参考文章:计算机视觉发展史
参考书籍:【深度学习与计算机视觉】 叶韵编著
计算机视觉的发展
计算机视觉是深度学习领域最热门的研究领域之一,目前在各领域应用广泛,而它是如何发展至今,让我们一起回顾一下计算机视觉的发展史。
20世纪50年代,主题是二维图像的分析和识别
1959年,神经生理学家David Hubel和Torsten Wiesel通过猫的视觉实验,首次发现了视觉初级皮层神经元对于移动边缘刺激敏感,发现了视功能柱结构,为视觉神经研究奠定了基础——促成了计算机视觉技术40年后的突破性发展,奠定了深度学习之后的核心准则。
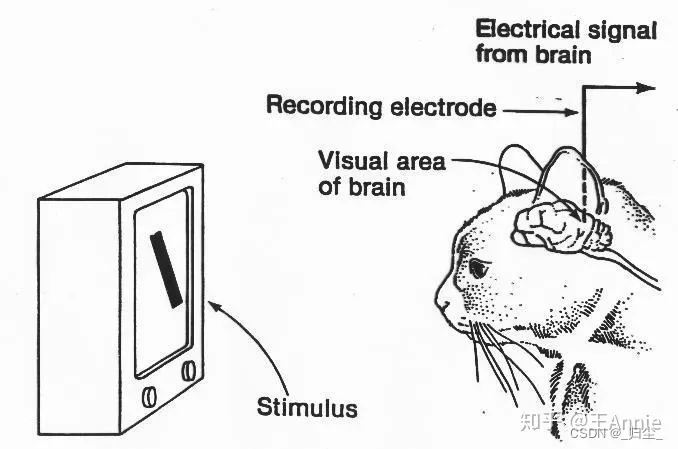
1959年,Russell和他的同学研制了一台可以把图片转化为被二进制机器所理解的灰度值的仪器——这是第一台数字图像扫描仪,处理数字图像开始成为可能。
这一时期,研究的主要对象如光学字符识别、工件表面、显微图片和航空图片的分析和解释等。
20世纪60年代,开创了三维视觉理解为目的的研究
1965年, Lawrence Roberts《三维固体的机器感知》描述了从二维图片中推导三维信息的过程。现代计算机视觉的前导之一,开创了理解三维场景为目的的计算机视觉研究。他对积木世界的创造性研究给人们带来极大的启发,之后人们开始对积木世界进行深入的研究,从边缘的检测、角点特征的提取,到线条、平面、曲线等几何要素分析,到图像明暗、纹理、运动以及成像几何等,并建立了各种数据结构和推理规则。

1966, MITAI实验室的Seymour Papert教授决定启动夏季视觉项目,并在几个月内解决机器视觉问题。Seymour和Gerald Sussman协调学生将设计一个可以自动执行背景/前景分割,并从真实世界的图像中提取非重叠物体的平台。——虽然未成功,但是计算机视觉作为一个科学领域的正式诞生的标志。
1969年秋天,贝尔实验室的两位科学家Willard S. Boyle和George E. Smith正忙于电荷耦合器件(CCD)的研发。它是一种将光子转化为电脉冲的器件,很快成为了高质量数字图像采集任务的新宠,逐渐应用于工业相机传感器,标志着计算机视觉走上应用舞台,投入到工业机器视觉中。
20世纪70年代,出现课程和明确理论体系
70年代中期,麻省理工学院(MIT)人工智能(AI)实验室:CSAIL正式开设计算机视觉课程。

1977年David Marr在MIT的AI实验室提出了,计算机视觉理论(Computational Vision),这是与 Lawrence Roberts当初引领的积木世界分析方法截然不同的理论。计算机视觉理论成为80年代计算机视觉重要理论框架,使计算机视觉有了明确的体系,促进了计算机视觉的发展。
20世纪80年代 ,独立学科形成,理论从实验室走向应用
1980年,日本计算机科学家Kunihiko Fukushima在Hubel和Wiesel的研究启发下,建立了一个自组织的简单和复杂细胞的人工网络——Neocognitron,包括几个卷积层(通常是矩形的),他的感受野具有权重向量(称为滤波器)。这些滤波器的功能是在输入值的二维数组(例如图像像素)上滑动,并在执行某些计算后,产生激活事件(2维数组),这些事件将用作网络后续层的输入。Fukushima的Neocognitron可以说是第一个神经网络,是现代 CNN 网络中卷积层+池化层的最初范例及灵感来源。
1982年,David Marr发表了有影响的论文-“愿景:对人类表现和视觉信息处理的计算研究”。基于Hubel和Wiesel的想法视觉处理不是从整体对象开始, David介绍了一个视觉框架,其中检测边缘,曲线,角落等的低级算法被用作对视觉数据进行高级理解的铺垫。同年《视觉》(Marr, 1982)一书的问世,标志着计算机视觉成为了一门独立学科。

1982年 日本COGEX公司于生产的视觉系统DataMan,是世界第一套工业光学字符识别(OCR)系统。
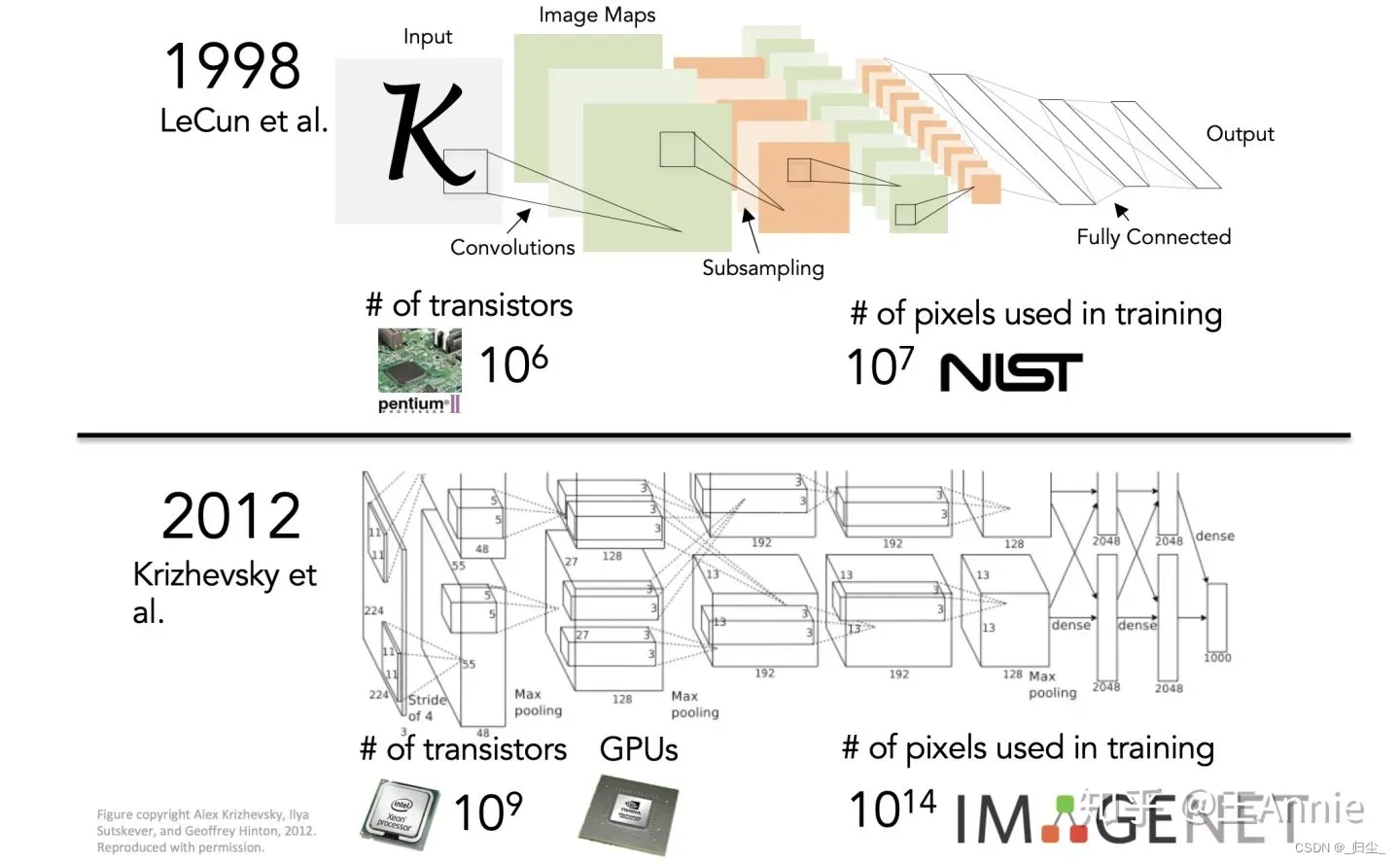
1989年,法国的Yann LeCun将一种后向传播风格学习算法应用于Fukushima的卷积神经网络结构。在完成该项目几年后,LeCun发布了LeNet-5–这是第一个引入今天仍在CNN中使用的一些基本成分的现代网络。现在卷积神经网络已经是图像、语音和手写识别系统中的重要组成部分。
20世纪90年代,特征对象识别开始成为重点
1997年,伯克利教授Jitendra Malik(以及他的学生Jianbo Shi)发表了一篇论文,描述了他试图解决感性分组的问题。研究人员试图让机器使用图论算法将图像分割成合理的部分(自动确定图像上的哪些像素属于一起,并将物体与周围环境区分开来)
