import用法总结
- 一、直接引入
- 二、from 模块/包 import 模块/函数
- 1.直接引入模块
- 2.引入模块中的所有函数
- 3.引入模块中的指定函数
- 4.相对引用
- 在B_2.py 中引用A.py 中的fun()
- 在C.py中引用B_2.py 模块
- 三、引用不同文件下的 包或模块
- 通过模块引用
- 通过包的引入
- 四、引入函数名冲突
- 函数名冲突的原因
- Python搜索模块的顺序:
- 总结
- 补充一个pycharm中的import方法
ImportError: attempted relative import with no known parent package
因为报错,决定整理一下import用法,做个笔记
一、直接引入
import modulename [as alias]
import 模块名,这时python可以引入以下两种模块; 举例如下:
- 我们安装好的模块;(其实就是在环境变量路径下的模块;)
- 运行文件所在目录下的文件;(这里我们推荐用 from. import 模块名的方式)
import os,sys # 模块间用,隔开,可以引用多个;
import pandas as pd # 这是给模块一个别名,方便后续使用
import random # 所有安装的第三方模块,都可以直接引入
import F1 # 这里F1 就是与运行的py文件同一级的模块或者包,在后面详细介绍;
二、from 模块/包 import 模块/函数
from modelname import member
参数说明如下:
modelname:模块名称,区分字母大小写,需要和定义模块时设置的模块名称的大小写保持致。
member:用于指定要导入的变量、函数或者类等。可以同时导入多个定义,各个定义之间使用逗号“,”分隔。如果想导入全部定义,也可以使用通配符星号“*”代替。
1.直接引入模块
import 模块名:这种方式引入模块时,使用模块内的函数,需要使用模块.函数名的方式来调用函数
import random # 直接引用时
print(random.randint()) # 想要调用random包中的函数,需要使用 random.函数名 的方式来调用,不能直接调用
2.引入模块中的所有函数
from 模块名 import * : 这种方式引入模块时,可以直接使用函数
from random import * # 这种方式是将所有random 包中的内容全部导入进来了,
print(randint()) # 这时候的函数可以直接引用,不再需要 random.函数名 来使用了;
3.引入模块中的指定函数
上面的方式引入了包内所有的函数,有时我们只会用其中一个或几个函数,这时候 我们可以使用以下方式: from random import random,randint
from random import random,randint # 指定引入的函数,其他函数不引入
print(random())
print(randint(1, 10))
4.相对引用
有时我们需要引用当前py文件的父文件夹的模块,这时可以使用相对引用;(但是这种引用,当其他文件引用本py时,有报错风险; 只有在一个项目中的文件相互引用时,由于文件夹结构是固定的,所以推荐使用相对引用
文件结构如下:其中每个A.py, B.py, C.py 文件中的内容为定义一个函数 fun() 打印文件名;
整个目录路径为:D:\PY_useful\import_intro
│
├─ A
│ └─ A.PY
│
├─ B
│ └─ B.PY
│ └─ B_2
│ └─ B_2.PY
│
└─ C
└─ C.PY
#.py文件中的代码:
# A.py
def fun():
print('It is A.py')
# B.py
def fun():
print('It is B.py')
# C.py
def fun():
print('It is C.py')
# B_2.PY
import sys
sys.path.append(r'D:\PY_useful\import_intro')
from A import A
A.fun() # 输出:It is A.py
from A.A import fun
fun() # 输出:It is A.py
def fun():
print('It is B_2')
在B_2.py 中引用A.py 中的fun()
# 错误的做法:
# 这时候,由于B_2.PY 在文件夹B_2中,所以按照相对引用来解析地址,我们会写出以下代码:
from ...A import A # . 表示当前目录,.. 表示父目录, ...表示父目录的父目录;
这时会报错:ValueError: attempted relative import beyond top-level package;
相对引用就会出现这样的错误,解决办法如下: 在环境变量地址中,加入顶级目录的路径,然后从高向低引用;
import sys
print(sys.path) # 添加前的环境变量列表
sys.path.append(r'D:\PY_useful\import_intro') # 添加顶级目录
print(sys.path) # 添加后的环境变量列表
# 方法一:
from A import A # 可以直接导入A包中的A模块
A.fun() # 输出:It is A.py
# 方法二:
from A.A import fun # 可以直接导入A包.A模块 中的fun 函数
fun() # 输出:It is A.py
在C.py中引用B_2.py 模块
from B.B_2 import B_2
B_2.fun()
# 或者:
from B.B_2.B_2 import fun
fun()
输出
It is A.py # 在引入模块的时候,会执行一次模块的内容,所以这里输出了两次 It is A.py
It is A.py
It is B_2
三、引用不同文件下的 包或模块
在D:\PY_useful文件夹中创建文件夹 File_4,File_4中创建M4.py文件,M4.py 中的内容为:
# M4.py 的内容;
def Func4():
print('In Func4')
如果想在别的地方,引用这里的Func4() 函数,有两种方法:
通过模块引用
首先需要将模块所在的路径(D:\PY_useful\File_4),加入环境变量路径中,然后通过引用模块,来使用Func4()函数;
a. 引入模块,然后通过模块调用函数
import sys
path_add = r'D:\PY_useful\File_4' # 模块所在的路径
sys.path.append(path_add) # 把路径添加到环境变量中
import M4
M4.Func4()
b. 直接引入模块中的函数
import sys
path_add = r'D:\PY_useful\File_4' # 模块所在的路径
sys.path.append(path_add) # 把路径添加到环境变量中
from M4 import Func4
Func4()
通过包的引入
首先需要将包(我们把File_4当作包)所在的路径(D:\PY_useful),加入环境变量路径中,然后通过引用包,来使用模块,再通过模块调用Func4()函数;
