基于深度学习的人体姿态估计研究综述
摘要: 人体姿态估计的目的是定位人体部位,并从图像和视频等输入数据中建立人体表示(如人体骨架)。近十年,人体姿态估计越来越受关注,并被广泛应用于人机交互、运动分析、增强现实和虚拟现实等领域。尽管基于深度学习的解决方案在人体姿态估计方面取得了很高的性能,但由于 训练数据不足、深度模糊和遮挡 使人体姿态估计仍存在挑战。本文通过系统性分析和比较姿态估计方案的输入数据和推理过程,全面回顾基于深度学习的 2D 和 3D 姿态估计解决方案。本次调查涵盖2014年以来的240多篇研究论文。此外,本文还包括 2D 和 3D 人体姿态估计数据集和评估指标。本文总结并讨论了常用数据集上已评估方法的定量性能比较。最后,本文总结了姿态估计所面临的挑战、应用和未来的研究方向。我们还提供定期更新的项目页面:https://github.com/ZCW/DL-HPE
1. Introduction
人体姿态估计(Human Pose Estimation: HPE)涉及从传感器,特别是图像和视频捕获的输入数据中估计人体部位的结构,它在计算机视觉领域被广泛研究。HPE提供人体的几何和运动信息,已被广泛应用于各种应用(如人机交互、运动分析、增强现实(AR)、虚拟现实(VR)、医疗保健等)。近年来,深度学习在图像分类、语义分割和目标检测等任务中的表现都优于经典的计算机视觉方法。虽然在HPE任务中采用深度学习技术已经取得了显著的进步和成绩,但仍然存在遮挡、训练数据不足和深度模糊等挑战。从带有2D姿态标注的图像和视频中提取2D HPE是很容易实现的,并且基于深度学习的单人姿态估计已达到了很高的性能。 目前,大多研究关注复杂场景下遮挡的多人姿态估计。 相比之下,对于3D HPE而言,获得精确的 3D 姿态标注要比2D困难得多,运动捕捉系统可以在受控的实验室环境中收集3D姿态标注,但它们在野外环境会受到局限。基于单目RGB图像和视频的 3D HPE 的主要挑战是深度模糊。 在多视图设置中,需要解决的关键问题是视点关联。一些工程使用深度传感器、惯性测量单元(inertial measurement units: IMUs)和射频设备进行 3D HPE,但这些方法通常成本较高,且需要特殊用途的硬件。
鉴于 HPE 研究的快速发展,本文试图追踪最新进展并总结其成果,以便清晰了解当前基于深度学习的 2D 和 3D HPE 研究进展。
1.1 Previous surveys and our contributions 先前的调查与我们的贡献
表1列出了先前的HPE survey。
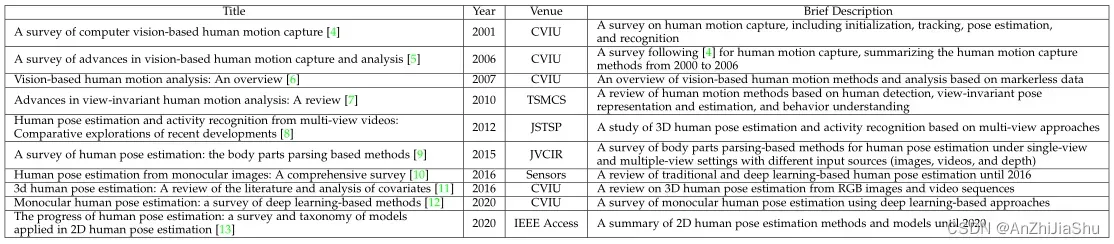
其中,[4] [5] [6] [7] 主要研究基于视觉的人体运动捕捉方法及其实现,包括姿态估计、姿态跟踪和动作识别,因此,姿势估计只是这些调查中涉及的主题之一。[8] 回顾了2012年之前的3D人体姿态估计研究工作。[9] 报告了基于身体部位解析方法的单视图和多视图 HPE。2001-2015年间发布的这些调查主要关注传统而非基于深度学习的视觉方法。[10] 介绍了传统的HPE方法和基于深度学习的HPE方法,但介绍的基于深度学习的方法较少。[11] 调查了涵盖 RGB 输入的3D HPE方法。[13] 仅仅回顾 2D HPE 方法以及分析模型解释。[12] 总结了从经典到最新的基于深度学习方法(直到2019年)的单目HPE,但它仅涵盖单目图像/视频中的2D HPE和3D单视图HPE,也没有给出广泛的性能比较。
本 survey 旨在解决之前 survey 的不足:系统回顾了最近基于深度学习的2D和3D HPE解决方案,其在主流的2D、3D数据集上的性能评估,其应用和综合讨论。本 survey 与先前 survey 的主要区别如下:
- 通过根据2D或3D场景、单视图或多视图、单目图像/视频或其他来源以及学习范式对最近的基于深度学习的2D和3D HPE方法(截至2020年)进行分类,对其进行全面回顾。
- 2D 和 3D HPE方法的广泛性能评估。我们总结并比较了 promising 方法在常用数据集上的性能。比较结果为不同方法的优缺点提供了线索,揭示了 HPE 的研究趋势和未来方向。
- 概述了各种HPE应用,如游戏、监控、AR/VR和医疗保健。
- 针对 HPE 面临的主要挑战,对 2D 和 3D HPE 进行了深入的讨论,指出了未来提高性能的潜在研究方向。
这些贡献使本 survey 比以前的 survey 更全面、更新和更深入。
1.2 Organization 全文组织
在以下几节中,我们将介绍 HPE 与深度学习的最新进展。
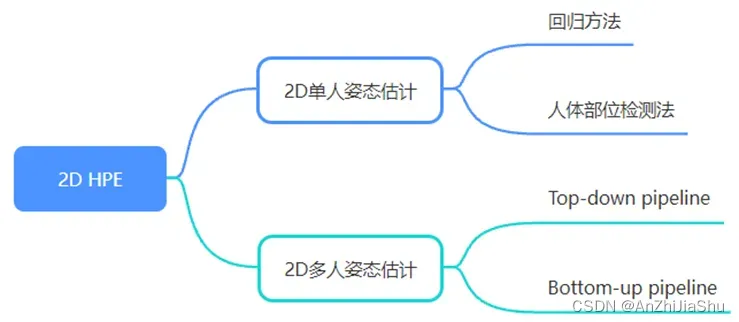
首先,我们在 §2 中概述了人体建模技术。然后,我们将 HPE 分为两大类:2D HPE (§3) 和3D HPE (§4) 。图1展示了深度学习 HPE 方法的分类。2D HPE方法分为 2D 单人 HPE和 3D 多人 HPE。
基于深度学习的 2D 单人 HPE 方法 (§3.1) 可分为两类:
- 回归法: 使用基于深度学习的回归器,直接建立从输入图像到身体关节的坐标映射;
- 身体部位检测法: 包括两个步骤:(1) 生成用于定位身体部位的关键点(即关节)热图;(2) 将检测到的关键点组装成全身姿态或骨架。
基于深度学习的 2D 多人HPE 方法 (§3.2) 也分为两类:
- top-down 法: 先检测人,然后利用单人HPE预测每个人的关键点来构造人体姿态。
- bottom-up法: 在人数未知的前提下,先检测所有人体关键点,然后将关键点分组为每个人的姿态。
根据输入源类型将 3D HPE 分成单目RGB图像和视频法 (§4.1) 或其他传感器法(例如惯性测量单元传感器,§4.2)。这些方法大多使用单目 RGB 图像和视频,并进一步分为单视图法和多视图法,然后将单视图法按单人与多人分开,多视图主要用于多人姿态估计,因此,该类别未指定单人或多人。
接下来,根据 2D 和 3D HPE pipeline,本文总结常用的数据集和评估指标,然后比较优越方法的结果 (§5) 。此外,本问还提到了HPE的各种应用,如AR/VR(§6),最后,本文对未来的研究方向进行了深入讨论(§7)。

2. Human body modeling 人体建模
人体建模能够表示从输入数据中提取的关键点和特征,是 HPE 重要的一部分。例如,大多数 HPE 方法使用 N-关节刚体运动学模型。人体是一个具有关节和四肢的复杂实体,包含身体运动学结构和身体形状信息。典型的方法使用基于模型的方法来描述和推断人体姿态,并渲染二维和三维姿态。如图2所示,人体建模通常有三种模型:kinematic model 运动学模型(用于2D/3D HPE);planar model 平面模型(用于2D HPE)和 volumetric model 体积模型(用于3D HPE)。在以下章节中,将介绍这些模型的不同表示形式。
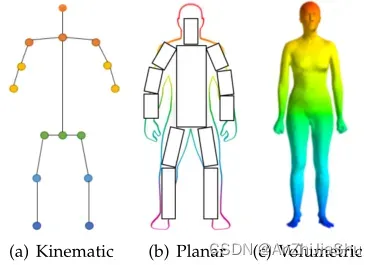
2.1 Kinematic model 运动学模型
如图2(a) 所示,运动学模型也称为基于骨架的模型或运动学链模型,以一组关节位置和肢体方向来表示人体结构。运动学模型能捕捉不同身体部位之间的关系。图形结构模型(pictorial structure model PSM),也叫树结构模型,是一种使用广泛的图形模型。这种灵活直观的人体模型已成功应用于 2D HPE 和 3D HPE。虽然运动学模型具有灵活的图形表示的优点,但它在表示纹理和形状信息方面受限。
2.2 Planar model 平面模型
如图2(b) 所示,平面模型用于表示人体的形状和外观。在平面模型中,身体部位通常由近似人体轮廓的矩形表示。一个例子是纸板模型 (cardboard model),它由表示人四肢的身体部分矩形组成。另一个例子是 Active Shape Model (ASM),它广泛用于通过主成分分析(PCA)捕捉完整的人体图和轮廓变形。
2.3 Volumetric models 体积模型
体积模型表示如图2(c)所示。随着人们对三维人体重建越来越感兴趣的,许多人体模型被提出用于各种各样的人体形状。我们简要讨论了几种常用的三维人体模型,这些模型用于基于深度学习的 3D HPE方法来恢复 3D 人体网格。
SMPL: Skinned Multi-Person Linear model 表皮多人线性模型 是一种基于表皮顶点的模型,代表了广泛的人体形状,用表现自然姿态变形的软组织动力学来建模SMPL。为了了解人体如何随姿态变形,SMPL中有1786个高分辨率3D扫描,使用模板网格对不同姿态进行扫描来优化混合权重、姿态相关的混合形状、平均模板形状,以及从顶点到关节位置的回归器。SMPL易于部署,并能与现有的渲染引擎兼容,因此在 3D HPE 中应用广泛。
DYNA: Dynamic Human Shape in Motion 动态人体形状: 该模型试图表示各种人体形状的真实软组织活动。低维线性子空间用于近似运动相关的软组织变形,软组织运动的低维线性系数用全身的速度和加速度、身体部位的角速度和加速度以及软组织形状系数来预测。此外,DYNA利用体重指数(BMI)为不同体型的人产生不同的变形。
Stitched Puppet Model 缝合木偶模型: 缝合木偶模型是一种基于部位的图形模型,与真实的身体模型相结合。不同的 3D 人体形状和姿态相关的形状变化可以转换为相应的图形节点表示,每个身体部位都由自己的低维状态空间表示。身体各部位通过图中节点之间的成对潜在连接被 “缝合” 在一起,通常,用于部位连接的 potential 函数是通过消息传递算法,如 Belief Propagation (BP) 来执行的。每个部位的状态空间不易离散化导致离散BP应用困难,因此采用基于粒子的 D-PMP 模型的最大乘积BP。
Frankenstein & Adam: The Frankenstein model: Frankenstein 模型不仅为身体运动,而且为面部表情和手势生成人体运动参数。该模型是通过混合各个组件网格的模型生成的:SMPL 用于身体,FaceWarehouse 用于面部,以及一个艺术装配用于手部。所有变换骨骼都合并到单个骨骼层次中,而每个组件原有的参数化保持不变,以表达 identity (猜测指的是 身体、脸、手)和运动变化。Adam 模型是由 Frankenstein 模型优化的,该模型使用了对人们衣服的大规模捕捉。Adam能够表示人类头发和衣服的几何图形,因此更适合在真实世界条件下表示人类。
GHUM & GHUML(ite): 一篇论文提出了一种完全可训练的端到端深度学习pipeline,用于对统计和关节式三维人体形状和姿态进行建模。GHUM是中等分辨率版本,GHUML是低分辨率版本。GHUM和GHUML通过高分辨率全身扫描(其数据集中超过60000种不同的人体配置)在深度可变自动编码器框架中进行训练,他们能够推断出一系列组件,例如非线性形状空间、姿态空间变形修正、骨骼关节中心估计器和混合蒙皮功能
3. 2D Human pose eatimation
2D HPE 是从图像或视频中估计人体关键点的2D位置或空间位置。传统的2D HPE法对身体部位采用不同的手工特征提取技术,这些早期工作将人体描述为一个棒状图(stick figure)来获得全局姿态结构。最近,基于深度学习的方法显著提高了 HPE 的性能,取得了重大突破。下文回顾了基于深度学习的2D HPE方法在单人和多人场景中的应用。
3.1 2D single-person pose estimation 2D单人姿态估计
当输入为单人图像时,2D 单人姿态估计用于定位人体关节位置。如果有多个人,则先裁剪输入图像,使每个裁剪的patch(或子图像)中只有一个人,这个过程可以通过上身检测器 (upper-body detector) 或全身检测器 (full-body detector) 自动实现。一般来说,深度学习技术 2D 单人 HPE pipeline 可分为两类:回归法和身体部位检测法。回归法应用端到端框架来学习从输入图像到人体关节或人体模型参数的映射;身体部位检测法的目标是预测身体部位和关节的大致位置,通常由热图表示进行监督。现在的2D HPE任务广泛应用基于热图的框架。2D单人HPE法的一般框架如图3所示。