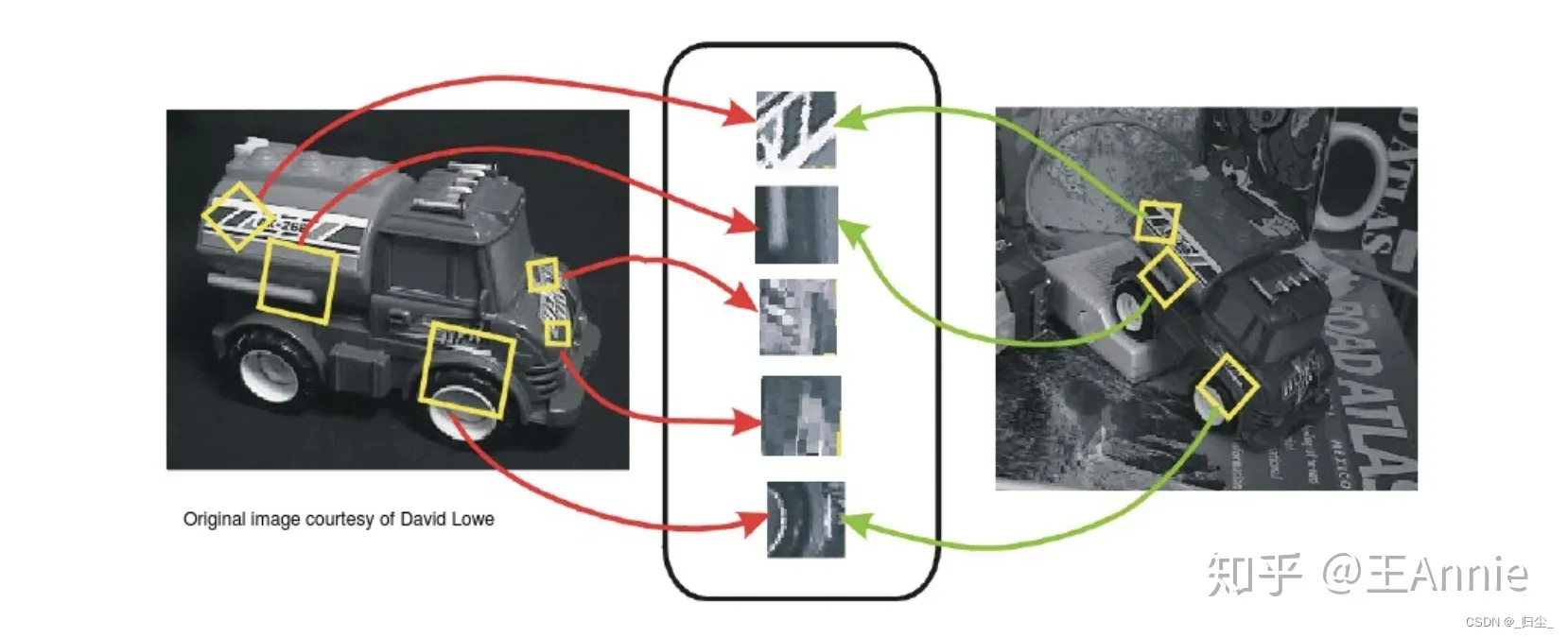
1999年, David Lowe 发表《基于局部尺度不变特征(SIFT特征)的物体识别》,标志着研究人员开始停止通过创建三维模型重建对象,而转向基于特征的对象识别。
1999年,Nvidia公司在推销Geforce 256芯片时,提出了GPU概念。GPU是专门为了执行复杂的数学和集合计算而设计的数据处理芯片。伴随着GPU发展应用,游戏行业、图形设计行业、视频行业发展也随之加速,出现了越来越多高画质游戏、高清图像和视频。
21世纪初,图像特征工程,出现真正拥有标注的高质量数据集
2001年,Paul Viola 和Michael Jones推出了第一个实时工作的人脸检测框架。虽然不是基于深度学习,但算法仍然具有深刻的学习风格,因为在处理图像时,通过一些特征可以帮助定位面部。该功能依赖于Viola / Jones算法,五年后,Fujitsu 发布了一款具有实时人脸检测功能的相机。
2005年,由Dalal & Triggs提出来方向梯度直方图,HOG(Histogramof Oriented Gradients)应用到行人检测上。是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征方法。
2006年,Lazebnik, Schmid & Ponce提出一种利用空间金字塔即 SPM (Spatial Pyramid Matching)进行图像匹配、识别、分类的算法,是在不同分辨率上统计图像特征点分布,从而获取图像的局部信息。
2006年,Pascal VOC项目启动。它提供了用于对象分类的标准化数据集以及用于访问所述数据集和注释的一组工具。创始人在2006年至2012年期间举办了年度竞赛,该竞赛允许评估不同对象类识别方法的表现。检测效果不断提高。
2006年左右,Geoffrey Hilton和他的学生发明了用GPU来优化深度神经网络的工程方法,并发表在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。他给多层神经网络相关的学习方法赋予了一个新名词–“深度学习”。随后深度学习的研究大放异彩,广泛应用在了图像处理和语音识别领域,他的学生后来赢得了2012年ImageNet大赛,并使CNN家喻户晓。
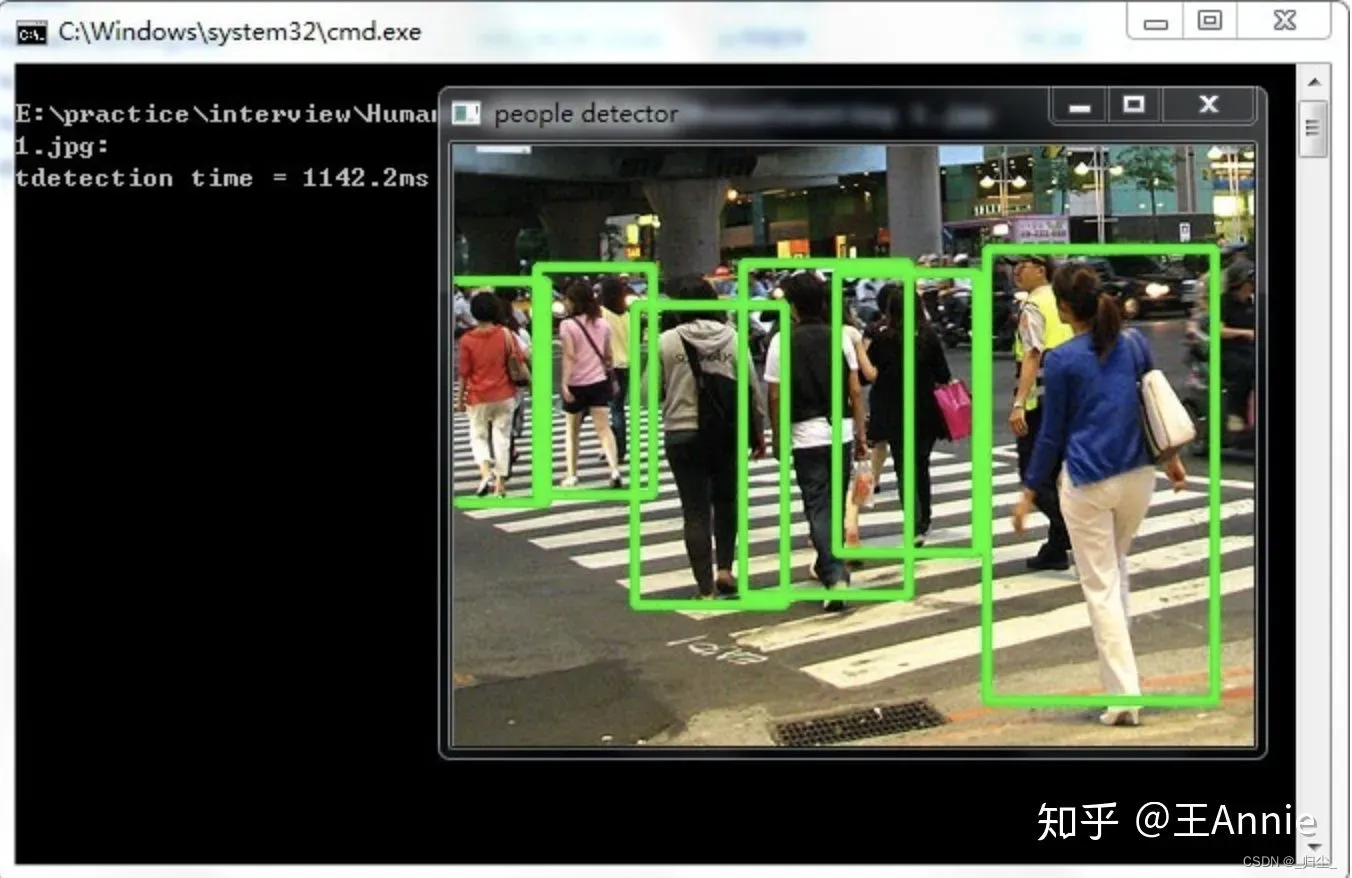
2009年,由Felzenszwalb教授在提出基于HOG的deformable parts model(DPM),可变形零件模型开发,它是深度学习之前最好的最成功的objectdetection & recognition算法。它最成功的应用就是检测行人,目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被VOC授予”终身成就奖”。
2010年-至今 深度学习在视觉中的流行,在应用上百花齐放
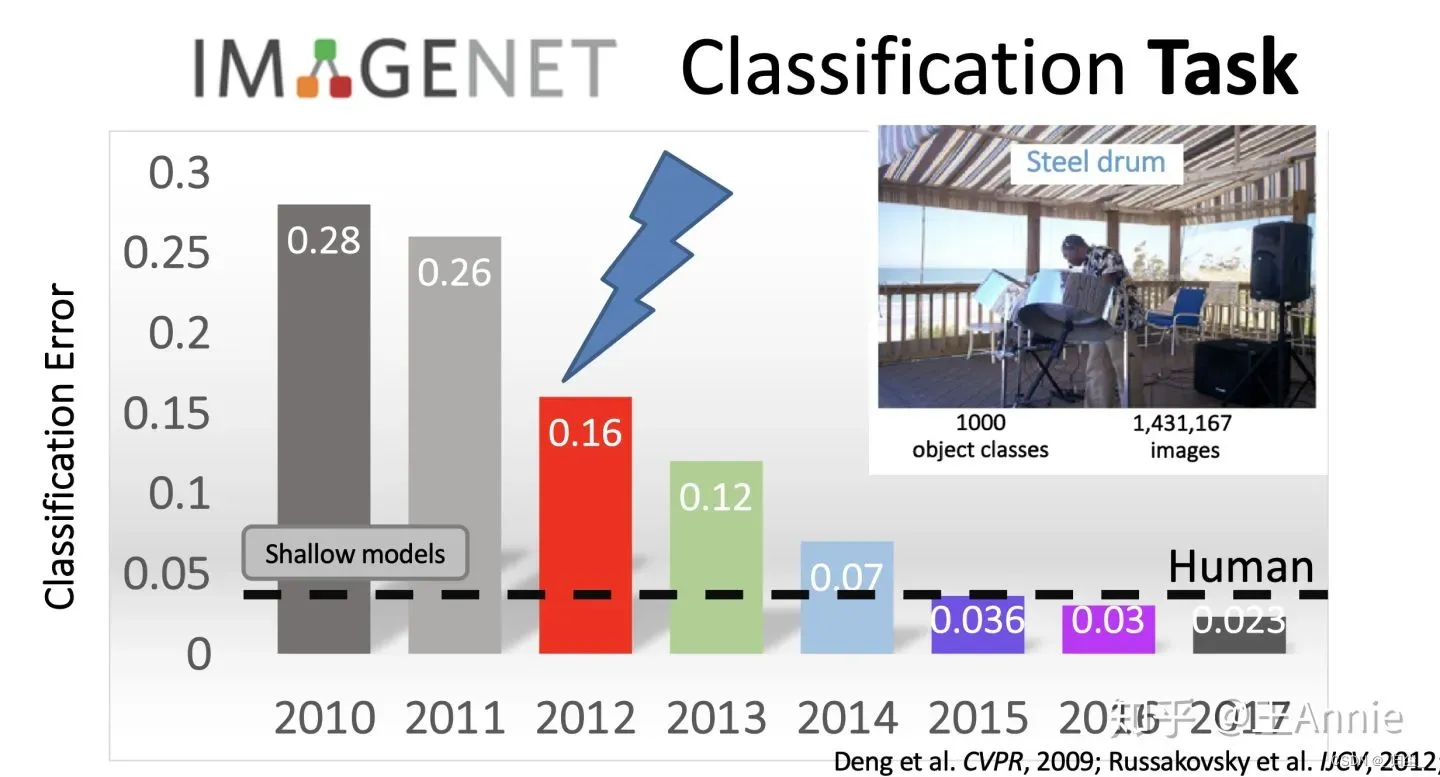
2009年,李飞飞教授等在CVPR2009上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,发布了ImageNet数据集,这是为了检测计算机视觉能否识别自然万物,回归机器学习,克服过拟合问题,经过三年多在筹划组建完成的一个大的数据集。从10年-17年,基于ImageNet数据集共进行了7届ImageNet挑战赛,李飞飞说”ImageNet改变了AI领域人们对数据集的认识,人们真正开始意识到它在研究中的地位,就像算法一样重要”。ImageNet是计算机视觉发展的重要推动者,和深度学习热潮的关键推动者,将目标检测算法推向了新的高度。

2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 创造了一个“大型的深度卷积神经网络”,也即现在众所周知的 AlexNet,赢得了当年的 ILSVRC。这是史上第一次有模型在 ImageNet 数据集表现如此出色。论文“ImageNet Classification with Deep Convolutional Networks”,迄今被引用约 7000 次,被业内普遍视为行业最重要的论文之一,真正展示了 CNN 的优点。机器识别的错误率从25%左右。降低了百分之16%左右,跟人类相比差别不大。是自那时起,CNN 才成了家喻户晓的名字。详细来说,AlexNet是一个有4卷积层+2全连接层的卷积神经网络,当时利用CUDA给出的实现,主要的改进有以下3点:1. 更深的网络结构;2. 校正线性单元(Rectified Linear Unit, ReLU),Dropout等方法的应用; 3. GPU训练网络。
