目录
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM 还包括核技巧,这使它成为实质上的非线性分类器。SVM 的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM 的的学习算法就是求解凸二次规划的最优化算法。
SVM原理
SVM 是一种在特征空间中寻找最大间隔超平面的判别式、线性、二分类器。之所以去寻找最大间隔的超平面就是为了追求模型的最大鲁棒性,对未知数据有最强的泛化能力。例如我们对样本施加一些噪声,间隔越大,就越不容易被错误分到另一类,如图9.17所示 ,a 图为所有的数据点,b 图为支持向量机最终的最大间隔超平面,可以看到它对噪声有着很强的鲁棒性。但是 c 图的分类效果的鲁棒性很差。
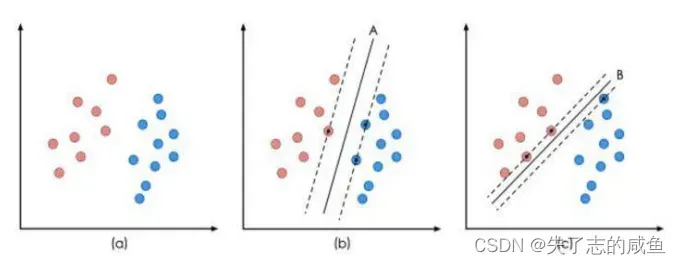
图 9.17 SVM原理
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。![]()
![]() 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。在推导之前,先给出一些定义。假设给定一个特征空间上的训练数据集:
即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。在推导之前,先给出一些定义。假设给定一个特征空间上的训练数据集:
![]()
其中,![]()
![]() ,
,![]()
![]()
超平面关于所有样本点的几何间隔的最小值为:
![]()
实际上这个距离就是我们所谓的支持向量到超平面的距离。根据以上定义,SVM模型的求解最大分割超平面问题可以表示为以下约束最优化问题:
![]()
![]()
将约束条件两边同时除以 ![]()
![]() ,得到:
,得到:
![]()
因为 ![]()
![]() 是标量,所以为了表达式简洁起见,令
是标量,所以为了表达式简洁起见,令![]()
![]() ,
,![]()
![]() ,又因为最大化
,又因为最大化 ![]()
![]() ,等价于最大化
,等价于最大化 ![]()
![]() ,也就等价于最小化
,也就等价于最小化![]()
![]() (
( ![]()
![]() 是为了后面求导以后形式简洁,不影响结果),因此SVM模型的求解最大分割超平面问题又可以表示为以下约束最优化问题:
是为了后面求导以后形式简洁,不影响结果),因此SVM模型的求解最大分割超平面问题又可以表示为以下约束最优化问题:
![]()
这是一个含有不等式约束的凸二次规划问题,可以对其使用拉格朗日乘子法得到其对偶问题,首先将有约束的原始目标函数转换为无约束的新构造的拉格朗日目标函数:
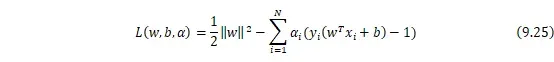
其中![]()
![]() 为拉格朗日乘子,且
为拉格朗日乘子,且 ![]()
![]() 。现在令
。现在令![]()
![]() ,当样本点不满足约束条件时,即在可行解区域外:
,当样本点不满足约束条件时,即在可行解区域外:![]()
![]() ,此时,将
,此时,将![]()
![]() 设置为无穷大,则
设置为无穷大,则 ![]()
![]() 也为无穷大。当满足本点满足约束条件时,即在可行解区域内:
也为无穷大。当满足本点满足约束条件时,即在可行解区域内:![]()
![]() ,此时,
,此时, ![]()
![]() 为原函数本身。于是,将两种情况合并起来就可以得到新的目标函数:
为原函数本身。于是,将两种情况合并起来就可以得到新的目标函数:
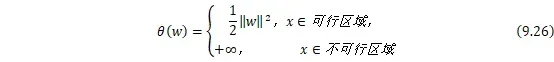
于是原约束问题就等价于:
![]()
新的目标函数先求最大值,再求最小值。这样的话,首先就要面对带有需要求解的参数![]()
![]() 和
和![]()
![]() 的方程,而
的方程,而![]()
![]() 又是不等式约束,这个求解过程不好做。所以需要使用拉格朗日函数对偶性,将最小和最大的位置交换一下,这样就变成了:
又是不等式约束,这个求解过程不好做。所以需要使用拉格朗日函数对偶性,将最小和最大的位置交换一下,这样就变成了:
![]()
要有![]()
![]() =
=![]()
![]() ,需要满足两个条件:
,需要满足两个条件:
- 优化问题是凸优化问题
- 满足KKT条件
首先,本优化问题显然是一个凸优化问题,所以条件一满足,而要满足条件二,即要求:
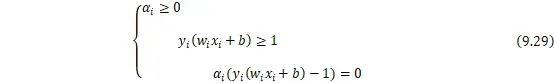
为了得到求解对偶问题的具体形式,令 ![]()
![]() 对
对![]()
![]() 和
和![]()
![]() 的偏导为0,用
的偏导为0,用![]()
![]() 将拉格朗日目标函数变为
将拉格朗日目标函数变为![]()
![]() 一个未知数的方式,对其求解
一个未知数的方式,对其求解![]()
![]() 后求对
后求对![]()
![]() 的极大,再把目标式子加一个负号,将求解极大转换为求解极小,这就是对偶问题。最后得到的问题形式如下:
的极大,再把目标式子加一个负号,将求解极大转换为求解极小,这就是对偶问题。最后得到的问题形式如下:
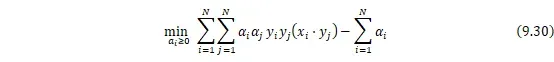
