目录标题
基于图神经网络的图分类问题
- 图神经网络的本质工作就是特征提取,并在图神经网络的最后实现图嵌入(将graph转为特征向量)。
- 过程:首选使用图神经网络进行graph的特征提取,最后进行readout操作(将graph的信息转换为可直接用于分类的n维特征向量),然后送入softmax进行分类,实现对graph的分类(如果有传统卷积神经网络分类经验的话应该很好理解)。
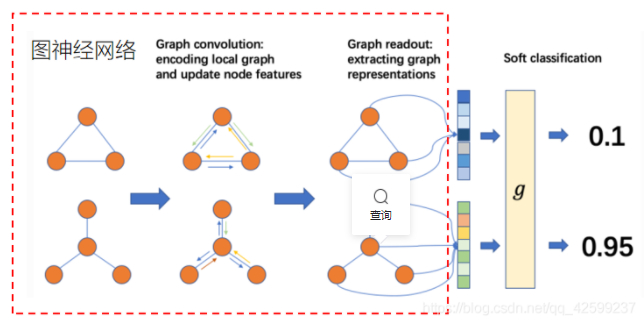
在本文中,图分类具体表示为下图(可与上图比较相看,利于理解)。
Input Video可根据人体关键点组成graph,作为输入数据,
中间的ST-GCNs负责特征提取
最后readout用于softmax分类。

GCN在行为识别领域的应用
学习文章:GCN行为识别应用
内容:选取了自18年以来将GCN和行为识别相结合的代表性工作论文,用于讨论并分析这些工作的核心思想,以及在此基础上可以尝试的idea。
主要任务
行为识别的主要任务是分类识别,对给定的一段动作信息(例如视频,图片,2D骨骼序列,3D骨骼序列),通过特征抽取分类来预测其类别。目前(18年过后)基于视频和RGB图片的主流方法是two-stream双流网络,而基于骨骼数据的主流方法就是图卷积网络了。
研究思路
人体的骨骼图本身就是一个拓扑图,因此将GCN运用到动作识别上是一个非常合理的想法。
但不同于传统的图结构数据,人体运动数据是一连串的时间序列,在每个时间点上具有空间特征,而在帧于帧之间则具有时间特征,如何通过图卷积网络来综合性的发掘运动的时空特征,是目前的行为识别领域的研究热点。
笔者选取了自18年以来将GCN和行为识别相结合的代表性工作,用于讨论并分析这些工作的核心思想,以及在此基础上可以尝试的idea。
ST-GCN(SpatialTemporal Graph Convolutional Networks for Skeleton-Based Action Recognition)解读
原论文
原始论文
这种算法基于人类关节位置的时间序列表示而对动态骨骼建模,并将图卷积扩展为时空图卷积网络而捕捉这种时空的变化关系。
作者提出了一个新颖的动态骨架模型ST-GCN,它可以从数据中自动地学习空间和时间的patterns,这使得模型具有很强的表达能力和泛化能力
解决问题
用于解决基于人体骨架关键点的人类动作识别问题
1.使用 OpenPose 处理了视频,提出了一个数据集
2.结合 GCN 和 TCN 提出了模型,在数据集上效果还不错
主要贡献
-
1.将图卷积网络扩展到时空域,称为时空图卷积网络(ST-GCN)。
对于每个关节而言,不仅考虑它在空间上的相邻关节,还要考虑它在时间上的相邻关节,也就是说将邻域的概念扩展到了时间上。 -
2.新的权重分配策略,文章中提到了三种不同的权重分配策略:
-