2014年,蒙特利尔大学提出生成对抗网络(GAN):拥有两个相互竞争的神经网络可以使机器学习得更快。一个网络尝试模仿真实数据生成假的数据,而另一个网络则试图将假数据区分出来。随着时间的推移,两个网络都会得到训练,生成对抗网络(GAN)被认为是计算机视觉领域的重大突破。
2017-2018 年深度学习框架的开发发展到了成熟期。PyTorch 和 TensorFlow 已成为首选框架,它们都提供了针对多项任务(包括图像分类)的大量预训练模型。
近年来,国内外巨头纷纷布局计算机视觉领域,开设计算机视觉研究实验室。以计算机视觉新系统和技术赋能原有的业务,开拓战场。
如Facebook的AI Research(FAIR)在视觉方面2016年声称其DeepFace人脸识别算法有着97.35%的识别准确率,几乎与人类不分上下。2017,Lin, Tsung-Yi等提出特征金字塔网络,可以从深层特征图中捕获到更强的语义信息。同时提出Mask R-CNN,用于图像的实例分割任务,它使用简单、基础的网络设计,不需要多么复杂的训练优化过程及参数设置,就能够实现当前最佳的实例分割效果,并有很高的运行效率。
2016,亚马逊收购了一支欧洲顶级计算机视觉团队,为Prime Air无人机加上识别障碍和着陆区域的能力。开发无人机送货。2017年亚马逊网络服务(AWS)宣布对其识别服务进行了一系列更新,为云客户提供基于机器学习的计算机视觉功能。客户将能够在数百万张面孔的集合上进行实时人脸搜索。例如,Rekognition可用于验证一个人的图像与现有数据库中的另一个图像相匹配,数据库高达数千万个图像,具有亚秒级延迟。
2018年末,英伟达发布的视频到视频生成(Video-to-Video synthesis),它通过精心设计的发生器、鉴别器网络以及时空对抗物镜,合成高分辨率、照片级真实、时间一致的视频,实现了让AI更具物理意识,更强大,并能够推广到新的和看不见的更多场景。
2019, BigGAN,同样是一个GAN,只不过更强大,是拥有了更聪明的课程学习技巧的GAN,由它训练生成的图像连它自己都分辨不出真假,因为除非拿显微镜看,否则将无法判断该图像是否有任何问题,因而,它更被誉为史上最强的图像生成器。2020年5月末,Facebook发布新购物AI,通用计算机视觉系统GrokNet让“一切皆可购买”。

自从20世纪中期开始,计算机视觉不断发展,研究经历了从二维图像到三维到视频到真实空间的探知,操作方法从构建三维向特征识别转变,算法从浅层神经网络到深度学习,数据的重要性逐渐被认知,伴随着计算机从理论到应用的速度加快,高质量的各种视觉数据不断沉淀,相信无论在社会经济农业还是工业领域,还是视频直播、游戏、电商不断发展,一定还会有更多好玩炫酷的计算机视觉应用出现在我们身边。
计算机视觉的应用
安防
安防是最早应用计算机视觉的领域之一。人脸识别和指纹识别在许多国家的公共安全系统里都有应用,因为公共安全部门拥有真正意义上最大的人脸库和指纹库。常见的应用有利用人脸库和公共摄像头对犯罪嫌疑人进行识别和布控。如利用公共摄像头捕捉到的画面,在其中查找可能出现的犯罪嫌疑人,用超分辨率技术对图像进行修复,并自动或辅助人工进行识别以追踪犯罪嫌疑人的踪迹;将犯罪嫌疑人照片在身份库中进行检索以确定犯罪嫌疑人身份也是常见的应用中之一;移动检测也是计算机视觉在安防中的重要应用,利用摄像头监控画面移动用于防盗或者劳教和监狱的监控。
交通
提到交通方面的应用,一些开车的朋友们一定立刻就想到了违章拍照,利用计算机视觉技术对违章车辆的照片进行分析提取车牌号码并记录在案。这是大家都熟知的一项应用。此外很多停车场和收费站也用到车牌识别。除了车牌识别,还有利用摄像头分析交通拥堵状况或进行隧道桥梁监控等技术,但应用并没有那么广泛。前面说的是道路应用,针对汽车和驾驶的计算机视觉技术也有很多,如行人识别、路牌识别、车辆识别、车距识别,还有更进一步的自动驾驶方向等。
工业生产
工业领域也是最早应用计算机视觉技术的领域之一。如利用摄像头拍摄的图片对部件长度进行非精密测量;利用识别技术识别工业部件上的缺陷和划痕等;对生产线上的产品进行自动识别和分类用来筛选不合格产品;通过不同角度的照片重建零部件三维模型。
在线购物