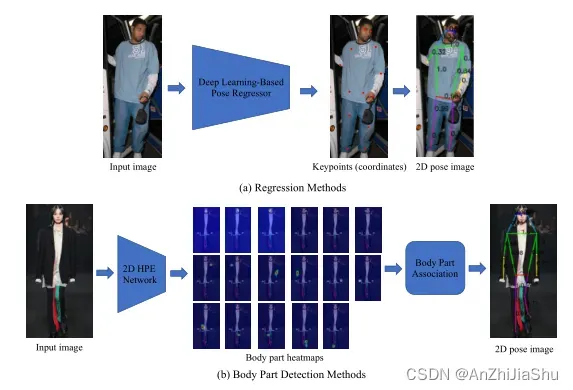
图3: 单人2D HPE框架。(a) 回归方法直接学习(通过深度神经网络)从原始图像到运动学身体模型的映射,并生成关节坐标。(b) 身体部位检测方法使用热图监督来预测身体关节位置。
3.1.1 Regression methods 回归法
有许多基于回归框架的工作利用图3(a)所示的 pipeline 预测关节坐标。以AlexNet 为 backbone,Toshev 和 Szegedy 提出级联深层神经网络回归器 DeepPose ,用于从图像中学习关键点。由于 DeepPose 优越的性能,HPE的研究范式开始从经典方法转向深度学习,尤其是卷积神经网 CNN。Carreira等人基于 GoogLeNet 上提出了一种迭代误差反馈网络( Iterative Error Feedback IEF),这是一种自校正模型,通过将预测误差注入输入空间来逐步改变初始解。Sun等人介绍了一种基于 ResNet-50 的结构感知回归(structure-aware regression)方法:合成姿态回归(compositional pose regression),该方法采用了一种包含人体信息和姿态结构的重新参数化和基于骨骼的表示,而非传统的基于关节的表示。Luvizon 等人提出了一种用于 HPE 的端到端回归方法,使用 soft argmax 函数在完全可微框架中将特征映射转换为关节坐标。
对基于回归的方法来说,编码丰富的姿态信息至关重要。学习更好的特征表示的一种流行策略是多任务学习,通过在相关任务(如姿态估计和基于姿态的动作识别)之间共享表示,模型可以更好地概括原始任务(姿态估计)。按照这个思路,Li 等人提出了一个异构多任务框架 (heterogeneous multi-task framework),该框架由两个任务组成:① 构建从完整图像中预测关节坐标的回归器;② 使用滑动窗口从图像 patch 中检测身体部位。Fan 等人提出了一种双源(即图像 patch 和完整图像)深度卷积神经网络(Dual-Source Deep Convolutional Neural Network DS-CNN),包含两项任务:①关节检测:确定patch是否包含身体关节;②关节定位:确定关节在patch中的确切位置。每项任务对应一个损失函数,组合这两项任务能产生更好的结果。Luvizon等人研究了一个多任务网络,以联合处理来自视频序列的2D/3D姿态估计和动作识别。
3.1.2 Body part detection methods 身体部位检测法
HPE的身体部位检测法旨在训练身体部位检测器来预测身体关节的位置。最近的检测方法将姿态估计作为热图预测问题来处理, 具体而言,其目标是估计出 K 张关键点的热图 ,每张关键点热图中的像素值
表示关键点位于位置 (x, y) 的概率(参见图3(b))。目标热图(即 ground truth热图)由以 ground truth 关节位置为中心的2D高斯分布生成。通过最小化预测热图和目标热图之间的差异(例如,均方误差(MSE))来训练姿态估计网络。
相比关节坐标,热图通过保留空间位置信息,为卷积网络的训练提供了更丰富的监督信息。 因此,人们对利用热图来表示关节位置和为HPE开发有效的CNN架构越来越感兴趣。Tompson等人将基于CNN的身体部位检测器与基于部位的空间模型相结合,形成了2D HPE的统一学习框架。Lifshitz等人提出了一种基于CNN预测关节位置的方法,它结合关键点 votes 和关节概率来确定人体姿态表示。Wei 等人介绍了一种基于卷积网络的顺序框架:卷积姿势机(Convolutional Pose Machines CPM),通过多阶段处理预测关键关节的位置(每个阶段的卷积网络利用前一阶段生成的2D置信图,并生成逐渐精细化的身体部位位置预测)。Newell等人提出了一个 “堆叠沙漏(stacked hourglass SHG)”编码器-解码器网络(该网络中的编码器通过bottleneck squeeze特征,然后解码器扩展它们),在中间监督(intermediate supervision)下重复 bottom-up 和 top-down 过程。层叠沙漏网络由连续的池化层和上采样层步骤组成,以捕获每个尺度的信息。之后,许多研究为HPE开发了复杂的SHG结构变体。Chu等人设计了一种新型沙漏残差单元(Hourglass Residual Units HRU),通过一个带有更大感受野的滤波器分支来扩展残差单元,以捕捉不同尺度的特征。Yang等人设计了一个多分支金字塔残差模块(Pyramid Residual Module PRM)来取代SHG中的残差单元,从而增强了深层 CNN 的尺度不变性。
随着生成式对抗网络(Generative Adversarial Networks GANs) 的出现,HPE对其进行了探索,以生成生物学上合理的姿态配置,并区分高置信度和低置信度的预测,从而 推断出遮挡身体部位的潜在姿态。Chen等人构建了一个结构感知的条件对抗网络:Adversarial PoseNet,它包含一个基于沙漏网络的姿态生成器和两个用于区分合理与不合理身体姿态的鉴别器。Chou等人构建了一个基于对抗性学习的网络,其中两个堆叠的沙漏网络分别具有与鉴别器和生成器相同的结构,生成器估计每个关节的位置,鉴别器区分 ground-truth 热图和预测热图。与以HPE网络为生成器并利用鉴别器提供监督的基于GANs的方法不同,Peng等人开发了一种对抗性数据增强网络( adversarial data augmentation network),通过将HPE网络视为鉴别器,并使用增强网络作为生成器来增强对抗性,从而优化数据增强和网络训练。
除了设计高效的HPE网络之外,还研究身体结构信息来为HPE网络的搭建提供更多更好的监督信息。 Yang等人为HPE设计了一个端到端的CNN框架,通过整合人体各部位的空间和外观一致性,该框架能够找到 hard negatives(难划分的负样本)。[71]提出了一个结构化特征级学习框架,用于推理 HPE 中人体关节之间的相关性,该框架捕获了更丰富的人体关节信息,提高了学习结果。Ke 等人设计了一种多尺度结构感知神经网络,它结合了多尺度监督、多尺度特征组合、结构感知损失信息方案和关键点masking 训练方法,以改进复杂场景中的HPE模型。Tang等人构建了一个基于沙漏的监督网络:Deeply Learned Compositional Model,用于描述人体各部位之间复杂而真实的关系,并学习人体中的组合模式信息(每个身体部位的方向、比例和形状信息)。Tang和Wu发现并非所有的身体部位都相互关联,因此引入了基于部位的分支网络(Part-based Branches Network) 来学习每个部位组的特定表示,而不是所有部位的共享表示。
视频序列中的人体姿态是(3D)时空信号。 因此,对视频中的时空信息进行建模对于基于视频的HPE非常重要。Jain等人设计了一个双分支CNN框架,将颜色和运动特征结合到帧对中,以在HPE中构建一个富有表达性的时空模型。Pfister 等人提出了一种卷积网络,该网络能够利用来自多个帧的时间上下文信息,通过光流将预测的热图与相邻帧对齐。与先前基于视频的计算密集型方法不同,Luo等人为HPE引入了一种具有长短时记忆(Long Short-Term Memory LSTM)的循环结构,从不同帧捕获时间几何一致性和相关性。Zhang等人引入了一个关键帧 proposal 网络(key frame proposal network),用于从帧中捕获空间和时间信息,以及一个用于高效基于视频的姿态估计的人体姿态插值模块。
3.2 2D multi-person pose estimation 2D多人姿态估计
与单人HPE相比,多人HPE更困难、更具挑战性,因为它需要计算人数和他们的位置,以及如何为不同的人分组关键点。为了解决这些问题,多人HPE方法可以分为 top-down 和 bottom-up 两种。top-down 法使用现有的人体检测器从输入图像中获取一组 boxes(每个 box 对应一个人),然后对 box 中的每个人应用单人姿态估计器以生成多人姿态。与 top-down 法不同,bottom-up 法先在定位图像的所有身体关节,然后将它们分组到相应的实例。top-down pipeline中,输入图像中的人数将直接影响计算时间。bottom-up 法的计算速度通常比 top-down 快,因为它们不需要分别检测每个人的姿态。 如图4所示为2D多人HPE方法的一般框架。
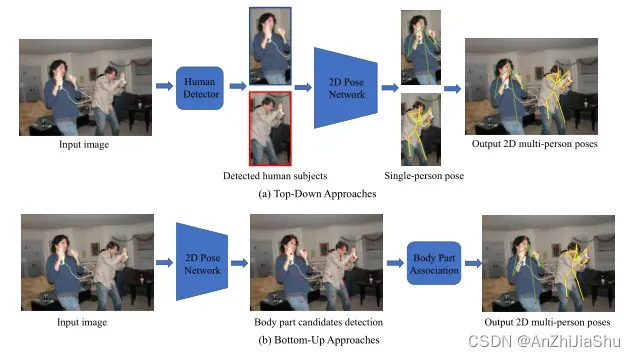
3.2.1 Top-down pipeline
在图4(a) 所示的自上而下的 pipeline 中,有两个重要部分:① 一个人体检测器用于获取 bounding box;② 单人姿态估计器用于预测这些边界框内关键点位置。一系列工作专注于设计和改进HPE网络中的模块。例如,为了回答构建HPE网络时 “一种简单的方法能表现多好(how good could a simple method be)” 的问题,肖等人在 ResNet (backbone) 中添加了一些反卷积层构建一个简单有效的结构,从而生成高分辨率表示的热图。Sun等人提出了一种新的高分辨率网络(HRNet),通过并行连接多分辨率子网络并进行重复多尺度融合来学习可靠的高分辨率表示。为了提高关键点定位的准确性,Wang等人引入了一个两阶段的基于图和模型未知 (model-agnostic ) 的框架:GraphPCNN,它由一个定位子网和一个图姿态精细化模块组成,前者用于获取粗略的关键点位置,后者用于获得精确的关键点定位表示。为获得更精确的关键点定位,Cai 等人引入了一个 multi-stage 网络,该网络带有一个残差步长网络(Residual Steps Network RSN)模块,通过有效的内部特征融合策略学习精细的局部表示,以及一个姿态优化机(Pose Refine Machine PRM)模块找到局部特征表示和全局特征表示之间的 trade-off。
多人环境中不可避免的肢体重叠产生的遮挡和截断使 top-down 方法在检测人体时失败,因此,对遮挡或截断的鲁棒性是多人HPE方法的一个重要方面。 为了实现这一目标, Iqbal 和 Gall 建立了一个基于卷积姿态机器的姿态估计器,以估计候选关节,然后,他们使用整数线性规划(integer linear programming ILP) 来解决关节与人之间的关联问题,并在严重遮挡的情况下获得人体姿态。Fang 等人设计了一种新的区域多人姿态估计(regional multi-person pose estimation RMPE)方法来提高HPE在复杂场景中的性能。具体来说,RMPE框架由三部分组成:① Symmetric Spatial Transformer Network 对称空间变换网络:用于检测不准确边界框内的单人区域;② Parametric Pose Non-Maximum-Suppression 参数姿态非最极大值抑制:用于解决冗余检测问题;③ Pose-Guided Proposals Generator:用于增加训练数据。Papandreou等人提出了一种两阶段架构:一个Faster R-CNN人体检测器创建候选人体 bounding box,一个关键点估计器通过使用热图偏移聚合 (heatmap-offset aggregation) 的形式预测关键点位置,整个方法在遮挡和杂乱场景中效果良好。为了缓解HPE中的遮挡问题,Chen等人提出了一种级联金字塔网络(Cascade Pyramid Network CPN),该网络包括两部分:① GlobalNet:一种用于预测眼睛或手等不可见关键点的特征金字塔网络;② RefineNet:一种将来自 GlobalNet 的所有级别的特征与 keypoint mining loss 相结合的网络。他们的结果表明,CPN在预测遮挡关键点方面性能良好。Su等人设计了两个模块:Channel Shuffle Module 和 Spatial&Channel-wise Attention Residual Bottleneck 来增强通道和空间信息,从而在遮挡场景下更好地估计多人姿态。Qiu 等人开发了遮挡姿态估计和校正(Occluded Pose Estimation and Correction OPEC Net)模块和遮挡姿态数据集,以解决人群姿态估计中的遮挡问题。Umer等人提出了一个关键点对应框架 keypoint correspondence framework,利用遮挡场景中前一帧的时间信息来恢复丢失的姿态,为提高视频数据集中稀疏标注的姿态估计结果,使用自监督对网络进行训练。
