YOLOv2
Add BN
使用BN层提高准确度(Accuracy improvements)
- 神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同, 那么网络的泛化能力也大大降低; 另外一方面,一旦每批训练数据的分布各不相同, 那么网络的 Batch 梯度下降算法就要在每次迭代都去学习适应不同的分布, 这样将会大大降低网络的训练速度。
- 解决办法是对数据都要做一个归一化预处理。YOLOv2网络通过在每一个卷积层后添加 批归一化 (batch normalization) ,极大的改善了收敛速度同时减少了对其它正则化方法的依赖(舍弃了 Dropout 优化后依然没有过拟合),使得mAP获得了2%的提升。
High Resolution Classifier [Focusing on backbone]
高分辨率分类器(High-resolution classifier )
- Train on ImageNet (224 x 224) // Model trained on small images may not be good
- Resize & Finetune on ImageNet (448 x448) // So we finetune the model on larger images
- Finetune on dataset // To let the model be used to larger images
- We get 13 x 13 feature maps finally
所有State-Of-The-Art的检测方法都在ImageNet上对分类器进行了预训练。从AlexNet开始,多数分类器都把 输入图像Resize到以下,这会容易丢失一些小目标的信息。
YOLOv1训练由两个阶段组成。 首先,训练像VGG16这样的分类器网络。 然后用卷积层替换全连接层,并端到端地重新训练以进行目标检测。 YOLOv1先使用的分辨率来训练分类网络,在训练检测网络的时候再切换到
的分辨率,这意味着YOLOv1的卷积层要重新适应新的分辨率,同时YOLOv1的网络还要学习检测网络。
直接切换分辨率,YOLOv1检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用 输入来 finetune 分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上微调之前已经适应高分辨率输入。YOLOv2 以图片开始用于分类器训练,但是然后使用10个epoch再次用
图片重新调整分类器。让网络可以调整滤波器来适应高分辨率图像,这使得检测器训练更容易。使用高分辨率的分类网络提升了将近4%的mAP。
Fine-Grained Features
更细粒度的特征(Fine-Grained Features)
- Lower features are concatenated directly to higher features
- A new layer is added for that purpose: reorg
浅层网络学到的是low-level信息,深层网络学到的是high-level信息。浅层信息包括预测框的位置信息,对目标的定位有很大的作用,决定是何种物体的是深层语义信息,所以需要将两种信息相结合。
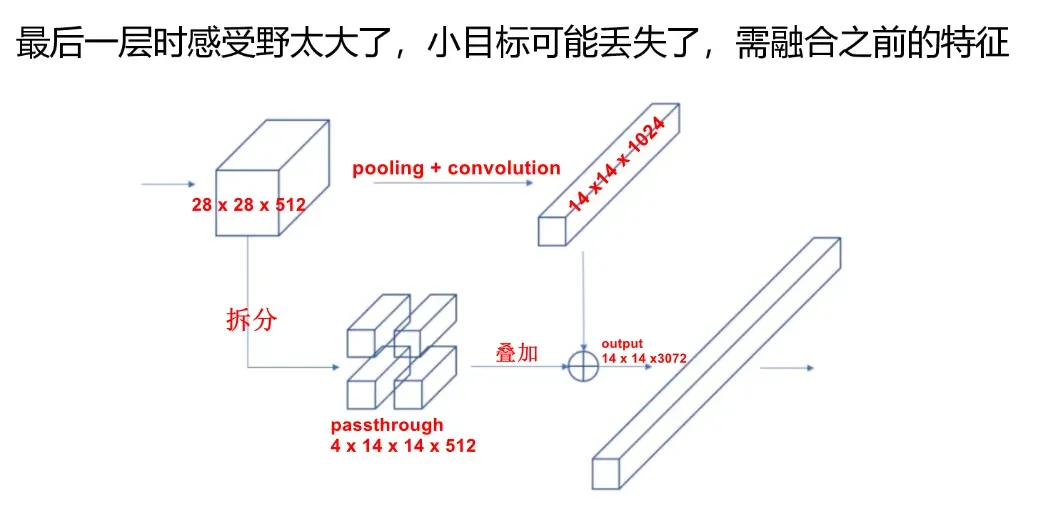
- 卷积层逐渐减小空间维度。 随着相应的分辨率降低,检测小目标变得更加困难。 其他目标检测器(如 SSD)可以从不同的特征图层中找到目标。 所以每一层都专注于不同的尺度。
- YOLO采用了一种称为 passthrough 的不同方法。 它将
层重整形为
,然后将其与原始的
输出层concat连接。 在新的
层上应用卷积滤波器来进行预测。
YOLOv2使用该方法,进行特征融合,使得模型提升了1%的提升。
Multi-Scale Training
多尺度训练
- Remove FC layers: Can accept any size of inputs, enhance model robustness.
