模型容量
拟合各种函数的能力
低容量的模型难以拟合训练数据
高容量的模型可以记住所有的训练数据
模型容量的影响
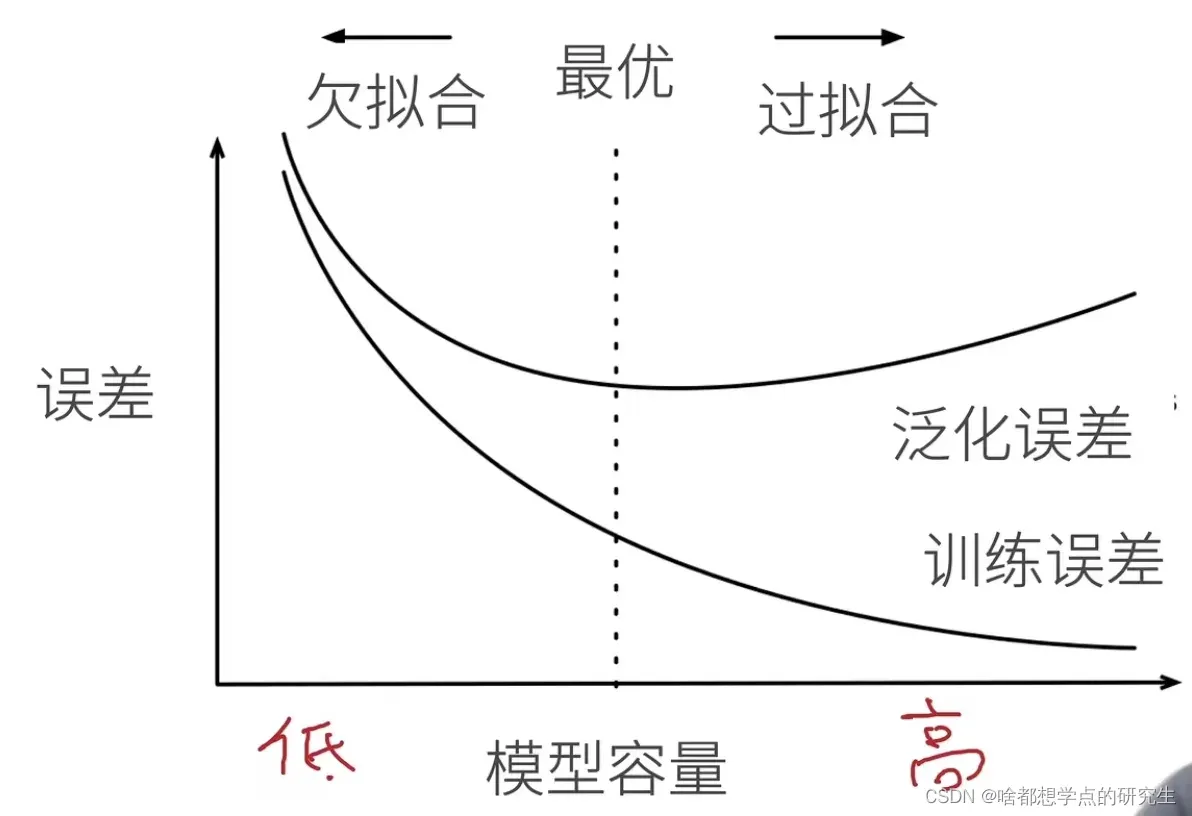
估计模型容量
难以在不同的种类算法之间比较: 例如树模型和神经网络
给定一个模型的种类,将有两个主要因素:参数的个数,参数值的选择范围
VC维
统计学习理论的一个核心思想
对于一个分类模型,VC等于一个最大的数据集的大小,不管如何给定标号,都存在一个模型来对它进行完美分类。
VC维的用处:
提供为什么一个模型好的理论依据,它可以衡量训练误差和泛化误差之间的间隔;但深度学习中很少使用,衡量不是很准确,计算深度学习模型的VC维很困难。
数据的复杂度
多个重要因素:样本个数,每个样本的元素个数,时间、空间结构,多样性
总结
