目录
1. Pytorch环境的配置及安装
首先需要下载Anaconda(包含了大量的package/工具包)
深度学习离不开显卡(TensorFlow/Pytorch支持英伟达的显卡),起到训练加速的作用
- 显卡的配置:驱动 + CUDA Toolkit(CUDA工具包)
- CUDA Toolkit 会跟随Pytorch一键安装
- 主要检查显卡的驱动是否正确安装:任务管理器—性能—GPU,若能看到GPU的型号,即意味着显卡的驱动已经正确安装
如何管理项目环境?
一个package相当于一个工具包,把环境理解成一个房子,初始环境base,不同环境可以有不同版本的工具包,切换环境即可
conda指令创建pytorch环境(如果开了代理服务器,务必关闭!!!)
以下命令在 Anaconda Prompt 中输入:
conda create -n pytorch python=3.8 # -n是name的意思conda activate pytorch # 激活环境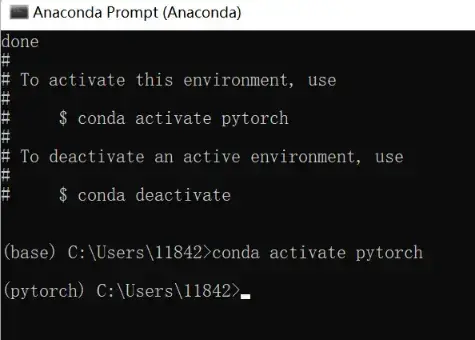
左边括号里的环境由base变成了pytorch(环境名称)
看一下环境中的工具包:
pip list 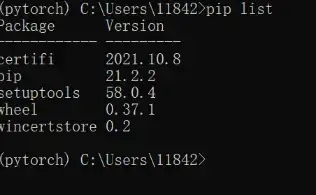
并没有pytorch,接下来:安装pytorch
网址:PyTorch
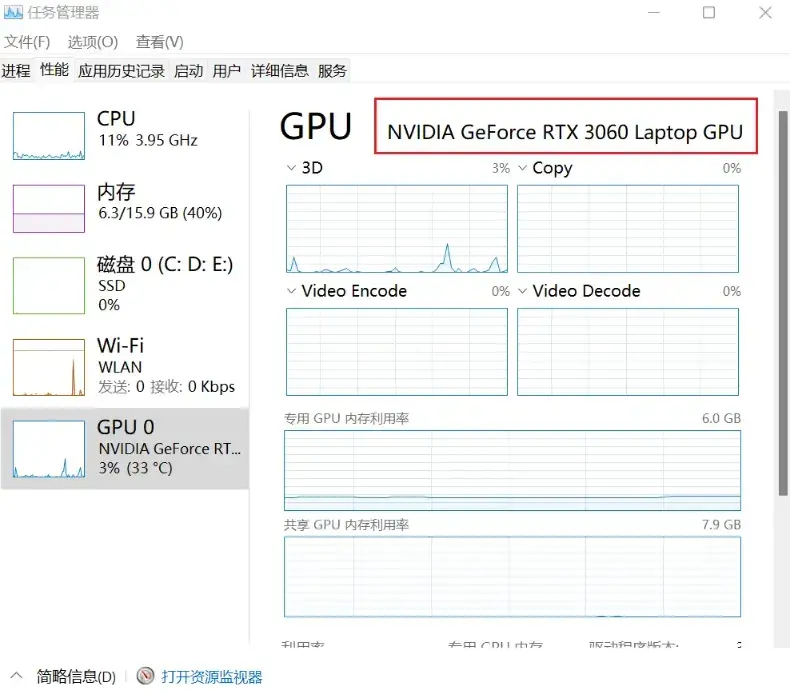
如何看自己电脑cuda版本?
- 任务管理器—性能—GPU
- 或:设备管理器—显示适配器
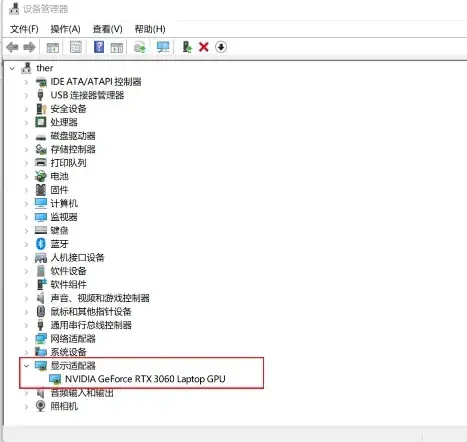
独立显卡
在cmd里输入:
nvidia-smi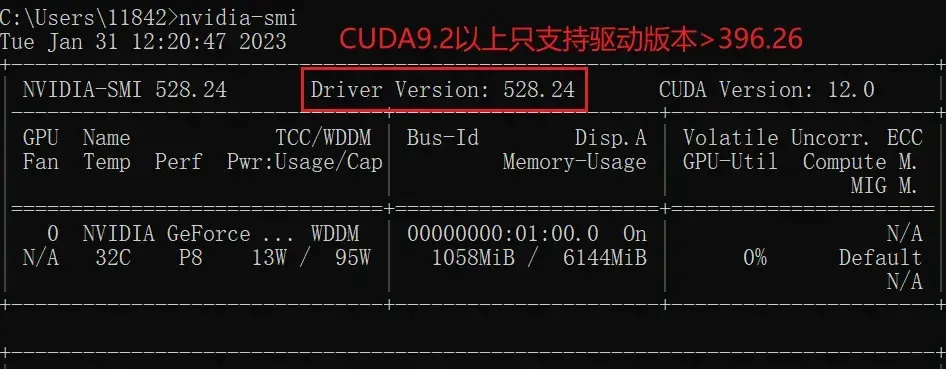
安装Pytorch
找到自己适合的版本,复制命令:
- Stable 稳定版:1.1版本以后加入了TensorBoard,可以看到训练过程中的数据,如损失函数的变化
- Package:一般Windows下推荐使用Conda,Linux下推荐使用pip
- Compute Platform:
- 无英伟达显卡或只有集显:CPU
- 有英伟达显卡:30系列显卡不支持11.1以下的CUDA
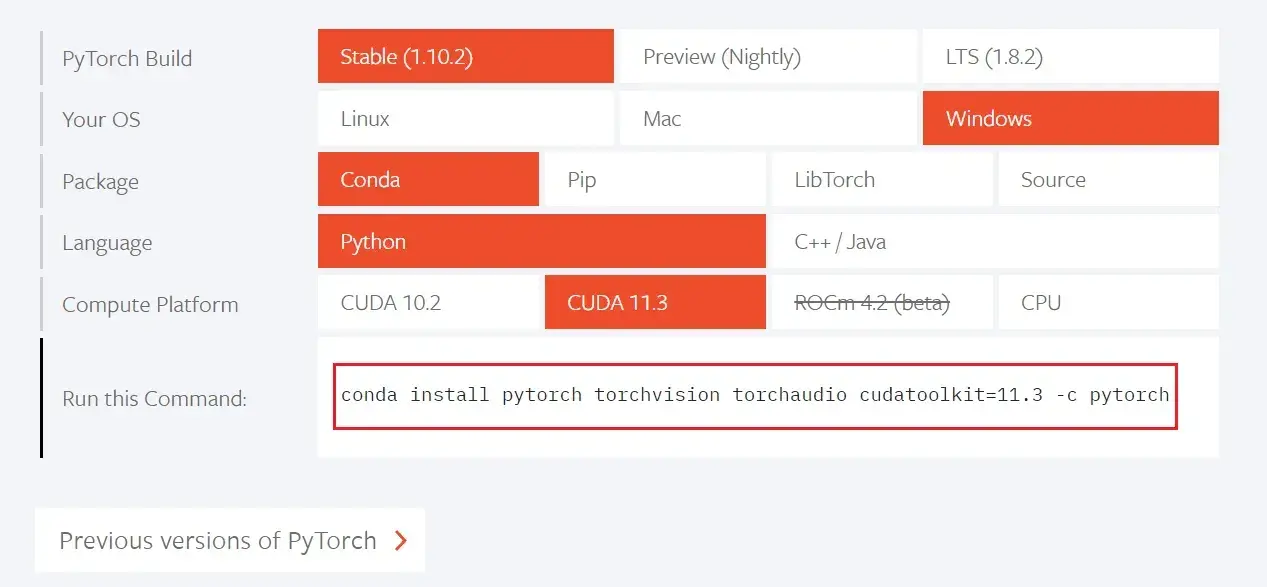
在刚刚激活了pytorch环境的窗口里输入:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch等待安装成功之后,再
pip list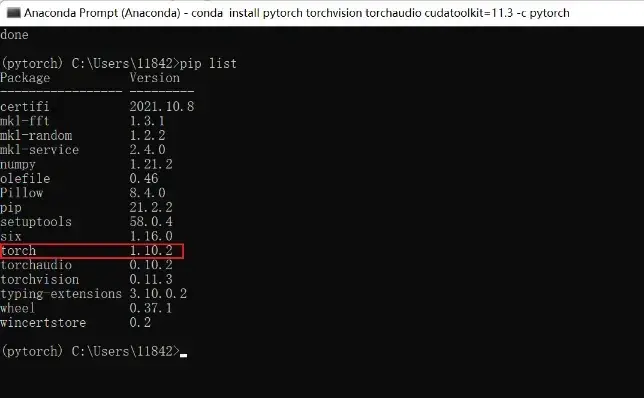
可以看到已经安装成功
检验安装是否成功:先输入
python再输入
import torch若没有报错则安装成功,如图
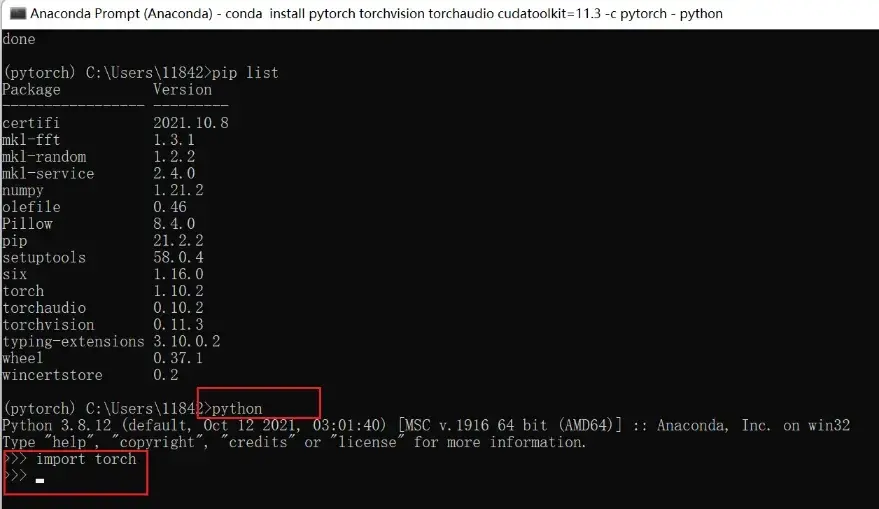
检验pytorch是否可以用GPU:
torch.cuda.is_available()返回True即可
2. Python编辑器的选择、安装及配置
PyCharm
PyCharm: the Python IDE for Professional Developers by JetBrains
在Python工作台/控制台验证:
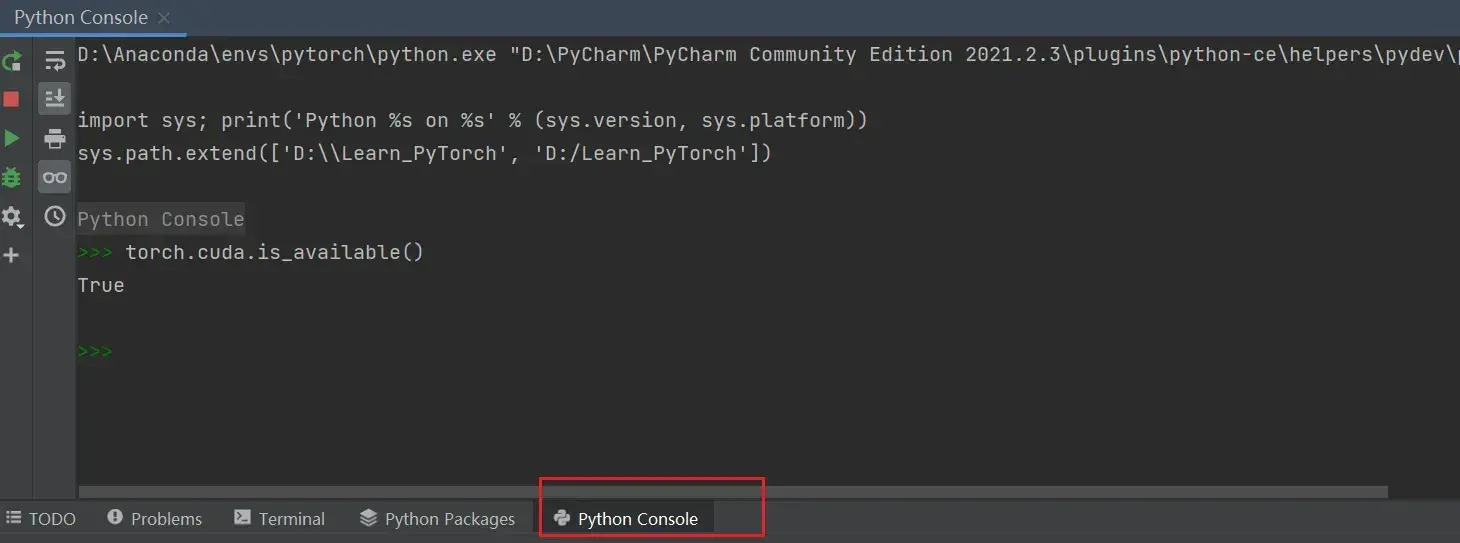
先输入
import torch再输入
torch.cuda.is_available()返回True即可,如上图
PyCharm神器
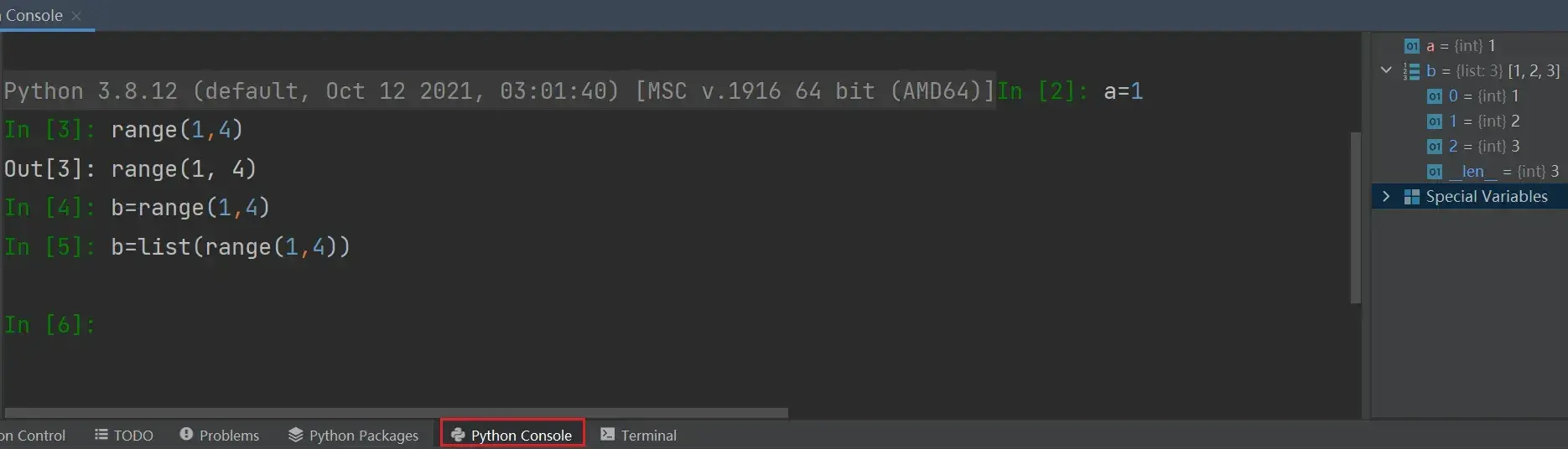
在左边输入,右边有变量的属性,很直观
———————————————————————————————————————————
Jupyter(可交互)
建议直接安装Anaconda,Jupyter会随着Anaconda一起安装
Jupyter 默认安装在 base 环境中,但是base环境中没有安装 Pytorch,导致Jupyter无法使用Pytorch,两种解决方式:
- 在base环境中再安装一遍Pytorch
- 在Pytorch环境中安装Jupyter(选择这种)
打开Anaconda Prompt是base环境,从base环境启用Jupyter需要一个package:ipykernel,如图:
输入
conda list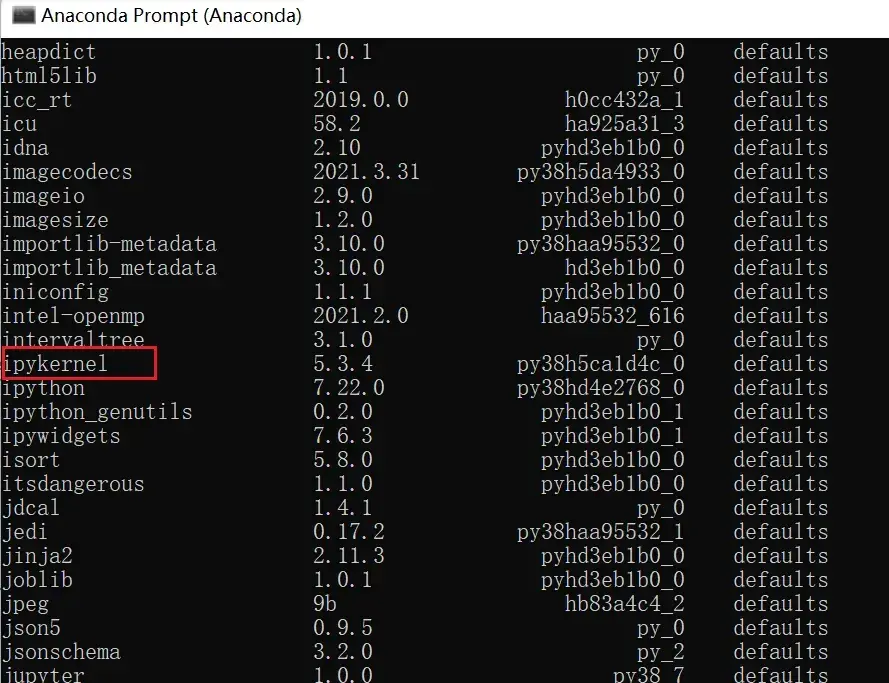
可以看到要用到的 package是 ipykernel
进入Pytorch环境中:
conda activate pytorch再输入
conda list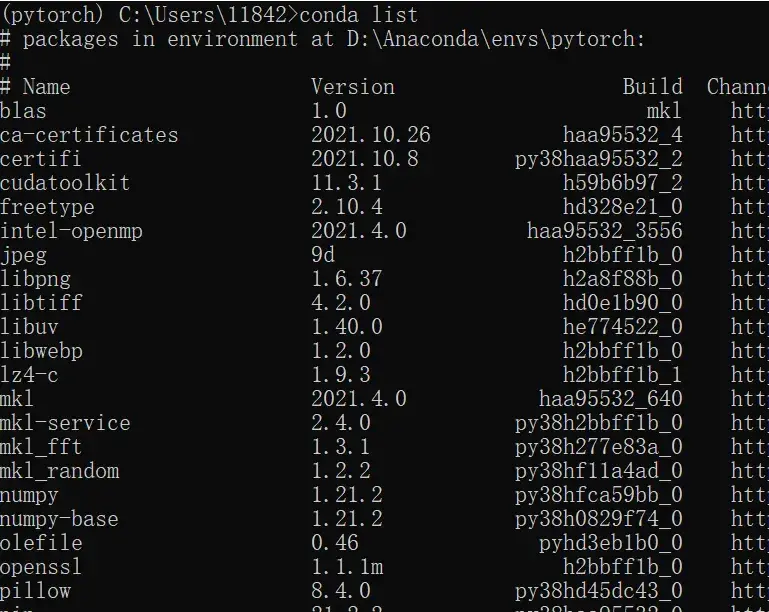
可以发现没有 ipykernel ,安装这个 package(同样需要关闭代理服务器!!!)
conda install nb_conda等到done之后,再输入
jupyter notebook等到页面跳转到浏览器,New — Python[conda env:pytorch]*
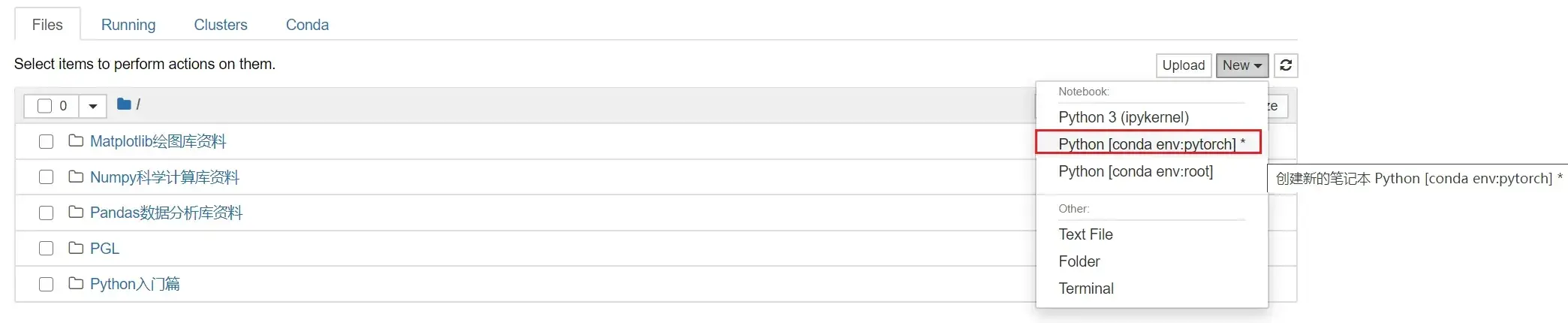
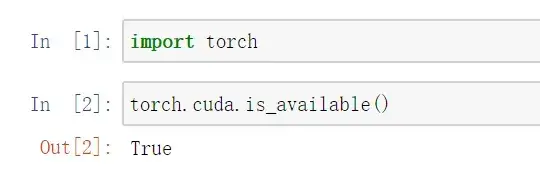
同样,先输入
import torch再输入
torch.cuda.is_available()返回True即可,如下图
意外插曲:
网页可以正常跳转,但是会有这个窗口弹出:
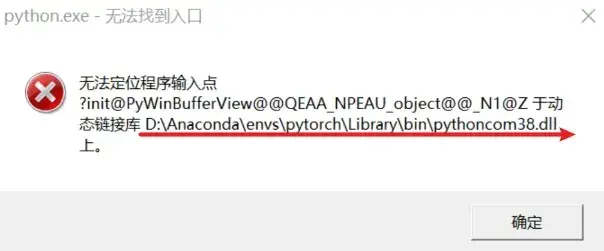
解决方式:按照地址删去 pythoncom38.dll 文件即可(可能需要删多个 pythoncom38.dll 文件)
3. Python学习中的两大法宝函数
说明
package(名称为 pytorch)就像一个工具箱,有不同的分隔区,分隔区里有不同的工具
探索工具箱,两个道具:
- dir() 函数:能让我们知道工具箱以及工具箱中的分隔区有什么东西(打开,看见)
- help() 函数:能让我们知道每个工具是如何使用的,工具的使用方法(说明书)
例:
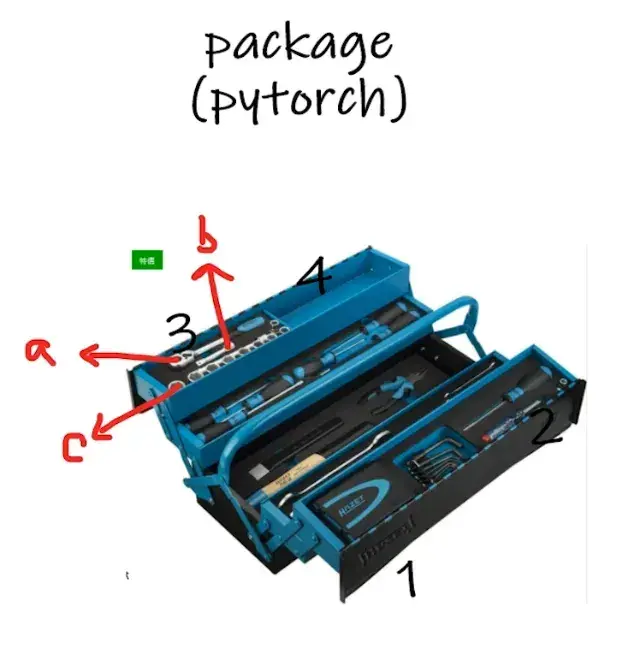
dir(pytorch),就能看到输出1、2、3、4等分隔区;想继续探索第3个分隔区里有什么的话,dir(pytorch.3),输出会是a,b,c(3号分隔区里有a,b,c等工具),如何使用?
help(pytorch.3.a) 输出:将此扳手放在特定地方,然后拧动
———————————————————————————————————————————
实战操作
打开PyCharm,输入
dir(torch)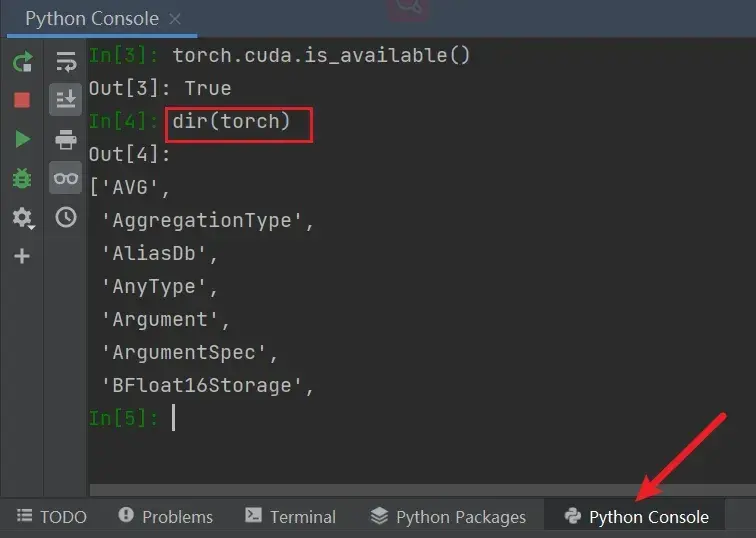
可以看到输出了大量的分隔区(或理解为更小的工具箱),ctrl+F找到cuda
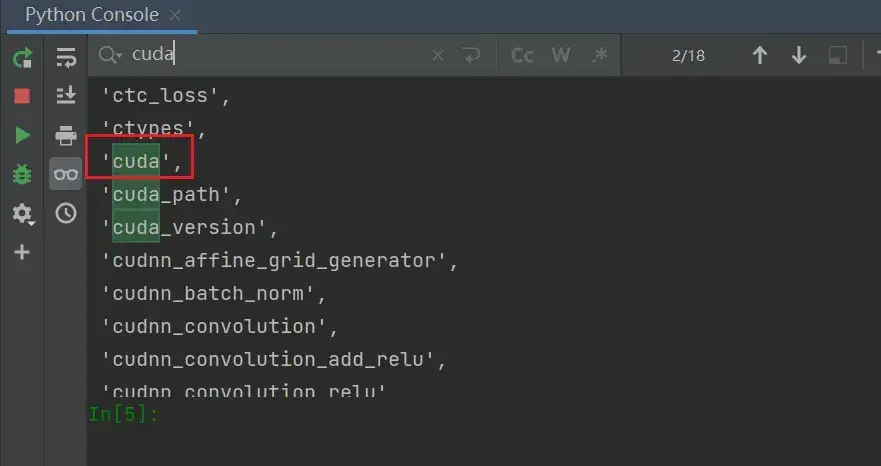
看cuda分隔区里有什么,输入
dir(torch.cuda)可以看到又输出了大量的分隔区
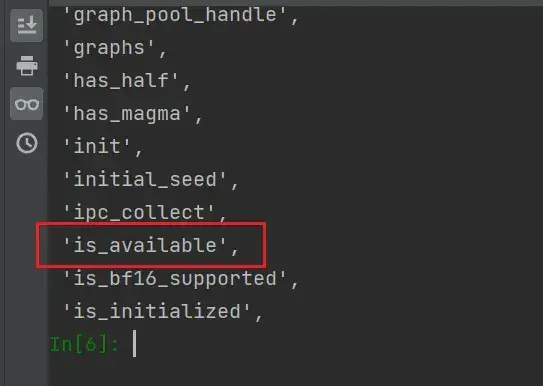
继续输入:
dir(torch.cuda.is_available)可以看到输出的前后都带有双下划线__,这是一种规范,说明这个变量不容许篡改,即它不再是一个分隔区,而是一个确确实实的函数(相当于工具,可以用help()函数)
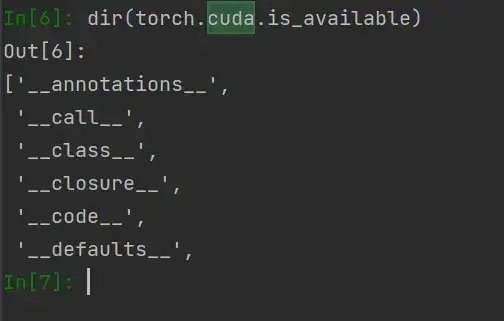
对工具使用 help():
help(torch.cuda.is_available)注意 is_available 不带括号
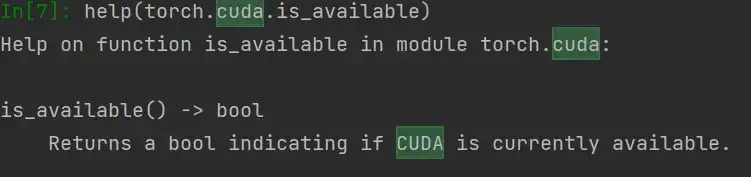
返回一个布尔值(True或False),表明cuda是否可用
总结
- dir() 函数:打开package
- help() 函数:官方的解释文档,看函数怎么用
4. Pycharm及Jupyter使用及对比
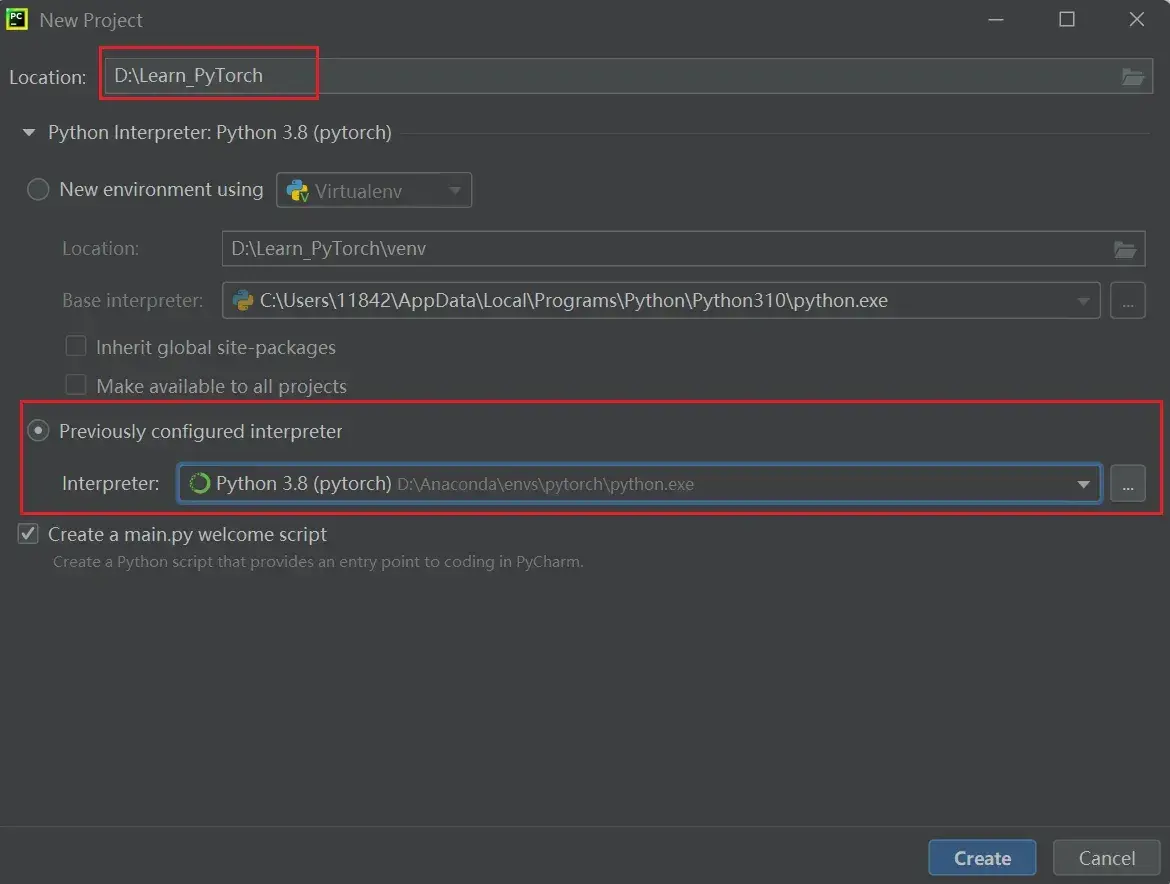
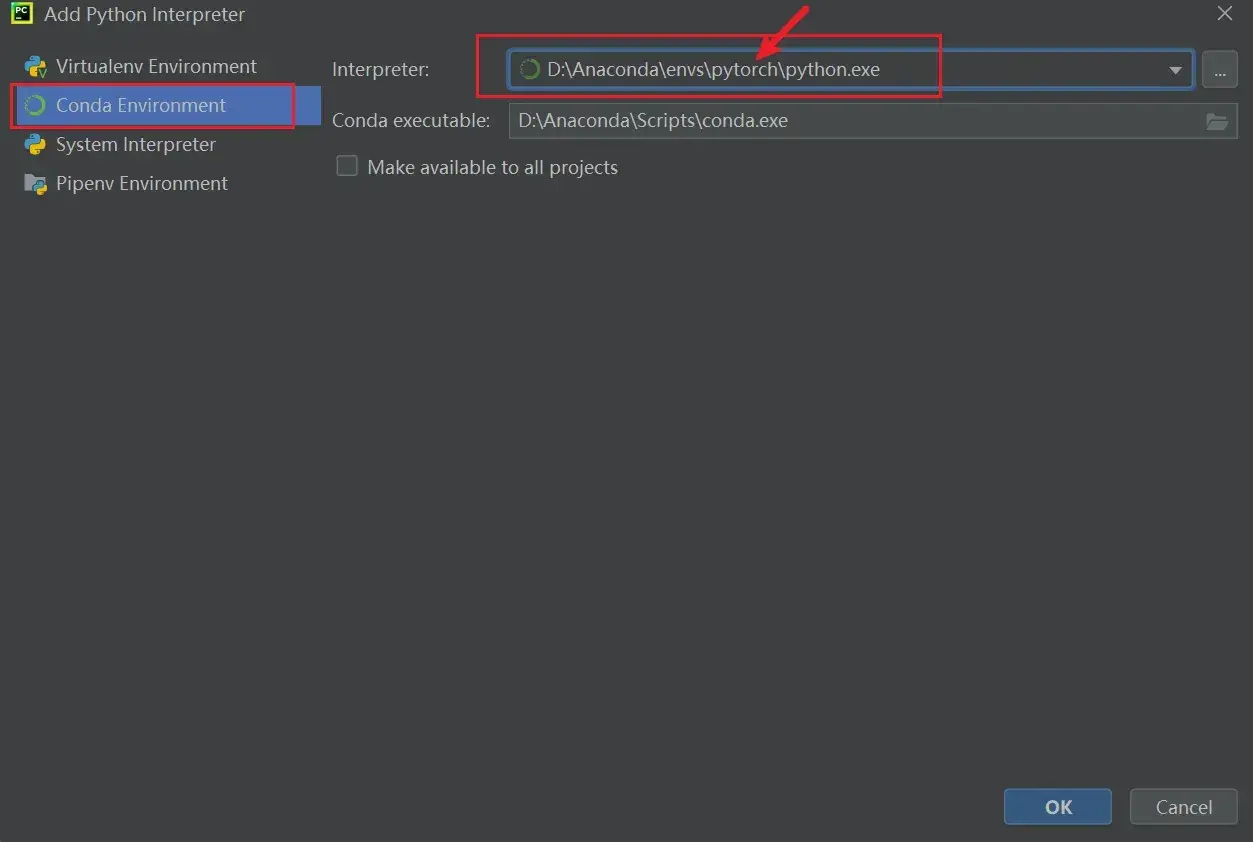
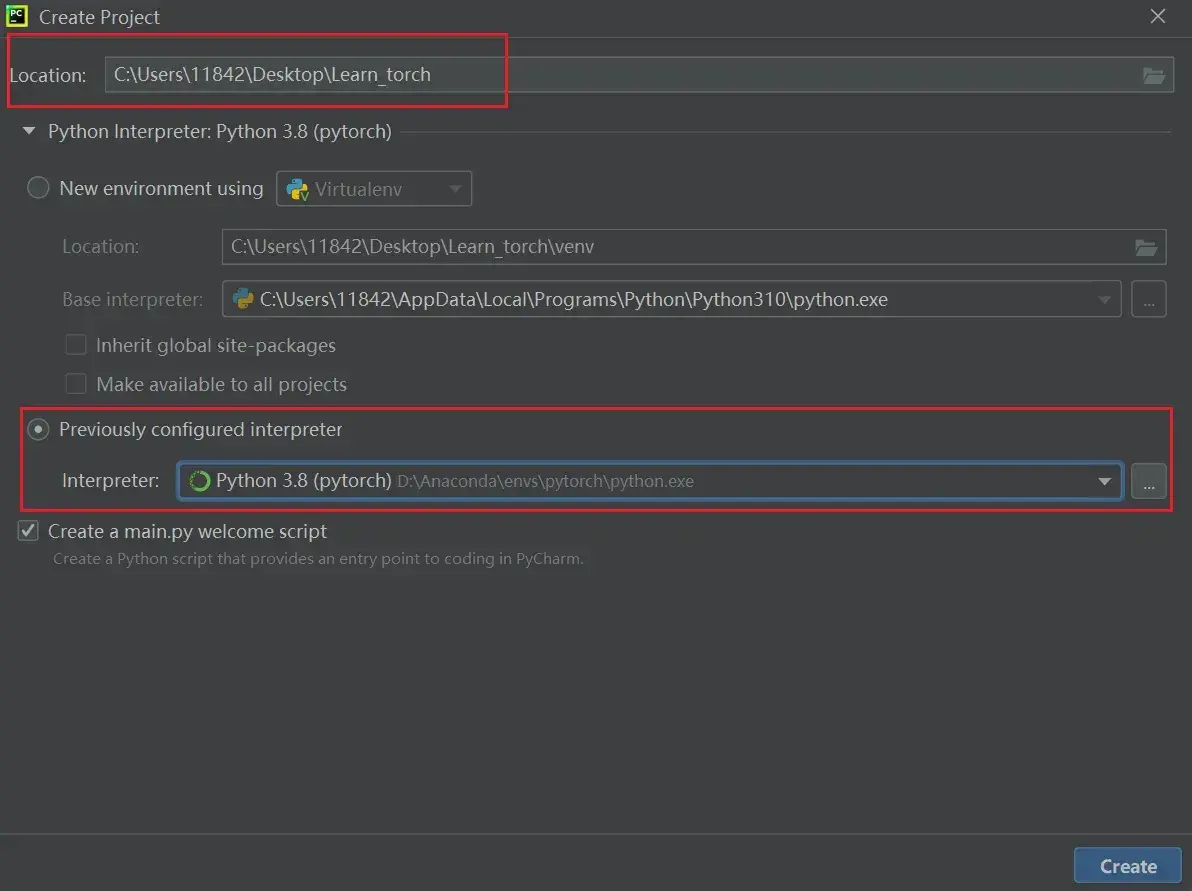
如何在PyCharm中新建项目?
(1)新建文件夹 Learn_torch(右键:New Folder)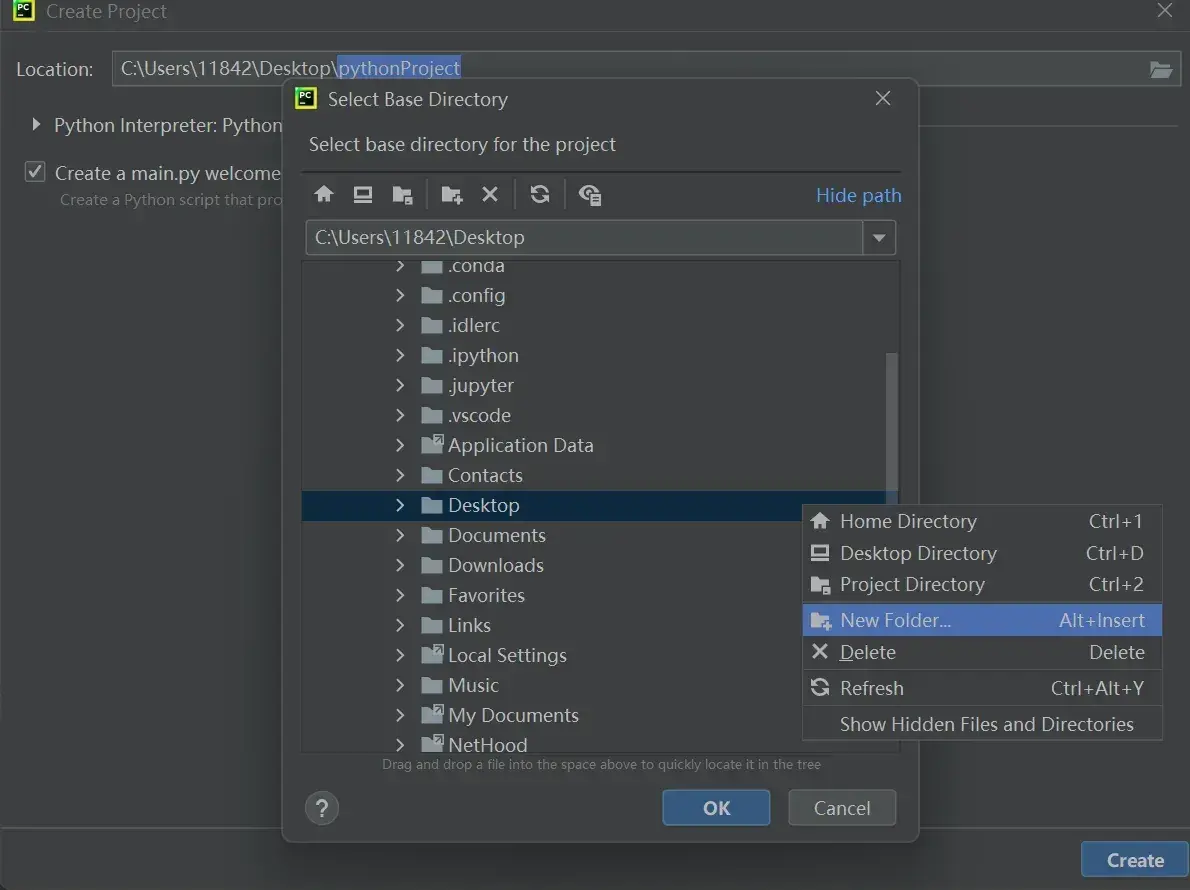
File —> Settings
(2)新建 Python文件,命名 first_demo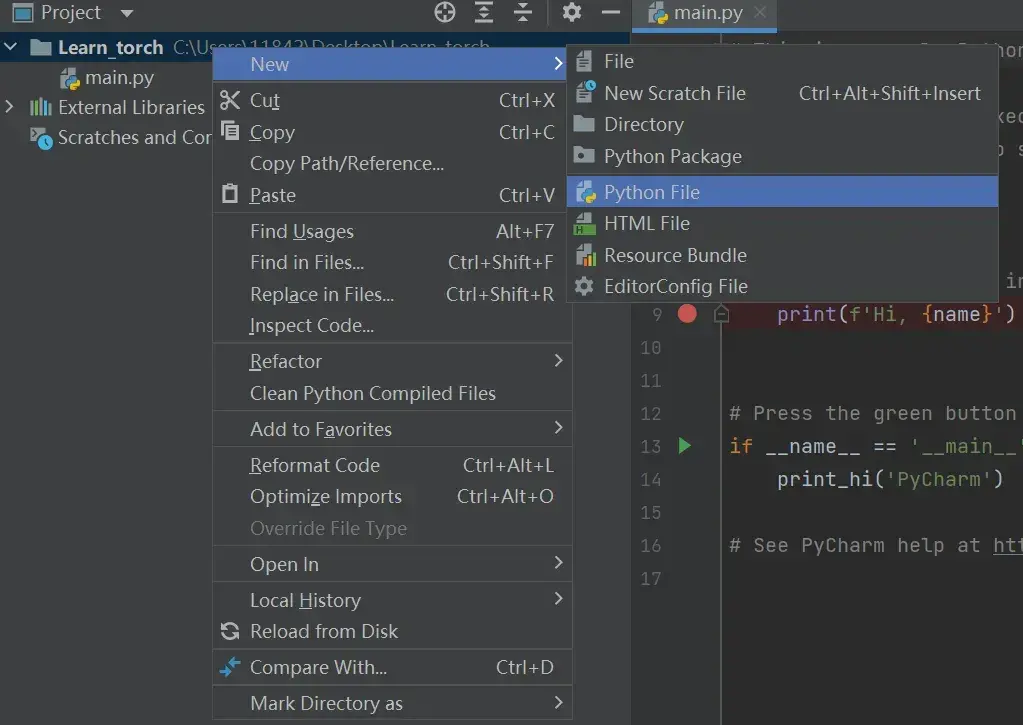
(3)运行程序:为该Python文件设置相应的Python解释器后,点击绿色的运行符号即可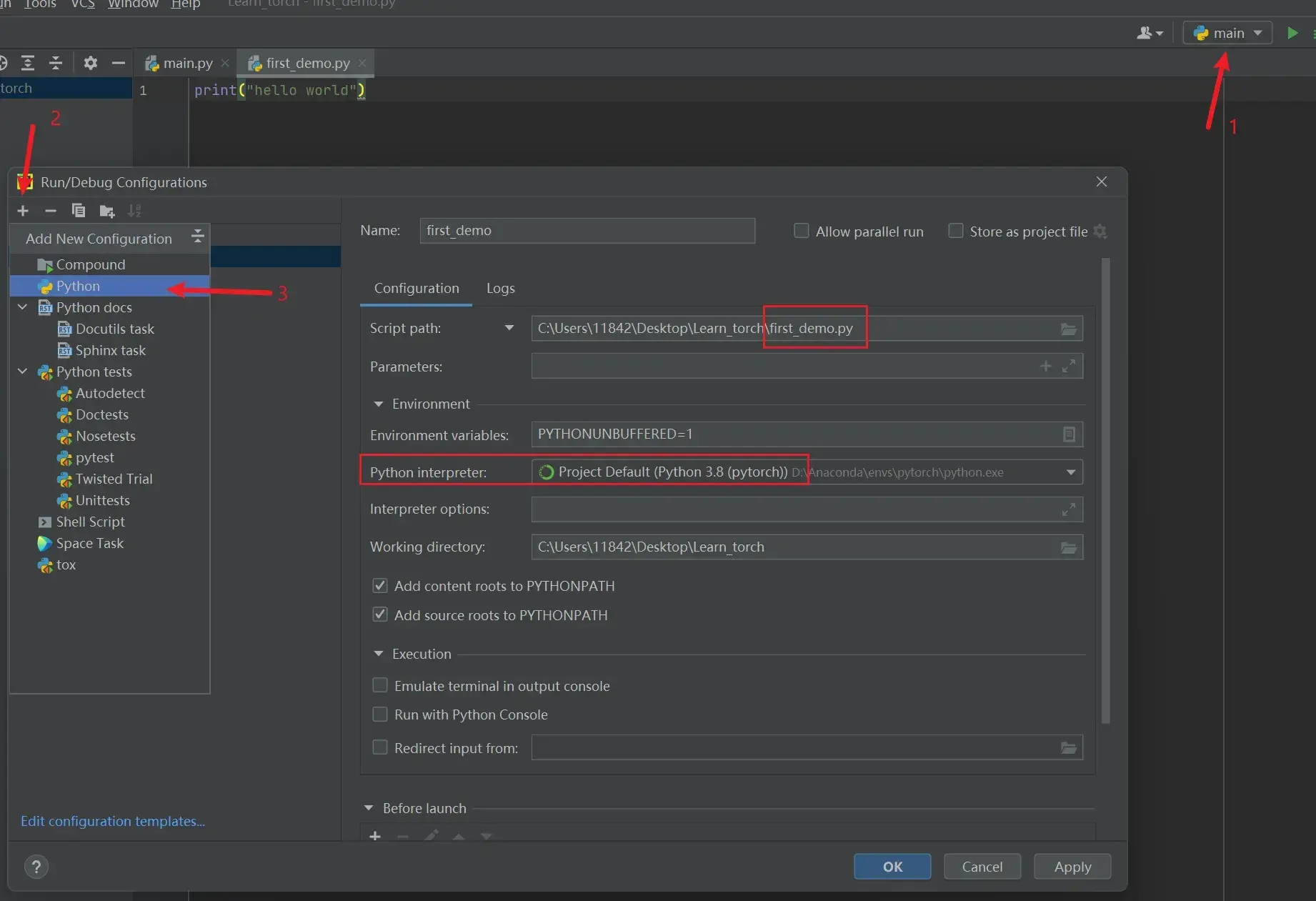
或直接右键: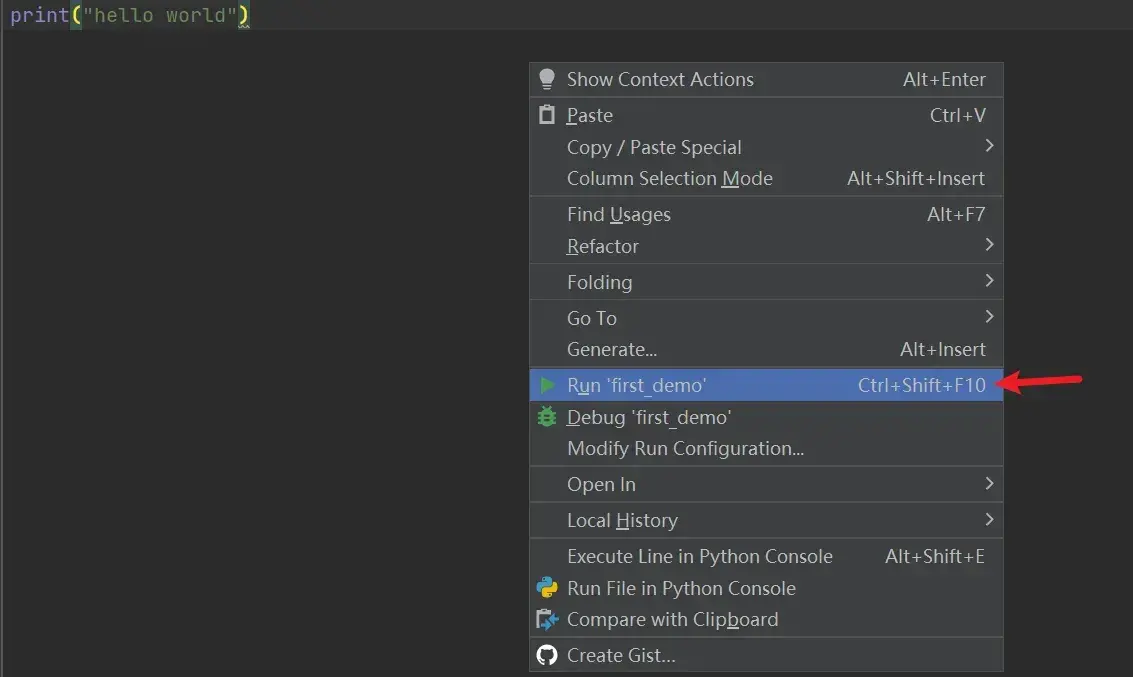
Python控制台
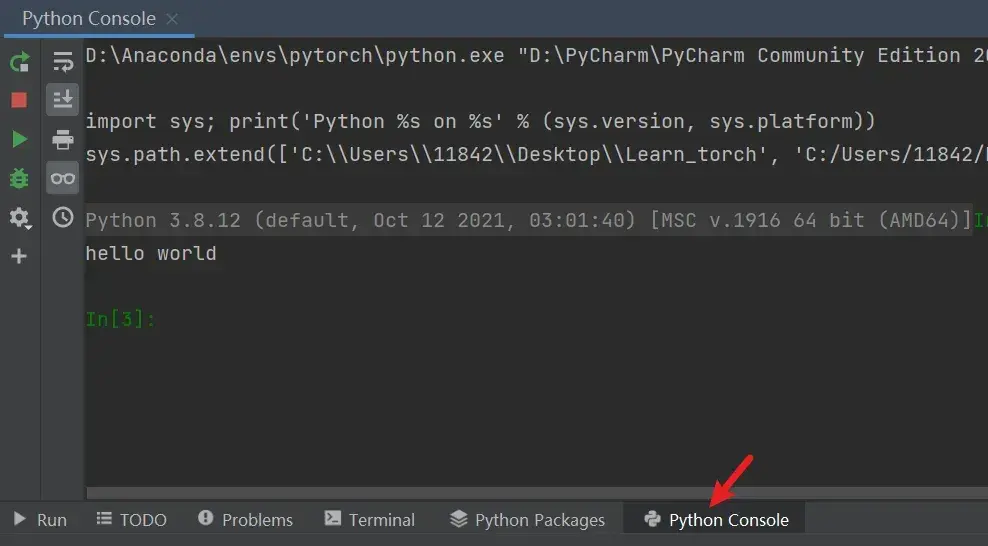
Python控制台(Python Console)是以每一行作为一个块进行执行
———————————————————————————————————————————
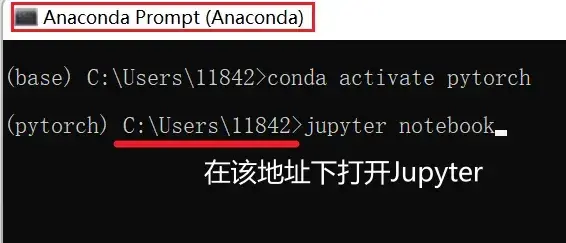
如何在Jupyter中新建项目?
首先在开始菜单打开anaconda的命令行,进入pytorch的conda环境,再打开Jupyter
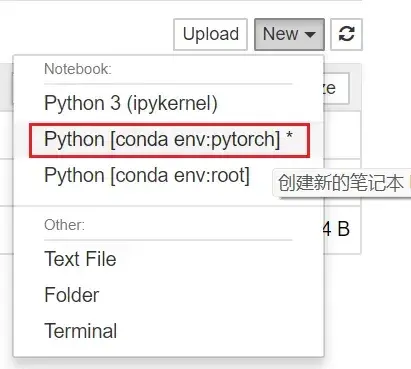
以每一个块为一个运行整体
———————————————————————————————————————————
三种运行方式(PyCharm、PyCharm的Python控制台、Jupyter Notebook)的适用场景:
代码是以块为一个整体运行的话,Python文件的块是所有行的代码,即在PyCharm运行时出现错误时,修改后要从头开始运行
PyCharm的Python控制台是一行一行代码运行的,即以每一行为一个块来运行的(也可以以任意行为块运行,按Shift+回车,输入下一行代码,再按回车运行)
- 优点:Python控制台可以看到每个变量的属性
- 缺点:出现错误后代码的可阅读性大大降低
- 一般调试时使用
Jupyter以任意行为块运行
Python控制台和Jupyter的好处是:某一块发生错误时,修改这一块时不会影响前面已经运行的块
| PyCharm | 从头开始运行 | 通用,传播方便,适用于大型项目 | 需要从头运行 |
| PyCharm的Python控制台 | 一行一行运行(也可以以任意行) | 可以显示每个变量的属性,一般调试时使用 | 出错时会破坏整体阅读性,不利于代码阅读及修改 |
| Jupyter Notebook | 以任意行为块运行 | 代码阅读性较高,利于代码的阅读及修改 | 环境需要配置 |
5. PyTorch加载数据初认识
对于神经网络训练,要从数据海洋里找到有用的数据
PyTorch 读取数据涉及两个类:Dataset & Dataloader
Dataset:提供一种方式,获取其中需要的数据及其对应的真实的 label 值,并完成编号。主要实现以下两个功能:
- 如何获取每一个数据及其label
- 告诉我们总共有多少的数据
Dataloader:打包(batch_size),为后面的神经网络提供不同的数据形式
———————————————————————————————————————————
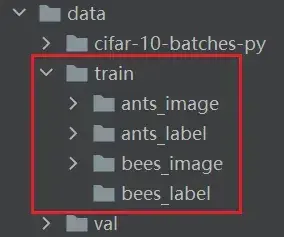
数据集的几种组织形式
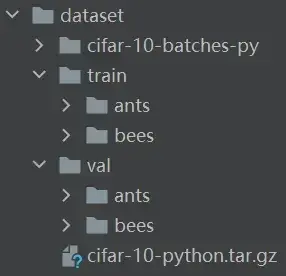
数据集 hymenoptera_data(识别蚂蚁和蜜蜂的数据集,二分类)
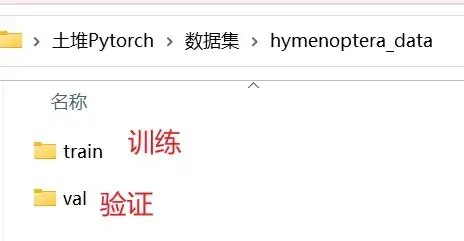
- train 里有两个文件夹:ants 和 bees,其中分别都是一些蚂蚁和蜜蜂的图片
- train_images是一个文件夹,train_labels是另一个文件夹,如OCR数据集
- label直接为图片的名称
———————————————————————————————————————————
Dataset类
from torch.utils.data import Dataset查看Dataset类的介绍:
help(Dataset)或者:
Dataset??Dataset 是一个抽象类,所有数据集都需要继承这个类,所有子类都需要重写 __getitem__ 的方法,这个方法主要是获取每个数据集及其对应 label,还可以重写长度类 __len__
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])6. Dataset类代码实战
两种方法读图片
# 法1
from PIL import Image
img_path = "xxx"
img = Image.open(img_path)
img.show()
# 法2:利用opencv读取图片,获得numpy型图片数据
import cv2
cv_img=cv2.imread(img_path)安装opencv:
在 PyCharm的 Terminal 里输入(关闭代理服务器!!!)
pip install opencv-python再
import cv2———————————————————————————————————————————
控制台读取&可视化图片
(一)数据格式1
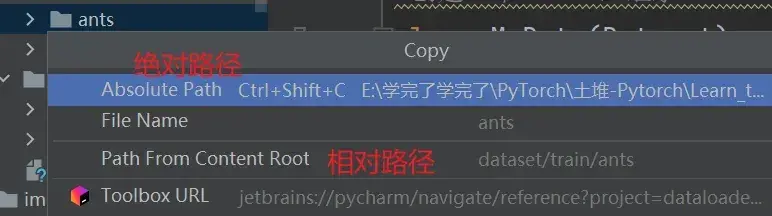
- 绝对路径:E:\学完了学完了\PyTorch\土堆-Pytorch\Learn_torch\dataset\train\ants
- 相对路径:dataset/train/ants
注意,路径引号前加 r 可以防止转义,或使用双斜杠
在Python控制台读取数据,可以看到图片的属性:
from PIL import Image
img_path = r"E:\学完了学完了\PyTorch\土堆-Pytorch\Learn_torch\dataset\train\ants\0013035.jpg"
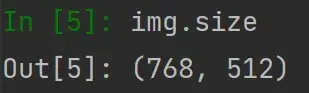
img = Image.open(img_path) 
输入 img.size 就可以返回属性的数值
可视化图片输入:img.show()

