Transfer Learning for NLP with TensorFlow Hub
Welcome to this hands-on project on transfer learning for natural language processing with TensorFlow and TF Hub. By the time you complete this project, you will be able to use pre-trained NLP text embedding models from TensorFlow Hub, perform transfer learning to fine-tune models on real-world data, build and evaluate multiple models for text classification with TensorFlow, and visualize model performance metrics with Tensorboard.
Learning Objectives
- Use pre-trained NLP text embedding models from TensorFlow Hub
- Perform transfer learning to fine-tune models on real-world text data
- Visualize model performance metrics with TensorBoard
Overview
Now, you will use pre-trained NLP text embedding models from TensorFlow Hub, perform transfer learning to fine-tune models on real-world data, build and evaluate multiple models for text classification with TensorFlow, and visualize model performance metrics with Tensorboard.
In order to successfully complete this project, you should be competent in the Python programming language, be familiar with deep learning for Natural Language Processing (NLP), and have trained models with TensorFlow or and its Keras API.
We will accomplish it by completing the following tasks in the project:
- Task 1: Introduction to the Project
- Task 2: Setup your TensorFlow and Colab Runtime
- Task 3: Load the Quora Insincere Questions Dataset
- Task 4: TensorFlow Hub for Natural Language Processing
- Tasks 5 & 6: Define Function to Build and Compile Models
- Task 7: Train Various Text Classification Models
- Task 8: Compare Accuracy and Loss Curves
- Task 9: Fine-tune Model from TF Hub
- Task 10: Train Bigger Models and Visualize Metrics with TensorBoard
While you are watching me work on each step, you will get a cloud desktop with all the required software pre-installed. This will allow you to follow along the instructions to complete the above mentioned tasks. After all, we learn best with active, hands-on learning.
Ready to get started? Click on the button below to launch the project on Rhyme.
Project
Task 2: Setup your TensorFlow and Colab Runtime.
查看GPU
!nvidia-smi
Output
Sun May 29 08:48:46 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 47C P8 10W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
导入需要的依赖
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (12, 8)
from IPython import display
import pathlib
import shutil
import tempfile
!pip install -q git+https://github.com/tensorflow/docs
import tensorflow_docs as tfdocs
import tensorflow_docs.modeling
import tensorflow_docs.plots
print("Version: ", tf.__version__)
print("Hub version: ", hub.__version__)
print("GPU is", "available" if tf.config.list_physical_devices('GPU') else "NOT AVAILABLE")
logdir = pathlib.Path(tempfile.mkdtemp())/"tensorboard_logs"
shutil.rmtree(logdir, ignore_errors=True)
执行结果
Building wheel for tensorflow-docs (setup.py) ... done
Version: 2.8.0
Hub version: 0.12.0
GPU is available
Task 3: Download and Import the Quora Insincere Questions Dataset
A downloadable copy of the Quora Insincere Questions Classification data can be found https://archive.org/download/fine-tune-bert-tensorflow-train.csv/train.csv.zip. Decompress and read the data into a pandas DataFrame.
使用pandas的读取函数来读取数据
df = pd.read_csv('https://archive.org/download/fine-tune-bert-tensorflow-train.csv/train.csv.zip',
compression='zip', low_memory=False)
df.shape
数据集的形式
(1306122, 3)
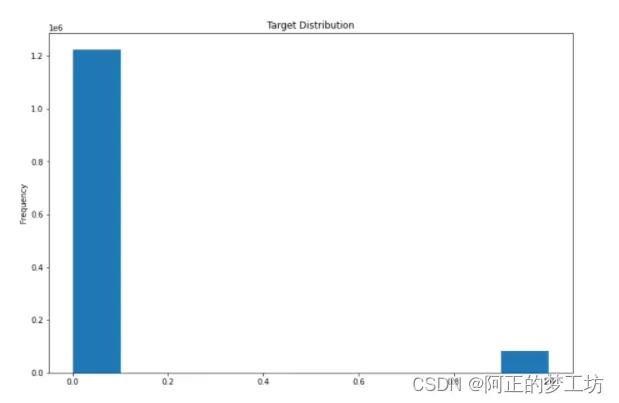
查看数据集标签的分布
df['target'].plot(kind='hist', title='Target Distribution');
1表示不好的问题
0表示好的问题
从sklearn中导入model_selection 进行训练集和测试集的切分
from sklearn.model_selection import train_test_split
train_df, remaining = train_test_split(df, random_state=42, train_size=0.01, stratify=df.target.values)
valid_df, _ = train_test_split(remaining, random_state=42, train_size=0.001, stratify=remaining.target.values)
train_df.shape, valid_df.shape
切分主要是按照train_size这个比例来从所有的数据中切分的
上面我们构造数据集大小
((13061, 3), (1293, 3))
sklearn中stratify参数是让训练集和测试集有相同的比例分布。
Parameter “stratify” from method “train_test_split” (scikit Learn)
The answer I can give is that stratifying preserves the proportion of how data is distributed in the target column – and depicts that same proportion of distribution in the train_test_split. Take for example, if the problem is a binary classification problem, and the target column is having proportion of 80% = yes, and 20% = no. Since there are 4 times more ‘yes’ than ‘no’ in the target column, by splitting into train and test without stratifying, we might run into the trouble of having only the ‘yes’ falling into our training set, and all the ‘no’ falling into our test set.(i.e, the training set might not have ‘no’ in its target column)
Hence by Stratifying, the target column for the training set has 80% of ‘yes’ and 20% of ‘no’, and also, the target column for the test set has 80% of ‘yes’ and 20% of ‘no’ respectively.