![]()
![]() ,
,![]()
![]()
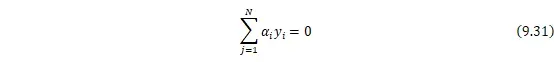
现在的优化问题变成了如上的形式。对于这个问题有更高效的优化算法,即序列最小优化(SMO)算法。正如上面提到的,既然知道了如果所有的拉格朗日乘子![]()
![]() 都满足KKT条件和对偶问题中的约束条件,那么这样的拉格朗日乘子
都满足KKT条件和对偶问题中的约束条件,那么这样的拉格朗日乘子![]()
![]() 一定是极值点。那就可以不停地试错,判断拉格朗日乘子
一定是极值点。那就可以不停地试错,判断拉格朗日乘子![]()
![]() 是不是满足约束条件,如果都满足就可以找到极值点
是不是满足约束条件,如果都满足就可以找到极值点![]()
![]() ,如果不满足,那我就优化选择到的乘子,重复此过程,直到得到优化结果。这就是SMO算法的大致思想。通过这个优化算法能得到
,如果不满足,那我就优化选择到的乘子,重复此过程,直到得到优化结果。这就是SMO算法的大致思想。通过这个优化算法能得到![]()
![]() ,再根据
,再根据![]()
![]() 就可以通过下式求解出
就可以通过下式求解出![]()
![]() 和
和![]()
![]() ,进而求得最初的目的:找到超平面,即”决策平面”。
,进而求得最初的目的:找到超平面,即”决策平面”。
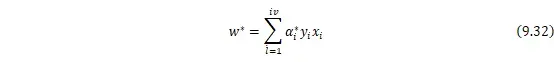
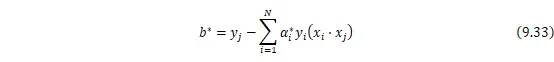
对于任意训练样本![]()
![]() ,总有
,总有![]()
![]() 或者
或者![]()
![]() 。若 ,则该样本不会在最后求解模型参数的式子中出现。若
。若 ,则该样本不会在最后求解模型参数的式子中出现。若![]()
![]() ,则必有
,则必有![]()
![]() ,所对应的样本点位于最大间隔边界上,是一个支持向量。这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关。
,所对应的样本点位于最大间隔边界上,是一个支持向量。这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关。
SVM模型训练过程
上面都是基于训练集数据线性可分的假设下进行的,但是实际情况下几乎不存在完全线性可分的数据,为了解决这个问题,引入了“软间隔”的概念,即允许某些点不满足约束,然后我们采用hinge损失,将原优化问题改写为:
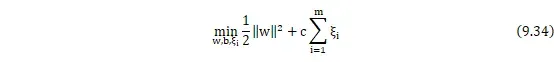
![]()
![]()
其中![]()
![]() 为“松弛变量”,
为“松弛变量”,![]()
![]() ,即为hinge损失函数。每一个样本都有一个对应的松弛变量,表征该样本不满足约束的程度。
,即为hinge损失函数。每一个样本都有一个对应的松弛变量,表征该样本不满足约束的程度。![]()
![]() 称为惩罚参数,
称为惩罚参数,![]()
![]() 值越大,对分类的惩罚越大。跟线性可分求解的思路一致,同样这里先用拉格朗日乘子法得到拉格朗日函数,再求其对偶问题可以得到线性支持向量机的训练算法如下:
值越大,对分类的惩罚越大。跟线性可分求解的思路一致,同样这里先用拉格朗日乘子法得到拉格朗日函数,再求其对偶问题可以得到线性支持向量机的训练算法如下:
- 选择惩罚参数
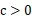
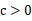 ,构造并求解凸二次规划问题:
,构造并求解凸二次规划问题:
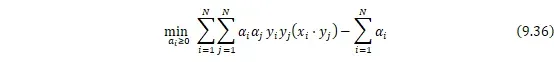
![]()
![]() c,
c, ![]()
![]()
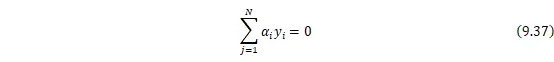
最后求解出最优解![]()
![]()
- 计算
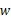 ,
,

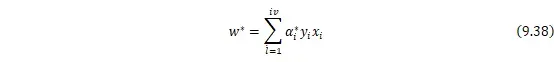
选择![]()
![]() 的一个分量
的一个分量![]()
![]() 满足条件
满足条件 ![]()
![]() ,计算
,计算![]()
![]()
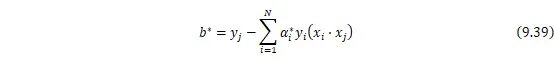
- 求最大间隔超平面
![]()
最后得到分类决策函数:
![]()
对于输入空间中的非线性分类问题,可以通过非线性变换将它转化为某个维特征空间中的线性分类问题,在高维特征空间中学习线性支持向量机。由于在线性支持向量机学习的对偶问题里,目标函数和分类决策函数都只涉及实例和实例之间的内积,所以不需要显式地指定非线性变换,而是用核函数替换当中的内积。核函数表示为![]()
![]() ,可以实现实例通过一个非线性转换后的内积。在线性支持向量机学习的对偶问题中,用核函数
,可以实现实例通过一个非线性转换后的内积。在线性支持向量机学习的对偶问题中,用核函数![]()
![]() 替代内积,求解得到的就是非线性支持向量机的分类决策函数:
替代内积,求解得到的就是非线性支持向量机的分类决策函数:
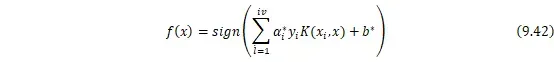
最后介绍一个常用的核函数——高斯核函数,其对应的SVM是高斯径向基函数分类器。
![]()
基于SVM的行人检测实战
上一节已经介绍了目标检测中图像特征提取方式Haar特征,HOG特征以及DMP特征。HOG特征更倾向于轮廓的检测,比如行人的检测;而Haar特征则能更好的描述敏感的变化,更适于检测人脸。下面介绍如何通过opencv实现行人检测,Opencv利用HOG特征实现行人检测,包括了HOG的特征提取和SVM识别两部分。本节将提到两种方式:
- 利用Opencv自带的已训练好的行人检测模型直接进行检测。
- 通过设置训练的正负样本得到HOG特征,并训练SVM,得到模型,最后进行行人的检测。
(1)OpenCV自带行人检测器实现行人检测
利用OpenCV自带的行人检测其实现行人检测主要有三步:
- 初始化HOG描述子;
- 设置HOG中的SVM为已训练好的SVM模型;
- 读取图像,检测,并在图像中显示出检测结果;
下面是使用opencv自带的hog目标检测模型结合其训练好的SVM实现行人检测。
import cv2
#待检测图像的文件路径
base_path = 'image/people.jpg'
img=cv2.imread(base_path)
#初始化HOG描述子
hog = cv2.HOGDescriptor()
# 设置支持向量机,其为一个预先训练好的行人检测器
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
#检测行人
rects, wei = hog.detectMultiScale(img, winStride=(4, 4), padding=(8, 8),
scale=1.05)
for (x, y, w, h) in rects:
#将检测结果在图像中圈出来
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
#显示图像
cv2.imshow("people detect", img)
cv2.waitKey(0)

图 9.18 行人检测
如图9.18所示使用opencv自带模型很好的实现了图像中行人的检测,下面对我们用到的检测器进行简单的介绍。
cv2.HOGDescriptor():OpenCV中的HOG特征提取功能使用了HOGDescriptor这个类来进行封装。其中包含了许多函数,下面列举了常用的一些函数:
- getDetectorSize(self):获得设置的hog描述子的维数;
- compute(self,,img,,winStride=None,padding=None, locations=None):计算输入的检测窗口的hog描述子;
- computeGradient(self,,img,grad,angleOfs,paddingTL=None,paddingBR=None):计算输入图像的梯度幅度图像;
- setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()):设置训练好的支持向量机检测器;
- detectMultiScale(self,img,hitThreshold=None,winStride=None,padding=None,scale=None, finalThreshold=None, useMeanshiftGrouping=None):对输入图像进行检测,并且返回目标位置与目标的权重。
(2)利用opencv实现HOG检测器的自定义数据训练
上面使用了自带的模型,较为简单。下面的代码可以通过设置正负样本,自己提取HOG特征,然后训练出SVM模型,进而进行检测得到结果。基本步骤如下:
训练模型
- 准备正样本和负样本;
- 计算样本的HOG特征;
- 训练SVM模型;
- 将训练好的SVM模型设置为opencv 中的SVM模型,得到训练好的行人检测器;
- 利用自己训练的检测器进行检测
下面是实现训练模型的代码,主要包括加载正样本行人标签信息的函数load_imgelable( ),加载正样本图片,并且进行尺度归一化的函数load_imge1( ),加载负样本所有原图片的函数load_imge2( ),从负样本原图片截取64*128的图像作为训练负样例的函数sample_neg( ),计算图像的HOG特征的函数compute_hog( ),初始化要训练的svm参数的函数svm_init( ),获取svm的支持向量的函数get_svm_detector(svm)
load_imgelable( )的核心代码如下:
def load_imgelable(dirname, imageNum=500):
'''
通过pascal格式的文件加载图像的中的行人数量,行人的位置信息的标签
:param dirname: 存储图像标签pascal格式文件的路径的文件,如annotations.lst
:param imageNum: 要读取的图像数目
:return: 返回存储图像方框数量与位置信息的list
'''
people_num=[]#每张照片里的行人数量
people_coordinate=[]#每张照片里的行人标注框坐标
cnt = imageNum
file = open(dirname)
