前言
上一篇博客给大家介绍了LabVIEW开放神经网络交互工具包(ONNX)及其下载与超详细安装,今天我们就一起来看一下如何使用LabVIEW开放神经网络交互工具包实现TensorRT加速YOLOv5。
以下是YOLOv5的相关笔记总结,希望对大家有所帮助。
| 内容 | 地址链接 |
|---|---|
| 【YOLOv5】LabVIEW+OpenVINO让你的YOLOv5在CPU上飞起来 | https://blog.csdn.net/virobotics/article/details/124951862 |
| 【YOLOv5】LabVIEW OpenCV dnn快速实现实时物体识别(Object Detection) | https://blog.csdn.net/virobotics/article/details/124929483 |
一、TensorRT简介
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
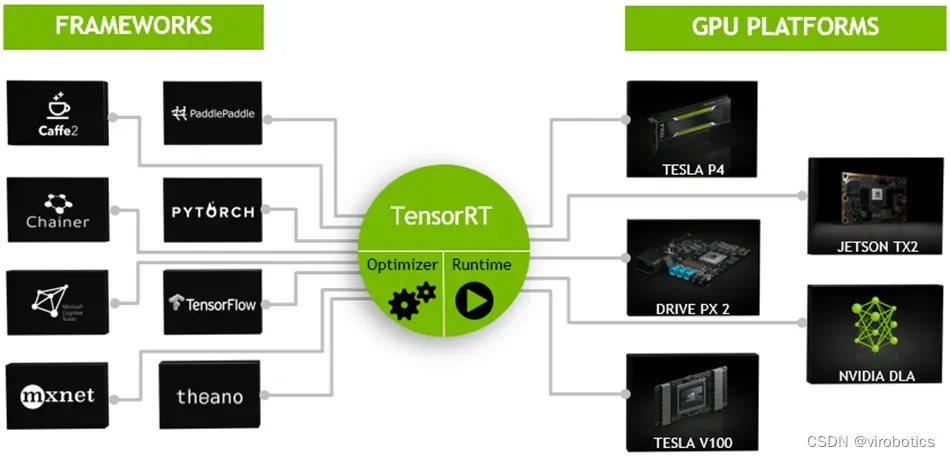
通常我们做项目,在部署过程中想要加速,无非就那么几种办法,如果我们的设备是CPU,那么可以用openvion,如果我们希望能够使用GPU,那么就可以尝试TensorRT了。那么为什么要选择TensorRT呢?因为我们目前主要使用的还是Nvidia的计算设备,TensorRT本身就是Nvidia自家的东西,那么在Nvidia端的话肯定要用Nvidia亲儿子了。