Hence, Stratify makes even distribution of the target(label) in the train and test set – just as it is distributed in the original dataset.
https://stackoverflow.com/questions/34842405/parameter-stratify-from-method-train-test-split-scikit-learn
This
stratifyparameter makes a split so that the proportion of values in the sample produced will be the same as the proportion of values provided to parameterstratify.For example, if variable
yis a binary categorical variable with values0and1and there are 25% of zeros and 75% of ones,stratify=ywill make sure that your random split has 25% of0’s and 75% of1’s.
看一下target的内容:前15条的标签
train_df.target.head(15).values
Output
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0])
下面再来看一下数据集中原始的问题:前15条数据
train_df.question_text.head(15).values
Output
array(['What is your experience living in Venezuela in the current crisis? (2018)',
'In which state/city the price of property is highest?',
'Do rich blacks also call poor whites, “White Trash”?',
'Should my 5 yr old son and 2 yr old daughter spend the summer with their father, after a domestic violent relationship?',
'Why do we have parents?',
'Do we experience ghost like Murphy did in Interstellar?',
'Are Estoniano women beautiful?',
'There was a Funny or Die video called Sensitivity Hoedown that got pulled. Does anyone know why?',
'Is it a good idea to go in fully mainstream classes, even if I have meltdowns that might disrupt people?',
'What classifies a third world country as such?',
'Is being a pilot safe?',
'Who is Illiteratendra Modi? Why does he keep with him a Rs 1 lakh pen?',
'Have modern management strategies such as Total supply Chain Management applied to education? Can they be?',
'Why are Lucky Charms considered good for you?',
'How many people in India use WhatsApp, Facebook, Twitter and Instagram?'],
dtype=object)
Task 4: TensorFlow Hub for Natural Language Processing
Our text data consist of questions and corresponding labels.
You can think of a question vector as a distributed representation of a question, and is computed for every question in the training set. The question vector along with the output label is then used to train the statistical classification model.
The intuition is that the question vector captures the semantics of the question and, as a result, can be effectively used for classification.
To obtain question vectors, we have two alternatives that have been used for several text classification problems in NLP:
- word-based representations and
- context-based representations
Word-based Representations
- A word-based representation of a question combines word embeddings of the content words in the question. We can use the average of the word embeddings of content words in the question. Average of word embeddings have been used for different NLP tasks.
- Examples of pre-trained embeddings include:
- Word2Vec: These are pre-trained embeddings of words learned from a large text corpora. Word2Vec has been pre-trained on a corpus of news articles with 300 million tokens, resulting in 300-dimensional vectors.
- GloVe: has been pre-trained on a corpus of tweets with 27 billion tokens, resulting in 200-dimensional vectors.
Context-based Representations
- Context-based representations may use language models to generate vectors of sentences. So, instead of learning vectors for individual words in the sentence, they compute a vector for sentences on the whole, by taking into account the order of words and the set of co-occurring words.
- Examples of deep contextualized vectors include:
- Embeddings from Language Models (ELMo): uses character-based word representations and bidirectional LSTMs. The pre-trained model computes a contextualised vector of 1024 dimensions. ELMo is available on Tensorflow Hub.
