一、报错信息
之前写代码时碰到了这样一个错误:
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by (1) passing the keyword argument find_unused_parameters=True to torch.nn.parallel.DistributedDataParallel; (2) making sure all forward function outputs participate in calculating loss. If you already have done the above two steps, then the distributed data parallel module wasn’t able to locate the output tensors in the return value of your module’s forward function. Please include the loss function and the structure of the return value of forward of your module when reporting this issue (e.g. list, dict, iterable).
翻译成中文即:
运行时错误:期望在开始新迭代之前已完成前一次迭代的reduction(但没做到这一点)。此错误表明您的模块具有未参与产生loss的参数。您可以通过 (1) 将关键字参数 find_unused_parameters=True 传递给 torch.nn.parallel.DistributedDataParallel 来启用未使用的参数检测; (2) 确保所有 forward 函数的所有输出都参与计算损失。如果您已经完成了上述两个步骤,那么分布式数据并行模块无法在模块的 forward 函数的返回值中定位输出张量。报告此问题时,请包括损失函数和模块 forward 返回值的结构(例如 list、dict、iterable)
二、出现原因
出现这样的报错基本是由于模型中某个(些)定义的模块没有参与梯度的反向传播导致的,即“your module has parameters that were not used in producing loss”。
三、解决方案
下面给出全网能找到的几种解决方案,包括我最后自己解决的方法,供大家参考。
在DistributedDataParallel中加入find_unused_parameters=True,如model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
肉眼逆向检查loss的计算过程,看模型的哪部分没有参与当前loss的梯度反向传播,然后debug。
借助param.grad的值来帮助我们分析,找到代码中哪一部分的参数没有接收到回传梯度,然后debug。
for name, param in model.named_parameters():
if param.grad is None:
print(name)
-
确保forward函数的所有输出都被用于计算loss了,如果forward的返回值中包含没有参与计算loss的变量,就不要输出它(这其实有歧义,也并不一定是万无一失的办法,最后我个人感觉本质原因还是因为模型中有部分参数未参与梯度反传,请继续看)。这一解决方法摘自Github pytorch issue: RuntimeError when using multiple DistributedDataParallel model · Issue #22436 · pytorch/pytorch (github.com)
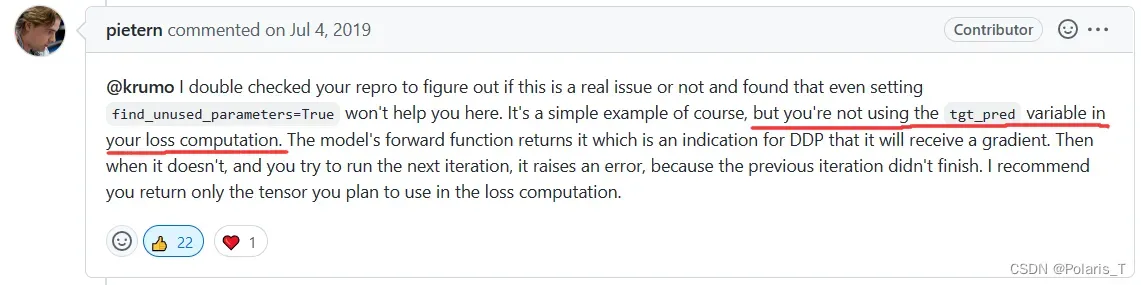
-
确保所有的forward的函数的所有输出都被用于计算损失函数了。这一解决方法摘自CSDN,该作者遇到的问题是:在多任务学习中,损失函数是通过一个整个继承自nn.Module的模块来计算的,但是在forward返回的loss中少加了一个任务的loss,导致这个报错。
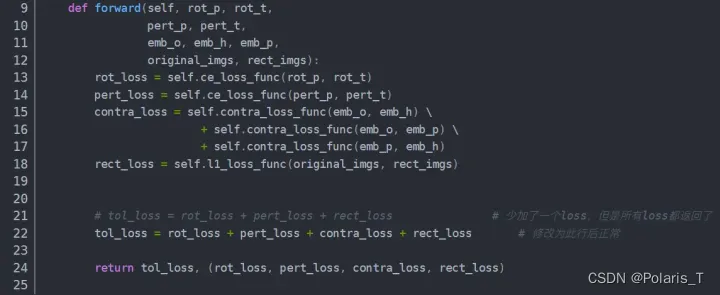
-
本人的解决方法。
正如我上文所说,我个人感觉本质原因是因为模型中有部分参数未参与梯度反传。
一般情况下,找到这部分参数对应的模块,然后使其参与loss计算即可解决了,但是本人的情况是:在一个for loop中有两次loss.backward(),第一次backward的loss1是由模型的某个中间层的feature map计算出的(即,最后一层的输出未参与loss计算),第二个backward的loss2是由模型的最终输出计算出的。在这样一个情境下,当执行第二个backward时,便会报错。分析一下不难发现,确实是由于我在计算第一个loss时,模型有一部分模块的参数并未参与梯度反传(即从上述中间层往后一直到最终层(包括最终层)的这些层)。按照上述解决方法,我必须使得这些层参与loss1的计算,也就是说我必须让最终层的输出参与loss1的计算。但是,我的实际需求确实是不需要最终输出参与loss1的计算的。因此,我想到这样一个办法:既然你非要让我所有参数都参与loss的梯度反传,那我直接让从中间层往后一直到最终层(包括最终层)的这些层的梯度为0不就行了?这样一来,这些层的参数梯度为0,更新时相当于没更新这部分参数,这不影响什么。
基于这样的思想,我设置了一个辅助性loss:util_adv_loss = torch.nn.functional.softplus(-real_logit_b).mean() * 0 + torch.nn.functional.softplus(-rec_logit_b).mean() * 0,这样一来,该loss对于整个模型的任何参数的偏导都是0(根据链式法则),那么在梯度反传时,所有模块的参数都得到0梯度,即不影响任何模块的更新,但又同时满足了报错中所提到的条件,即需要“All the parameters in your module should be used in producing loss”。
文章出处登录后可见!