不过因为TensorRT的入门门槛略微有些高,直接劝退了想要入坑的玩家。其中一部分原因是官方文档比较杂乱;另一部分原因就是TensorRT比较底层,需要一点点C++和硬件方面的知识,学习难度会更高一点。我们做的开放神经网络交互工具包GPU版本,在GPU上做推理时,ONNXRuntime可采用CUDA作为后端进行加速,要更快速可以切换到TensorRT,虽然和纯TensorRT推理速度比还有些差距,但也十分快了。如此可以大大降低开发难度,能够更快更好的进行推理。。
二、准备工作
按照 LabVIEW开放神经网络交互工具包(ONNX)下载与超详细安装教程 安装所需软件,因本篇博客主要给大家介绍如何使用TensorRT加速YOLOv5,所以建议大家安装GPU版本的onnx工具包,否则无法实现TensorRT的加速。
三、YOLOv5模型的获取
为方便使用,博主已经将yolov5模型转化为onnx格式,可在百度网盘下载
链接:https://pan.baidu.com/s/15dwoBM4W-5_nlRj4G9EhRg?pwd=yiku
提取码:yiku
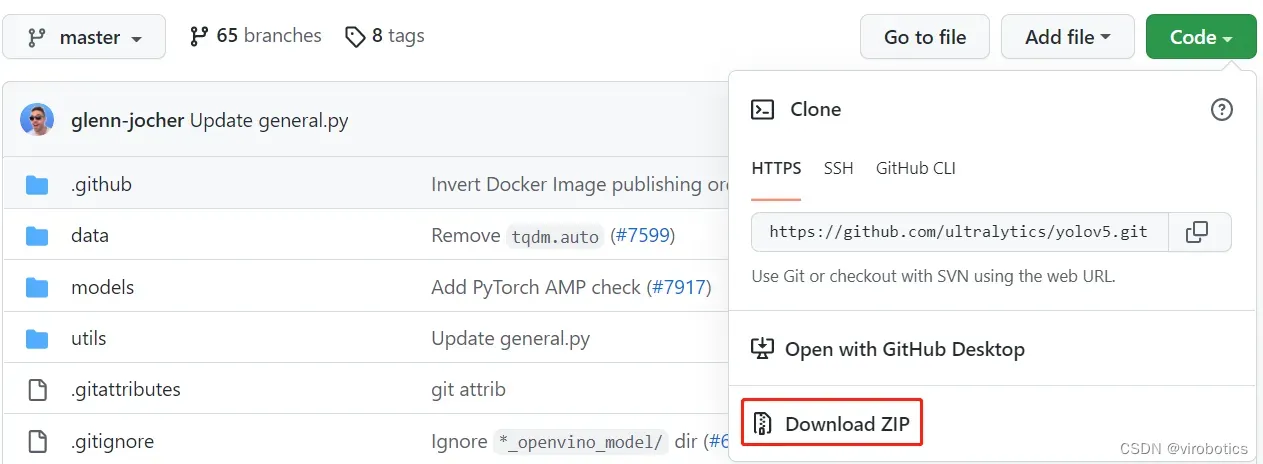
1.下载源码
将Ultralytics开源的YOLOv5代码Clone或下载到本地,可以直接点击Download ZIP进行下载,
下载地址:https://github.com/ultralytics/yolov5
2.安装模块
解压刚刚下载的zip文件,然后安装yolov5需要的模块,记住cmd的工作路径要在yolov5文件夹下:
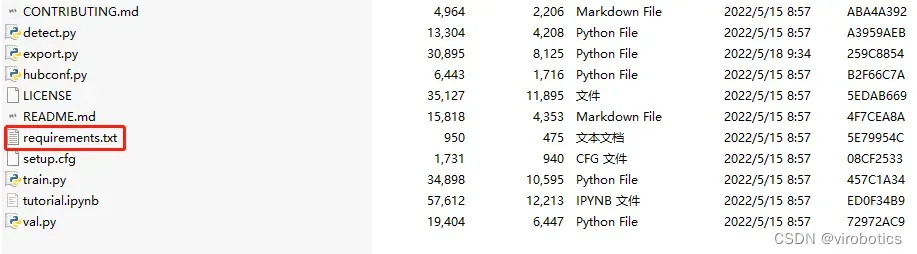
打开cmd切换路径到yolov5文件夹下,并输入如下指令,安装yolov5需要的模块
pip install -r requirements.txt
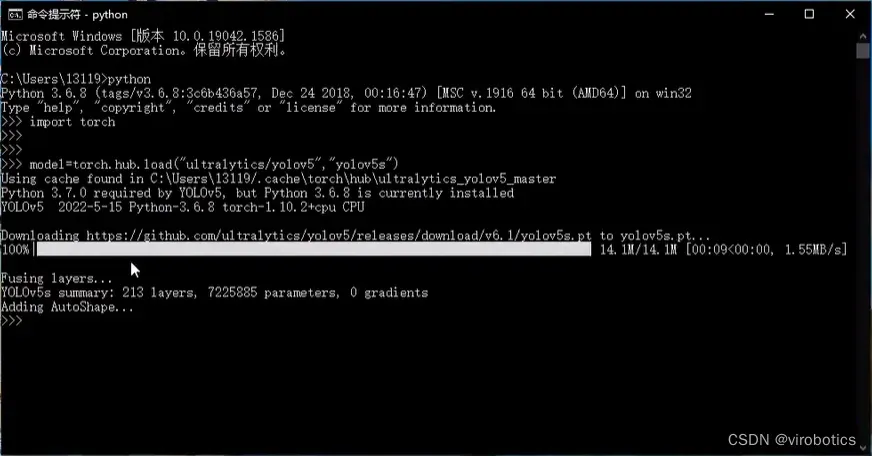
3.下载预训练模型
打开cmd,进入python环境,使用如下指令下载预训练模型:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
成功下载后如下图所示:
4.转换为onnx模型
在yolov5之前的yolov3和yolov4的官方代码都是基于darknet框架实现的,因此opencv的dnn模块做目标检测时,读取的是.cfg和.weight文件,非常方便。但是yolov5的官方代码是基于pytorch框架实现的。需要先把pytorch的训练模型.pt文件转换到.onnx文件,然后才能载入到opencv的dnn模块里。
将.pt文件转化为.onnx文件,主要是参考了nihate大佬的博客:https://blog.csdn.net/nihate/article/details/112731327
将export.py做如下修改,将def export_onnx()中的第二个try注释掉,即如下部分注释:
'''
try:
check_requirements(('onnx',))