- Size across 320, 352, …, 608. Change per 10 batch [border % 32 = 0, decided by down sampling]
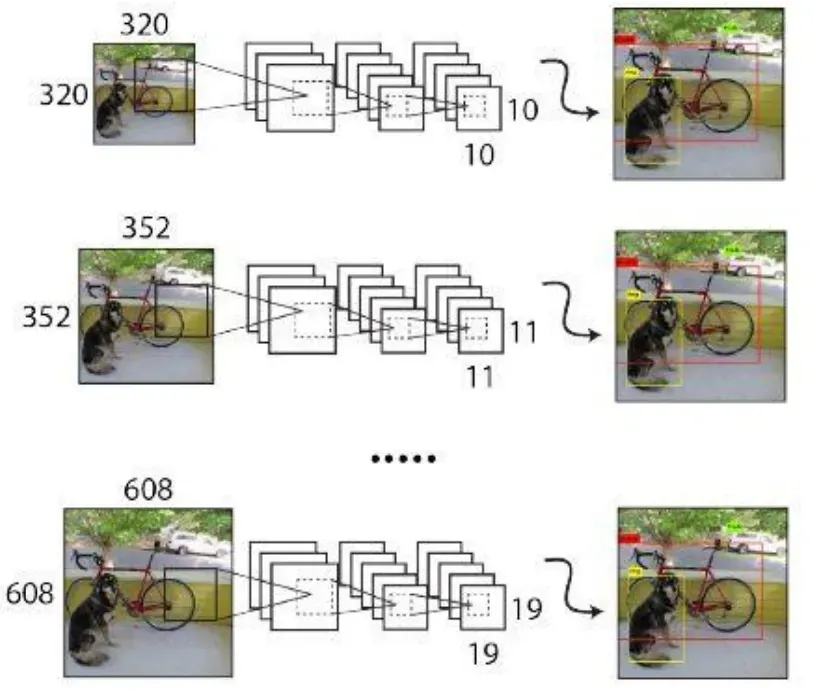
- 由于YOLOv2模型移除全连接层后只有卷积层和池化层,所以YOLOv2的输入可以不限于416×416大小的图片。
- 为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的迭代(iterations)之后改变模型的输入图片大小。
- 由于YOLOv2的为32倍下采样,输入图片大小选择一系列为32倍数的值: {320, 352,…, 608} ,输入图片最小为
,此时对应的特征图大小为
;而输入图片最大为
,对应的特征图大小为
。
- 通过多尺度训练出的模型可以预测多个尺度的物体。并且,输入图片的尺度越大则精度越高,尺度越低则速度越快, 因此YOLO v2多尺度训练出的模型可以适应多种不同的场景要求。
- 在训练过程,每隔10个batch随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。
- 另外,可以使用较低分辨率的图像进行目标检测,但代价是准确度。 这对于低GPU设备的速度来说是一个很好的权衡。
- 在288×288时,YOLO的运行速度超过90FPS,mAP几乎与Fast R-CNN一样好。 在高分辨率下,YOLO在VOC 2007上实现了78.6 mAP
Anchor Boxes
聚类
在YOLO-V1中使用全连接层进行bounding box预测(要把1470×1的全连接层reshape为7×7×30的最终特征),这会丢失较多的空间信息,导致定位不准。Faster-RCNN和SSD中的先验框个数和宽高维度是手动设置不同比例(1:1;1:2;2:1)的先验框,因此很难确定设计出的一组预选框是最贴合数据集的,也就有可能为模型性能带来负面影响。
- Motivation
- 假设一开始就可以选择更好和更具代表性的先验框尺寸,那么网络应该更容易学习准确的预测位置。
- 解决方案
- 统计学习中的 K-means聚类方法,通过对数据集中的 GT Box 做聚类,找到 GT Box 的统计规律。以聚类个数𝑘为锚定框个数,以𝑘个聚类中心Box的宽高维度为宽高的维度.
