参考PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】P25~33
现有网络模型的使用及修改
官方文档
以VGG16为例

pretrained = True时是已经在ImageNet数据集上训练好的,需要先安装scipy库才能使用ImageNet数据集
ImageNet数据集
train_data = torchvision.datasets.ImageNet("./data_image_net", split='train', download=True,
import torchvision
from torch import nn
# false意思是不下载已经在ImageNet里面训练好的模型,
# 即conv、pooling layers里面的那些参数,而true就要下载他们
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
'''
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
'''
两者对比
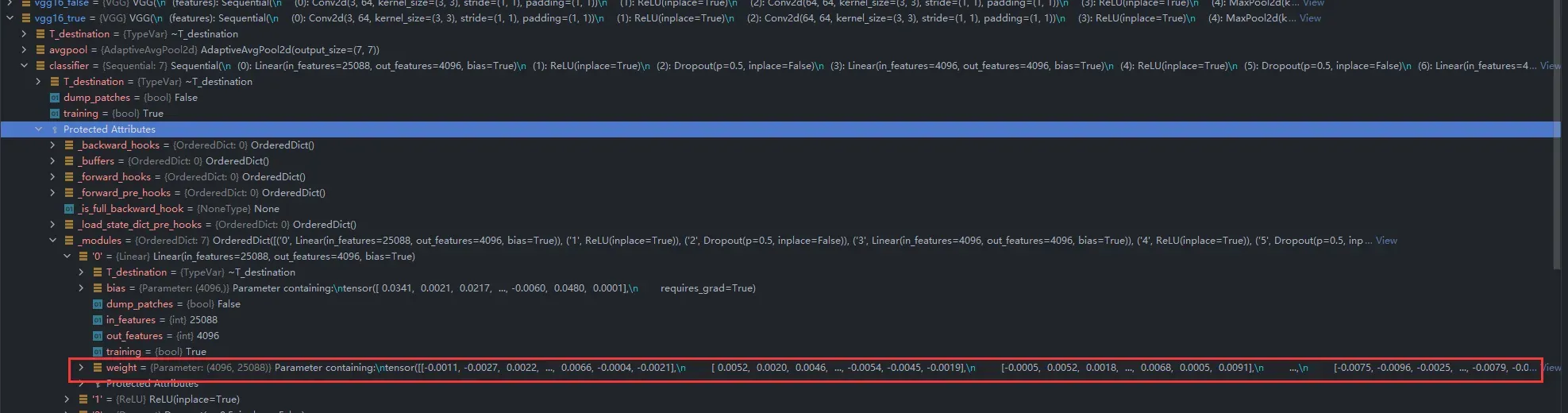
VGG16训练时,用的是ImageNet数据集,它把数据分为个类,而
CIFAR把数据分为类,那么就有两种做法,来利用
VGG16来处理 CIFAR数据集:
VGG16后面利用add_module()添加一个新的线性层,使映射到
;
- 直接把
VGG16最后的输出层改为
import torchvision
from torch import nn
# false意思是不下载已经在ImageNet里面训练好的模型,
# 即conv、pooling layers里面的那些参数,而true就要下载他们
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
# vgg16_true.add_module('add_linear',nn.Linear(1000, 10))
# 要想用于 CIFAR10 数据集, 可以在网络下面多加一行,转成10分类的输出,这样输出的结果,跟下面的不一样,位置不一样
print(vgg16_true)
'''
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
'''
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
# 层级不同
# 如何利用现有的网络,改变结构
print(vgg16_true)
'''
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
'''
# 上面是添加层,下面是如何修改VGG里面的层内容
print(vgg16_false)
'''
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
'''
vgg16_false.classifier[6] = nn.Linear(4096, 10) # 中括号里的内容,是网络输出结果自带的索引,套进这种格式,就可以直接修改那一层的内容
print(vgg16_false)
'''
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
'''
网络模型的保存与读取
保存
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数 模型 + 参数 都保存
torch.save(vgg16, "vgg16_method1.pth") # 引号里是保存路径
# 保存方式2,模型参数(官方推荐) ,因为这个方式,储存量小,在terminal中,ls -all可以查看
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
读取
当使用第一种方式进行保存的时候,如果是官方自带的数据集则可以直接使用
import torch
import torchvision
from P26_1_model_save import *
model = torch.load("vgg16_method1.pth")
print(model)
第一种读取
当使用的是如果是自己的模型,就需要在加载中,把class重新写一遍,但并不需要实例化。一种简便的写法是,在另一个文件中创建模型,然后通过import导入这个读取的这个文件中
重写模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
直接导入
from P26_1_model_save import *
第二种读取
vgg16 = torchvision.models.vgg16(pretrained=False) # 创建原始模型
vgg16.load_state_dict(torch.load("vgg16_method2.pth")) # 读取参数
# model = torch.load("vgg16_method2.pth")
print(vgg16)
完整的模型套路
创建模型
model.py
import torch
from torch import nn
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 通常在本地测试输出
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
# torch.Size([64, 10])
二分类问题计算正确率

import torch