3.2.2 Bottom-up pipeline
自下而上的 pipeline 有两个主要步骤:① 人体关节检测(即提取局部特征并预测人体关节候选对象);② 为单个身体装配关节候选对象(即使用部位关联策略 part association strategies 将关节候选对象分组以构建最终姿态表示)如图4(b) 所示。
Pishchulin等人提出了一种基于 Fast R-CNN的身体部位检测器:DeepCut,这是最早的两阶段的自底向上方法之一。DeepCut先检测所有候选身体部位,然后标记每个部位,并使用整数线性规划(ILP)将这些部位组装到最终姿态。DeepCut 的计算成本很高,因此,Insafutdinov 等人引入了DeeperCut,通过将更强大的身体部位检测器、更好的增量优化策略和用于分组身体部位的imageconditioned pairwise 来提高性能和速度,从而改善了DeepCut。后来,Cao等人构建了 OpenPose 检测器,该检测器使用卷积姿态机(Convolutional Pose Machines CPMs)通过热图和部位亲和场( Part Affinity Fields PAF,一组二维向量场,带有编码肢体位置和方向的向量图) 预测关键点坐标,将关键点与每个人关联。OpenPose大大加快了自下而上多人HPE的速度。基于OpenPose框架,Zhu等人改进了OpenPose结构,通过添加冗余边来增加 PAFs 中关节之间的连接,并获得了比 OpenPose 方法更好的性能。尽管基于OpenPose的方法在高分辨率图像上取得了很好的效果,但在低分辨率图像和遮挡情况下,它们的性能较差。 为了解决这个问题,Kreiss等人提出了一种自下而上的 PifPaf,该方法使用部位强度场(Part Intensity Field PIF) 来预测身体部位的位置,并使用部位关联场(Part Association Field PAF) 来表示关节关联。在低分辨率和遮挡场景下,PifPaf 优于先前基于OpenPose的方法。 受 OpenPose 和层叠沙漏结构启发,Newell等人引入了一个 single-stage 深度网络,同时获得姿态检测和组分配。 继此之后,Jin等人提出了一种新的可微层次图分组(Hierarchical Graph Grouping HGG)方法来学习人体部位分组。Cheng等人在 HGG 和 HRNet 的基础上,提出了一种简单的HRNet扩展:Higher Resolution Network (HigherHRnet),它通过 deconvolves(反卷积) HRNet生成的高分辨率热图,来解决 bottom-up 姿态估计中的尺度变化问题。
自下而上的HPE方法也采用了多任务结构。 Papandreou等人引入PersonLab,将姿态估计模块和 person 分割模块结合起来,用于关键点检测和关联。PersonLab由 short-range offsets(用于细化热图)、 mid-range offsets(用于预测关键点)和 long-range offsets(用于将关键点分组到实例(人)中)组成。Kocabas等人提出了一个带有一个姿态残差网络的多任务学习模型:MultiPoseNet,它可以同时执行关键点预测、人体检测和语义分割任务。
3.3 2D HPE Summary
总之,随着深度学习技术的蓬勃发展,2D HPE的性能得到了显著提高。近年来,更深更强大的网络 提升了2D单人HPE(如DeepPose和堆叠沙漏网络以及2D多人HPE(如AlphaPose和OpenPose)的性能。
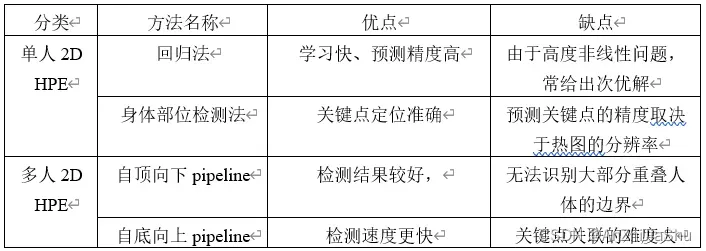
尽管这些工作在不同的2D HPE场景中取得了足够好的性能,但仍然存在问题。2D 单人 HPE 的回归法和身体部位检测法各有优势和局限性:
- 回归方法可以通过端到端的框架学习从输入图像到关键点坐标的非线性映射,这提供了一种快速学习范式和 sub-pixel level 的预测精度,然而,由于高度非线性问题,它们通常给出次优解。
- 人体部位检测方法,尤其是基于热图的框架,在2D HPE中得到了更广泛的应用,因为:(1)热图中每个像素的概率预测可以提高关键点定位的准确性;(2)热图通过保存空间位置信息提供更丰富的监督信息。然而,预测关键点的精度取决于热图的分辨率,使用高分辨率热图会增加计算成本和内存占用。
对于 2D 多人HPE的 top-down 和 bottom-up pipeline,很难确定哪种方法更好,这两种方法在最近的工作中都被广泛使用,各有优缺点:
- top-down pipeline 产生更好的结果,因为它首先从图像中检测每个人体,然后预测单人关键点位置。在这种情况下,背景基本上被移除,易于估计每个检测到的人体区域内的关键点热图。
- bottom-up 法通常比 top-down 法更快,因为它们直接检测所有关键点,并使用关键点关联策略(如亲和链接 affinity linking 、关联嵌入 associative embedding 和逐像素关键点回归 pixel-wise keypoint regression )将其分组为单独的姿态。
在未来的研究中需要解决 2D HPE中的几个挑战:
- 首先是在拥挤人群场景中对被显著遮挡人体的可靠检测。top-down 法中的人体检测器可能无法识别大部分重叠人体的边界。类似地,对于遮挡场景中的 bottom-up 法,关键点关联的难度更大。 *
- 第二个挑战是计算效率。尽管像 OpenPose 等方法可以在具有中等计算能力的特殊硬件上实现近实时处理(例如,在配备Nvidia GTX 1080 Ti GPU的机器上实现 22 FPS),但在资源受限的设备上实现网络仍然很困难。 现实世界的应用(如在线 coaching、游戏、AR和VR)需要在商业设备上使用更高效的HPE方法,从而为用户带来更好的交互体验。
- 第三个挑战在于有限的罕见姿态数据集。尽管当前的 2D HPE 数据集对于正常姿态估计(例如站立、行走、跑步)来说足够大(例如COCO数据集),但这些数据集对于异常姿态(例如摔倒)来说训练数据有限,数据不平衡会导致模型偏差,导致对这些姿态不准确的估计。开发有效的数据生成或数据增强技术来生成额外的姿态数据,有助于训练更健壮的模型。
4. 3D Human pose estimation
3D HPE是一种预测人体关节在在三维空间位置的技术,它可以提供与人体相关的大量3D结构信息,近年来受到了广泛关注。它可以应用于各种应用(例如,3D电影和动画产业、虚拟现实和在线3D动作预测)。尽管最近2D HPE取得了显著的进步,但3D HPE仍然是一项具有挑战性的任务。 现有的大多数研究工作都是针对单目图像或视频中的 3D HPE,这是一个不适定的逆问题,因为3D到2D的投影丢失了一维。 当多个视点可用或部署了IMUs 和 LiDAR 等传感器时,3D HPE可能是一个采用信息融合技术的适定问题。另一个限制是深度学习模型需要大量数据,并且对数据收集环境敏感。2D人体数据集中,可以轻松获得精确的2D姿态标注,但收集精确的3D姿态标注非常耗时,手动标记也不实用。 此外,数据集通常是从室内环境中收集的,并带有选定的日常动作。 最近几个工作证明了有偏差数据集训练的模型,在交叉数据集推理下,泛化能力差的问题。本节先关注单目RGB图像和视频中的3D HPE,然后讨论基于其他类型传感器的3D HPE。
4.1 3D HPE from monocular RGB images and videos (单目RGB图像和视频的3D HPE)
单目相机机是在 2D 和 3D 场景中应用最广泛的 HPE 传感器。研究人员想将基于单目图像和视频的 2D 深度学习 HPE 工作扩展到3D。基于深度学习的3D HPE方法分为两大类:单视图3D HPE和多视图3D HPE。
4.1.1 Single-view 3D HPE
从单目图像和视频的单一视图重建 3D 人体姿态是一项非常重要的任务,它会受到自遮挡和其他对象遮挡、深度模糊和训练数据不足 的影响。这是一个严重的不适定问题,因为不同的3D人体姿态可以投影成相似的2D姿态 。此外,对于基于2D关节的方法,2D身体关节的微小定位误差可能会导致3D空间中的较大姿态失真。与单人情况相比,多人情况更加复杂。因此,下文将分别对它们进行讨论
A. Single-person 3D HPE
根据单人3D HPE方法是否使用人体模型(如第2节所列)来估计3D人体姿势,可以将其分为无模型和基于模型的两类。 图5所示为单人 3D HPE 方法的分类。
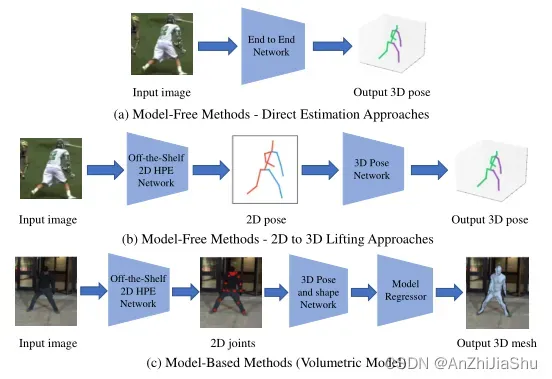
图5.单人3D-HPE框架。(a) Direct estimation 直接估计法:从二维图像直接估计三维人体姿势。(b) 2D to 3D lifting二维到三维提升法:利用预测的二维人体姿势(中间表示)进行三维姿势估计。(c)基于模型法:结合参数化身体模型来恢复高质量的 3D人体网格。由 3D姿态和形状网络推断出的 3D姿态参数和形状参数被输入到模型回归器中,以重建 3D人体网格。
a. Model-free methods 无模型方法
无模型方法不使用人体模型来重建三维人体表示,这些方法可进一步分为两类:① Direct estimation 直接估计方法;② 2D to 3D lifting 二维到三维提升方法。
(1) Direct estimation 直接估计: 如图5(a) 所示,直接估计方法从 2D 图像直接推断 3D 人体姿态,而无需估计中间 2D 姿态表示。Li 和 Chen 提出了一种早期的深度学习方法,他们采用了一个浅层网络来同步训练带有滑动窗口(滑动窗口用于物体检测,不仅要识别出图像中的物体,还要用一个矩形框标示出物体的位置。设计一个固定比例的方框,称之为“窗口”,之后在整张图片上移动该窗口扫描图片,将框住的内容传进网络中判断其中是否有我们想探测的物体。在完成一次扫描后,还可以等比例放缩窗口,进行多次扫描,滑动窗口的计算可以看作是一个卷积过程)的身体部位检测和姿态坐标回归。Li 等人提出了一种后续方法,将 image-3D 姿态对作为网络输入,score 网络给正确的 image-3D 姿态对分配高分数,其他的分配低分数。然而,这些方法效率很低,因为它们需要多个前馈网络进行推断。Sun等人提出了一种结构感知回归方法,采用更稳定的基于骨骼的表示法替代基于关节的表示法,通过利用三维骨骼结构和基于骨骼的表示对骨骼之间的 long range 交互进行编码从而定义成分损失。Tekin等人通过学习 3D 姿态到高维潜在空间的映射,对关节之间的结构依赖进行编码,学习的高维姿态表示可以强制执行3D姿态的结构约束。Pavlakos 等人引入体积表示法,将高度非线性的三维坐标回归问题转化为离散空间中可管理的形式。卷积网络预测体积中每个关节的体素似然,采用人类关节的顺序深度关系来缓解对精确 3D ground truth 姿态的需求。