如果按照标准K-means使用欧式距离函数,大框比小框产生更多误差。但是,我们真正想要的是使得预测框与 GT框的有高的IOU得分,而与框的大小无关。因此采用了如下距离度量
IOU越大,边框距离越近。即聚类分析时选用Bbox与聚类中心Bbox之间的IOU值作为距离指标,聚类结果如下图:
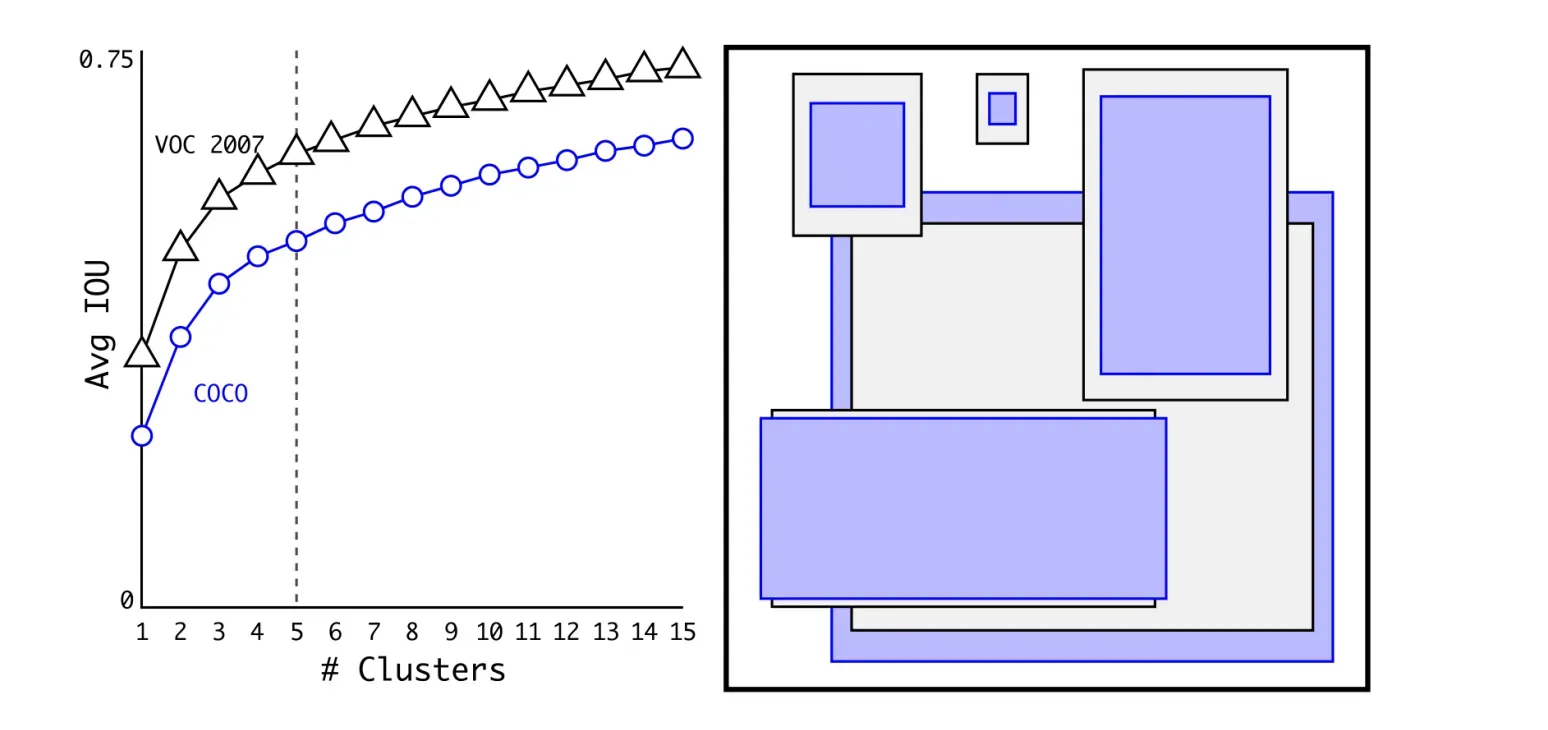
上面左图:随着𝑘的增大,IOU也在增大(高召回率),但是复杂度也在增加。所以平衡复杂度和IOU之后,最终得到𝑘值为5 。
上面右图:5个聚类的中心与手动挑选的框是不同的,扁长的框较少,瘦高的框较多。作者文中的对比实验说明了 K-means 方法的生成的框更具有代表性,使得检测任务更容易学习。
YOLO-V2中的anchor box可以同时预测类别和坐标。跟YOLO-V1比起来,去掉最后的池化层,确保输出的卷积特征图有更高的分辨率。缩减图片的输入尺寸,分辨率为416×416,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。因为大物体通常占据了图像的中间位置,可以只用一个中心的cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测(增加计算复杂度),所以在YOLOv2 设计中要保证最终的特征图有奇数个位置。
YOLOv2使用卷积层降采样(factor=32),使得输入卷积网络的416×416的图片最终得到13×13的卷积特征图(416/32=13)。每个中心预测5种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个Cell一一对应。
YOLOv2把预测类别的机制从空间位置(Cell)中解耦,由Anchor Box同时预测类别和坐标。