图(b)单标签划分策略,将节点和其1邻域节点划分到相同的子集中,使他们具有相同的label,自然也就具有相同的权重。这样的话每个kernel中的权重实际上就是一个1*N的向量,N是节点的特征维数。
图©按距离划分,将节点自身划分为一个子集,1领域划分到一个子集。每个kernel的权重是一个2*N的向量。
图(d)空间构型划分,节点与重心距离划分,距离重心更近(相对于中心节点)的1邻域节点为一个子集,距离重心更远的1邻域节点为一个子集,中心节点自身为1个子集。每个kernel的权重是一个3*N的向量。
经过测试发现第三种策略效果最好,这是因为第三种策略实际上也包含了对末肢关节赋予更多关注的思想,通常距离重心越近,运动幅度越小,同时能更好的区分向心运动和离心运动。
核心思想
1.将图卷积扩展到了时域上,从而更好的发掘动作的运动特征,而不仅仅是空间特征。
2.设计了新的权重分配策略,能更加差异化地学习不同节点的特征。
3.合理的运用先验知识,对运动幅度大的关节给予更多的关注,潜在的体现在权重分配策略中。
简介

该模型是在骨骼图序列上制定的,其中每个节点对应于人体的一个关节。图中存在两种类型的边,即符合关节的自然连接的空间边(spatial edge)和在连续的时间步骤中连接相同关节的时间边(temporal edge)。在此基础上构建多层的时空图卷积,它允许信息沿着空间和时间两个维度进行整合。
OpenPose 预处理
openpose是一个开源的人体关键点检测工具,是一个标注人体的关节(颈部,肩膀,肘部等),连接成骨骼,进而估计人体姿态的算法。作为视频的预处理工具,我们只需要关注 OpenPose 的输出就可以了
ST-GCN直接使用openpose工具进行人体关键点提取(将输入视频分割为多个帧,对每一帧进行关键点检测,并将其打包,用于后续操作)
总的来说,视频的骨骼标注结果维数比较高。在一个视频中,可能有很多帧(Frame)。每个帧中,可能存在很多人(Man)。每个人又有很多关节(Joint)。每一个关节又有不同特征(位置、置信度)。

对于一个 batch 的视频,我们可以用一个 5 维矩阵(N,C,T,V,M) 表示。
N.代表视频的数量,通常一个 batch 有 256 个视频(其实随便设置,最好是 2 的指数)。
C 代表关节的特征,通常一个关节包含 等 3 个特征(如果是三维骨骼就是 4 个)。
T代表关键帧的数量,一般一个视频有 150 帧。
V代表关节的数量,通常一个人标注 18 个关节。
M代表一帧中的人数,一般选择平均置信度最高的 2 个人。
所以,OpenPose 的输出,也就是 ST-GCN 的输入
基于人体关键点构造graph
现在我们有了一段视频中,不同帧之中的人体关键点信息。我们在骨架序列上构造了一个无向时空图G = (V, E),该骨架序列包含N个关节和T个帧,同时具有体内和帧间连接,即时间-空间graph
组合方法:把一帧中每个人体关键点作为node,人体关键点之间的自然连接和时域连接作为edge,构成graph(可以理解为三维的graph),如下图所示。

构造单帧graph(空间域)
一个graph可表示为G = (V, E),V为节点特征(node),E为边特征(edge)
其中V = {vti|t = 1, . . . , T, i =1, . . . , N}
即vti表示不同节点特征,其中t表示不同帧的节点(即时间域),i表示同一帧中不同人体关键点(节点),vti的维度为(x,y,confidence),其中x,y为该关键点的坐标,confidence为该关键点的置信度。
根据V节点即可即可组成单帧的graph(即上图的深蓝色部分)。
构造帧间graph(时间域)
在连续帧中找到相同节点,并将其连成时域信息(edge的信息)。
edge信息由两个子集组成。
第一个子集:同一帧中,关键点间的关系(i表示同一帧中不同的关键点,j表示不同帧间的同一关键点)

第二个子集:不同帧间的人体关节间的关系

至此,根据一段视频中不同帧的人体关键点信息组成了,包含空间与时间信息的graph。
其中,节点信息为(横坐标,纵坐标,置信度);边信息为(ES,EF)。
ST-GCN模型
ST-GCN模型中介绍了如何对上述过程构造的graph进行计算。
传统卷积网络的公式:

其中,p为采样函数,采样x像素点周围h,w范围内的相邻像素点做卷积运算;W为权重函数,提供用于与输入采样特征进行内积运算的权重矩阵。
将这种方法扩展至graph上,
x像素点等同于graph的node;
一个像素点位置包括n维特征,等同于一个node上包含着n维特征。
在此定义graph上的卷积运算,即把Vt节点特征经过卷积运算后得到c维的向量特征。

对graph上的采样函数p和权重函数w进行重新定义。
采样函数
传统卷积神经网络中,采样函数可以理解为卷积核的大小,即每次进行卷积运算(特征提取)时所覆盖的范围。例如,一个3*3的卷积核,在对某一个像素点进行卷积操作时,实际是将该像素点于其相邻的8个像素点的信息进行计算、聚合。
ST-GCN中,节点等同于传统卷积的图像像素点,采样函数就是负责指定对每个节点进行图卷积操作时,所涉及到的相邻节点范围,在本文中D = 1,即一阶相邻节点(直接相连的节点),用公式表示如下,其中d表示两个节点间的距离。

对于D=1,采样函数p可以写为下式,即只采样直接相邻的节点

可视化如下图,这张图在原文中是解释分区策略的,但也比较适合解释采样函数。若以红色节点为计算图卷积的中心node,则其采样范围为红色虚线内的节点,也就是D=1的相邻节点。

权重函数
- 传统神经网络中,权重函数可通过按照空间顺序(如从左到右、从上到下)索引一个(c,K,K)维张量(即c *K *K的卷积核)进行来实现。
- 对于graph,没有这种默认的空间排列,所以需要自定义一种排列方式。
本文采用方法:对graph中某node的相邻node进行子集划分,每个子集都有一个label,即实现映射:

将相邻节点映射至它所属的子集label。具体划分规则在后文有具体介绍。
至此,权重函数(W(vti, vtj)表示基于某node及其邻域得到权重向量Rc)

可以通过直接下标一个(c,K)张量实现,或用下式(lti(vtj)表示vtj在以vti为中心节点进行分子集标签中的所属标签)实现

空域图卷积

空间-时间模型
在上一小节,我们已经得到了针对广义graph的卷积运算公式,现在针对ST-GCN中的空间-时间graph进行图卷积公式的进一步优化更新。
在时间-空间graph上定义相邻节点:

从上式可以看出,相邻节点的定义是“在空间距离上小于K,在帧距离上前后小于Γ/2”,即在空间邻域的定义上加入了时间约束。
上文介绍的采样函数、权重函数是针对空间graph的,时间上的图卷积也需要一套采样函数、权重函数。其基本原理一致,只是重新定义一下标签分组的映射函数,其余计算方式相同

分区策略
文章中共提到三种分区策略,如下图所示。我对分区label的理解就是,同一个分区中的节点在卷积计算时,与之内积的权重向量是一样的,有几个分区就有几种权重向量。
(a) 输入骨骼序列的示意图,红色节点为本次卷积计算的中心节点,红色虚线内蓝色节点为其采样的相邻节点。
(b) 单一划分:把节点的邻域节点全划为一个子集(包括自身)
缺点:邻域节点与同一个权重进行内积,无法计算局部微分属性。
©基于距离划分:中心节点为一类,相邻节点(不包括自身)为另一类
(d) 空间配置划分(也是本文真正采用的方法,这么分配或许更能表征人体关键点的向心运动与离心运动):按照关节点的向心离心关系定义,r表示节点到骨骼图重心的平均距离。此时对于一个节点的卷积运算,其权重矩阵包括三种权重向量。

