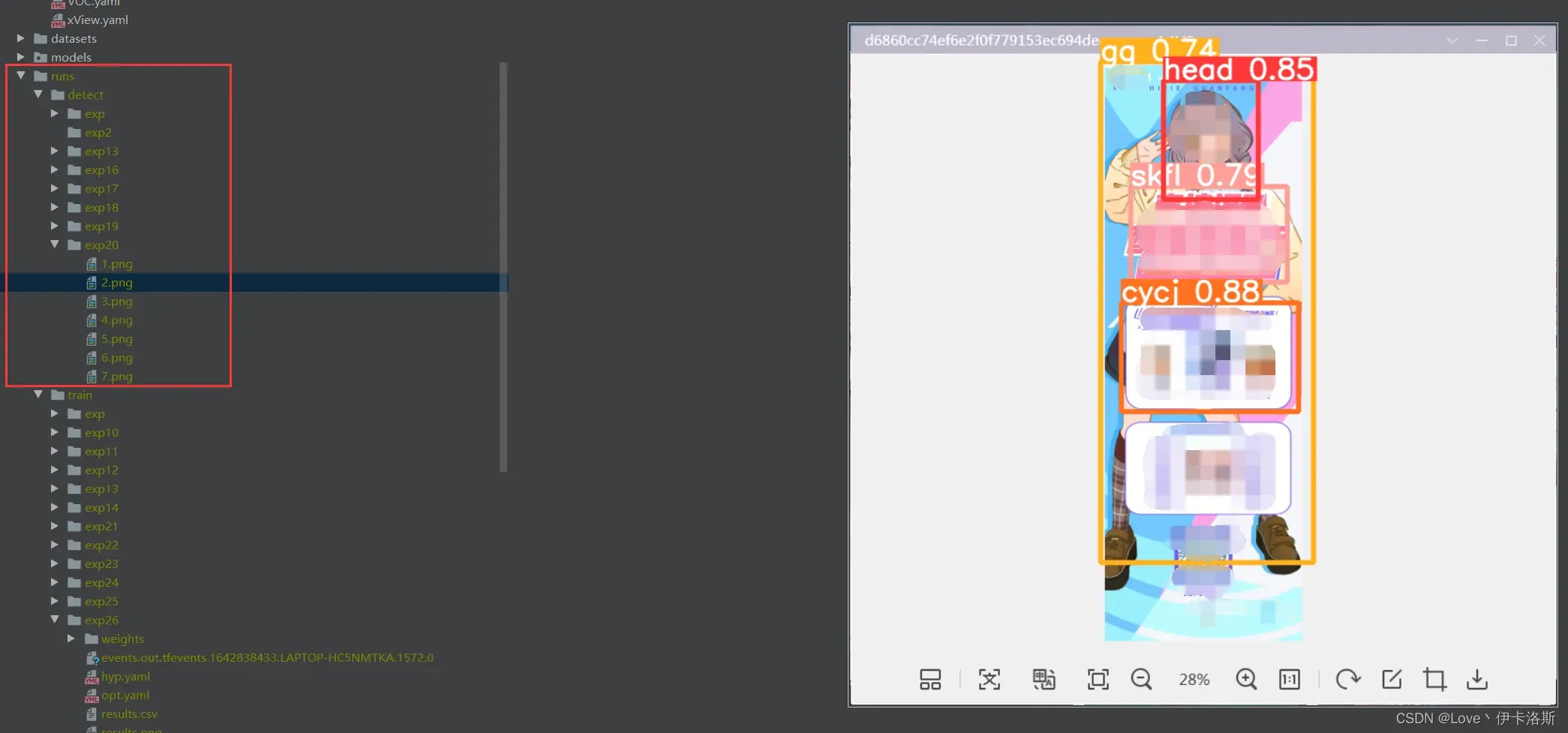
因为这个模型我已经提前锻炼过,所以 准确性较高。
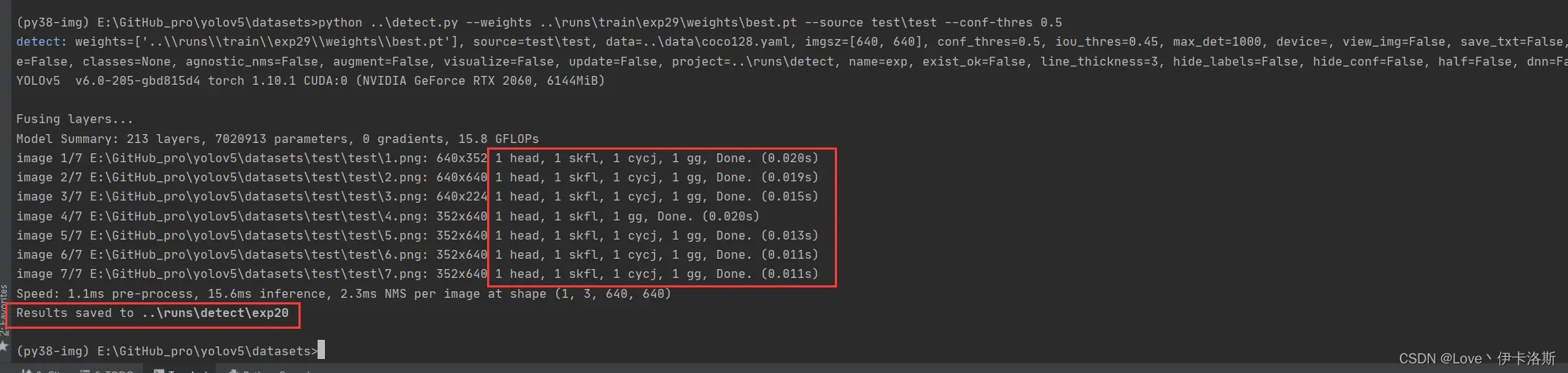
置信度还是很不错的 ,当然你刚开始训练的话,基本也就0.1差不多(粗略估计)
labelimg相关使用
下载
官方仓库:https://github.com/tzutalin/labelImg/releases
使用
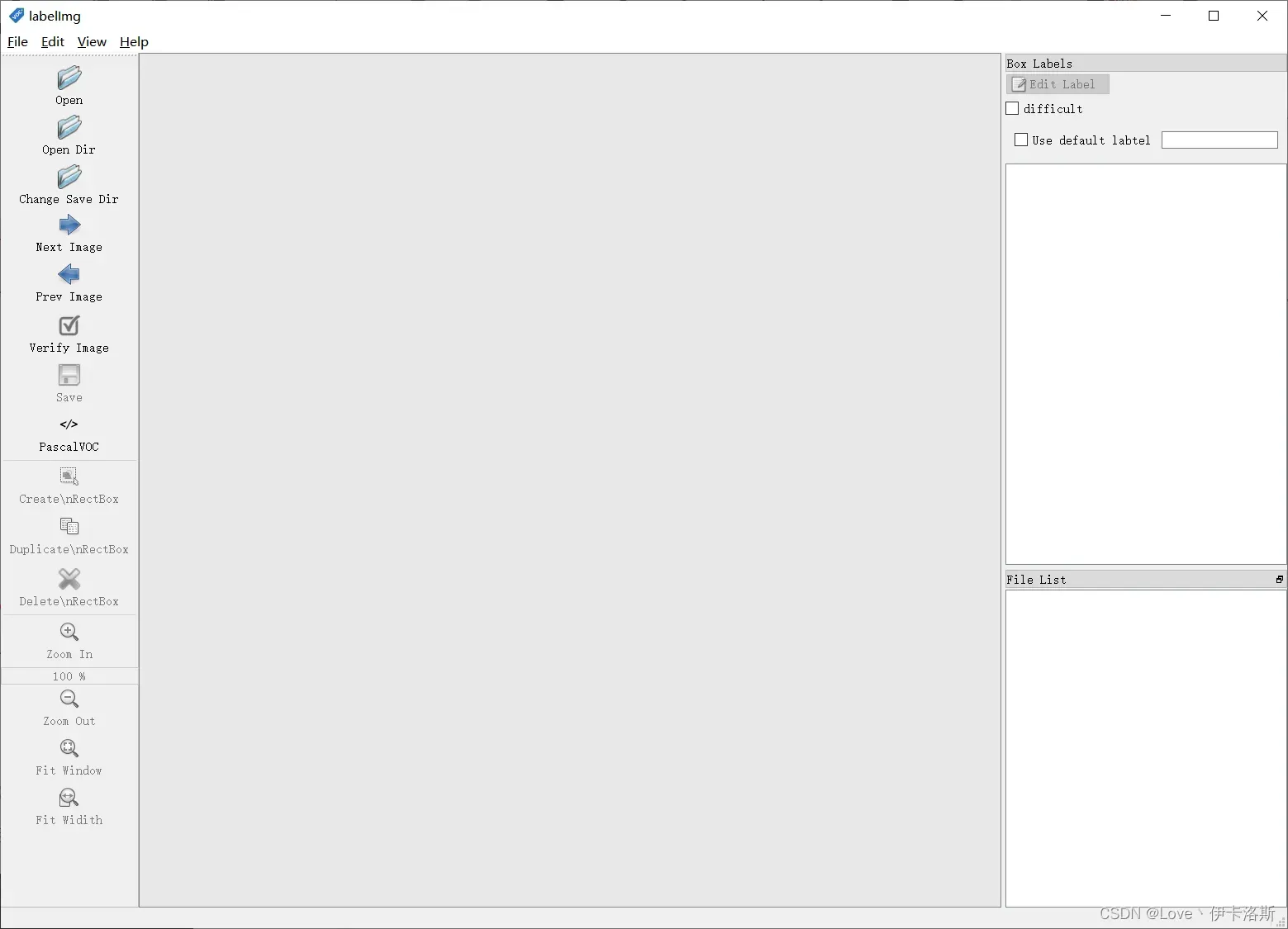
解压,运行exe
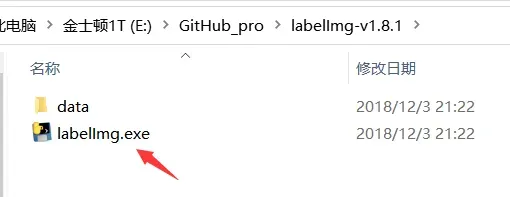
删除默认提供的类名(根据自己需要)
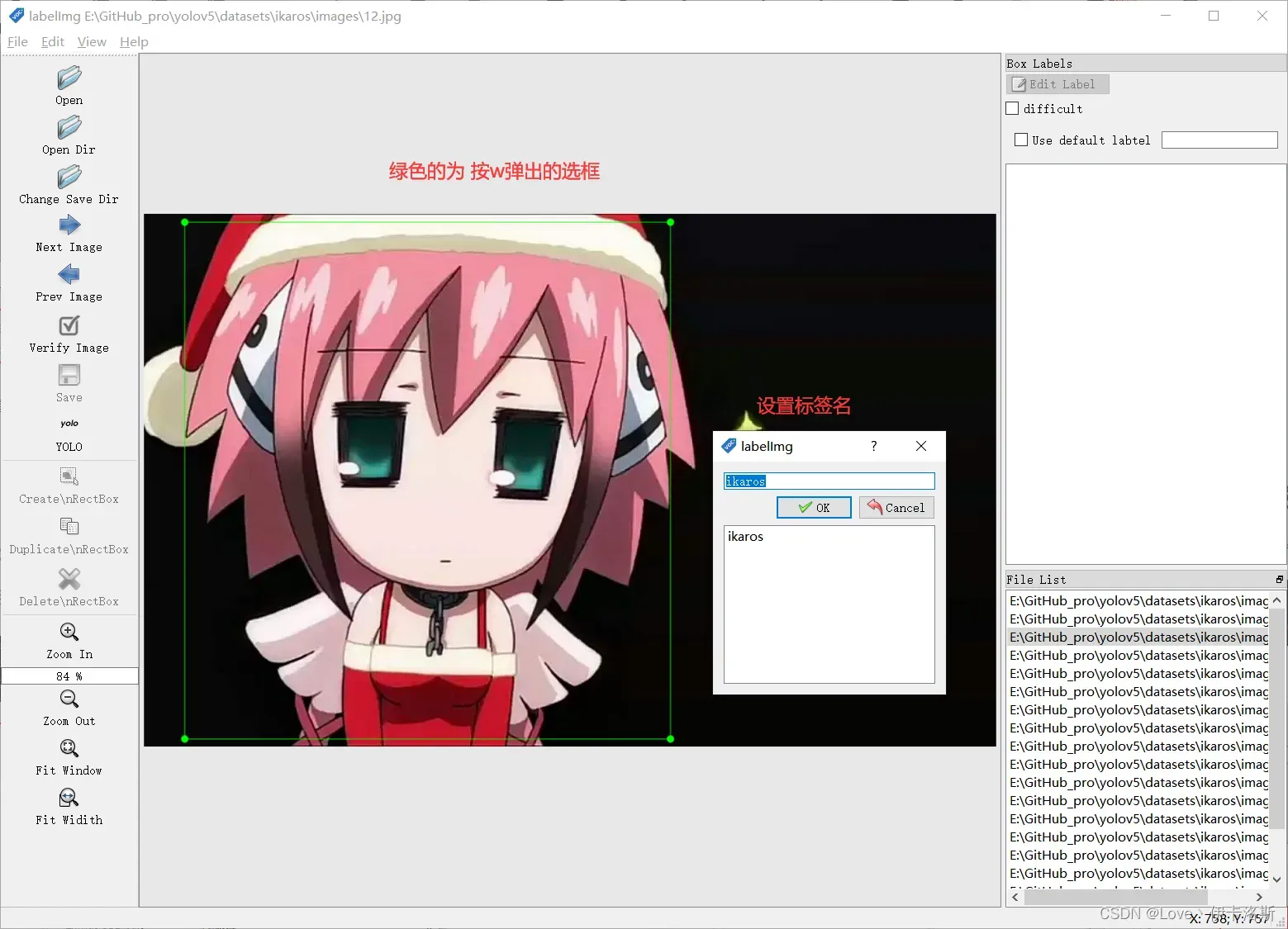
我这推荐的几个实用的快捷键
w 创建选框
a 前一张图片
d 后一张图片
ctrl+S 保存
准备需要标注的图片数据集
我这按自己喜欢的结构创建,images 和 labels 文件夹 和 yaml文件,在外面套个文件夹
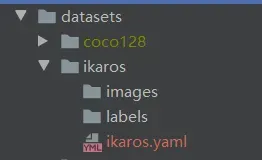