- Universal Sentence Encoder (USE): The encoder uses a Transformer architecture that uses attention mechanism to incorporate information about the order and the collection of words. The pre-trained model of USE that returns a vector of 512 dimensions is also available on Tensorflow Hub.
- Neural-Net Language Model (NNLM): The model simultaneously learns representations of words and probability functions for word sequences, allowing it to capture semantics of a sentence. We will use a pretrained models available on Tensorflow Hub, that are trained on the English Google News 200B corpus, and computes a vector of 128 dimensions for the larger model and 50 dimensions for the smaller model.
Tensorflow Hub provides a number of modules to convert sentences into embeddings such as Universal sentence ecoders, NNLM, BERT and Wikiwords.
Transfer learning makes it possible to save training resources and to achieve good model generalization even when training on a small dataset. In this project, we will demonstrate this by training with several different TF-Hub modules.
这个项目要用的modules
module_url = "https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1" #@param [
"https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1",
"https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1",
"https://tfhub.dev/google/tf2-preview/nnlm-en-dim128/1",
"https://tfhub.dev/google/universal-sentence-encoder/4",
"https://tfhub.dev/google/universal-sentence-encoder-large/5"
] {allow-input: true}
Tasks 5 & 6: Define Function to Build and Compile Models
打开tfhub中预训练好的swivel: https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1
定义函数和编译模型,返回history 对象
def train_and_evaluate_model(module_url, embed_size, name, trainable=False):
hub_layer = hub.KerasLayer(module_url, input_shape=[], output_shape=[embed_size], dtype=tf.string, trainable=trainable)
model = tf.keras.models.Sequential([
hub_layer,
tf.keras.layers.Dense(255, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss=tf.losses.BinaryCrossentropy(),
metrics=[tf.metrics.BinaryAccuracy(name='accuracy')])
history = model.fit(train_df['question_text'], train_df['target'],
epochs=100,
batch_size=32,
validation_data=(valid_df['question_text'], valid_df['target']),
callbacks=[tfdocs.modeling.EpochDots(),
tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=2, mode='min'),
tf.keras.callbacks.TensorBoard(logdir/name)],
verbose=0)
return history
Task 7: Train Various Text Classification Models
可以通过改变module_url来训练不同的模型
gnews-swivel-20dim
histories = {}
module_url = "https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1"
histories['gnews-swivel-20dim'] = train_and_evaluate_model(module_url, embed_size=20, name='gnews-swivel-20dim')
训练效果
Model: "sequential_15"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_15 (KerasLayer) (None, 128) 124642688
dense_45 (Dense) (None, 255) 32895
dense_46 (Dense) (None, 64) 16384
dense_47 (Dense) (None, 1) 65
=================================================================
Total params: 124,692,032
Trainable params: 49,344
Non-trainable params: 124,642,688
_________________________________________________________________
Epoch: 0, accuracy:0.9309, loss:0.3219, val_accuracy:0.9381, val_loss:0.2110,
.............
训练第二个模型:nnlm-en-dim50
histories['nnlm-en-dim50'] = train_and_evaluate_model(module_url, embed_size=50, name='nnlm-en-dim50')
看一下模型的结构和训练结果
Model: "sequential_16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_16 (KerasLayer) (None, 50) 48190600
dense_48 (Dense) (None, 255) 13005
dense_49 (Dense) (None, 64) 16384
dense_50 (Dense) (None, 1) 65
=================================================================
Total params: 48,220,054
Trainable params: 29,454
Non-trainable params: 48,190,600
_________________________________________________________________
Epoch: 0, accuracy:0.9338, loss:0.3285, val_accuracy:0.9381, val_loss:0.2246,
.......................
训练第三个模型:nnlm-en-dim128
histories['nnlm-en-dim128'] = train_and_evaluate_model(module_url, embed_size=128, name='nnlm-en-dim128')
训练效果
Model: "sequential_17"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_17 (KerasLayer) (None, 128) 124642688
dense_51 (Dense) (None, 255) 32895
dense_52 (Dense) (None, 64) 16384
dense_53 (Dense) (None, 1) 65
=================================================================
Total params: 124,692,032
Trainable params: 49,344
Non-trainable params: 124,642,688
_________________________________________________________________
Epoch: 0, accuracy:0.9309, loss:0.3167, val_accuracy:0.9381, val_loss:0.2104,
................