最经典的应用是淘宝和京东的拍照购物功能。除此之外,还有很多方面在应用。图片信息是在电商商品列表中扮演着信息传播最重要的角色,尤其是在手机上。当我们打开购物APP时,最先最快看到的信息一定是图片。而为了让每一位用户都能看到最干净、有效、赏心悦目的图片,电商背后的计算机视觉就成了非常重要的技术。几乎所有的电商都有违规图片检测的算法,用于检测一些带有违规信息的图片,如不实促销标签、色情图片等。在移动网络主导的时代,一个手机APP的一个页面能展示图片的数量非常有限,如果搜索一个商品返回的结果里有重复图片出现,则是对展示页面的巨大浪费,于是重复图片检测算法又发挥了重要的作用。对于第三方商家,一些商家在商品页面发布违规或是虚假宣传的文字很容易被检测,所有一些商家会把文字放到图片里,这个时候文字识别(Optical Character Recongnition, OCR)就成了保护消费者利益的防火墙。除了保护消费者利益,计算机视觉技术也在电商领域里保护着一些名人的利益,一些精通Photoshop的商家常常把明星的脸放到自己的商品广告中,人脸识别便成了打击这些行为的一把利剑。
信息检索
搜索引擎可以利用文字描述返回用户想要的信息,图片也可以作为输入来进行信息的检索。最早做图片搜素的是一家老牌网站Tineye,上传图片就能返回相同或相似的结果。后来随着深度学习在计算机视觉领域的崛起,Google和百度等公司也推出了自己的图片搜索引擎,只要上传自己拍摄的图片,就能从返回的结果中找到相关的信息。
游戏娱乐
在游戏娱乐领域,计算机视觉的主要应用是在体感游戏,如Kinect、Wii和PS4等。在这些游戏设备上会用到一种特殊的深度摄像头,用于返回场景到摄像头距离的信息,从而用于三维重建或辅助识别,这种办法比常见的双目视觉技术更加可靠实用。此外就是手势识别、人脸识别、人体姿势识别等技术,用来接收玩家指令或和玩家互动。
摄影摄像
数码相机诞生后,计算机视觉技术就开始应用于消费电子领域的照相机和摄像机上。最常见的就是人脸,尤其是笑脸识别,不需要再喊“茄子”,只要露出微笑就会捕捉下美好的瞬间。新手照相也不用担心对焦不准,相机会自动识别出人脸并对焦。手抖的问题也在机械技术和视觉技术结合的手段下,得到了一定程度上的控制。近些年一个新的计算机视觉子学科——计算摄影学的崛起,也给消费电子领域带来了新玩意——“光场相机”。有了光场相机甚至不需要对焦,拍完之后回家慢慢选对焦点,聚焦到任何一个距离上的画面都能一次捕捉到。除了图像获取外,图像后期处理也有很多计算机视觉技术的应用,如Photoshop中的图像分割技术和抠图技术,高动态范围(High Dynamic Range, HDR)技术用于美化照片,利用图像拼接算法创建全景照片等。
机器人/无人机
机器人和无人机中主要利用计算机视觉和环境发生互动,如教育或玩具机器人利用人脸识别和物体识别对用户和场景作出相应的反应。无人机也是近年来火热的一个领域。用于测量勘探的无人机可以在很低成本下采集海量的图片用于三维地形重建;用于自动物流的无人机利用计算机视觉识别降落地点,或者辅助进行路线规划;用于拍摄的无人机,目标追踪技术和距离判断等可以辅助飞行控制系统作出精确的动作,用于跟踪拍摄或自拍等。
体育
高速摄像系统已经普遍用于竞技体育中。球类运动中结合时间数据和计算机视觉的进球判断、落点判断、出界判断等。基于视觉技术对人体动作进行捕捉和分析也是一个活跃的研究方向。
医疗
医疗影像是医疗领域中一个非常活跃的研究方向,各种影像和视觉技术在这个领域中至关重要。计算断层成像(Computed Tomography, CT)和磁共振成像(Magnetic Resonance Imaging, MRI)中重建三维图像,并进行一些三维表面渲染都有涉及一些计算机视觉的基础手段。细胞识别和肿瘤识别用于辅助诊断,一些细胞或者体液中小型颗粒物的识别,还可以用来量化分析血液或其他体液中的指标。在医疗影像领域有一个国际医学影像计算与计算机辅助介入会议(International Conference on Medical Image Computing and Computer Assisted Intervention, MICCAI),每年会议上都会有许多计算机视觉在医疗领域的创新,它是一个非常有影响力的会议。
常见计算机视觉工具包
OpenCV