outputs = torch.tensor([[0.1, 0.2],
[0.3, .4]])
print(outputs.argmax(1)) # 参数为0表示每一列的最大值下标,参数为1表示每一行的最大值下标
# tensor([1, 1])
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print((preds == targets).sum())
# tensor(1)
train.py
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) # 这里的参数,SGD里面的,只要定义两个参数,一个是tudui.parameters()本身,另一个是lr
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("------------第 {} 轮训练开始------------".format(i + 1))
# 训练步骤开始
tudui.train() # 这两个层,只对一部分层起作用,比如 dropout层;如果有这些特殊的层,才需要调用这个语句
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 优化器,梯度清零
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item())) # 不加item()输出为tensor类型,加item()输出为数值类型
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 每训练完一轮,进行测试,在测试集上测试,以测试集的损失或者正确率,来评估有没有训练好,测试时,就不要调优了,就是以当前的模型,进行测试,所以不用再使用梯度(with no_grad 那句)
# 测试步骤开始
tudui.eval() # 这两个层,只对一部分层起作用,比如 dropout层;如果有这些特殊的层,才需要调用这个语句
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 测试时用不到梯度,不需要对梯度进行调整和优化
for data in test_dataloader: # 在测试集中,选取数据
imgs, targets = data
outputs = tudui(imgs) # 分类的问题,是可以这样的,用一个output进行绘制
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item() # 为了查看总体数据上的 loss,创建的 total_test_loss,初始值是0
accuracy = (outputs.argmax(1) == targets).sum() # 正确率,这是分类问题中,特有的一种评价指标
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
# 在分类问题上比较特有,通常使用正确率来表示优劣。因为其他问题,可以可视化地显示在tensorbo中。
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
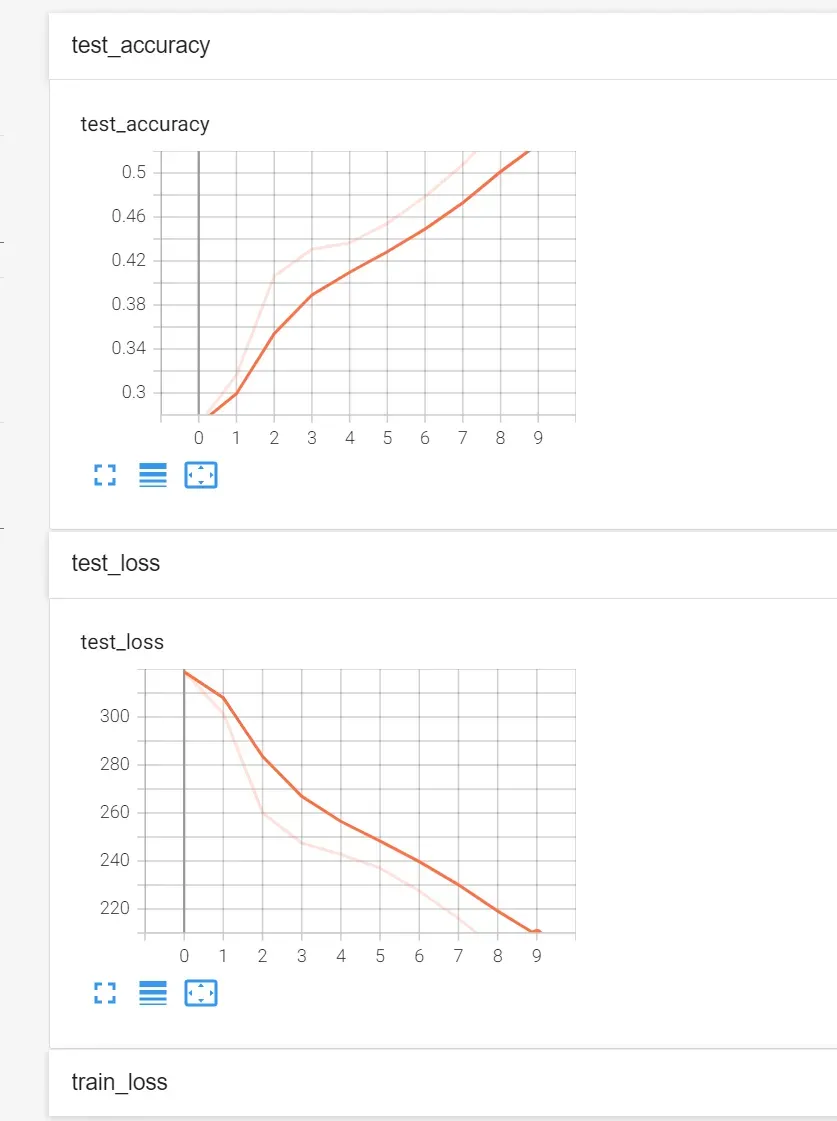
运行结果
训练数据集的长度为:50000
测试数据集的长度为:10000
------------第 1 轮训练开始------------
训练次数:100, Loss: 2.2905263900756836
训练次数:200, Loss: 2.292351484298706
训练次数:300, Loss: 2.284001350402832
训练次数:400, Loss: 2.2501742839813232
训练次数:500, Loss: 2.188832998275757
训练次数:600, Loss: 2.0124356746673584
训练次数:700, Loss: 2.0578112602233887
整体测试集上的Loss: 318.8580551147461
整体测试集上的正确率: 0.27149999141693115
模型已保存
------------第 2 轮训练开始------------
训练次数:800, Loss: 1.913382887840271
训练次数:900, Loss: 1.8749072551727295
训练次数:1000, Loss: 1.9265092611312866
训练次数:1100, Loss: 1.9669464826583862
训练次数:1200, Loss: 1.6926833391189575
训练次数:1300, Loss: 1.6518962383270264
训练次数:1400, Loss: 1.747132658958435
训练次数:1500, Loss: 1.8273415565490723
整体测试集上的Loss: 301.4771748781204
整体测试集上的正确率: 0.31610000133514404
模型已保存
------------第 3 轮训练开始------------
训练次数:1600, Loss: 1.7792370319366455
训练次数:1700, Loss: 1.6622941493988037
训练次数:1800, Loss: 1.9741404056549072
训练次数:1900, Loss: 1.6974323987960815
训练次数:2000, Loss: 1.9055237770080566
训练次数:2100, Loss: 1.5350408554077148