(2) 2D to 3D lifting 2D到3D提升: 受 2D HPE的推动,从估计的2D人体姿态中推断3D人体姿态的 2D to 3D lifting 方法已成为主流的 3D HPE 解决方案,如图5(b)所示。得益于 sota 2D 姿态检测器的优异性能,2D 到 3D 提升方法通常优于直接估计方法。 在第一阶段,使用现有的 2D HPE 网络模型来估计 2D 姿态,然后在第二阶段使用 2D to 3D lifting 来获得 3D 姿态。Chen 和 Ramanan 部署了从一个库中预测的 2D 姿态和 3D 姿态的最近邻匹配,但当 3D 姿态与给定的 2D 姿态图像在条件上不独立时,3D HPE可能会失败。Martinez 等人提出了一种简单但有效的全连接残差网络,以基于2D关节位置回归3D关节位置,尽管该方法在当时取得了 sota 结果,但由于它过度依赖2D姿态检测器的重建模糊性,在某些时候可能会失败。Tekin 等人和Zhou等人使用2D热图代替2D姿态作为估计3D姿势的中间表示。Moreno Noguer 通过距离矩阵回归推断出3D人体姿态,其中2D和3D人体关节的距离被编码为两个欧几里德距离矩阵(EDMs),EDMs 对平面内图像旋转和平移具有不变性,并且在应用归一化操作时具有缩放不变性。Wang 等人开发了一种成对排序卷积神经网络(Pairwise Ranking Convolutional Neural Network:PRCNN),用于预测成对人体关节的深度排序,然后使用从粗到细的姿态估计器从 2D 关节和深度排序矩阵中回归三维姿态。Jahangiri等提出先生成多种不同的3D姿态假设,然后应用 ranking 排序网络选择最佳 3D 姿态。
由于人体姿态可以表示成以关节为节点、骨骼为边的图,因此图卷积网络(GCN)也被应用于 2D to 3D 姿态提升问题,并表现出良好的性能。 Choi 等人提出了基于图卷积网络 GCN 的 Pose2Mesh,用于从 PoseNet 中优化中间 3D 姿态,使用GCN,MeshNet 使用从 mesh 拓扑构造的图中回归出 mesh 顶点的三维坐标。Ci 等人提出了一个通用的局部连接网络(Locally Connected Network:LCN),LCN 利用全连接网络和GCN对局部关节邻域之间的关系进行编码。LCN可以克服GCN的缺点,即权重共享方案会损害姿态估计模型的表示能力,并且结构矩阵缺乏灵活性来支持自定义的节点依赖。Zhao等人解决了GCN中所有节点卷积滤波器共享权重矩阵的局限性问题。Semantic-GCN 用于研究语义信息和语义关系,语义图卷积(SemGConv)操作用于学习边缘的 channel-wise 权重,由于SemGConv 和 non-local 层是交错的,因此可以捕获节点之间的局部和全局关系。
3D HPE数据集通常是从受控环境中收集的选定的日常运动。由于很难获取野外的3D 姿态标注数据,因此对于具有异常姿态和遮挡的野外数据的3D HPE仍然是一个挑战。 为此,一组 2D-to-3D lifting 方法被提出用于从缺少3D姿态标注的野外图像中估计3D人体姿态。Zhou等人提出了一种弱监督转移学习方法,该方法使用野外图像的2D姿态作为弱标签。3D 姿态估计模块与 2D 姿态估计模块的中间层连接,对于野外图像,2D 姿态估计模块执行有监督的2D热图回归,在弱监督的3D姿势估计模块中应用 3D骨骼长度约束导致的loss(3D bone length constraint induced loss)。Habibie等人提出了投影损失 projection loss,在没有3D标注的情况下优化3D人体姿态,并设计了一个3D-2D投影模块,利用 earlier 网络层预测的3D姿态来估计2D身体关节位置,投影损失用于更新3D人体姿态,无需3D标注。Chen等人提出了一种基于闭合和不变性提升特性的无监督提升网络,该网络将 geometric self-consistency(几何自约束) loss 用于 lift-reproject-lift 过程,闭合意味着对于提升的3D骨骼,在随机旋转和重投影后,生成的2D骨架将位于有效2D姿态的分布范围内。不变性是指当从三维骨架改变二维投影的视点时,重新提升的三维骨架应相同。
视频可以提供时间信息来提高3D HPE的准确性和鲁棒性从而替代从单目图像估计3D人体姿态。Hossain和Little 提出了一种递归神经网络,该网络使用具有shortcut connect 的长-短期记忆(Long Short-Term Memory: LSTM)单元来利用人类姿态序列中的时间信息。他们的方法利用序列到序列网络中的过去事件来预测时间(临时)一致的3D姿态。先前的工作通常忽略了空间约束和时间相关性之间的互补性,Dabral et al.、Cai et al. 和 Li et al.利用时空关系和约束(例如,骨架长度约束和左右对称约束)改善连续帧的3D HPE性能。Pavllo 等人提出了一种时间卷积网络,从连续的2D序列中估计2D关键点上的3D姿态,然而,他们的方法是基于一个假设:“预测误差在时间上非连续且独立的”,但在存在遮挡的情况下这个假设可能不成立。Chen等人添加了骨架方向模块和骨架长度模块,以确保视频帧中的人体解剖结构的时间一致性,而Liu等人利用注意力机制识别重要帧,并在大的 temporal 感受野中建立long-range依赖模型。Zeng等人采用拆分和重组策略来解决罕见的、不可见的姿态问题,先通过独立的时间卷积网络分支将人体分割为局部区域进行处理,然后将每个分支获得的低维全局上下文进行组合以保持全局一致性。
b. Model-based methods 基于模型的方法.
基于模型的方法包括第 2 节中提到的参数化身体模型(如运动学模型和体积模型),以估计人体姿态和形状,如图5(c)所示。
运动学模型是由具有运动约束的连接骨架和关节构成的铰接体表示,近年来在 3D HPE中受到越来越多的关注。许多方法利用基于运动学模型的先验知识,如骨骼关节连接信息、关节旋转特性和固定骨长比,进行合理的姿态估计。Zhou等人将运动学模型作为运动学层嵌入到网络中,以强制执行方向和旋转约束。Nie等人和Lee等人利用骨架长短期记忆(LSTM)网络来利用关节关系和连通性。观察到人体各部分具有基于运动学结构的明显自由度( distinct degree of freedom:DOF)Wang等人和Nie等人提出了双向网络来模拟人体骨骼的运动学和几何依赖关系。Kundu 等人设计了一种运动学结构保存方法,通过 energy-based loss 推断局部运动学参数,并基于 parent-relative 局部肢体运动学模型探索 2D 部位分割。Xu等人证明,noisy 2D关节是估计精确3D姿态的关键障碍之一,因此,基于运动学结构,采用2D姿态校正模块来优化不可靠的 2D关节。Zanfir 等人引入了一种运动学潜在正则化流表示法(应用于原始分布的可逆变换序列),具有可微的语义身体部位对齐损失函数。
与生成人体姿态或骨架的运动学模型相比,体积模型可以恢复高质量的人体网格,提供额外的人体形状信息。作为最流行的体积模型之一,SMPL (Skinned Multi-Person Linear Model) 模型能与现有的渲染引擎相兼容,已被广泛应用于3D HPE中。Omran 等人回归 SMPL 参数以重建3D人体网格。Kolotouros等人没有预测SMPL参数,而是使用Graph-CNN架构回归了SMPL网格顶点的位置。Zhu等人将SMPL模型与分层的网格变形框架相结合,以增强自由形式 3D 变形的灵活性。Kundu等人在SMPL模型中加入了颜色恢复模块,以通过反射对称获得顶点颜色。Arnab等人指出,使用SMPL模型的方法通常在野外数据上失败,他们采用束调整 (bundle adjustment) 方法来处理遮挡、异常姿态和对象模糊。Doersch和Zisserman 提出了一种转移学习方法,通过在合成的人类视频数据集SURREAL上进行训练来回归SMPL参数。Kocabas等人将大规模运动捕捉数据集 AMASS 纳入其基于SMPL的方法VIBE(Video Inference for Body Pose and Shape Estimation:用于身体姿势和形状估计的视频推断)的对抗性训练中,VIBE利用AMASS数据集通过姿态回归模块区分真实人体运动和预测姿态。低分辨率视觉内容在现实场景中比高分辨率视觉内容更常见,但当分辨率降低时,现有训练有素的模型可能会失败。 Xu等人将对比学习方案引入到基于自监督分辨率感知SMPL的网络中,自监督对比学习方案利用自监督损失和对比特征损失来增强特征和尺度的一致性。
有几种扩展的基于 SMPL 的模型来解决 SMPL 模型计算复杂度高,缺少手和面部标志等局限性。Bogo等人提出了SMPLify来估计3D人体网格,它将SMPL模型与检测到的2D关节相匹配,并将重投影误差降至最低。Lassner等人提出了扩展版本的SMPLify,通过使用随机森林回归来回归SMPL参数,降低了运行时间,但仍然无法实现实时吞吐量。Kanazawa等人进一步提出了一种对抗式学习方法,可以实时直接推断SMPL参数。Pavlakos 等人介绍了一种新模型:SMPL-X,该模型可以预测完全结构化的手和面部标志。在SMPLify 方法之后,他们还提出了 SMPLify-X,这是从AMASS数据集学习的改进版本。Hassan 等人进一步将 SMPLify-X 扩展到 PROX (Proximal Relationships with Object eXclusion ),通过添加 3D环境约束来强制 (Relationships with Object eXclusion) 。Kolotouros等人将基于回归和基于优化的SMPL参数估计方法集成到一个名为SPIN(SMPL oPtimization IN the loop:循环中的SMPL优化)的新方法中,在训练循环中使用SMPLify。Osman等人通过额外10000次扫描的训练将 SMPL 升级为 STAR,以更好地进行模型泛化,且模型参数数量减少到SMPL的20%。
除了使用基于SMPL的模型外,其他体积模型也被用来恢复3D人体网格。Chen等人介绍了一种圆柱体人体模型,用于为3D数据生成遮挡标签,并执行数据扩充,同时引入姿态正则化项来惩罚错误估计的遮挡标签。Xiang等人利用 Adam模型重建3D运动,并引入了一种 3D 人体表示,即 3D部位方向场(3D Part Orientation Fields,POF),对 2D 空间中的人体部位在 3D 方向进行编码。Wang等人提出了一种新的 Bone-level Skinned 模型,通过设置骨架长度和关节角度,解耦骨架建模和 identity-specific 变化。Fisch和Clark介绍了一种方向关键点模型,该模型可以计算整个 3-axis 关节旋转,包括6D HPE的摇摆、俯仰和滚转。
B. Multi-person 3D HPE
单目RGB图像/视频的3D多人HPE,与2D多人HPE类似,可分为:top-down 法和 bottom-up 法,分别如图6(a) 和图6(b) 所示。3.2 节中2D自顶向下和自下而上方法的比较也适用于3D情况。
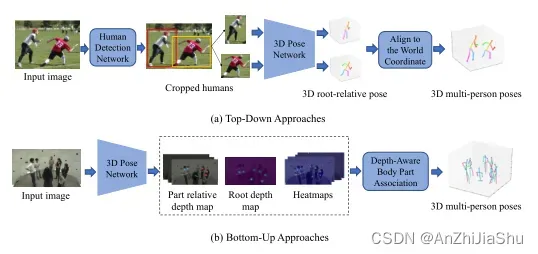
图6. 多人3D HPE框架示意图。(a) Top-down 法先通过人体检测网络检测单人区域,对于每个单人区域,应用3D姿态网络估计单个3D姿态,然后,将所有 3D 姿态与世界坐标对齐。(b) Bottom-up 法先估计所有身体关节和深度图,然后根据 root 深度和部位相对深度将身体部位关联到每个人。
a. Top-down approaches.
