当传统方法约束MVS中的特征点遇到遮挡,反光等原因会使得效果受到很大影响。
- 因此Deep Learning的方法是使用卷积网络抽取特征 ,并且去隐式地约束这些特征与source image特征的关联。具体约束方法有最小化方差等。
MVSNet出于2018年ECCV,有效应用于深度图估计(不过GPU消耗太大)。利用三维代价体:基于可微分的单应性变换的cost volume来回归像素的深度。
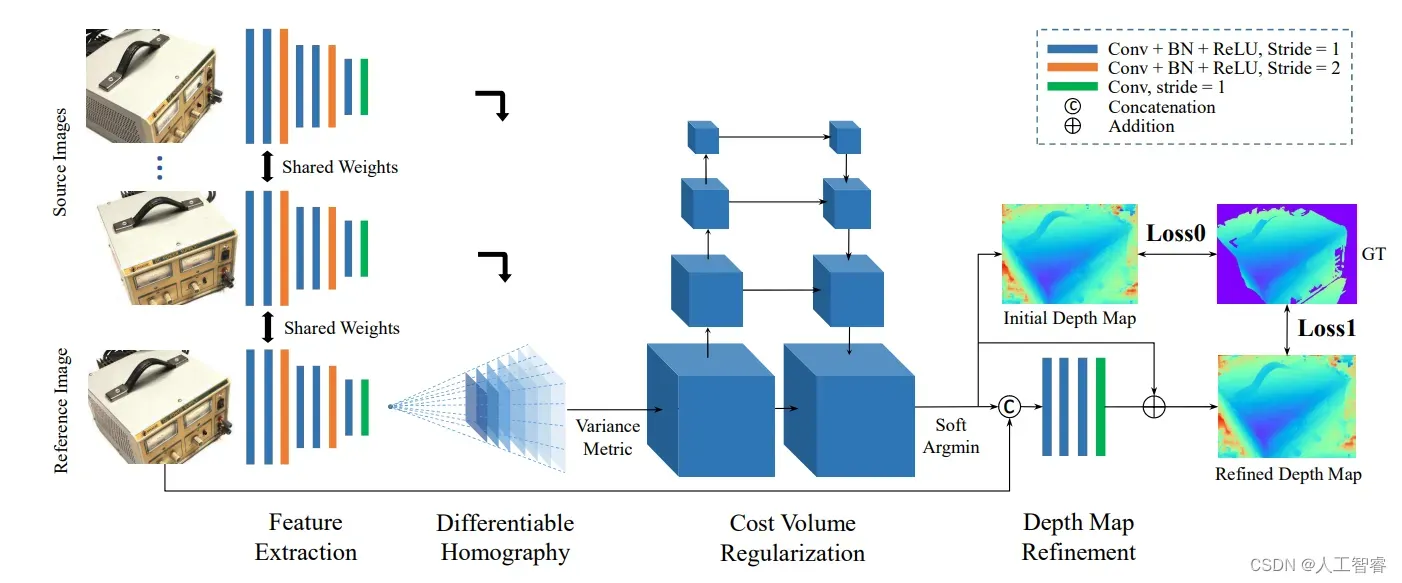
过程:
- 输入一张reference image(为主) 和几张source images(辅助)
- 分别用网络提取出下采样四分之一的32通道的特征图;
- 沿用双目立体匹配里提出的cost volume的概念,将几张source images的特征利用单应性变换( homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。
- 利用3D卷积操作cost volume正则化,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
- 利用多张图片之间的重建约束(photometric and geometric
consistencies)来选择预测正确的深度信息,重建成三维点云。
注意:原论文公式(1)写错了,但是代码没写错。其实就是相机1坐标系下p1如何转换为相机坐标系下p2的问题,已知世界坐标系下相机1、2的R和t,只需要闭环矩阵转换就可以了。当然其中涉及内参K的映射反映射。
资源:
2.核心部分:Multi-View Stereo中的平面扫描(plane sweep)
3.实战部分:MVSNet_pytorch lighting
3.1不用pl的pytorch版本,比源码效果好
3.2代码部分:详细的介绍
文章出处登录后可见!
已经登录?立即刷新