文章目录
- 前言
- 断点续训
- 1. 更改train.py文件的参数
- 2. 清理数据集中的datasets.cache缓存
- 3. 断点续训
- 注意细节
- 1. exp问题
- 2. 训练过程可视化软件问题
- 【附】:YOLOv7中 train.py训练参数设置信息
前言
模型训练过程中可能由于网络问题、或者服务器断开等问题导致模型训练意外出现中断,或者是由于自己主动中断训练等各种情况。
这时候就需要断点续训,即接着之前已经训练好的weights.pt和epochs重新开始训练。还需要训练日志也重新续接上,好在wandb等训练可视化的软件中接着之前的训练过程开始训练。
接下来我以自己出现的断点续训情况进行描述和解决步骤的说明。
【出现模型训练中断的环境情况说明】: 自己的电脑通过pycharm连接上学校的服务器,由于服务器需要通过内网(即校园网)进行登录连接,而校园网由于各种不稳定情况或者晚上十二点偶尔就会关闭或者断开
(学校傻缺,人为的制造bug)等原因断开连接,导致服务器(XShell软件通过ssh连接服务器)断联,从而pycharm连接的服务器解释器出现断开连接,训练过程中断。
【注】: YOLOv5,YOLOv7代码十分相似(你懂的),所以操作互通。
断点续训
1. 更改train.py文件的参数