imglab = file.readline()
while imglab != '':
#文件末尾
imglab_name = dirname.rsplit(r'/',1)[0] + r'/'+ imglab.split('/', 1)[1].strip('\n')
#图像路径
f = open(imglab_name, encoding='gbk')
line_list = f.readlines()
for line in line_list:
if str(line).__contains__('Objects with ground truth'):
nums = re.findall(r'\d+', str(line))
people_num.append(nums[0])
break
for index in range(1, int(nums[0]) + 1):
for line in line_list:
if str(line).__contains__("Bounding box for object " + str(index)):
coordinate = re.findall(r'\d+', str(line))
people_coordinate.append([coordinate[1],coordinate[2],
coordinate[3],coordinate[4]])
break
f.close()
cnt = cnt-1
if cnt == 0:
break
imglab = file.readline()
return [people_num,people_coordinate] #返回所有图像的标注内容
load_imge1( )函数的核心代码如下:
def load_imge1(dirname,people_num,people_coordinate,imageNum=500, showImage = False):
'''
加载正样本图像,并进行尺度归一化
:param dirname: 存储图像名称的文件,如pos.lst
:param imageNum: 要读取的图像数目
:param showImage: 是否显示图像
:return: 返回存储图像内容的list
'''
img_list = []
cnt = imageNum
file = open(dirname)
img = file.readline()
flag0=0
while img != '': #文件末尾
flag1=imageNum-cnt
for i in range(0,int(people_num[flag1])):
[Xmin,Ymin,Xmax,Ymax]=people_coordinate[flag0]
imgid=img.rsplit('/', 1)[1].strip('\n')
img_name = dirname.rsplit(r'/',1)[0] + r'/'+ img.split('/', 1)[1].strip('\n') #图像路径
img_all = cv2.imread(img_name,0) #将图像读取,并转为灰度图像
w=(int(Ymax)-int(Ymin))/2-int(Xmax)+int(Xmin)
if (int(Xmin)-int(w/2))>0:
img_cut=img_all[int(Ymin):int(Ymax),(int(Xmin)-int(w/2)):(int(Xmax)+int(w/2))]
else:
img_cut=img_all[int(Ymin):int(Ymax),int(Xmin):int(Xmax)]
img_content=cv2.resize(img_cut,dsize=(64,128))
img_list.append(img_content)
flag0=flag0+1
if showImage: #是否显示图像,默认否
cv2.imshow(img_name+str(i), img_content)
cv2.waitKey(10)
cnt = cnt-1
if cnt == 0:
break
img = file.readline()
return img_list #返回所有图像的内容
load_imge2( )函数的核心代码如下:
def load_imge2(dirname, imageNum = 500, showImage = False):
'''
加载负样本的图像
:param dirname: 存储图像名称的文件,如pos.lst
:param imageNum: 要读取的图像数目
:param showImage: 是否显示图像
:return: 返回存储图像内容的list
'''
img_list = []
cnt = imageNum
file = open(dirname) #
img = file.readline()
while img != '': #文件末尾
img_name = dirname.rsplit(r'/',1)[0] + r'/'+ img.split('/', 1)[1].strip('\n') #图像路径
img_content = cv2.imread(img_name,0) #将图像读取,并转为灰度图像
img_list.append(img_content)