———————————————————————————————————————————
读数据
想要获取图片地址(通过索引),需要os库
import os
dir_path = "dataset/train/ants"
img_path_list = os.listdir(dir_path) # 将文件夹下的东西变成一个列表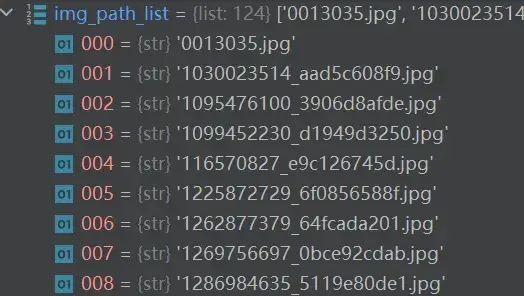
import os
root_dir = "dataset/train"
label_dir = "ants"
path = os.path.join(root_dir, label_dir) # 把两个路径拼接在一起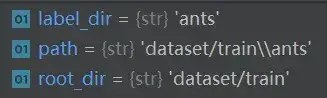
完整代码:
from torch.utils.data import Dataset
from PIL import Image #读取图片
import os #想要获得所有图片的地址,需要导入os(系统库)
#创建一个class,继承Dataset类
class MyData(Dataset):
def __init__(self,root_dir,label_dir): #创建初始化类,即根据这个类去创建一个实例时需要运行的函数
#通过索引获取图片的地址,需要先创建图片地址的list
#self可以把其指定的变量给后面的函数使用,相当于为整个class提供全局变量
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path) #获得图片下所有的地址
def __getitem__(self, idx): #idx为编号
#获取每一个图片
img_name=self.img_path[idx] #名称
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) # 每张图片的相对路径
img=Image.open(img_item_path) #读取图片
label=self.label_dir
return img,label
def __len__(self): #数据集的长度
return len(self.img_path)
#用类创建实例
root_dir="dataset/train"
ants_label_dir="ants"
bees_label_dir="bees"
ants_dataset=MyData(root_dir,ants_label_dir)
bees_dataset=MyData(root_dir,bees_label_dir)
img, label = ants_dataset[0]
img.show() # 可视化第一张图片
#将ants(124张)和bees(121张)两个数据集进行拼接
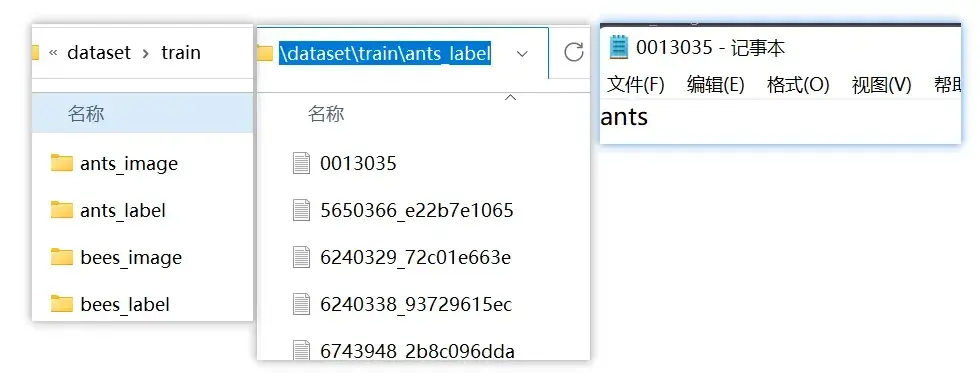
train_dataset=ants_dataset+bees_dataset(二)数据格式2
当label比较复杂,存储数据比较多时,不可能以文件夹命名的方式,而是以每张图片对应一个txt文件,txt里存储label信息的方式
rename_dataset.py代码如下: 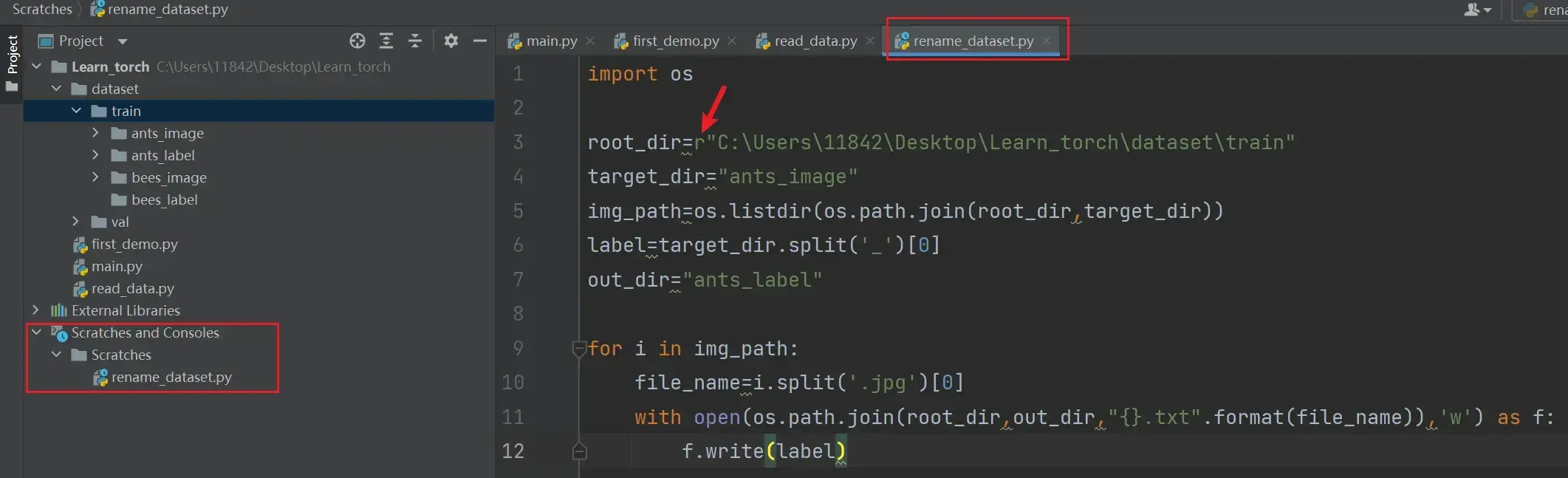
import os
root_dir=r"E:\学完了学完了\PyTorch\土堆-Pytorch\Learn_torch\dataset\train"
# 把原来的ants重命名为ants_image
target_dir="ants_image"
img_path=os.listdir(os.path.join(root_dir,target_dir))
label=target_dir.split('_')[0] # ants
out_dir="ants_label"
for i in img_path:
file_name=i.split('.jpg')[0]
with open(os.path.join(root_dir,out_dir,"{}.txt".format(file_name)),'w') as f:
f.write(label)运行效果如图:
7. TensorBoard的使用
- 安装
- add_scalar() 的使用(常用来绘制 train/val loss)
- add_image() 的使用(常用来观察训练结果)
transforms 在 Dataset 类中很常用,对图像进行变换,如图像要统一到某一个尺寸,或图像中的每一个数据进行类的转换
学 TensorBoard 探究:
- 训练过程中loss是如何变化的
- 模型在不同阶段的输出
———————————————————————————————————————————
SummaryWriter类
from torch.utils.tensorboard import SummaryWriter查看一个类如何使用:在PyCharm中,按住Ctrl键,把鼠标移到类上
是一个直接向 log_dir 文件夹写入的事件文件,可以被 TensorBoard 进行解析
初始化函数:
def __init__(self, log_dir=None):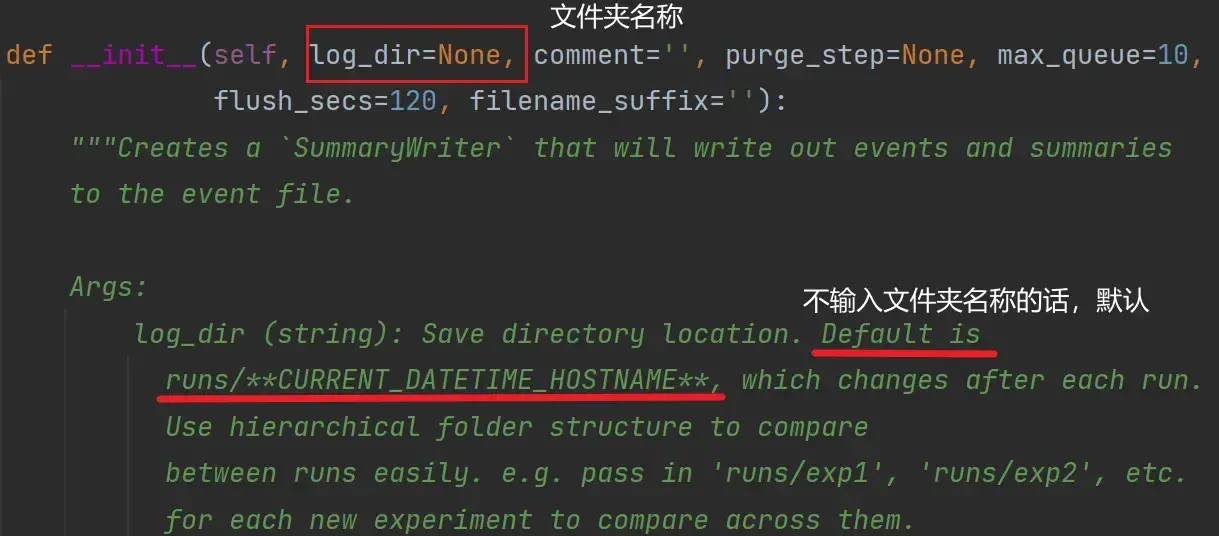
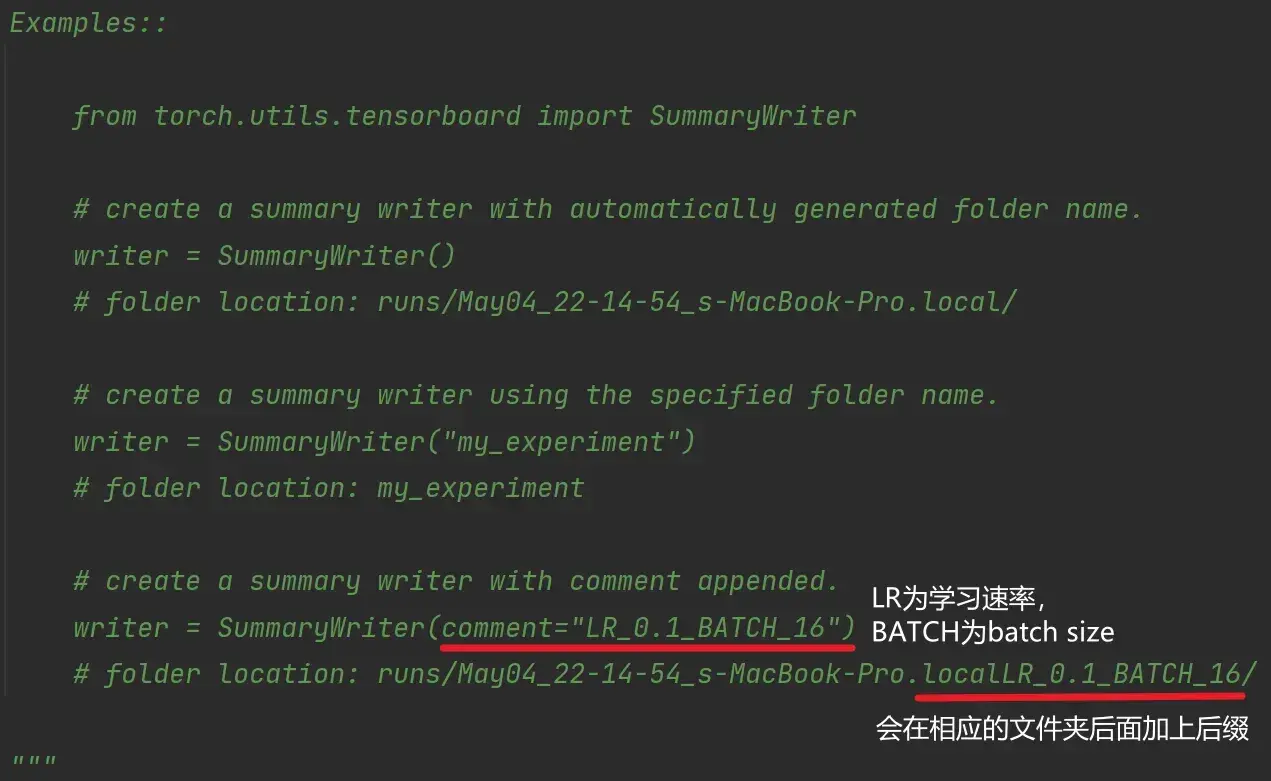
# 实例化SummaryWriter类
writer = SummaryWriter("logs") # 把对应的事件文件存储到logs文件夹下主要用到两个方法:
writer.add_image()
writer.add_scalar()
writer.close()———————————————————————————————————————————
安装TensorBoard
在 Anaconda 命令行中激活 pytorch 环境,或直接在 PyCharm 的 Terminal 的 pytorch 环境中安装
输入:
pip install tensorboard即可安装成功
———————————————————————————————————————————
Ctrl + / 注释
add_scalar() 方法的使用
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):添加一个标量数据到 Summary 当中,需要参数
- tag:Data指定方式,类似于图表的title
- scalar_value:需要保存的数值(y轴)
- global_step:训练到多少步(x轴)
例:y=x
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
#两个方法
# writer.add_image()
# y=x
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()运行后多了一个logs文件夹,下面是TensorBoard的一些事件文件,如图:
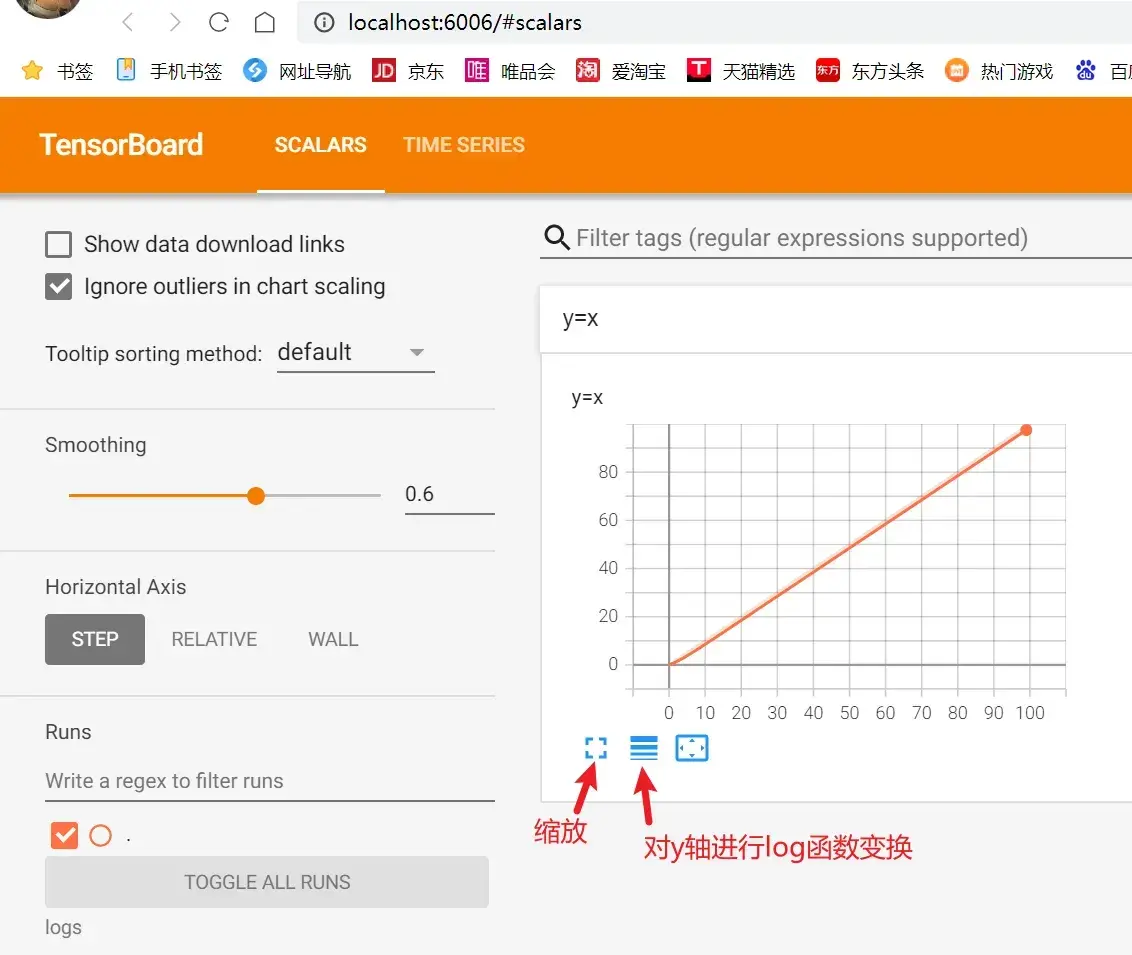
如何打开事件文件?
在 Terminal 里输入:
tensorboard --logdir=logs # logdir=事件文件所在文件夹名结果如图:

为了防止和别人冲突(一台服务器上有好几个人训练,默认打开的都是6006端口),也可以指定端口,命令如下:
tensorboard --logdir=logs --port=6007例:y=2x
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
#两个方法
# writer.add_image()
# y=2x
for i in range(100):
writer.add_scalar("y=2x",2*i,i) # 标题、y轴、x轴
writer.close() 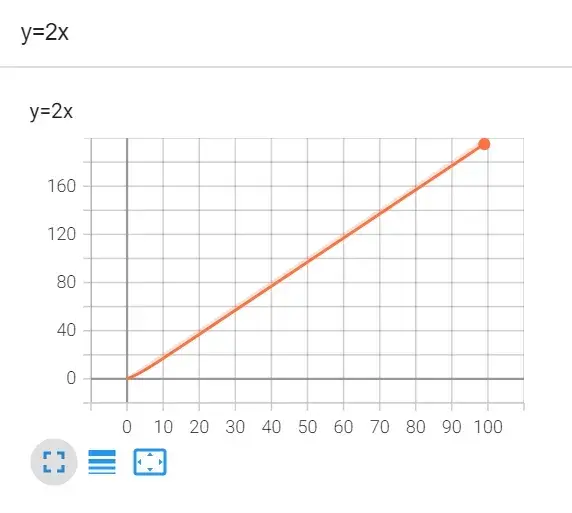
title 和 y 不一致的情况:

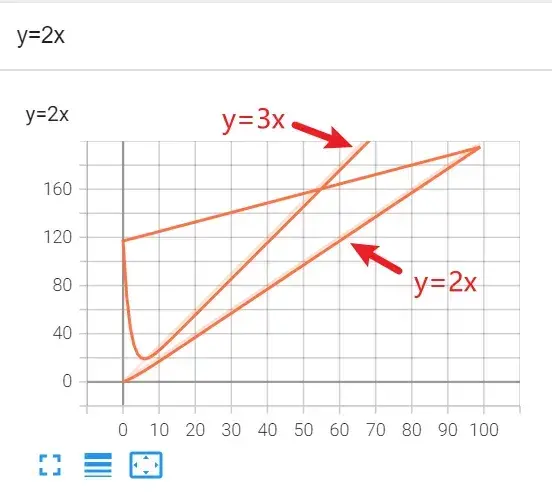
每向 writer 中写入新的事件,也记录了上一个事件
如何解决?
把logs文件夹下的所有文件删掉,程序删掉,重新开始
或:重新写一个子文件,即创建新的 SummaryWriter(“新文件夹”)
删掉logs下的文件,重新运行代码,在 Terminal 里按 Ctrl+C ,再输入命令:
tensorboard –logdir=logs –port=6007
就可以出现名字为y=2x,但实际纵坐标是y=3x数值的图像
以上即是显示 train_loss 的一个方式
———————————————————————————————————————————
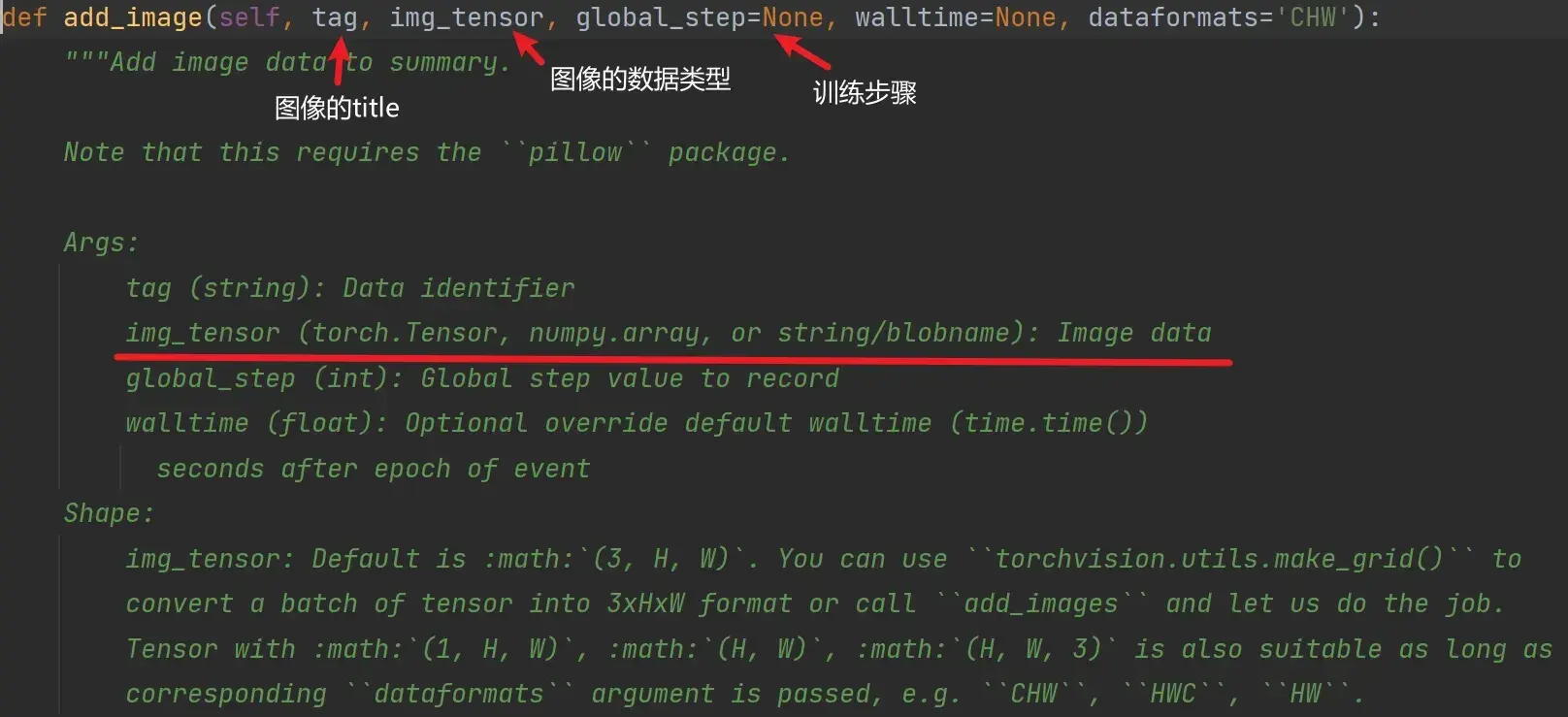
add_image() 的使用
def add_image(self, tag, img_tensor, global_step=None):- tag:对应图像的title
- img_tensor:图像的数据类型,只能是torch.Tensor、numpy.array、string/blobname
- global_step:训练步骤,int 类型

例子:
在Python控制台输入:
# 打开控制台,其位置就是项目文件夹所在的位置
# 故只需复制相对地址
image_path = "data/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(image_path)
print(type(img))———————————————————————————————————————————
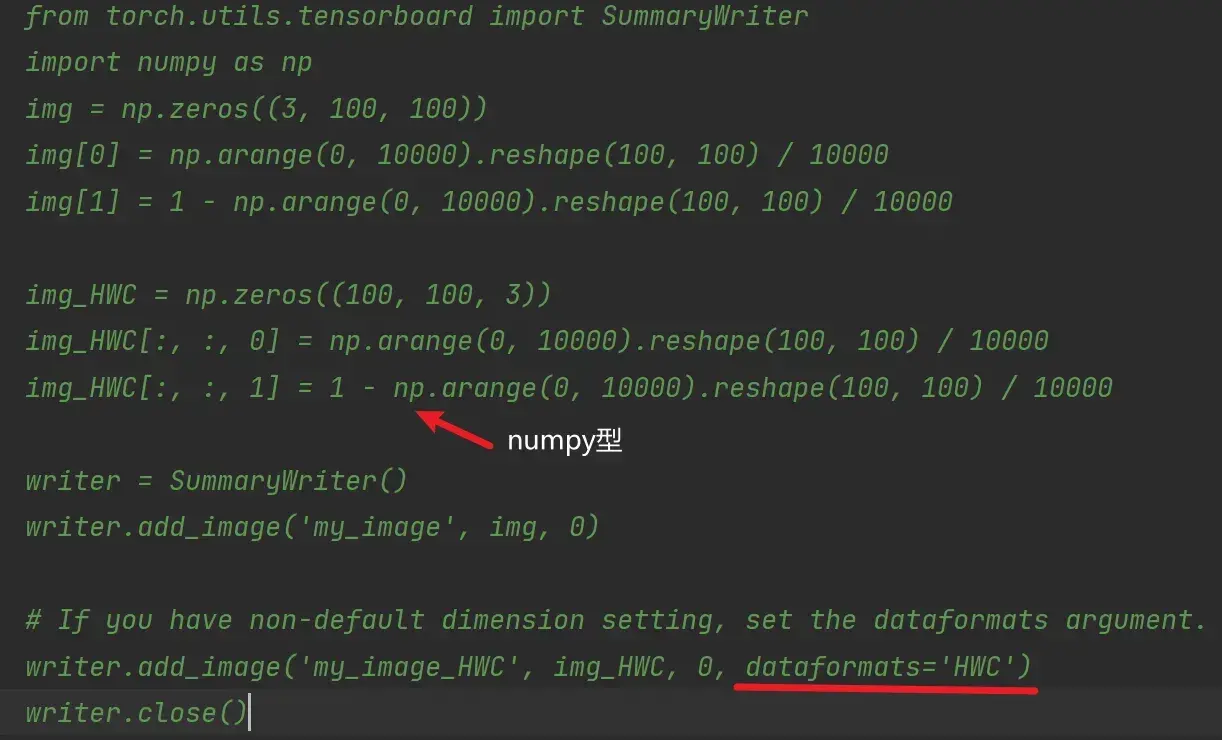
利用numpy.array(),对PIL图片进行转换
在Python控制台,把PIL类型的img变量转换为numpy类型(add_image() 函数所需要的图像的数据类型),重新赋值给img_array:
import numpy as np
img_array=np.array(img)
print(type(img_array)) # numpy.ndarray从PIL到numpy,需要在add_image()中指定shape中每一个数字/维表示的含义
step1:蚂蚁为例
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
import numpy as np
from PIL import Image
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
image_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
print(type(img_array))
print(img_array.shape) #(512,768,3) 即(H,W,C)(高度,宽度,通道)
writer.add_image("test",img_array,1, dataformats='HWC') # 第1步
writer.close()结果:
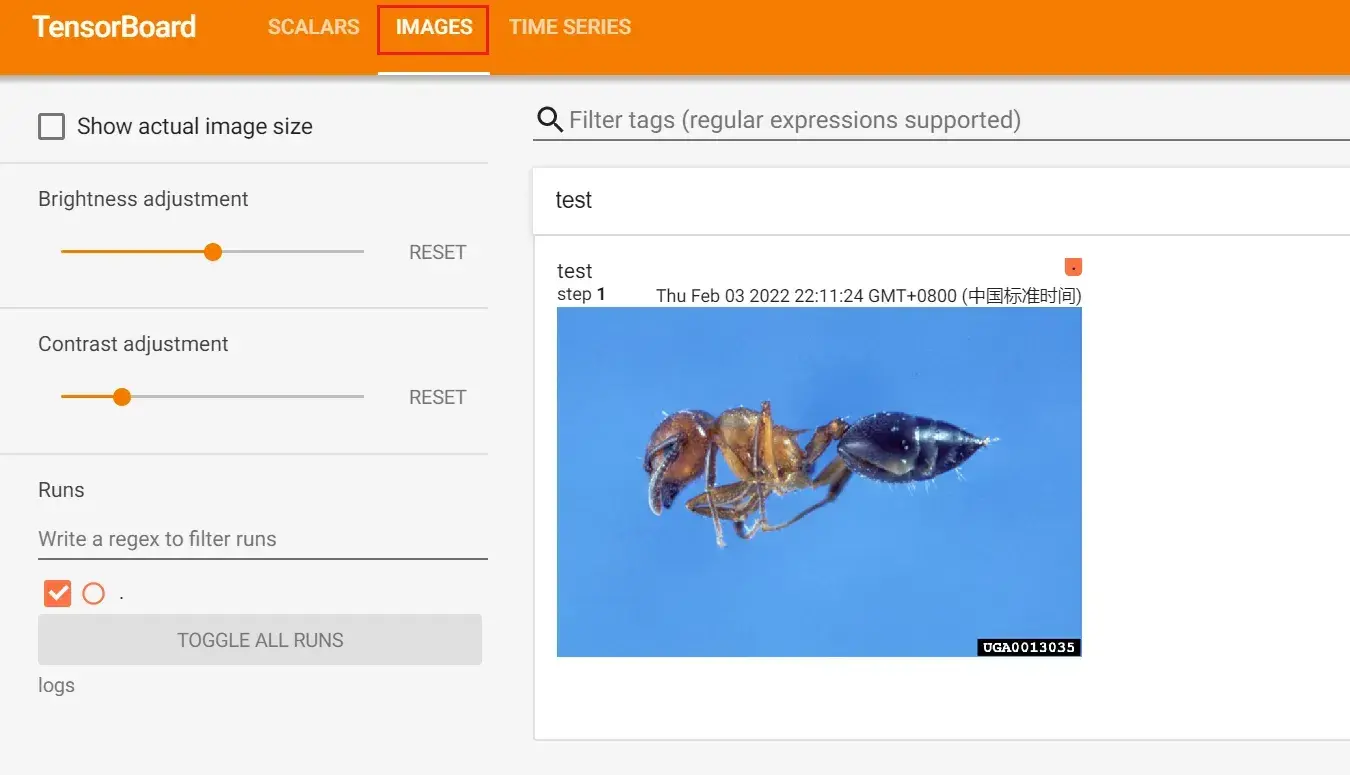
step2:蜜蜂为例
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
import numpy as np
from PIL import Image
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
image_path="data/train/bees_image/16838648_415acd9e3f.jpg"
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
print(type(img_array))
print(img_array.shape) #(512,768,3) 即(H,W,C)(高度,宽度,通道)
writer.add_image("test",img_array,2, dataformats='HWC') # 第2步
writer.close()结果:
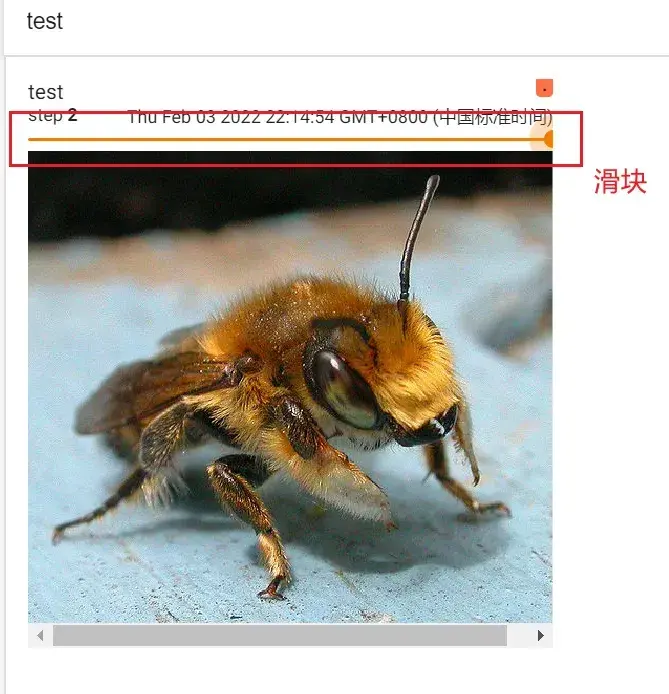
在一个title下,通过滑块显示每一步的图形,可以直观地观察训练中给model提供了哪些数据,或者想对model进行测试时,可以看到每个阶段的输出结果
如果想要单独显示,重命名一下title即可,即 writer.add_image() 的第一个字符串类型的参数
8. 图像变换,torchvision中transforms的使用
对图片进行一些变换
transforms的结构及用法
from torchvision import transforms结构
按住Ctrl,看 transforms.py文件(工具箱),它定义了很多 class文件(工具)
搜索快捷键:
File—> Settings—> Keymap—> 搜索 structure(快捷键 Alt+7)
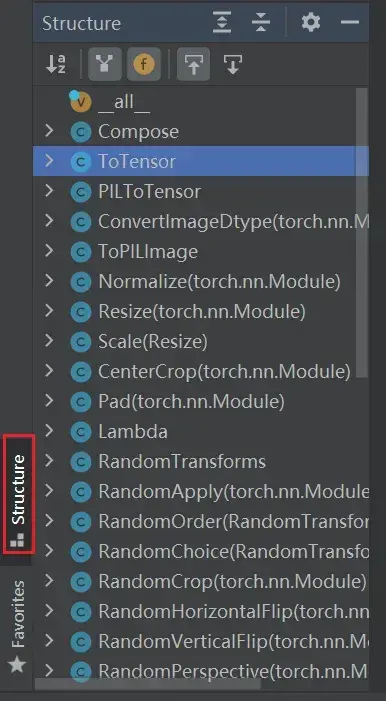
一些类
- Compose类:结合不同的transforms

图片先经过中心裁剪,再变成Tensor返回 - ToTensor类:把一个PIL的Image或者numpy数据类型的图片转换成 tensor 的数据类型
- ToPILImage类:把一个图片转换成PIL Image
- Normalize类:归一化
- Resize类:尺寸变换
- CenterCrop类:中心裁剪
使用
- transforms.py 工具箱
- totensor / resize等类 工具
拿一些特定格式的图片,经过工具(class文件)后,就会输出我们想要的图片变换的结果
———————————————————————————————————————————
两个问题
python的用法 ——> tensor数据类型
通过 transforms.ToTensor去解决两个问题
- Transforms该如何使用
- Tensor数据类型与其他图片数据类型有什么区别?为什么需要Tensor数据类型
from PIL import Image
from torchvision import transforms
# 绝对路径 C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg
# 相对路径 data/train/ants_image/0013035.jpg
img_path="data/train/ants_image/0013035.jpg" #用相对路径,绝对路径里的\在Windows系统下会被当做转义符
# img_path_abs="C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg",双引号前加r表示转义
img = Image.open(img_path) #Image是Python中内置的图片的库
print(img) # PIL类型1、transforms 该如何使用(python)
从transforms中选择一个class,对它进行创建,对创建的对象传入图片,即可返回出结果
ToTensor将一个 PIL Image 或 numpy.ndarray 转换为 tensor的数据类型
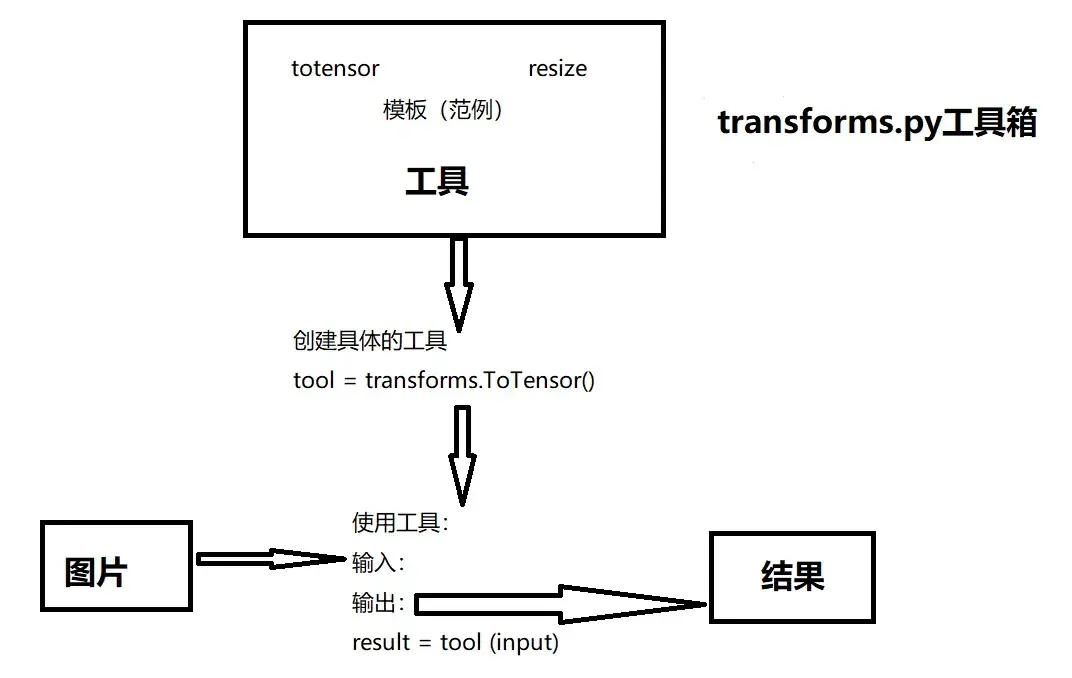
# 1、Transforms该如何使用
tensor_trans = transforms.ToTensor() #从工具箱transforms里取出ToTensor类,返回tensor_trans对象
tensor_img=tensor_trans(img) #创建出tensor_trans后,传入其需要的参数,即可返回结果
print(tensor_img)Ctrl+P可以提示函数里需要填什么参数
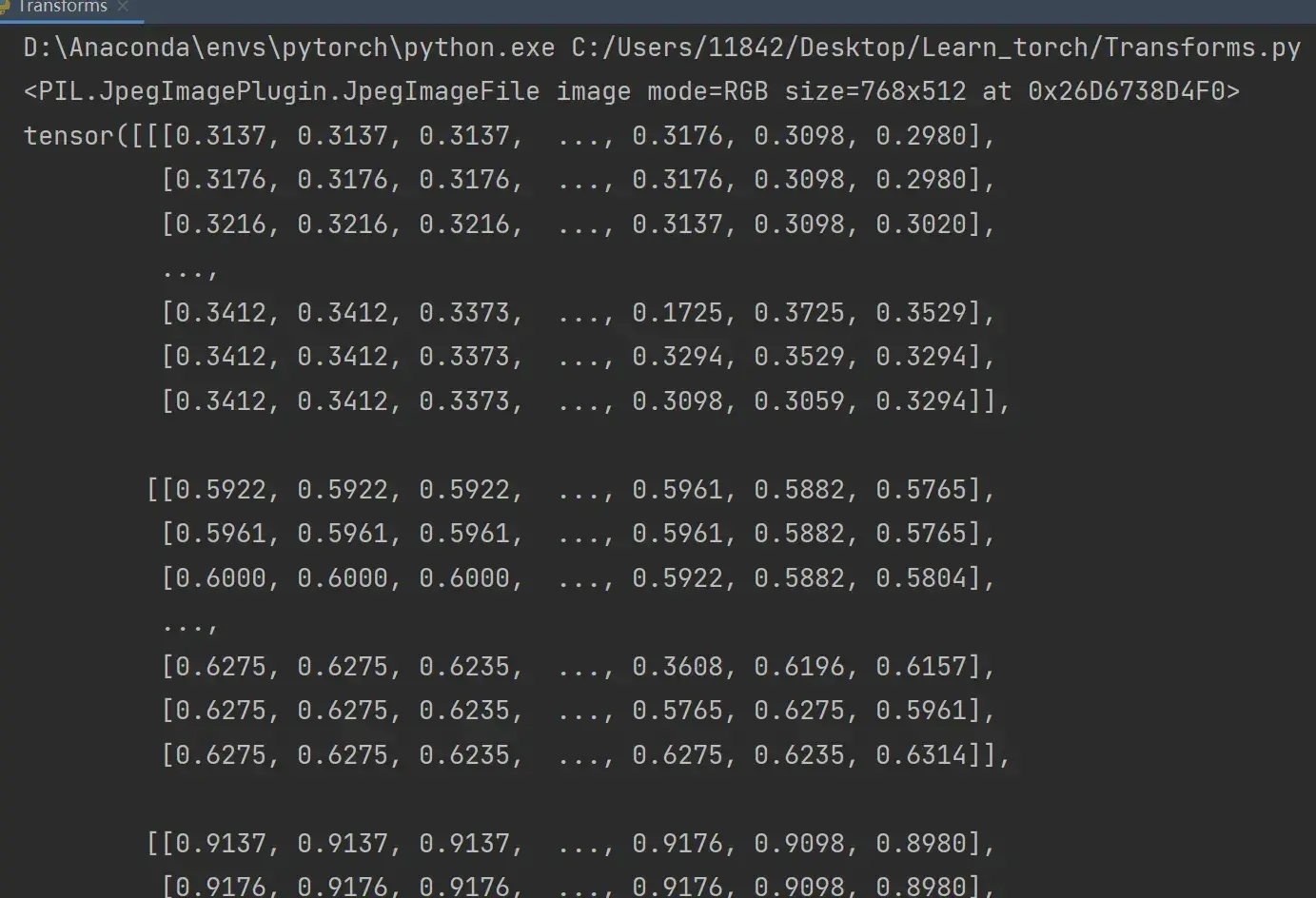
2、为什么我们需要 Tensor 数据类型
在Python Console输入:
from PIL import Image
from torchvision import transforms
img_path= "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) 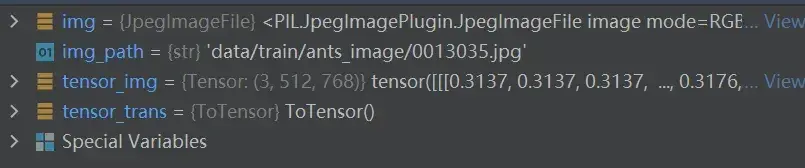
打开img,即用Python内置的函数读取的图片,具有的参数有:
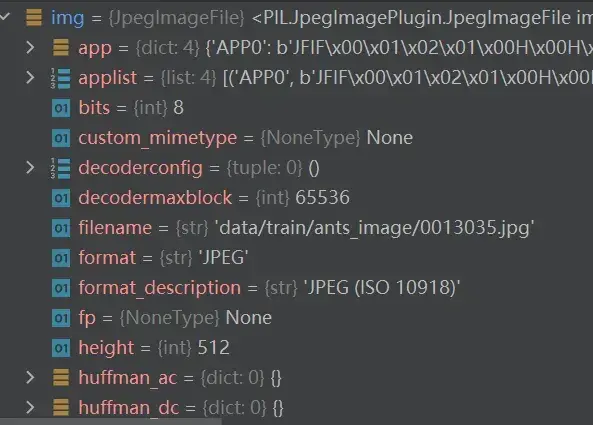
再打开tensor_img,看一下它有哪些参数:
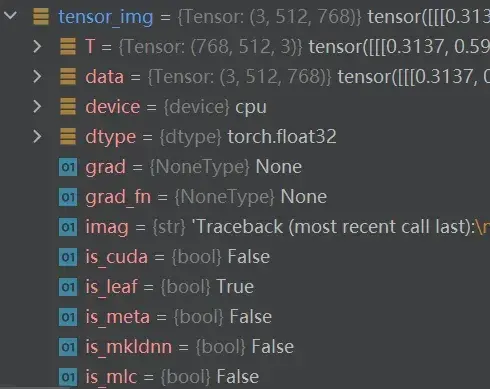
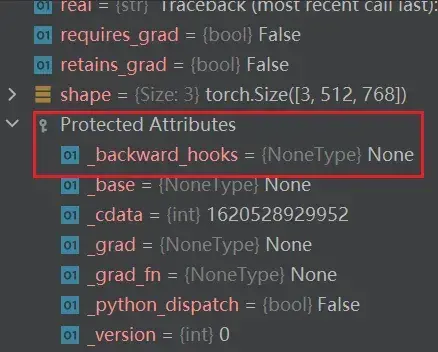
Tensor 数据类型包装了反向神经网络所需要的一些理论基础的参数,如:_backward_hooks、_grad等(先转换成Tensor数据类型,再训练)
———————————————————————————————————————————
两种读取图片的方式
- PIL Image
from PIL import Image img_path = "xxx" img = Image.open(img_path) img.show() - numpy.ndarray(通过opencv)
import cv2 cv_img=cv2.imread(img_path)
上节课以 numpy.array 类型为例,这节课使用 torch.Tensor 类型:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python的用法 ——> tensor数据类型
# 通过 transforms.ToTensor去解决两个问题
# 1、Transforms该如何使用
# 2、Tensor数据类型与其他图片数据类型有什么区别?为什么需要Tensor数据类型
# 绝对路径 C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg
# 相对路径 data/train/ants_image/0013035.jpg
img_path="data/train/ants_image/0013035.jpg" #用相对路径,绝对路径里的\在Windows系统下会被当做转义符
# img_path_abs="C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg",双引号前加r表示转义
img = Image.open(img_path) #Image是Python中内置的图片的库
#print(img)
writer = SummaryWriter("logs")
# 1、Transforms该如何使用
tensor_trans = transforms.ToTensor() #从工具箱transforms里取出ToTensor类,返回tensor_trans对象
tensor_img = tensor_trans(img) #创建出tensor_trans后,传入其需要的参数,即可返回结果
#print(tensor_img)
writer.add_image("Tensor_img",tensor_img) # .add_image(tag, img_tensor, global_step)
# tag即名称
# img_tensor的类型为torch.Tensor/numpy.array/string/blobname
# global_step为int类型
writer.close()运行后,在 Terminal 里输入:
tensorboard --logdir=logs
进入网址后可以看到图片:
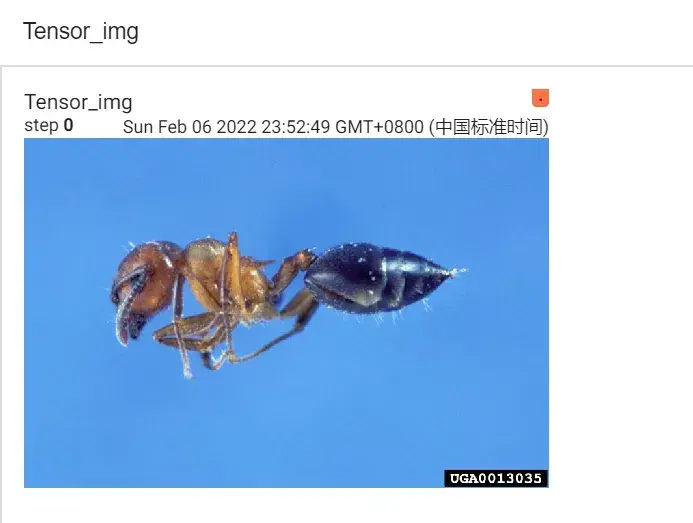
9. 常见的Transforms的使用
- 输入
- 输出
- 作用
图片有不同的格式,打开方式也不同
| 图片格式 | 打开方式 |
| PIL | Image.open() ——Python自带的图片打开方式 |
| tensor | ToTensor() |
| narrays | cv.imread() ——Opencv |
———————————————————————————————————————————
Compose 的使用
把不同的 transforms 结合在一起,后面接一个数组,里面是不同的transforms
Example:图片首先要经过中心裁剪,再转换成Tensor数据类型
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])———————————————————————————————————————————
Python中 __call__ 的用法
内置函数 __call__ ,不用.的方式调用方法,可以直接拿对象名,加上需要的参数,即可调用方法
按 Ctrl+p,会提示需要什么参数
class Person:
def __call__(self, name): #下划线__表示为内置函数
print("__call__"+"Hello "+name)
def hello(self,name):
print("hello"+name)
person = Person()
person("zhangsan")
person.hello("lisi")输出结果如下:
__call__Hello zhangsan
hellolisi———————————————————————————————————————————
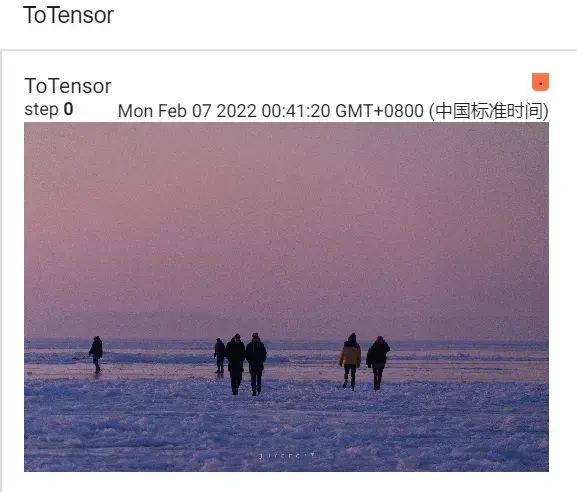
ToTensor 的使用
把 PIL Image 或 numpy.ndarray 类型转换为 tensor 类型(TensorBoard 必须是 tensor 的数据类型)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img=Image.open("images/people.jpg")
print(img) #可以看到类型是PIL
#ToTensor的使用
trans_totensor = transforms.ToTensor() #将类型转换为tensor
img_tensor = trans_totensor(img) #img变为tensor类型后,就可以放入TensorBoard当中
writer.add_image("ToTensor",img_tensor)
writer.close()(运行前要先把之前的logs进行删除)运行后,在 Terminal 里输入:
tensorboard --logdir=logs
进入网址后可以看到图片:
———————————————————————————————————————————
ToPILImage 的使用
把 tensor 数据类型或 ndarray 类型转换成 PIL Image
———————————————————————————————————————————
Normalize 的使用
用平均值/标准差归一化 tensor 类型的 image(输入)
图片RGB三个信道,将每个信道中的输入进行归一化
output[channel] = (input[channel] - mean[channel]) / std[channel]设置 mean 和 std 都为0.5,则 output= 2*input -1。如果 input 图片像素值为0~1范围内,那么结果就是 -1~1之间
#Normalize的使用
print(img_tensor[0][0][0]) # 第0层第0行第0列
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) # mean,std,因为图片是RGB三信道,故传入三个数
img_norm = trans_norm(img_tensor) # 输入的类型要是tensor
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)输出结果:
tensor(0.6549)
tensor(0.3098)刷新网页:

加入step值:
#Normalize的使用
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([6,3,2],[9,3,5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,2) # 第二步
writer.close()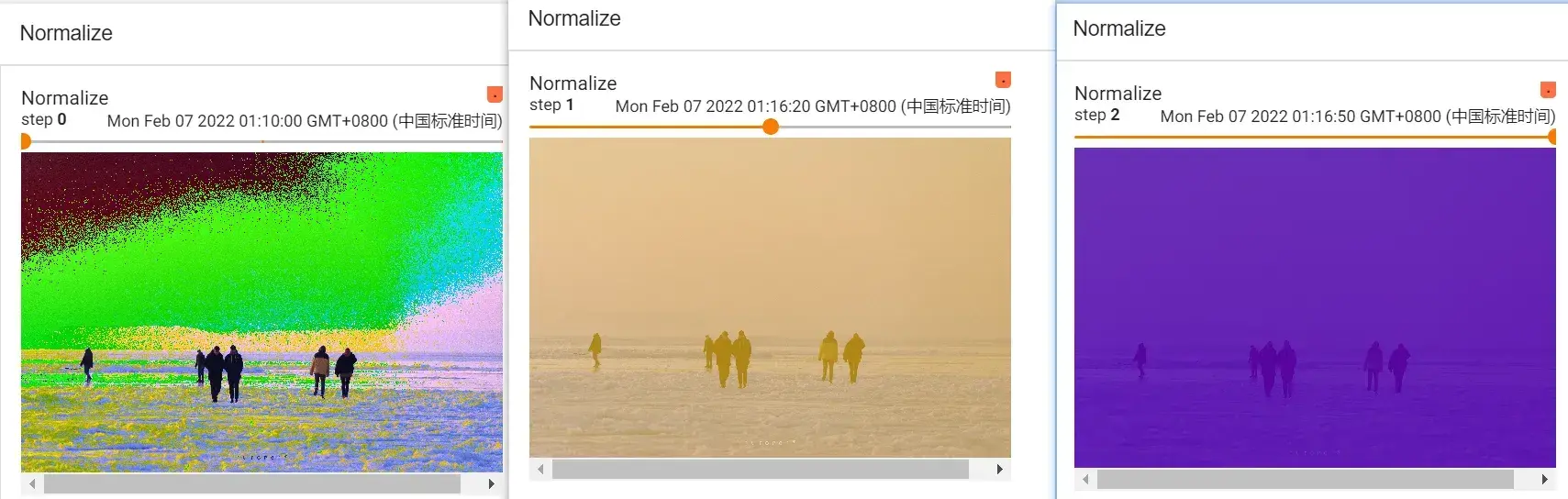
———————————————————————————————————————————
Resize() 的使用
输入:PIL Image 将输入转变到给定尺寸
- 序列:(h,w)高度,宽度
- 一个整数:不改变高和宽的比例,只单纯改变最小边和最长边之间的大小关系。之前图里最小的边将会匹配这个数(等比缩放)
PyCharm小技巧设置:忽略大小写,进行提示匹配
- 一般情况下,你需要输入R,才能提示出Resize
- 我们想设置,即便你输入的是r,也能提示出Resize,也就是忽略了大小写进行匹配提示
File—> Settings—> 搜索case—> Editor-General-Code Completion-去掉Match case前的√
—>Apply—>OK
返回值还是 PIL Image
#Resize的使用
print(img.size) # 输入是PIL.Image
trans_resize = transforms.Resize((512,512))
#img:PIL --> resize --> img_resize:PIL
img_resize = trans_resize(img) #输出还是PIL Image
#img_resize:PIL --> totensor --> img_resize:tensor(同名,覆盖)
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
———————————————————————————————————————————
Compose() 的使用
Compose() 中的参数需要是一个列表,Python中列表的表示形式为[数据1,数据2,…]
在Compose中,数据需要是transforms类型,所以得到Compose([transforms参数1,transforms参数2,…])
#Compose的使用(将输出类型从PIL变为tensor类型,第二种方法)
trans_resize_2 = transforms.Resize(512) # 将图片短边缩放至512,长宽比保持不变
# PIL --> resize --> PIL --> totensor --> tensor
#compose()就是把两个参数功能整合,第一个参数是改变图像大小,第二个参数是转换类型,前者的输出类型与后者的输入类型必须匹配
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img) # 输入需要是PIL Image
writer.add_image("Resize",img_resize_2,1)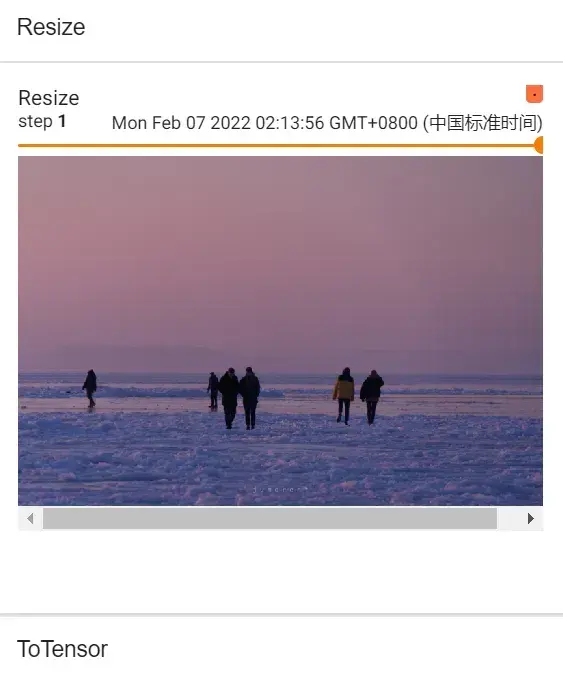
———————————————————————————————————————————
RandomCrop() 的使用
随机裁剪,输入PIL Image
参数size:
- sequence:(h,w) 高,宽
- int:裁剪一个该整数×该整数的图像
(1)以 int 为例:
#RandomCrop()的使用
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10): #裁剪10个
img_crop = trans_compose_2(img) # 输入需要是PIL Image
writer.add_image("RandomCrop",img_crop,i)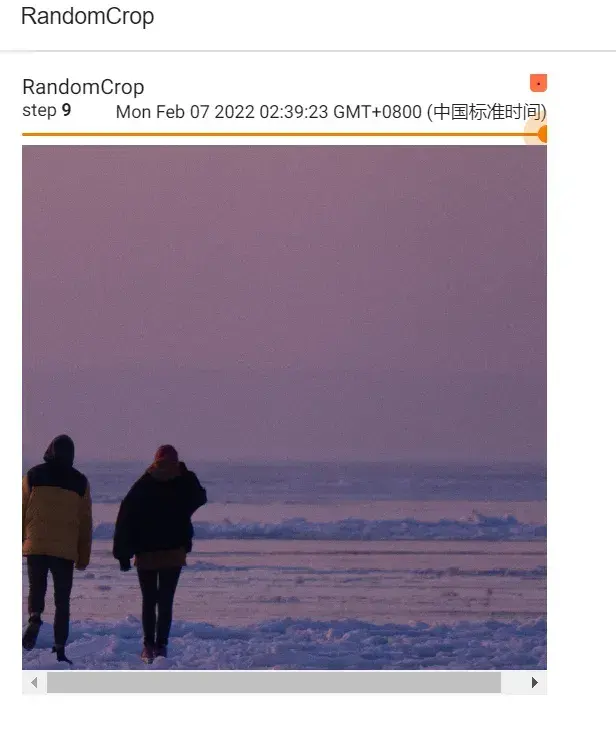
(2)以 sequence 为例:
#RandomCrop()的使用
trans_random = transforms.RandomCrop((500,1000))
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10): #裁剪10个
img_crop = trans_compose_2(img)
writer.add_image("RandomCropHW",img_crop,i) 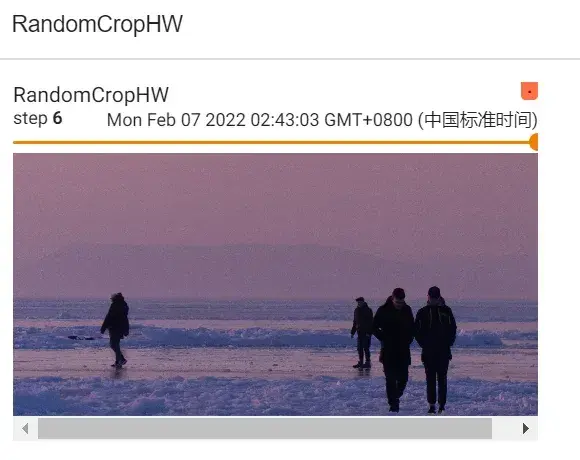
———————————————————————————————————————————
总结使用方法
- 关注输入和输出类型
- 多看官方文档
- 关注方法需要什么参数:参数如果设置了默认值,保留默认值即可,没有默认值的需要指定(看一下要求传入什么类型的参数)
- 不知道变量的输出类型可以
- 直接print该变量
- print(type()),看结果里显示什么类型
- 断点调试 dubug
- 最后要 totensor,在 tensorboard 看一下结果(tensorboard需要tensor数据类型进行显示)
10. torchvision 中的数据集使用
- 如何把数据集(多张图片)和 transforms 结合在一起
- 标准数据集如何下载、查看、使用
torchvision — Torchvision 0.11.0 documentation
如:COCO 目标检测、语义分割;MNIST 手写文字;CIFAR 物体识别
输入输出模块,不常用
提供一些比较常见的神经网络,有的已经预训练好,如分类、语义分割、目标检测、视频分类
torchvision提供的一些比较少见的特殊的操作,不常用
提供一些常用的小工具,如TensorBoard
———————————————————————————————————————————
本节主要讲解torchvision.datasets,以及它如何跟transforms联合使用
CIFAR10数据集