package:通常包总是一个目录,可以使用import导入包,或者from + import来导入包中的部分模块。包目录下为首的一个文件便是 init.py。然后是一些模块文件和子目录,假如子目录中也有 init.py 那么它就是这个包的子包了。
当程序不能把文件夹当作包时,在文件夹中建立空的py文件,文件名修改为: init.py , 有了这个空文件,文件夹会被python程序理解成包;
a. 通过包,引入模块来调用函数;
import sys
path_add = r'D:\PY_useful' # 包所在的路径
sys.path.append(path_add) # 把路径添加到环境变量中
from File_4 import M4
M4.Func4()
b. 通过包,引入模块,再引入指定函数;
import sys
path_add = r'D:\PY_useful' # 模块所在的路径
sys.path.append(path_add) # 把路径添加到环境变量中
from File_4.M4 import Func4
Func4()
四、引入函数名冲突
函数名冲突的原因
想要解决函数名冲突,我们必须先明白Python的搜索模块顺序,python 按照顺序搜索模块,找到匹配项便会直接返回,不再向后查找,所以当有函数名相同的情况发生时,先被找到的函数会被执行;
Python搜索模块的顺序:
- 程序的主目录
- PTYHONPATH目录(如果已经进行了设置)
- 标准连接库目录
- 自己添加的path路径
上面的顺序,使用sys.path 就可以看到,不需要记,记住sys.path 就可以啦~;
import sys
for i in sys.path:
print(i)
D:\PY_useful\import_intro\F1\F2 # 这是 .py 文件所在的位置
D:\PY_useful\import_intro # 这是 项目目录
C:\ProgramData\Anaconda3\python36.zip #下面这几个是python自己的目录
C:\ProgramData\Anaconda3\DLLs
C:\ProgramData\Anaconda3\lib
C:\ProgramData\Anaconda3
C:\ProgramData\Anaconda3\lib\site-packages # 下面是安装模块的目录
C:\ProgramData\Anaconda3\lib\site-packages\win32
C:\ProgramData\Anaconda3\lib\site-packages\win32\lib
C:\ProgramData\Anaconda3\lib\site-packages\Pythonwin
总结
主要是学习的这篇文章,条理清晰
参考了这篇文章,具体内容比上篇细致,先码住
我的另一篇文章:jupyter notebook中调用文件内自定义的函数
一般就是直接引入;最近相对引入要用的比较多,老是报错,这个文章介绍的挺清楚的;学吧学吧。
以后遇见其他相关问题会不断更新的。
补充一个pycharm中的import方法
结构如下:
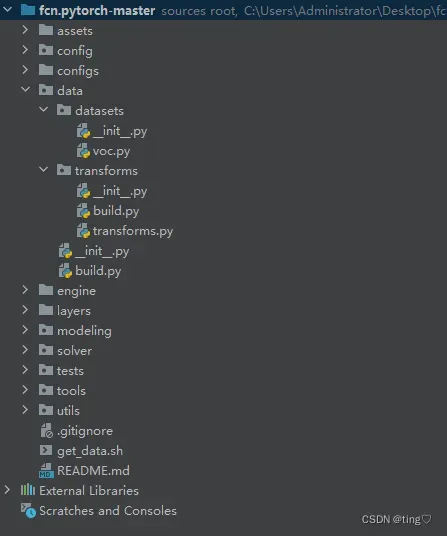

报错“attempted relative import with no known parent package“
-
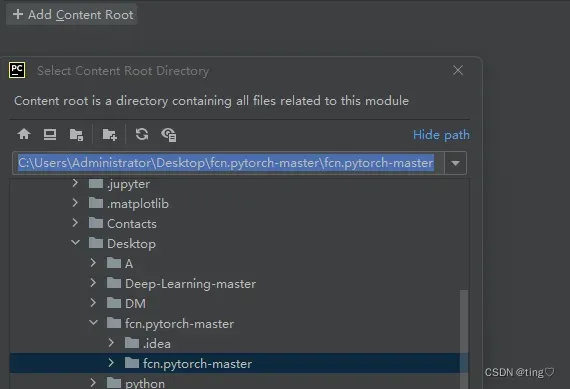
打开File->Setting->python structure
-
点击add contend root ,选择所在文件夹
-
mark as sources,OK
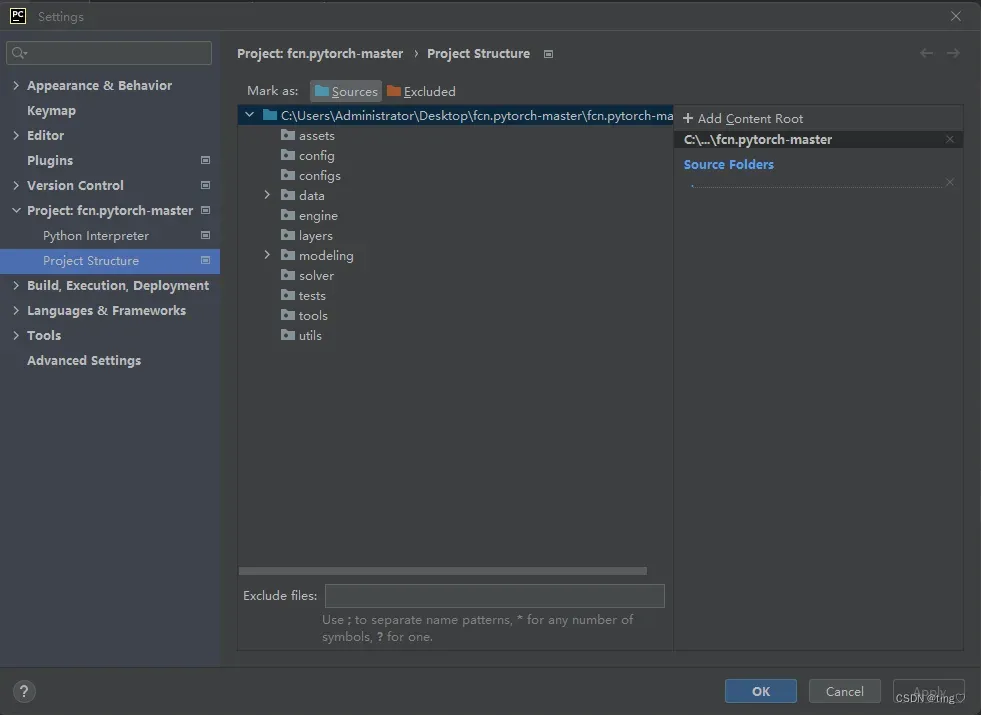
然后就可以直接调用了
![]()
文章出处登录后可见!