我们将要标注的原始图片放在 images文件夹内
从百度爬点图片
然后我们开始用工具进行标注,“open dir”打开我们需要标注的图片的文件夹
图片会自动加载进来
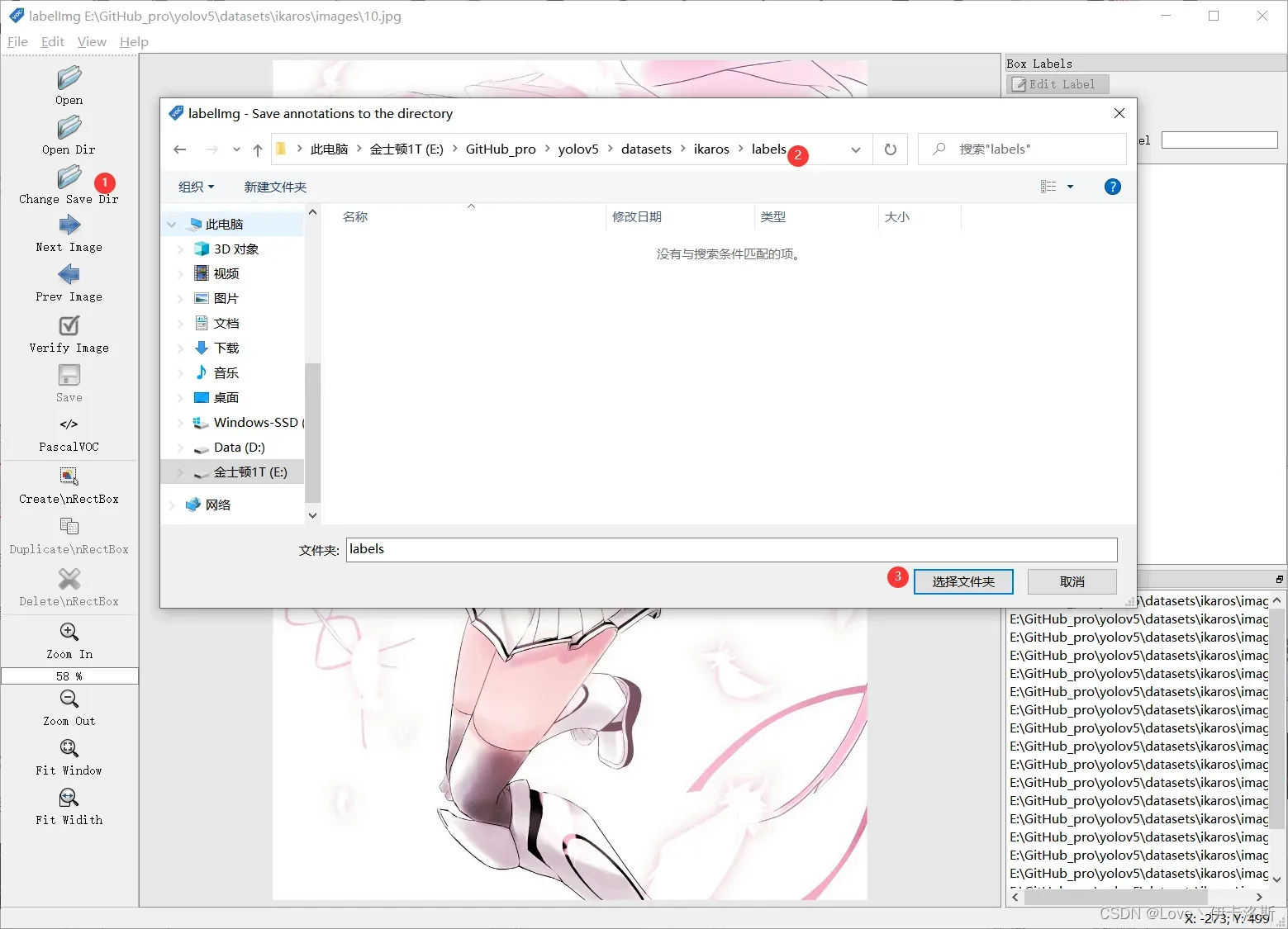
“change save dir”设置保存labels的路径为我们的 labels
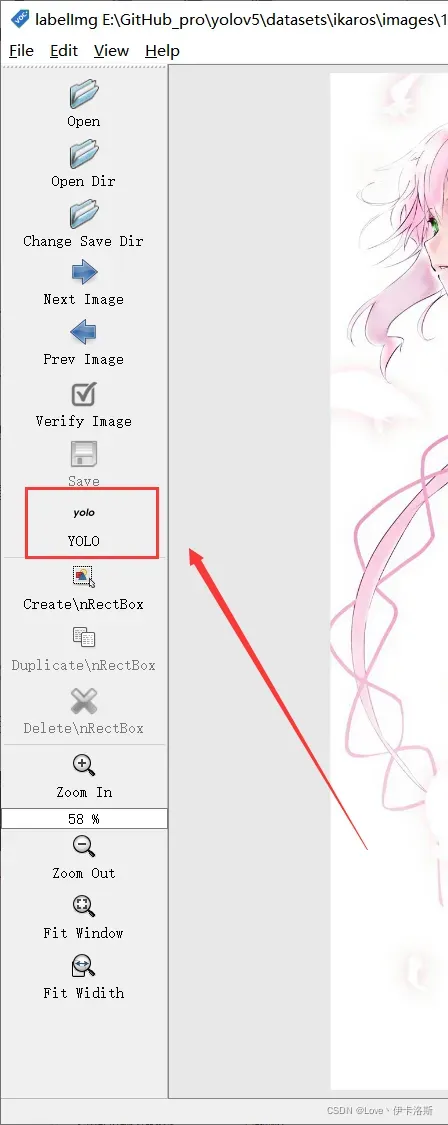
修改标注的格式为yolo(点击切换)
然后就是使用我们的快捷键 进行框选区域和打标签了。(记得保存)
标注完,保存后,生成的配置都在 对应文件夹下,classes.txt为所有的labels,其他单个文件为 对应label的参数
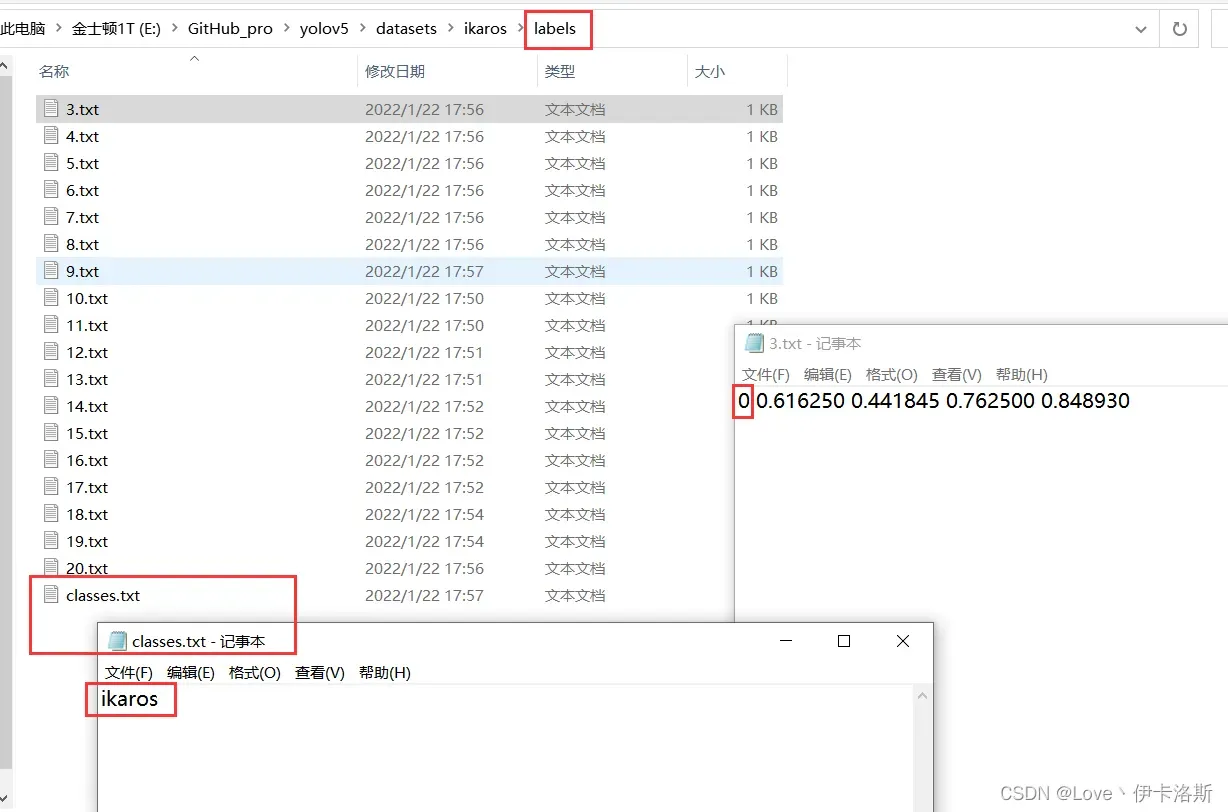
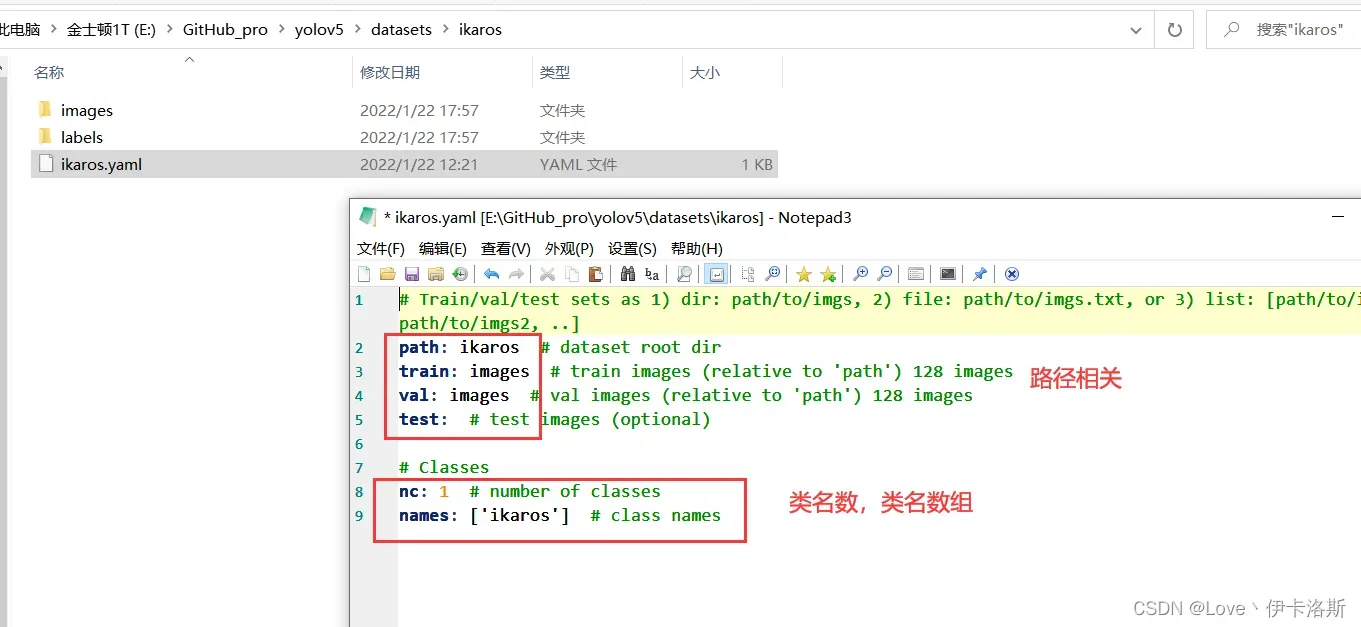
修改 yaml文件的相关配置
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ikaros # dataset root dir
