引言
本文利用yolov5-6.1版本完成目标检测模块,利用deepsort跟踪算法实现目标跟踪模块,将二者集成,在自己的数据集上形成一套行之有效的目标检测+跟踪模型。
yolov5-6.1版本代码下载地址:yolov5 deepsort- CSDN搜索 (github.com)![]() https://github.com/ultralytics/yolov5deepsort代码下载地址:https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch
https://github.com/ultralytics/yolov5deepsort代码下载地址:https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch![]() https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch注意:root下的models和utils是使用的yolov5的v6.1版本的代码,如使用其它版本可以用相应版本的models和utils代码替换。
https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch注意:root下的models和utils是使用的yolov5的v6.1版本的代码,如使用其它版本可以用相应版本的models和utils代码替换。
1 代码整体框架
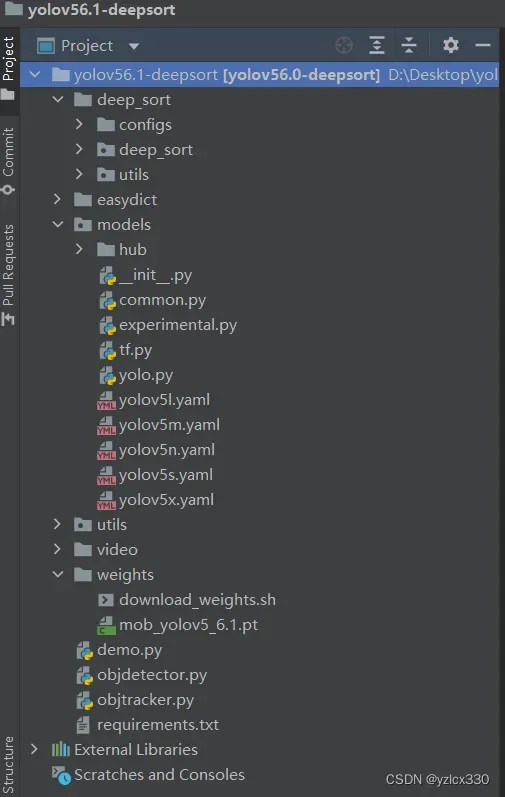
其中分为yolov5-6.1模块,deepsort模块。
2 目标检测模块
2.1 环境依赖
YOLOv5的代码是开源的,因此我们可以从github上克隆其源码。该项目利用yolov5-6.1版本来作为讲解。下载yolov5-6.1代码,其目录结构如下:
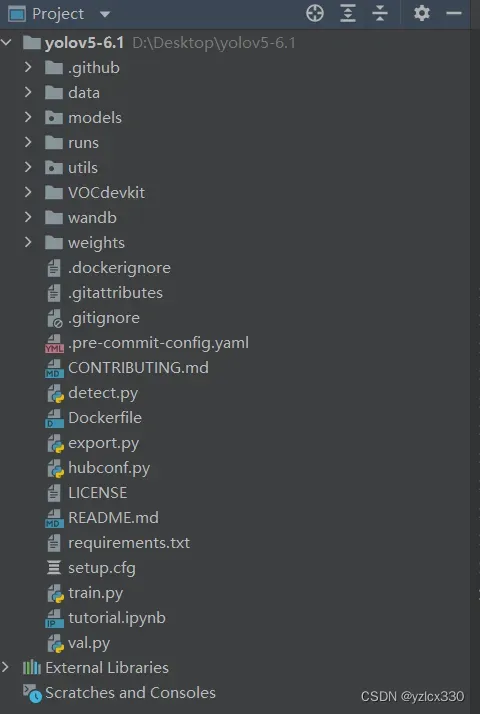
data:主要是存放一些超参数的配置文件,是用来配置训练集和测试集还有验证集的路径的。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。
models:里面主要是一些网络构建的配置文件和函数。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等。
weights:放置训练好的权重参数。
detect.py:利用训练好的权重参数进行目标检测。
train.py:训练自己的数据集的函数。
test.py:测试训练的结果的函数。
requirements.txt:yolov5-6.1的环境依赖包。利用以下命令完成环境依赖安装。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 数据集准备
这里需要将VOC(xml)格式的数据集转换成yolo所需的txt格式,需要对xml格式的标签文件转换为txt文件。将标注好的数据集按照以下形式存放。
运行代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["hat", "person"]
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()在VOCdevkit目录下生成images和labels文件夹,文件夹下分别生成了train文件夹和val文件夹,里面分别保存着训练集的照片和txt格式的标签,还有验证集的照片和txt格式的标签。images文件夹和labels文件夹就是训练yolov5模型所需的训练集和验证集。
2.3 预训练权重
为了缩短训练时间,可以从下面网址中获取预训练权重。ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)![]() https://github.com/ultralytics/yolov5/releases
https://github.com/ultralytics/yolov5/releases
2.4 参数修改
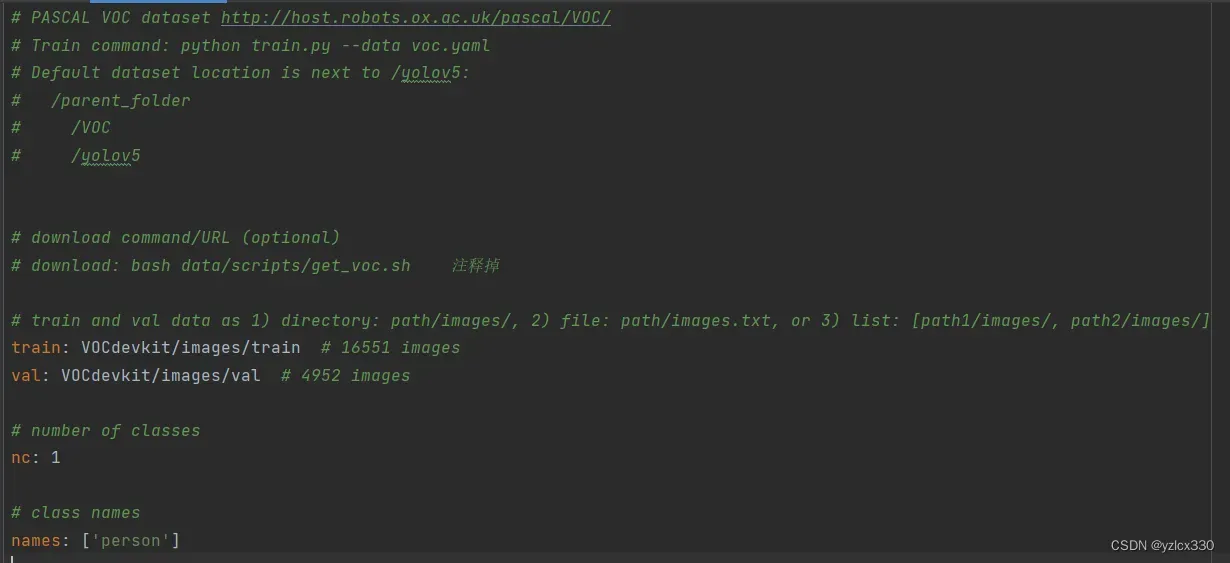
修改data目录下的相应的yaml文件 。也可以创建新的mob.yaml文件。train和val改为自己数据集路径。nc改为自己要训练的类别数量。names改为自己的类别名称。
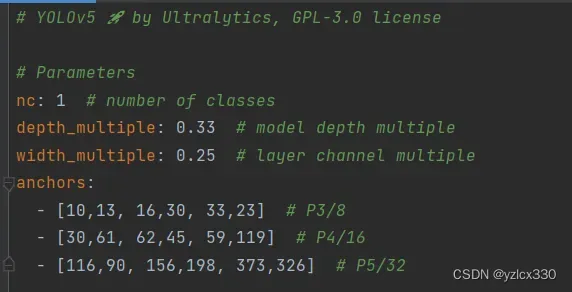
修改models下的yaml文件。我这里使用的是yolov5n.pt预训练权重,将nc改为自己类别数量。
2.5 模型训练
在根目录下找到train.py文件,根据自己文件路径修改–weights –cfg –data。