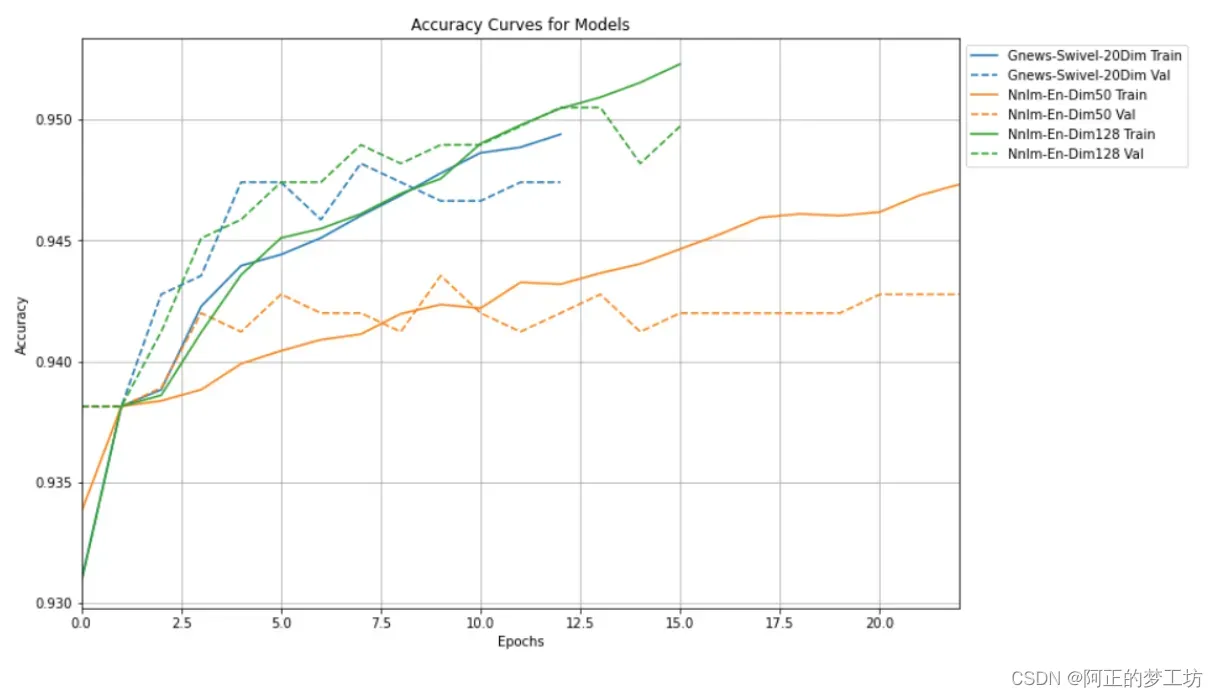
Task 8: Compare Accuracy and Loss Curves
绘制训练准确率
plt.rcParams['figure.figsize'] = (12, 8)
plotter = tfdocs.plots.HistoryPlotter(metric = 'accuracy')
plotter.plot(histories)
plt.xlabel("Epochs")
plt.legend(bbox_to_anchor=(1.0, 1.0), loc='upper left')
plt.title("Accuracy Curves for Models")
plt.show()
绘图结果
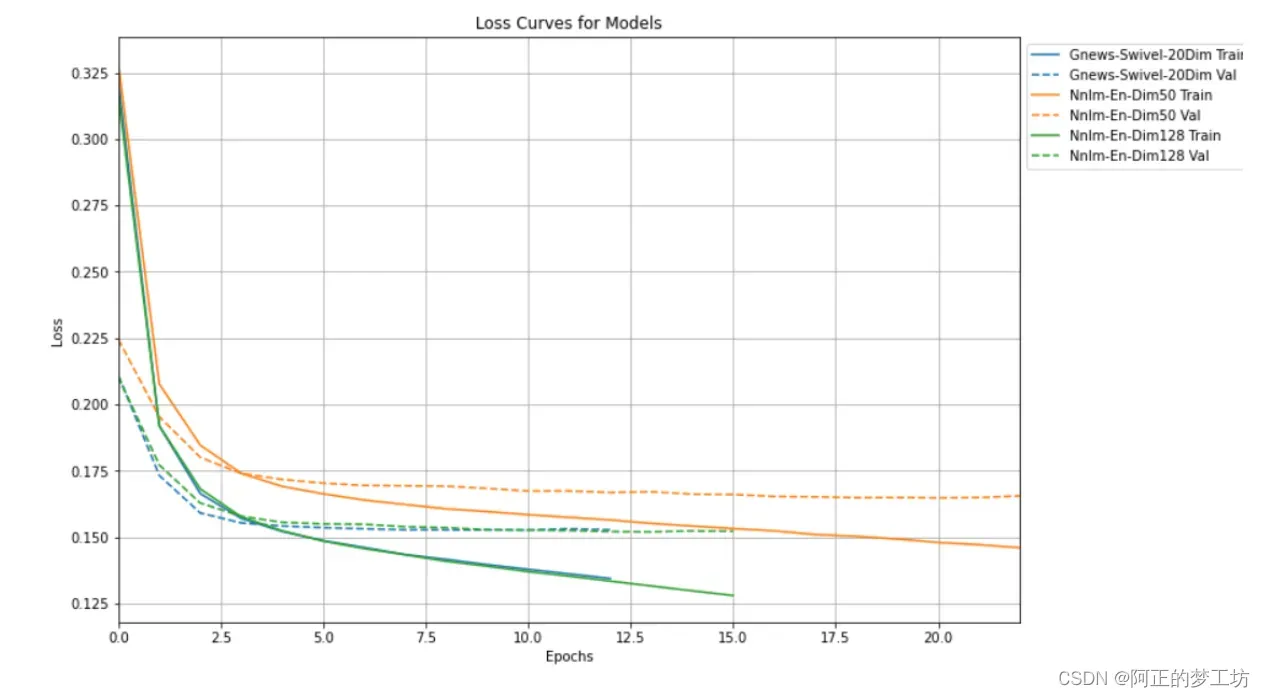
Plot the loss
plotter = tfdocs.plots.HistoryPlotter(metric = 'loss')
plotter.plot(histories)
plt.xlabel("Epochs")
plt.legend(bbox_to_anchor=(1.0, 1.0), loc='upper left')
plt.title("Loss Curves for Models")
plt.show()
Output
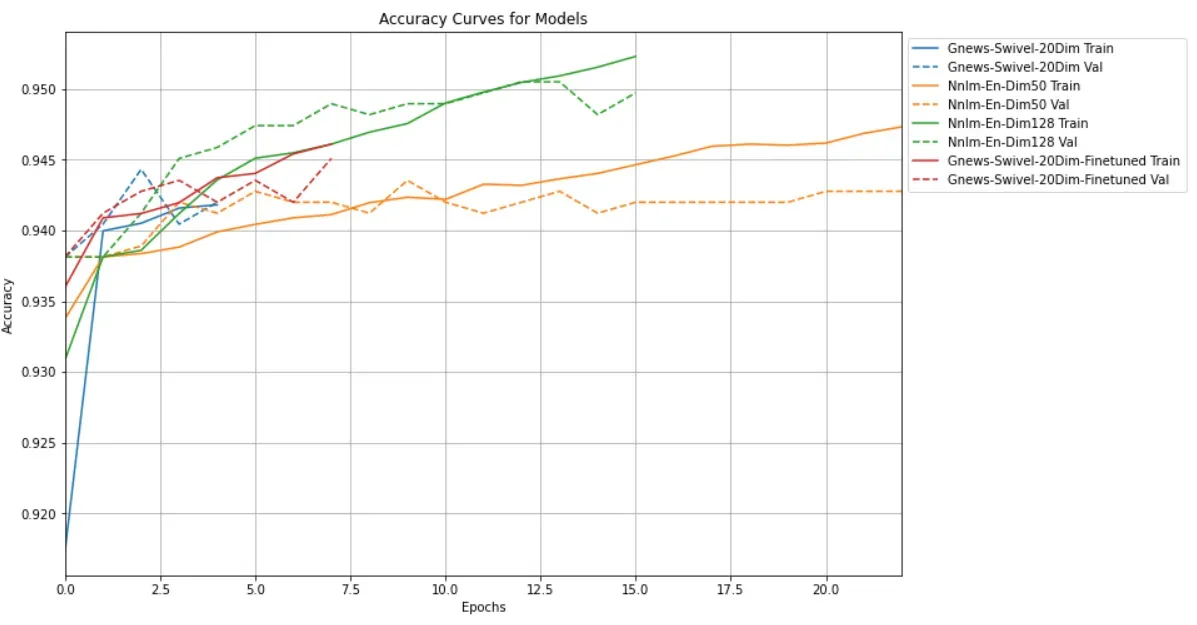
Task 9: Fine-tune Model from TF Hub
这里我们进行fine tune, 查看训练效果
histories['gnews-swivel-20dim-finetuned'] = train_and_evaluate_model(module_url,
embed_size=20,