将下图中的 –resume 参数的 default=False 设置为 True。这一步是将解释器中的断点续训设置为True(即进行断点续训),如果是从头开始训练就不需要更改这个参数值。
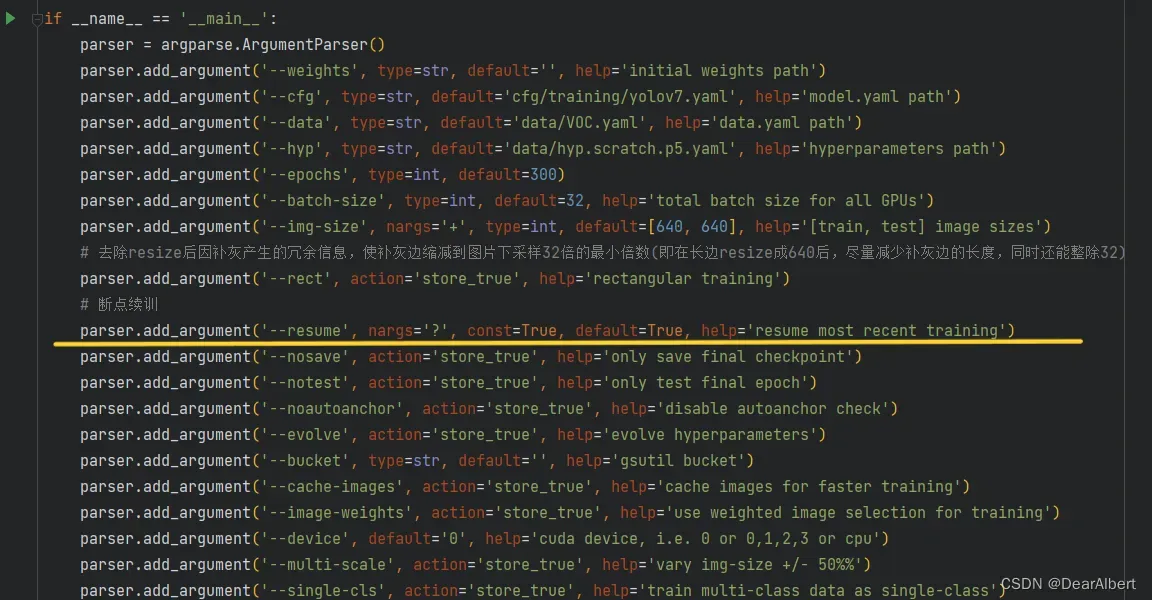
2. 清理数据集中的datasets.cache缓存
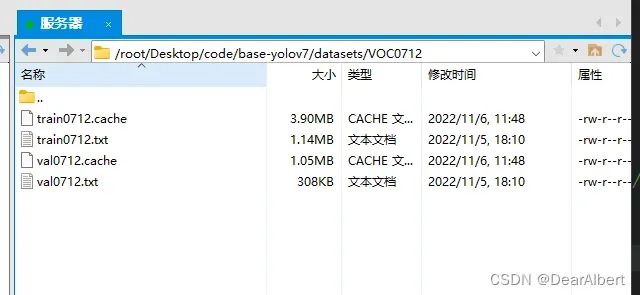
以 YOLOv7 训练为例,我用的训练集是VOC0712。在之前的训练中会出现datasets.cache缓存,如果不清理的话,YOLOv7断点续训会失败(YOLOv7在每次训练开始的时候都要清除上一次训练的数据集缓存,不然都会出现训练失败的情况)。清理完缓存,在断点续训开始的时候,会重新生成数据集索引。
(YOLOv5没试过,不知道会不会出现这种情况,如果不会的话这一步跳过)
3. 断点续训
在Terminal中输入训练指令即可重新开始训练,如下图所示。
需要注意的是断点续训需要调用之前断开的训练时的 last.pt 权重文件,即将断训前最后一次epochs的 pt权重文件(last.pt) 作为预训练权重输入到接下来要训练的网络中,剩下而指令还用你自己的模型之前训练的指令就行。这里我为了方便,已经将一些指令提前写入到文件当中,所以传入指令的时候大部分指令都已经省略。
【注】: 这里强调一下,我这里的指令是我自己训练时候单机多卡的指令,在这里只是给出一个参照。