Top-down 3D多人HPE法先检测每个人,然后利用3D姿态估计网络估计每个被检测人的绝对root(人体中心关节)坐标和 3D root-relative 位姿。基于每个人的绝对根坐标及其相对根姿态,所有姿态都与世界坐标对齐。 Rogez等人提出本地化分类回归方法:LCR-Net,通过定位每个人的候选区域以生成潜在姿态,并使用回归器联合优化姿态 proposal,LCR-Net在受控环境数据集上表现良好,但不能很好地推广到野外图像中。为了解决此问题,Rogez等人提出了 LCR-Net++,对训练数据进行合成数据增强来提高性能。Zanfir等人将语义分割添加到使用场景约束的3D多人HPE模块中,此外,针对基于视频的多人3D HPE,采用匈牙利匹配方法解决了3D时间分配问题。Moon等人介绍了一种相机距离感知方法,将裁剪后的人体图像输入到 RootNet 中,估计以相机为中心的人体 root 坐标,然后利用PoseNet估计每个被裁剪人的 root-relative 3D姿态。Benzine等人提出了Single-shot (Single-shot什么意思?Single shot指明了算法属于one-stage方法,例如:SSD算法全名是 Single Shot Multibox Detector) 的 PandaNet(Pose estimAtioN and Detection Anchor-based Network),引入一种基于低分辨率 anchor 的表示方法来避免遮挡问题,开发了一个pose-aware anchor selection module 通过移除模糊的 anchor 来解决重叠问题,使用与不同规模相关的损失自动加权来处理不同规模人群的不平衡问题。Li 等人解决了自上而下方法缺乏全局信息的问题,他们采用层次化的多人顺序关系方法,利用身体层次的语义和全局一致性对交互信息进行层次化编码。
b. Bottom-up approaches.
自下而上的方法先生成所有身体关节位置和深度图,然后根据 root 深度和部位相对深度将身体部位与每个人关联。自下而上方法的一个关键挑战是如何对每个人的人体关节进行分组。Zanfir等人将人分组问题表述为二进制整数规划( binary integer programming: BIP)问题,采用肢体评分模块估计被检测到的关节的候选运动学连接,骨架分组模块通过解决BIP问题将肢体组装成骨架。Nie等人提出了单阶段多人姿态机(Single-stage multi-person Pose Machine:SPM),定义每个人唯一的 identity 根关节,通过使用密集位移图,将身体关节与每个根关节对齐。然而,这种方法的局限性在于:只有成对的2D图像和3D姿势标注可以用于监督学习。在没有成对2D图像和3D姿势标注的情况下,Kundu等人提出了一种冻结网络,在实际部署范式下利用两种不同模式之间共享的潜在空间,将学习转化为跨模型对齐问题。Fabbri等人开发了一种基于距离的启发式方法,在多人环境中连接关节。具体来说,从检测到的头部(例如,最高置信度的关节)开始,通过选择3D欧氏距离最近的关节来连接其余关节。
自下而上方法的另一个挑战是遮挡问题。为了应对这一挑战,Meta等人开发了一种遮挡鲁棒姿态图(Occlusion-Robust Pose-Maps:ORPM)方法,将冗余纳入位置图公式中,这有助于遮挡场景下热图中的人员关联。Zhen等人利用深度感知部位关联算法,通过推理人与人之间的遮挡和骨骼长度约束,将关节分配给个体。Mehta等人在不考虑准确性的前提下,快速推断出可见身体关节的中间3D姿势,然后利用学习到的姿态先验知识和全局上下文,通过推断遮挡关节来重建3D姿态,并通过应用时间连贯性和拟合运动学骨骼模型来优化最终的 3D 姿态。
c. Comparison of top-down and bottom-up approaches.
自上而下的方法通常依靠最先进的人员检测法和单人姿态估计法获得较好的结果,但随着人体数量的增多,尤其在拥挤场景中,其计算复杂度和推理时间也会加剧。此外,由于自顶向下的方法先检测每个人的边界框,因此可能忽略场景中的全局信息,导致裁剪区域的估计深度可能与实际深度顺序不一致且预测的人体位置可能重叠。 相反, 自下而上的方法具有线性计算和时间复杂性,但不能直接恢复三维人体网格。 自顶向下法在检测到每个人之后,通过结合基于模型的3D单人HPE估计器,可以轻松恢复每个人的人体网格。而自底向上法需要额外的模型回归模块来根据最终的3D姿势重建人体网格。
4.1.2 Multi-view 3D HPE
部位遮挡是单视图 3D HPE的一个挑战性问题,自然而然想到通过多视图解决此问题,因为一个视图中的遮挡部分可能在其他视图中可见。 从多个视图中重建三维姿态,需要解决不同摄像机之间位置的关联。
一些方法使用身体模型,通过优化模型参数,使模型投影与2D姿态相匹配,来解决关联问题。广泛使用的3D图形结构模型就是这样一种模型。然而,这些方法通常需要大量内存和高昂的计算成本,尤其对于多视图多人 3D HPE。Rodin等人在网络中采用了多视图一致性约束,但它需要大量的3D ground truth 训练数据。为了克服这一限制,Rhodin等人进一步提出了一种编码器-解码器框架,从多视图图像和背景分割中学习几何感知的潜在 3D 表示,而无需3D标注。Huang等人提出了多视图匹配框架在具有一致性约束的所有视点上重建3D人体姿态。Pavlakos等人和Zhang等人根据所有校准的相机参数,将多视图图像的2D关键点热图聚合为3D图形结构模型,但当多视图相机环境更改时,需要重新训练模型。Liang 等人和 Habermann等人推断出非刚性3D变形参数,从多视图图像重建3D人体网格。Kocabas等人利用极线几何来匹配多视图姿态对,以重建 3D 姿态,并将其方法推广到新的多视图相机环境中。应该注意的是,在没有循环一致性约束的情况下单独匹配每对视图可能会导致错误的3D姿态重建。Tu等人在3D体素空间中聚合每个相机视图中的所有特征,避免每个相机视图中的错误估计,并设计一个cuboid proposal 网络和一个姿态回归网络,分别用于定位所有人和估计三维姿态。当给定足够的视点(超过十个)时,使用所有视点进行三维姿态估计是不现实的,Pirinen等人提出了一种自监督强化学习方法,选择一小组视点,通过三角剖分重建3D姿势。
在多视点HPE中,除了精度之外,还需要考虑轻量级结构、快速推理时间和对新相机设置的有效适应。与将所有视图输入匹配在一起的 [202]方法不同,Chen等人采用迭代处理策略,匹配每个视图的2D姿态和3D姿态,同时迭代更新3D姿态,与先前运行时间随相机数量增加而暴增的方法相比,它们的方法具有线性时间复杂度。Remelli等人将每个视图的图像编码为一个统一的潜在表示,以便解耦特征图和相机视点。轻量级规范融合使用基于GPU的直接线性变换将2D表示提升到3D姿态,以加速处理。为提高多视图融合方案的泛化性,Xie等人提出了一种预训练的多视图融合模型(MetaFuse),该模型部署了与模型无关的元学习框架来学习通用融合模型的最佳初始化,以有效适应具有少量标记数据的新相机设置。
4.2 3D HPE from other sources 其他来源的3D HPE
单目RGB相机是3D HPE最常用的设备, 其他传感器(如深度传感器、IMU和射频设备)也可用于 3D HPE。
深度传感器和点云传感器: 由于深度传感器具有低成本和高利用率的特性,近年来在 3D 计算机视觉领域颇受关注。深度模糊问题是 3D HPE的关键挑战之一,利用深度传感器可以缓解深度模糊问题。Yu 等人提出了单视图实时方法:DoubleFusion,可在不使用图像的情况下从单个深度传感器估计3D人体姿态,inner body 层通过体积表示重建三维形状,outer 层通过融合更多的几何细节更新身体形状和姿态。Xiong等人利用深度图像提出了 Anchor-to-Joint 回归网络(A2J),通过将估计的多个 anchor 点与全局-局部的空间上下文信息相结合来估计 3D 关节位置。Kadkhodammadi等人在真实的手术室环境中,使用多视图RGB-D相机捕捉带有深度信息的彩色图像,部署了一个基于随机森林的先验知识,以纳入先验环境信息,通过多视图融合和RGB-D优化,估计最终的 3D 姿态。Zhi等人利用RGB-D视频中的高分辨率反照率纹理重建了细节的网格。
与深度图像相比,点云可以提供更多的信息。 最先进的点云特征提取技术 PointNet 和PointNet++ 在分类和分割任务中表现出了优异的性能。Jiang等人将 PointNet 与 SMPL 身体模型相结合,以回归3D人体姿态,带有图形聚合模块的改进 PointNet++ 可以提取更有用的无序特征,通过注意模块映射到有序的骨架关节特征后,骨架图模块提取有序特征以回归SMPL参数,从而实现精确的 3D 姿态估计。Wang等人提出了一种具有时空网格注意卷积方法的PointNet++,用于预测细化的3D人体网格。
单目图像IMUs: 可穿戴惯性测量单元(Wearable Inertial Measurement UnitsI: IMUs)可以通过记录无物体遮挡和衣服障碍的运动来跟踪特定人体部位的方向和加速度。然而,在使用IMU时,drifting 问题可能会超时发生。Marcard等人提出了稀疏惯性姿态器(Sparse Inertial Poser: SIP),用于从附着在人体上的 6个IMUs 中重建人体姿态,并将收集到的信息拟合到具有一致性约束的 SMPL 身体模型中,以获得准确的结果。Marcard等人进一步将6-17 个IMU传感器与手持式移动摄像头相关联,用于野外3D HPE,并引入了一种基于图的优化方法,将每个2D人物检测分配给来自 long-range 帧的3D姿态候选。Huang等人指出了稀疏惯性姿态器(SIP)方法的局限性:即多个姿态参数可以生成相同的IMU方向,收集IMU数据也很耗时。因此,他们通过在SMPL网格上放置虚拟传感器,从AMASS数据集的运动捕捉序列中获取方向和加速度,创建了一个大型合成数据集。Zhang等人提出了一种方向正则化图形结构模型,用于从与IMU方向相关的多视图热图中估计3D姿态。Huang等人提出了将IMUs数据与多视图图像融合的two-stage 方法:DeepFuse,第一阶段仅处理多视图图像以预测体积表示,第二阶段使用 IMUs 通过 IMU-bone 细化层细化三维姿态。