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
print(f)
torch.onnx.export(
model,
im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'output': {
0: 'batch',
1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)'''
并新增一个函数def my_export_onnx():
def my_export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
print('anchors:', model.yaml['anchors'])
wtxt = open('class.names', 'w')
for name in model.names:
wtxt.write(name+'\n')
wtxt.close()
# YOLOv5 ONNX export
print(im.shape)
if not dynamic:
f = os.path.splitext(file)[0] + '.onnx'
torch.onnx.export(model, im, f, verbose=False, opset_version=12, input_names=['images'], output_names=['output'])
else:
f = os.path.splitext(file)[0] + '_dynamic.onnx'
torch.onnx.export(model, im, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['output'], dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
})
return f
在cmd中输入转onnx的命令(记得将export.py和pt模型放在同一路径下):
python export.py --weights yolov5s.pt --include onnx
如下图所示为转化成功界面
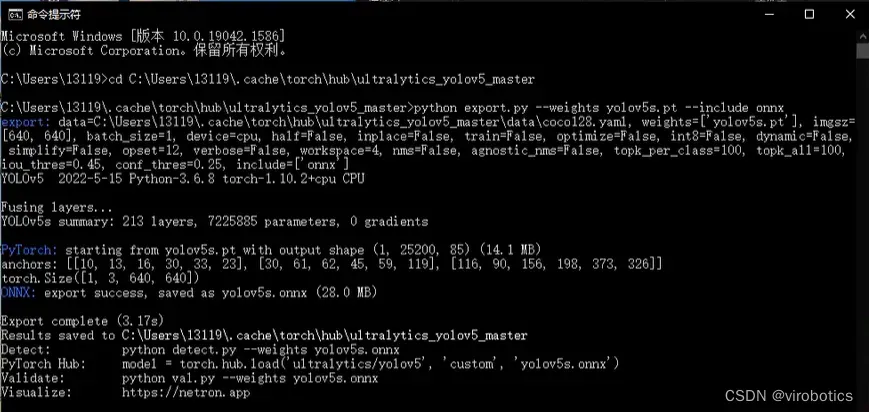
其中yolov5s可替换为yolov5m\yolov5m\yolov5l\yolov5x

四、LabVIEW使用TensorRT加速YOLOv5,实现实时物体识别(yolov5_new_onnx.vi)
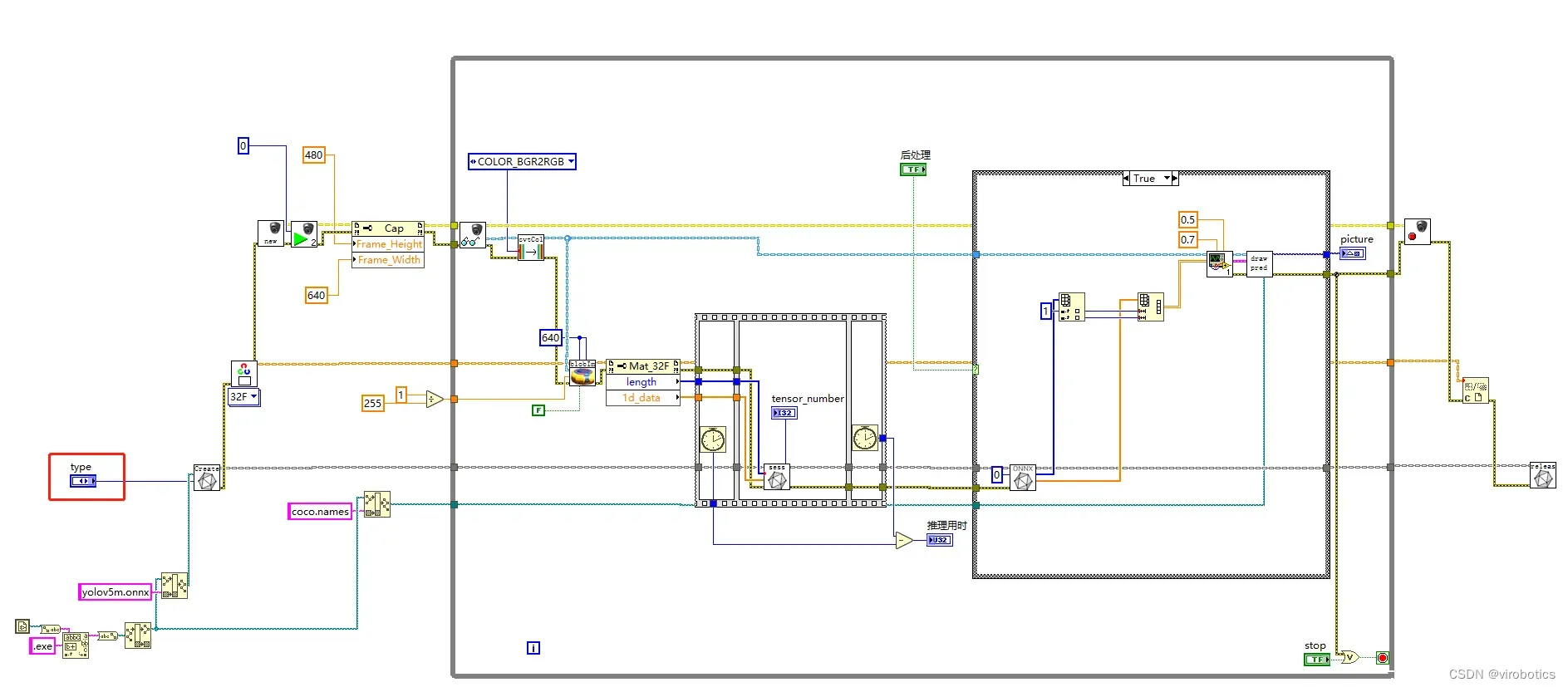
1.LabVIEW调用YOLOv5源码
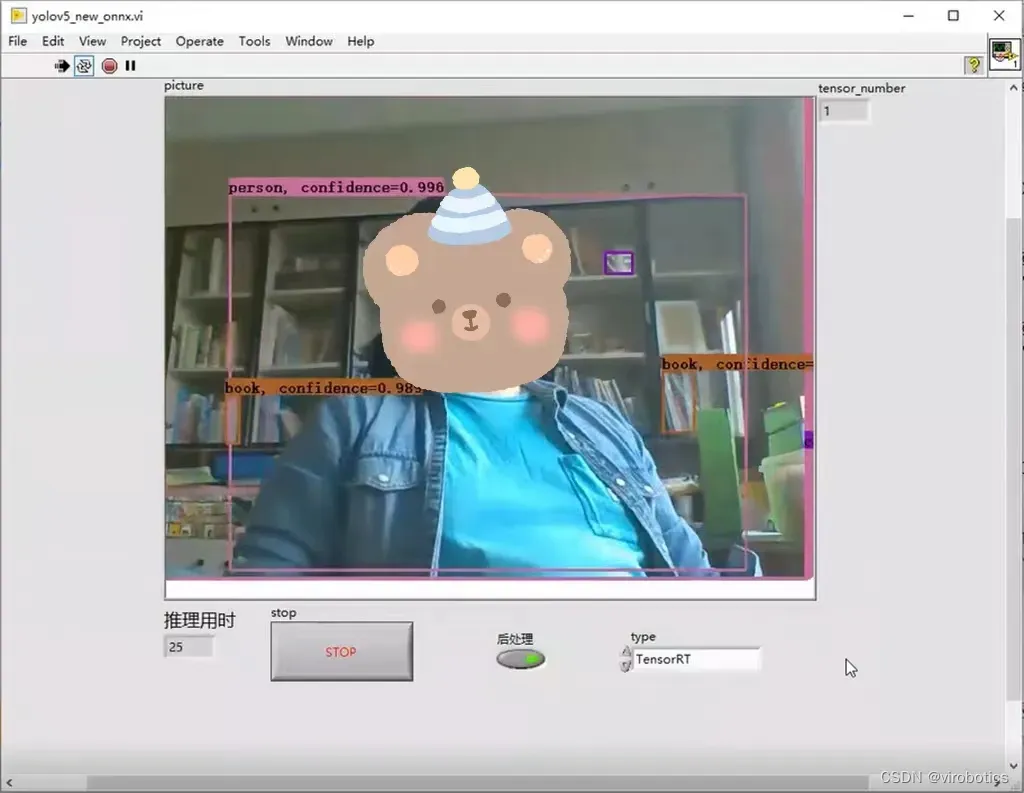
2.识别结果
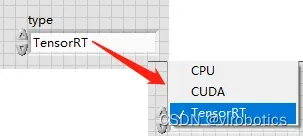
选择加速方式为:TensorRT
使用TensorRT加速,实时检测推理用时为20~30ms/frame,比单纯使用cuda加速快了30%,同时没有丢失任何的精度。博主使用的电脑显卡为1060显卡,各位如果使用30系列的显卡,速度应该会更快。