你自己断点续训的时候,输入的指令(一台机器一张GPU)应该是 <你自己之前训练时的指令 + (–weights …指令)>
其中的 -m torch.distributed.launch –nproc_per_node 2 、–device 0,1 这两个指令是用来 单机多卡 训练的,一张GPU的机器不需要这两个指令。 对照从零开始的Usage 和 断点续训的 Usage,可以看出我就在断点续训的指令中比初始训练指令多添加了一个权重的指令。
总结:简单方法 – (直接指令操作)
- 第一步:把你之前训练终止的文件夹名称改成exp(或者exp最高)。具体原因不清楚,反正不改成exp会报错。
- 第二步:在原来训练指令的基础上添加断点续训指令。
断点续训指令: 原来的指令 –resume –weights 断点续训权重地址
【例如】:
- 原先的训练指令: python -m torch.distributed.launch –nproc_per_node=2 train.py –device 0,1 –adam –batch-size 4 –workers 2 –name yolov7
- 断点续训指令: python -m torch.distributed.launch –nproc_per_node=2 train.py –device 0,1 –adam –batch-size 4 –workers 2 –name yolov7 –resume –weights ./runs/train/exp/weights/last.pt
- Terminal中的输出信息
1. 输入训练指令
![]()
2. 断点续训开始
![]()
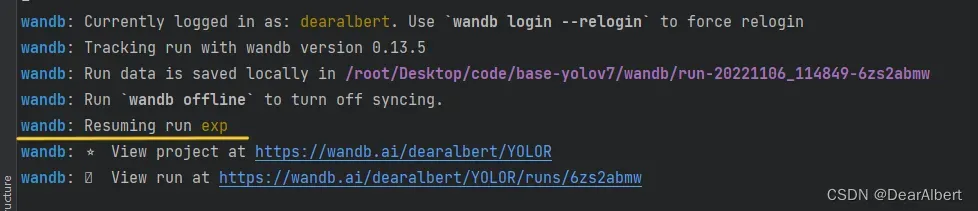
3. wandb情况
4. 断点续训情况
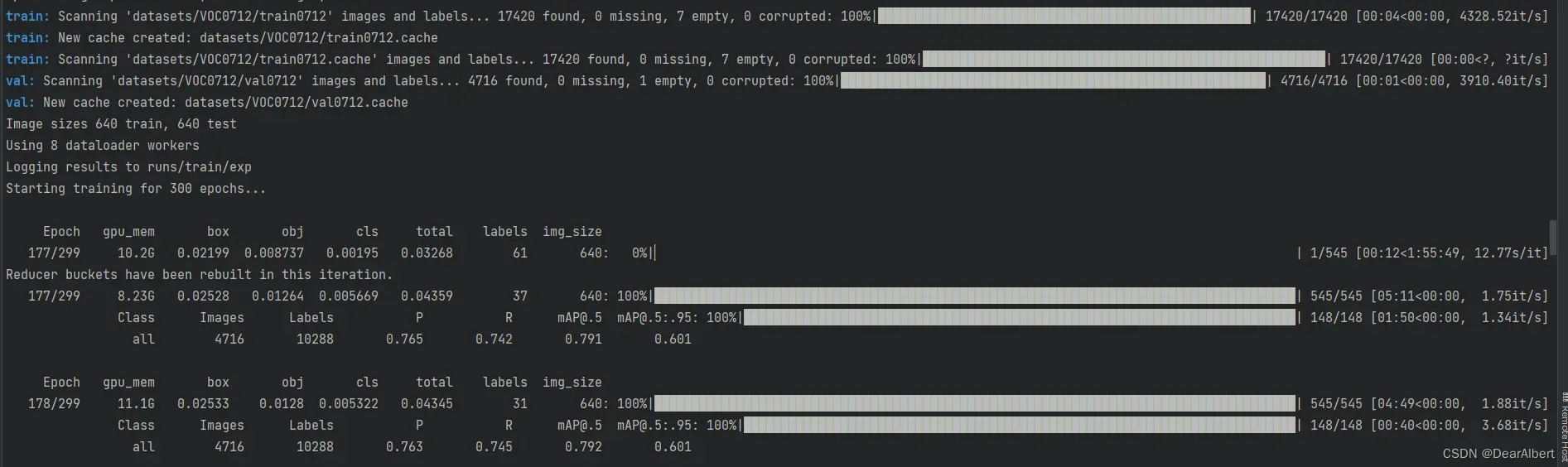
这里可以看出,断点续训开始之前网络会重新cache一下train、val。epochs会沿着之前训练中断的地方重新开始训练。
注意细节
1. exp问题
尽量保证断点续训的 exp 是最last的,否则会出现一些莫名其妙的东西。也就是说断点续训的exp(如果runs/train中有多个exp,例如exp1、exp2、exp3等等)要保证是最后一个生成的,如果不是的话最好吧需要续训的exp之后的exp转移到其他地方或者删除(比如需要续训exp2,就要移除掉项目中exp2之后的exp3、expn等等后面所有其他训练结果。exp1需不需要移除我没试过,有兴趣的朋友可以试一下)。
2. 训练过程可视化软件问题
我用的是 wandb 可视化软件,断点续训的话不会产生与续训前结果重叠问题。但是群里有朋友反映他断点续训 Tensorboard 可视化会出现重叠混乱等问题。