射频设备: 基于射频(Radio frequency:RF)的传感技术也被用来定位人,部署基于射频的传感系统的主要优势是信号能够在WiFi范围内穿透墙壁并扫描到人体,而无需携带无线发射机。此外,非可视数据可以保护隐私。然而,与视觉摄像头图像相比,射频信号的空间分辨率相对较低,并且射频系统可显示生成的粗略三维姿态估计。Zhao等人提出了一种基于射频的深度学习方法:RFPose,用于估计多人场景的 2D 姿态,之后的扩展版本:RF-Pose3D,可以估计多人的3D骨骼。基于此,Zhao等人提出了一种带有多头注意力模块的时间对抗性训练方法:RF Avatar,使用SMPL身体模型恢复完整的3D人体网格。
其他传感器/源: 除了使用上述传感器外,Isogawa等人还根据非视线(non-line-of-sight: NLOS)成像系统捕获的量子3D时空直方图来估计3D人体姿态。Tome等人通过鱼眼摄像头解决了 egocentric 3D姿态估计问题。Saini等人使用多个自动微型飞行器(MA-Vs)拍摄的图像估计人体运动。Clever 等人通过压力感应垫收集的压力图像,重点研究了床上休息位置的HPE。
4.3 3D HPE 总结
下图为 3D HPE 的方法分类:
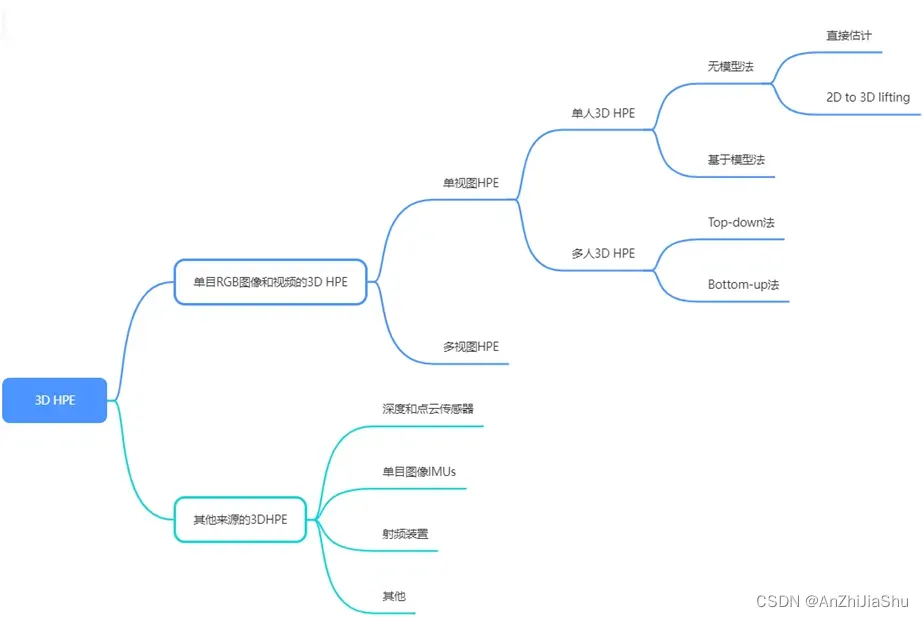
近年来,3D HPE取得了重大进展。大量 3D HPE 采用 2D to 3D lifting 策略,由于2D HPE的进步,3D HPE的性能也得到显著改善。一些 2D HPE方法,如 OpenPose、CPN、AlphaPose 和 HRNet 已被广泛用作 3D HPE方法中的 2D 姿态检测器。除了三维姿态外,一些方法从图像或视频中恢复三维人体网格。3D HPE 尽管迄今取得了进展,但仍存在一些挑战:
- 一个挑战是模型的泛化能力。高质量的3D ground truth 姿态标注依赖运动捕捉系统,而运动捕捉系统无法在随机环境中轻松部署。现有的数据集主要是在受约束的场景中捕获的,sota 方法在这些数据集上取得较好的结果,但应用于野外数据时,性能会下降。可以利用游戏引擎生成具有不同姿态和复杂场景的合成数据集,例如 SURREAL 数据集和 GTA-IM 数据集,然而,由于合成数据分布与真实数据分布之间存在差距,从合成数据中学习可能无法达到预期的性能。
- 类似于 2D HPE,遮挡的鲁棒性和计算效率也是三维HPE面临的两个关键挑战。由于严重的相互遮挡和每个人可能的低分辨率,当前3D HPE方法在拥挤场景中的性能大幅下降。3D HPE 比 2D HPE 的计算量大,例如,2D to 3D lifting 方法依赖2D姿态作为推断3D姿态的中间表示,因此,在保持高精度姿态估计的同时,开发计算效率高的 2D HPE pipeline 至关重要。
5 Datasets and evaluation metrics 数据集和评估指标
HPE 需要数据集。数据集也未不同的算法提供公平的比较。应用程序场景的复杂性和多样性给收集全面、通用的数据集带来了挑战。大量数据集基于不同的评价指标来评估和比较结果。本节将介绍HPE中使用的传统数据集,以及最近用于2D和3D HPE的数据集。除了这些具有不同功能和任务要求的数据集外,本节还介绍了2D和3D HPE的几种常用评估指标。总结了现有方法在流行数据集上取得的结果。
5.1 Datasets for 2D HPE
在深度学习应用于人体姿态估计之前,就有许多2D人体姿态数据集。这些数据集有两种类型:(1)上身姿态数据集,包括Buffy Stickmen、ETHZ PASCAL Stickmen、We are Family、Video pose 2 和 Sync. Activities;和(2)全身姿态数据集,包括 PASCAL Person Layout、Sport 和 UIUC people。然而,最近只有少数工作使用这些 2D HPE 数据集,因为它们有许多限制,例如数据量少或缺乏多样的对象动作。由于基于深度学习的方法需要大量训练数据,因此本节仅回顾大规模 2D HPE数据集。表2将这些数据集归纳为两个不同的类别(基于图像和基于视频)。
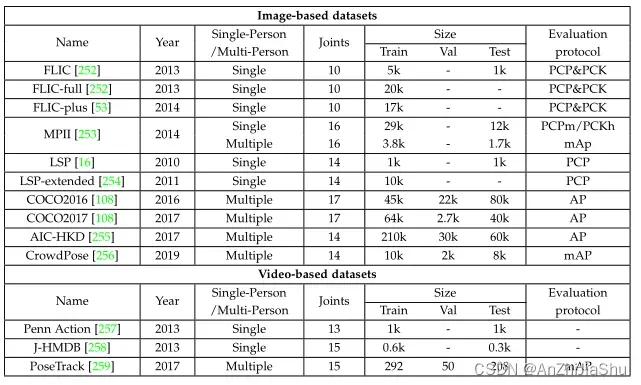
5.1.1 Image-based datasets 基于图像的数据集
Frames Labeled In Cinema (FLIC) Dataset: 从电影中标记帧的数据集。FLIC 数据集是早期基于图像的2D HPE数据集之一,其中包含从好莱坞电影中自动收集的5003幅图像,大约 4000 幅图像用作训练集,其余图像用作测试集。FLIC数据集使用身体部位检测器 Poselets,从30部流行好莱坞电影的每10帧中获取约2万个候选者,这些图像中的人有不同的姿态。从电影中获取的完整帧集称为FLIC-full 数据集,它是原始 FLIC 数据集的超集,包含20928个遮挡的非正面样本。FLIC plus 数据集删除了所有包含与 FLIC 数据集中的测试集相同场景的图像。 FLIC 数据集链接
Leeds Sports Pose (LSP) Dataset: LSP 数据集包含 2000 幅来自Flickr 的带标注图像和8个运动标签,涵盖不同的运动,包括田径、羽毛球、棒球、体操、跑酷、足球、网球和排球。在LSP数据集中,每个人的全身共有14个关节。LSP-extended 数据集扩展了LSP数据集,仅用于训练。LSP-extended 数据集拥有来自Flickr的10000多幅图像。在最近的工作中,LSP 和 LSP-extended 数据集用于单人HPE。LSP 数据集链接
Max Planck Institute for Informatics (MPII) Human Pose Dataset:
MPII 数据集是评估铰接式(articulated) HPE的流行数据集。该数据集包括约25000张图像,40000多个带标注身体关节的人体。MPII 通过两级分层方法系统地收集图像,以捕捉日常人类活动。整个数据集涵盖410项人类活动,所有图像都带标签,每个图像都是从YouTube视频中提取的,并提供了前后未加标注的帧。Amazon Mechanical Turk 的工作人员为 MPII 标记了丰富的标注(包括身体部位遮挡、三维躯干和头部方向)。MPII中的图像适用于2D单人或多人HPE。MPII 数据集链接
Microsoft Common Objects in Context (COCO) Dataset COCO 数据集是使用最广泛的大规模数据集。它有超过330000张图像和200000个带有关键点的标记对象,每个人都有17个关节。COCO数据集不仅可用于姿态估计和分析,还可用于自然环境中的目标检测和图像分割、上下文识别等。针对HPE的COCO数据集有两个版本:COCO keypoints 2016和COCO keypoints 2017,分别由COCO 2016 keypoints Detection Challenge 和 COCO 2017 keypoints Detection Challenge主办。COCO 2016和COCO 2017的区别在于训练集、验证集和测试集的划分。COCO 数据集已在多人 HPE 中广泛使用。此外,Jin等人]提出了具有HPE全身标注的 COCO-WholeBody 数据集。COCO数据集链接
AI Challenger Human Keypoint Detection (AIC-HKD) Dataset: AIC-HKD 数据集是目前最大的2D HPE 训练数据集。它有300000个用于关键点检测的标注图像。有210000张图像用于训练,30000张图像用于验证,600000多张图像用于测试。这些图片来自互联网搜索引擎,主要是人们的日常活动。AIC-HKD 数据集链接
CrowdPose Dataset: CrowdPose数据集是拥挤和遮挡场景的 2D HPE最新数据集之一。该数据集包含从30000张具有 Crowd Index (测量满足均匀分布以判断图像中的拥挤程度) 的图像中选择的20000张图像。训练、验证和测试数据集分别有10000、2000、8000张图像。CrowdPose 数据集链接
5.1.2 Video-based datasets 基于视频的数据集
Penn Action Dataset: Penn Action 数据集由2326个视频序列组成,包含15个不同的动作和人类关节注解。视频包含带有运动动作注解的框架:棒球投球、棒球挥杆、网球正手、网球发球、板凳推举、保龄球、挺举、高尔夫挥杆、跳绳、跳高、引体向上、俯卧撑、仰卧起坐、蹲下和弹琴。图像的注解使用亚马逊 Mechanical Turk 进行标记。Penn Action 数据集链接
Joint-annotated Human Motion Database (J-HMDB): J-HMDB 是一个全注解视频数据集,用于动作识别、人体检测和 HPE,共有21个动作类别,包括刷毛、接球、拍手、爬楼梯、高尔夫、跳跃、踢球、挑、倒、拉、推、跑、射球、射弓、射枪、坐、站、挥棒、扔、走和挥手。数据集共有928个视频剪辑,包括31838个带注解的帧。数据集基于Amazon Mechanical Turk,采用一个2D铰接的人偶模型来生成所有注解。J-HMDB数据集中70%的图像用于训练,其余图像用于测试。J-HMDB 数据集链接
PoseTrack Dataset: PoseTrack 数据集是一个用于视频分析中多人姿态估计和关节跟踪的大型数据集。视频中的每个人都有一个带注解的唯一 track ID。PoseTrack包含1356个视频序列、约46000个带注解的视频帧和276000个身体姿态注解,用于训练、验证和测试。Pose Track数据集链接