计算机视觉领域应用最广泛的开源工具包。它基于C/C++预研,支持Linux/Windows/MacOS/Android/iOS,并提供了Python, Matlab和Java等语言的接口。因为其丰富的接口,优秀的性能和商业友好的使用许可,不管是在学术界还是业界都非常受欢迎。OpenCV最早源于Intel公司1998年的一个研究项目。当时在Intel从事计算机视觉的工程师盖瑞·布拉德斯基(Gary Bardski)访问一些大学和研究组时发现学生之间实现计算机视觉算法用的都是各自实验室里的内部代码或者库,这样新来实验室的学生就能基于前人写的基本函数快速上手进行研究。于是OpenCV指在提供一个用于计算机视觉的科研和商业应用的高性能通用库。第一个alpha版本的OpenCV于2000年的CVPR上发布。在接下来的5年里,又陆续发布了5个beta版本。2006年发布了第一个正式版。2009年随着盖瑞加入了Willow Garage,OpenCV从Willow Garage得到了积极的支持,并发布了1.1版。2010年OpenCV发布了2.0版本,添加了非常完备的C++接口,从2.0开始的版本用户非常庞大,至今仍在维护和更新。2015年OpenCV3正式发布,除了架构的调整,还加入了更多算法、更多性能的优化和更加简洁的API,另外也加强了对GPU的支持,现在已经应用于许多研究机构和商业公司中。
MATLAB
MATLAB Compter Vision System Toolbox,一直以来就是学术界所钟爱的工具,计算机视觉领域当然少不了MATLAB的踪影。MATLAB的视觉工具包也沿袭了上手简单、可视化方便的风格,成为许多计算机视觉研究者和工程师的选择。
SimpleCV
SimpleCV,一个基于Python的视觉库,提供非常简单易用的接口,底层实现是基于OpenCV、PIL等其他的计算机视觉和图像处理库。
CCV
CCV,一个基于C语言实现的带缓存的计算机视觉库,非常简洁。
VLFeat
VLFeat,老牌的计算机视觉库,基于C语言实现,并提供MATLAB的接口方便使用。
VXL
VXL,一个基于C++语言实现的计算机视觉库。
基于深度学习的计算机视觉
深度学习成了现金大部分计算机视觉领域的标配,计算机视觉上的成功又进一步促进了深度学习。
从ImageNet竞赛到AlphaGo战胜李世石——计算机视觉超越人类
上面讲视觉发展历史的时候有介绍过ImageNet图像分类竞赛和AlexNet的一骑绝尘。这一节再来看看那几年发生了什么。
2013年,马修·塞勒(Matthew Zeiler)以初创公司Clarifi创始人,以及纽约大学计算机系的博士生的两个身份参加了ImageNet比赛,并分别取得了第一名和第三名,这一年他把ImageNet的前5类错误率降低到了11.7%。从这一年开始几乎所有的参赛者都开始使用卷积神经网络,少数没有使用深度神经网络的参赛者都处于垫底位置。
2014年,Google开始在ImageNet发力。当年在Google担任软件工程师的克里斯蒂安·赛格蒂(Christian Szegedy)提出了一种Inception的结构,并基于这种结构搭建了一个22层的卷积神经网络GoogLeNet,达到了6.66%错误率的成绩。和2013年相比,这一年基于卷积神经网络的成绩普遍提升,前5名都达到了小于10%的成绩。另外值得一提的是,GoogLeNet从网络、形态上讲,已经脱离了AlexNet和LeNet的卷积叠加+全连接的框架。这一年,所有的参赛者都使用了深度神经网络。
2015年,在建立更深网络的大趋势下,微软亚洲研究院(MicroSoft Research Asia, MSRA)的何恺明提出了深度残差网络(Deep Residual Networks),把网络层数做到了152层,并在ImageNet的分类比赛中取得了3.57%的错误率。在当年,这个成绩的意义除了第一名,更重要的是超过了接受过训练的人在ImageNet数据集上对图片进行分类的成绩(5.1%)。虽然这个结果并不能说明深度学习算法已经真的超过了人类,但是在深度学习接入ImageNet的分类竞赛前,算法只能做到28%的错误率,而在引入深度学习后,三年内就填补了最先进算法到人类水平的23%左右的空白,深度学习已经充分展现了威力。
2016年,前5名分类的错误率被进一步降低到了2.99%。冠军是我国公安部三所的搜神(Trimps-Soushen)代表队。2016年的ImageNet竞赛基本上是中国公司代表队的全面开花。在各个不同类别比赛的最终排行榜上都能看到中国公司和机构的名字,出现最多的是海康威视、公安部三所搜神和汤晓鸥老师的商汤科技。这是个可喜可贺的情况,说明中国在深度学习的应用上已经走在了世界的前列。不过从另一方面讲,2016年很多国外传统强队根本没有参赛,并且也没有什么特别亮眼的新方法被提出,这届竞赛有些更像是模型组合及调参大赛,也不是一件特别鼓舞人心的事情。
每一门学科技术的发展都是螺旋式上升,深度学习被大炒几年后是否也会像股票和三线城市的房价一样回调停滞?总之,作为一门威力强大但是却没有被透彻研究的技术,深度学习还有很多可以探索的领域,其发展也许还任重道远。
