浅学一下SPP吧。
背景
在CNN已经在视觉检测领域表现出明显的性能提升的时候,CNN网络却有一个地方困扰着研究者和一些使用者,那就是当时的CNN网络只能以固定大小的图片进行输入(比如224×224),这限制了输入图像的长宽比和缩放尺度。
那么有人可能会提出建议,在前面加上一些手段,比如裁剪和变形等,这样图片输入就可以任意了,但是最终入网的大小是不固定的。建议很好,下次不允许再建议。让我们深入了解为什么这种方法不起作用。
原因:
1、裁剪会导致信息的丢失;
2、变形会导致位置信息的扭曲;
上面具体的示例论文中给出了下面两张非常直观的图片;
虽然图片的裁剪和变形有点激进,但在现实世界中可能会比这更好,但事实证明这样做会极大地影响准确性。此外,当对象是可缩放和可变的时,使用预定义的大小。不再适用。
谈完了裁剪和变形对于改变CNN固定输入不行的情况下,我们很自然的想到,那CNN为什么又是非要固定输入呢?
哎,那是因为后面全连接层的权重矩阵是固定大小的(这个权重矩阵中的值可以随着训练而改变,但是权重矩阵的大小是不允许的),导致了一个全连接层connected 输入也是固定的(因为是全连接的,可以理解为一个输入对应的权重)。
实际上,全连接层之前的卷积层不需要固定的图像大小,它可以生成任意大小的特征图。问题的症结在于它输入到全连接层的特征图需要是固定大小的,这就导致了输入到卷积层的大小是固定的(卷积层是一个输入可以是任意大小,意思是什么输入可以打滚,但是输入影响输出,180磅的英国大力士敢碰,结果不一样)
综上所述, CNN固定尺寸的问题来源于全连接层,也是网络的最后阶段,传统的裁剪和变形也不行。我们需要一种新的算法改进这种情况,哒哒,空间金字塔池化( spatial pyramid pooling,SPP)出现了。
SPP算法原理
一个简短的结论
一句话先来总结一下算法的原理:SPP层对特征进行池化,并产生固定长度的输出,这个输出再喂给全连接层。
白话文为:SPP可以接受任意大小的输入的特征图,但是SPP的输出统统的给你变成一样大小的特征图。
具体方法
输入一个任意大小的特征图,SPP将特征图均匀的分成不同大小的均分块,也就是用不同大小的n*n的块来对输入的特征图进行提取,具体的做法论文给出了如下的图: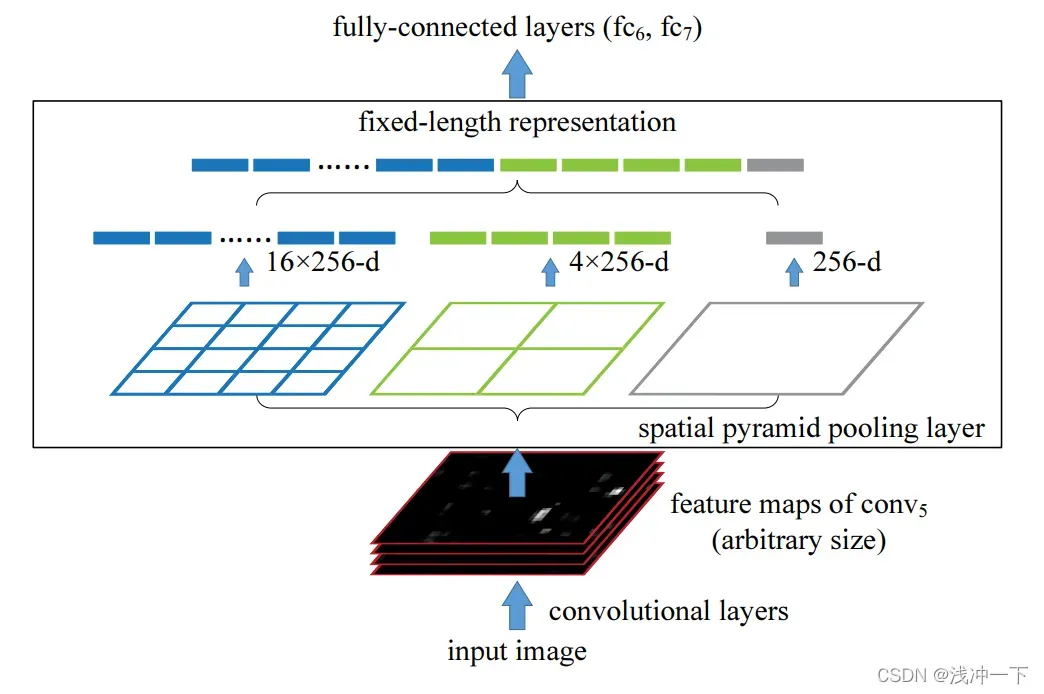
图中分别使用、
、
块来对输入特征进行提取,也可以理解为分别将输入的特征图分成
、
、
的不同大小的块,但是每一块最终的描述子都是一样大小的,将这些分割好的块,再拼接在一起,就形成了全连接层的输入。图上采用的为
、
、
的不同大小的块提取,那么最终拼接在一起的大小为
,在此情况下啊,无论你输入的特征图的多大的,经过SPP之后输出的特征大小都是固定的,假定你就使用
、
、
的不同大小的块提取,那么任何大小的特征图输入进来,输出的大小都是
.当然我们这里说的是通道数为
的情况下,真实情况下,还要乘上输入的通道数。
SPP算法的优点
1)SPP能在输入尺寸任意的情况下产生固定大小的输出,而在SPP出现之前在深度网络中的使用的较为先进滑窗池化(sliding window pooling)则不能;
2)SPP使用了多级别的空间箱(bin),也就是使用不同大小的块对特征图进行提起,而滑窗池化则只用了一个窗口尺寸。多级池化对于物体的变形十分鲁棒;
3)由于其对输入的灵活性,SPP可以池化从各种尺度抽取出来的特征。
SPP的代码实现
具体代码实现可以参考上面的链接。
文章出处登录后可见!