教程:15 分钟了解面向数据的 Python — 通过数据/逻辑分离降低复杂性
一个 3 步教程,教您 Python 的面向数据方法的三个主要概念
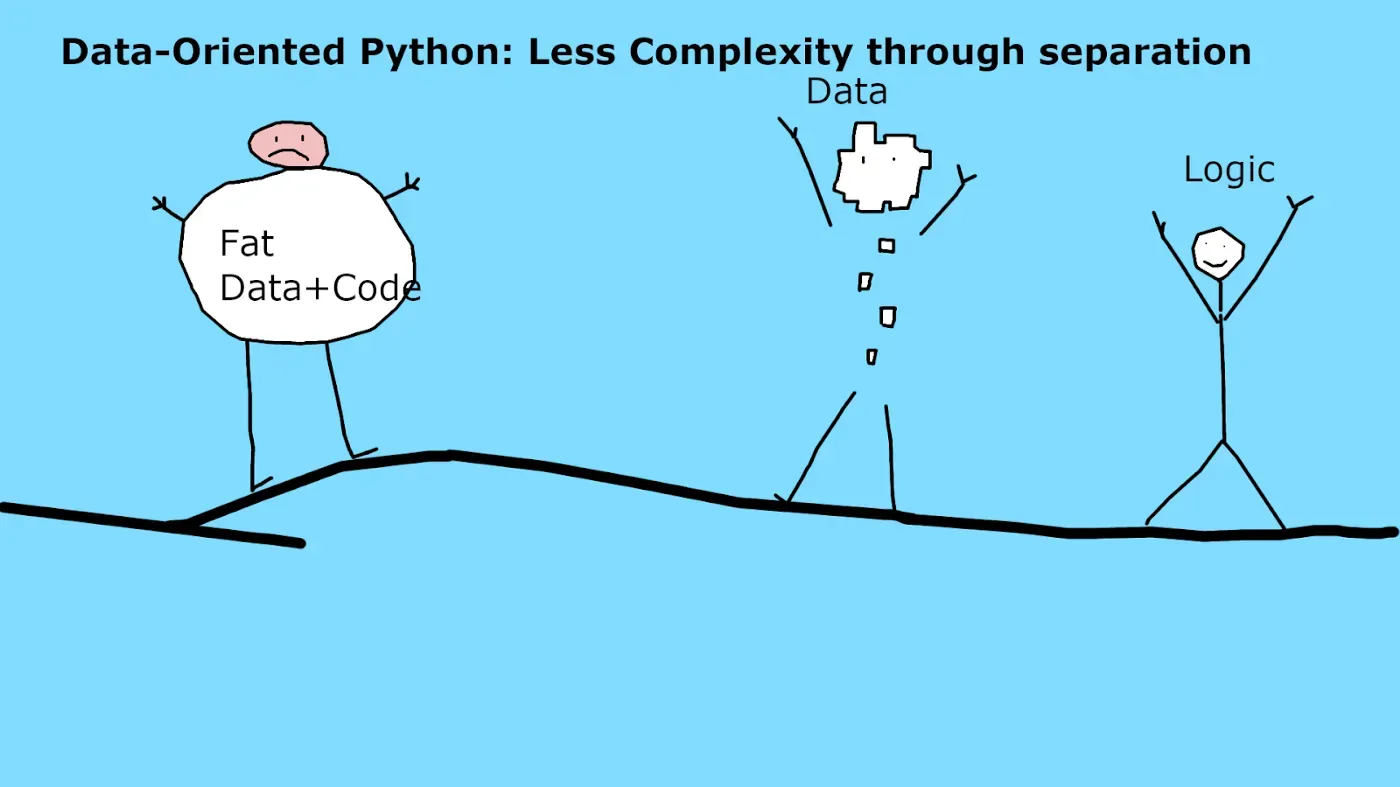
您听说过面向数据的编程方法吗?如果没有,那么,现在你有。本教程旨在让您对它感到兴奋,使用 Python。
我们要做一些非常简单的事情:
1. 我们将看一个常见的虹膜分类问题,我已经通过编写两个 Python 类为您“解决”了这个问题。
2. 然后我们将尝试在稍微不同的上下文中应用这些类,并重用它们。
3. 这不会很顺利,所以我们将使用面向数据的方法将我的几个类变成很酷的面向数据的 Python 代码。
你可以跟着做,说明在下面和 GitHub 上。
First Steps
将标准 Python 代码转换为面向数据的 Python 代码的最简单示例可能如下所示:
# NON DO VERSION-----------------------------------class data(): X = 1 def add(self): self.X = X+1
## DO version--------------------------------------class data(PRecord): ## (1) Using a base type PRecord = a map/dict in Python X = field() ## (2) Using an immutable type from pyristent
def add(data): ## (3) Separating the logic (add) from the data return data.set(X=data.X+1) ## (2) return a new data piece, as data is immutable!