train: images # train images (relative to 'path') 128 images
val: images # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 1 # number of classes
names: ['ikaros'] # class names
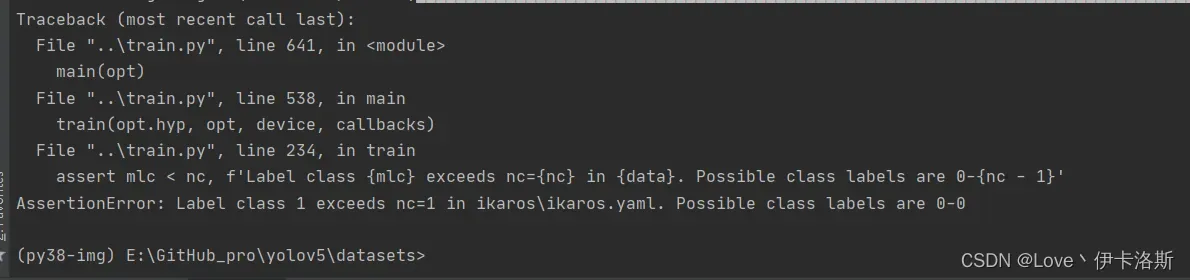
拉去训练,1组报错
追加一个类
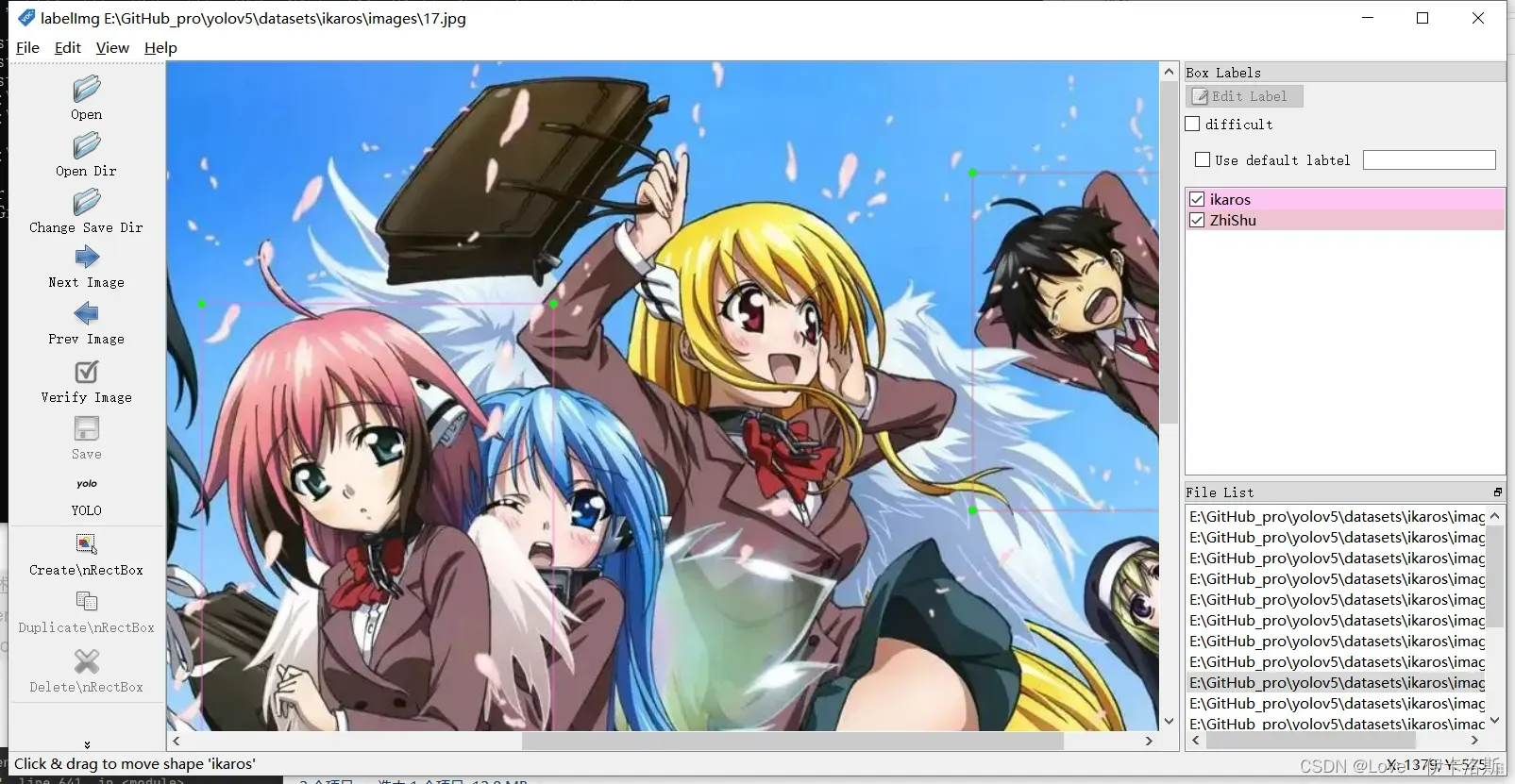
改yaml为
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ikaros # dataset root dir
train: images # train images (relative to 'path') 128 images
val: images # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 2 # number of classes