if showImage: #是否显示图像,默认否
cv2.imshow(img_name, img_content)
cv2.waitKey(10)
cnt = cnt-1
if cnt == 0:
break
img = file.readline()
return img_list #返回所有图像的内容
sample_neg( )函数的核心代码如下:
def sample_neg(neg_sample_all, imageNum=500, size=(64,128)):
"""
获取负样例,从没有行人的图片中截取64*128的图像作为训练负样例
:param neg_sample_all: 所有没有行人的图像
:param imageNum: 负样本的数目
:param size: 截取的图像的大小
:return: 返回负样本图像的内容
"""
neg_sample_list = []
cnt = imageNum
width, height = size[0], size[1] #图像的宽度和高度
for i in range(len(neg_sample_all)):
row, col = neg_sample_all[i].shape
for j in range(2):
y = int(random.random()*(row - height)) #随机选择图像截取的起点,也就是说从图像中随机截取的图像
x = int(random.random()*(col - width))
neg_sample_list.append(neg_sample_all[i][y:y+height, x:x+width])
cnt = cnt-1
if cnt == 0:
break
return neg_sample_list
compute_hog( )函数的核心代码如下:
def compute_hog(img_list, wsize = (64, 128)):
"""
计算图像的HOG特征
:param img_list:
:param wsize: #图像的大小
:return:
"""
gradient_list = []
hog = cv2.HOGDescriptor() #初始化HOG描述子
for i in range(len(img_list)):
if img_list[i].shape[1] >= wsize[0] and img_list[i].shape[0] >= wsize[1]:
#图像要大于需要的图像的大小
roi = img_list[i][(img_list[i].shape[0] - wsize[1]) // 2:
(img_list[i].shape[0] - wsize[1]) // 2 + wsize[1],
(img_list[i].shape[1] - wsize[0])//2 :
(img_list[i].shape[1] - wsize[0])//2 + wsize[0]]
hog_data = hog.compute(roi) #计算截取的图像的 HOG特征
gradient_list.append(hog_data)
return gradient_list #返回图像的HOG特征
svm_init( )函数的核心代码如下:
def svm_init(): #初始化svm
svm = cv2.ml.SVM_create() #
svm.setCoef0(0)
svm.setDegree(3) #多项式核时,变量的阶数
criteria = (cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 1000, 1e-3)
svm.setTermCriteria(criteria)
svm.setGamma(0) #
svm.setKernel(cv2.ml.SVM_LINEAR) #SVM的核函数
svm.setNu(0.5)
svm.setP(0.1)
svm.setC(0.01)
svm.setType(cv2.ml.SVM_EPS_SVR) #SVM的类型
return svm
get_svm_detector( )函数核心代码如下:
def get_svm_detector(svm): #获取SVM特征向量
sv = svm.getSupportVectors() #获取支持向量
rho, _, _ = svm.getDecisionFunction(0)
sv = np.transpose(sv)
return np.append(sv, [[-rho]], 0)
最后是我们调用这些函数进行训练的主程序代码,训练完成后我们会把训练好的SVM分类器保存成一个myHogDector.bin的文件,以供我们检测阶段时,加载使用。核心代码如下:
import cv2
import numpy as np
import random
import re
if __name__ == "__main__":
print("加载训练样本")
base_path = 'INRIAPerson//'
[people_num,people_coordinate]=load_imgelable(base_path+"Train//annotations.lst", imageNum=614)