训练次数:2200, Loss: 1.4884883165359497
训练次数:2300, Loss: 1.803768277168274
整体测试集上的Loss: 260.12389600276947
整体测试集上的正确率: 0.40619999170303345
模型已保存
------------第 4 轮训练开始------------
训练次数:2400, Loss: 1.7479407787322998
训练次数:2500, Loss: 1.384969711303711
训练次数:2600, Loss: 1.582413673400879
训练次数:2700, Loss: 1.6613783836364746
训练次数:2800, Loss: 1.4632248878479004
训练次数:2900, Loss: 1.6056734323501587
训练次数:3000, Loss: 1.3493989706039429
训练次数:3100, Loss: 1.5223374366760254
整体测试集上的Loss: 247.42617630958557
整体测试集上的正确率: 0.43070000410079956
模型已保存
------------第 5 轮训练开始------------
训练次数:3200, Loss: 1.3581160306930542
训练次数:3300, Loss: 1.5007731914520264
训练次数:3400, Loss: 1.475603699684143
训练次数:3500, Loss: 1.5333726406097412
训练次数:3600, Loss: 1.567336916923523
训练次数:3700, Loss: 1.360451340675354
训练次数:3800, Loss: 1.2853747606277466
训练次数:3900, Loss: 1.4290802478790283
整体测试集上的Loss: 242.84022045135498
整体测试集上的正确率: 0.436599999666214
模型已保存
------------第 6 轮训练开始------------
训练次数:4000, Loss: 1.4038498401641846
训练次数:4100, Loss: 1.420902967453003
训练次数:4200, Loss: 1.5379866361618042
训练次数:4300, Loss: 1.2233322858810425
训练次数:4400, Loss: 1.1818506717681885
训练次数:4500, Loss: 1.3466275930404663
训练次数:4600, Loss: 1.408211350440979
整体测试集上的Loss: 236.99072802066803
整体测试集上的正确率: 0.45419999957084656
模型已保存
------------第 7 轮训练开始------------
训练次数:4700, Loss: 1.3199535608291626
训练次数:4800, Loss: 1.5102570056915283
训练次数:4900, Loss: 1.3993655443191528
训练次数:5000, Loss: 1.3973842859268188
训练次数:5100, Loss: 1.042458176612854
训练次数:5200, Loss: 1.2817647457122803
训练次数:5300, Loss: 1.2045180797576904
训练次数:5400, Loss: 1.4111905097961426
整体测试集上的Loss: 227.4614075422287
整体测试集上的正确率: 0.47850000858306885
模型已保存
------------第 8 轮训练开始------------
训练次数:5500, Loss: 1.215441346168518
训练次数:5600, Loss: 1.2028216123580933
训练次数:5700, Loss: 1.234225869178772
训练次数:5800, Loss: 1.2485334873199463
训练次数:5900, Loss: 1.3112620115280151
训练次数:6000, Loss: 1.5477596521377563
训练次数:6100, Loss: 0.989898145198822
训练次数:6200, Loss: 1.122158169746399
整体测试集上的Loss: 216.0968815088272
整体测试集上的正确率: 0.5077000260353088
模型已保存
------------第 9 轮训练开始------------
训练次数:6300, Loss: 1.4186499118804932
训练次数:6400, Loss: 1.1189241409301758
训练次数:6500, Loss: 1.5597584247589111
训练次数:6600, Loss: 1.1259204149246216
训练次数:6700, Loss: 1.066240668296814
训练次数:6800, Loss: 1.1731362342834473
训练次数:6900, Loss: 1.0835442543029785
训练次数:7000, Loss: 0.9253491759300232
整体测试集上的Loss: 202.96147692203522
整体测试集上的正确率: 0.5428000092506409
模型已保存
------------第 10 轮训练开始------------
训练次数:7100, Loss: 1.2742401361465454