五、纯CPU下opencv dnn和onnx工具包加载YOLOv5实现实时物体识别推理用时对比
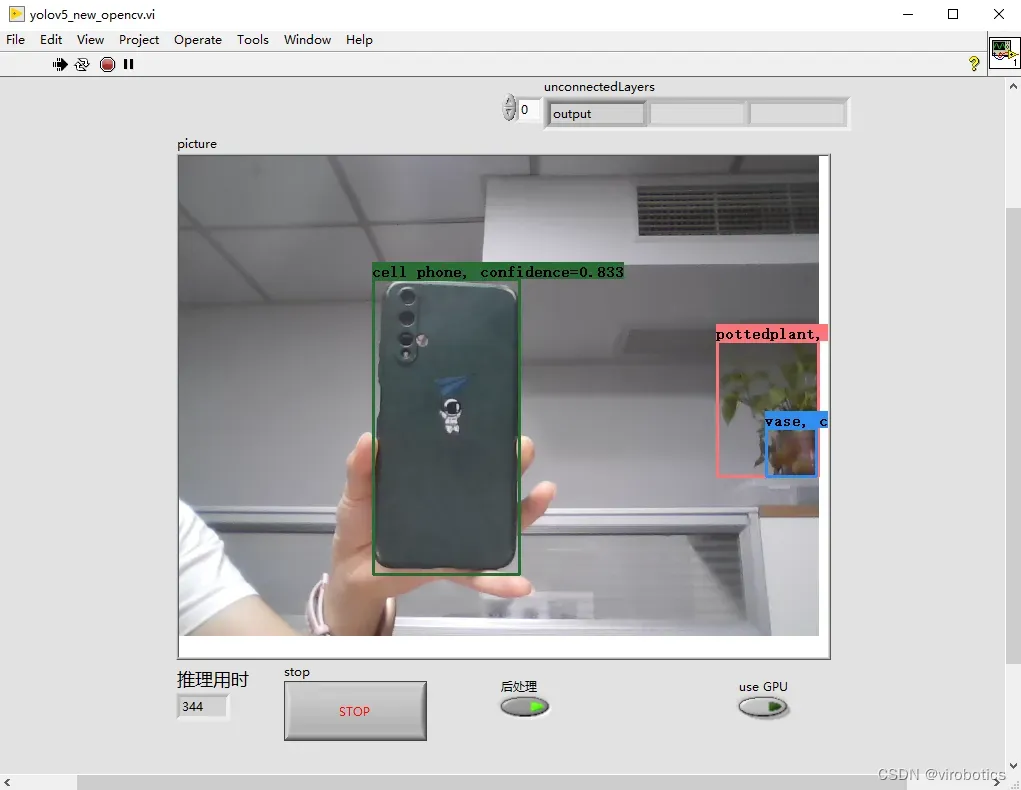
1、opencv dnn cpu下YOLOv5推理速度为:300ms左右/frame
2、onnx工具包cpu下YOLOv5推理速度为:200ms左右/frame
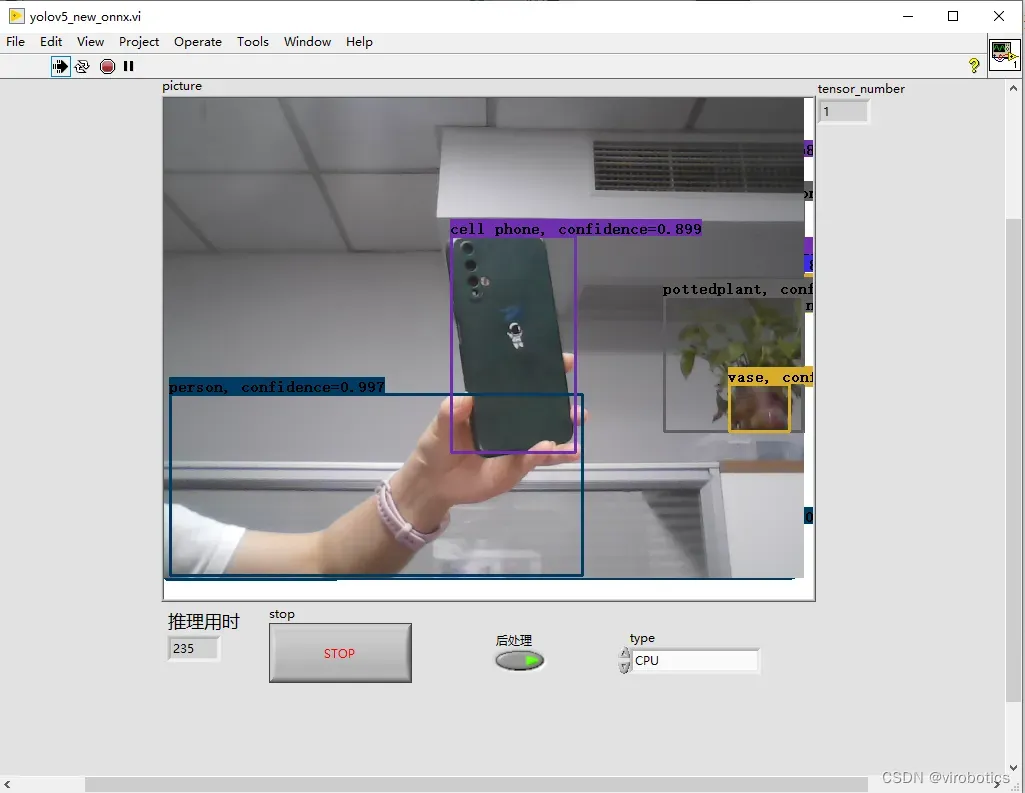
对比我们发现,同样使用cpu进行推理,onnx工具包推理速度要比opencv dnn推理速度快30%左右。
六、源码及模型下载
链接:https://pan.baidu.com/s/1cBVt8niF2fNT4j40JfiA-w?pwd=yiku
提取码:yiku
附加说明:计算机环境
操作系统:Windows10
python:3.6及以上
LabVIEW:2018及以上 64位版本
视觉工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.11.vip
总结
以上就是今天要给大家分享的内容。大家可根据链接下载相关源码与模型。
如果有问题可以在评论区里讨论,提问前请先点赞支持一下博主哦,如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:705637299。
如果文章对你有帮助,欢迎关注、点赞、收藏
文章出处登录后可见!