相信很多小伙伴最开始都是从分类任务入手深度学习这个领域的吧,这个就类似学习代码的第一课,“Hello world”一样。深度学习中,除了模型设计之外,最重要的想必就是选取合适的损失函数了。不过一般实验中,损失函数的调用十分简单,也就是一行代码的事情,但是最近发现,好多小伙伴,对于损失函数的基础意义及实现细节,还是不甚了解,所以在此对分类任务中常用的交叉熵损失函数进行详细的介绍。
1. 事件发生的概率与信息量和信息熵
损失函数的目标就是想通过计算网络输出与实际标签之间的差异,然后通过反向传播更新网络的权重,使得输出越来越接近实际标签值。对于分类任务来说,网络输出的结果就是预测每一个类别的概率值,接着就是如何设计损失函数,使得标签为正的类别的概率值越高。对于优化问题,我们需要设计目标函数存在一个下界,在优化过程当中,如果优化算法能够使目标函数不断减小,根据单调有界准则,这个优化算法就能证明是收敛有效的。这时候信息量的概念就引进来了,信息量的基本想法是:一个不太可能发生的事件居然发生了,我们收到的信息要多于一个非常可能发生的事件发生。从这句话中,我们可以看出,事件包含的信息量应与其发生的概率负相关。所以现在目标就是如何最小化我们的信息量,使得对应的概率也就可以变得越大。


2. 相对熵(KL散度)

3. 交叉熵

关于信息量,与信息熵,相对熵以及交叉熵的具体解释和定义,可以参考这篇博文交叉熵损失函数(Cross Entropy Loss),讲解的十分详细。
4. 交叉熵损失函数
刚刚说到,交叉熵是信息论中的一个概念,它与事件的概率分布密切相关,这也就是为什么神经网络在使用交叉熵损失函数时会先使用函数或者
函数将网络的输出转换为概率值。
4.1 多分类
每个样本只能有一个标签,比如ImageNet图像分类任务,或者MNIST手写数字识别数据集,每张图片只能有一个固定的标签。
对单个样本,假设真实分布为,网络输出分布为
,总的类别数为
,则在这种情况下,交叉熵损失函数的计算方法如下所示,我们可以看出,实际上也就是计算了标签类别为1的交叉熵的值,使得对应的信息量越来越小,相应的概率也就越来越大了。

具体的Pytorch实现,如下所示,该函数,同时包含了softmax计算概率,以及后续计算交叉熵的两个步骤:
loss = nn.CrossEntropyLoss()4.2 多标签分类
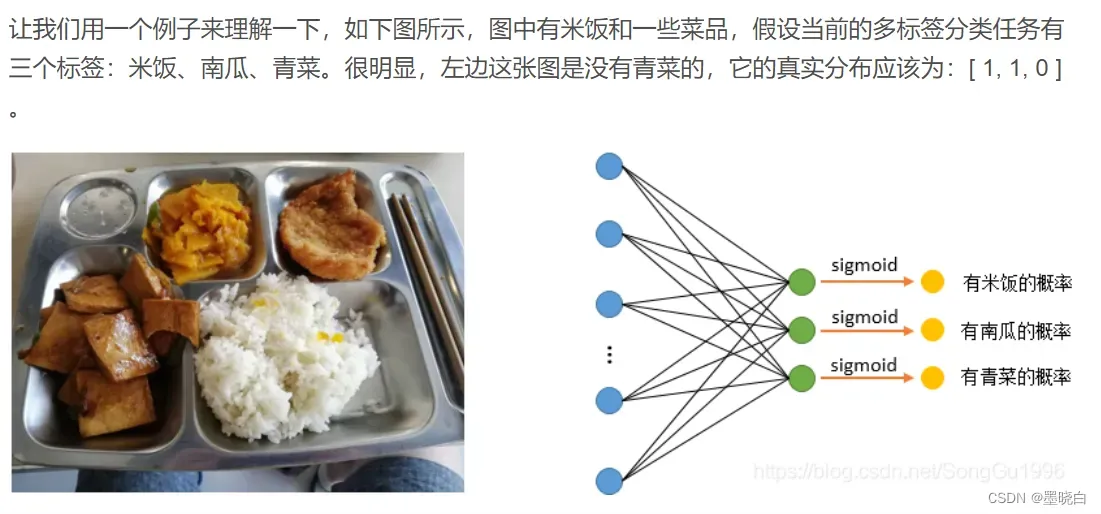
多标签分类任务,即一个样本可以有多个标签,比如一张图片中同时含有“猫”和“狗”,这张图片就同时拥有属于“猫”和“狗”的两种标签。在这种情况下,我们将函数作为网络最后一层的输出,得出每个类别预测为1的概率。以图像识别任务为例,网络最后一层的输出应该理解为:网络认为图片中含有这一类别物体的概率。而每一类的真实标签都只有两种可能值,即“图片中含有这一类物体”和“图片中不含有这一类物体”,这是一个二项分布。综上所述,对多标签类任务中的每一类单独分析的话,真实分布是一个二项分布,可能的取值为0或者1,而网络预测的分布可以理解为标签是1的概率。此外,由于多标签分类任务中,每一类是相互独立的,所以网络最后一层神经元输出的概率值之和并不等于1。对多标签分类任务中的一类任务来看,交叉熵损失函数为:

具体的Pytorch实现,如下所示,该函数,同时包含了sigmoid计算概率,以及后续计算交叉熵的两个步骤:
loss = nn.BCELoss()4.3 二分类
对于二分类,既可以选择多分类的方式,也可以选择多标签分类的方式进行计算,结果差别也不会太大。
文章出处登录后可见!