names: ['ikaros',
'ZhiShu'] # class names
从零开始的train.py训练生活
前面准备工作做好后,开始训练 先叫上GPU来100组俯卧撑(当然 你GPU兄弟累了 可以不叫他 诶嘿~)
$ cd datasets
$ python ..\train.py --data ikaros\ikaros.yaml --epochs 100 --batch-size 1 --nosave --cache
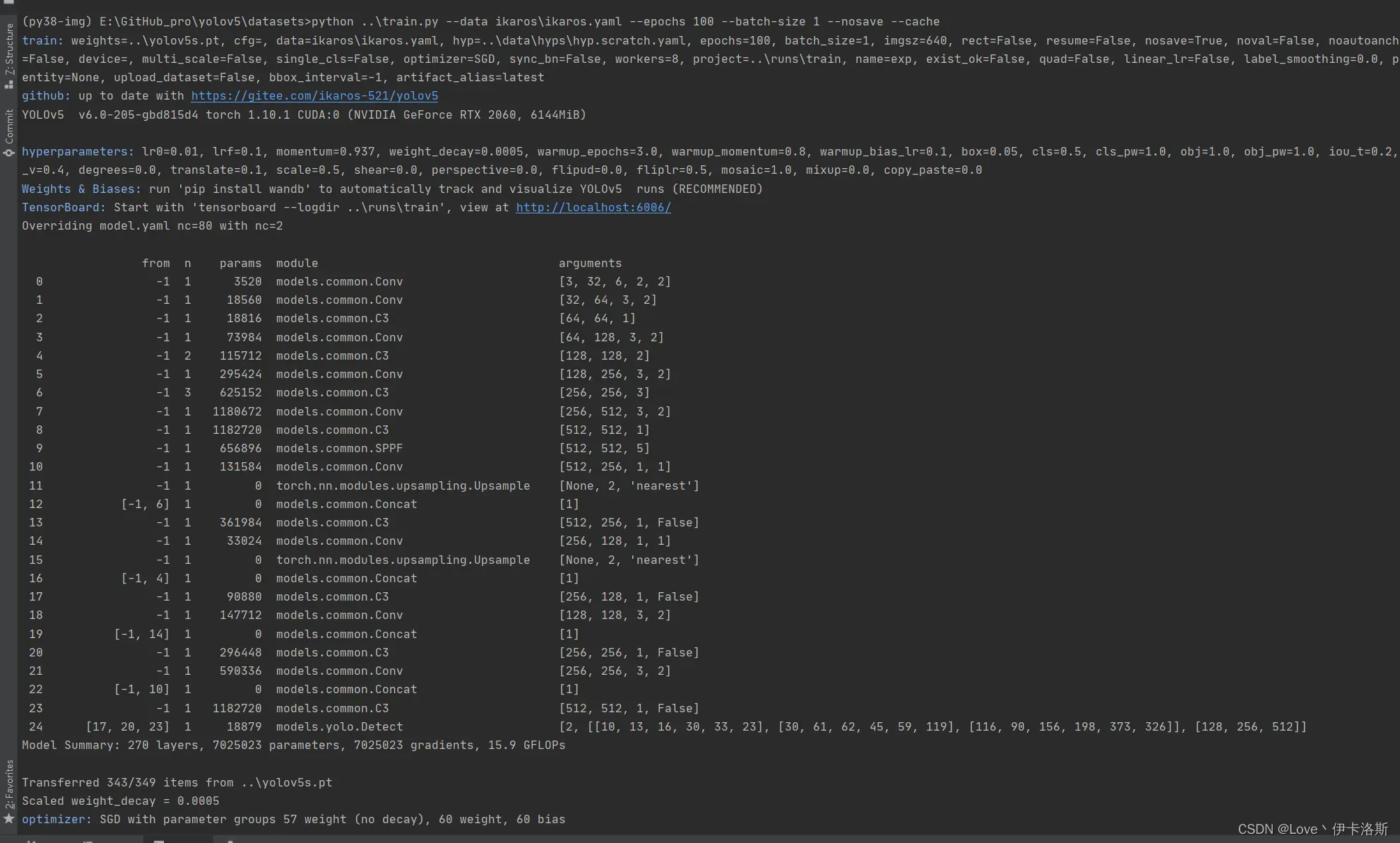
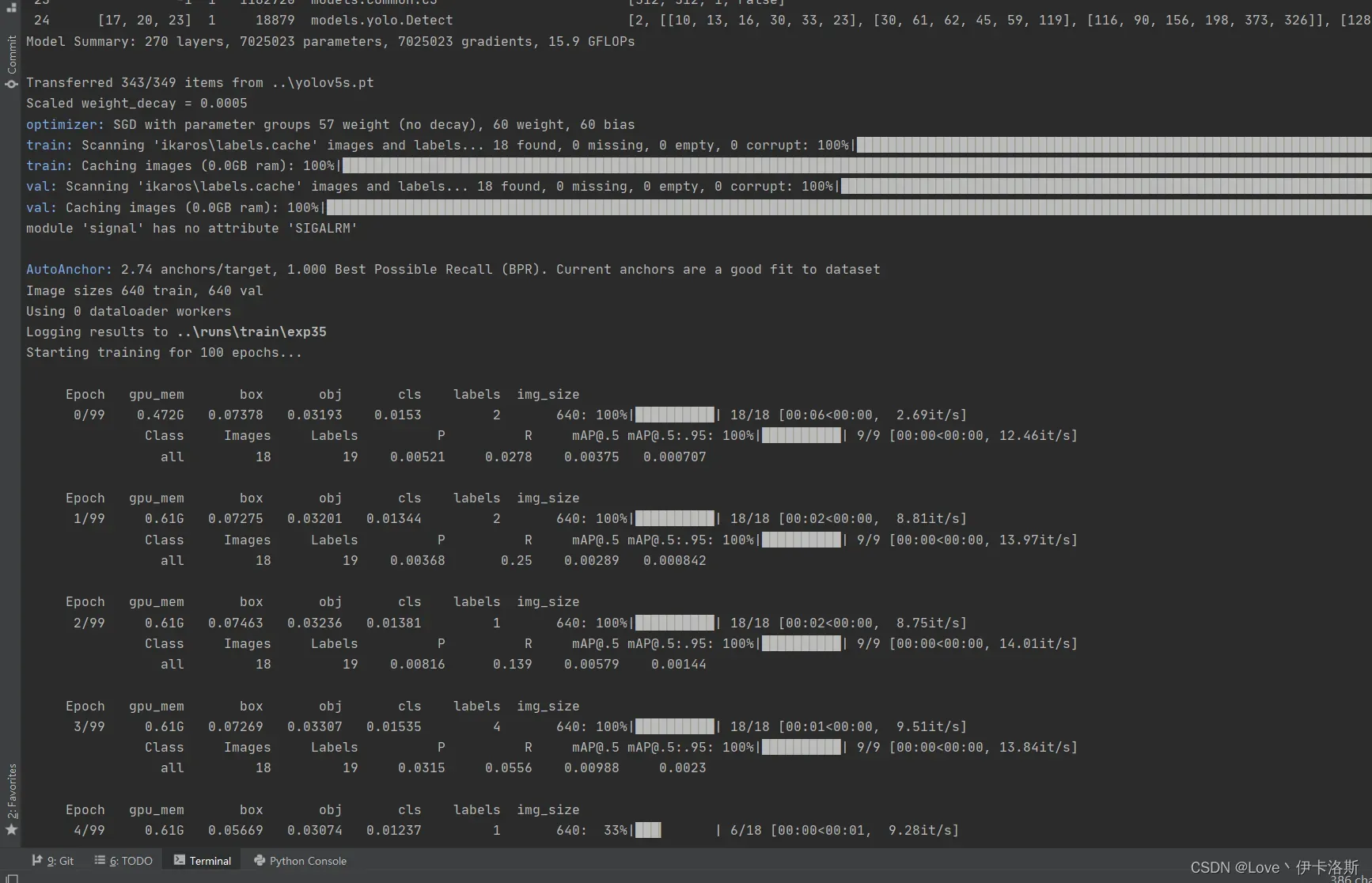
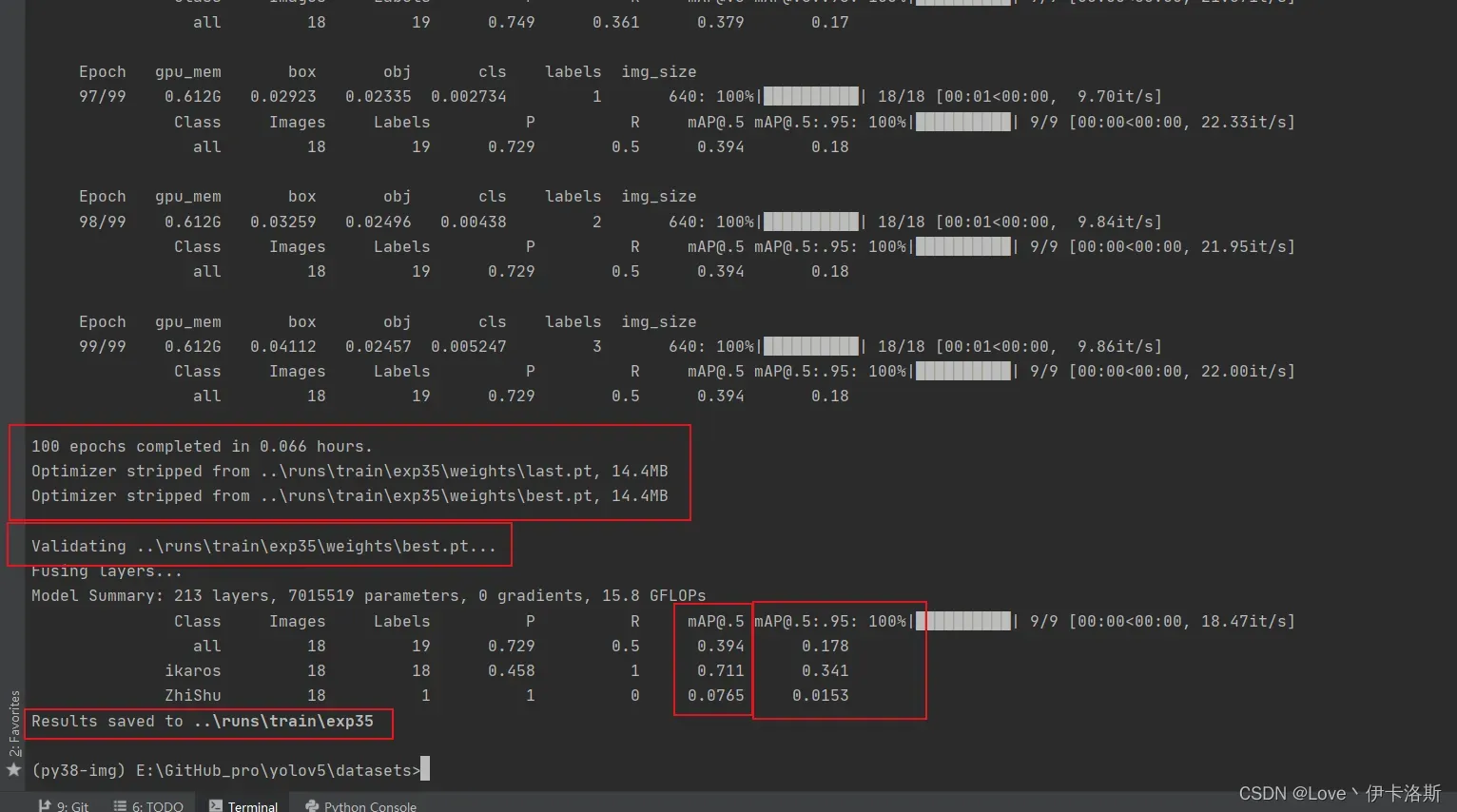
100组终于练好了。可以发现我们的锻炼结果不咋滴哈,all mAP@.5只有 0.394,没有0.5的置信度我很难办事呀,兄弟还得练哈
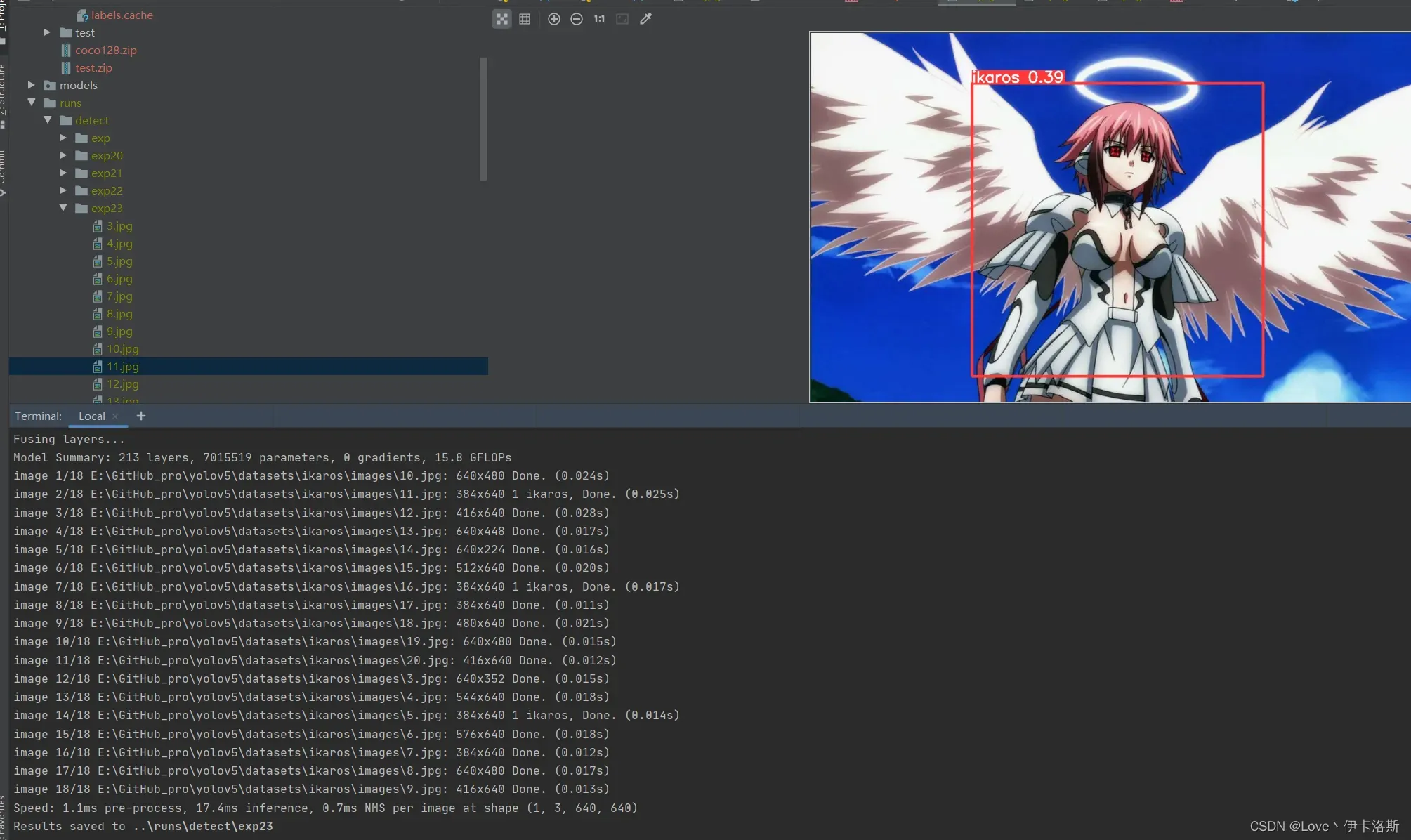
我们先拿这个练完100组的权重兄去测一测,置信度阈值设为0.3