将节点的1邻域划分为3个子集,第一个子集连接了空间位置上比根节点更远离整个骨架的邻居节点,第二个子集连接了更靠近中心的邻居节点,第三个子集为根节点本身,分别表示了离心运动、向心运动和静止的运动特征
可学习的边重要性权重
因为人体在运动时,某几个关节经常时成团运动(如手腕和肘),并且可能出现在身体的各个部分,因此这些关节的建模应包含有不同的重要性。
为此,ST-GCN为每层添加了一个可学习的掩膜M,它基于骨骼graph中边的信息学习到的重要性权重来衡量该节点特征对其相邻节点的贡献度。
即:ST-GCN为由人体关键点构成的graph中的每个边都赋予了一个衡量这条边所连接的两个节点间相互影响大小的值,而这个值是通过graph的边信息训练学习得到的。
这种方法提升了ST-GCN的效果,文章最后说可以再考虑加入注意力机制。
TCN
GCN 帮助我们学习了到空间中相邻关节的局部特征。
在此基础上,我们需要学习时间中关节变化的局部特征。
如何为 Graph 叠加时序特征,是图网络面临的问题之一。这方面的研究主要有两个思路:时间卷积(TCN)和序列模型(LSTM)。
ST-GCN 使用的是 TCN,由于形状固定,我们可以使用传统的卷积层完成时间卷积操作。为了便于理解,可以类比图像的卷积操作。st-gcn 的 feature map 最后三个维度的形状为 (C,V,T) ,与图像 feature map 的形状 (C,W,H)相对应。
图像的通道数 C 对应关节的特征数 C。
图像的宽 W 对应关键帧数 V。
图像的高 H 对应关节数T 。
在图像卷积中,卷积核的大小为『w』 『1』,则每次完成 w 行像素,1 列像素的卷积。『stride』为 s,则每次移动 s 像素,完成 1 行后进行下 1 行像素的卷积。

在时间卷积中,卷积核的大小为『temporal_kernel_size』 [公式] 『1』,则每次完成 1 个节点,temporal_kernel_size 个关键帧的卷积。『stride』为 1,则每次移动 1 帧,完成 1 个节点后进行下 1 个节点的卷积。
ST-GCN模型的实现
图卷积经典公式
在这里再放一下基于频域的图卷积公式

其中,A是graph的邻接矩阵,
I是单位矩阵,
A+I即给graph加了个自环,以保证数据传输的有效性。
W则是由多个输出通道的权重向量组成。
fin是输入的特征图,其维度为(c,V,T),其中V为节点数,T为帧数
图卷积实现
基于频域的图卷积公式

实现过程:先执行 1 × Γ的2D标准卷积fin W,再与Λ− 1/2 (A + I)Λ− 1/2相乘。
对于有多个子集划分策略的处理
上述公式只适用于单一子集划分的方法,即所有的W都一样,对与有多个子集的划分策略,邻接矩阵A被分为多个矩阵Aj,其中

因此,之前的频域图卷积公式变成了

这里加个α是为了不让Λ存在全为0的一行,不然会没有办法求Λ-1/2。
可学习的边重要性权重实现
ST-GCN为每个邻接矩阵(表示了graph的内部连接关系)配有一个可学习的M
对于4.2与4.3中的公式,分别把其中的A+I和Aj改为:A+I叉乘一个M(元素相乘);Aj叉乘一个M,如下式所示。

ST-GCN网络架构与训练
至此,已经实现了基于openpose提取人体关键点,根据关键点建立时间-空间graph,再重新定义时间-空间graph上的卷积方法。最后进行网络架构设计和训练设计。
1、由于在同一层GCN中,不同的节点共享权重矩阵,因此要保持输入数据的规模是一致的。所以再输入数据时先进行一次批规范化Batch-Normalization。
2、ST-GCN由9层ST-GCN模块组成,前三层输出64维特征,中间3层输出128维特征,最后3层输出256维特则会那个,每一层的时间核Γ都为9,并且每一层都有resnet机制
3、为了避免过拟合,每层都加入dropout=0.5,第4、7层的池化stride=2。
4、最后是对graph进行readout操作,即将图嵌入,将graph数据转为n维向量,并送入经典分类器softmax进行图分类。
5、再训练过程中,采用随机梯度下降方法,初始学习率设为0.01,每经10epoch衰减0.1倍。
6、为了防止过拟合,在数据方面进行增强。首先对骨架序列进行仿射变换(模拟相机移动);再在原始序列中随机抽取片段进行训练。
结合代码分析结构
网络结构
归一化

