Learning Placeholders for Open-Set Recognition
CVPR2021
Code: https://github.com/zhoudw-zdw/CVPR21-Proser.git
摘要
传统分类器部署在闭集设置下,训练类和测试类属于同一个集合。然而,现实世界的应用程序可能面临未知类别的输入,模型会将它们识别为已知类别。在这种情况下,提出了开放集识别以保持对已知类的分类性能并拒绝未知数。封闭集模型对熟悉的已知类实例进行过度自信的预测,因此当扩展到开放集环境时,跨类别的校准和阈值化成为必不可少的问题。为此,我们建议学习 Open-SEt Recognition (PROSER) 的占位符,它通过为数据和分类器分配占位符来为未知类做准备。具体来说,学习数据占位符试图预测开放集类数据,从而将封闭集训练转变为开放集训练。此外,为了学习目标类和非目标类之间的不变信息,我们保留分类器占位符作为已知和未知之间的类特定边界。所提出的 PROSER 通过流形混合有效地生成新类,并在训练期间自适应地设置保留的开放集分类器的值。对各种数据集的实验验证了我们提出的方法的有效性。
介绍
开集识别检测未知类的实例。
面对新类别的未知输入,区分已知和未知实例的一种直观方法是在输出概率上施加阈值 [10]。它假设模型为已知类别产生的概率高于未知类别。
然而,深度学习方法往往会过度拟合训练实例并产生过度自信的预测 [27、8、9]。结果,即使对于未知的类实例,该模型也会输出很高的概率,从而使阈值难以调整。
此外,类组合是多种多样的,如图 1 所示。由于已知类的语义信息在不同的任务中有所不同,因此很难获得适合所有开放集任务的最佳阈值。
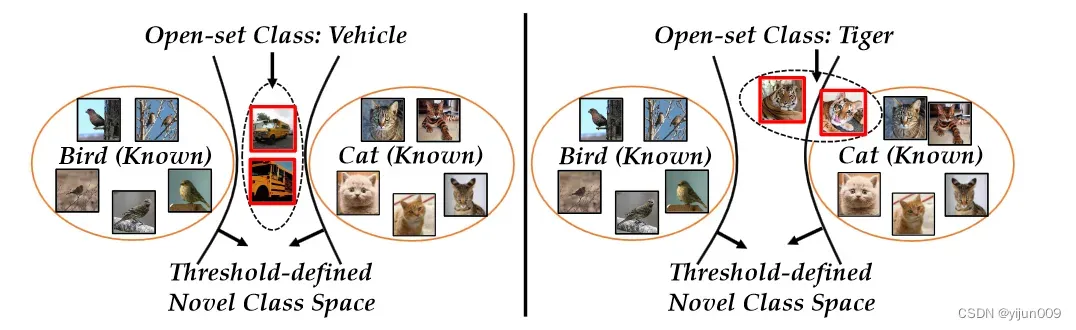
图 1. 基于阈值的开集识别的缺点。 如果置信度低于固定阈值,就是新的类空间。 鸟和猫是已知类,而车辆和老虎分别是左右图中的开放集类。 由于车辆和老虎类别的分布不同,很难依靠单一的阈值来识别具有不同特征的未知类别。 将车辆与已知类别区分开来的阈值不适用于老虎。
因此,需要校准闭集分类器。
其他方法试图预测新类的分布并用开集概率校准输出。 [6] 提出了 G-OpenMax,它利用 GAN 生成未知样本来训练新的分类器。 [22] 试图生成位于决策边界之间的图像作为反事实(counterfactual )实例。 [26]将自我监督和增强输入与生成的开放集样本相结合。这些方法试图用生成模型预测新的类分布,并将封闭集训练转变为开放集训练。
提高开放集识别的目的可以概括为一个校准问题[8, 34]。 首先,为了使封闭集模型为未知类做好准备,应该增加新类的数据占位符并将开放集转换为封闭集。 其次,为了更好地区分已知和未知实例,应该通过为新类保留分类器占位符来校准过度自信的预测。
受上述问题的启发,我们提出学习用于 Open-SEt Recognition (PROSER) 的占位符,旨在从两个方面校准开放集分类器。
- 详细地说,我们用一个额外的类别占位符来扩充封闭集分类器,它代表已知和未知之间的特定类阈值。我们为开放集类保留占位符,以获取目标类和非目标类之间的不变信息。
- 此外,为了有效地预测新类的分布,我们考虑生成数据占位符,这些占位符用有限的复杂性成本模仿开放集类别。因此,我们可以将闭集分类器转换为开集分类器,并在测试期间自适应地预测特定类别的阈值。
在各种数据集上的实验验证了我们提出的方法在未知检测和开放集识别问题上的有效性。此外,决策边界的可视化表明 PROSER 学习了不同类别组合的自适应阈值。
了解思想之后,后面的内容见:Learning Placeholders for Open-Set Recognition CVPR2021开放集论文解读 – apron的文章 – 知乎
https://zhuanlan.zhihu.com/p/433150826
文章出处登录后可见!