python ..\detect.py --weights ..\runs\train\exp35\weights\best.pt --source ikaros\images --conf-thres 0.3
还行 还得多练练
置信度阈值设为0.01
python ..\detect.py --weights ..\runs\train\exp35\weights\best.pt --source ikaros\images --conf-thres 0.01
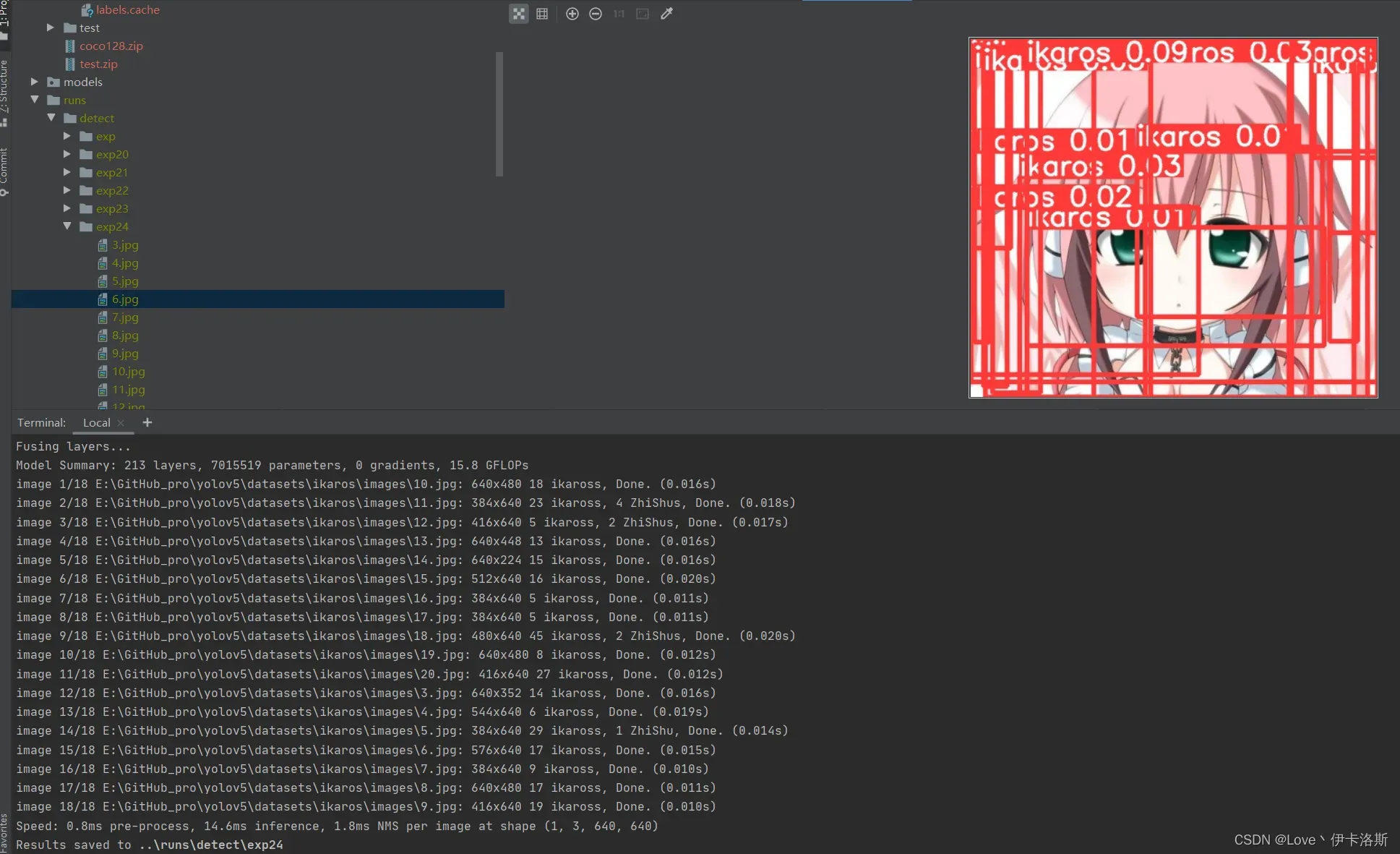
差不多了 在多练练。前面练好的pt不要丢,叫上继续训练 再来100组
python ..\train.py --data ikaros\ikaros.yaml --epochs 100 --weights ..\runs\train\exp35\weights\best.pt --batch-size 1 --nosave --cache