5.2 Evaluation Metrics for 2D HPE
因为要考虑许多特性和要求(例如,上部/全身、单/多姿态估计、人体大小),所以很难精确评估HPE的性能。我们总结一下常用的 2D HPE 评估指标。
Percentage of Correct Parts (PCP) 正确部位的百分比: PCP 是早期2D HPE 常用的一种测量方法,它评估 stick predictions 来 report 肢体的定位精度。当预测关节和 ground truth 关节之间的距离小于肢体长度的一部分(介于0.1到0.5之间)时,确定肢体的定位。在某些工作中,PCP测量也称为PCP@0.5(阈值为0.5)。这一指标用于LSP数据集的单人HPE评估。然而,PCP在最近的研究中并没有得到广泛的应用,因为它会惩罚难以检测的长度短的肢体。模型的PCP度量越高,模型的性能越好。为了解决 PCP 的缺点,引入了检测关节百分比(Percentage of Detected Joints:PDJ),若预测关节和真实关节间的距离在躯干直径的特定部分内,则认为预测关节已检测。
Percentage of Correct Keypoints (PCK) 正确关键点的百分比: PCK 用于测量给定阈值内不同关键点的定位精度。PCKh@0.5 表示阈值被设置为每个测试图像 head segment 长度的50%。PCK@0.2表示当检测到的关节和真实关节之间的距离小于躯干直径的0.2倍。PCK值越高,模型性能越好。
Average Precision (AP) and Average Recall (AR) 平均精度和平均召回率: AP度量是根据精确度(真阳性/总阳性)和召回率(真阳性/总真阳比率)衡量关键点检测准确性的指标。AP计算0到1之间召回的平均精度值。AP有几个类似的变体,例如,关键点的平均精度(Average Precision of Keypoints: APK)。mAP 是所有类平均精度的平均值,在 MPII 和 PoseTrack 数据集上应用广泛。平均召回率(AR)是COCO关键点评估中使用的另一个指标。对象关键点相似度(Object Keypoint Similarity: OKS)在对象检测中起着与 IoU 相似的作用,用于AP或AR。该度量是根据受试者的规模以及预测点和 ground truth 点之间的距离计算的。COCO评估通常使用10个OKS阈值的mAP作为评估指标。
5.3 Performance Comparison of 2D HPE Methods
表3∼表6 总结了不同2D HPE方法在流行数据集上的性能,以及相关和常用的评估指标。
表3 使用PCP度量来评估中基于身体检测和基于回归方法在LSP数据集上的性能比较。
表3: LSP数据集上不同2D单人HPE方法的比较。 使用PCP测量(针对躯干、头部、腿部、手臂和全身等四肢)和“Person-Centric”注解。最好的两个分数分别用红色和蓝色标记

表4为MPII数据集上不同2D HPE方法的比较结果,使用PCKh@0.5测量。值得注意的是,身体检测方法通常比回归方法具有更好的性能,因此在最近的2D HPE研究中更受欢迎。
表4:MPII数据集上2D单人HPE的比较结果。使用 PCKh@0.5测量(即,阈值等于每个测试图像头部段长度的50%)。最好的两个分数分别用红色和蓝色标记
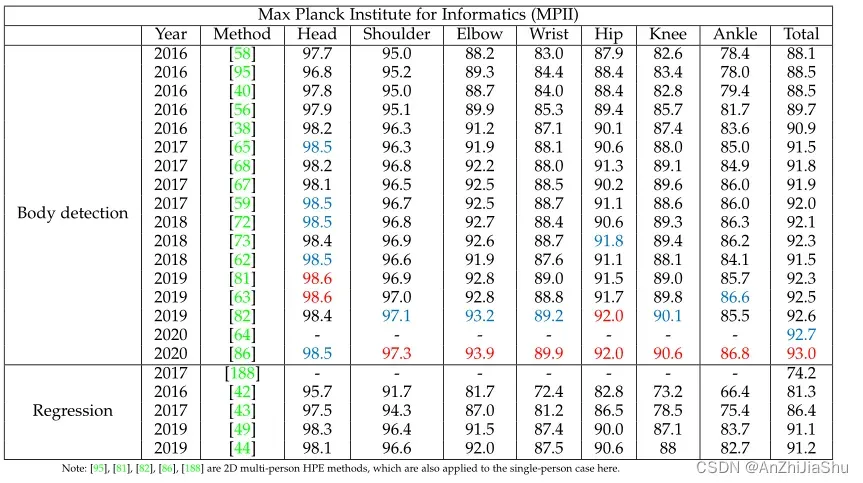
表5为 MPII 数据集的完整测试集上的 mAP 比较。
表5: MPII数据集的完整测试集上 2D多人HPE方法的比较结果。 使用mAP 评估。最好的两个分数分别用红色和蓝色标记
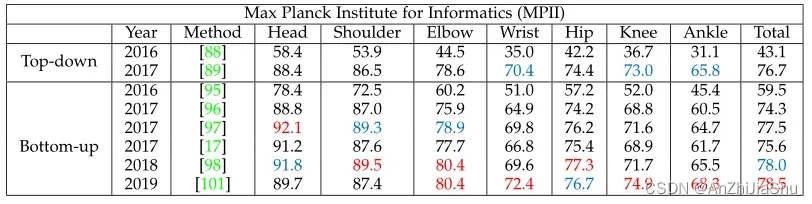
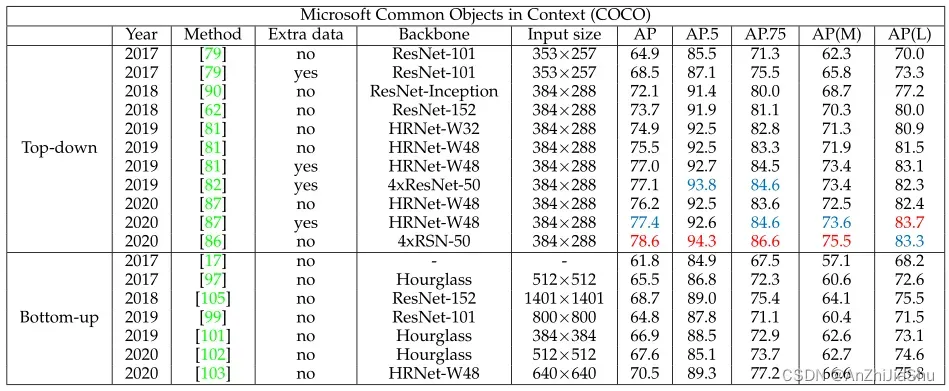
表6 显示了不同2D HPE方法在COCO数据集的 test-dev set 上的实验结果,以及每种方法的实验设置(额外数据、模型backbone、输入图像大小)和AP分数。
表6: COCO test-dev 集上不同2D多人HPE方法的比较结果。使用AP(AP.5: OKS=0.50 时的AP,AP.75: OKS=0.75 时的AP,AP(M) 用于中等对象,AP(L) 用于大对象)评估。最好的两个分数分别用红色和蓝色标记
5.4 Datasets for 3D HPE
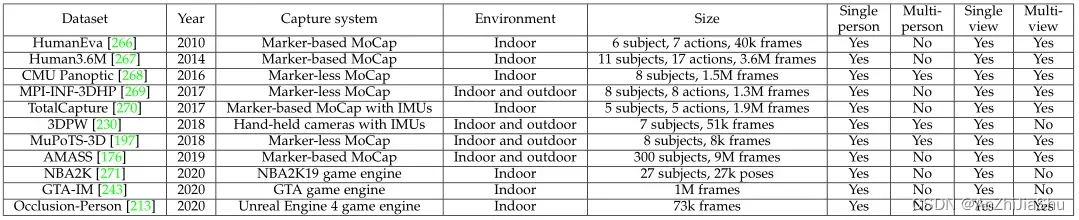
与众多具有高质量标注的2D人体姿态数据集相比,为3D HPE数据集获取准确的3D注解是一项具有挑战性的任务,需要运动捕捉系统,如MoCap和可穿戴 IMUs。由于这一要求,许多 3D姿态数据集都是在受约束的环境中创建的。表7总结了不同设置下广泛使用的3D姿势数据集。
HumanEva 数据集: HumanEva 数据集包含7个经过校准的视频序列(4个灰度视频和3个带颜色视频),带有由ViconPeak的商业MoCap系统捕获的ground truth 3D标注。该数据集由4名受试者在3m×2m的区域内执行6种常见动作(步行、慢跑、手势、投掷和接球、拳击和组合)组成。HumanEva数据集链接
Human3.6M 数据集: Human3.6M 是使用最广泛的单目图像和视频 3D HPE室内数据集。11名专业演员(6名男性和5名女性)在室内实验室环境中从4个不同的角度进行17项活动(如吸烟、拍照、通话)。此数据集包含 3.6百万个由基于精确标记的MoCap系统捕获的ground truth 3D人体姿态标注。有3个具有不同训练和测试数据分割的 protocol,protocol#1 使用受试者S1、S5、S6和S7的图像进行训练,使用受试者S9和S11的图像进行测试;protocol#2 使用与 protocol#1相同的训练测试分割,但预测在与ground-truth进行比较之前通过严格的转换进行进一步的后处理。protocol#3 使用受试者S1、S5、S6、S7和S9的图像进行训练,使用受试者S11的图像进行测试。数据集链接
MPI-INF-3DHP 数据集: MPI-INF-3DHP是一个由多摄像头工作室中的商用无标记MoCap系统捕获的数据集。8名演员(4名男性和4名女性)执行8项人类活动,包括步行、坐姿、复杂的运动姿势和动态动作。来自14台摄像机的超过1.3百万帧被记录在一个允许自动分割和增强的绿屏工作室中。MPI-INF-3DHP 数据集数据集链接
TotalCapture 数据集: TotalCapture 包含超过1.9百万帧的IMU和Vicon标签的完全同步视频。13个传感器放置在关键身体部位,如头部、上背部和下背部、上下肢和脚。数据是在室内用8台校准的全高清摄像机采集的,摄像机的频率为60 Hz,测量面积约为。有5名演员(4男1女)表演动作,重复3次,包括步行、跑步和自由泳。TotalCapture 数据集链接
CMU Panoptic Dataset: CMU全景数据集包含65个序列(5.5小时),1.5 百万个多人场景的3D骨架。该数据集由一个无标记运动捕获系统捕获,该系统带480个VGA相机视图、30多个HD视图、10个RGB-D传感器和一个经过校准的基于硬件的同步系统。测试集包含9600帧高清相机,用于4种活动(Ultimatum, Mafia, Haggling, and Pizza)。CMU Panoptic 数据集链接
3DPW Dataset: 3DPW 数据集由手持相机和 IMUs 在自然场景中采集,捕捉日常活动(例如,城市购物、上楼梯、做运动、喝咖啡和坐公共汽车)。该数据集中有60个视频序列(超过51000帧),相应的3D姿态由可穿戴IMU计算。测试集包含9600帧高清摄像头,用于4种活动(Ultimatum, Mafia, Haggling, and Pizza)。3DPW 数据集链接
MuCo-3DHP Dataset: MuCo-3DHP数据集是一个多人3D训练集,由MPI-INF-3DHP单人数据集组成,具有来自多视图无标记运动捕捉系统的 ground truth 3D 姿态。采用了背景增强和阴影感知前景增强的方法实现数据的多样性。MU-Co-3DHP 数据集链接
MuPoTS-3D Dataset: MuPoTS-3D数据集是一个多人3D测试集,其 ground truth 3D姿态由包含20个真实场景(5个室内场景和15个室外场景)的多视图无标记MoCap系统捕获。 在一些室外镜头中,有遮挡、剧烈的照明变化和镜头光斑等具有挑战性的样本。8名受试者在20个序列中收集了8000多个帧。MuPo TS-3D 数据集链接
AMASS Dataset: AMASS数据集是通过统一15个不同的基于光学标记的 MoCap 数据集,并使用 SMPL 模型来表示人体运动序列而创建的。这个大型数据集包含8593个序列中40多个小时的运动数据,其中900万帧以60 Hz的频率采样。300名受试者记录了11000多个动作。AMASS 数据集链接
NBA2K Dataset: NBA2K数据集是通过使用 RenderDoc 拦截游戏引擎和图形卡之间的调用,从NBA2K19 视频游戏中提取的。该合成数据集包含27个主题的27144个篮球姿势,该数据集提供了35个关键点的3D姿势和相应的RGB图像,质量很高。NBA2K 数据集链接
GTA-IM Dataset: GTA-IM数据集是GTA游戏引擎从Grand Theft Auto(GTA) 视频游戏中收集的GTA室内运动数据集。有100万个分辨率为1920×1080的 RGB-D帧, ground truth 3D人体姿态为98个关节,涵盖各种动作,包括坐、走、爬和开门。每个场景都包含多个设置,例如客厅、卧室和厨房,以强调人与场景的交互。GTA-IM 数据集链接
Occlusion-Person Dataset: 遮挡人数据集是一个多视图合成数据集,具有图像中关节的遮挡标签。Unrelcv用于从3D模型渲染多视图图像和深度图。在半径为两米的圆上,每45度使用一个相机,共使用8个相机。此数据集包含73K帧,遮挡了 20.3% 的关节。该数据集也提供了ground truth 3D 标注和遮挡标签。Occlusion-Person数据集链接
