loguru简介
loguru是一个开源的Python日志记录器,它提供了简单且易于使用的接口,同时具有高度的可定制性。loguru的特点包括:支持格式化日志、记录到文件或终端、支持自动清理日志、支持旋转日志等。
基本使用方法
loguru的基本使用方法非常简单,只需要导入loguru模块,并使用logger函数创建一个日志记录器对象即可。下面是一个简单的示例:
from loguru import logger
# 使用默认配置创建一个日志记录器对象
logger = logger.opt()
logger.info('hello, world!')
在上面的示例中,我们使用logger.opt()函数创建了一个默认配置的日志记录器对象,并使用logger.info()方法输出了一条日志信息。
在下面的示例中,我们使用logger.opt()方法创建了一个默认配置的日志记录器对象,然后使用logger.add()方法添加了一个输出到文件的处理器。接着,我们使用logger.opt()方法创建了一个具有自定义配置的新的日志记录器对象,并使用mylogger.debug()和mylogger.info()方法输出了日志信息。由于我们在创建mylogger对象时设置了日志级别为DEBUG,因此mylogger.debug()方法和mylogger.info()方法都会输出日志信息。
from loguru import logger
# 创建一个默认配置的日志记录器对象
logger = logger.opt()
# 创建一个输出到文件的处理器
logger.add("mylog.log", rotation="10 MB")
# 使用自定义配置创建一个新的日志记录器对象
mylogger = logger.opt(
colors=True,
format="<green>{time}</green> <level>{message}</level>",
level="DEBUG"
)
# 输出日志信息
mylogger.debug("this is a debug log")
mylogger.info("this is an info log")
除了使用默认配置创建日志记录器对象外,我们还可以通过调用logger.add()函数来添加多个不同的日志输出。例如,我们可以同时将日志信息输出到终端和文件中,如下所示:
from loguru import logger
# 添加输出到终端的处理器
logger.add(
handler=sys.stdout,
format="<green>{time}</green> <level>{message}</level>",
enqueue=True
)
# 添加输出到文件的处理器
logger.add(
handler="log.txt",
format="{time} {level} {message}",
enqueue=True,
rotation="1 week",
retention="7 days",
compression="zip"
)
# 使用默认配置创建一个日志记录器对象
logger = logger.opt()
logger.info('hello, world!')
在上面的示例中,我们使用logger.add()函数分别添加了一个输出到终端的处理器和一个输出到文件的处理器。其中,handler参数指定了处理器的输出目标,可以是一个文件名、一个文件对象或者一个类似sys.stdout的特殊值。format参数指定了日志信息的格式,可以使用类似{time}和{message}的占位符来格式化输出。enqueue参数指定了处理器是否使用队列进行异步处理。rotation参数指定了日志文件的旋转方式,可以按时间、大小等条件进行旋转。retention参数指定了旋转后的日志文件保留的时间。compression参数指定了旋转后的日志文件是否压缩。
进阶使用方法
除了基本使用方法外,loguru还提供了一些进阶的使用方法,如自定义日志级别、日志过滤、异常处理等。
自定义日志级别
loguru允许我们自定义日志级别,可以通过logger.level()函数来添加自定义日志级别。例如,我们可以添加一个名为TRACE的日志级别,并将其显示
from loguru import logger
# 添加自定义日志级别
logger.level("TRACE", no=5, color="<blue>", icon="🐞")
# 使用自定义日志级别
logger.trace("this is a trace log")
在上面的示例中,我们使用logger.level()函数添加了一个名为TRACE的日志级别,并将其显示为蓝色并带有一个小虫子图标。然后,我们使用logger.trace()方法输出了一条自定义级别的日志信息。
日志过滤
loguru还支持日志过滤功能,可以通过logger.add()函数的filter参数来添加过滤器。例如,我们可以添加一个过滤器来只输出级别为INFO或更高级别的日志信息,如下所示:
from loguru import logger
# 添加输出到终端的处理器,并添加日志过滤器
logger.add(
handler=sys.stdout,
format="<green>{time}</green> <level>{message}</level>",
enqueue=True,
filter=lambda record: record["level"].no >= 20
)
# 使用默认配置创建一个日志记录器对象
logger = logger.opt()
logger.info('hello, world!')
