文@ 000002
不久前,MIM 正式出道,我们也在知乎上介绍了 MIM 的基本使用,详情请看这篇文章
OpenMMLab 新工具出道:MIM is all you need
自 MIM 出道以来,我们收到了社区小伙伴们不少积极的反馈,不少朋友大呼真香,也有不少朋友询问怎么基于 MIM 快速构建自己的新项目。那么今天,我们就来好好说道说道,如何基于 MIM 快速构建自己的新项目,本文用到的样例可见 https://github.com/open-mmlab/mim-example
样例一:开发新算法
作为 OpenMMLab 各个算法库的统一入口,MIM 可以一行命令启动各个算法库的训练和测试,因此,新的项目可以不再维护或依赖算法库的训练/测试入口,开发者可以将开发更加聚焦在新的模块添加上,从而显著提升研发效率。我们首先以 SwinTransformer 为例,讲解基于 MIM 开发并使用新算法的全过程。
(PS:目前最新版的 MMClassification 和 MMSegmentation 已经支持了SwinTransformer ,MMDetection 的支持也在路上啦~)
一键安装预编译 MMCV
首先我们可以基于 MIM 安装项目依赖,MIM 会自动检查 CUDA 和 PyTorch 环境并尽量帮我们安装和环境匹配的预编译版本的 MMCV-full,从而省去编译的耗时。相比以前还需要手动检查环境和 CUDA 并且去找到对应的预编译包的路径,现在 MIM 已经将 MMCV-full 的安装流程一键化了。
pip install openmim>=0.1.1 # install mim through pypi
pip install timm # swin transformer relies timm
mim install mmcv-full==1.3.5 # install mmcv
MKL_THREADING_LAYER=GNU mim install mmdet==2.13.0 # install mmdet to run object detection
MKL_THREADING_LAYER=GNU mim install mmsegmentation=0.14.0 # install mmseg to run semantic segmentation
另外,我们还通过 MIM 安装了 MMDetection 和 MMSegmentation,这样确保了我们可以通过 MIM 来启动这两个项目的训练和测试。同时,这个项目也是把 MMDetection 和 MMSegmentation 当作 Library 来使用的,稍后我们会发现,无需 folk MMDetection 和 MMSegmentation 两个项目或者把当前项目的代码放到 MMDet/MMSeg 的文件夹下,我们可以使用一份代码实现用于这两个 repo 中相关任务的训练和测试。
一份代码实现,多个任务
整个 SwinTransformer 项目的代码目录结构如下。涉及到 SwinTransformer 项目的代码只有6个文件(_base_配置文件是从 MMDet/MMSeg 复制的不算)。其中包括 SwinTransformer 的算法实现swin_transformer.py 和预训练模型加载并转 key 的 swin_checkpoint.py 。其余的都是配置文件,配置文件中有两个用于实例分割任务,一个用于语义分割。
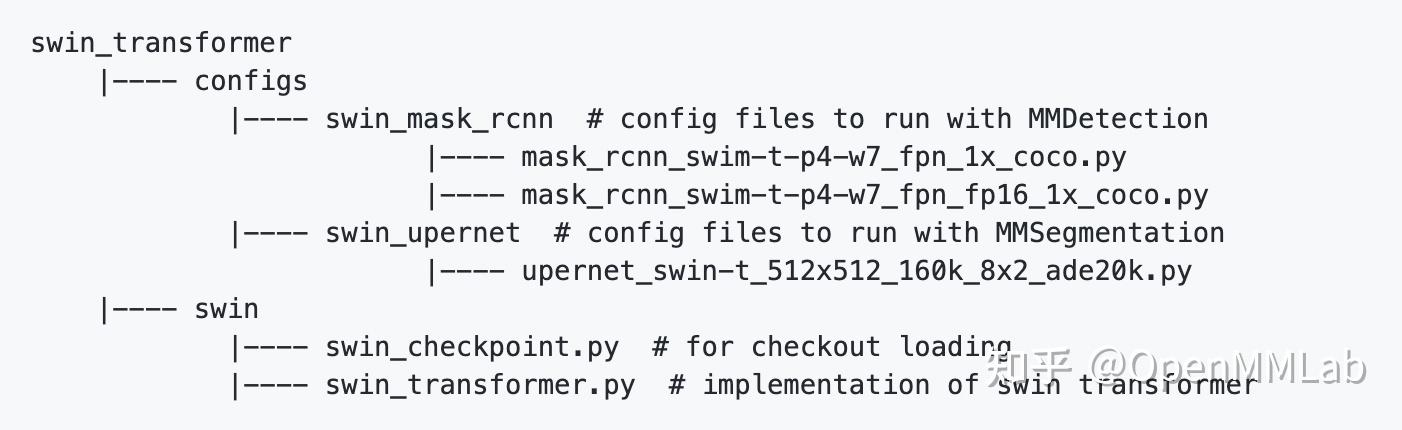
能做到如此轻量化,诀窍在于使用了 MMCV 的 registry。SwinTransformer 的关键代码如下所示
from mmcv.cnn import MODELS
@MODELS.register_module()
class SwinTransformer(nn.Module):
# code implementation
def __init__(self, *args, **kwargs):
super().__init__() 因为在实现的时候使用了 MMCV 的 registry,同时 MMDetection 和 MMSegmentation 已经在新版中将 model 的 registry 继承自了 MMCV,因此,在 MMDetection 和 MMSegmentation 的模型 registry 中存在了一个 字符串'mmcv.SwinTransformer' 到类 <class 'SwinTransformer'> 的映射。在 MaskRCNN 的配置文件中,我们就可以通过如下方式使用这份代码实现