三个简单的步骤,听起来很简单吧?让我们快速看一下我们在这里应用的这三个想法。
简而言之,面向数据的方法
面向数据的方法称为面向数据的编程 (DOP) 或面向数据的设计 (DOD)。 DOD 是从游戏设计领域出来的,其目标是让数据进行计算,从而使游戏运行得更快。 DOP 人员显然意识到 DOD 中用于游戏的想法在大多数数据密集型环境中出于完全不同的原因是有意义的!现在奇怪的是,使用的方法实际上不同。所以我在这里写的是以下想法:
这个想法很简单:我们将数据与业务逻辑分开。我们这样做的方式是利用通用结构并保持数据不可变。通过这样做,我们解耦了系统的各个部分,从而降低了整个系统的复杂性。 (用我自己的话)
这里的关键成分是:
- 分离数据,使其成为“一等公民”。事实上,许多编程语言已经有了“数据类”,它只保存数据而没有其他东西。[0][1]
- 我们使用通用结构,例如映射和数组,因为它们已经带有诸如“打印”或“排序”之类的内置方法,我们无需编写它们。[0][1]
- 我们保持数据不可变,因为可变性会产生复杂性。不用问“x=2吗?还是代码中此时的 x=3?”。[0]
所有这些成分旨在通过使数据成为一等公民来降低复杂性。现在让我们动手实践一下吧!
Quick-install guide
前往 Github,克隆存储库“DOP-Example”并运行[0]
./batect dev 这将打开一个 Jupyter 笔记本服务器,已经加载了正确的笔记本,全部在 Docker 中。打开“DO-Tutorial,ipynb”,你就可以跟着学习了。
编写你的第一个面向数据的 Python
我编写了两个简单的类和一段 Python 代码,它们执行以下操作:
– ML_Dataset 可以加载和保存我的 Iris 数据集,
– ML_Predictor 可以将 SVM 拟合到 ML_Dataset、预测单个结果以及将洞输入矩阵的预测写入 ML_Dataset
– 程序代码创建一个 ML_Dataset、一个 ML_Predictor,拟合预测器,将新生成的测试空间的预测写入数据集中,最后运行一个测试预测。
这是这两个类的 Python 代码。
#### — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — ### These are our two machine learning classes. We wrapped stuff into classes to possibly extend this and make it more reusable…class ML_Dataset(): “”” Should hold our data, targets, predictions, basically X and y… Should also be able to fill itself, once we need it. “”” X = None y = None y_pred = None def load_iris(self): iris = datasets.load_iris() self.X = iris[“data”][:,3:] # petal width self.y = (iris[“target”]==2).astype(np.int)
class ML_CLF(): “””Should hold the classifier we want to use here, should also be able to fit and predict. “”” clf = None def fit_clf(self, m: ML_Dataset): self.clf = svm.SVC(gamma=’scale’, decision_function_shape=’ovo’, probability=True) self.clf.fit(m.X,m.y) def predict(self, X): return self.clf.predict(X) def write_preds(self,m): “””Writes predictions into an ML_Dataset using this classifier””” m.y_pred = self.clf.predict_proba(m.X)
这就是我的小程序的样子:
#### — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — ### Our running program. Yes, we’re still exploring stuff here.# create our dataset, load stuff into it.m = ML_Dataset()m.load_iris()# create our classifier and fit it to the datasetc = ML_CLF()c.fit_clf(m)# let’s try it out, into a new dataset to predict on into our dataset, then write our prediction in it and print them out…m.X = np.linspace(0,3,1000).reshape(-1,1)c.write_preds(m)print(m.y_pred)print(“individual predictions: “, c.predict([[1.7],[1.5]]))
这在这个特定情况下工作得很好。现在让我们通过首先交换数据集来重用代码。
Pt 1 分离数据和代码
让我们用不同的数据集交换数据集。我把业务逻辑,将 iris 数据集加载到保存数据的类中。因此,我们需要更改类或创建一个新类以将我们的数据集交换为不同的类。我们可以这样做,它看起来像这样:
#### — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — # Option 1, write a new classclass ML_Dataset_2(): “”” Should hold our data, targets, predictions, basically X and y… Should also be able to fill itself, once we need it. “”” X = None y = None y_pred = None def load_different_dataset(self): self.X = np.array([[1],[2],[3],[4],[5]]) self.yy=np.array([1,0,0,1,1])# Option 2, change the classclass ML_Dataset(): “”” Should hold our data, targets, predictions, basically X and y… Should also be able to fill itself, once we need it. “”” X = None y = None y_pred = None def load_iris(self): iris = datasets.load_iris() self.X = iris[“data”][:,3:] # petal width self.y = (iris[“target”]==2).astype(np.int) def load_different_dataset(self): self.X = np.array([[1],[2],[3],[4],[5]]) self.y = np.array([1,0,0,1,1])
但是每次我想交换一些东西时都写一个新的类听起来有问题。让我们尝试面向数据的方法,将数据与“代码”分开。为此,编写一个类来保存数据 X,y,y_pred,以及一个将数据加载到数据类中的函数。最后,我们编写第二个函数,将新数据加载到数据集中。这可能看起来像这样:
### THE DO Approachclass ML_Dataset(): “”” Should hold our data, targets, predictions, basically X and y… Should also be able to fill itself, once we need it. “”” X = None y = None y_pred = Nonedef load_iris(m: ML_Dataset): iris = datasets.load_iris() m.X = iris[“data”][:,3:] # petal width m.y = (iris[“target”]==2).astype(np.int)## load old datam = ML_Dataset()load_iris(m)## load something newdef load_new(m: ML_Dataset): m.X=np.array([[1],[2],[3],[4],[5]]) m.y= np.array([1,0,0,1,1])load_new(m)
这对我来说已经更容易理解了。让我们看看另一个问题,数据的可变性。
Pt 2 Immutable Data
让我们打印出到目前为止我们使用的数据:
## OLD Approachm = ML_Dataset()load_iris(m)## load something newdef load_new(m: ML_Dataset):…## print out our datasetprint(m.X)
注意 m.X 的内容如何变化。我们不能简单地执行 print(m.X), print(m_old_X),因为数据确实发生了变化。在这种情况下,我们必须先打印,然后再进行更改。这很好,但让我们看一下面向数据的方法,即具有不可变数据的方法。
对于不可变数据,我们使用 Python 包 pyrsistent,并通过导入 `from pyrsistent import field, PRecord` 将我们的类重新创建为具有不可变字段的类。然后,我们通过将新数据加载到其中来创建数据集的新版本。这可能看起来像这样:[0]
### NEW DOP Implementation# We’re using the module for immutable python pyrsistent hereclass ML_Dataset(PRecord): X = field() y = field() y_pred = field() X_new = field()def load_iris(): iris = datasets.load_iris() r_1 = ML_Dataset() r_2=r_1.set(X=iris[“data”][:,3:]) r_3=r_2.set(y=iris[“target”]) return r_3## Here’s how we use itr = load_iris()r_2 = r.set(X = np.linspace(0,3,1000).reshape(-1,1))## Just making sure this stuff is actually immutable!r.set(X=”1")# print(r.X)# >> [0. ]…… [0.01201201]## Oh that doesn’t work, let’s try direct item assignment maybe?r[“X”]=1## >> TypeError: ‘ML_Dataset’ object does not support item assignment# Nice, so now this cannot happen accidentally.