CIFAR10 数据集包含了6万张32×32像素的彩色图片,图片有10个类别,每个类别有6千张图像,其中有5万张图像为训练图片,1万张为测试图片

标准数据集如何下载、查看、使用
#如何使用torchvision提供的标准数据集
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0]) # 查看测试集中的第一个数据,是一个元组:(img, target)
print(test_set.classes) # 列表
img,target = test_set[0]
print(img)
print(target) # 3
print(test_set.classes[target]) # cat
img.show()数据集下载过慢时:
获得下载链接后,把下载链接放到迅雷中,会首先下载压缩文件tar.gz,之后会对该压缩文件进行解压,里面会有相应的数据集
采用迅雷下载完毕后,在PyCharm里新建directory,名字也叫dataset,再将下载好的压缩包复制进去,download依然为True,运行后,会自动解压该数据
没有显示下载地址时:
按住Ctrl键,查看数据集的源代码,若其中有 url地址,可直接复制到迅雷中进行下载
——————————————————————————————————————————–
如何把数据集(多张图片)和 transforms 结合在一起
CIFAR10数据集原始图片是PIL Image,如果要给pytorch使用,需要转为tensor数据类型(转成tensor后,就可以用tensorboard了)
transforms 更多地是用在 datasets 里 transform 的选项中
import torchvision
from torch.utils.tensorboard import SummaryWriter
#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
writer = SummaryWriter("p10")
#显示测试数据集中的前10张图片
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i) # img已经转成了tensor类型
writer.close()运行后在 terminal 里输入
tensorboard --logdir="p10"
11. DataLoader 的使用
- dataset:告诉程序中数据集的位置,数据集中索引,数据集中有多少数据(想象成一叠扑克牌)
- dataloader:将数据加载到神经网络中,每次从dataset中取数据,通过dataloader中的参数可以设置如何取数据(想象成抓的一组牌)
torch.utils.data — PyTorch 1.10 documentation
参数介绍
参数如下(大部分有默认值,实际中只需要设置少量的参数即可):
- dataset:只有dataset没有默认值,只需要将之前自定义的dataset实例化,再放到dataloader中即可

- batch_size:每次抓牌抓几张
- shuffle:打乱与否,值为True的话两次打牌时牌的顺序是不一样。默认为False,但一般用True
- num_workers:加载数据时采用单个进程还是多个进程,多进程的话速度相对较快,默认为0(主进程加载)。Windows系统下该值>0会有问题(报错提示:BrokenPipeError)
- drop_last:100张牌每次取3张,最后会余下1张,这时剩下的这张牌是舍去还是不舍去。值为True代表舍去这张牌、不取出,False代表要取出该张牌
———————————————————————————————————————————
示例
# 测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)输出结果:
torch.Size([3, 32, 32]) #三通道,32×32大小
3 #类别为3dataset
- __getitem()__:return img,target
dataloader(batch_size=4):从dataset中取4个数据
- img0,target0 = dataset[0]
- img1,target1 = dataset[1]
- img2,target2 = dataset[2]
- img3,target3 = dataset[3]
把 img 0-3 进行打包,记为imgs;target 0-3 进行打包,记为targets;作为dataloader中的返回
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)输出结果:
torch.Size([4, 3, 32, 32]) #4张图片,三通道,32×32
tensor([0, 4, 4, 8]) #4个target进行一个打包数据是随机取的(断点debug一下,可以看到采样器sampler是随机采样的),所以两次的 target 0 并不一样
———————————————————————————————————————————
batch_size
# 用上节课torchvision提供的自定义的数据集
# CIFAR10原本是PIL Image,需要转换成tensor
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#batch_size=4,意味着每次从test_data中取4个数据进行打包
writer = SummaryWriter("dataloader")
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("test_data",imgs,step)
step=step+1
writer.close()运行后在 terminal 里输入:
tensorboard --logdir="dataloader"运行结果如图,滑动滑块即是每一次取数据时的batch_size张图片:

由于 drop_last 设置为 False,所以最后16张图片(没有凑齐64张)显示如下:

———————————————————————————————————————————
drop_last
若将 drop_last 设置为 True,最后16张图片(step 156)会被舍去,结果如图:

———————————————————————————————————————————
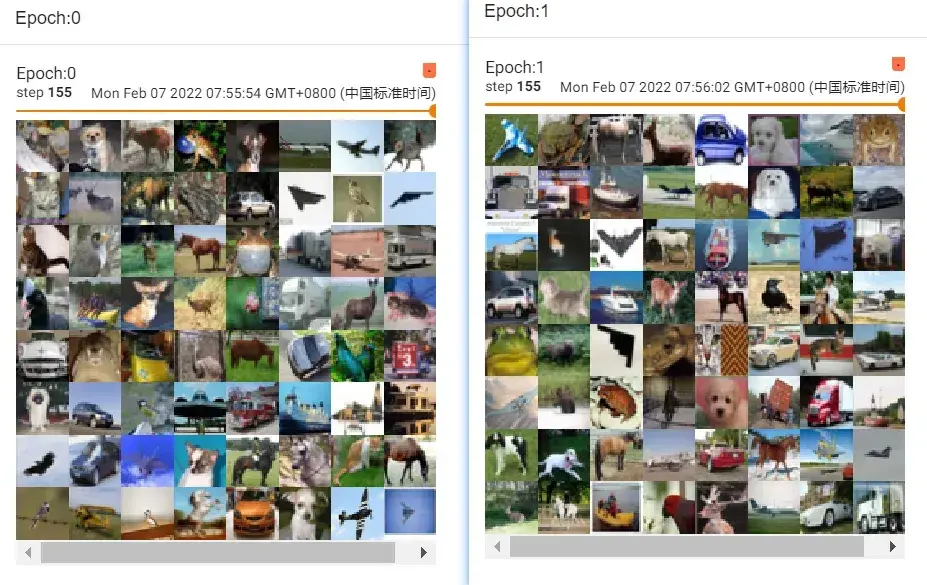
shuffle
一个 for data in test_loader 循环,就意味着打完一轮牌(抓完一轮数据),在下一轮再进行抓取时,第二次数据是否与第一次数据一样。值为True的话,会重新洗牌(一般都设置为True)
shuffle为False的话两轮取的图片是一样的
在外面再套一层 for epoch in range(2) 的循环
# shuffle为True
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step=step+1结果如下:
可以看出两次 step 155 的图片不一样
12. 神经网络的基本骨架 – nn.Module 的使用
Pytorch官网左侧:Python API(相当于package,提供了一些不同的工具)
关于神经网络的工具主要在torch.nn里
torch.nn — PyTorch 1.10 documentation

———————————————————————————————————————————
Containers
包含6个模块:
- Module
- Sequential
- ModuleList
- ModuleDict
- ParameterList
- ParameterDict
其中最常用的是 Module 模块(为所有神经网络提供基本骨架)
CLASS torch.nn.Module #搭建的 Model都必须继承该类模板:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module): #搭建的神经网络 Model继承了 Module类(父类)
def __init__(self): #初始化函数
super(Model, self).__init__() #必须要这一步,调用父类的初始化函数
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x): #前向传播(为输入和输出中间的处理过程),x为输入
x = F.relu(self.conv1(x)) #conv为卷积,relu为非线性处理
return F.relu(self.conv2(x))- 前向传播 forward(在所有子类中进行重写)
- 反向传播 backward
———————————————————————————————————————————
Code —> Generate —> Override Methods 可以自动补全代码
例子:
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
# def __init__(self):
# super(Tudui, self).__init__()
def forward(self,input):
output = input + 1
return output
tudui = Tudui() #拿Tudui模板创建出的神经网络
x = torch.tensor(1.0) #将1.0这个数转换成tensor类型
output = tudui(x)
print(output)结果如下:
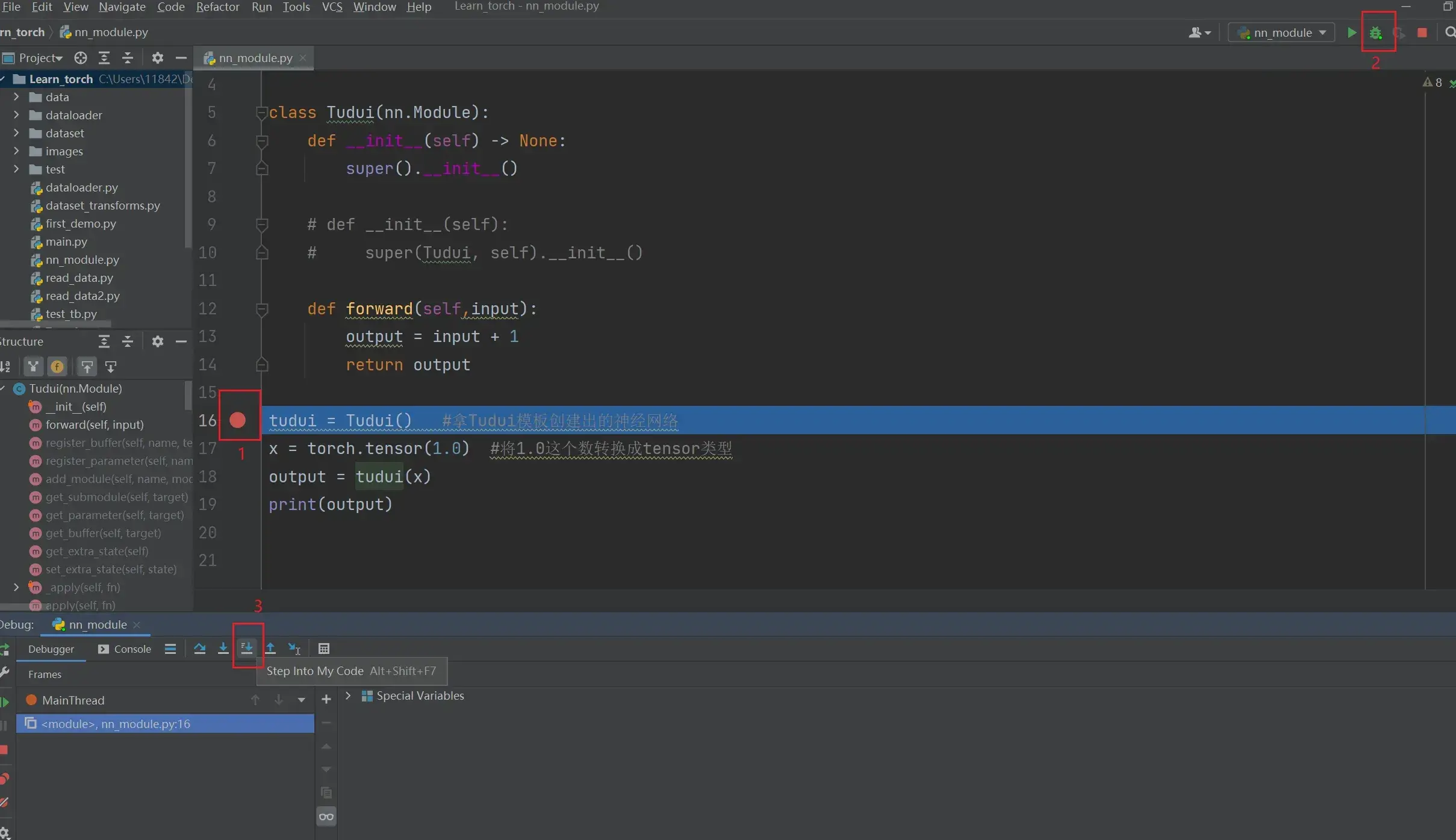
tensor(2.)debug看流程
在下列语句前打断点:
tudui = Tudui() #整个程序的开始然后点击蜘蛛,点击 Step into My Code,可以看到代码每一步的执行过程
13. 土堆说卷积操作
torch.nn — PyTorch 1.10 documentation
Convolution Layers
Conv2d — PyTorch 1.10 documentation
torch.nn 和 torch.nn.functional 的区别:前者是后者的封装,更利于使用
点击 torch.nn.functional – Convolution functions – conv2d

stride(步进)
可以是单个数,或元组(sH,sW) — 控制横向步进和纵向步进
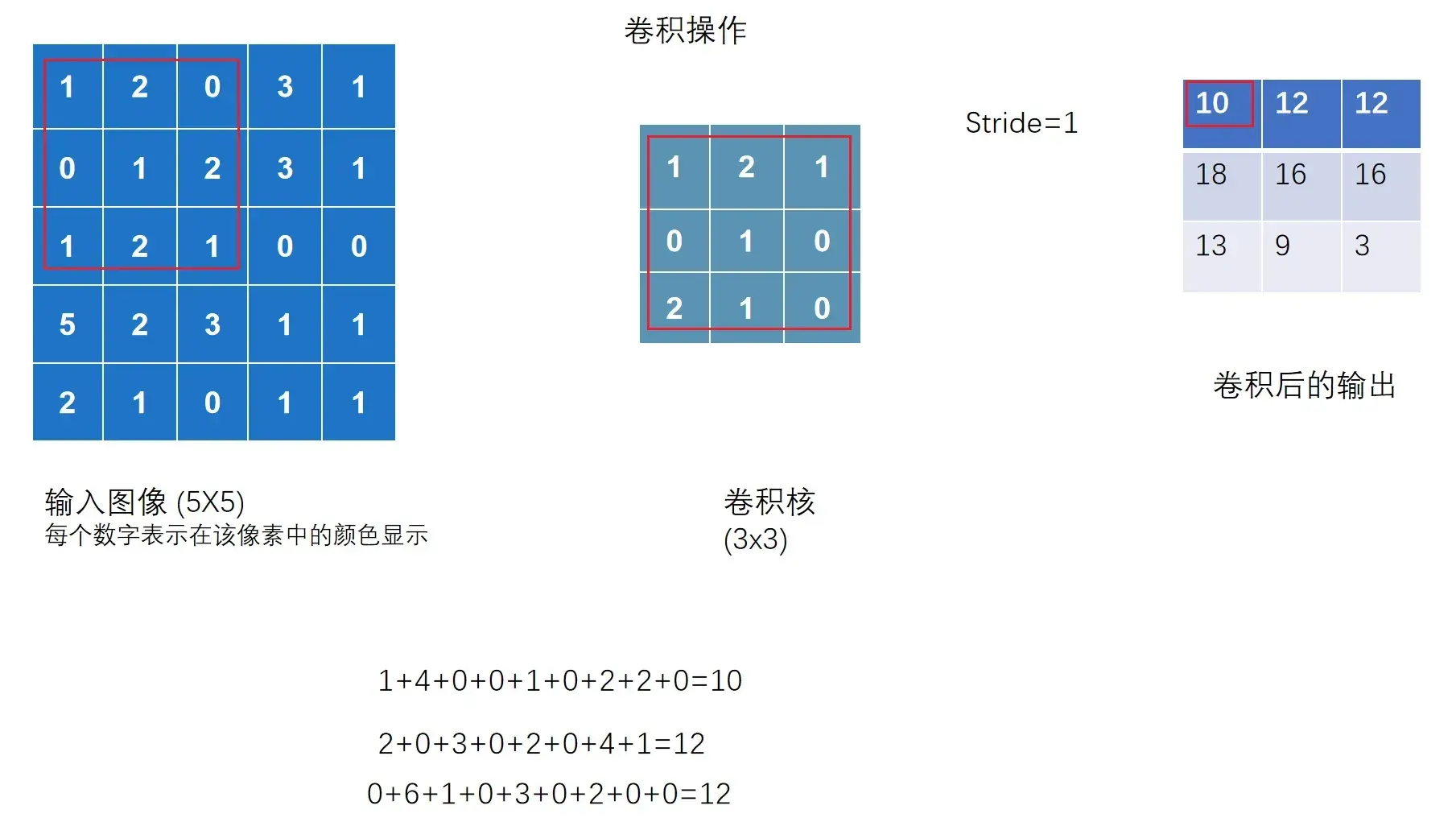
当 stride = 2 时,横向和纵向都是2,输出是一个2×2的矩阵
——————————————————————————————————————————–
要求输入的维度 & reshape函数
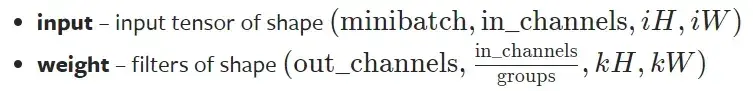
- input:尺寸要求是batch,几个通道,高,宽(4个参数)
- weight:尺寸要求是输出,in_channels(groups一般为1),高,宽(4个参数)
使用 torch.reshape 函数,将输入改变为要求输入的维度
实现上图的代码:
import torch
import torch.nn.functional as F
input =torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]) #将二维矩阵转为tensor数据类型
# 卷积核kernel
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
# 尺寸只有高和宽,不符合要求
print(input.shape) #5×5
print(kernel.shape) #3×3
# 尺寸变换为四个数字
input = torch.reshape(input,(1,1,5,5)) #通道数为1,batch大小为1
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
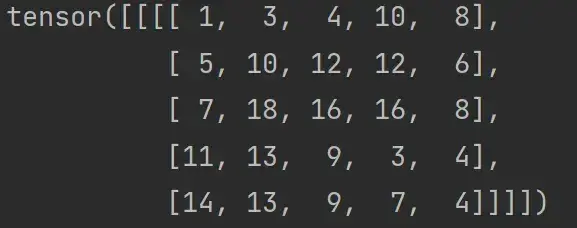
output = F.conv2d(input,kernel,stride=1) # .conv2d(input:Tensor, weight:Tensor, stride)
print(output)结果为:

当将步进 stride 改为 2 时:
output2 = F.conv2d(input,kernel,stride=2)
print(output2)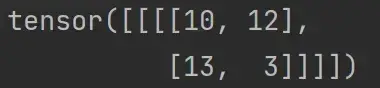
———————————————————————————————————————————
padding(填充)
在输入图像左右两边进行填充,决定填充有多大。可以为一个数或一个元组(分别指定高和宽,即纵向和横向每次填充的大小)。默认情况下不进行填充
padding=1:将输入图像左右上下两边都拓展一个像素,空的地方默认为0
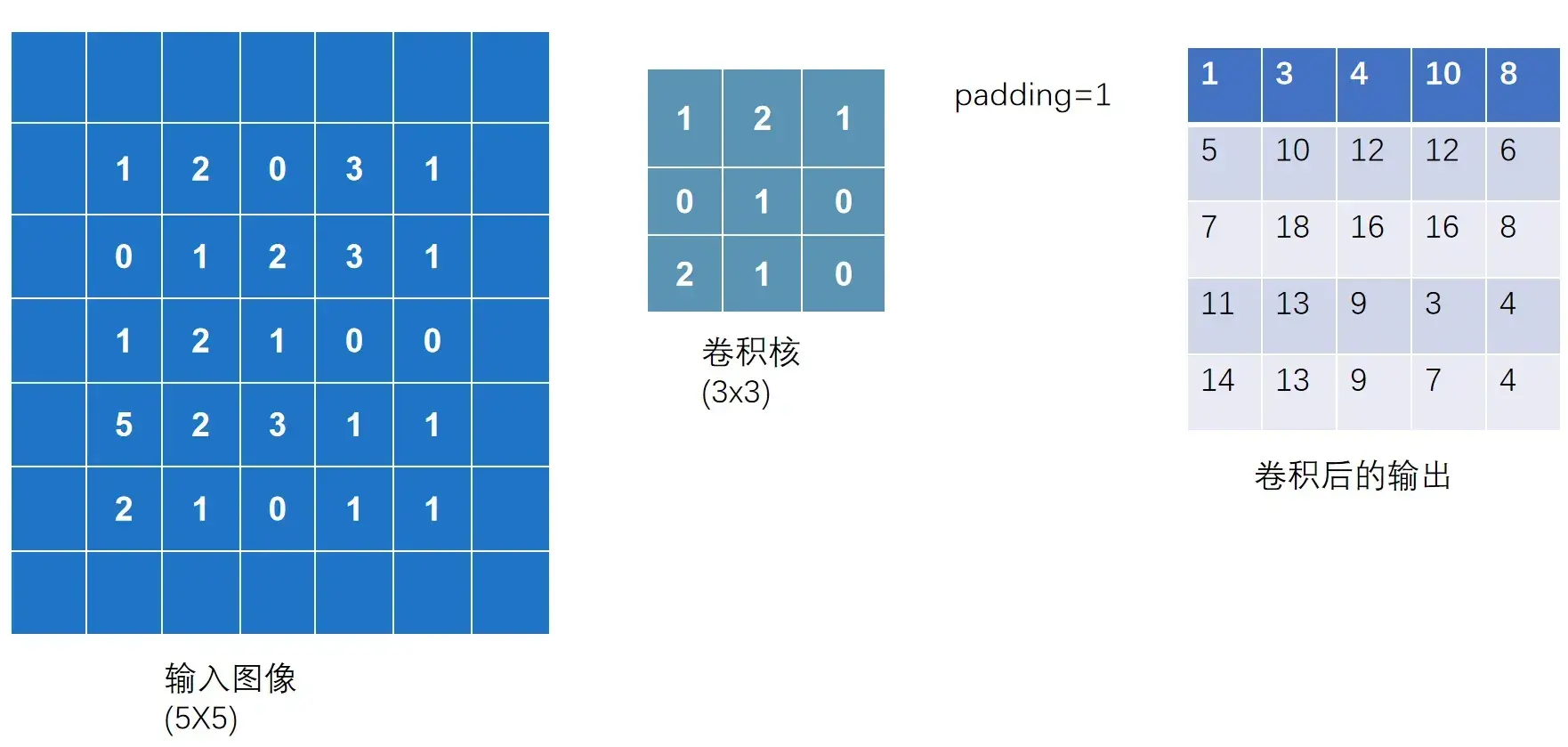
代码实现:
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print(output3)输出结果如下:可以看出输出尺寸变大
14. 神经网络 – 卷积层
torch.nn — PyTorch 1.10 documentation
| 一维卷积 | Applies a 1D convolution over an input signal composed of several input planes. |
| 二维卷积 | Applies a 2D convolution over an input signal composed of several input planes. |
| 三维卷积 | Applies a 3D convolution over an input signal composed of several input planes. |
图像为二维矩阵,所以讲解 nn.Conv2d
Conv2d — PyTorch 1.10 documentation

CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# in_channels 输入通道数
# out_channels 输出通道数
# kernel_size 卷积核大小
#以上参数需要设置
#以下参数提供了默认值
# stride=1 卷积过程中的步进大小
# padding=0 卷积过程中对原始图像进行padding的选项
# dilation=1 每一个卷积核对应位的距离
# groups=1 一般设置为1,很少改动,改动的话为分组卷积
# bias=True 通常为True,对卷积后的结果是否加减一个常数的偏置
# padding_mode='zeros' 选择padding填充的模式
动图:
conv_arithmetic/README.md at master · vdumoulin/conv_arithmetic · GitHub

kernel_size
定义了一个卷积核的大小,若为3则生成一个3×3的卷积核
- 卷积核的参数是从一些分布中进行采样得到的
- 实际训练过程中,卷积核中的值会不断进行调整
in_channels & out_channels
- in_channels:输入图片的channel数(彩色图像 in_channels 值为3)
- out_channels:输出图片的channel数
in_channels 和 out_channels 都为 1 时,拿一个卷积核在输入图像中进行卷积
out_channels 为 2 时,卷积层会生成两个卷积核(不一定一样),得到两个输出,叠加后作为最后输出
———————————————————————————————————————————
CIFAR10数据集实例
# CIFAR10数据集
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True) # 这里用测试数据集,因为训练数据集太大了
dataloader = DataLoader(dataset,batch_size=64)
# 搭建神经网络Tudui
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 因为是彩色图片,所以in_channels=3
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) #卷积层conv1
def forward(self,x): #输出为x
x = self.conv1(x)
return x
tudui = Tudui() # 初始化网络
# 打印一下网络结构
print(tudui) #Tudui((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)))
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs,targets = data #经过ToTensor转换,成为tensor数据类型,可以直接送到网络中
output = tudui(imgs)
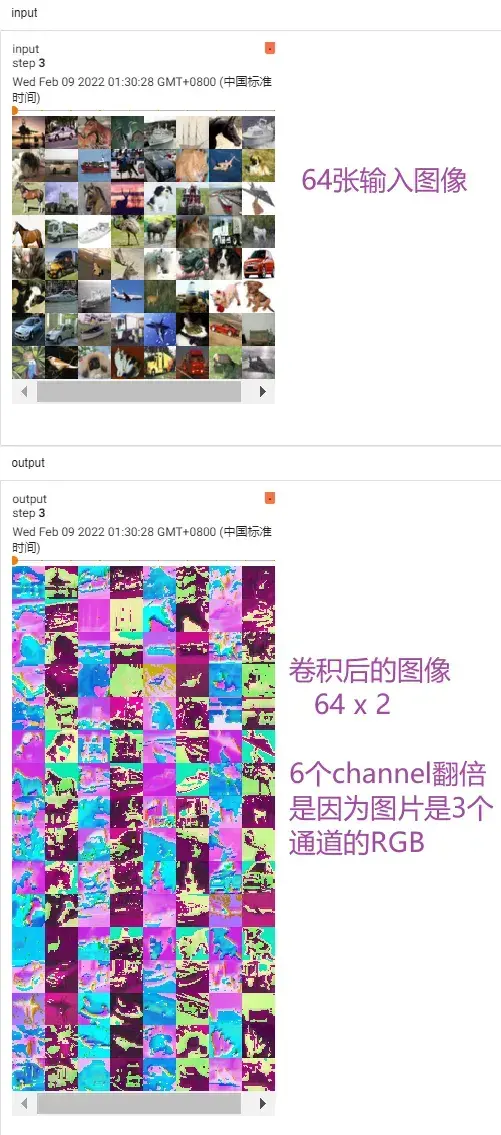
print(imgs.shape) #输入大小 torch.Size([64, 3, 32, 32]) batch_size=64,in_channels=3(彩色图像),每张图片是32×32的
print(output.shape) #经过卷积后的输出大小 torch.Size([64, 6, 30, 30]) 卷积后变成6个channels,但原始图像减小,所以是30×30的
writer.add_images("input",imgs,step)
# 6个channel无法显示。torch.Size([64, 6, 30, 30]) ——> [xxx,3,30,30] 第一个值不知道为多少时写-1,会根据后面值的大小进行计算
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step = step + 1运行后,在 Terminal 里启动 pytorch 环境:
conda activate pytorch打开 tensorboard:
tensorboard --logdir=logs打开网址 http://localhost:6006/:
———————————————————————————————————————————
卷积层 vgg16
———————————————————————————————————————————
卷积前后维度计算公式

15. 神经网络 – 最大池化的使用
torch.nn — PyTorch 1.10 documentation
- MaxPool:最大池化(下采样)
- MaxUnpool:上采样
- AvgPool:平均池化
- AdaptiveMaxPool2d:自适应最大池化
最常用:MaxPool2d — PyTorch 1.10 documentation
参数
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
# kernel_size 池化核
注意,卷积中stride默认为1,而池化中stride默认为kernel_size

——————————————————————————————————————————–
ceil_mode参数
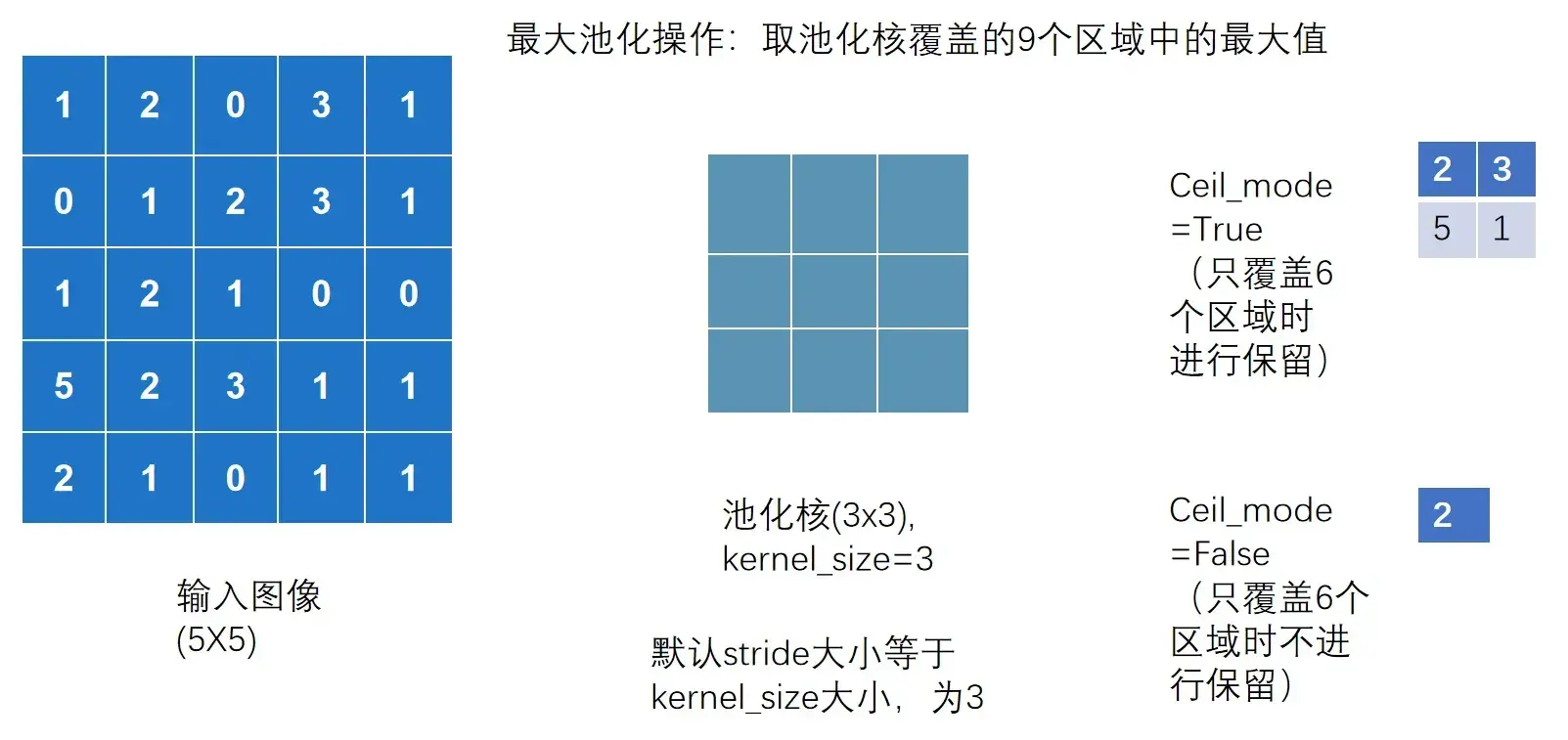
Ceil_mode 默认情况下为 False,对于最大池化一般只需设置 kernel_size 即可
——————————————————————————————————————————–
输入输出维度计算公式