再次 测试 python ..\detect.py --weights ..\runs\train\exp36\weights\last.pt --source ikaros\images --conf-thres 0.5,差不多得了,有兴趣接着练
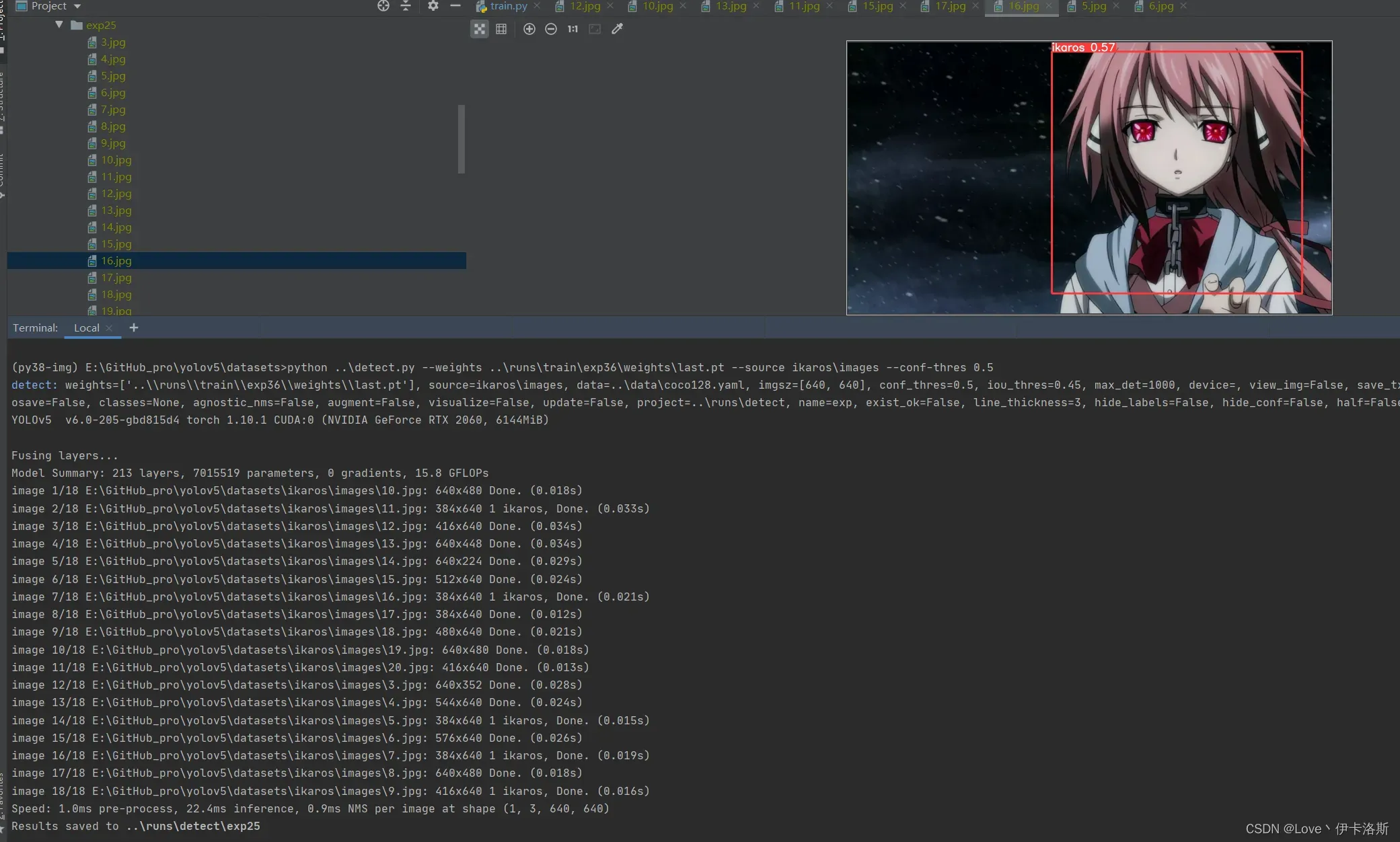
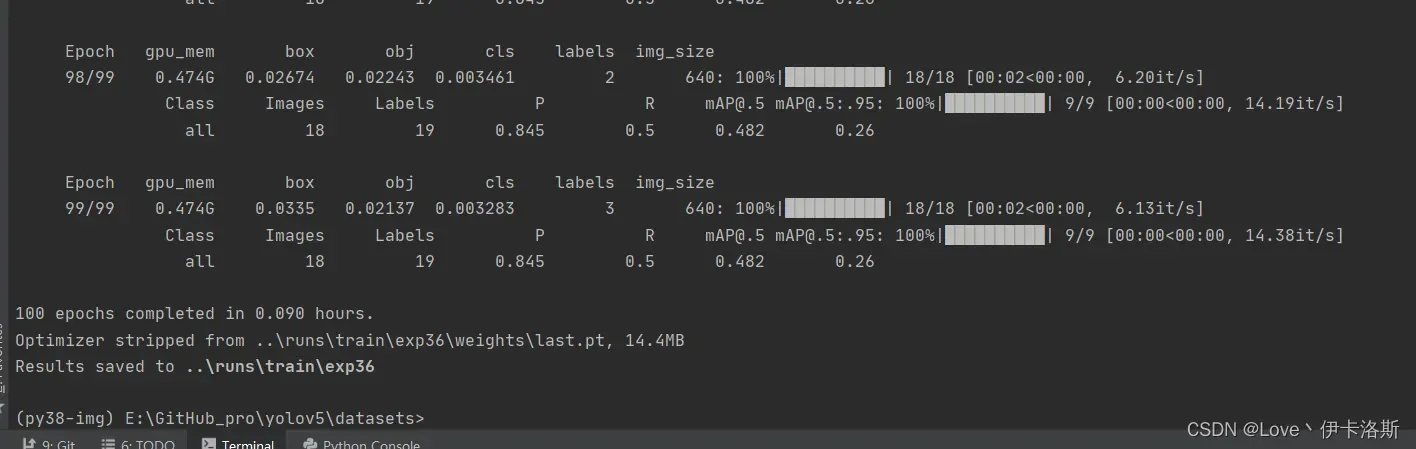
增加了样本数,继续锻炼
python ..\train.py --data ikaros\ikaros.yaml --epochs 100 --weights ..\runs\train\exp36\weights\last.pt --batch-size 1 --workers 4 --nosave --cache
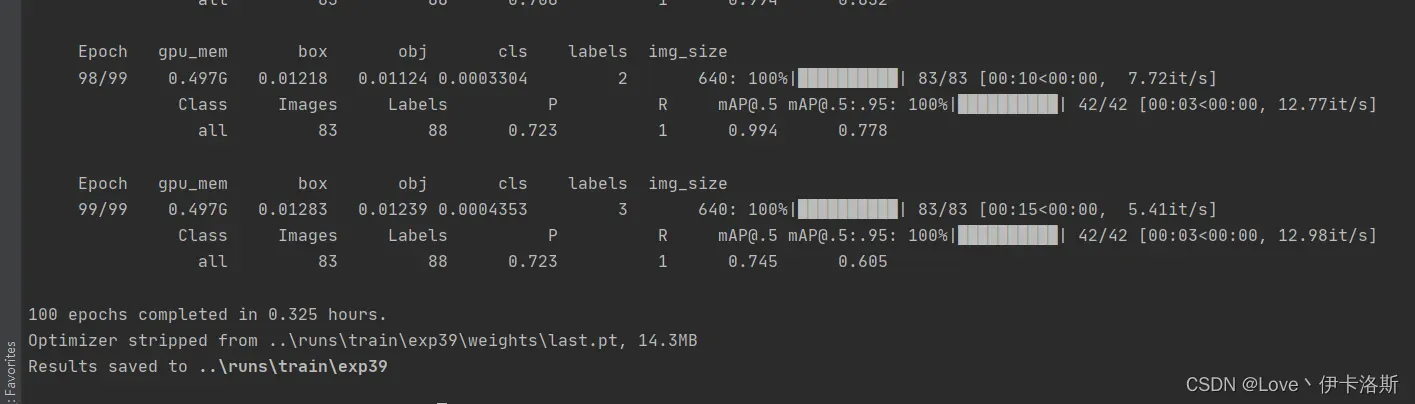
mAP@.5 0.745 效果不错了
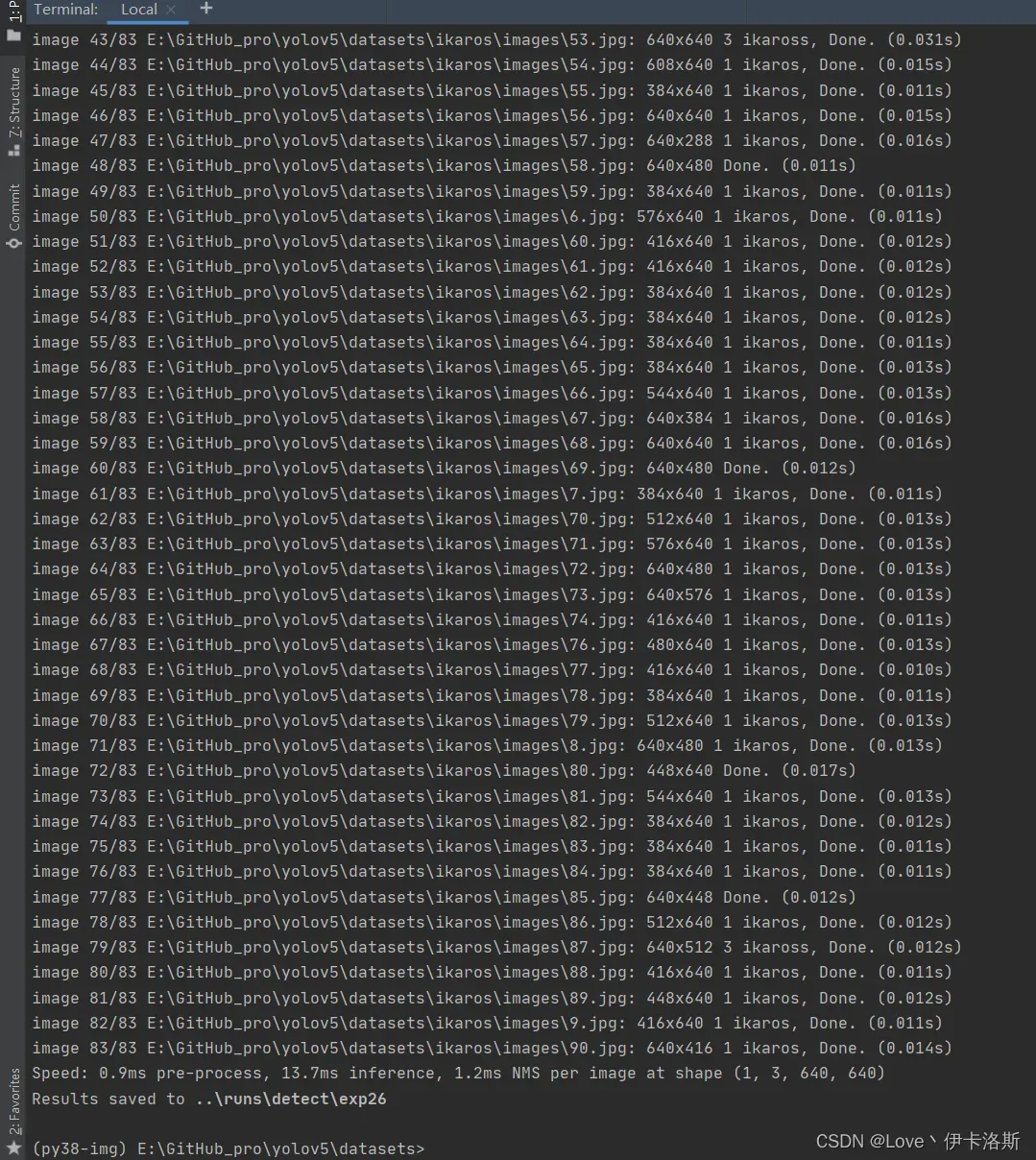
找个视频识别下
python ..\detect.py --weights ..\runs\train\ikaros\ikaros.pt --source ..\data\videos\FallenDown.mp4