- YOLO v1是由每个Cell来负责预测类别,每个Cell对应的2个Bounding Box 负责预测坐标(YOLOv1中最后输出7×7×30的特征,每个Cell对应1×1×30,前10个主要是2个Bounding Box用来预测坐标,后20个表示该Cell在假设包含目标的条件下属于20个类别的概率)。
- YOLO v2中,不再让类别的预测与每个Cell(空间位置)绑定一起,而是全部放到Anchor Box中。
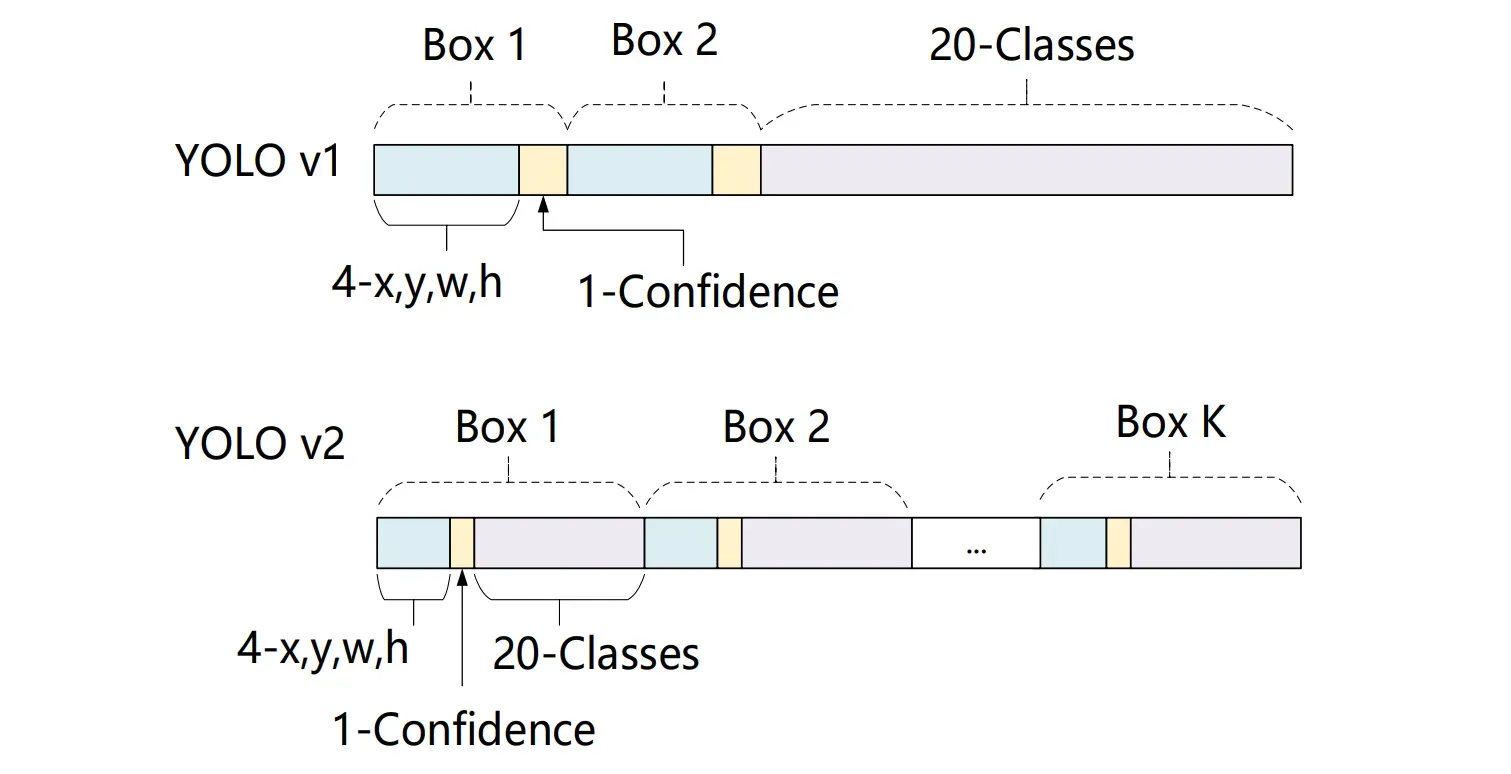
由于YOLO v2将类别预测从cell级别转移到边界框级别,在每一个区域预测5个边框,每个边框有25个预测值,因此最后输出的特征图通道数为125。其中,一个边框的25个预测值分别是20个类别预测、4个位置预测及1个置信度预测值。这里与v1有很大区别,v1是一个区域内的边框共享类别预测,而这里则是相互独立 的类别预测值。
YOLOv1只能预测98个边界框(7 × 7 × 2),而YOLOv2使用anchor boxes之后可以预测上千个边界框 (13 × 13 × 5 = 845) 。所以使用anchor boxes之后,YOLOv2的召回率大大提升,由原来 的81%升至88%。
直接位置预测
YOLOv2沿用v1版本的方法:预测边界框中心点相对于对应cell左上角位置的相对偏移量,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移量,这样预测值都在范围内。根据边界框预测的4个偏移值,可以使用如下公式来计算边界框实际中心位置和长宽:
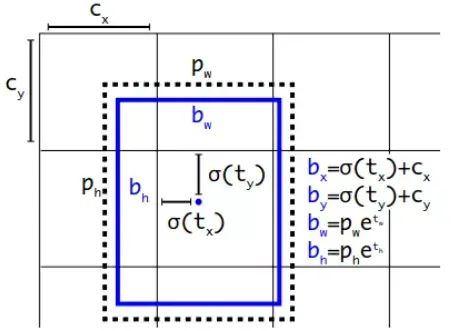
其中,为cell的左上角坐标。在上图中,当前的cell的左上角坐标为
。由于sigmoid函数的处理,边界框的中心位置会被约束在当前cell的内部,防止偏移过多,然后
和
是先验框的宽度与高度,它们的值也是相对于特征图(这里是