5.5 Evaluation Metrics for 3D HPE
MPJPE(Mean Per Joint Position Error:平均每关节位置误差)是评估3D HPE性能最广泛使用的评估指标。通过使用估计的3D关节和 ground truth 位置之间的欧氏距离计算MPJPE,如下所示:
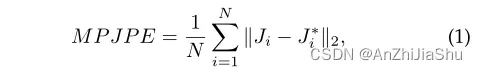
PMPJPE 也称为重建误差,是经过估计姿态和 ground truth 姿态之间通过后处理进行刚性对齐后的MPJPE。
NMPJPE 是将预测位置按比例正则化为参考后的MPJPE。
MPVE (Mean Per V ertex Error) 测量ground trth 顶点和预测顶点之间的欧氏距离,如下所示:
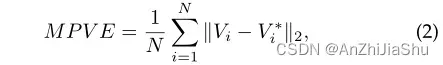
3DPCKis 是2D HPE评估中使用的正确关键点百分比(PCK)度量的3D扩展版本。如果预测与ground truth 之间的距离在某个阈值内,则认为预测的关节是正确的。通常阈值设置为150mm。
总结: 正如Ji等人所指出的,低 MPJPE 并不总是表示准确的姿态估计,因为它取决于预测的人体形状和骨骼比例。尽管 3DPCK 对不正确的关节更为稳健,但它无法评估正确关节的精度。此外,现有指标用于评估单个帧中姿态的精度,但现有的评估指标无法在连续帧上检查重建人体姿态的时间一致性和平滑性。设计能够评估具有时间一致性和平滑性的3D HPE性能的帧级评估指标仍然是一个悬而未决的问题。
5.6 Performance Comparison of 3D HPE Methods
表8∼表11为常用的单视图单人场景、单视图多人场景和多视图场景数据集上不同3D HPE方法的性能比较。
在表8中,大多数3D单视图单人HPE模型成功地在Human3.6M 数据集上以极高的精度估计了3D人体姿态。尽管Human3.6M 数据集有大量的训练和测试数据,但它只包含11名演员(6名男性和5名女性),他们执行17项活动,如吃饭、讨论、吸烟和拍照。在具有更复杂场景的野外数据上估计三维姿势时,这些方法的性能会下降。同时也观察到,基于模型的方法与无模型方法的性能相当。 在视频数据可用时利用时间信息可以提高性能。
表8:Human3.6M 数据集上不同3D单视图单人HPE方法的比较。 最好的两个分数分别用红色和蓝色标记。在 model-free 方法中,“Direct”表示无需二维姿态表示,直接估计三维姿态的方法。“Lifting”表示将2D姿态表示提升到3D空间(即3D姿态)的方法。“Temporal”是指使用时间信息的方法。
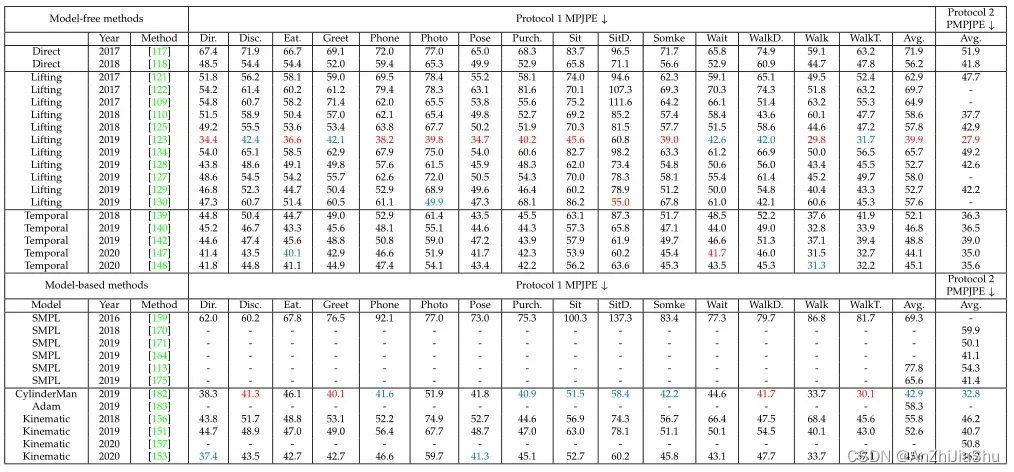
由于遮挡更严重,3D单视图多人HPE比3D单视图单人HPE更难完成。如表9和表10所示,近年来,单视图多人HPE方法取得了良好的进展。
表9: MuPoTS-3D数据集上不同3D单视图多人HPE方法的比较。 最好的两个分数分别用红色和蓝色标记
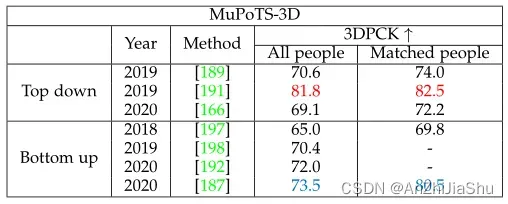
表10: CMU全景数据集上不同3D单视图多人HPE方法的比较。 Ultimatum, Mafia, Haggling, pizza 表示四种活动。最好的两个分数分别用红色和蓝色标记。
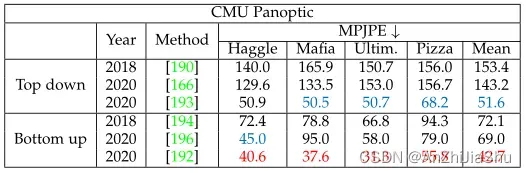
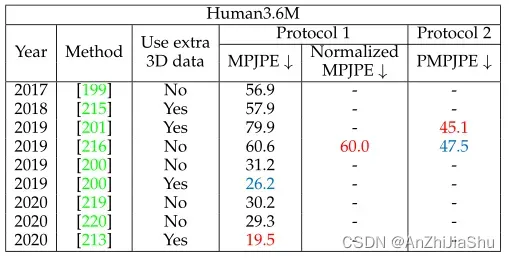
通过比较表8和表11的结果,可以明显看出,与使用相同数据集和评估指标的单视图3D HPE方法相比,多视图3D HPE方法的性能(例如, Protocol 1下的MPJPE)有所提高。
表11: Human3.6M 数据集上不同3D多视图HPE方法的比较。 最好的两个分数分别用红色和蓝色标记
6 APPLICATIONS
在本节中回顾 HPE 的几个流行应用及相关工作(图7)。

Action recognition, prediction, detection, and tracking 动作识别、预测、检测和跟踪: 姿态信息可用作各种应用的线索,如动作识别、预测、检测和跟踪。Angelini等人提出了一种使用基于姿态算法的实时动作识别方法。Yan等人利用姿态的动态骨架模式进行动作识别。Markovitz等人研究了人体姿态图,以检测视频中人类行为的异常。Cao等人使用预测的3D姿态进行 long-range 人体运动预测。Sun等人提出了一种用于视频对齐的视图不变概率姿态嵌入方法。
基于姿态的视频监控通过姿态和人体网格表示而非人类敏感身份进行监控,具有保护隐私的优点。 Das等人嵌入带姿态的视频来识别日常生活活动,以监控人类行为。
Action correction and online coaching 动作纠正和在线辅导: 一些活动,如舞蹈、体育和专业训练,需要精确的人体控制,以严格按照标准姿势进行反应。通常,私人教练负责面对面地纠正姿势和指导动作。在3D HPE和动作检测的帮助下,无需私人教练在场,AI私人教练只需设置相机就能让辅导更加方便。Wang等人设计了一个AI教练系统,该系统带有姿态估计模块,用于个性化的运动训练辅助。
Clothes parsing: 电子商务对服装购买等领域产生了显著的影响。服装产品图片已经不能满足客户的需求,客户希望挑选衣服时能看到自己穿着这件衣服的可靠外观。衣服解析和姿态转换通过推断穿着特定衣服的人的3D外观来实现。HPE可以为 Clothes parsing 提供合理的人体区域。此外,推荐系统可以通过基于所选项目的客户推断出的可靠3D外观进行适当性评估来升级。Patel等人实现了从3D姿态、形状和服装风格预测服装。
Animation, movie, and gaming 动画、电影和游戏: 运动捕捉是动画、电影和游戏行业中呈现具有复杂运动和真实物理交互角色的关键组件。动作捕捉设备通常价格昂贵,安装复杂,HPE可以提供真实的姿态信息,同时缓解对专业高成本设备的需求。
AR 和 VR: 增强现实(AR)技术旨在增强数字对象在真实环境中的交互体验。虚拟现实(VR)技术的目标是为用户提供身临其境的体验。AR和VR设备使用人体姿态信息作为输入来实习不同应用的目标。真实场景中生成卡通人物可以代替真实人物。Weng等人借助3D姿态估计和人体网格恢复,从单个照片创建3D角色动画。Zhang等人提出了一种基于姿态的系统,该系统将网球比赛的广播视频转换为交互式可控视频 sprites。视频 sprites 中的运动员保留了真正专业运动员的技术和风格。
Healthcare 医疗健康: HPE提供定量的人体运动信息,医生可以诊断一些复杂的疾病,进行康复训练和物理治疗。Lu等人设计了一种基于姿态的评估系统,用于评估帕金森病运动严重程度。Gu等人开发了一种基于姿态的物理治疗系统,可以在家里对患者进行评估和建议。此外,可以建立这样一个系统来检测异常动作并提前预测以下动作,如果系统确定可能发生危险,将立即发送警报。Chen等人使用HPE算法进行跌倒检测监测,以便提供即时帮助。此外,HPE方法可以为医院环境中的患者提供可靠的姿态标签,以加强对神经与自然行为相关的研究。
7 CONCLUSION AND FUTURE DIRECTIONS 结论及未来方向
本文系统地概述了最近基于深度学习的2D和3D HPE方法。本文介绍了这些方法的全面分类和性能比较。尽管 HPE 取得了巨大成功,但如第3.3节和4.3节所述,仍然存在许多挑战。在此,我们进一步指出促进HPE研究进展的几个有希望的未来方向。
- Domain adaptation for HPE 领域适配。 对于一些应用,如从婴儿图像或艺术品集合估计人类姿态,没有足够的带有ground truth 标注的训练数据。此外,这些应用的数据与标准姿态数据集的分布不同,在现有标准数据集上训练的HPE方法可能无法很好地推广到不同领域。最近利用基于GAN的学习方法缓解领域差距,但如何有效地传递人体姿态知识以弥补领域差距仍未解决。
- 人体模型(如SMPL、SMPLify、SMPLX、GHUM& GHUML和Adam)用于建模人体网格表示,但这些模型有大量的参数。如何在保持重建网格质量的同时减少参数数量是一个有趣的问题。 此外,不同的人有不同的身体形状变形,可以利用其他信息,如BMI和轮廓来生成更有效的人体模型。
- 大多现有方法都忽略了人与3D场景的交互。 可以探索很强的人-场景关系约束,例如人类主体不能同时出现在场景中其他对象的位置,具有语义线索的物理约束可以提供可靠和真实的三维HPE。
- 三维HPE用于视觉跟踪和分析。现有的基于视频的三维人体姿态和形状重建算法都是不平滑、不连续的。 一个原因是,MPJPE等评估指标无法评估平滑度和真实度。应制定适当的帧级评估指标,重点关注时间一致性和运动平滑度。
- 现有训练有素的网络很少关注分辨率不匹配。 HPE网络的训练数据通常是高分辨率的图像或视频,当从低分辨率输入中预测人体姿态时,可能会导致不准确的估计。对比学习方案(例如,原始图像及其低分辨率版本作为一个 positive pair)可能有助于构建分辨率感知 HPE网络。
- 视觉任务中的深层神经网络容易受到对抗性攻击 。难以察觉的噪声会显著影响HPE的性能。很少有文献考虑针对HPE的对抗性攻击,准的对抗性攻击防御的研究可以提高HPE网络的鲁棒性,促进基于姿态的实际应用。
- 由于人体的异质性,人体各部位可能具有不同的运动模式和形状。单个共享网络体系结构对于估计具有不同自由度的所有身体部位可能不是最佳的。 神经结构搜索(Neural Architecture Search:NAS)可以搜索最佳结构来估计每个身体部位。此外,NAS还可用于发现高效的HPE网络体系结构,以降低计算成本。当需要满足多个目标(例如延迟、准确性和能耗)时,也值得在HPE中探索多目标NAS。
文章出处登录后可见!