深度学习在图片分类上的成功是被关注讨论最多的,事实上在其他领域深度学习算法在指标上也在渐渐赶超人类。如人脸识别领域的一个公认数据集LFW(Labeled Faces in the Wild)上,人类识别的准确率是97.53%,而如今基于深度学习的人脸识别已经可以达到99.5%的水平。
2016年初万众瞩目的围棋人机大战中,AlphaGo突破了人类智慧的最后堡垒。虽然AlphaGo不算是计算机视觉的应用,但是深度卷积神经网络却在其中扮演了重要角色。棋盘的特征是以19*19的图像形式表示的,通道数是人为规定的颜色、轮次等其他特征,然后放到基于深度卷积神经网络的估值和策略网络中进行训练。
事实上在许多特定任务上,基于深度学习的算法超越人类水平都不是什么新鲜事,未来还会看到更多的例子。
GPU和并行技术——深度学习和计算视觉发展的加速器
前面提到过,深度学习的概念早就有了,早期制约其发展的因素是方方面面的,其中一个很重要的方面就是计算能力的限制。相对其他许多传统的机器学习方法,深度神经网络本身就是一个消耗计算量的大户。另一方面,由于多层神经网络本身极强的表达能力,对数据量也提出了很高的要求。一个普遍被接受的观点是,深度学习在数据量较少时,和传统算法差别不大,甚至有时候传统算法更胜一筹。而当数据量持续增加的情况下,传统的算法往往会出现性能上的“饱和”,而深度学习则会随着数据的增加持续提高性能。所以大数据和深度神经网络的碰撞才擦出了今天深度学习的火花,而大数据之大更加大了对计算能力的需求。在GPU被广泛应用到深度学习训练之前,计算能力的低下限制了对算法的探索和实验,以及在海量数据上进行训练的可行性。
从20世纪80年代开始,人们就开始使用专门的计算单元负责对三维模型形成的图像进行渲染。不过直到1999年NVIDIA发布GeForce256时,才正式提出了GPU的概念。早期的GPU中,显卡的作用主要是渲染,但因为天然就很强的并行处理能力和少逻辑重计算的属性,从2000年开始就有不少科研人员开始尝试用GPU来加速通用高密度、大吞吐量的计算任务。2001年,通用图形处理器(General-Purpose computing on GPU, GPGPU)的概念被正式提出。2002年,多伦多大学的James Fung发布了OpenVIDIA,利用GPU实现了一些计算机视觉库的加速,这是第一次正式将GPU用到了渲染以外的用途上。到了2006年,NVIDIA推出了利用GPU进行通用计算的平台CUDA,让开发者不用再和着色器/OpenGL打交道,而更专注于计算逻辑的实现。这时,GPU无论是在宽带还是浮点运算能力上都已经接近同时期GPU能力的10倍,而CUDA的推出一下降低了GPGPU编程的门槛,于是CUDA很快就流行开并成为了GPU通用计算的主流框架。后来深度学习诞生了,鉴于科研界对GPU计算的一贯偏爱,自然开始有人利用GPU进行深度网络的训练。之后的事情前面也讲到了,GPU助Alex一战成名,同时也成为了训练深度神经网络的标配。
除了NVIDIA,ATI(后被AMD收购)也是另一大GPU厂商。事实上ATI在GPU通用计算领域的探索比NVIDIA还早,但也许是因为投入程度不够,或是其他原因,被NVIDIA占尽先机,尤其是后来在深度学习领域。
说完了GPU领域的风云变幻,接下来看一些实际的问题:如何选购一块做深度学习的GPU?一提到用于深度学习的GPU,很多人立刻会想到NVIDIA的Tesla系列。实际上根据使用场景和预算的不同,选择是可以多样化的。NVIDIA主要有3个系列的显卡:GeForce、Quadro和Tesla。GeForce面向游戏,Quadro面向3D设计、专业图像和CAD等,而Tesla则是面向科学计算。所以这里主要讨论一下GeForce和Tesla的区别。
GeForce系列显卡面向游戏,所以性能要求是最高的,而精度上的限制就低很多,另外稳定性比Tesla也差很多。毕竟玩游戏的时候如果程序崩了也就丢个存档,但服务器如果崩了没准能“挂掉”一个公司。当然从实际角度看最大的两个优点是:即可以进行深度学习又可以玩游戏;便宜。