训练次数:7200, Loss: 0.9114198088645935
训练次数:7300, Loss: 1.103304386138916
训练次数:7400, Loss: 0.8360403180122375
训练次数:7500, Loss: 1.2414509057998657
训练次数:7600, Loss: 1.2416971921920776
训练次数:7700, Loss: 0.851065993309021
训练次数:7800, Loss: 1.2335820198059082
整体测试集上的Loss: 194.33641028404236
整体测试集上的正确率: 0.564300000667572
模型已保存
train()把网络设置成训练的模式(没有也不会出错)
GPU加速
对模型、数据和损失函数可以使用GPU加速
cuda()
if xx.cuda.is_available():
xx = xx.cuda()
import time
import torch
import torchvision
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() # 这是GPU加速训练的第一部分
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 这是GPU加速训练的第二部分
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
# 添加开始时间
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 这两行是GPU加速的第三部分(未完)
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # 这两行也是必不可少的,GPU加速训练的部分
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的 Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
colaboratory网站
利用google的服务运行代码
默认是没有使用gpu加速的
to(device)
device = torch.device(“cpu”)
xx.to(device)
当有多张显卡时
device = torch.device(“cpu:0”)
保险写法
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
应用
import time
import torch
import torchvision
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 定义训练的设备
device = torch.device("cuda") # 定义训练的设备
print(device)
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
tudui.to(device) # 这里新添加了gpu加速的内容 这里,其实不用另外赋值 tudui = xxx,直接调用 tudui.to(device)就可以的
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device) # 这里添加了加速设备,其实也是不需要重新赋值的,直接调用就可以了
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 这里是数据,需要重新赋值
targets = targets.to(device) # 这里一样
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
完整的模型验证套路
利用已经训练好的模型进行测试
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png"
image = Image.open(image_path) # PIL类型的图片
print(image)
image = image.convert('RGB') # 这里在word中,有截图,是跟png的通道数有关系的
# 因为png格式是四个通道,除了RGB三通道外,还有一个透明度通道。
# 所有,我们调用image = image.convert('RGB'),保留其颜色通道
# 图像大小,只能是模型中的32,32,然后转为 totensor 数据类型
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image) # 应用 transform
print(image.shape) # 打印图像大小
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 加载训练模型
model = torch.load("tudui_0.pth", map_location=torch.device('cpu')) # 从gpu运行的模型放在cpu运行
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad(): # 这步可以节约内存,提高性能
output = model(image)
print(output)
print(output.argmax(1))
看看开源项目
--名称为属性,后面的数值就是为该属性赋值

把代码中,参数设置为require的内容,全部改成default,并设置一个默认值
文章出处登录后可见!
已经登录?立即刷新