name='gnews-swivel-20dim-finetuned',
trainable=True)
看一下微调的结果:需要不断地微调,有时候会出现过拟合的现象,需要我们重新训练。
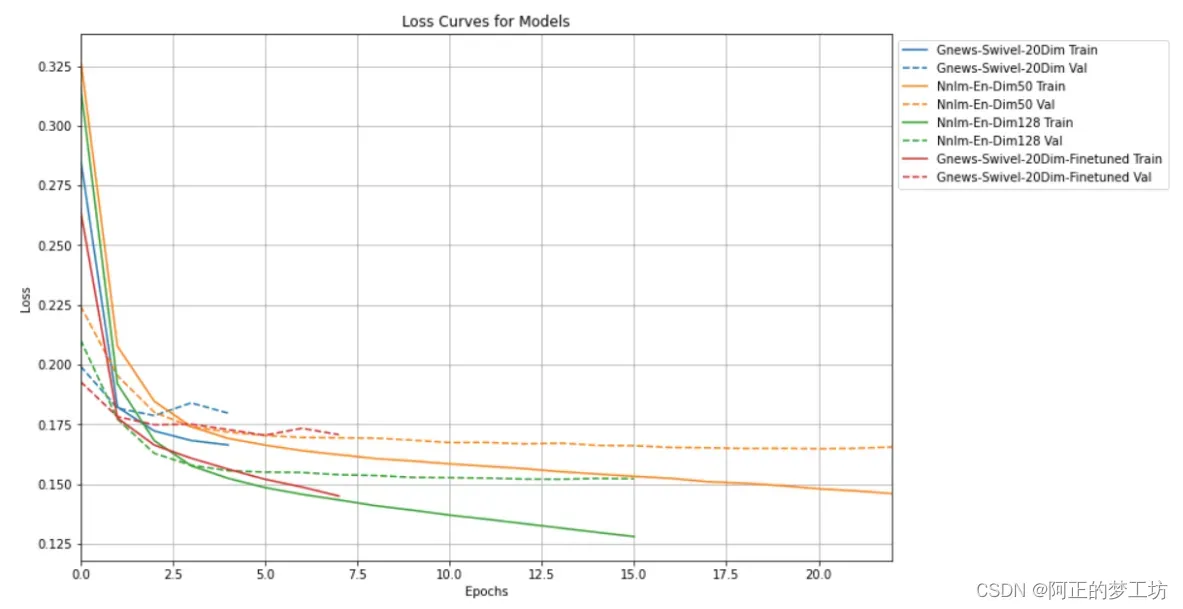
Task 10: Train Bigger Models and Visualize Metrics with TensorBoard
训练两个更大一点的模型
universal-sentence-encoder
histories['universal-sentence-encoder'] = train_and_evaluate_model(module_url,
embed_size=512,
name='universal-sentence-encoder')
训练结果
Model: "sequential_22"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_22 (KerasLayer) (None, 512) 256797824
dense_66 (Dense) (None, 255) 130815
dense_67 (Dense) (None, 64) 16384
dense_68 (Dense) (None, 1) 65
=================================================================
Total params: 256,945,088
Trainable params: 147,264
Non-trainable params: 256,797,824
_________________________________________________________________
Epoch: 0, accuracy:0.9377, loss:0.2853, val_accuracy:0.9381, val_loss:0.1698,
.........
universal-sentence-encoder-large
histories['universal-sentence-encoder-large'] = train_and_evaluate_model(module_url,
embed_size=512,
name='universal-sentence-encoder-large')
训练结果
Model: "sequential_23"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_23 (KerasLayer) (None, 512) 147354880
dense_69 (Dense) (None, 255) 130815
dense_70 (Dense) (None, 64) 16384
dense_71 (Dense) (None, 1) 65
=================================================================
Total params: 147,502,144
Trainable params: 147,264
Non-trainable params: 147,354,880
_________________________________________________________________
Epoch: 0, accuracy:0.9002, loss:0.3592, val_accuracy:0.9381, val_loss:0.1811,
...........