Tesla从诞生之初就是瞄准高精度科学运算。所以Tesla严格意义上来说不是块显卡,而是计算加速卡。对于不带视频输出的Tesla卡而言,玩游戏是指望不上的。由于Tesla开始面向的主要是高性能计算,尤其是科学计算,在许多科学计算领域,如大气等物理过程的模拟中对精度的要求非常高,所以Tesla的设计上双精度浮点数的能力比起GeForce系列强很多。如GTX Titan和K40两块卡,GTX Titan的单精度浮点数运算能力是K40的1.5倍,但是双精度浮点数运算能力却只有K40的不到15%。不过从深度学习的角度来看,双精度显得不是那么必要,如经典的AlexNet就是两块GTX 580训练出来的。所以,2016年开始,NVIDIA也在Tesla系列里推出了M系列加速卡,专门针对深度学习进行了优化,并且牺牲双精度运算能力而大幅提升了单精度运算的性能。前面也提到了,除了精度,Tesla主要面向工作站和服务器,所以稳定性特别好,同时也会有很多针对服务器的优化,如高端的Tesla卡上的GPUDirect技术可以支持远程直接内存访问(Remote Direct Memory Access,RDMA)用来提升节点间数据交互的效率。当然,Tesla系列有一个最大的特点就是贵。
综上所述,如果是在大规模集群上进行深度学习研发和部署,Tesla系列是首选,尤其是M和P子系列是不二之选。单机上开发的话,“土豪”或者追求稳定性高的人就选择Tesla。而最有性价比且能兼顾日常使用的选择则是GeForce。
基于卷积神经网络的计算机视觉应用
和计算机关联最紧密的深度学习技术是卷积神经网络。本节来列举一些卷积神经网络发挥重要作用的计算机视觉的方向。
图像分类
顾名思义,图像分类就是对于输入的已知图像,由算法提取特征并最终分到已知的一个类别里,或者说判断图像中是否包含一个已知类别中的物体。前面也讲过ILSVRC(ImageNet Large Scale Visual Recognition Challenge)从2010年到2016年的风云变幻,而图像分类是深度学习在计算机视觉领域大放异彩的第一个方向。不管是最开始的MNIST(MNIST数据集是美国国家标准与技术研究所(National Institute of Standards and Technology,简称NIST)制作的一个非常简单的数据集,内容是一些手写的阿拉伯数字),还是后来的ImageNet,基于深度学习的图像分类在特定任务上早就超过了人的平均水平。
物体检测
物体检测和图像分类差不多,也是计算机视觉里最基础的研究方向。它和图像分类的侧重点不同,物体检测要稍微复杂一些,关心的是什么东西出现在了什么地方,是一种更强的信息。在物体检测领域以基于Region Proposal的R-CNN及后续的衍生算法,以及基于直接回归的YOLO/SSD一系列的算法为代表。这两类算法都是基于卷积神经网络,借助的不仅仅是深度网络强大的图像特征提取和分类能力,也会用到神经网络的逼近能力。
人脸识别
人脸识别是计算机视觉里非常悠久的一个方向,也是和人相关的研究最多的一个计算机视觉子领域。和我们生活中最相关的应用一般有两个方面:第一个是检测图像中是否存在人脸,这个应用和物体检测很像。主要应用有数码相机中对人脸的检测,网络或手机相册中对人脸的提取等;第二个是人脸匹配,有了第一个方面或是其他手段把人脸部分找到后,人脸的匹配才是一个更主流的应用。主要的思想是把要对比的两个人脸之间的相似度计算出来。计算这种度量,传统的方法叫做度量学习(metric learning)。其基本思想是通过变换,让变换后的空间中定义为相似的样本距离更近,不相似的样本距离更远。基于深度学习也有相应的方法,比较有代表性的是Siamese网络和Triplet网络,当然广义上来说都可以算是度量学习。有了这种度量,可以进一步判断是否是一个人。作者就是身份辨识,广泛用于罪犯身份确认、银行卡开卡等场景中。2015年马云在度过的汉诺威信息技术博览会上“刷脸”的大新闻,背后就是这种技术。此外还可以利用相似度实现一些好玩的应用,如用自拍照找相似的明星脸等。
人脸领域最流行的测试基准数据是LFW(Labeled Faces in the Wild),顾名思义就是从实拍照片中标注的人脸。该图片库由美国麻省理工大学开发,约13000多张图片,其中有1680人的脸出现了两次或两次以上。在这个数据上,人类判断两张脸是否是同一人能达到的准确率为99.2%。而在深度学习大行其道之后,自2014年起这个记录已经被各种基于深度学习的方法打破。虽然这未必真的代表深度学习胜过了人类,但基于深度学习的人脸算法让相关应用的可用性大大提高。如今人脸识别相关的商业应用已经遍地开花。
图像搜索
狭义来说图像搜索还有个比较学术的名字是内容的图片检索(Content Based Image Retrival, CBIR)。图像搜索是个比较复杂的领域,除了单纯的图像算法,还带有搜索和海量数据处理的属性。其中图像部分背后的重要思想之一和人脸识别中提到的度量学习很像,也是要找到和被搜图像的某种度量最近的图片。最常见的应用如Google的Reverse Image Search和百度的识图功能,京东和淘宝的拍照购物及相似款推荐等。深度学习在其中的作用主要是把图像转换为一种更适合搜索目的的表达,并且考虑到图像搜索应用场景和海量数据,这个表达常常会哈希/二值化处理,以达到更高的检索/排序效率。