——————————————————————————————————————————–
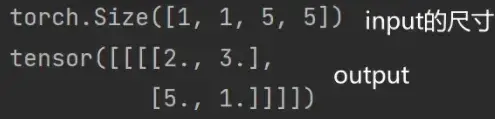
代码实现
要求的 input 必须是四维的,参数依次是:batch_size、channel、高、宽
上述图用代码实现:(以 Ceil_mode = True 为例)
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) #最大池化无法对long数据类型进行实现,将input变成浮点数的tensor数据类型
input = torch.reshape(input,(-1,1,5,5)) #-1表示torch计算batch_size
print(input.shape)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
# 创建神经网络
tudui = Tudui()
output = tudui(input)
print(output)
运行结果如下:
——————————————————————————————————————————–
为什么要进行最大池化?最大池化的作用是什么?
最大池化的目的是保留输入的特征,同时把数据量减小(数据维度变小),对于整个网络来说,进行计算的参数变少,会训练地更快
- 如上面案例中输入是5×5的,但输出是3×3的,甚至可以是1×1的
- 类比:1080p的视频为输入图像,经过池化可以得到720p,也能满足绝大多数需求,传达视频内容的同时,文件尺寸会大大缩小
池化一般跟在卷积后,卷积层是用来提取特征的,一般有相应特征的位置是比较大的数字,最大池化可以提取出这一部分有相应特征的信息
池化不影响通道数
池化后一般再进行非线性激活
——————————————————————————————————————————–
用数据集 CIFAR10 实现最大池化
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
# 创建神经网络
tudui = Tudui()
writer = SummaryWriter("../logs_maxpool")
step = 0
for data in dataloader:
imgs,targets = data
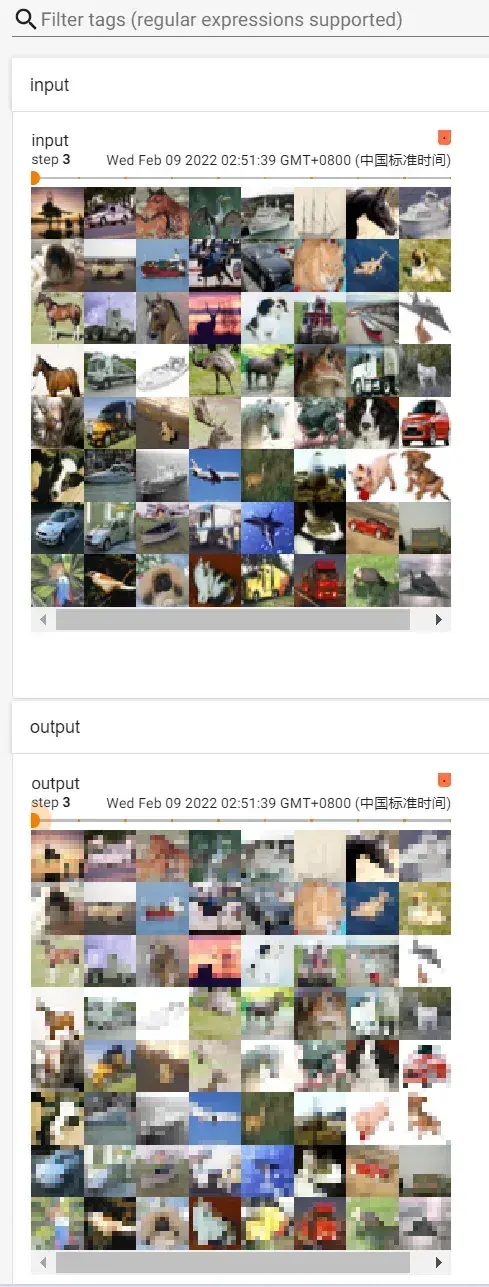
writer.add_images("input",imgs,step)
output = tudui(imgs) #output尺寸池化后不会有多个channel,原来是3维的图片,经过最大池化后还是3维的,不需要像卷积一样还要reshape操作(影响通道数的是卷积核个数)
writer.add_images("output",output,step)
step = step + 1
writer.close()运行后在 terminal 里输入(注意是在pytorch环境下):
tensorboard --logdir=logs_maxpool打开网址:
16. 神经网络 – 非线性激活
-
Padding Layers(对输入图像进行填充的各种方式)
几乎用不到,nn.ZeroPad2d(在输入tensor数据类型周围用0填充)
nn.ConstantPad2d(用常数填充)
在 Conv2d 中可以实现,故不常用
非线性激活:给神经网络引入一些非线性的特征
非线性越多,才能训练出符合各种曲线或特征的模型(提高泛化能力)
——————————————————————————————————————————–
最常见:RELU
ReLU — PyTorch 1.10 documentation
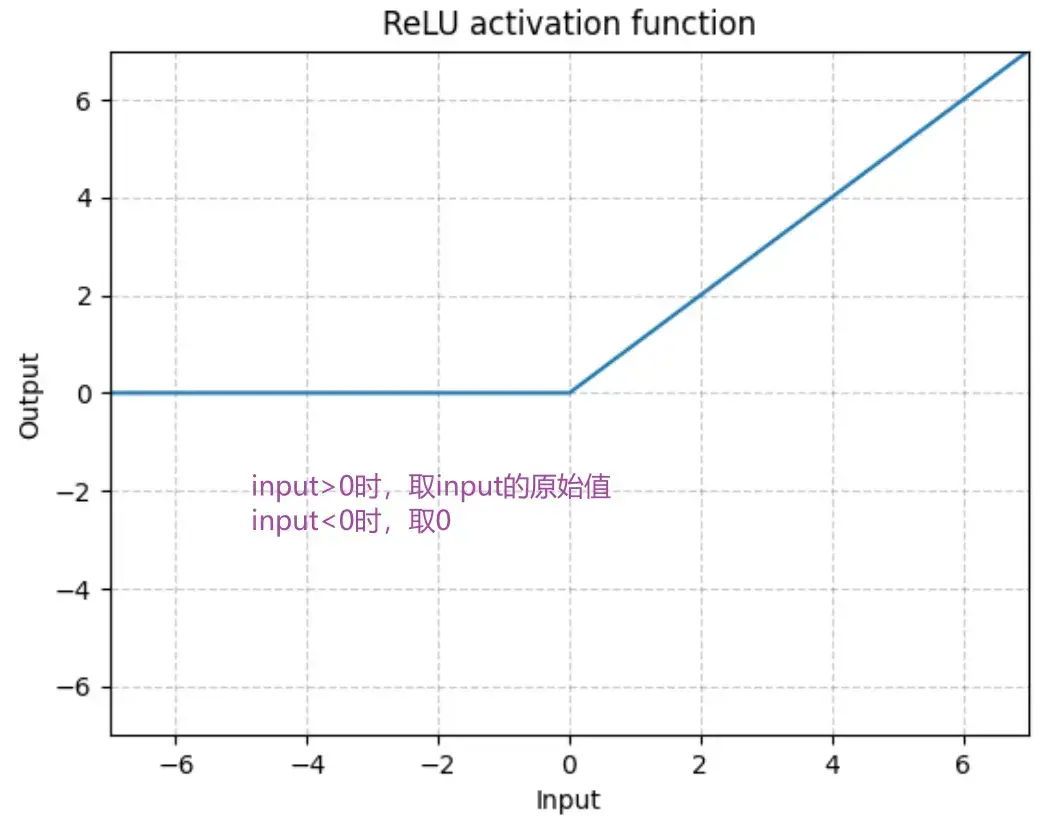
输入:(N,*) N 为 batch_size,*不限制
代码举例:RELU
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2)) #input必须要指定batch_size,-1表示batch_size自己算,1表示是1维的
print(input.shape) #torch.Size([1, 1, 2, 2])
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU() #inplace默认为False
def forward(self,input):
output = self.relu1(input)
return output
# 创建网络
tudui = Tudui()
output = tudui(input)
print(output)运行结果:
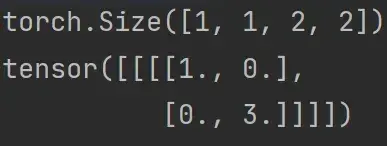
跟输入对比可以看到:小于0的值被0截断,大于0的值仍然保留
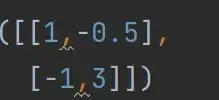
——————————————————————————————————————————–
Sigmoid
Sigmoid — PyTorch 1.10 documentation
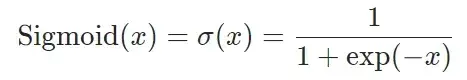
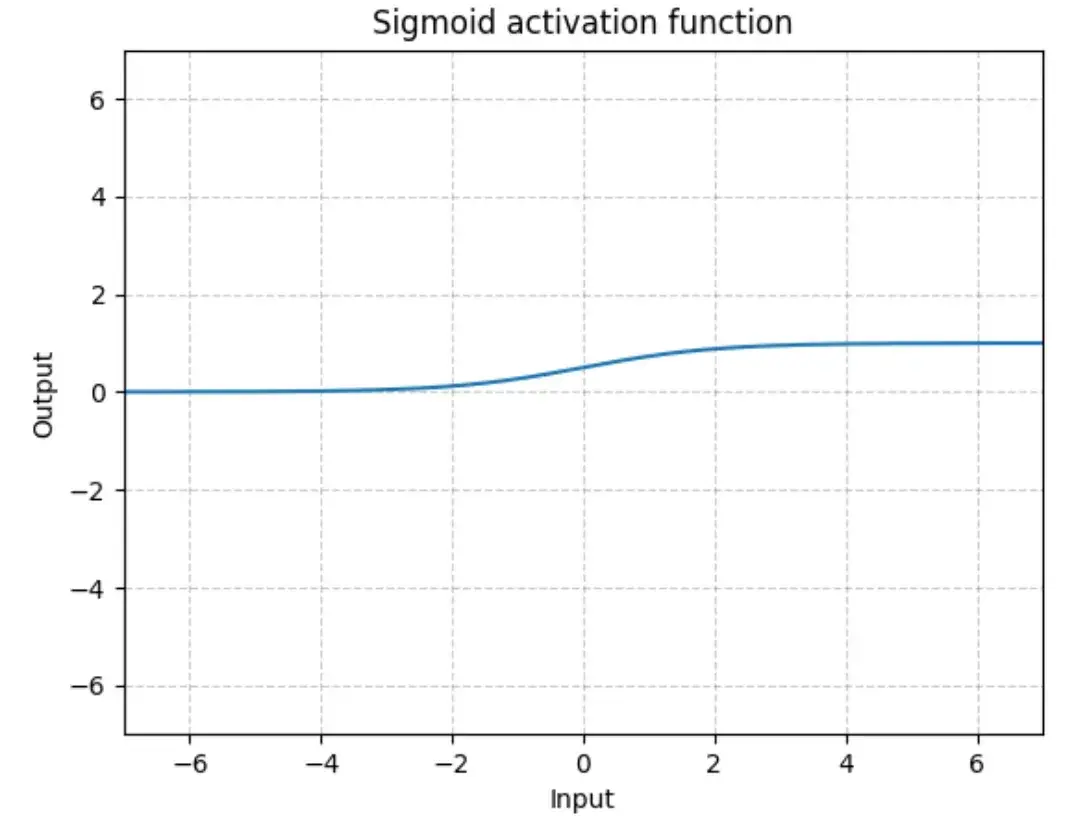
输入:(N,*) N 为 batch_size,*不限制
代码举例:Sigmoid(数据集CIFAR10)
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.sigmoid1 = Sigmoid() #inplace默认为False
def forward(self,input):
output = self.sigmoid1(input)
return output
# 创建网络
tudui = Tudui()
writer = SummaryWriter("../logs_sigmoid")
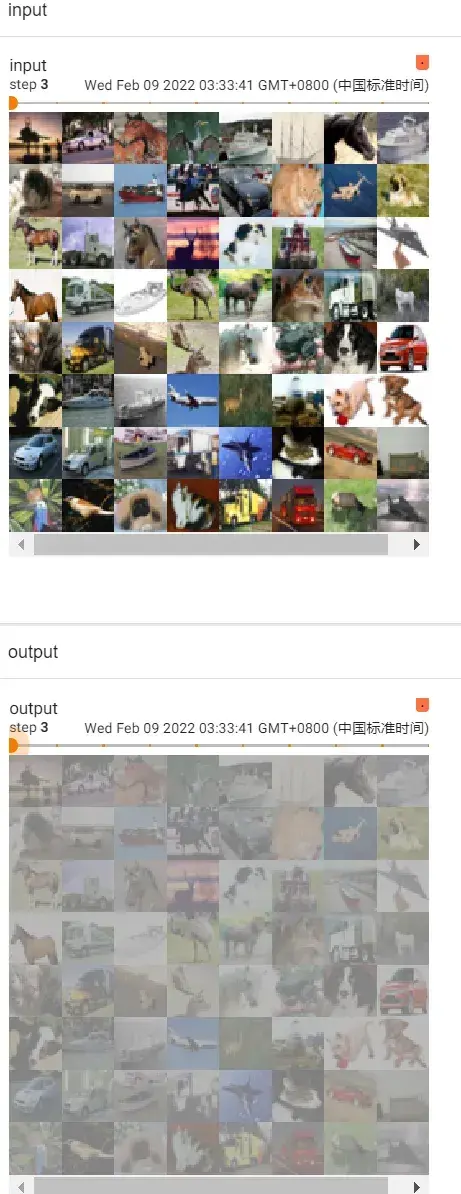
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,global_step=step)
output = tudui(imgs)
writer.add_images("output",output,step)
step = step + 1
writer.close()
运行后在 terminal 里输入:
tensorboard --logdir=logs_sigmoid打开网址:
——————————————————————————————————————————–
关于inplace

17. 神经网络 – 线性层及其他层介绍
批标准化层(不难,自学)
torch.nn — PyTorch 1.10 documentation
BatchNorm2d — PyTorch 1.10 documentation
对输入采用Batch Normalization,可以加快神经网络的训练速度
CLASS torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
# num_features C-输入的channel# With Learnable Parameters
m = nn.BatchNorm2d(100)
# Without Learnable Parameters
m = nn.BatchNorm2d(100, affine=False) # 正则化层num_feature等于channel,即100
input = torch.randn(20, 100, 35, 45) #batch_size=20,100个channel,35x45的输入
output = m(input)———————————————————————————————————————————
Recurrent Layers(特定网络中使用,自学)
RNN、LSTM等,用于文字识别中,特定的网络结构
torch.nn — PyTorch 1.13 documentation
———————————————————————————————————————————
Transformer Layers(特定网络中使用,自学)
特定网络结构
torch.nn — PyTorch 1.13 documentation
———————————————————————————————————————————
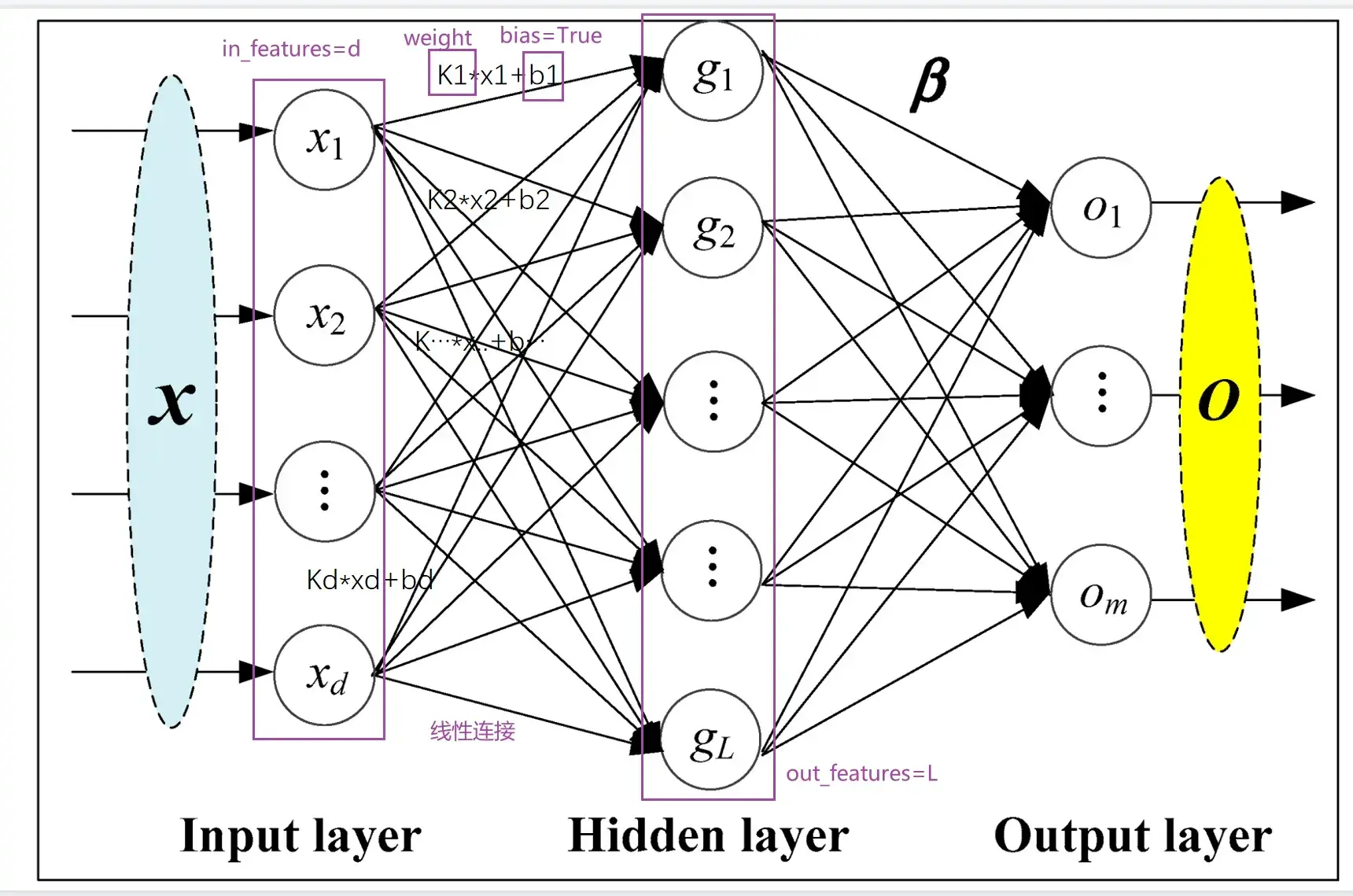
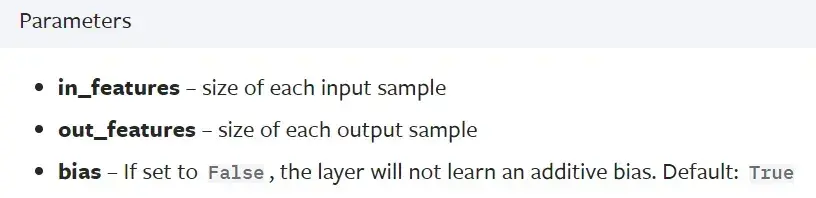
Linear Layers(本节讲解)
Linear — PyTorch 1.10 documentation

——————————————————————————————————————————–
代码实例
vgg16 model
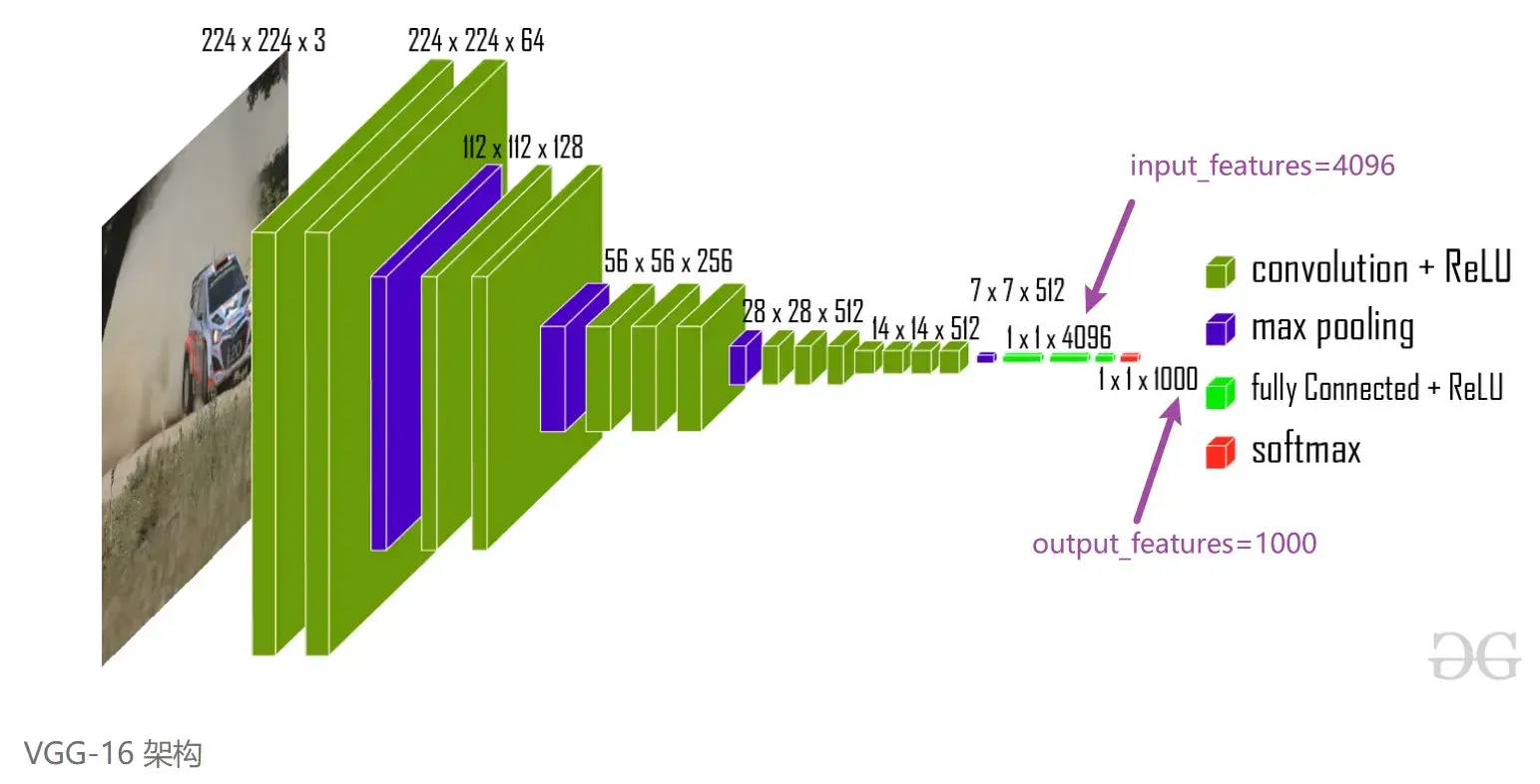
———————————————————————————————————————————
flatten 摊平
torch.flatten — PyTorch 1.10 documentation
# Example
>>> t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]]) #3个中括号,所以是3维的
>>> torch.flatten(t) #摊平
tensor([1, 2, 3, 4, 5, 6, 7, 8])
>>> torch.flatten(t, start_dim=1) #变为1行
tensor([[1, 2, 3, 4],
[5, 6, 7, 8]])- reshape():可以指定尺寸进行变换
- flatten():变成1行,摊平
output = torch.flatten(imgs)
# 等价于
output = torch.reshape(imgs,(1,1,1,-1))
for data in dataloader:
imgs,targets = data
print(imgs.shape) #torch.Size([64, 3, 32, 32])
output = torch.reshape(imgs,(1,1,1,-1)) # 想把图片展平
print(output.shape) # torch.Size([1, 1, 1, 196608])
output = tudui(output)
print(output.shape) # torch.Size([1, 1, 1, 10])
for data in dataloader:
imgs,targets = data
print(imgs.shape) #torch.Size([64, 3, 32, 32])
output = torch.flatten(imgs) #摊平
print(output.shape) #torch.Size([196608])
output = tudui(output)
print(output.shape) #torch.Size([10])——————————————————————————————————————————–

import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs,targets = data
print(imgs.shape) #torch.Size([64, 3, 32, 32])
# output = torch.reshape(imgs,(1,1,1,-1)) # 想把图片展平
# print(output.shape) # torch.Size([1, 1, 1, 196608])
# output = tudui(output)
# print(output.shape) # torch.Size([1, 1, 1, 10])
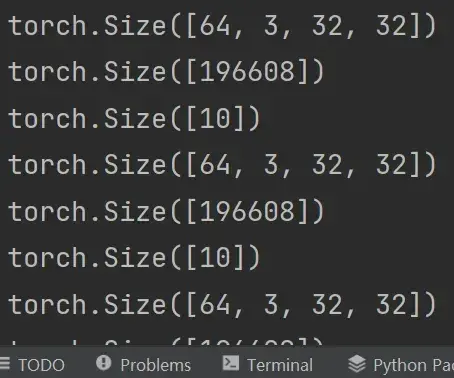
output = torch.flatten(imgs) #摊平
print(output.shape) #torch.Size([196608])
output = tudui(output)
print(output.shape) #torch.Size([10])运行结果如下:
———————————————————————————————————————————
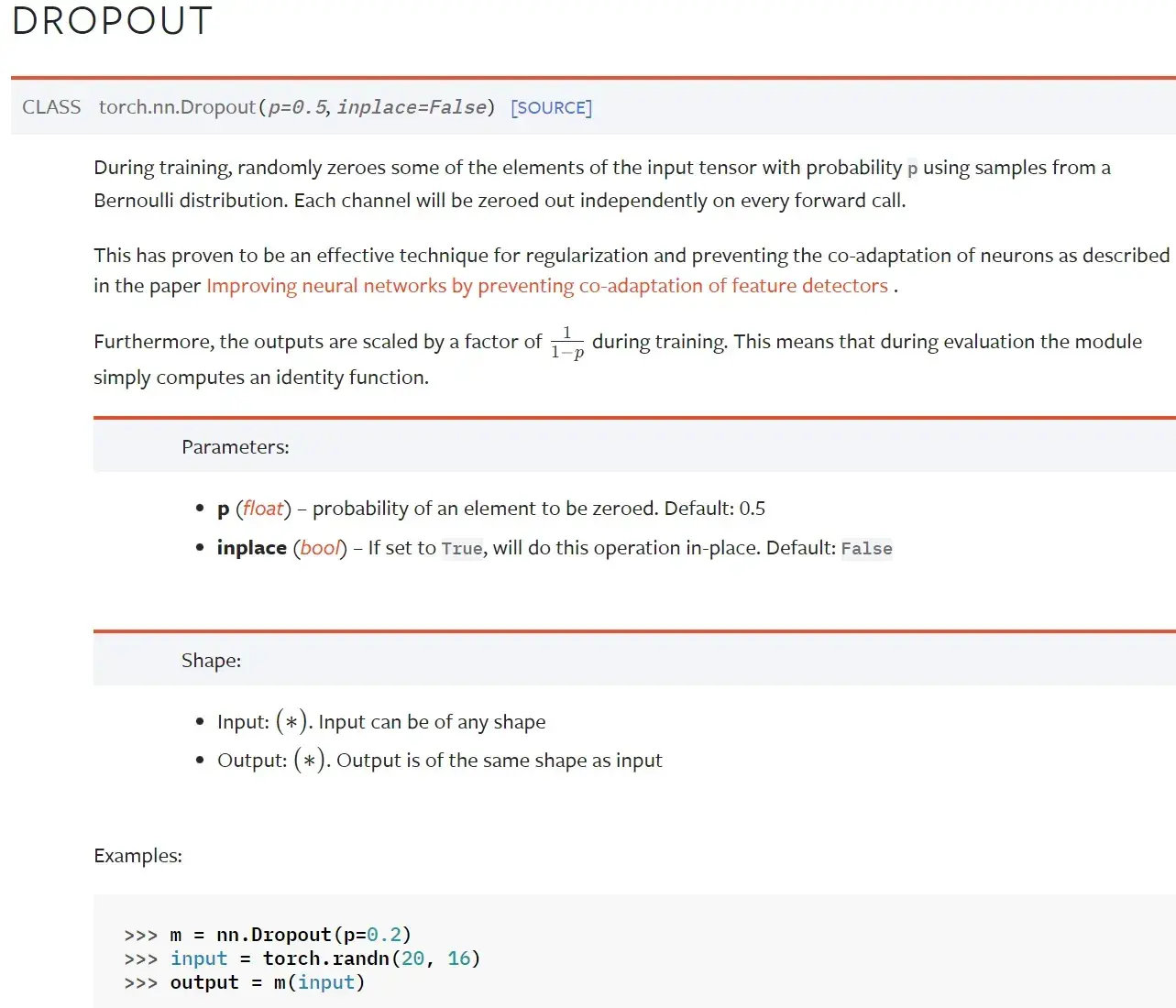
Dropout Layers(不难,自学)
Dropout — PyTorch 1.10 documentation
在训练过程中,随机把一些 input(输入的tensor数据类型)中的一些元素变为0,变为0的概率为p
目的:防止过拟合
———————————————————————————————————————————
Sparse Layers(特定网络中使用,自学)
Embedding
Embedding — PyTorch 1.10 documentation
用于自然语言处理
——————————————————————————————————————————–
Distance Functions
计算两个值之间的误差
torch.nn — PyTorch 1.13 documentation

——————————————————————————————————————————–
Loss Functions
loss 误差大小
torch.nn — PyTorch 1.13 documentation

———————————————————————————————————————————
pytorch提供的一些网络模型
- 图片相关:torchvision torchvision.models — Torchvision 0.11.0 documentation
分类、语义分割、目标检测、实例分割、人体关键节点识别(姿态估计)等等 - 文本相关:torchtext 无
- 语音相关:torchaudio torchaudio.models — Torchaudio 0.10.0 documentation
下一节:Container ——> Sequential(序列)
18. 神经网络 – 搭建小实战和 Sequential 的使用
Containers中有Module、Sequential等
Sequential — PyTorch 1.10 documentation
Example:
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))好处:代码简洁易懂
———————————————————————————————————————————
对 CIFAR10 进行分类的简单神经网络
CIFAR 10:根据图片内容,识别其究竟属于哪一类(10代表有10个类别)
CIFAR-10 and CIFAR-100 datasets
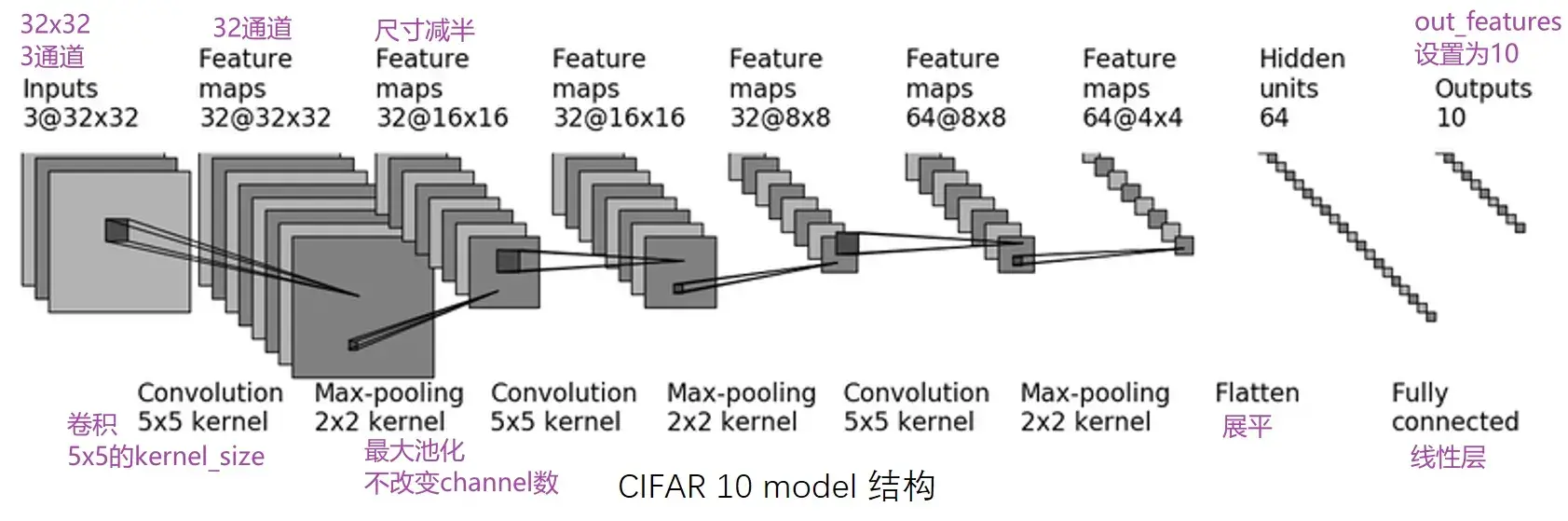
第一次卷积:首先加了几圈 padding(图像大小不变,还是32×32),然后卷积了32次
- Conv2d — PyTorch 1.10 documentation
- 输入尺寸是32×32,经过卷积后尺寸不变,如何设置参数? —— padding=2,stride=1
- 计算公式:

几个卷积核就是几通道的,一个卷积核作用于RGB三个通道后会把得到的三个矩阵的对应值相加,也就是说会合并,所以一个卷积核会产生一个通道
任何卷积核在设置padding的时候为保持输出尺寸不变都是卷积核大小的一半
通道变化时通过调整卷积核的个数(即输出通道)来实现的,在 nn.conv2d 的参数中有 out_channel 这个参数,就是对应输出通道
kernel 的内容是不一样的,可以理解为不同的特征抓取,因此一个核会产生一个channel
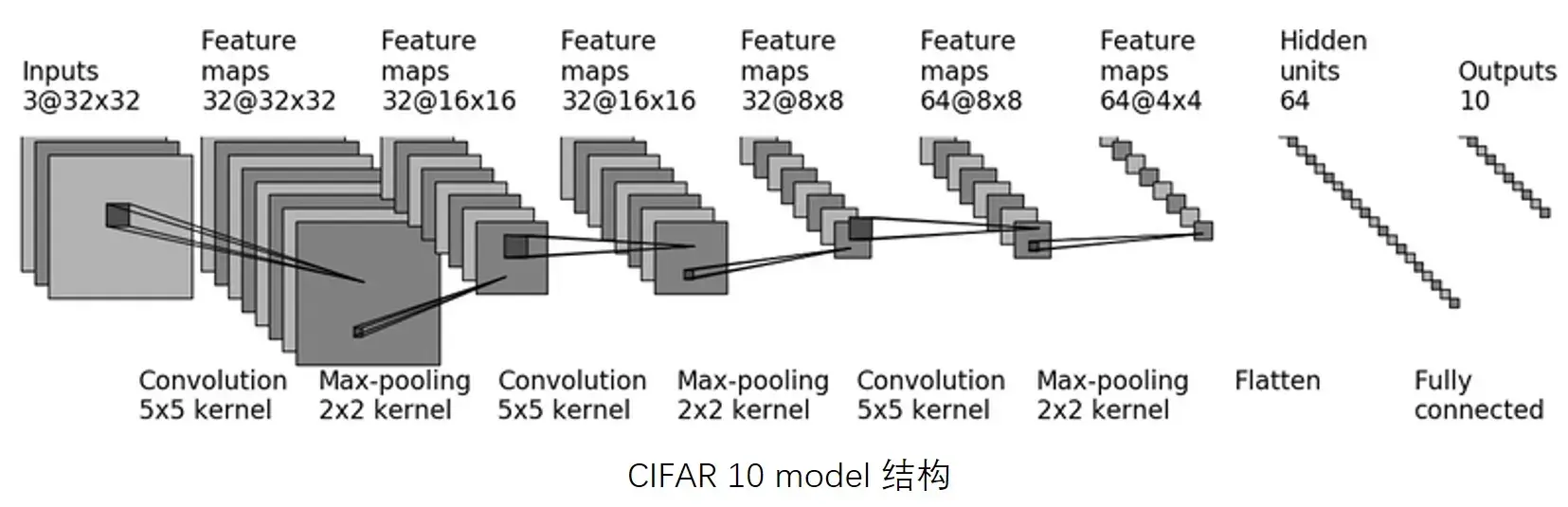
直接搭建,实现上图 CIFAR10 model 的代码
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2) #第一个卷积
self.maxpool1 = MaxPool2d(kernel_size=2) #池化
self.conv2 = Conv2d(32,32,5,padding=2) #维持尺寸不变,所以padding仍为2
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten() #展平为64x4x4=1024个数据
# 经过两个线性层:第一个线性层(1024为in_features,64为out_features)、第二个线性层(64为in_features,10为out_features)
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10) #10为10个类别,若预测的是概率,则取最大概率对应的类别,为该图片网络预测到的类别
def forward(self,x): #x为input
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui()
print(tudui)可以看到网络结构:

———————————————————————————————————————————
实际过程中如何检查网络的正确性?
核心:一定尺寸的数据经过网络后,能够得到我们想要的输出
对网络结构进行检验的代码:
input = torch.ones((64,3,32,32)) #全是1,batch_size=64,3通道,32x32
output = tudui(input)
print(output.shape)运行结果:
torch.Size([64, 10])——————————————————————————————————————————–
若不知道flatten之后的维度是多少该怎么办?
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2) #第一个卷积
self.maxpool1 = MaxPool2d(kernel_size=2) #池化
self.conv2 = Conv2d(32,32,5,padding=2) #维持尺寸不变,所以padding仍为2
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten() #展平为64x4x4=1024个数据
# 经过两个线性层:第一个线性层(1024为in_features,64为out_features)、第二个线性层(64为in_features,10为out_features)
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10) #10为10个类别,若预测的是概率,则取最大概率对应的类别,为该图片网络预测到的类别
def forward(self,x): #x为input
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64,3,32,32)) #全是1,batch_size=64(64张图片),3通道,32x32
output = tudui(input)
print(output.shape) # torch.Size([64,1024])看到输出的维度是(64,1024),64可以理解为64张图片,1024就是flatten之后的维度了
———————————————————————————————————————————
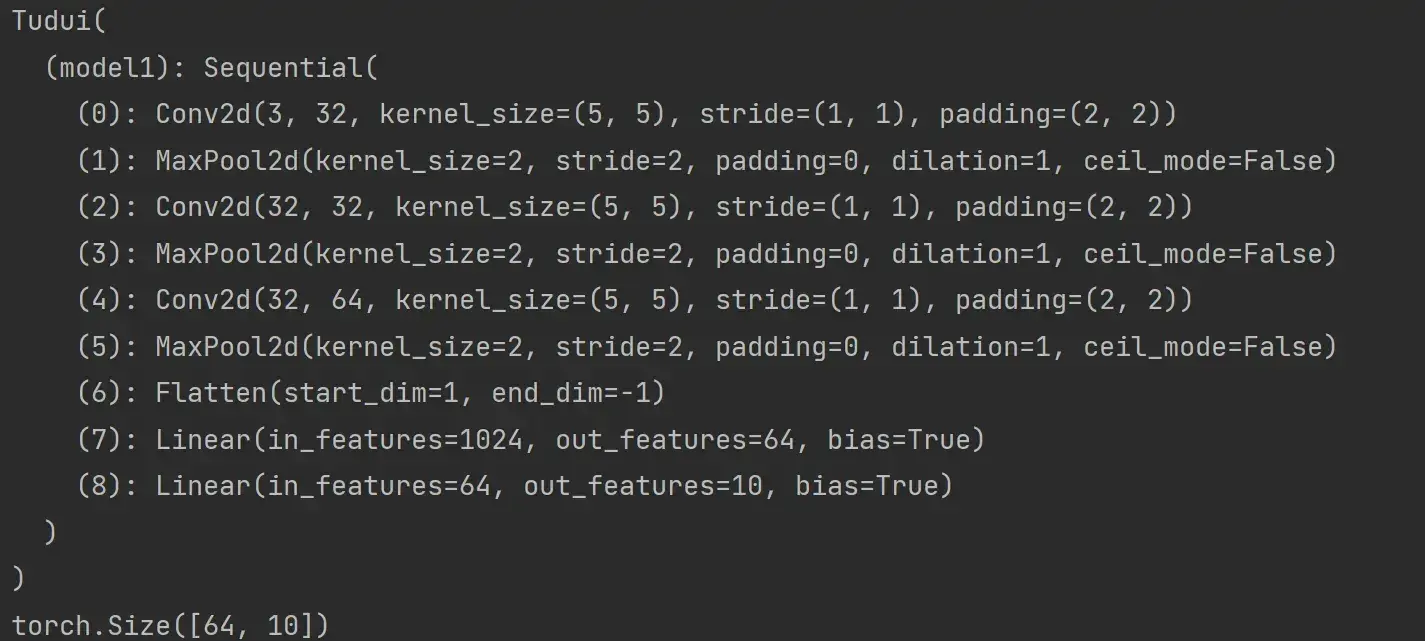
用 Sequential 搭建,实现上图 CIFAR10 model 的代码
作用:代码更加简洁
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x): #x为input
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64,3,32,32)) #全是1,batch_size=64,3通道,32x32
output = tudui(input)
print(output.shape)运行结果:
——————————————————————————————————————————–
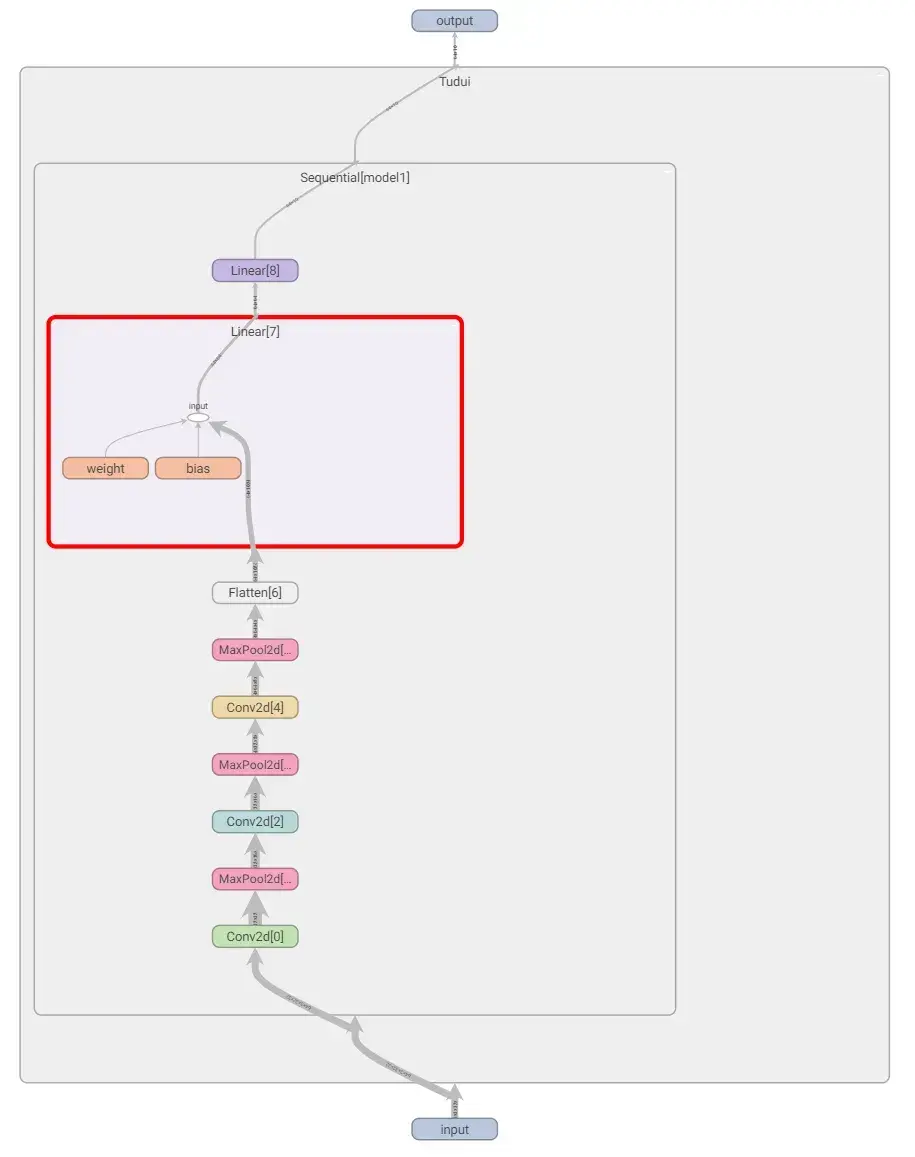
引入 tensorboard 可视化模型结构
在上述代码后面加上以下代码:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("../logs_seq")
writer.add_graph(tudui,input) # add_graph 计算图
writer.close()运行后在 terminal 里输入:
tensorboard --logdir=logs_seq打开网址,双击图片中的矩形,可以放大每个部分:
19. 损失函数与反向传播
torch.nn 里的 loss function 衡量误差,在使用过程中根据需求使用,注意输入形状和输出形状即可
loss 衡量实际神经网络输出 output 与真实想要结果 target 的差距,越小越好
作用:
- 计算实际输出和目标之间的差距
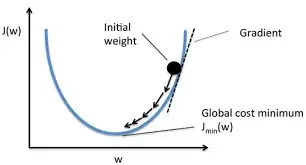
- 为我们更新输出提供一定的依据(反向传播):给每一个卷积核中的参数提供了梯度 grad,采用反向传播时,每一个要更新的参数都会计算出对应的梯度,优化过程中根据梯度对参数进行优化,最终达到整个 loss 进行降低的目的
梯度下降法:
———————————————————————————————————————————
L1LOSS

input:(N,*) N是batch_size,即有多少个数据;*可以是任意维度
CLASS torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')代码
- 取平均的方式:
import torch
from torch.nn import L1Loss
# 实际数据或网络默认情况下就是float类型,不写测试案例的话一般不需要加dtype
inputs = torch.tensor([1,2,3],dtype=torch.float32) # 计算时要求数据类型为浮点数,不能是整型的long
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3)) # 1 batch_size, 1 channel, 1行3列
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss()
result = loss(inputs,targets)
print(result)运行结果:
tensor(0.6667)- 求和的方式:
修改上述代码中的一句即可
loss = L1Loss(reduction='sum')运行结果:
tensor(2.)———————————————————————————————————————————
MSELOSS(均方误差)
input:(N,*) N是batch_size,即有多少个数据;*可以是任意维度
CLASS torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
代码
import torch
from torch import nn
# 实际数据或网络默认情况下就是float类型,不写测试案例的话一般不需要加dtype
inputs = torch.tensor([1,2,3],dtype=torch.float32) # 计算时要求数据类型为浮点数,不能是整型的long
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3)) # 1 batch_size, 1 channel, 1行3列
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs,targets)
print(result_mse)结果:
tensor(1.3333)
———————————————————————————————————————————
CROSSENTROPYLOSS(交叉熵)
适用于训练分类问题,有C个类别
例:三分类问题,person,dog,cat
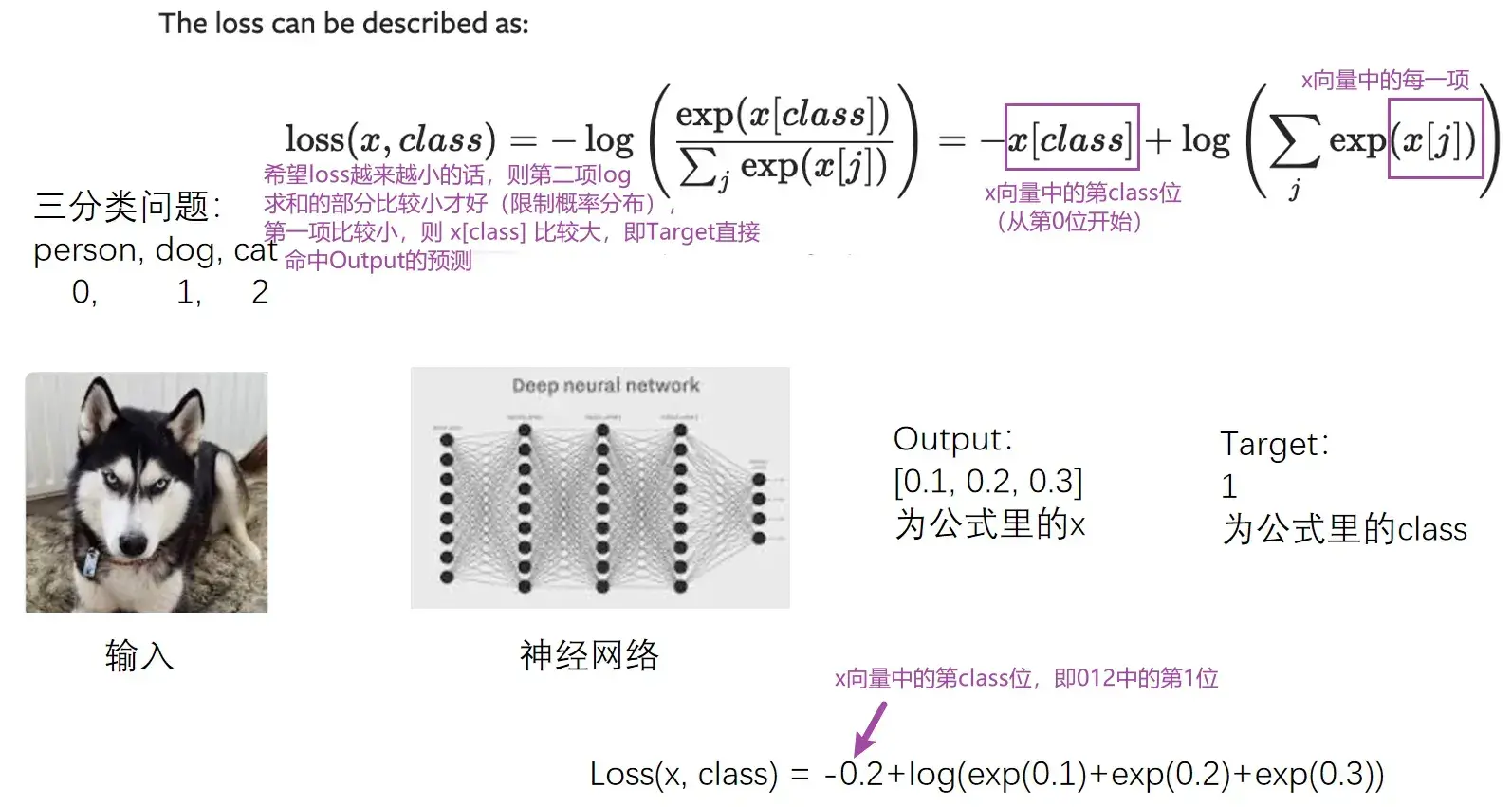
这里的output不是概率,是评估分数
 input 为没有进行处理过的对每一类的得分
input 为没有进行处理过的对每一类的得分
代码:
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)结果:
tensor(1.1019)———————————————————————————————————————————
如何在之前写的神经网络中用到 Loss Function(损失函数)
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x): # x为input
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs,targets = data # imgs为输入,放入神经网络中
outputs = tudui(imgs) # outputs为输入通过神经网络得到的输出,targets为实际输出
result_loss = loss(outputs,targets)
print(result_loss) # 神经网络输出与真实输出的误差结果:
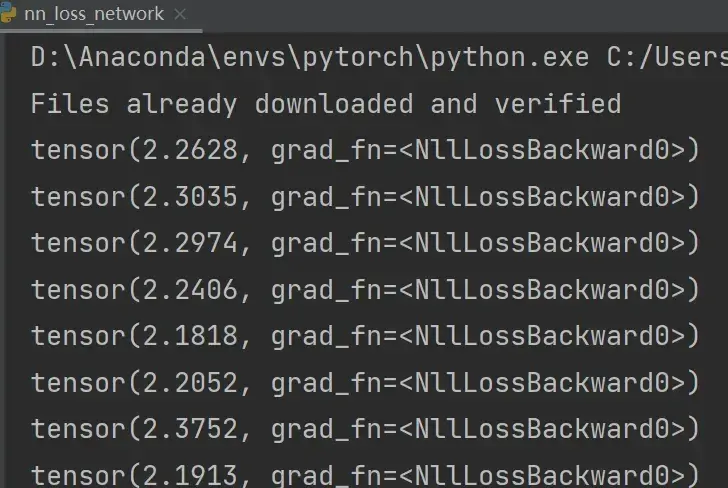
———————————————————————————————————————————
backward 反向传播
计算出每一个节点参数的梯度
在上述代码后加一行:
result_loss.backward() # backward反向传播,是对result_loss,而不是对loss在这一句代码前打上断点(运行到该行代码的前一行,该行不运行),debug 后: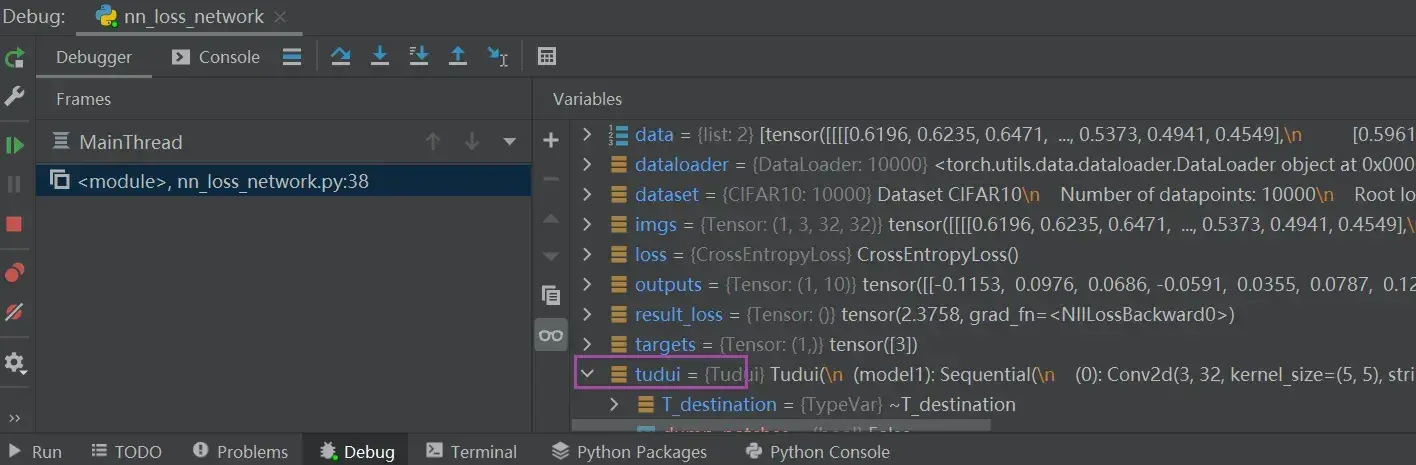
tudui ——> model 1 ——> Protected Attributes ——> _modules ——> ‘0’ ——> bias / weight——> grad(是None)
点击Step into My Code,运行完该行后,可以发现刚刚的None有值了(损失函数一定要经过 .backward() 后才能反向传播,才能有每个需要调节的参数的grad的值)
下一节:选择合适的优化器,利用梯度对网络中的参数进行优化更新,以达到整个 loss最低的目的
20. 优化器
当使用损失函数时,可以调用损失函数的 backward,得到反向传播,反向传播可以求出每个需要调节的参数对应的梯度,有了梯度就可以利用优化器,优化器根据梯度对参数进行调整,以达到整体误差降低的目的
torch.optim — PyTorch 1.10 documentation
———————————————————————————————————————————
如何使用优化器?
(1)构造
# Example:
# SGD为构造优化器的算法,Stochastic Gradient Descent 随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) #模型参数、学习速率、特定优化器算法中需要设定的参数
optimizer = optim.Adam([var1, var2], lr=0.0001)(2)调用优化器的step方法
利用之前得到的梯度对参数进行更新
for input, target in dataset:
optimizer.zero_grad() #把上一步训练的每个参数的梯度清零
output = model(input)
loss = loss_fn(output, target) # 输出跟真实的target计算loss
loss.backward() #调用反向传播得到每个要更新参数的梯度
optimizer.step() #每个参数根据上一步得到的梯度进行优化———————————————————————————————————————————
算法
如Adadelta、Adagrad、Adam、RMSProp、SGD等等,不同算法前两个参数:params、lr 都是一致的,后面的参数不同
CLASS torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
# params为模型的参数、lr为学习速率(learning rate)
# 后续参数都是特定算法中需要设置的学习速率不能太大(太大模型训练不稳定)也不能太小(太小模型训练慢),一般建议先采用较大学习速率,后采用较小学习速率
——————————————————————————————————————————–
SGD为例
以 SGD(随机梯度下降法)为例进行说明:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
# 加载数据集并转为tensor数据类型
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 加载数据集
dataloader = DataLoader(dataset,batch_size=1)
# 创建网络名叫Tudui
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x): # x为input,forward前向传播
x = self.model1(x)
return x
# 计算loss
loss = nn.CrossEntropyLoss()
# 搭建网络
tudui = Tudui()
# 设置优化器
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # SGD随机梯度下降法
for data in dataloader:
imgs,targets = data # imgs为输入,放入神经网络中
outputs = tudui(imgs) # outputs为输入通过神经网络得到的输出,targets为实际输出
result_loss = loss(outputs,targets)
optim.zero_grad() # 把网络模型中每一个可以调节的参数对应梯度设置为0
result_loss.backward() # backward反向传播求出每一个节点的梯度,是对result_loss,而不是对loss
optim.step() # 对每个参数进行调优
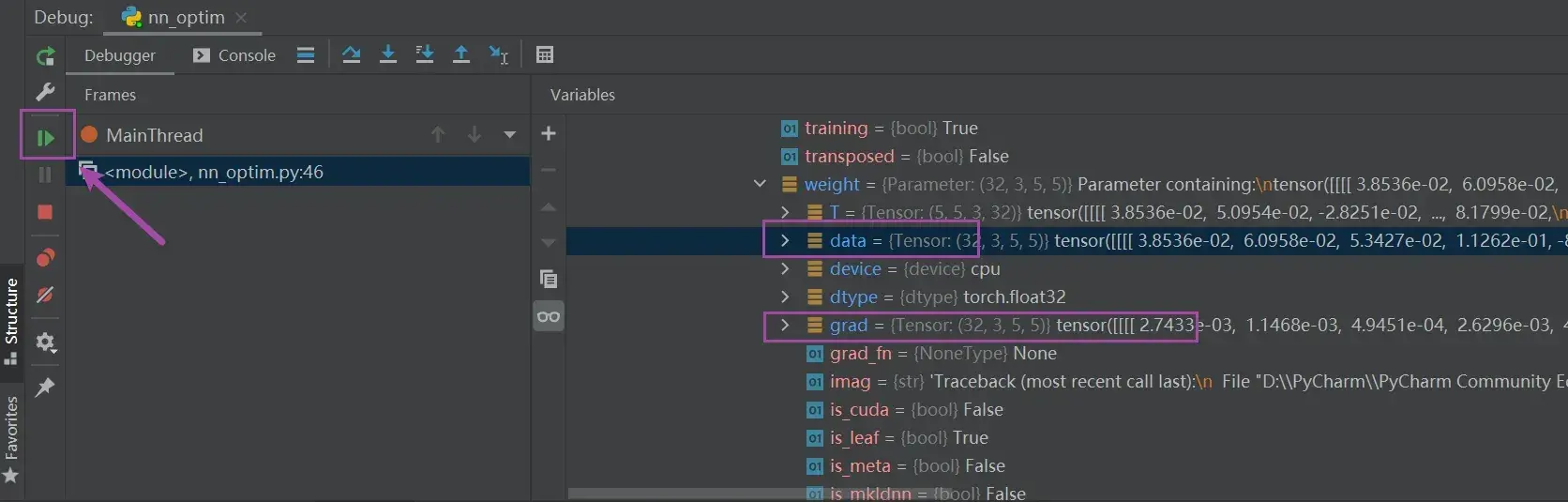
可以在以下地方打断点,debug:

tudui ——> Protected Attributes ——> _modules ——> ‘model1’ ——> Protected Attributes ——> _modules ——> ‘0’ ——> weight ——> data 或 grad
通过每次按箭头所指的按钮(点一次运行一行),观察 data 和 grad 值的变化
- 第一行 optim.zero_grad() 是让grad清零
- 第三行 optim.step() 会通过grad更新data
——————————————————————————————————————————–
完整代码
在 data 循环外又套一层 epoch 循环,一次 data 循环相当于对数据训练一次,加了 epoch 循环相当于对数据训练 20 次
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
# 加载数据集并转为tensor数据类型
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
# 创建网络名叫Tudui
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x): # x为input,forward前向传播
x = self.model1(x)
return x
# 计算loss
loss = nn.CrossEntropyLoss()
# 搭建网络
tudui = Tudui()
# 设置优化器
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # SGD随机梯度下降法
for epoch in range(20):
running_loss = 0.0 # 在每一轮开始前将loss设置为0
for data in dataloader: # 该循环相当于只对数据进行了一轮学习
imgs,targets = data # imgs为输入,放入神经网络中
outputs = tudui(imgs) # outputs为输入通过神经网络得到的输出,targets为实际输出
result_loss = loss(outputs,targets)
optim.zero_grad() # 把网络模型中每一个可以调节的参数对应梯度设置为0
result_loss.backward() # backward反向传播求出每一个节点的梯度,是对result_loss,而不是对loss
optim.step() # 对每个参数进行调优
running_loss = running_loss + result_loss # 每一轮所有loss的和
print(running_loss)部分运行结果:
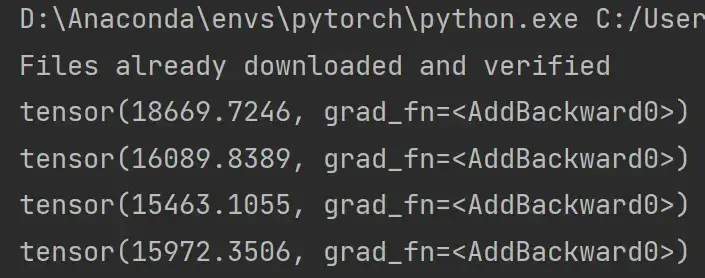
优化器对模型参数不断进行优化,每一轮的 loss 在不断减小
实际过程中模型在整个数据集上的训练次数(即最外层的循环)都是成百上千/万的,本例仅以 20 次为例
21. 现有网络模型的使用及修改

本节主要讲解 torchvision

本节主要讲解 Classification 里的 VGG 模型,数据集仍为 CIFAR10 数据集(主要用于分类)
torchvision.models — Torchvision 0.11.0 documentation
———————————————————————————————————————————
数据集 ImageNet
注意:必须要先有 package scipy
在 Terminal 里输入
pip list寻找是否有 scipy,若没有的话输入
pip install scipy(注意关闭代理!!!)
———————————————————————————————————————————
参数及下载

下载 ImageNet 数据集:
import torchvision.datasets
train_data = torchvision.datasets.ImageNet("../data_image_net",split='train',download=True,
transform=torchvision.transforms.ToTensor())./xxx表示当前路径下,../xxx表示返回上一级目录
多行注释快捷键:ctrl+/
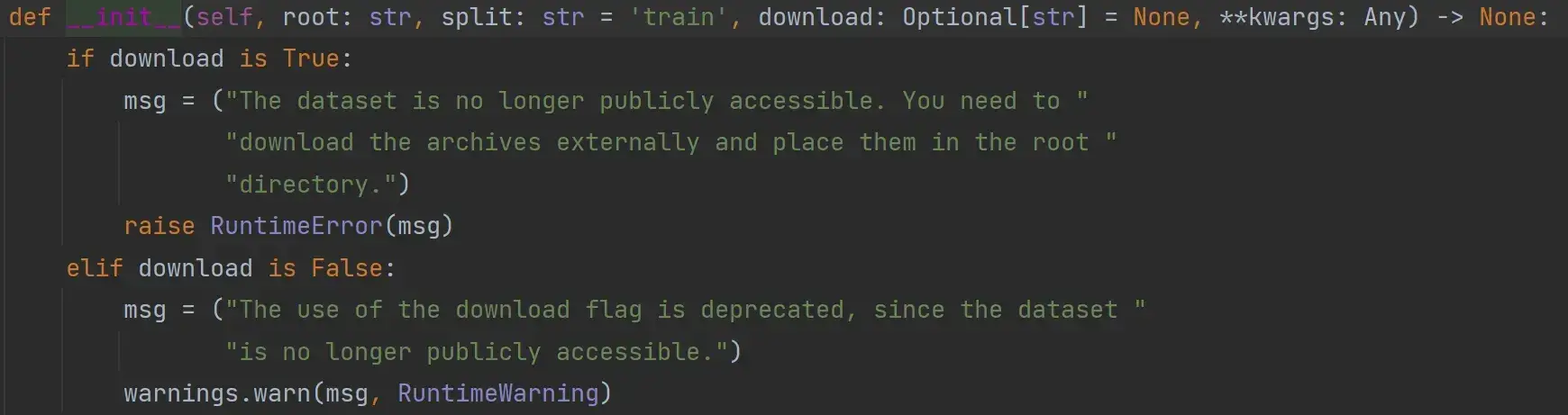
运行后会报错:
RuntimeError: The dataset is no longer publicly accessible. You need to download the archives externally and place them in the root directory.
下载地址:
Imagenet 完整数据集下载_wendell 的博客-CSDN博客_imagenet下载
100 多个G,太大… 放弃
按住 Ctrl 键,点击 ImageNet,查看其源码:
——————————————————————————————————————————–
VGG16 模型
VGG 11/13/16/19 常用16和19
参数 pretrained=True/False

- pretrained 为 False 的情况下,只是加载网络模型,参数都为默认参数,不需要下载
- 为 True 时需要从网络中下载,卷积层、池化层对应的参数等等(在ImageNet数据集中训练好的)
import torchvision.models
vgg16_false = torchvision.models.vgg16(pretrained=False) # 另一个参数progress显示进度条,默认为True
vgg16_true = torchvision.models.vgg16(pretrained=True)
print('ok')断点打在 print(‘ok’) 前,debug 一下,结果如图:
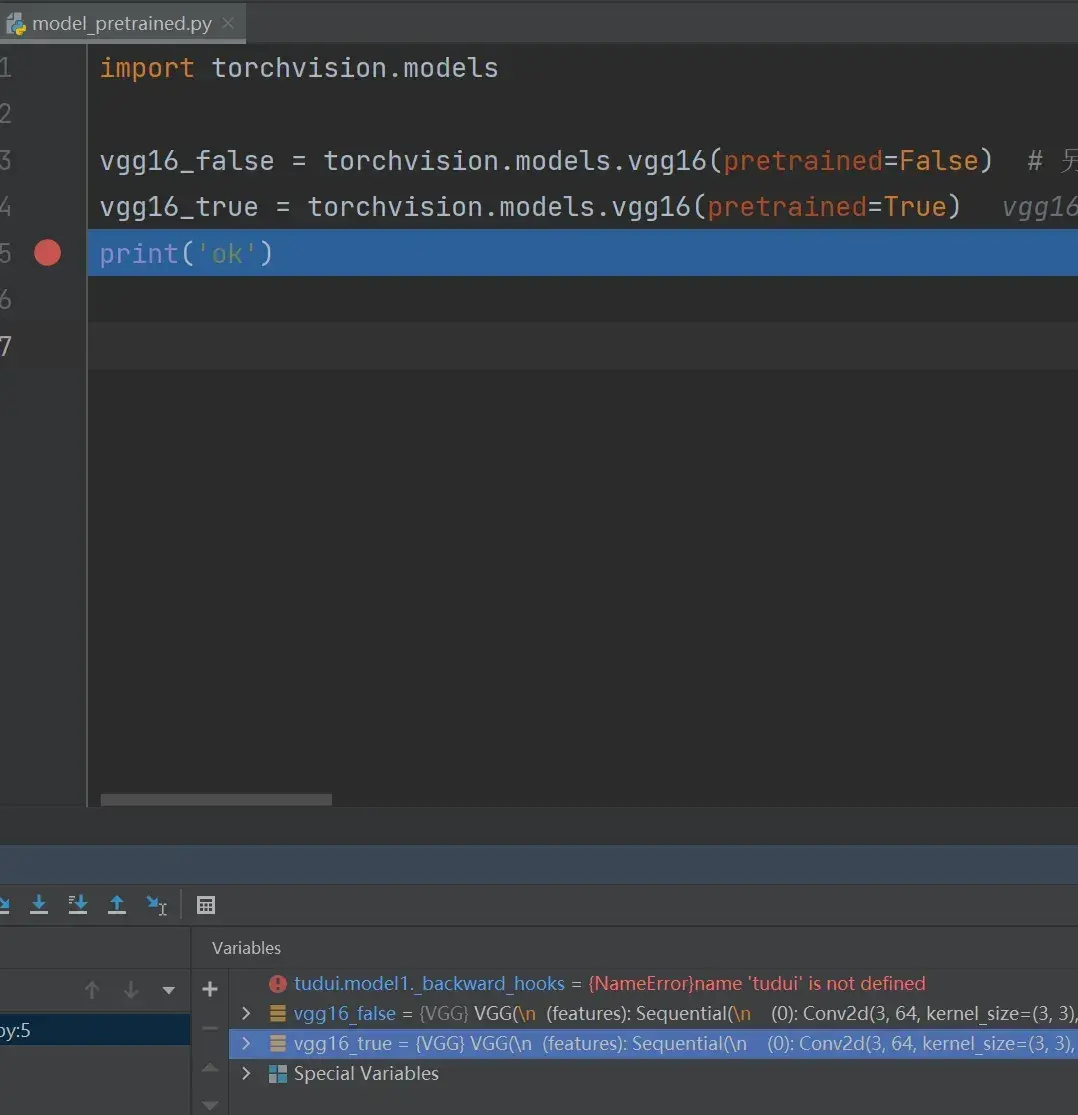
vgg16_true ——> classifier ——> Protected Attributes ——> modules ——> ‘0’(线性层) ——> weight

为 false 的情况,同理找到 weight 值:

总结:
- 设置为 False 的情况,相当于网络模型中的参数都是初始化的、默认的
- 设置为 True 时,网络模型中的参数在数据集上是训练好的,能达到比较好的效果
———————————————————————————————————————————
vgg16 网络架构
import torchvision.models
vgg16_false = torchvision.models.vgg16(pretrained=False) # 另一个参数progress显示进度条,默认为True
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)输出:
VGG(
(features): Sequential(
# 输入图片先经过卷积,输入是3通道的、输出是64通道的,卷积核大小是3×3的
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 非线性
(1): ReLU(inplace=True)
# 卷积、非线性、池化...
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
# 最后线性层输出为1000(vgg16也是一个分类模型,能分出1000个类别)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
) 所以 out_features = 1000
所以 out_features = 1000
———————————————————————————————————————————
如何利用现有网络去改动它的结构?
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)CIFAR10 把数据分成了10类,而 vgg16 模型把数据分成了 1000 类,如何应用这个网络模型呢?
- 把最后线性层的 out_features 从1000改为10
- 在最后的线性层下面再加一层,in_features为1000,out_features为10
利用现有网络去改动它的结构,避免写 vgg16
很多框架会把 vgg16 当做前置的网络结构,提取一些特殊的特征,再在后面加一些网络结构,实现功能
——————————————————————————————————————————–
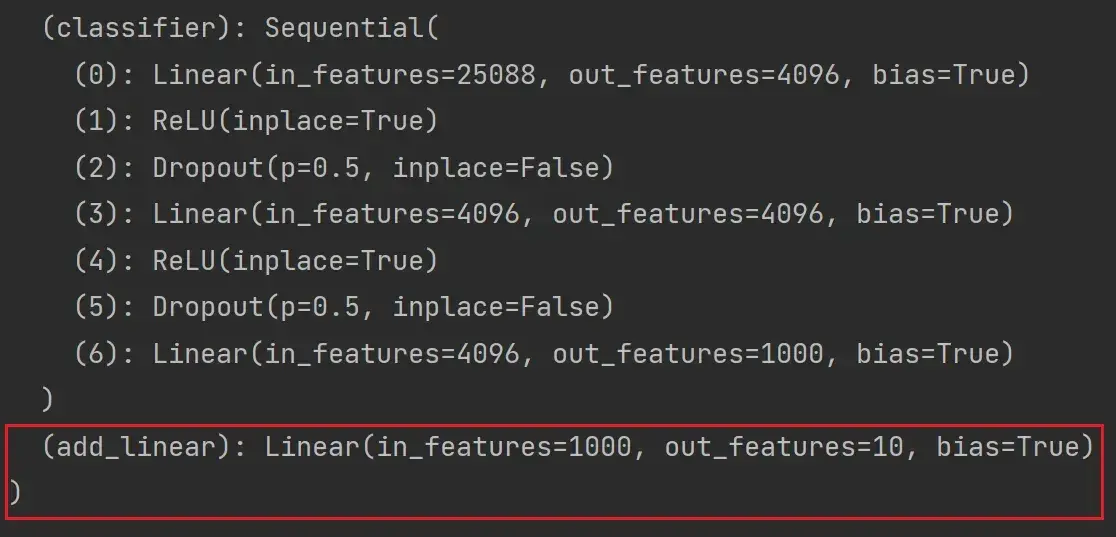
添加
以 vgg16_true 为例讲解,实现上面的第二种思路:
# 给 vgg16 添加一个线性层,输入1000个类别,输出10个类别
vgg16_true.add_module('add_linear',nn.Linear(in_features=1000,out_features=10))
print(vgg16_true)结果如图:
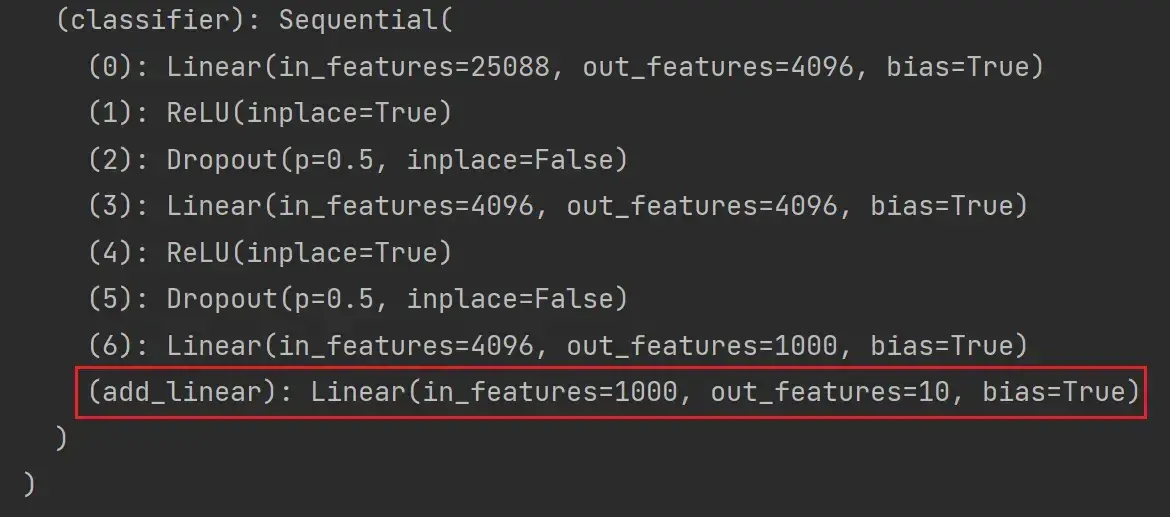
如果想将 module 添加至 classifier 里:
# 给 vgg16 添加一个线性层,输入1000个类别,输出10个类别
vgg16_true.classifier.add_module('add_linear',nn.Linear(in_features=1000,out_features=10))
print(vgg16_true)结果如图:
———————————————————————————————————————————
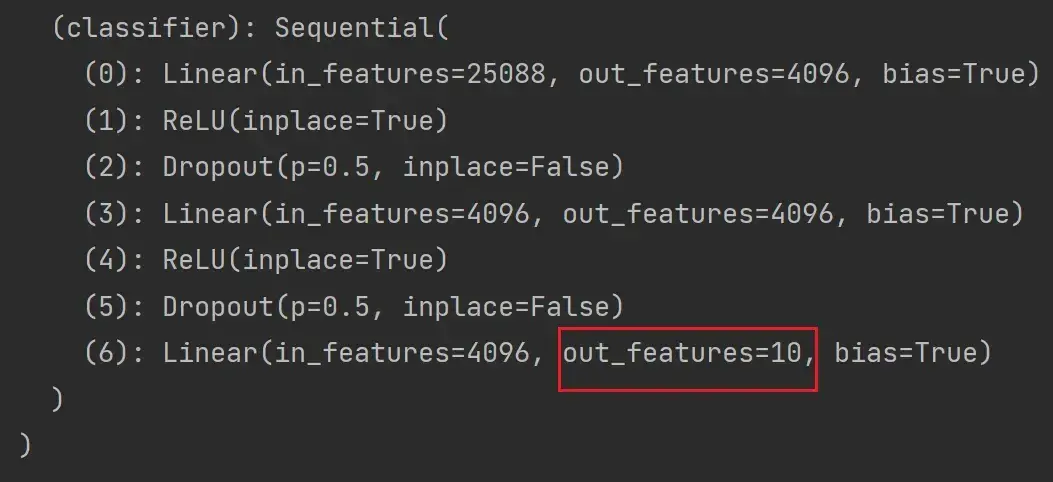
修改
以上为添加,那么如何修改呢?
以 vgg16_false 为例:
vgg16_false = torchvision.models.vgg16(pretrained=False) # 另一个参数progress显示进度条,默认为True
print(vgg16_false)结果如下:
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)想将最后一层 Linear 的 out_features 改为10:
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)结果如下:
本节:
- 如何加载现有的一些 pytorch 提供的网络模型
- 如何对网络模型中的结构进行修改,包括添加自己想要的一些网络模型结构
22. 网络模型的保存与读取
后续内容:

———————————————————————————————————————————
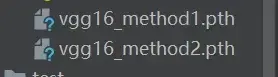
两种方式保存模型
import torch
import torchvision.models
vgg16 = torchvision.models.vgg16(pretrained=False) # 网络中模型的参数是没有经过训练的、初始化的参数方式1:不仅保存了网络模型的结构,也保存了网络模型的参数
# 保存方式1:模型结构+模型参数
torch.save(vgg16,"vgg16_method1.pth")方式2:网络模型的参数保存为字典,不保存网络模型的结构(官方推荐的保存方式,用的空间小)
# 保存方式2:模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
# 把vgg16的状态保存为字典形式(Python中的一种数据格式)运行后 src 文件夹底下会多出以下两个文件:
———————————————————————————————————————————
两种方式加载模型
方式1:对应保存方式1,打印出的是网络模型的结构
# 方式1 对应 保存方式1,加载模型
model = torch.load("vgg16_method1.pth",)
print(model) # 打印出的只是模型的结构,其实它的参数也被保存下来了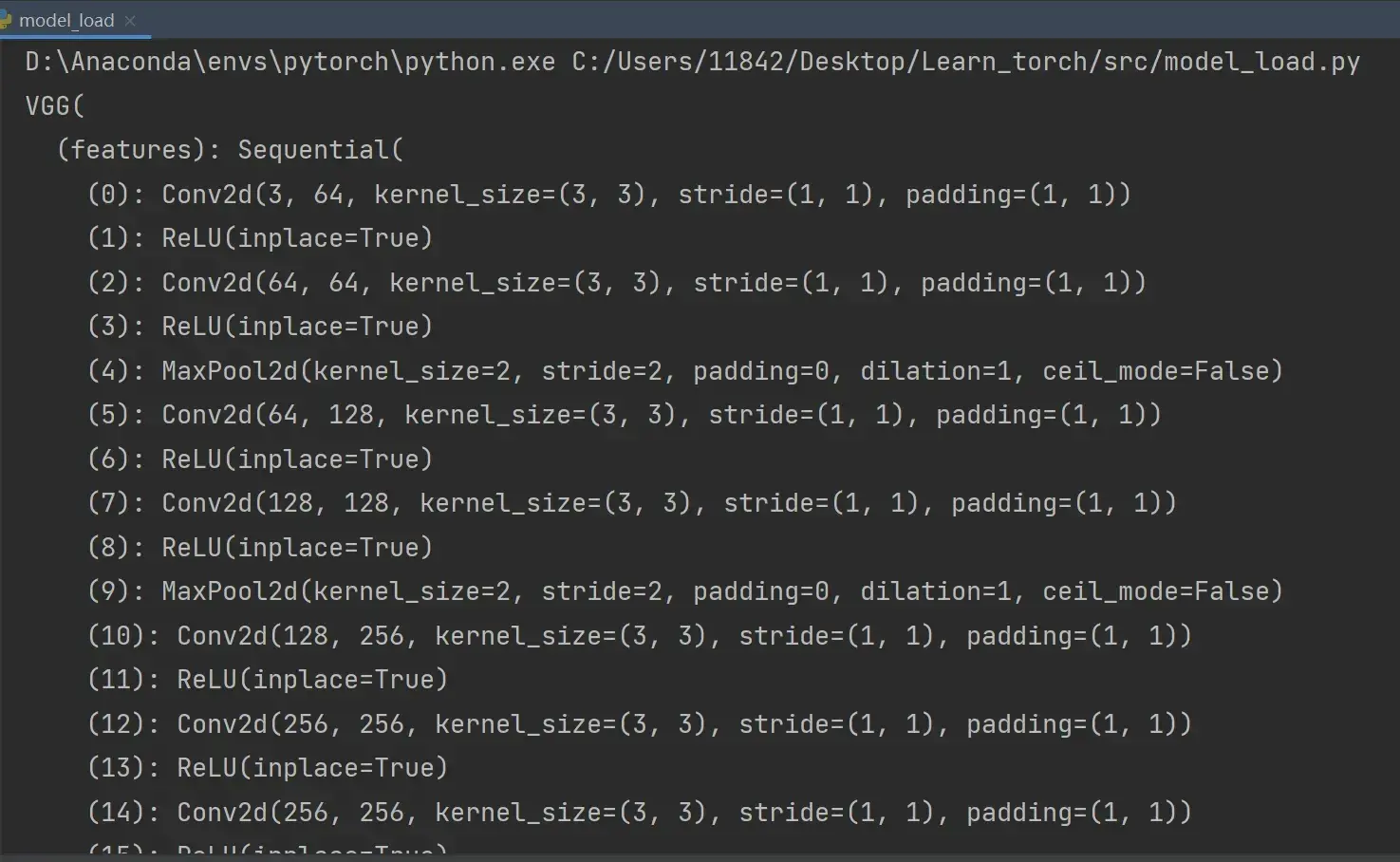
在print这句打上断点,debug一下,可以看一下模型参数
方式2:对应保存方式2,打印出的是参数的字典形式
# 方式2 加载模型
model = torch.load("vgg16_method2.pth")
print(model)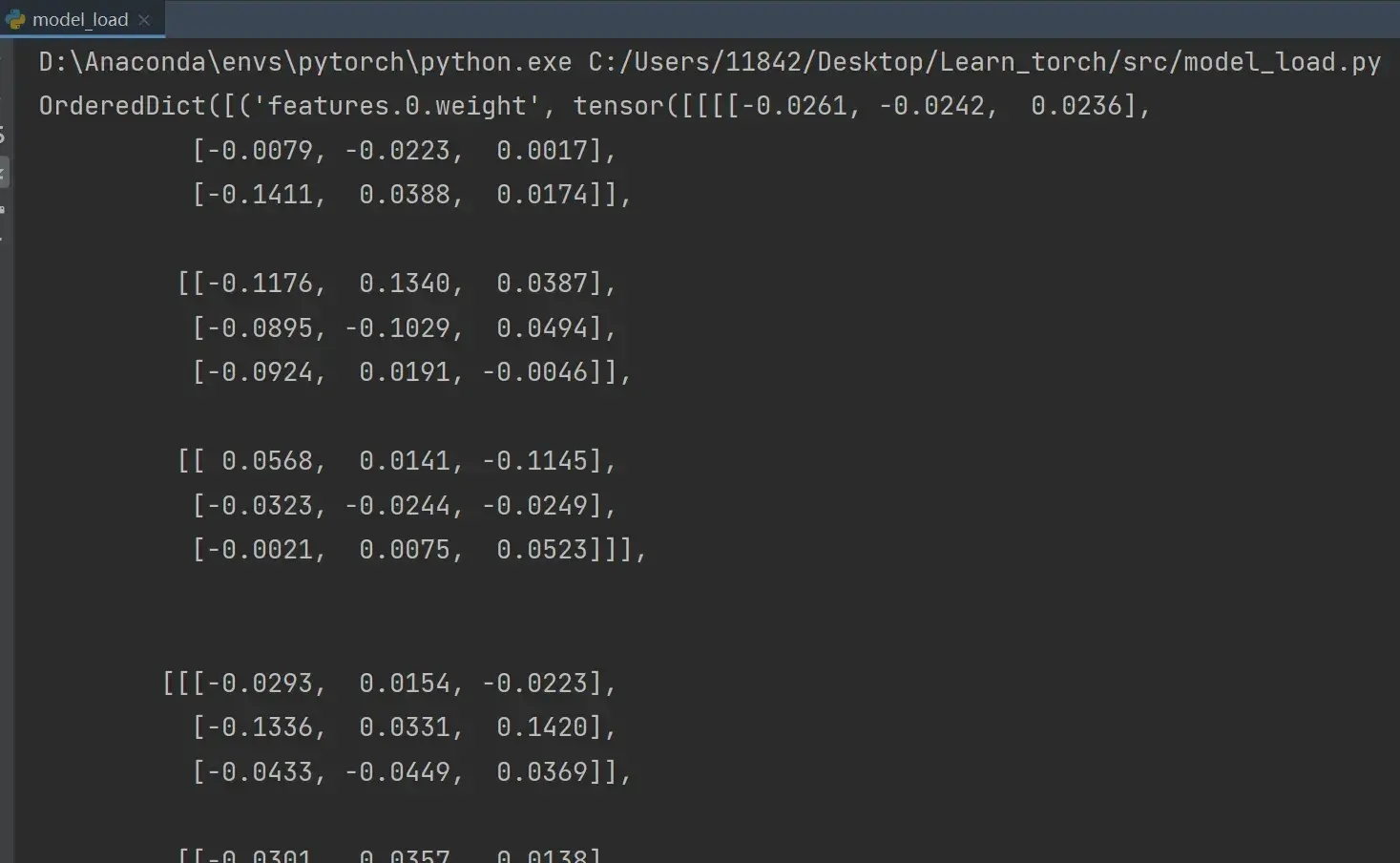
如何恢复网络模型结构?
import torchvision.models
vgg16 = torchvision.models.vgg16(pretrained=False) # 预训练设置为False
vgg16.load_state_dict(torch.load("vgg16_method2.pth")) # vgg16通过字典形式,加载状态即参数
print(vgg16)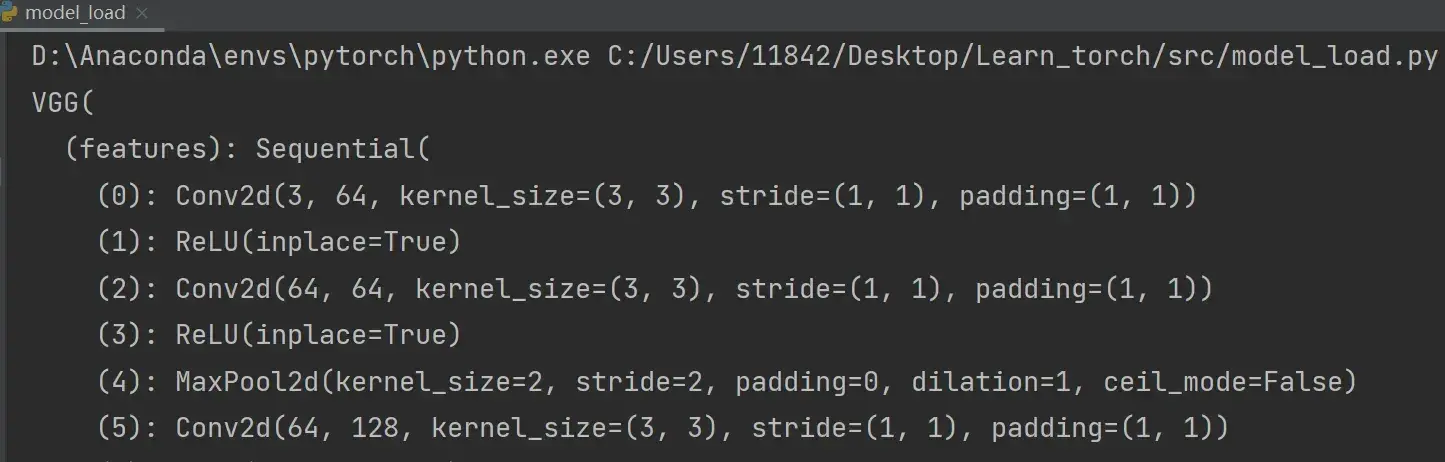
———————————————————————————————————————————
方式1 有陷阱(自己定义网络结构,没有用 vgg16 时)
用方式1保存的话,加载时要让程序能够访问到其定义模型的一种方式
问题描述
首先在 model_save.py 中写以下代码:
# 陷阱
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x): # x为输入
x = self.conv(x)
return x
tudui = Tudui() # 有一个卷积层和一些初始化的参数
torch.save(tudui,"tudui_method1.pth")运行后 src 文件夹底下多出一个文件:
![]()
再在 model_load.py 中写以下代码:
# 陷阱
import torch
model = torch.load("tudui_method1.pth")
print(model)运行后发现报错:
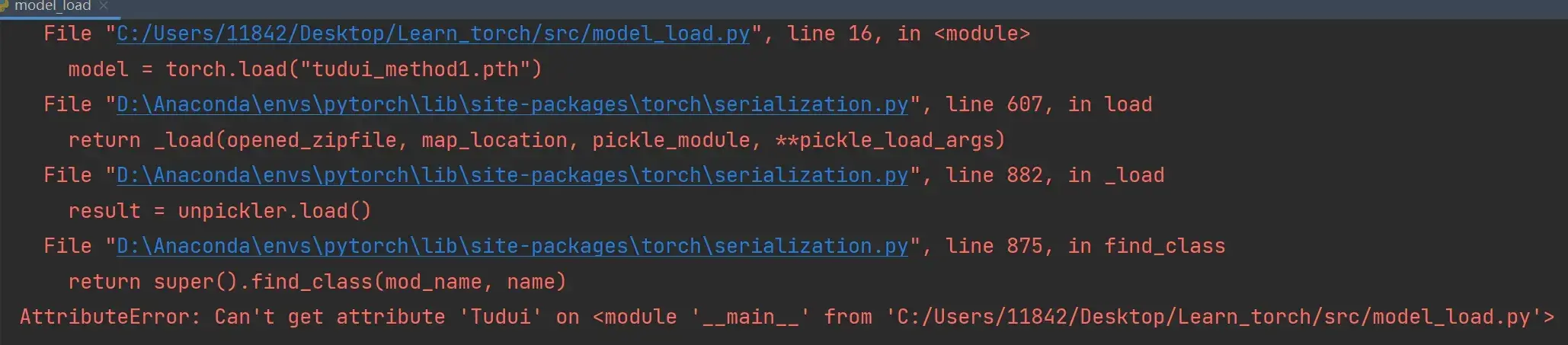
AttributeError: Can't get attribute 'Tudui' on <module '__main__' from 'C:/Users/11842/Desktop/Learn_torch/src/model_load.py'>
# 不能得到'Tudui'这个属性,因为没有这个类——————————————————————————————————————————–
解决
还是需要将 model_save.py 中的网络结构复制到 model_load.py 中,即下列代码需要复制到 model_load.py 中(为了确保加载的网络模型是想要的网络模型):
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x): # x为输入
x = self.conv(x)
return x但是不需要创建了,即在 model_load.py 中不需要写:
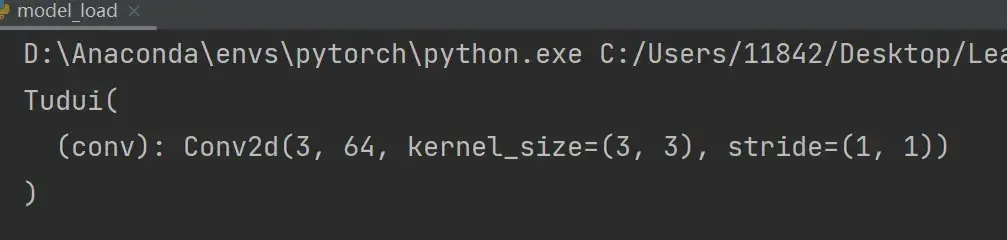
tudui = Tudui()此时 model_load.py 完整代码为:
# 陷阱
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x): # x为输入
x = self.conv(x)
return x
model = torch.load("tudui_method1.pth")
print(model)运行结果如下:
解决另法:
实际写项目过程中,直接定义在一个单独的文件中(如model_save.py),再在 model_load.py 中:
from model_save import *23. 完整的模型训练套路
以 CIFAR10 数据集为例,分类问题(10分类)
在语句后面按 Ctrl + d 可以复制这条语句
———————————————————————————————————————————
model.py 文件代码
import torch
from torch import nn
# 搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
# 测试网络的验证正确性
tudui = Tudui()
input = torch.ones((64,3,32,32)) # batch_size=64(代表64张图片),3通道,32x32
output = tudui(input)
print(output.shape)运行结果如下:
![]()
返回64行数据,每一行数据有10个数据,代表每一张图片在10个类别中的概率
———————————————————————————————————————————
train.py 文件代码
(与 model.py 文件必须在同一个文件夹底下)
import torchvision.datasets
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
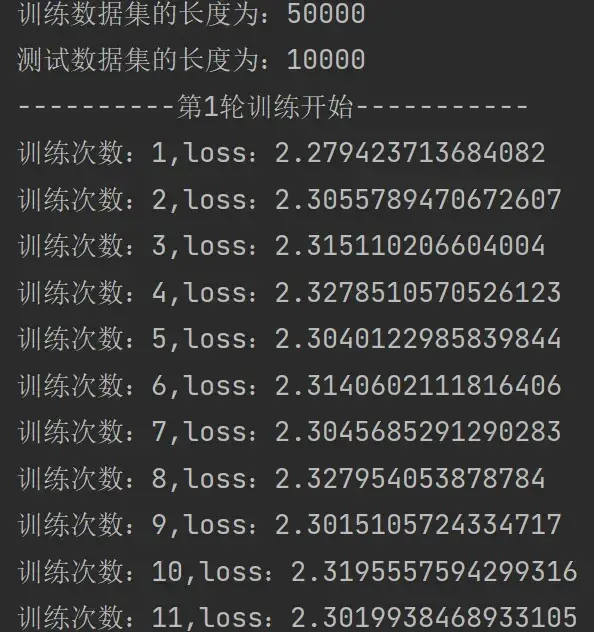
for i in range(epoch):
print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader: # 从训练的dataloader中取数据
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
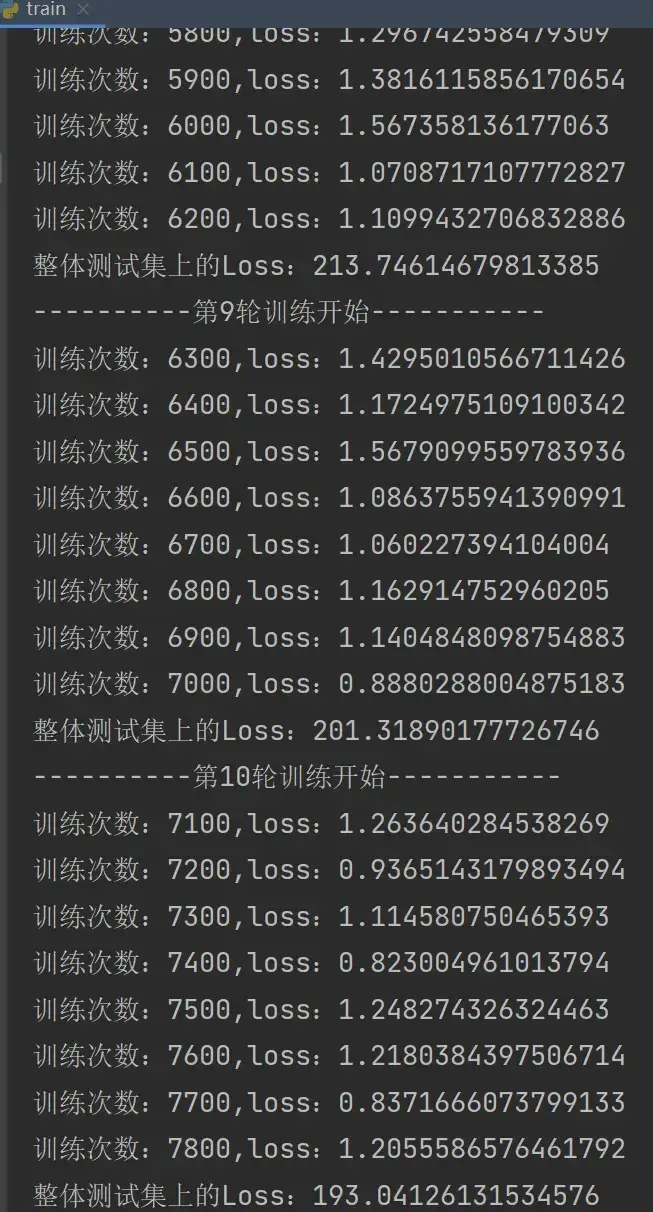
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))运行结果如下:
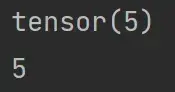
print(a) 和 print(a.item()) 的区别
import torch a = torch.tensor(5) print(a) print(a.item())
———————————————————————————————————————————
如何知道模型是否训练好,或达到需求?
每次训练完一轮就进行测试,以测试数据集上的损失或正确率来评估模型有没有训练好
测试过程中不需要对模型进行调优,利用现有模型进行测试,所以有以下命令:
with torch.no_grad(): 在上述 train.py 代码后继续写:
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字,所以要.item()一下
print("整体测试集上的Loss:{}".format(total_test_loss))结果如下:
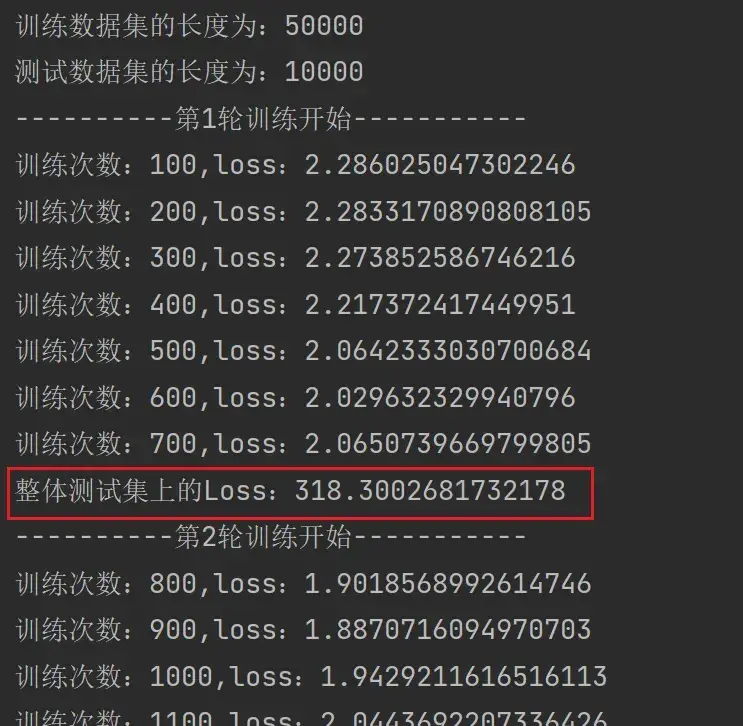
此处为了使测试的 loss 结果易找,在 train.py 中添加了一句 if 的代码,使train每训练100轮才打印1次:
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))完整代码
import torchvision.datasets
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
for i in range(epoch):
print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
print("整体测试集上的Loss:{}".format(total_test_loss))
———————————————————————————————————————————
与 TensorBoard 结合
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step += 1
writer.close()
运行结果:
在 Terminal 里输入:
tensorboard --logdir=logs_train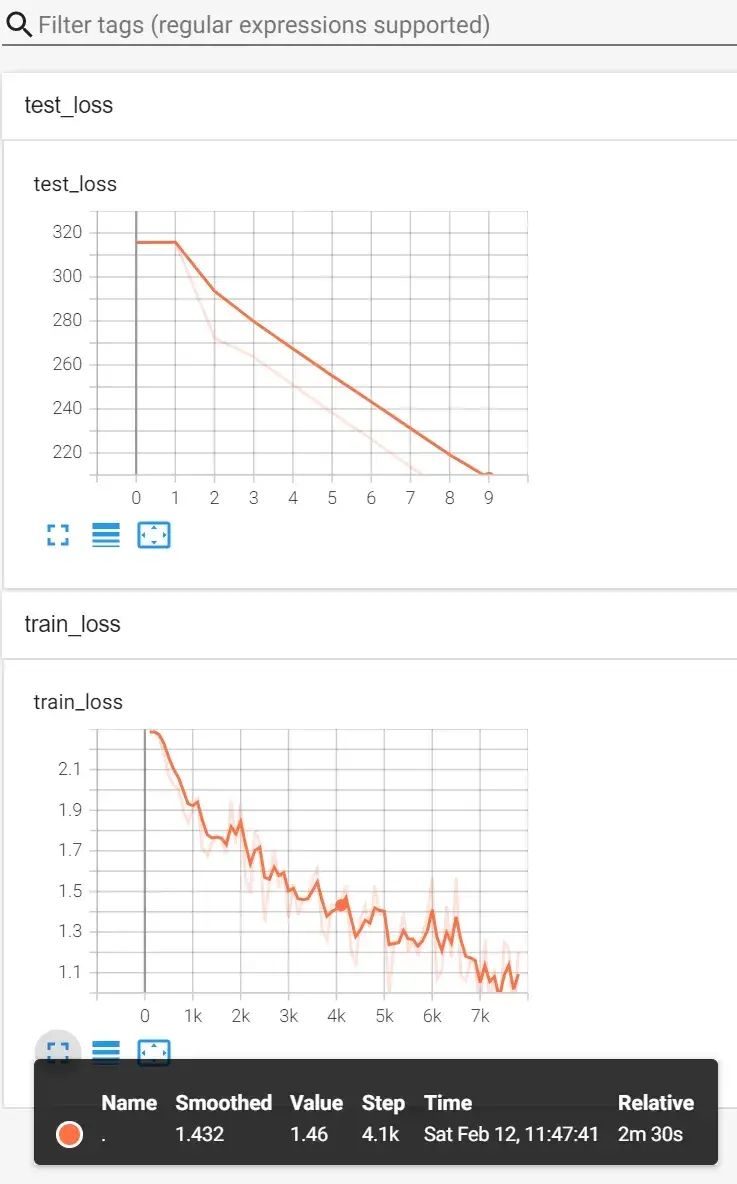
———————————————————————————————————————————
保存每一轮训练的模型
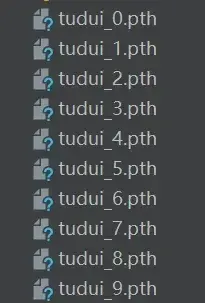
添加两句代码:
torch.save(tudui,"tudui_{}.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()运行后:
———————————————————————————————————————————
正确率的实现(对分类问题)
即便得到整体测试集上的 loss,也不能很好说明在测试集上的表现效果
- 在分类问题中可以用正确率表示(下述代码改进)
- 在目标检测/语义分割中,可以把输出放在tensorboard里显示,看测试结果
例子:

第一步:
import torch
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
print(outputs.argmax(1)) # 0或1表示方向,1为横向比较大小. 运行结果:tensor([1, 1])
第二步:
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print(preds == targets) # tensor([False, True])
print(sum(preds == targets).sum()) # tensor(1),对应位置相等的个数上例说明了基本用法,现对原问题的代码再进一步优化,计算整体正确率:
# 测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
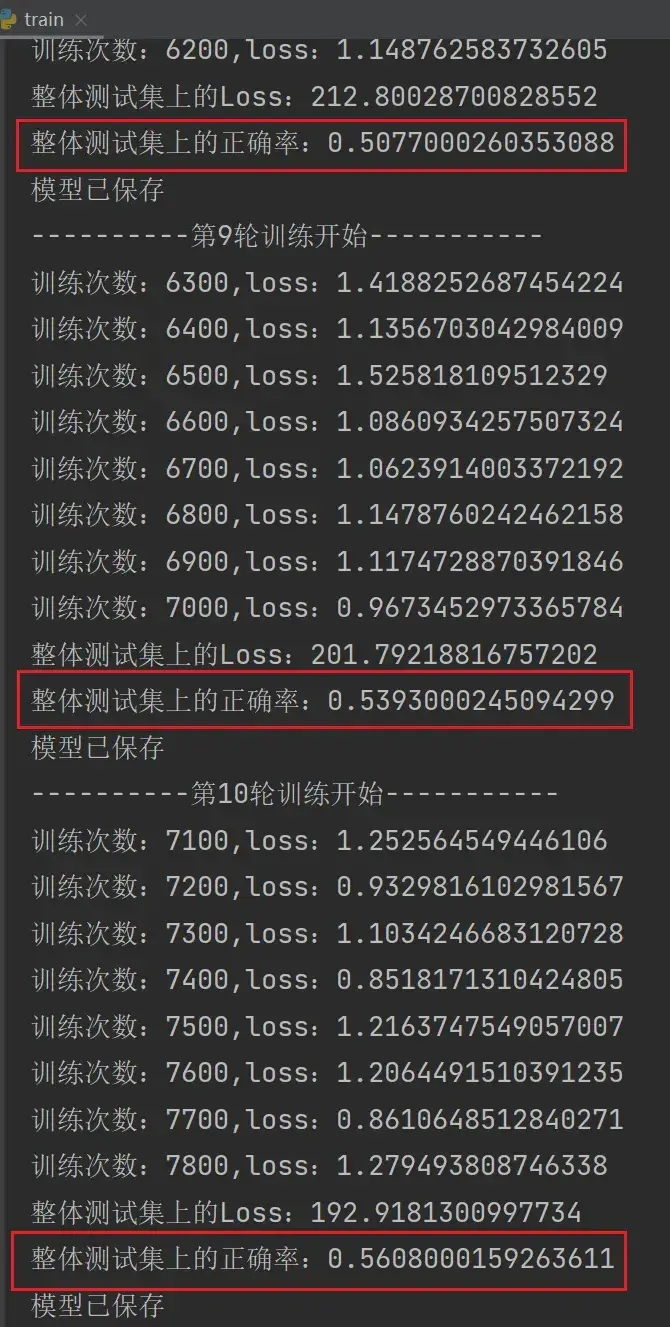
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/imgs.size(0)))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/imgs.size(0),total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_{}.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()运行结果:
在 Terminal 里输入:
tensorboard --logdir=logs_train打开网址 http://localhost:6006/ :
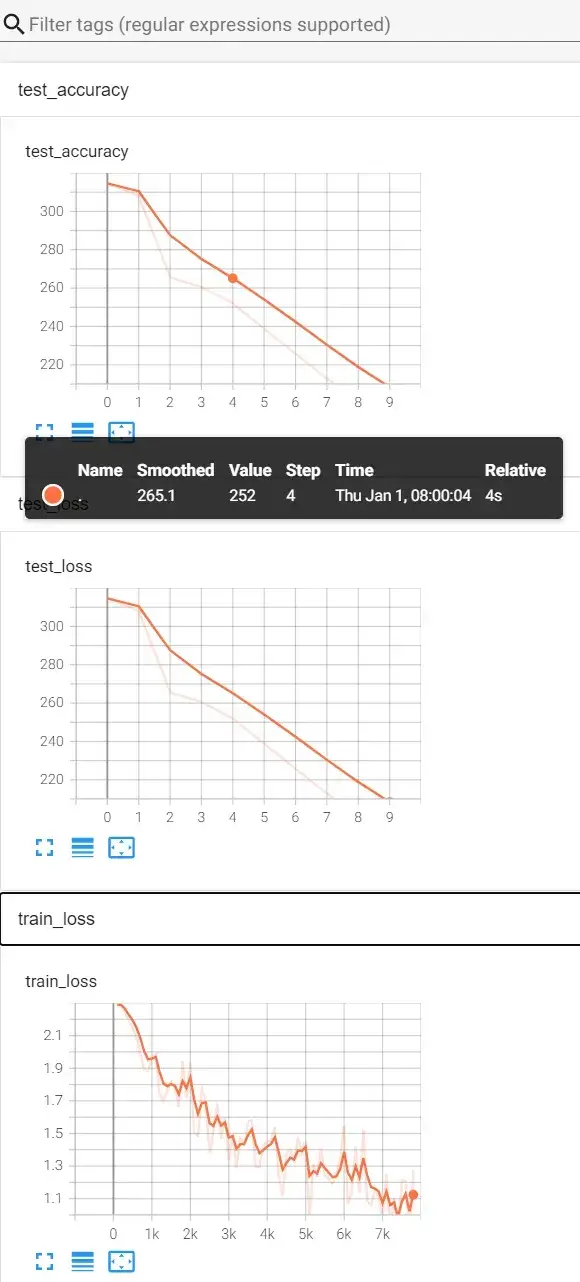
———————————————————————————————————————————
train.py 完整代码
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_{}.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()———————————————————————————————————————————
model.train() 和 model.eval()
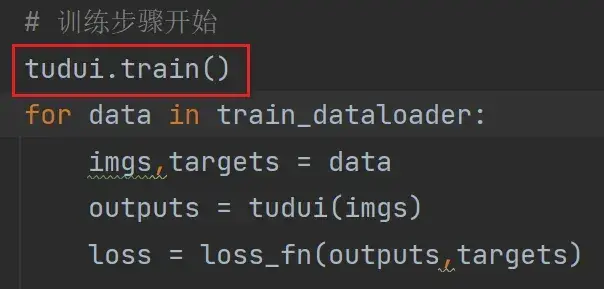
训练步骤开始之前会把网络模型(我们这里的网络模型叫 tudui)设置为train,并不是说把网络设置为训练模型它才能够开始训练
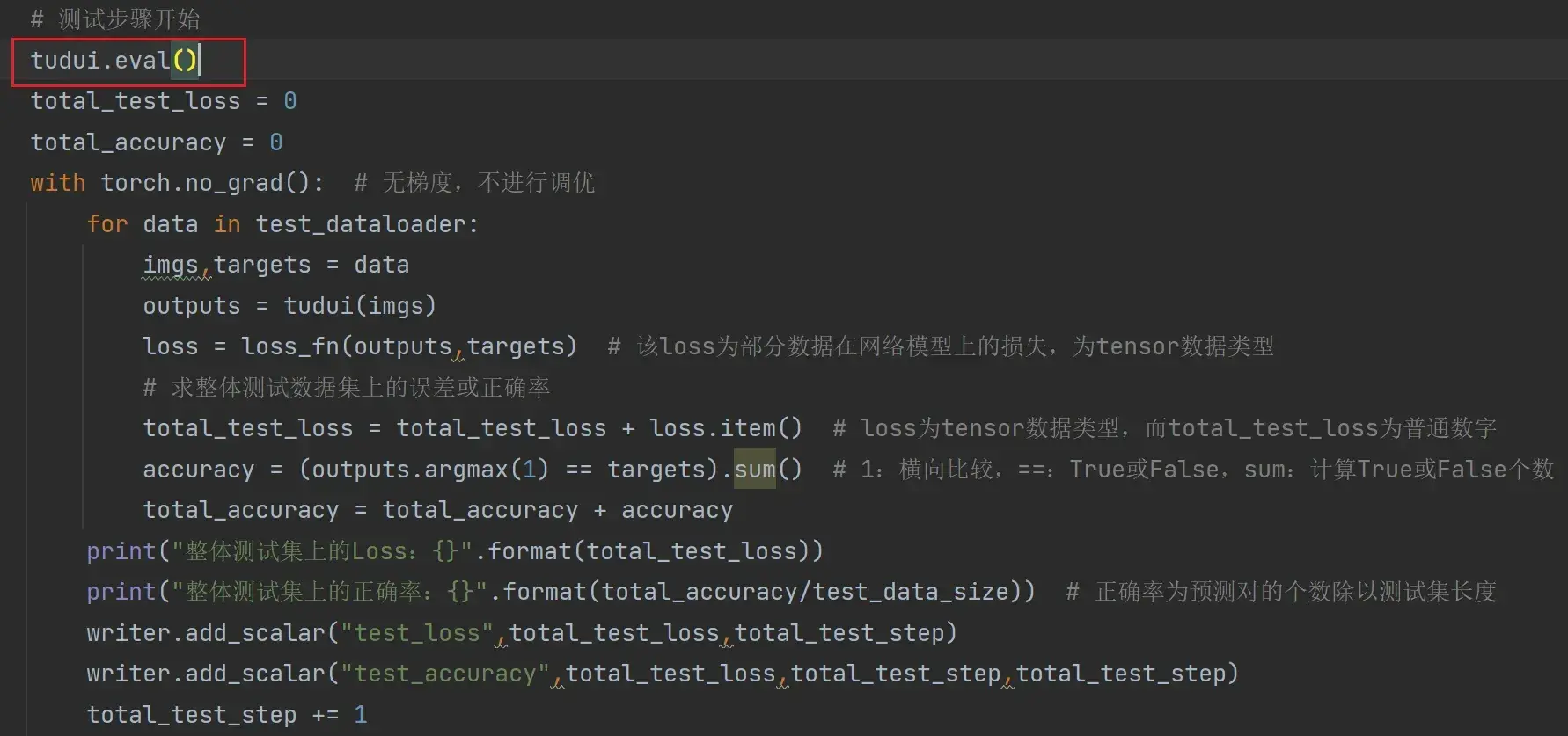
测试网络前写 网络.eval(),并不是说需要这一行才能把网络设置成 eval 状态,才能进行网络测试
——————————————————————————————————————————–
作用
这两句不写网络依然可以运行,它们的作用是:
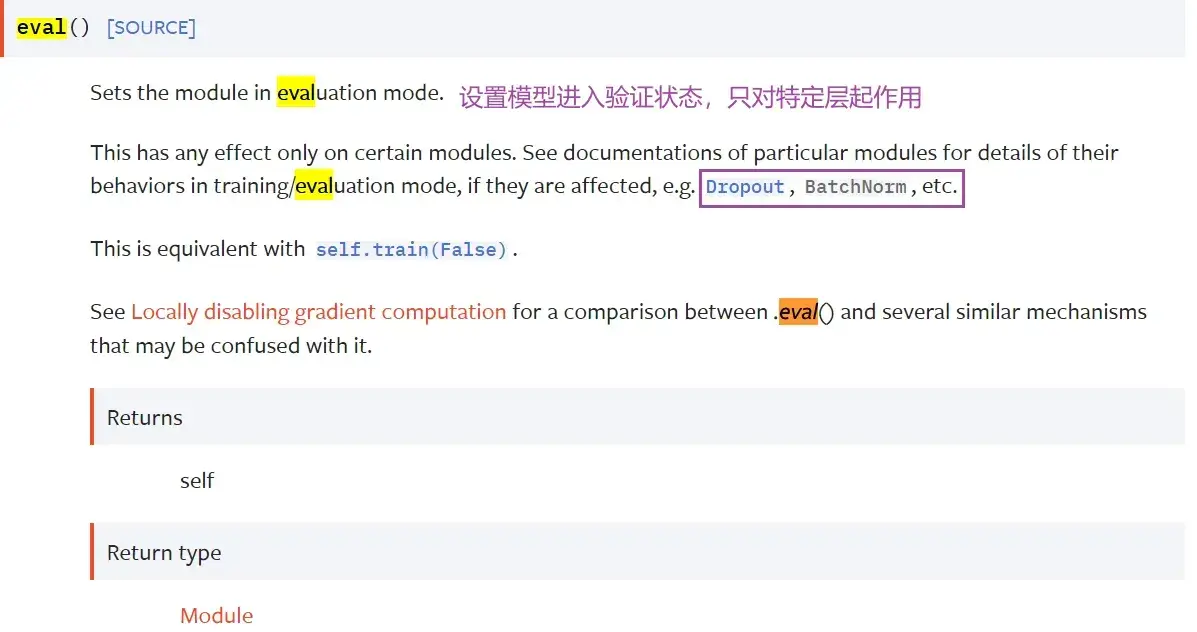 本节写的案例没有 Dropout 层或 BatchNorm 层,所以有没有这两行无所谓
本节写的案例没有 Dropout 层或 BatchNorm 层,所以有没有这两行无所谓
如果有这些特殊层,一定要调用
———————————————————————————————————————————
回顾案例
首先,要准备数据集,准备对应的 dataloader
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)然后,创建网络模型、损失函数、优化器,设置训练中的一些参数、训练轮数 epoch(为了能够进行多次训练)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数调用
tudui.train() 使网络进入训练状态,从训练的 dataloader 中不断取数据,算出误差,放到优化器中进行优化,采用某种特定的方式展示输出,一轮结束后或特定步数后进行测试
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)测试过程中可以设置
tudui.eval() 要设置
with torch.no_grad(): 让网络模型中的参数都没有,因为我们只需要进行测试,不需要对网络模型进行调整,更不需要利用梯度来优化
从测试数据集中取数据,计算误差,构建特殊指标显示出来
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy最后可以通过一些方式来展示一下训练的网络在测试集上的效果
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1在特定步数或某一轮可以保存模型,保存模型的方式是之前讲的方式1:
torch.save(tudui,"tudui_{}.pth".format(i))回忆官方推荐的方式2:
torch.save(tudui.state_dict,"tudui_{}.pth".format(i))(将网络模型的状态转化为字典型,展示它的特定保存位置)
24. 利用GPU训练
两种方式实现代码在GPU上训练:
第一种使用GPU训练的方式

网络模型:
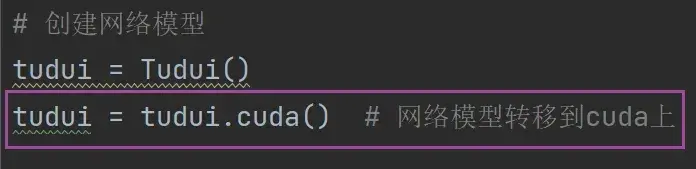
数据(包括输入、标注):
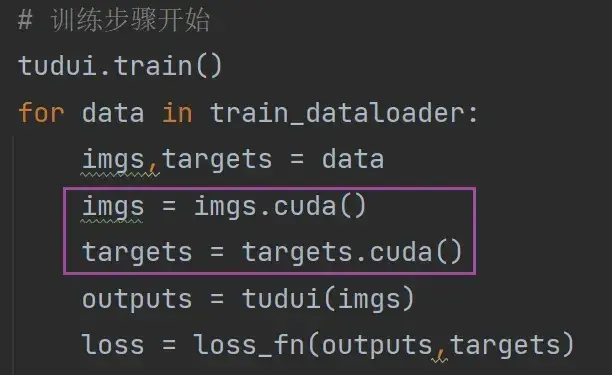

损失函数:

更好的写法:
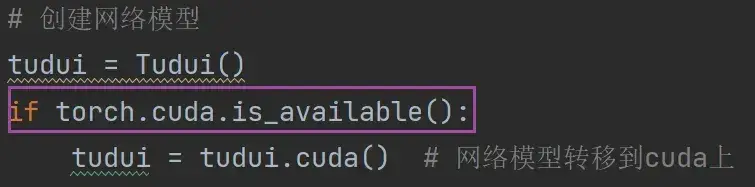
其他地方同理加上
这种写法在CPU和GPU上都可以跑,优先在GPU上跑
———————————————————————————————————————————
比较CPU/GPU训练时间
为了比较时间,引入 time 这个 package
对于CPU
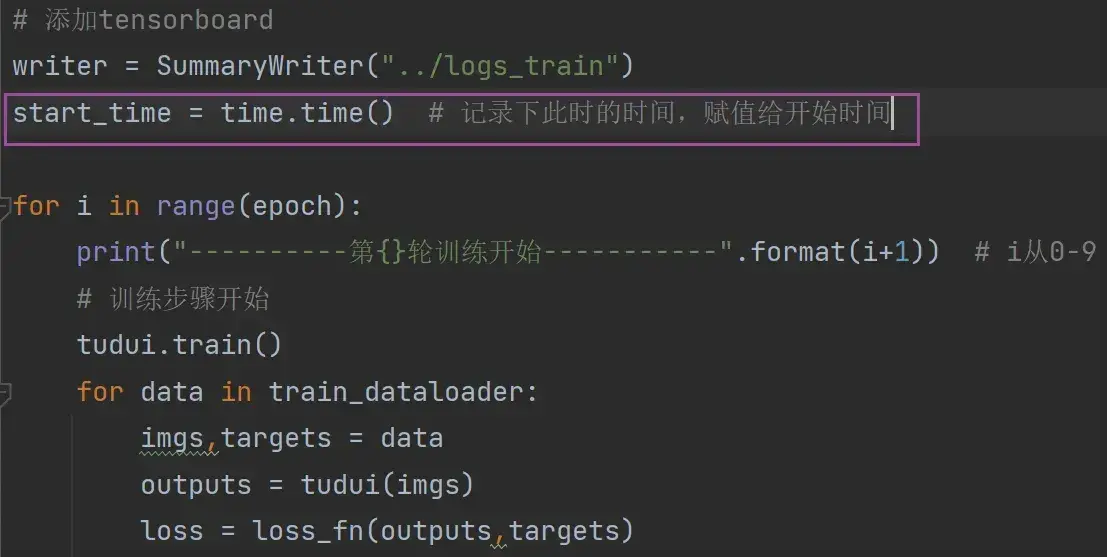
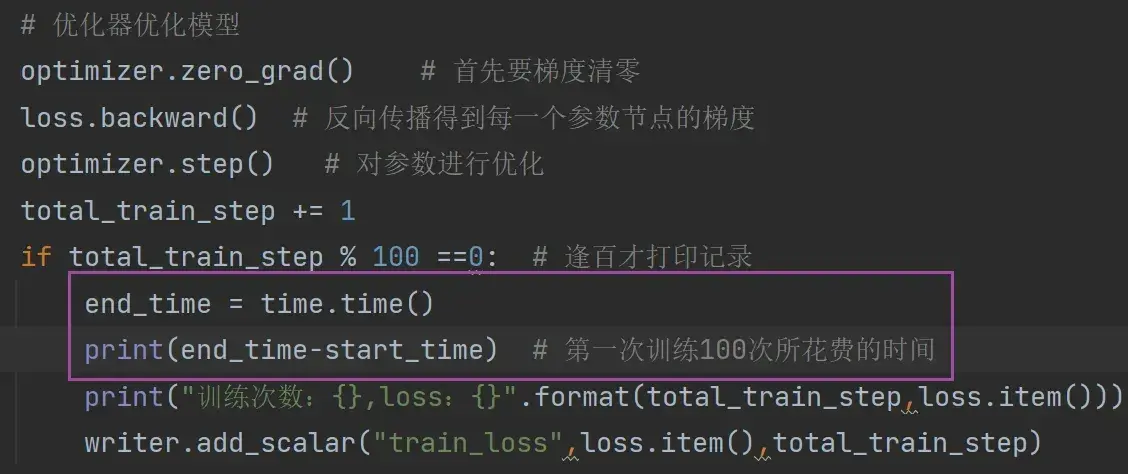
运行 train.py,可以看到它运行了4.53s
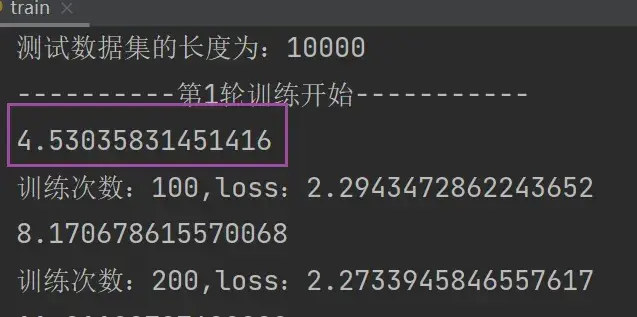
对于GPU
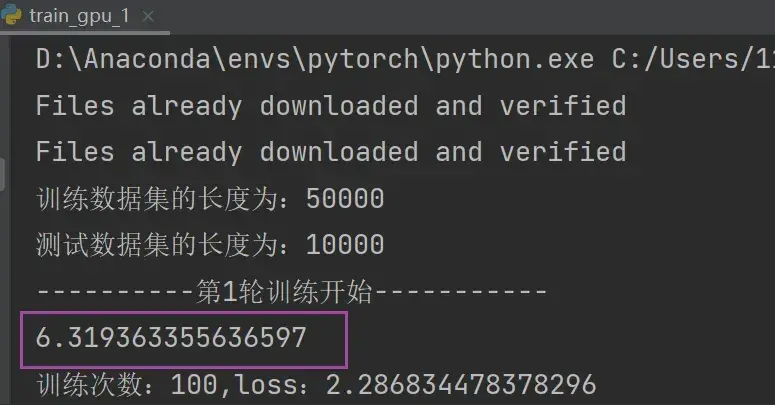
时间竟然比CPU长(我不理解orz)
———————————————————————————————————————————
查看GPU信息
在 Terminal 里输入
nvidia-smi会出现一些GPU的信息
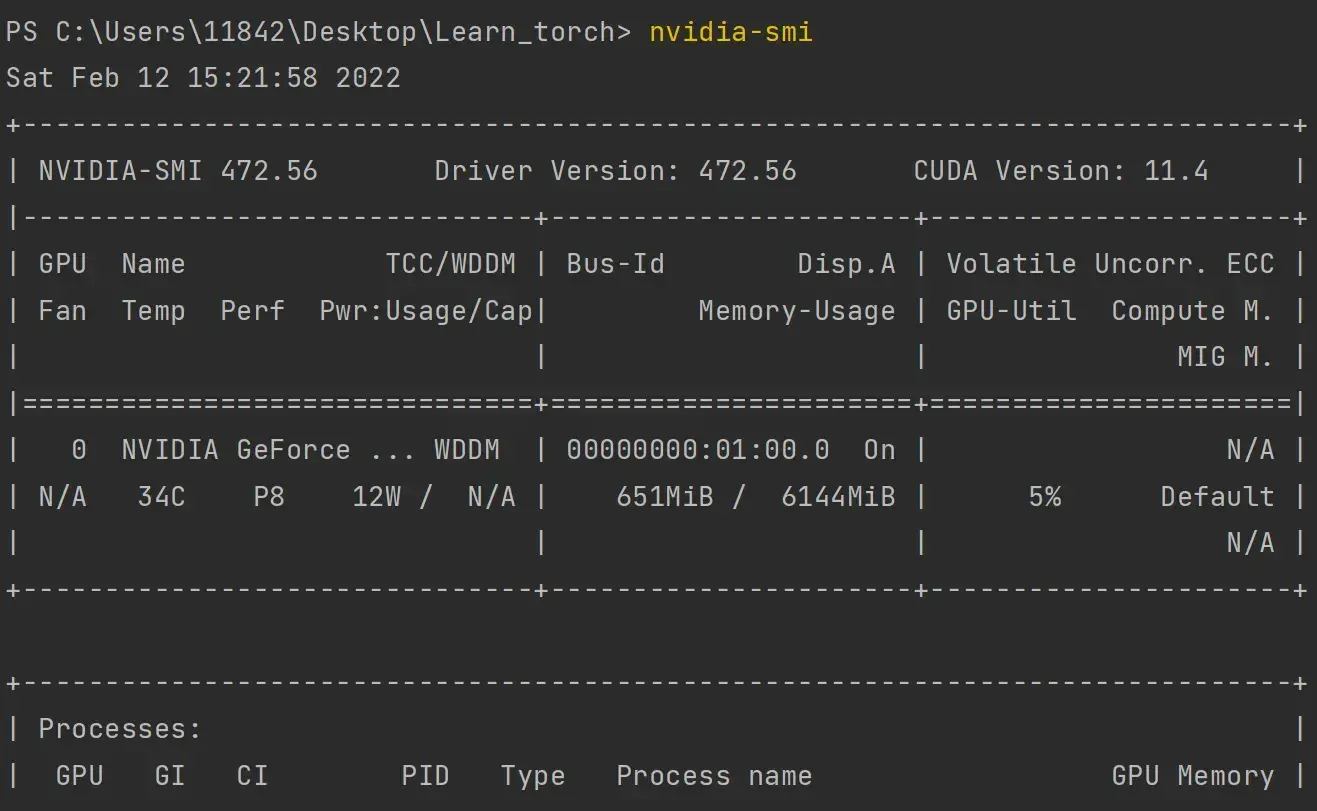
———————————————————————————————————————————
Google Colab
Google 为我们提供了一个免费的GPU,默认提供的环境当中就有Pytorch
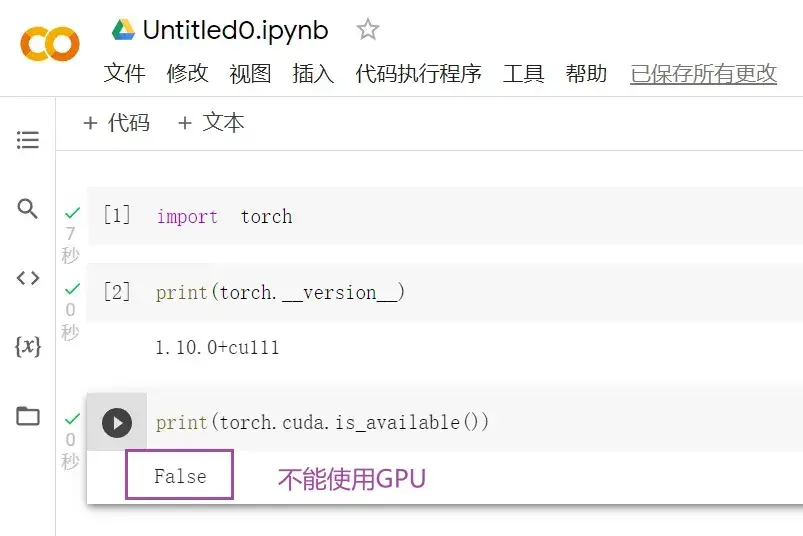
如何使用GPU?
修改 ——> 笔记本设置 ——> 硬件加速器选择GPU(每周免费使用30h)
使用GPU后会重新启动环境
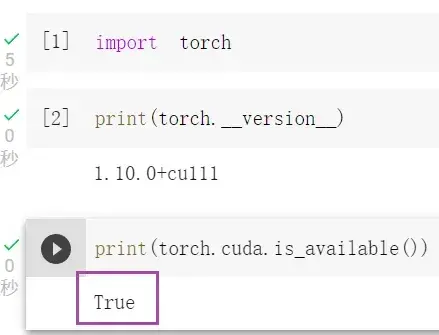
将 train_gpu_1.py 代码复制进去运行,速度很快,结果如下:
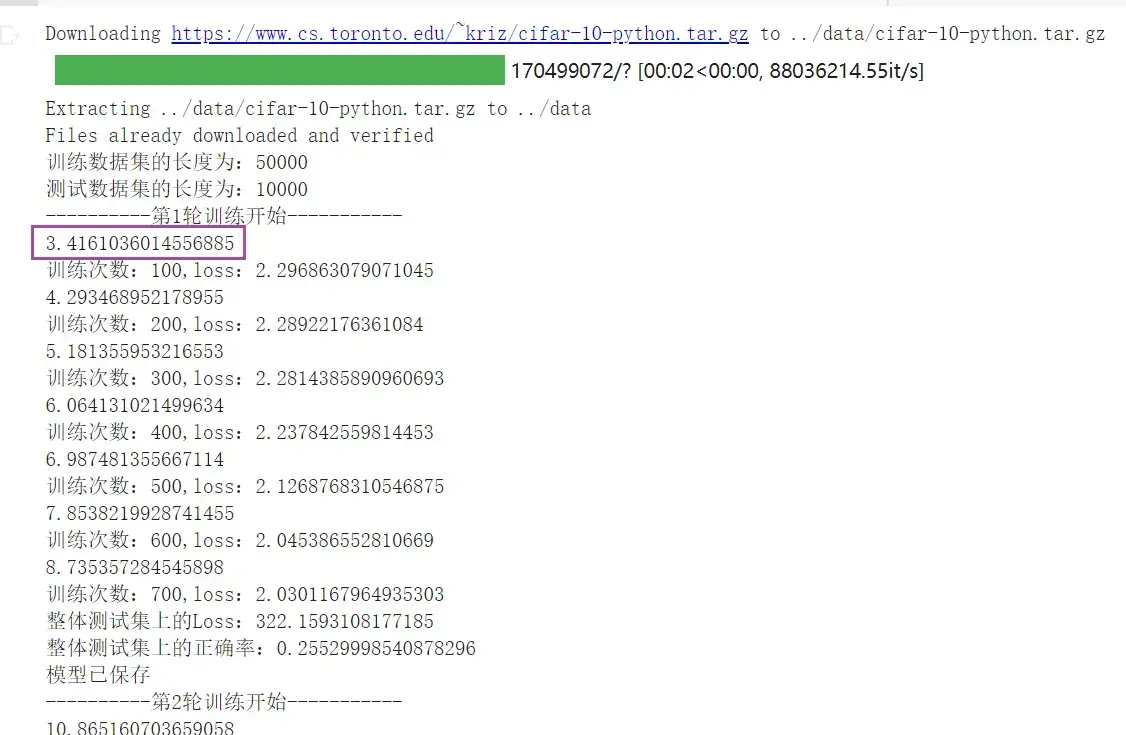
查看GPU配置
在 Google Colab 上运行 terminal 中运行的东西,在语句前加 !(感叹号)
———————————————————————————————————————————
第二种使用GPU训练的方式(更常用)

以下两种写法对于单显卡来说等价:
device = torch.device("cuda")
device = torch.device("cuda:0")语法糖(一种语法的简写),程序在 CPU 或 GPU/cuda 环境下都能运行:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
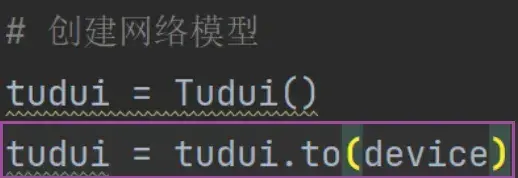

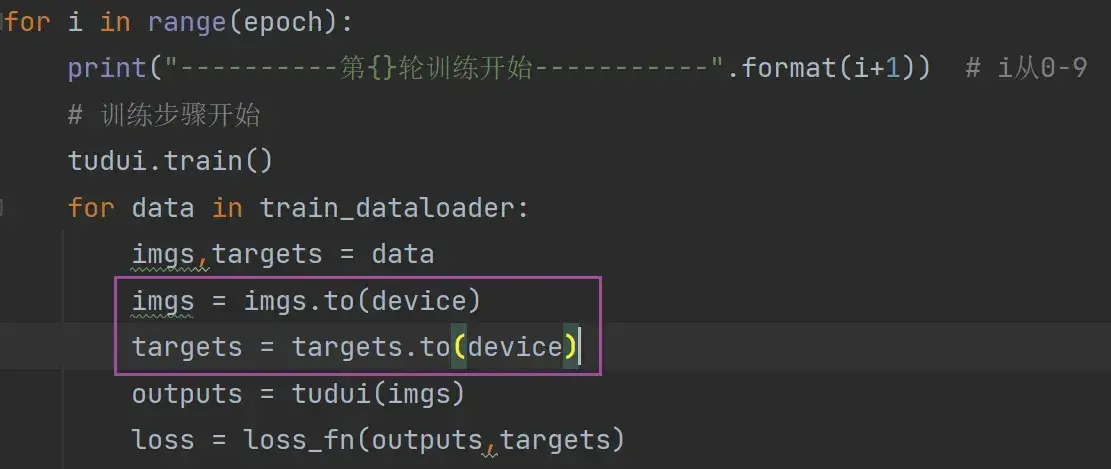
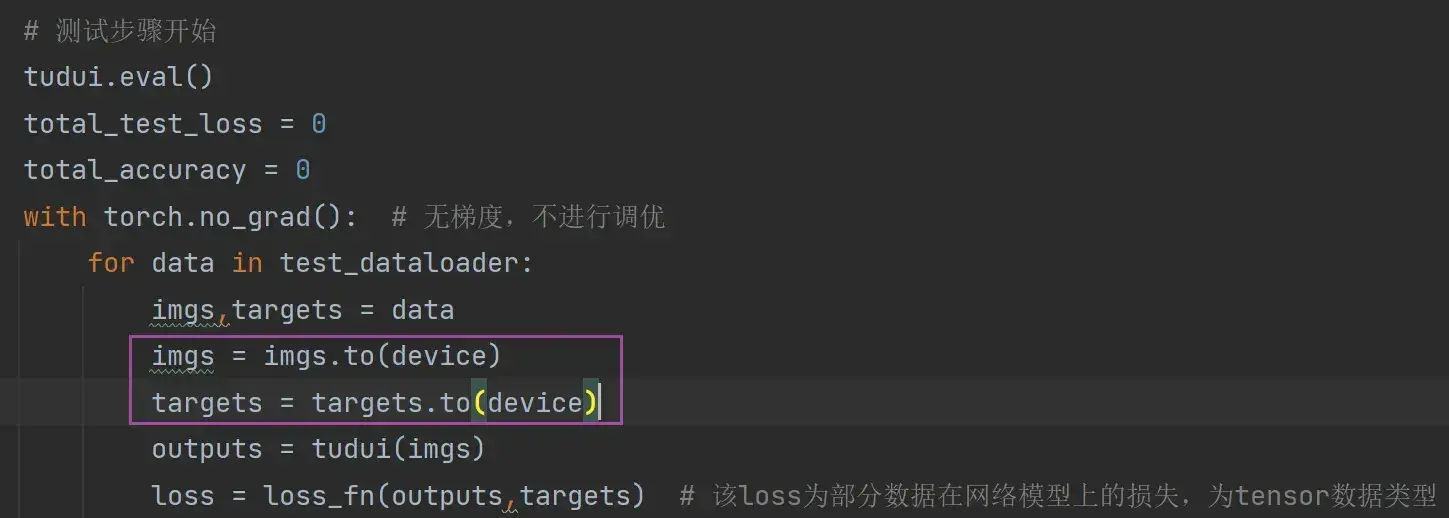
网络模型、损失函数都不需要另外赋值,直接 .to(device) 就可以
但是数据(图片、标注)需要另外转移之后再重新赋值给变量
25. 完整的模型验证(测试、demo)套路
核心:利用已经训练好的模型,给它提供输入进行测试(类似之前案例中测试集的测试部分)
———————————————————————————————————————————
示例
Resize():
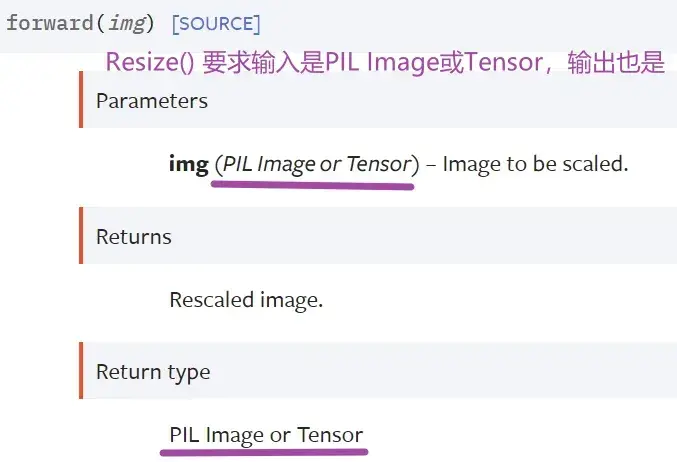
随便在网络上找图片,通过 Resize() 使图片符合模型
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
image_path = "../imgs/dog.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0>
# image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片
# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Image
torchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])
# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
# 然后加载网络模型
model = torch.load("tudui_0.pth") # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)
output = model(image)
print(output)运行会报错,报错提示如下:
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [32, 3, 5, 5], but got 3-dimensional input of size [3, 32, 32] instead
原因:要求是四维的输入 [batch_size,channel,length,width],但是获得的图片是三维的 —— 图片没有指定 batch_size(网络训练过程中是需要 batch_size 的,而图片输入是三维的,需要reshape() 一下)
解决:torch.reshape() 方法
在上述代码后面加上:
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad(): # 节约内存和性能
output = model(image)
print(output)
运行结果:
1.3220 概率最大,预测的是第六类
print(output.argmax(1))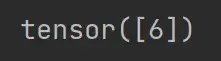
——————————————————————————————————————————–

怎么找到?
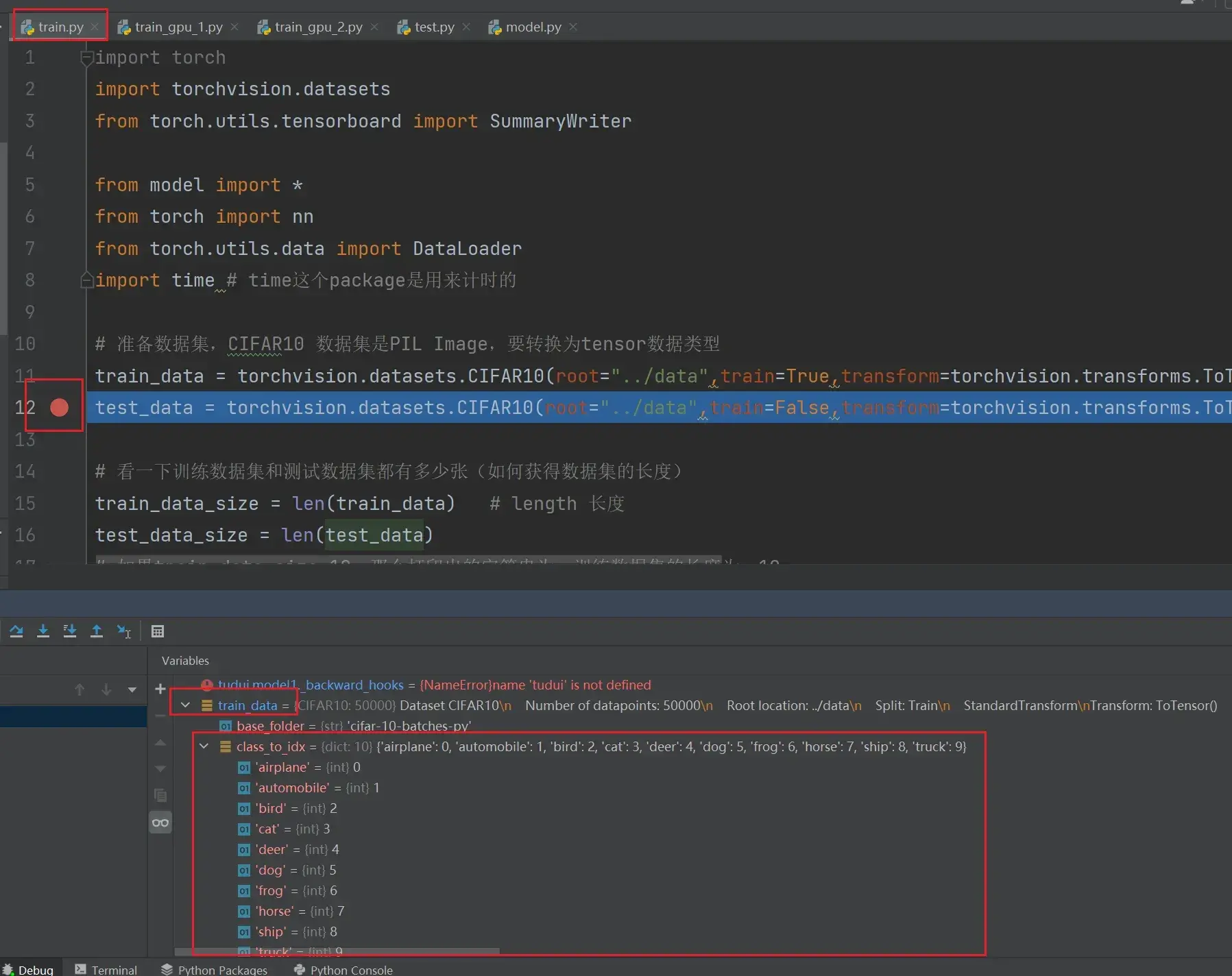
第六类对应的是 frog(青蛙)
———————————————————————————————————————————
预测错误的原因可能是训练次数不够多,在 Google Colab 里,将训练轮数 epoch 改为 30 次,完整代码(train.py):
import torch
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch import nn
from torch.utils.data import DataLoader
import time # time这个package是用来计时的
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
device = torch.device("cuda")
print(device)
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
# 创建网络模型
tudui = Tudui()
tudui.to(device)
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
loss_fn.to(device)
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 30 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time() # 记录下此时的时间,赋值给开始时间
for i in range(epoch):
print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
end_time = time.time()
print(end_time - start_time) # 第一次训练100次所花费的时间
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size)) # 正确率为预测对的个数除以测试集长度
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_test_loss,total_test_step,total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_{}_gpu.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()
运行结果:
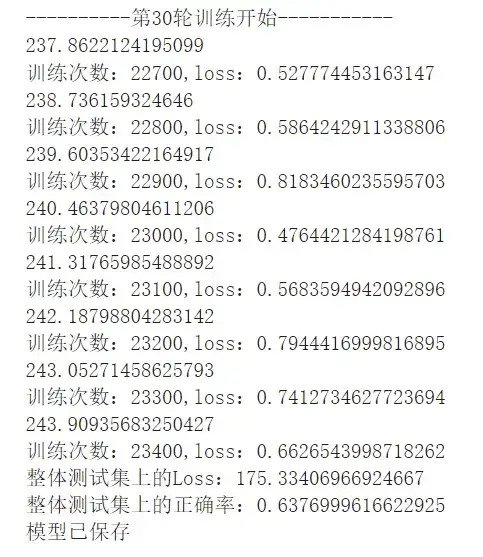
下载后复制到 PyCharm 中 Learn_Torch 的 src 文件夹下,然后将之前 test.py 中的路径修改为:
model = torch.load("tudui_29_gpu.pth")运行后报错,报错提示:
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor原因:采用GPU训练的模型,在CPU上加载,要从GPU上映射到CPU上(在不同环境中加载已经训练好的模型,需要经过映射)
解决:
model = torch.load("tudui_29_gpu.pth",map_location=torch.device('cpu'))——————————————————————————————————————————–
test.py(把训练模型运用到实际环境中)完整代码
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0>
# image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片
# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Image
torchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])
# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
# 然后加载网络模型
model = torch.load("tudui_29_gpu.pth",map_location=torch.device('cpu')) # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))——————————————————————————————————————————–
示例二
再以飞机的图片为例(airplane.png 保存在 imgs 文件夹里)
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0>
# image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片
# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Image
torchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])
# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
# 然后加载网络模型
model = torch.load("tudui_29_gpu.pth",map_location=torch.device('cpu')) # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1)) # 把输出转换为一种利于解读的方式运行结果:
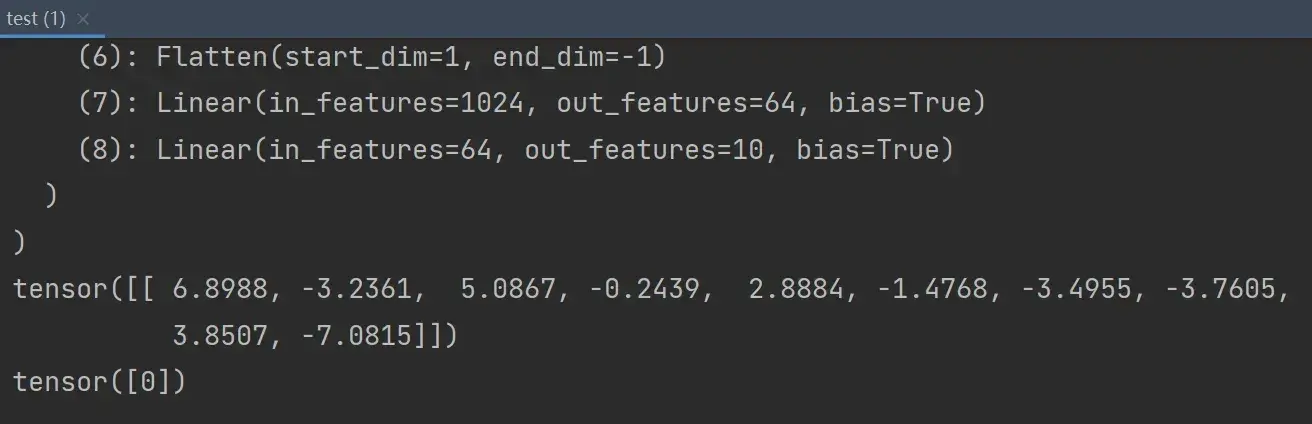
第 0 类就是 airplane,预测正确
注意:
model.eval() # 模型转化为测试类型
with torch.no_grad():这两行不写也可以,但为了养成良好的代码习惯,最好写上。如果网络模型中正好有 Dropout 或 BatchNorm 时,不写的话预测就会有问题
26. 看看开源项目
GitHub – junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch
README.md
先读 README.md(怎么安装、注意事项)
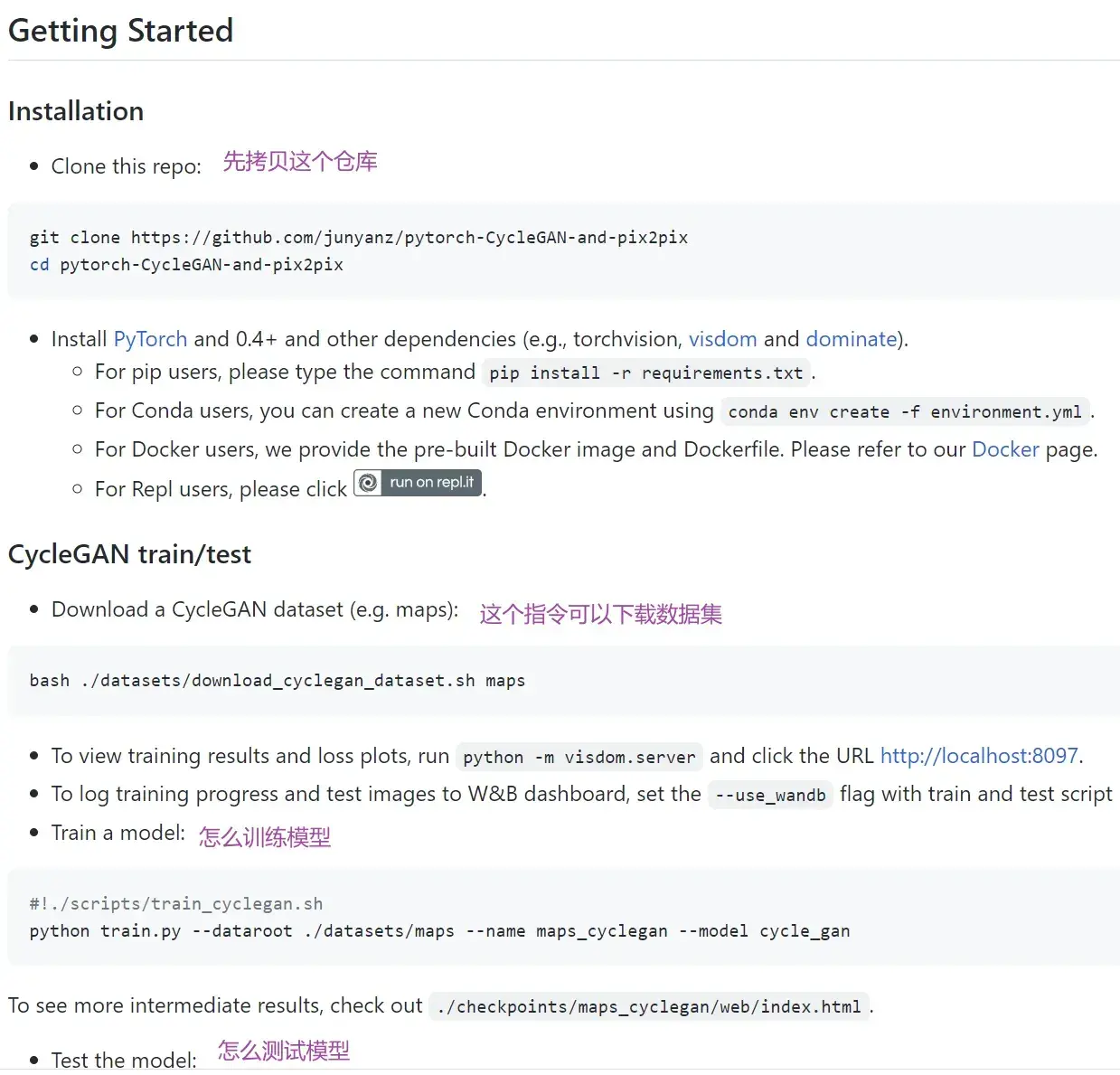
——————————————————————————————————————————–
train.py
"""General-purpose training script for image-to-image translation.
This script works for various models (with option '--model': e.g., pix2pix, cyclegan, colorization) and
different datasets (with option '--dataset_mode': e.g., aligned, unaligned, single, colorization).
You need to specify the dataset ('--dataroot'), experiment name ('--name'), and model ('--model').
It first creates model, dataset, and visualizer given the option.
It then does standard network training. During the training, it also visualize/save the images, print/save the loss plot, and save models.
The script supports continue/resume training. Use '--continue_train' to resume your previous training.
Example:
Train a CycleGAN model:
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan
Train a pix2pix model:
python train.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA
See options/base_options.py and options/train_options.py for more training options.
See training and test tips at: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/docs/tips.md
See frequently asked questions at: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/docs/qa.md
"""
import time
from options.train_options import TrainOptions
from data import create_dataset
from models import create_model
from util.visualizer import Visualizer
if __name__ == '__main__':
opt = TrainOptions().parse() # get training options
dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other options
dataset_size = len(dataset) # get the number of images in the dataset.
print('The number of training images = %d' % dataset_size)
model = create_model(opt) # create a model given opt.model and other options
model.setup(opt) # regular setup: load and print networks; create schedulers
visualizer = Visualizer(opt) # create a visualizer that display/save images and plots
total_iters = 0 # the total number of training iterations
for epoch in range(opt.epoch_count, opt.n_epochs + opt.n_epochs_decay + 1): # outer loop for different epochs; we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>
epoch_start_time = time.time() # timer for entire epoch
iter_data_time = time.time() # timer for data loading per iteration
epoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epoch
visualizer.reset() # reset the visualizer: make sure it saves the results to HTML at least once every epoch
model.update_learning_rate() # update learning rates in the beginning of every epoch.
for i, data in enumerate(dataset): # inner loop within one epoch
iter_start_time = time.time() # timer for computation per iteration
if total_iters % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_iters += opt.batch_size
epoch_iter += opt.batch_size
model.set_input(data) # unpack data from dataset and apply preprocessing
model.optimize_parameters() # calculate loss functions, get gradients, update network weights
if total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML file
save_result = total_iters % opt.update_html_freq == 0
model.compute_visuals()
visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)
if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disk
losses = model.get_current_losses()
t_comp = (time.time() - iter_start_time) / opt.batch_size
visualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)
if opt.display_id > 0:
visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)
if total_iters % opt.save_latest_freq == 0: # cache our latest model every <save_latest_freq> iterations
print('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))
save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'
model.save_networks(save_suffix)
iter_data_time = time.time()
if epoch % opt.save_epoch_freq == 0: # cache our model every <save_epoch_freq> epochs
print('saving the model at the end of epoch %d, iters %d' % (epoch, total_iters))
model.save_networks('latest')
model.save_networks(epoch)
print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch, opt.n_epochs + opt.n_epochs_decay, time.time() - epoch_start_time))
——————————————————————————————————————————–
训练参数设置
from .base_options import BaseOptions
class TrainOptions(BaseOptions):
"""This class includes training options.
It also includes shared options defined in BaseOptions.
"""
def initialize(self, parser):
parser = BaseOptions.initialize(self, parser)
# visdom and HTML visualization parameters
parser.add_argument('--display_freq', type=int, default=400, help='frequency of showing training results on screen')
parser.add_argument('--display_ncols', type=int, default=4, help='if positive, display all images in a single visdom web panel with certain number of images per row.')
parser.add_argument('--display_id', type=int, default=1, help='window id of the web display')
parser.add_argument('--display_server', type=str, default="http://localhost", help='visdom server of the web display')
parser.add_argument('--display_env', type=str, default='main', help='visdom display environment name (default is "main")')
parser.add_argument('--display_port', type=int, default=8097, help='visdom port of the web display')
parser.add_argument('--update_html_freq', type=int, default=1000, help='frequency of saving training results to html')
parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
# network saving and loading parameters
parser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')
parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')
parser.add_argument('--save_by_iter', action='store_true', help='whether saves model by iteration')
parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')
parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
# training parameters
parser.add_argument('--n_epochs', type=int, default=100, help='number of epochs with the initial learning rate')
parser.add_argument('--n_epochs_decay', type=int, default=100, help='number of epochs to linearly decay learning rate to zero')
parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
parser.add_argument('--gan_mode', type=str, default='lsgan', help='the type of GAN objective. [vanilla| lsgan | wgangp]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')
parser.add_argument('--pool_size', type=int, default=50, help='the size of image buffer that stores previously generated images')
parser.add_argument('--lr_policy', type=str, default='linear', help='learning rate policy. [linear | step | plateau | cosine]')
parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')
self.isTrain = True
return parser
没有dataroot
点进其继承的父类查看,可以看到有dataroot

下载代码用 PyCharm 打开后,查看代码里有没有 required=True,若有,删掉 required=True ,加一个默认值 default=”./dataset/maps” ,就可以在 PyCharm 里右键运行了
即找到所有 required=True 的参数,将它删去并添加上默认值default
文章出处登录后可见!