logger.debug('this is a debug log')
在上面的示例中,我们使用logger.add()函数添加了一个输出到终端的处理器,并添加了一个日志过滤器。过滤器是一个函数,它接受一个日志记录对象作为输入,如果该函数返回True,则表示该日志记录对象会被处理器处理,否则会被忽略。
在本示例中,我们使用lambda表达式定义了一个简单的过滤器,它只处理级别为INFO或更高级别的日志信息。
异常处理
loguru还支持捕获和记录异常信息,可以通过logger.catch()方法来捕获异常并记录异常信息。例如,我们可以在一个函数中添加logger.catch()来自动记录异常信息,如下所示:
from loguru import logger
# 定义一个会抛出异常的函数
def foo():
a = 1 / 0
# 使用logger.catch()自动记录异常信息
@logger.catch()
def bar():
foo()
# 调用bar()函数
bar()
在上面的示例中,我们定义了一个会抛出异常的函数foo(),然后在bar()函数中使用logger.catch()方法来自动记录异常信息。最后,我们调用bar()函数,捕获并记录了异常信息。
绑定参数
logger.bind()方法用于绑定参数到日志记录器中,这些参数可以在日志信息中引用。例如,我们可以使用logger.bind()方法绑定一个user_id参数,并在日志信息中引用该参数,示例如下:
from loguru import logger
# 绑定一个user_id参数
logger = logger.bind(user_id=12345)
# 输出带有user_id参数的日志信息
logger.info("user {user_id} logged in")
在上面的示例中,我们使用logger.bind()方法绑定了一个user_id参数,并使用logger.info()方法输出了一条带有user_id参数的日志信息。
输出日志到指定目标
logger.sink()方法用于将日志记录器的输出发送到指定的目标,例如文件、网络等。例如,我们可以使用logger.sink()方法将日志记录器的输出发送到一个网络套接字中,示例如下
from loguru import logger
# 创建一个网络套接字
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(('localhost', 9000))
# 将日志记录器的输出发送到网络套接字中
logger.add(sock.sendall)
# 输出日志信息
logger.info("hello world")
在上面的示例中,我们创建了一个网络套接字,并使用logger.add()方法将日志记录器的输出发送到该套接字中。接着,我们使用logger.info()方法输出了一条日志信息,该信息将被发送到网络套接字中。
记录模型训练时当前的设备配置
效果图:
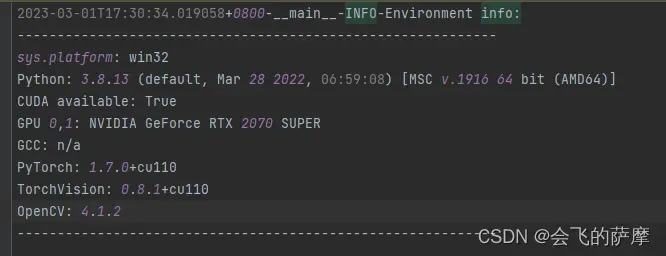
参考mmdet的
# Copyright (c) OpenMMLab. All rights reserved.
"""This file holding some environment constant for sharing by other files."""
import os.path as osp
import subprocess
import sys
from collections import defaultdict
import pynvml
import cv2
import torch
def collect_env():
"""Collect the information of the running environments.
Returns:
dict: The environment information. The following fields are contained.
- sys.platform: The variable of ``sys.platform``.
- Python: Python version.
- CUDA available: Bool, indicating if CUDA is available.
- GPU devices: Device type of each GPU.
- CUDA_HOME (optional): The env var ``CUDA_HOME``.
- NVCC (optional): NVCC version.
- GCC: GCC version, "n/a" if GCC is not installed.
- MSVC: Microsoft Virtual C++ Compiler version, Windows only.
- PyTorch: PyTorch version.
- PyTorch compiling details: The output of \
``torch.__config__.show()``.
- TorchVision (optional): TorchVision version.
- OpenCV: OpenCV version.
"""
env_info = {}
env_info['sys.platform'] = sys.platform
env_info['Python'] = sys.version.replace('\n', '')
cuda_available = torch.cuda.is_available()
env_info['CUDA available'] = cuda_available
if cuda_available:
devices = defaultdict(list)
for k in range(torch.cuda.device_count()):
devices[torch.cuda.get_device_name(k)].append(str(k))
for name, device_ids in devices.items():
env_info['GPU ' + ','.join(device_ids)] = name
try:
# Check C++ Compiler.
# For Unix-like, sysconfig has 'CC' variable like 'gcc -pthread ...',
# indicating the compiler used, we use this to get the compiler name
import sysconfig
cc = sysconfig.get_config_var('CC')
if cc:
cc = osp.basename(cc.split()[0])
cc_info = subprocess.check_output(f'{cc} --version', shell=True)
env_info['GCC'] = cc_info.decode('utf-8').partition(
'\n')[0].strip()
else:
# on Windows, cl.exe is not in PATH. We need to find the path.
# distutils.ccompiler.new_compiler() returns a msvccompiler
# object and after initialization, path to cl.exe is found.
import os
from distutils.ccompiler import new_compiler
ccompiler = new_compiler()
ccompiler.initialize()
cc = subprocess.check_output(
f'{ccompiler.cc}', stderr=subprocess.STDOUT, shell=True)
encoding = os.device_encoding(sys.stdout.fileno()) or 'utf-8'
env_info['GCC'] = 'n/a'
except subprocess.CalledProcessError:
env_info['GCC'] = 'n/a'
env_info['PyTorch'] = torch.__version__
try:
import torchvision
env_info['TorchVision'] = torchvision.__version__
except ModuleNotFoundError:
pass
env_info['OpenCV'] = cv2.__version__
return env_info
def is_mlu_available():
"""Returns a bool indicating if MLU is currently available."""
return hasattr(torch, 'is_mlu_available') and torch.is_mlu_available()
def get_device(gpu_id=None):
"""Returns an available device, cpu, cuda or mlu."""
is_device_available = {
'cuda': torch.cuda.is_available(),
'mlu': is_mlu_available()
}
device_list = [k for k, v in is_device_available.items() if v]
if len(device_list) == 1:
return device_list[0] if gpu_id is None else '{}:{}'.format(device_list[0], gpu_id)
else:
return 'cpu'
def get_gpu_memory_info(gpu_id):
pynvml.nvmlInit()
handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
total = meminfo.total // 1024 // 1024 # 单位:MB
used = meminfo.used // 1024 // 1024
free = meminfo.free // 1024 // 1024
return total, used, free
if __name__ == '__main__':
env_info_dict = collect_env()
env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()])
dash_line = '-' * 60 + '\n'
fh_path = os.path.join('work_dir', mode + '_{time}' + ".log")
logger.add(
sink=fh_path,
format="{time}-{name}-{level}-{message}", level="INFO"
)
logger.info(f'Environment info:\n{dash_line}{env_info}\n{dash_line}')
文章出处登录后可见!