太好了,所以 Python 现在阻止我覆盖数据,我现在基本上有了一个版本化的数据集。我们来看第三步,使用泛型数据结构的思路。
Pt 3 通用数据结构
我想出了在我的分类器对象中添加“注释”的想法,这样我就可以留下类似“试验 1,试验参数 x,y,z”的评论。在我的旧代码中这样做,它看起来像这样:
#### — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — ### These are our two machine learning classes. We wrapped stuff into classes to possibly extend this and make it more reusable…class ML_CLF():“””Should hold the classifier we want to use here,should also be able to fit and predict. “”” clf = None trial_note = “trial 1” def fit_clf(self, m: ML_Dataset): self.clf = svm.SVC(gamma=’scale’, decision_function_shape=’ovo’, probability=True) self.clf.fit(m.X,m.y) def predict(self, X): return self.clf.predict(X) def write_preds(self,m): “””Writes predictions into an ML_Dataset using this classifier””” m.y_pred = self.clf.predict_proba(m.X)
让我们创建一个分类器并打印出来,看看我的笔记是什么样子的:
#### — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — ### Now let’s create another classifier.# Let’s print it out to see the commentc = ML_CLF()print(c)# <__main__.ML_CLF object at 0x7f7b102cbdf0>
这不是我所期望的。我们可以通过提供 __str__ 方法来解决这个问题。但是面向数据的方法采用了不同的方法。让我们通过像字典一样使用泛型类来为字典使用内置函数,如 print() 或 item()。我们仍然希望保持它不可变,所以我们使用来自 pyrsistent 的 PRecord,它本质上是一个字典。如果我们这样做,我们的代码可能如下所示:
class ML_Predictor(PRecord): clf = field() note = field()def predict_stuff(m: ML_Predictor, d: ML_Dataset): m_2 = m.set(clf=m.clf.fit(r.X,r.y)) # Al right! Now we got… # — m, as the initialized and unfitted CLF # — m_2 as the fitted predictor. From the outside, not easy to distinguish… d_2 = d.set(y_pred = m_2.clf.predict_proba(d.X_new)) return d_2### Our Program — — — — — — — — — — — — — — — — — — — — — — — — — — r = load_iris()r_2 = r.set(X_new = np.linspace(0,3,1000).reshape(-1,1))c = ML_Predictor(clf=svm.SVC(gamma=’scale’, decision_function_shape=’ovo’, probability=True), note=”This is trial 1; using SVC”)c_2 = c.set(clf=svm.SVC(gamma=’scale’, decision_function_shape=’ovo’, probability=True, kernel=’poly’), note=”This is trial 2\; using SVC with polyn. kernel”)print(c)print(c_2)print(c.items()) # we can use all the default cool functions on this generic Map!```
耶!为了使它完整,我还从之前的类中删除了业务逻辑。现在我们得到了一段很好的可重用代码,它使数据成为一等公民,更容易理解恕我直言,也更容易模块化。
就是这样,您刚刚学习了 Python 的面向数据方法的第一课。让我们回顾一下。
Recap
- 面向数据的 Python 让数据成为一等公民
- 至于降低复杂性
- 它将数据与业务逻辑分离
- 它使用通用数据结构
- 它只使用不可变的数据
如果您对此感兴趣,我强烈建议您继续阅读此方法。
接下来读什么
遗憾的是,我没有任何 Python 特定的资源。但是我有资源。
- 有一本书叫“面向数据的编程”,由 Manning 出版,作者是 Yehonathan Sharvit。他还在他的网站上免费发布了许多此类内容。[0][1]
- 还有一本书更针对面向数据的设计社区进行游戏设计。它被 Richard Fabian 称为“面向数据的设计”。这本书再次在他的网站上以在线版本的形式提供。[0][1]
- 还有一个 Github 存储库,其中包含许多尚未提及的信息,包括视频等,因此请检查一下。[0]
- 我发现一篇关于面向数据的 Python 的文章很好地解释了,即使我们依靠 NumPy 来处理“指针优化”之类的大部分词,我们仍然可以从中获得 5 到 10 倍的速度优势.[0]
文章出处登录后可见!