在这个配置文件中,我们通过 custom_imports 导入了自己的代码,使得真正代码运行起来的时候 SwinTransformer 能被加进 registry 中,然后我们通过 'mmcv.SwinTransformer'确保了代码运行时 registry 能找到这个实现并实例化一个 SwinTransformer 的 backbone。
训练与测试
使用 MIM 作为统一的入口,我们可以快速启动模型的训练和测试,如下为使用 MMDetection/MMSegmentation 训练的例子,可以发现,即使当前项目没有放到 MMDetection/MMSegmentation 的源码文件夹下,我们也能通过 mim 来启动 MMDetection/MMSegmentation 训练自己新加入的模型。
PYTHONPATH='.':$PYTHONPATH mim train mmdet configs/swin_mask_rcnn/mask_rcnn_swim-t-p4-w7_fpn_fp16_1x_coco.py \--work-dir ../work_dir/mask_rcnn_swim-t-p4-w7_fpn_fp16_1x_coco.py --launcher slurm --partition $PARTITION --gpus 8 --gpus-per-node 8 --srun-args $SRUN_ARGS
# 使用 mmseg
PYTHONPATH='.':$PYTHONPATH mim train mmseg configs/upernet/upernet_swin-t_512x512_160k_8x2_ade20k.py --work-dir ../work_dir/upernet_swin-t_512x512_160k_8x2_ade20k.py --launcher slurm --partition $PARTITION --gpus 8 --gpus-per-node 8 --srun-args $SRUN_ARGS
样例二:使用新数据集
另外一个经常需要添加的模块是 数据集,因此,我们以 nuImages 数据集为例,讲解基于 MIM MMSegmentation 使用 nuImages 跑模型的全过程。
(PS:目前 MMDetection3D 已经支持了基于 nuImages 的实例分割,也欢迎大家去使用~)
整个项目的代码目录结构如下。整个项目同样非常轻量化,包括数据集的转换脚本,数据集的模块实现,和 PSPNet 在 nuImages 数据集上的配置模型。

新的数据集模块
根据 official documentation. 语义分割的标注存储在若干 json 文件中,我们通过 nuimages API 将他们读取出来并转换成 PNG 格式的 mask 用于训练。语义类的定义和 nuScens 的定义保持了一致。我们提供了一个脚本完成上述步骤,可以按照如下命令进行使用。
python -u nuim_converter.py \
--data-root $DATA \
--versions $VERSIONS \
--out-dir $OUT \
--nproc $NUM_WORKERS 在数据集转换完成后,我们可以得到的数据集结构如下

然后我们就可以基于这个结构去支持一个新的数据集类了。
import os.path as osp
import mmcv
from mmcv.utils import print_log
from mmseg.datasets import CustomDataset
from mmseg.datasets.builder import DATASETS
from mmseg.utils import get_root_logger
@DATASETS.register_module()
class NuImagesDataset(CustomDataset):
CLASSES = ()
def load_annotations(self, img_dir, img_suffix, ann_dir,
seg_map_suffix, split):
annotations = mmcv.load(split)
img_infos = []
for img in annotations['images']:
img_info = dict(filename=img['file_name'])
seg_map = img_info['filename'].replace(
img_suffix, seg_map_suffix)
img_info['ann'] = dict(
seg_map=osp.join('semantic_masks', seg_map))
img_infos.append(img_info)
print_log(
f'Loaded {len(img_infos)} images from {ann_dir}',
logger=get_root_logger())
return img_infos 新的数据集支持采用继承的方式,我们只需要重载 load_annotations 函数将数据解析成 MMSegmentation 的中间格式,然后就可以跑模型啦~
定义新的数据集配置
和 MMSegmentation 中的其他数据集一样,我们也定义了一个新的数据集基础配置,方便和任意新算法的配置进行组合。如下图所示,主要需要定义 train_pipeline 和 test_pipeline,以及修改数据集的类型和 split 文件即可。custom_imports 确保了运行的时候模块被正确加载。

训练与测试
最终,我们可以使用如下命令启动 MMSegmentation 来训练模型
PYTHONPATH='.'$PYTHONPATH mim train mmseg \
configs/pspnet/pspnet_r18-d8_512x1024_80k_nuim.py
--work-dir $WORK_DIR \
--launcher slurm -G 8 -p $PARTITION 我们可以通过如下命令测试训练得到的模型。
PYTHONPATH='.'$PYTHONPATH mim test mmseg \
configs/pspnet/pspnet_r18-d8_512x1024_80k_nuim.py
--checkpoint $WORK_DIR/latest.pth \
--launcher slurm -G 8 -p $PARTITION \
--eval mIoU 总结
通过 MIM,我们可以快速的开发新的算法或者支持新的数据集。在这个新的项目中,我们只需要像 import torch 那样 import OpenMMLab 算法库中已实现的各个模块,实现自己的新模块,并将新模块加进一个 registry 中,就可以通过 mim 来使用这个新模块进行训练和测试。
相比以往 folk 代码 改代码的方式,新的方式无需 folk 代码,可以随时通过更新依赖的方式享受最新版 OpenMMLab 算法库的红利,也无需维护 folk 版的代码,使得项目从此非常轻量化。
PS:以后 OpenMMLab 团队的成员进行的 research project 也都会以这种方式以最快速度添加到 MIM-example 中,大家敬请期待吧~
版权声明:本文为博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!