准确率比较
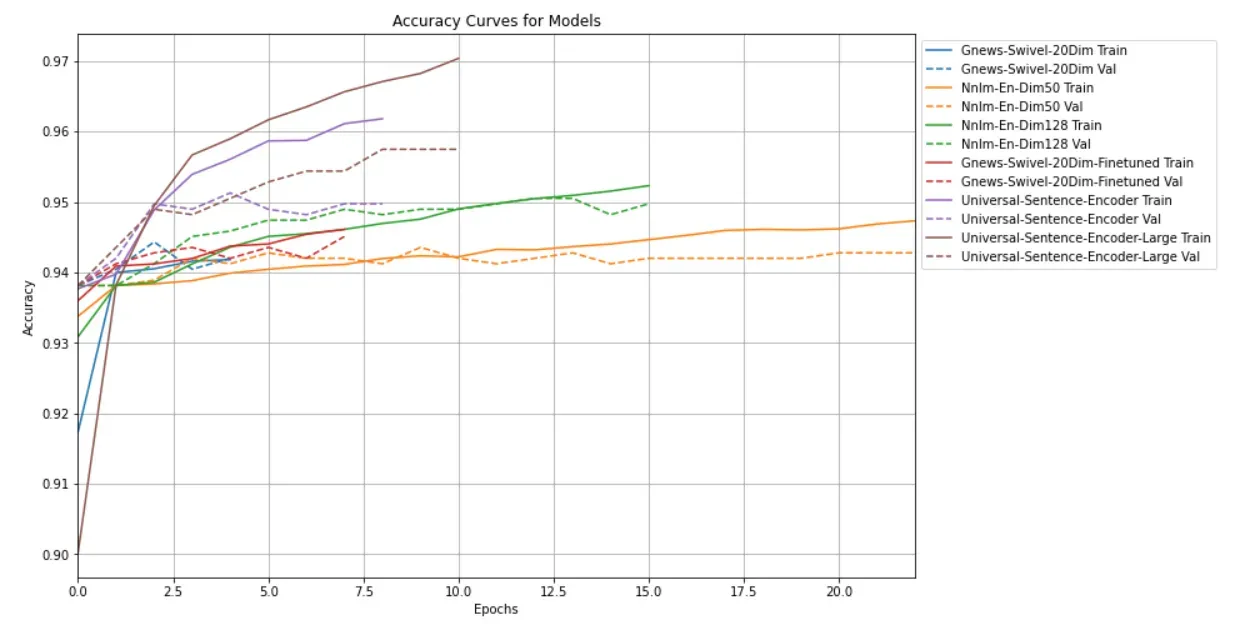
loss 比较
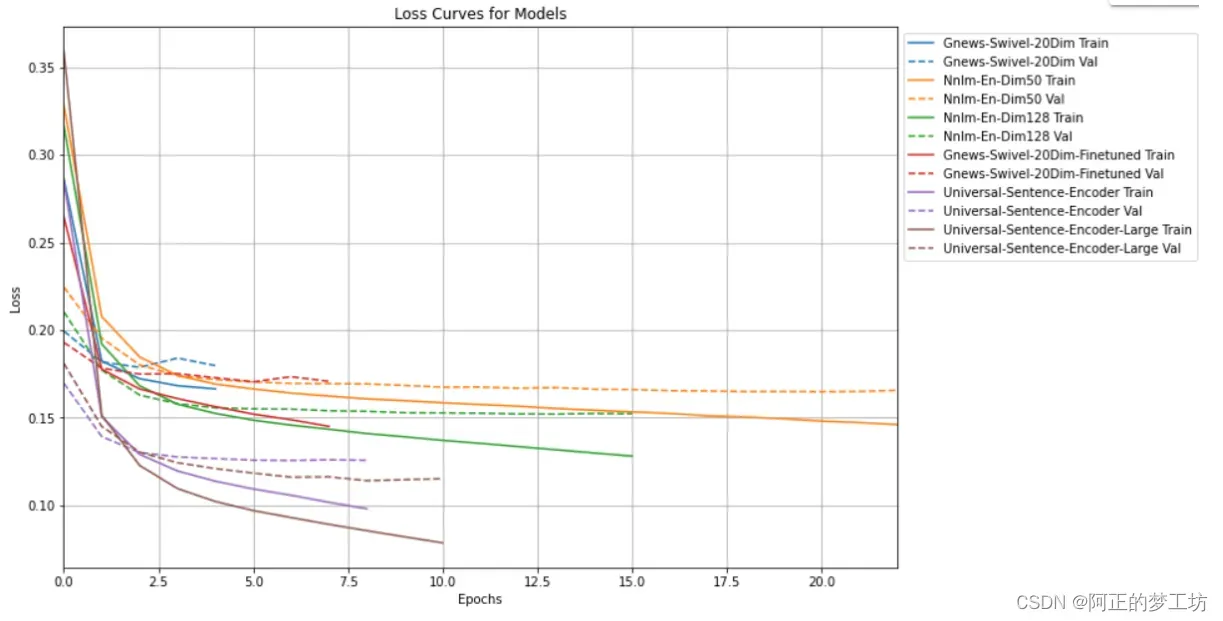
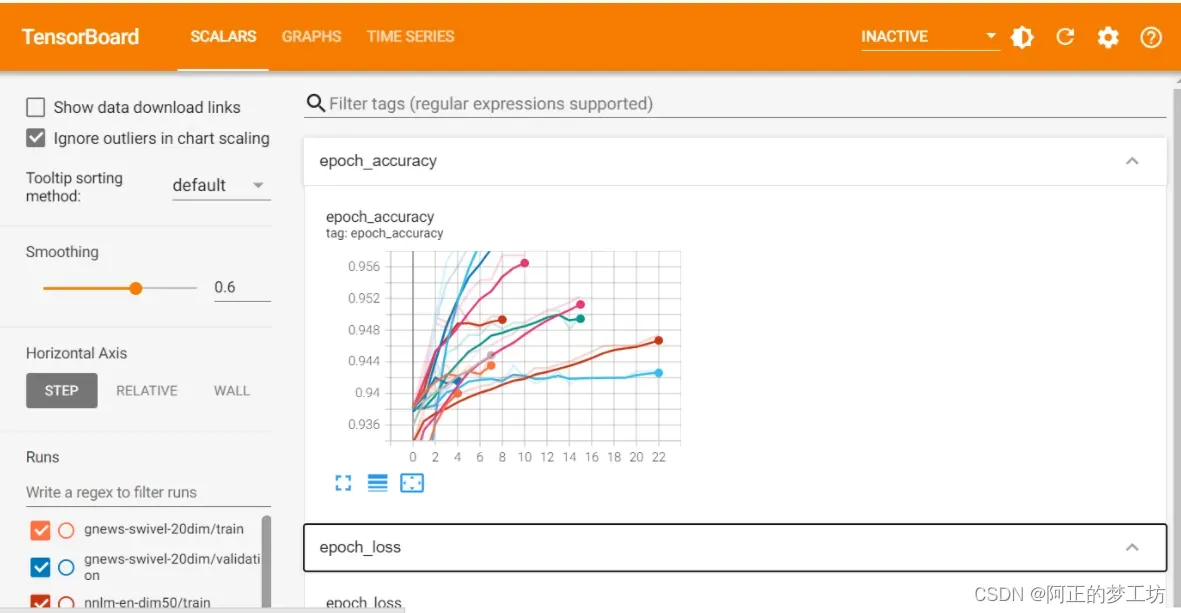
现在来看一下TensorBoard
%load_ext tensorboard
%tensorboard --logdir {logdir}
下面是打开的结果
其他
怎么查看TensorFlow Hub?
输入: tfhub.dev 就可以进入到 hub
使用 TensorFlow Hub,这里提供可以 Fine Tune 的模型,只需要设置 trainable=True 即可。
并且,在这个 project 里面,我们还学习到训练不同的模型的过程。
另外,Transer Learning 为什么可行呢?
Here are a few reasons I could think of:
- Many NLP tasks share common knowledge about language (linguistic representations, structural similarities, syntax, semantics…).
- Annotated data is rare, make use of as much supervision as possible. If you can combine data sets that you used for several tasks to get much bigger datasets. Bigger datasets are generally better for deep learning models.
- Unlabelled data is abundant (e.g. on the world wide web) and one should try to use as much of it as possible.
- Empirically, transfer learning has resulted in SOTA results for many supervised NLP tasks (e.g. classification, information extraction, Q&A, etc).
来源:Snehan Kekre
文章出处登录后可见!