这里不太清楚是不是可视化软件的问题,有兴趣的朋友可以测试一下。具体情况如下图所示。
- Tensorboard断点续训
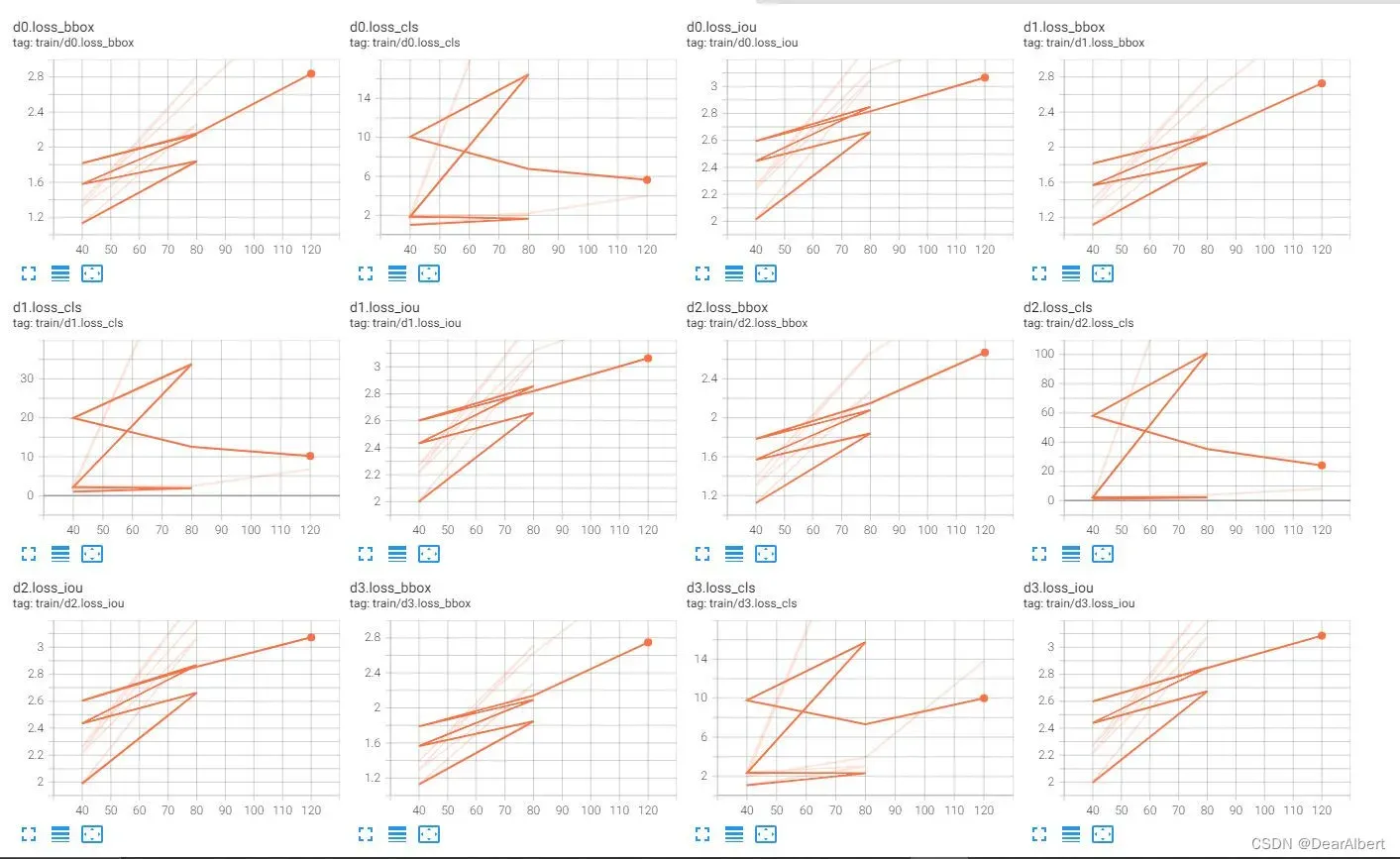
如上图所示,在40个epochs的时候多次使用断点续训,Tensorboard出现可视化混乱的情况。
原因可能是中断之后又重新运行,tensorboard没有清理文件,导致多个日志混杂在一起。
- wandb断点续训
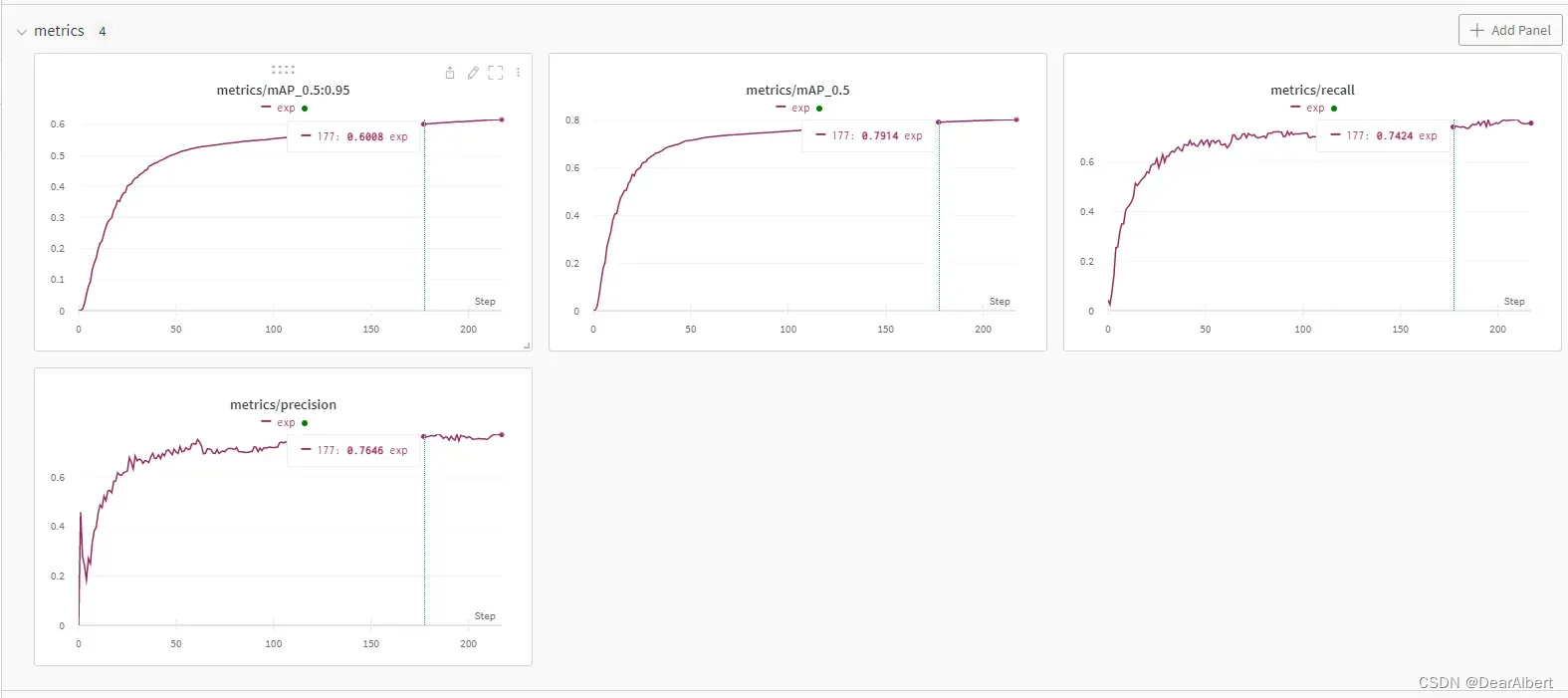
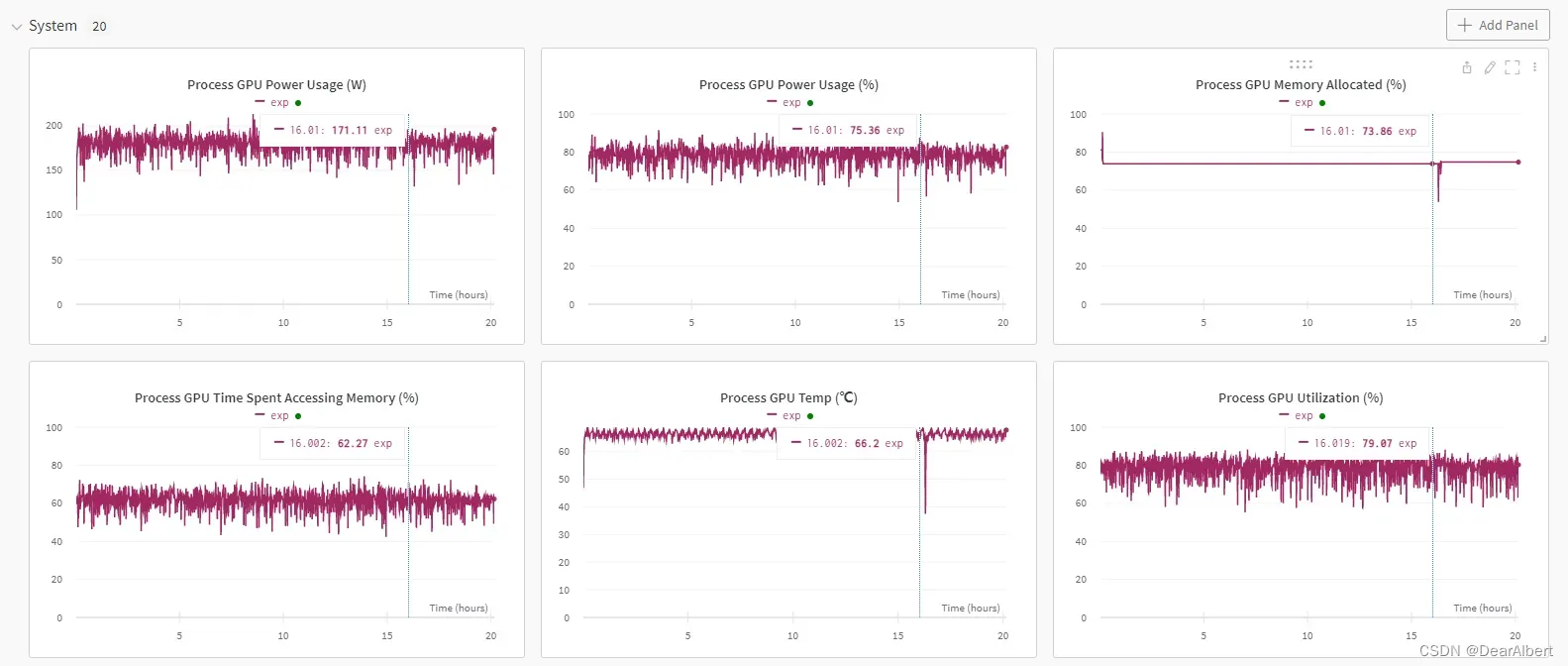
从上图可以看出,wandb在176个epochs的时候出现断点,接下来断点续训177个epochs连接上了之前的训练结果。从 System栏 中可以看出,在16h之后曲线有一个突然下降,这时候就是模型训练断开,GPU Memory释放,GPU Temp温度下降;之后断点续训开始,曲线接着之前的训练结果继续开始运行。
【附】:YOLOv7中 train.py训练参数设置信息
这里附上 YOLOv7 中 train.py 中的训练参数信息,可以作为对照。防止出现看完文章操作流程后,对训练参数指令传入部分如何写还是模糊的情况发生。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--cfg', type=str, default='cfg/training/yolov7.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/VOC.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
# 去除resize后因补灰产生的冗余信息,使补灰边缩减到图片下采样32倍的最小倍数(即在长边resize成640后,尽量减少补灰边的长度,同时还能整除32)
parser.add_argument('--rect', action='store_true', help='rectangular training')
# 断点续训
parser.add_argument('--resume', nargs='?', const=True, default=True, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone of yolov7=50, first3=0 1 2')
parser.add_argument('--v5-metric', action='store_true', help='assume maximum recall as 1.0 in AP calculation')
opt = parser.parse_args()
文章出处登录后可见!