# 加载正例图像,大小均为(64*128)
pos_list = load_imge1(base_path+"Train//pos.lst",people_num,
people_coordinate,imageNum=614, showImage=False) #正样本
# 负例图像,大小不定,需要裁剪
neg_list_all = load_imge2(base_path+"Train//neg.lst",
imageNum=1218, showImage=False)
neg_list = sample_neg(neg_list_all, imageNum=1218, size=[64, 128]) #行人,一般是站立的,负例图像
print("加载训练样本完成")
ylabels = []
gradient_list = []
print("计算HOG特征")
pos_gradient_list = compute_hog(pos_list, wsize=(64, 128)) #计算HOG特征
[ylabels.append(1) for _ in range(len(pos_list))] #正例标签
neg_gradient_list = compute_hog(neg_list, wsize=(64, 128)) #计算HOG特征
[ylabels.append(-1) for _ in range(len(neg_list))] #负例标签
gradient_list.extend(pos_gradient_list)
gradient_list.extend(neg_gradient_list)
print("计算HOG特征完成")
print("训练SVM模型")
svm = svm_init() #初始化svm
svm.train(np.array(gradient_list),
cv2.ml.ROW_SAMPLE, np.array(ylabels)) #训练SVM模型
hog = cv2.HOGDescriptor() #hog描述子
hard_neg_list = []
hog.setSVMDetector(get_svm_detector(svm)) #setSVMDetector用于加载svm模型,对hog特征分类的svm的系数赋值
#加入错误分类的标签,重新对svm进行训练
for i in range(len(neg_list_all)):
rects, wei = hog.detectMultiScale(neg_list_all[i], winStride=(2,2), padding=(8,8), scale=1.01)
for (x,y, w,h ) in rects:
merge=int(h/2)
hardExample = neg_list_all[i][y:y+h, x:x+merge]
hard_neg_list.append(cv2.resize(hardExample,(64,128)))
hard_gradient_list = compute_hog(hard_neg_list)
[ylabels.append(-1) for _ in range(len(hard_neg_list))]
gradient_list.extend(hard_gradient_list)
#训练svm
svm.train(np.array(gradient_list), cv2.ml.ROW_SAMPLE, np.array(ylabels))
#保存hog
hog.setSVMDetector(get_svm_detector(svm))
hog.save('myHogDector.bin')
print("训练SVM模型完成")
测试模型
通过上面的学习,已经训练了一个自己的SVM分类器,下面就可以用自己的分类器对任意一张图片进行行人检测,检测的步骤其实跟OpenCV自带行人检测器实现行人检测的方式,只需要把其中的检测器换成自己的分类。主要步骤如下:
- 初始化HOG描述子;
- 加载已训练好的检测器;
- 读取图片并进行检测;打印显示检测结果;
下面是实现检测功能的核心代码:
import cv2
base_path = 'image/people.jpg'#待检测图像的文件路径
img=cv2.imread(base_path)
hog = cv2.HOGDescriptor() #初始化HOG描述子
# 设置支持向量机,其为一个预先训练好的行人检测器
hog.load('myHogDector.bin')
rects, wei = hog.detectMultiScale(img, winStride=(2, 2), padding=(8, 8), scale=1.05) #检测行人
for (x, y, w, h) in rects:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2) #将检测结果在图像中圈出来
cv2.imshow("people detect", img) #显示图像
cv2.waitKey(0)如图9.19为自己训练的检测器的结果,明显可以看到,在图9.19中的训练结果几乎与opencv自带的行人检测器效果差不多。当然也还可以通过增大训练样本集,改善样本的质量等方法继续提高自己训练的模型。

图 9.19 输出结果
文章出处登录后可见!