模型容量需要匹配数据复杂度,否则可能导致欠拟合和过拟合
统计机器学习提供数学工具来衡量模型复杂度
实际中一般靠观察训练误差和验证误差。
为了理解模型复杂度和训练数据集⼤小对⽋拟合和过拟合的影响,下⾯我们以多项式函数拟合为
例来实验。⾸先导⼊实验需要的包或模块。

我们将⽣成⼀个⼈⼯数据集。在训练数据集和测试数据集中,给定样本特征x,我们使⽤如下的
三阶多项式函数来⽣成该样本的标签:
y = 1.2x − 3.4x^2 + 5.6x^3 + 5 + ϵ,
其中噪声项ϵ服从均值为0、标准差为0.1的正态分布。训练数据集和测试数据集的样本数都设为100。

看一下前2个样本。 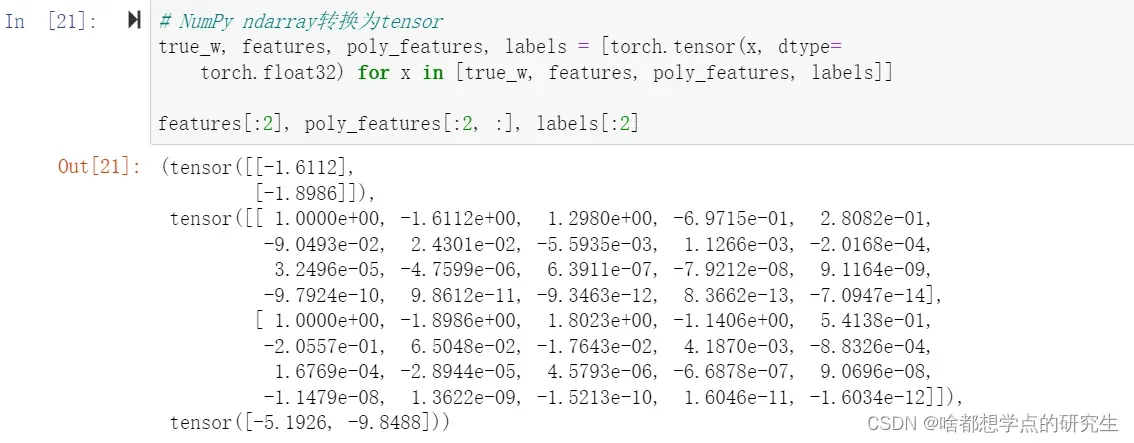
实现一个函数来评估模型在给定数据集上的损失。 
定义训练函数。

