前言
本文接上一篇博客:Python处理JSON文件数据各类操作一文详解。
处理JSON文件一般并且进行统计或分析都需要把JSON文件格式转换为dataframe形式或是将dataframe转换为JSON,这都需要用到to_json()和read_json()函数。如果能够掌握该两种函数的参数用法能够节省不少时间和代码对后续的文件再处理,因此本篇文章初衷为详细介绍并运用此函数来达到彻底掌握的目的。希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新。纯分享,希望大家喜欢。
to_json()
to_json()函数主要是将DataFrame数据类型转换为JSON文件格式。
直接看官网解释:
默认参数格式为:
DataFrame.to_json(path_or_buf=None, orient=None, date_format=None, double_precision=10, force_ascii=True, date_unit='ms', default_handler=None, lines=False, compression=None, index=True) 
参数说明:
- path_or_buf:【string or file handle, optional】可以指定对象为文件路径或者为DataFrame,如果不指定,则返回结果为一个字符串。
- orient:【string】,指定为将要输出的JSON格式。其中我们输入的对象可能为Series或者为DataFrame:
- Series:默认索引为index,也就是行。允许的值输出形式有:{‘split’,’records’,’index’}
- DataFrame:默认索引为columns,也就是列索引。允许的值输出形式有:{‘split’,’records’,’index’,’columns’,’values’}
- JSON字符形式的输出格式类型:
- ‘split’:将行索引index,列索引columns,值数据date分开来。dict like {‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values]}。
- ‘records’:将列表list格式,以[{列名->值},..]形式输出。list like [{column -> value}, … , {column -> value}]
- ‘index’:将字典以{行索引:{列索引:值}}以这种形式输出dict like {index -> {column -> value}}。
- ‘columns’:将字典以{列索引:{行索引:值}}以这种形式输出 dict like {column -> {index -> value}}。
- ‘values’:就全部输出值就好了。
- ‘table’:这个输出有点复杂,具体描述该文件。dict like {‘schema’: {schema}, ‘data’: {data}} describing the data, and the data component is like
orient='records'.。到时候实现一下即可了解、
- date_format:【None, ‘epoch’, ‘iso’】,日期转换类型。可将日期转为毫秒形式,iso格式为ISO8601时间格式。对于orient=’table’,默认值为“iso”。对于所有其他方向,默认值为“epoch”。
- double_precision:【int, default 10】,对浮点值进行编码时使用的小数位数。默认为10位。
- force_unit:【boolean, default True】,默认开启,编码位ASCII码。
- date_unit:【string, default ‘ms’ (milliseconds)】,编码到的时间单位,控制时间戳和ISO8601精度。“s”、“ms”、“us”、“ns”中的一个分别表示秒、毫秒、微秒和纳秒.默认为毫秒。
- default_handler :【callable, default None】,如果对象无法转换为适合JSON的格式,则调用处理程序。应接收单个参数,该参数是要转换并返回可序列化对象的对象。
- lines:【boolean, default False】,如果“orient”是“records”,则写出以行分隔的json格式。如果“orient”不正确,则会抛出ValueError,因为其他对象与列表不同。
- compression:【None, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’】,表示要在输出文件中使用的压缩的字符串,仅当第一个参数是文件名时使用。
- index:【boolean, default True】,是否在JSON字符串中包含索引值。仅当orient为“split”或“table”时,才支持不包含索引(index=False)。
接下来进行操作演示:
先创建对应dataframe:
date={'code':[20,20,19,19,20],
'type':['hive','hive','clickhouse','clickhouse','hive'],
'datetime':['2022-5-23','2022-5-23','2022-5-23','2022-5-23','2022-5-24']
}
df=pd.DataFrame(date)
time_data = pd.to_datetime(df["datetime"],format='%Y-%m-%d')
df['datetime']=time_data
df.dtypes 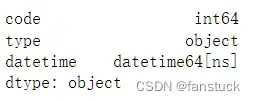
split:
df.to_json(orient='split')
该方法将行索引和列索引和值全都分开来进行存储成json格式。
records
df.to_json(orient='records')
直接将dataframe的内容输出为列表,此类方法不会把index和columns记录到JSON文件中。
index
df.to_json(orient='index')
该方法直接以index行索引为键,不记录列索引columns进行保存。
columns
df.to_json(orient='columns')
该方法直接以columns列索引为键,不记录行索引index进行保存。
values
df.to_json(orient='values')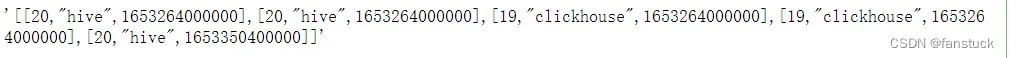
该方法就直接输出值列表了,没有记录index和columns。
lable
df.to_json(orient='table')
从输出格式上来看,该输出将Dataframe输出为具体的表格记录,schema中记录了各个index、columns、data的类型,默认主键为”primaryKey”:[“index”]。其中data为为逐行记录数据,每一行根据索引index和columns来输出。
date_format
date_format有两种格式可以选择,分别是’epoch‘和’iso’。默认为epoch,意为将日期转为毫秒形式:
df.to_json(orient='values',date_format='epoch')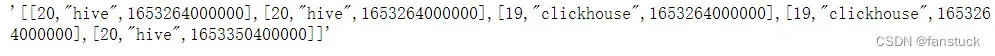 可以设定为ISO标准:
可以设定为ISO标准:
df.to_json(orient='values',date_format='iso') ISO标准也就是我们熟知的标准时间格式。
double_precision
df.to_json(orient='values',date_format='iso',double_precision=10)精度默认为小数点后10位,自己可以调值。
force_ascii
默认为ASCII编码,这里不用演示。
date_unit
df.to_json(orient='values',date_unit='s')
该参数关联epoch,设定的参数将觉得读出来的datetime转化为秒还是毫秒、微秒和纳秒.默认为毫秒。
default_handler
该函数如果对象无法转换为适合JSON的格式,则调用处理程序。不作演示。
index
df.to_json(orient='split',index=False)index设定只能orient为split和table的时候使用,默认为True,设定为False将不再记录index。
参阅
文章出处登录后可见!