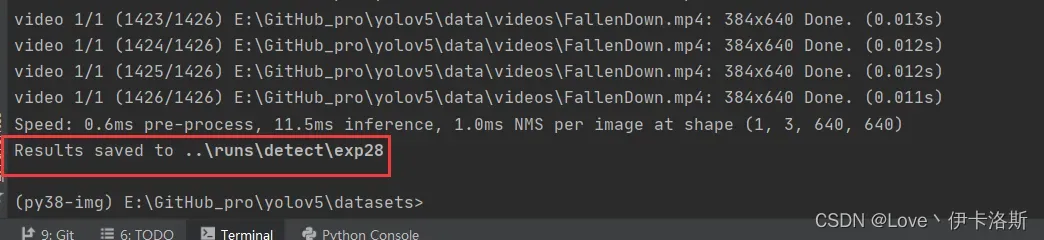
报错相关
RuntimeError: [enforce fail at …\c10\core\CPUAllocator.cpp:76] data. DefaultCPUAllocator: not enough memory: you tried to allocate 131072000 bytes.
申请内存过多,没有足够的内存了。
解决方案:同样也是 调小 –batch-size 和 –workers
参考命令:
python ..\train.py --data ..\data\coco128.yaml --epochs 3 --batch-size 1 --workers 1 --img 128
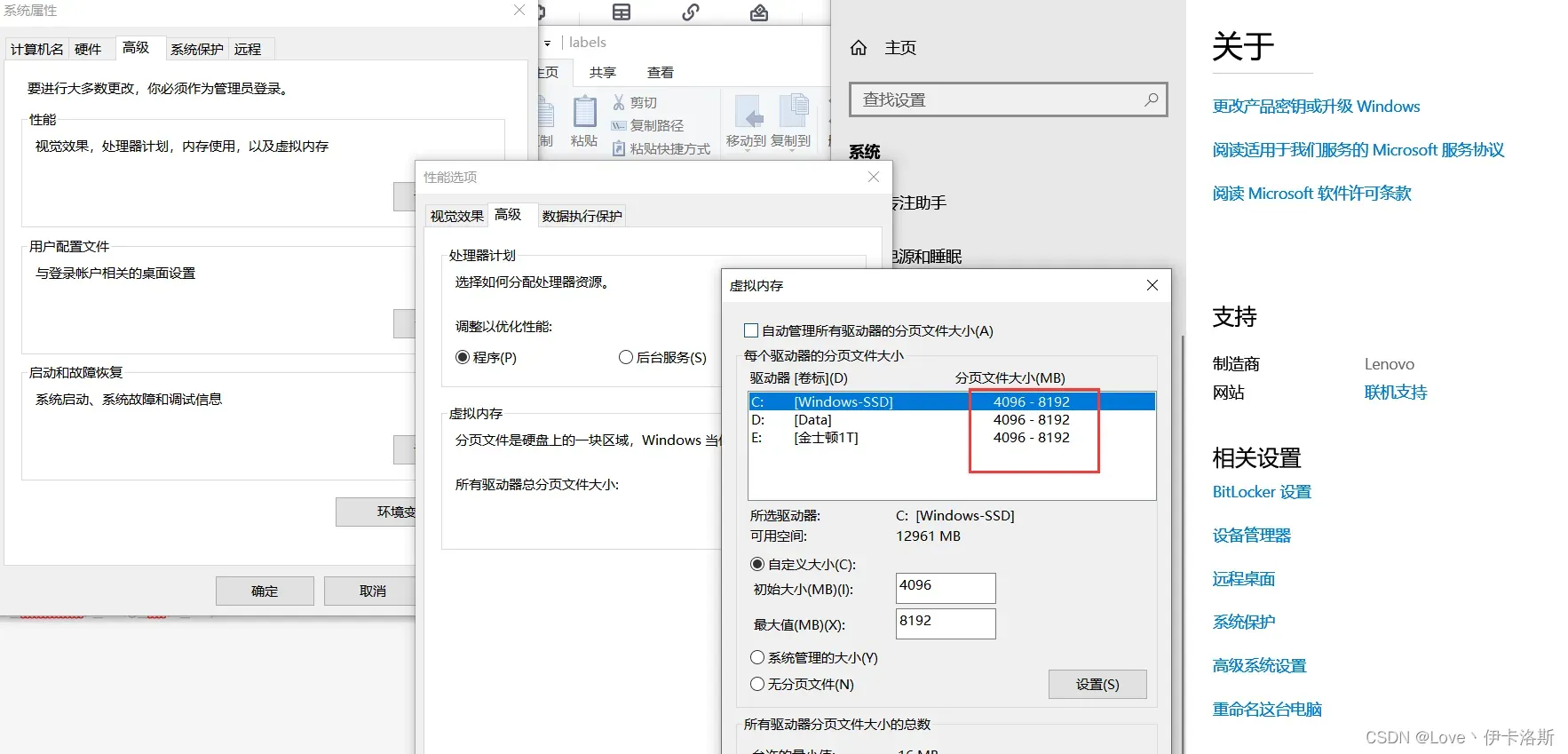
报错 OSError: [WinError 1455] 页面文件太小,无法完成操作。
增加分配虚拟内存,然后重启。调小 –batch-size,或者改 –batch-size -1 自动识别(不过我这就经常崩溃)
减小 –workers


# 我的显卡是RTX2060 测了几套下来,基本上--batch-size 2 --workers 8 不能再高了
python ..\train.py --data ikaros\ikaros.yaml --epochs 100 --weights ..\runs\train\exp36\weights\last.pt --batch-size 1 --workers 4 --nosave --cache
不吃GPU 实则环境错误的情况
基本会报错 UserWarning: User provided device_type of 'cuda', but CUDA is not available.
看看 CUDA 相关环境是否装好;看 pytorch版本是否匹配,是否错装了 cpuonly版;命令是否写错了
版权声明:本文为博主Love丶伊卡洛斯原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Ikaros_521/article/details/122636499