使用三阶多项式函数,它与数据生成函数的阶数相同。
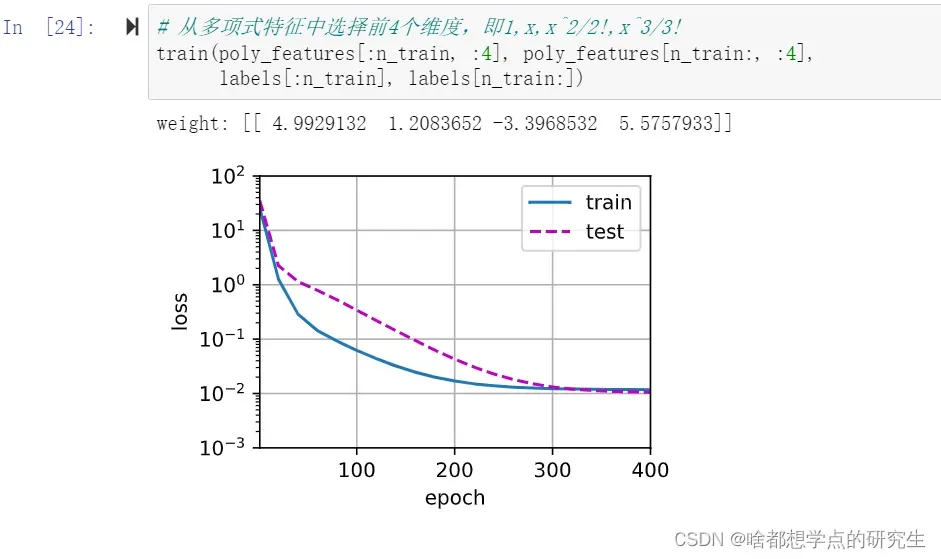
看看线性函数拟合,减少该模型的训练损失相对困难。 在最后一个迭代周期完成后,训练损失仍然很高。 当用来拟合非线性模式(如这里的三阶多项式函数)时,线性模型容易欠拟合。
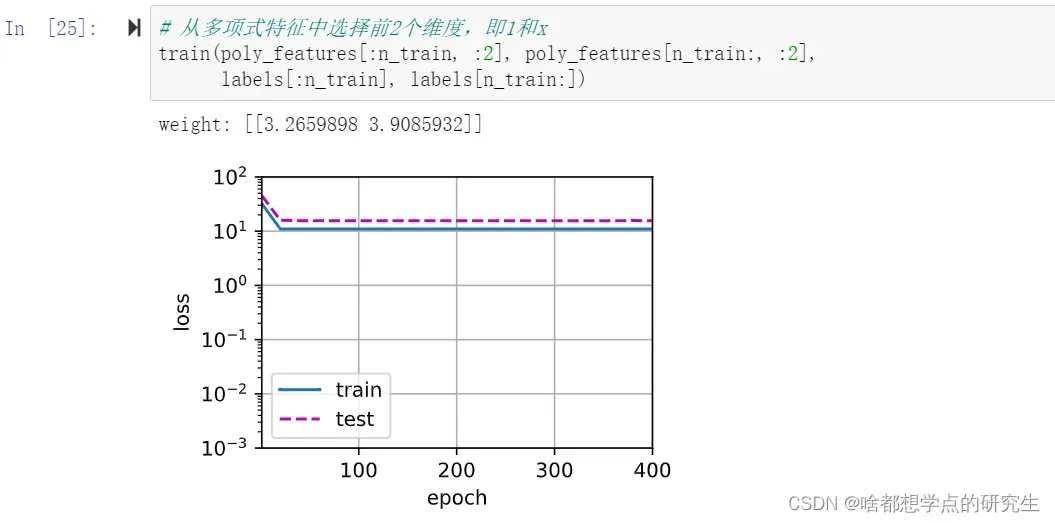
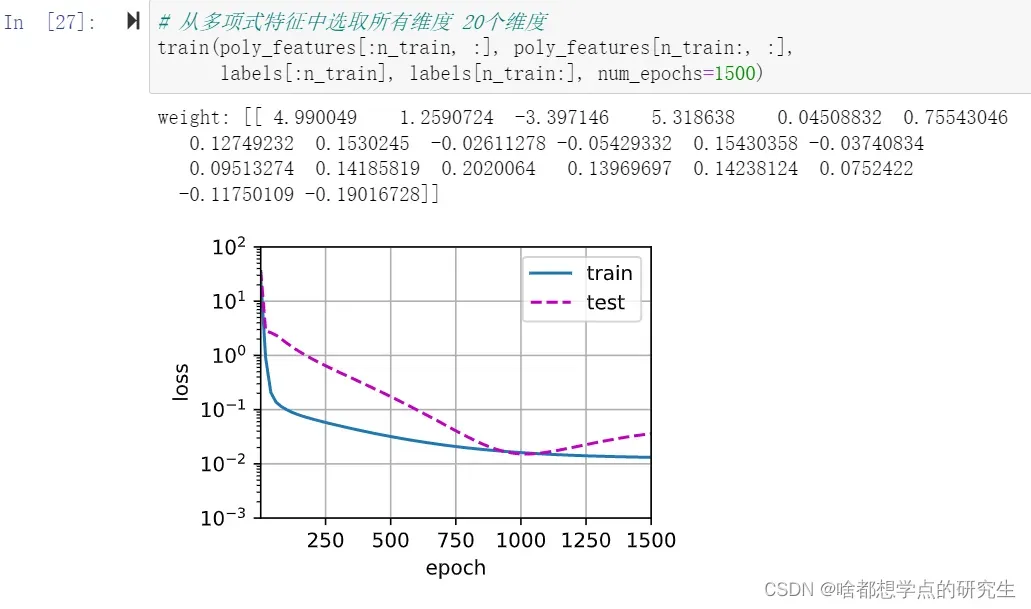
让我们尝试使用一个阶数过高的多项式来训练模型。 在这种情况下,没有足够的数据用于学到高阶系数应该具有接近于零的值。 因此,这个过于复杂的模型会轻易受到训练数据中噪声的影响。 虽然训练损失可以有效地降低,但测试损失仍然很高。 结果表明,复杂模型对数据造成了过拟合。
文章出处登录后可见!