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'weights/yolov5n.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5n.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/mob.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=200)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=20, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt运行train.py。将数据加载到内存并且冻结前8层网络以加快训练速度。
python train.py --cache --freeze=8启用tensorbord查看。
tensorbord --logdir ./runs3 跟踪模块
3.1 跟踪数据集准备
deep_sort\deep_sort\deep\checkpoint下的权重ckpt.t7是deepsort在行人ReID数据 集训练出来,用于提取行人的外观特征 Market 1501数据集 Market-1501 数据集是在清华大学校园中采集于2015年构建并公开。
数据集目录结构
Market-1501-v15.09.15
bounding_box_test
bounding_box_train
gt_bbox
gt_query
query
这里我们制作自己的数据集进行跟踪权重的训练。将图像中的检测目标扣出,作为跟踪数据集。
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = 'xxxxxxxx'
# XML文件的地址
anno_path = 'xxxxxxxxx'
# 存结果的文件夹
cut_path = 'xxxxxxxxxxx'
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
# print(imagelist
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
print(obj_i)
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
try:
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
except:
continue
print("&&&&")
if __name__ == '__main__':
main()运行上述代码,得到扣出的目标数据集。
将上述数据集进行分类,这里检测目标只要person,但是类别有31个。分好后train和test文件夹下分别有31个文件夹,代表31个类别。将train和test移动到deep_sort/deep目录下。
修改train.py中dataset的预处理如下。
transform_train = torchvision.transforms.Compose([
torchvision.transforms.Resize((128, 64)),
torchvision.transforms.RandomCrop((128, 64), padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])在model.py中修改类别为31。
class Net(nn.Module):
def __init__(self, num_classes= 31 ,reid=False):
super(Net,self).__init__()
# 3 128 64
self.conv = nn.Sequential(
nn.Conv2d(3,64,3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# nn.Conv2d(32,32,3,stride=1,padding=1),
# nn.BatchNorm2d(32),
# nn.ReLU(inplace=True),
nn.MaxPool2d(3,2,padding=1),
)运行train.py训练。
python train.py并将训练好的ckpt.t7跟踪权重文件放到checkpoint目录下,将训练好的yolo权重mob_yolov5_6.1.pt放到weights目录下。
修改objdetector.py
OBJ_LIST = ['person']
DETECTOR_PATH = 'weights/mob_yolov5_6.1.pt'修改deep_sort/configs/deep_sort.yaml文件
DEEPSORT:
REID_CKPT: "deep_sort/deep_sort/deep/checkpoint/ckpt.t7"
MAX_DIST: 0.2
MIN_CONFIDENCE: 0.3
NMS_MAX_OVERLAP: 0.5
MAX_IOU_DISTANCE: 0.7
MAX_AGE: 70
N_INIT: 3
NN_BUDGET: 1004 跟踪效果
运行demo.py查看跟踪效果。


至此,大致流程训练完毕!本项目实现了稳定跟踪,但对reid效果暂未考虑,后续将继续完善!欢迎交流!
文章出处登录后可见!