图像分割
图像分割是个比较传统的视觉应用,指的是以像素为单位将图像划分为不同部分,这些部分代表着不同的感兴趣区域。
传统的图像分割算法五花八门,如基于梯度和动态规划路径的Intelligent Scissors(Photoshop中的磁力套索);利用高一维空间的超曲面解决当前空间轮廓的水平集(Level Set)方法:直接聚类的K-means;后期很流行的基于能量最小化的GraphCut/GrabCut和随机场的CRF(Conditional Random Field)等。
后来深度学习出现了。和传统方法相比,深度学习未必能做到很精细的像素级分割。但是因为深度学习能学到大量样本中的图像语义信息的天然优势,这更贴近人对图像的理解,所以分割的结果可用性通常也更好一些。常见的基于深度学习的图像分割手段是全卷积神经网络(Fully Convolutional Networks,FCN)。Facebook的人工智能实验室FAIR(Facebook Artificial Intelligence Research)于2016年发布了一套用于分割+物体检测的框架。其构成是一个大体分割出物体区域的网络DeepMask,加上利用浅层图像信息精细图像分割的SharpMask,最后是一个MultiPathNet模块进行物体检测。其实在这背后也体现出学界和业界开始慢慢流行起的另一个很底层的思想:就是图像分割和物体检测背后其实是一回事,不应该分开来研究。对照物体检测和图像分类的关系,图像分割传达的是比物体检测更进一步、更强的信息。
视频识别
因为和图像的紧密联系,视频当然少不了深度学习的方法。深度学习在图像分类任务上大行其道之后,视频识别的研究立刻就跟进了上来,比较有代表性的工作从2014年起相继出现。
2014年的CVPR上,斯坦福大学的李飞飞组发表了一篇视频识别的论文。其基本思路是用视频中的多帧作为输入,再通过不同的顺序和方式将多帧信息进行融合。其方法并没有什么特别出彩的地方,但随着论文发布了Sport-1M数据集,包含了Youtube上487类共计113万的体育视频,是目前最大的视频分类数据集。
2014年的NIPS上,牛津大学传统视觉强组VGG(Visual Geometry Group)发表了一篇更经典的视频识别的文章,将图像的空间信息,也就是画面信息,用一个称为Spatial Stream ConvNet的网络处理,而视频中帧间的时序信息用另一个称为Temporal Stream ConNet的网络处理,最后融合称为Two Streams,直译就是二流法。这个方法后来被改来改去,发展出了更深网络的双流法,以及更炫融合方式的双流法,甚至是除了双流还加入音频流的三流法。不过影响最大的改进还是马里兰大学和Google的一篇论文,其对时序信息进行了处理和改进,加入了LSTM,以及改进版二流合并的方法,成为了主流框架之一。
因为视频有时间的维度,所以还有一个很自然的想法是用三维卷积去处理视频帧,这样自然能将时序信息包括进来,这也是一个流行的思路。
更近的一些研究中,最新的深度学习概率框架生成式对抗网络(Generative Adversarial Networks,GAN)也被用到了视频处理当中。2016年,Comma AI的实习生Eder Santana和被称为天才黑客的George Hotz将GAN用于对视频输入进行降维,然后用低维表达和LSTM进行处理,从而对视频的未来帧进行预测,可以比较准确地预测沿直线前进时未来的画面。
视频作为比图像更高一维度的数据,并且还带有时序信息和声音等信息,可探索的空间更大,相信未来会有更多精彩有趣的深度学习相关应用出现。
纹理/图像合成
这是一个2016年左右才开始进入大众视野的领域,是因为一个叫Prisma的APP。纹理合成其实也是计算机视觉的一个传统应用,主要实现的是根据一种图案,进行相似的复制和排列生成纹理。在2014年前后,这个领域开始被深度学习大幅攻占。到了2015年,纹理合成上的进展自然而然地拓展到了图片风格学习上。其中最有影响力的是德国的Leon Gatys发表的《A Neural Algorithm of Artistic Style》,其中提出的办法可以学习特定图片的纹理风格并基于其他图片的内容生成风格化的图片。
其他应用
除了上面提到的这些应用,传统图像和视觉领域里很多方向现在都有了基于深度学习的解决方案,包括图像降噪、图像去模糊、图像复原、超分辨率、图像内容描述、图像深度(立体)信息提取等,在此就不一一详述了。
文章出处登录后可见!