首先,对输入矩阵进行归一化,具体实现如下:
N, C, T, V, M = x.size()
# 进行维度交换后记得调用 contiguous 再调用 view 保持显存连续
x = x.permute(0, 4, 3, 1, 2).contiguous()
x = x.view(N * M, V * C, T)
x = self.data_bn(x)
x = x.view(N, M, V, C, T)
x = x.permute(0, 1, 3, 4, 2).contiguous()
x = x.view(N * M, C, T, V)
归一化是在时间和空间维度下进行的( V x C)。也就是将一个关节在不同帧下的位置特征(x 和 y 和 acc)进行归一化。
这个操作是利远大于弊的:
关节在不同帧下的关节位置变化很大,如果不进行归一化不利于算法收敛
在不同 batch 不同帧下的关节位置基本上服从随机分布,不会造成不同 batch 归一化结果相差太大,而导致准确率波动。
时空变换
通过 ST-GCN 单元,交替的使用 GCN 和 TCN,对时间和空间维度进行变换:
# N*M(256*2)/C(3)/T(150)/V(18)
Input:[512, 3, 150, 18]
ST-GCN-1:[512, 64, 150, 18]
ST-GCN-2:[512, 64, 150, 18]
ST-GCN-3:[512, 64, 150, 18]
ST-GCN-4:[512, 64, 150, 18]
ST-GCN-5:[512, 128, 75, 18]
ST-GCN-6:[512, 128, 75, 18]
ST-GCN-7:[512, 128, 75, 18]
ST-GCN-8:[512, 256, 38, 18]
ST-GCN-9:[512, 256, 38, 18]
空间维度是关节的特征(开始为 3),时间的维度是关键帧数(开始为 150)。在经过所有 ST-GCN 单元的时空卷积后,关节的特征维度增加到 256,关键帧维度降低到 38。
感觉这样设计是因为,人的动作阶段并不多,但是每个阶段内的动作比较复杂。比如,一个挥高尔夫球杆的动作可能只需要分解为 5 步,但是每一步的手部、腰部和脚部动作要求却比较多。
输出
最后,使用平均池化、全连接层(或者叫 FCN)对特征进行分类,具体实现如下:
# self.fcn = nn.Conv2d(256, num_class, kernel_size=1)
# global pooling
x = F.avg_pool2d(x, x.size()[2:])
x = x.view(N, M, -1, 1, 1).mean(dim=1)
# prediction
x = self.fcn(x)
x = x.view(x.size(0), -1)
Graph 上的平均池化可以理解为对 Graph 进行 read out,即汇总节点特征表示整个 graph 特征的过程。
这里的 read out 就是汇总关节特征表示动作特征的过程了。
通常我们会使用基于统计的方法,例如对节点求 max,sum,mean 等等。mean 鲁棒性比较好,所以这里使用了 mean。
GCN-卷积核
从结果上看,最简单的图卷积似乎已经能取得很好的效果了,具体实现如下:
def normalize_digraph(A):
Dl = np.sum(A, 0)
num_node = A.shape[0]
Dn = np.zeros((num_node, num_node))
for i in range(num_node):
if Dl[i] > 0:
Dn[i, i] = Dl[i]**(-1)
AD = np.dot(A, Dn)
return AD
作者在实际项目中使用的图卷积公式就是:

公式可以进行如下化简:

其实就是以边为权值对节点特征求加权平均。其中,
可以理解为卷积核
Multi-Kernal

作者结合运动分析研究,将其划分为三个子图,分别表达向心运动、离心运动和静止的动作特征。

对于一个根节点,与它相连的边可以分为 3 部分。第 1 部分连接了空间位置上比本节点更远离整个骨架重心的邻居节点(黄色节点),包含了离心运动的特征。第 2 部分连接了更为靠近重心的邻居节点(蓝色节点),包含了向心运动的特征。第 3 部分连接了根节点本身(绿色节点),包含了静止的特征。
使用这样的分解方法,1 个图分解成了 3 个子图。卷积核也从 1 个变为了 3 个,即 (1,18,18)变为(3,18,18)。3 个卷积核的卷积结果分别表达了不同尺度的动作特征。要得到卷积的结果,只需要使用每个卷积核分别进行卷积,在进行加权平均(和图像卷积相同)。
A = []
for hop in valid_hop:
a_root = np.zeros((self.num_node, self.num_node))
a_close = np.zeros((self.num_node, self.num_node))
a_further = np.zeros((self.num_node, self.num_node))
for i in range(self.num_node):
for j in range(self.num_node):
if self.hop_dis[j, i] == hop:
if self.hop_dis[j, self.center] == self.hop_dis[
i, self.center]:
a_root[j, i] = normalize_adjacency[j, i]
elif self.hop_dis[j, self.
center] > self.hop_dis[i, self.
center]:
a_close[j, i] = normalize_adjacency[j, i]
else:
a_further[j, i] = normalize_adjacency[j, i]
if hop == 0:
A.append(a_root)
else:
A.append(a_root + a_close)
A.append(a_further)
A = np.stack(A)
self.A = A
Multi-Kernal GCN

TCN
GCN 帮助我们学习了到空间中相邻关节的局部特征。
在此基础上,我们需要学习时间中关节变化的局部特征。
如何为 Graph 叠加时序特征,是图网络面临的问题之一。这方面的研究主要有两个思路:时间卷积(TCN)和序列模型(LSTM)。
ST-GCN 使用的是 TCN,由于形状固定,我们可以使用传统的卷积层完成时间卷积操作。为了便于理解,可以类比图像的卷积操作。st-gcn 的 feature map 最后三个维度的形状为 (C,V,T) ,与图像 feature map 的形状 (C,W,H)相对应。
图像的通道数 C 对应关节的特征数 C。
图像的宽 W 对应关键帧数 V。
图像的高 H 对应关节数T 。
在图像卷积中,卷积核的大小为『w』 『1』,则每次完成 w 行像素,1 列像素的卷积。『stride』为 s,则每次移动 s 像素,完成 1 行后进行下 1 行像素的卷积。
在时间卷积中,卷积核的大小为『temporal_kernel_size』 [公式] 『1』,则每次完成 1 个节点,temporal_kernel_size 个关键帧的卷积。『stride』为 1,则每次移动 1 帧,完成 1 个节点后进行下 1 个节点的卷积。
具体实现如下:
padding = ((kernel_size[0] - 1) // 2, 0)
self.tcn = nn.Sequential(
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(
out_channels,
out_channels,
(temporal_kernel_size, 1),
(1, 1),
padding,
),
nn.BatchNorm2d(out_channels),
nn.Dropout(dropout, inplace=True),
)
Attention
作者在进行图卷积之前,还设计了一个简易的注意力模型(ATT)。如果不了解图注意力模型可以看这里。
# 注意力参数
# 每个 st-gcn 单元都有自己的权重参数用于训练
self.edge_importance = nn.ParameterList([
nn.Parameter(torch.ones(self.A.size()))
for i in self.st_gcn_networks
])
# st-gcn 卷积
for gcn, importance in zip(self.st_gcn_networks, self.edge_importance):
print(x.shape)
# 关注重要的边信息
x, _ = gcn(x, self.A * importance)
在运动过程中,不同的躯干重要性是不同的。例如腿的动作可能比脖子重要,通过腿部我们甚至能判断出跑步、走路和跳跃,但是脖子的动作中可能并不包含多少有效信息。
因此,ST-GCN 对不同躯干进行了加权(每个 st-gcn 单元都有自己的权重参数用于训练)。
代码分析
总结
论文最后一部分就是各种比较实验了,得出ST-GCN在NTU-RGB+D数据集上效果优异,但在kinetics数据集表现一般的结论,论文分析说可能是因为ST-GCN没有充分考虑人物与背景的互动关系所致。
文章出处登录后可见!