,我们把特征图的长宽记作H,W)大小的,在特征图中的cell长宽均为1。这样我们就可以算出边界框相对于整个特征图的位置和大小了。如果想得到边界框在原图的位置和大小,那就乘以上网络下采样的倍数。
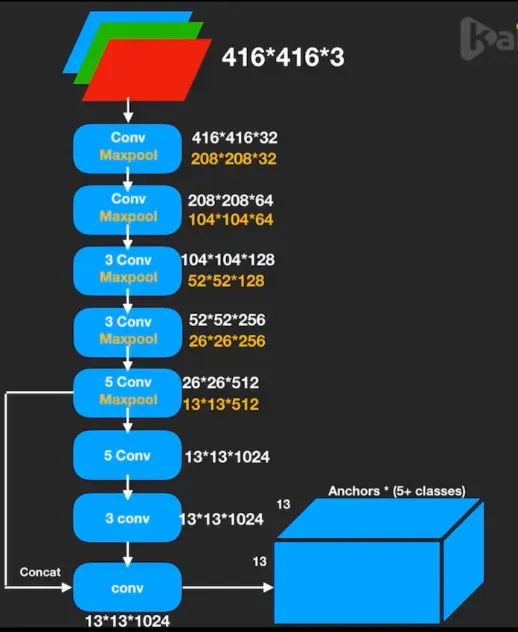
Darknet-19
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个max pooling层。

- Darknet-19 与 VGG16 模型设计原则是一致的,主要采用
卷积,采用
的最大池化层之后,特征图维度降低2倍,而同时将特征图的通道增加两倍。用连续
卷积,这样既减少了计算量,又增加了网络深度。此外,DarkNet去掉了全连接层与Dropout层。
- Darknet-19 ,包括19个卷积层 和 5个max pooling层,采用 global avg pooling+Softmax 做预测,与NIN(Network in Network)类似,并且在
卷积来压缩特征图通道以降低模型计算量和参数。
- DarkNet的实际输入为
,没有全连接层(FC层),5次降采样到
- DarkNet使用了BN层,这一点带来了2%以上的性能提升。 BN层有助于解决反向传播中的梯度消失与爆炸问题,可以加速模型的收敛,同时起到一定的正则化作用,降低模型过拟合。BN层的具体位置是在每一个卷积之后,激活函数LeakyReLU之前。
- 在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数较小。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%
- Passthrough层:DarkNet还进行了深浅层特征的融合,具体方法是将浅层
的特征变换为
,这样就可以直接与深层
的特征进行通道拼接。这种特征融合有利于小物体的检测,也为模型带来了1%的性能提升。
文章出处登录后可见!