剪辑和粘贴:使用 AI 从文本提示创建照片拼贴
如何使用 ML 模型从照片中提取物体并重新排列它们以创造现代艺术

在我之前的许多帖子中,我展示了如何使用 AI 模型根据文本提示创建新的艺术作品。对于这些项目,我使用了至少两个 AI 模型,一个像生成对抗网络 (GAN) 这样的生成器来创建图像,另一个是像 OpenAI 的对比语言-图像预训练 (CLIP) [1] 这样的多模态语言/图像模型指挥发电机。[0]
对于这个项目,我想看看是否可以让 CLIP 在不使用 AI 模型作为生成器的情况下,根据文本提示组装现代照片拼贴画。我构建了一个自定义图像生成器,它组装部分图像并使用 CLIP 迭代地分析和调整拼贴中的部分。我将系统称为“剪辑和粘贴”,其中第二个首字母缩略词代表通过编辑语义组装的图片。
下图显示了 CLIP 和 PASTE 的重要组成部分。我将简要讨论这些元素,然后在以下部分中描述细节。
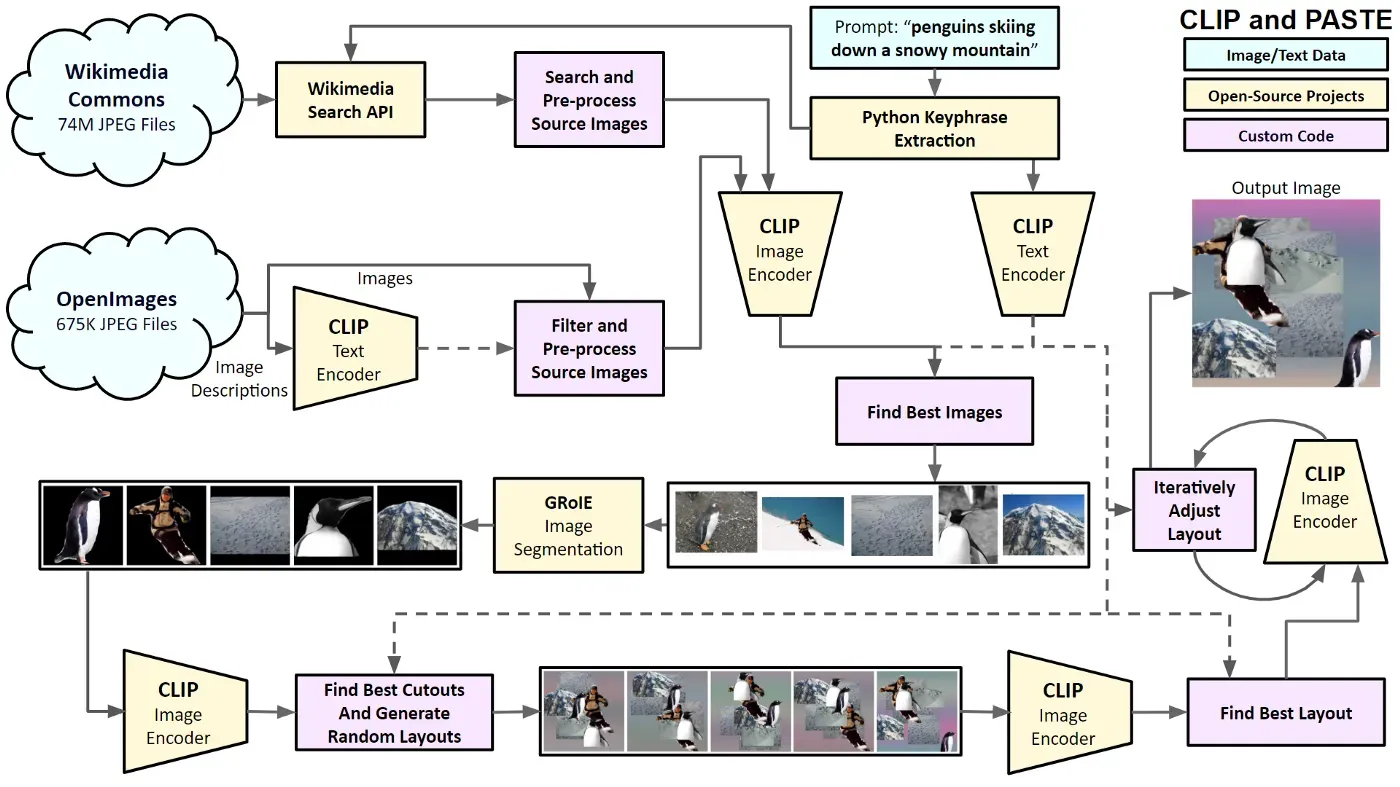
该过程以文本提示开始,例如“企鹅在雪山上滑雪”。该系统使用 Python Keyphrase Extraction 库 [2] 来提取关键字。然后它从 Wikimedia Commons [3] 和 OpenImages [4] 中搜索与提示中的关键字匹配的图像。我使用 Wikimedia Search API 来查找可能匹配的图像。对于 OpenImages,我使用 CLIP 文本编码器通过比较关键字和描述的嵌入来找到最佳文本匹配。接下来,系统从 Wikimedia Commons 和 OpenImages 下载前 100 个图像,并通过 CLIP 图像编码器运行它们,再次将它们与关键字进行比较。该系统通过 GRoIE [5] 图像分割模型运行顶部图像,以从照片中创建剪切。剪切通过 CLIP 重新运行,以找到与关键字最匹配的图像部分。我构建了一个自定义图像合成器,将这些碎片随机组合成多张照片拼贴画。布局通过 CLIP 运行以找到最佳布局。该系统使用 Pytorch 中的 Adam 优化器 [6] 通过迭代分析和合成拼贴画来调整图像部分的位置。 100 次迭代后,显示最终图像。
您可以在以下部分阅读系统的详细信息。请务必查看附录以获取更多生成的照片拼贴。您可以在此处使用 Google Colab 创建自己的。[0]
Background
制作照片拼贴画(也称为照片蒙太奇)的艺术可以追溯到 100 多年前。
拼贴画通常被认为是一种典型的现代艺术技术。这个词——来自法语动词 coller,意思是“粘贴”——最初用于描述巴勃罗毕加索和乔治布拉克的立体主义创新,他们于 1912 年开始将剪报和其他材料粘贴到他们的画布上。从那一刻起,故事是这样的,艺术家们用剪断和粘贴的方式将我们周围的世界带入了意想不到的、变革性的画布组合中。 ——塞缪尔·赖利,《经济学人》[0]
以下是早期照片拼贴的一些样本,从左上角按时间顺序显示。




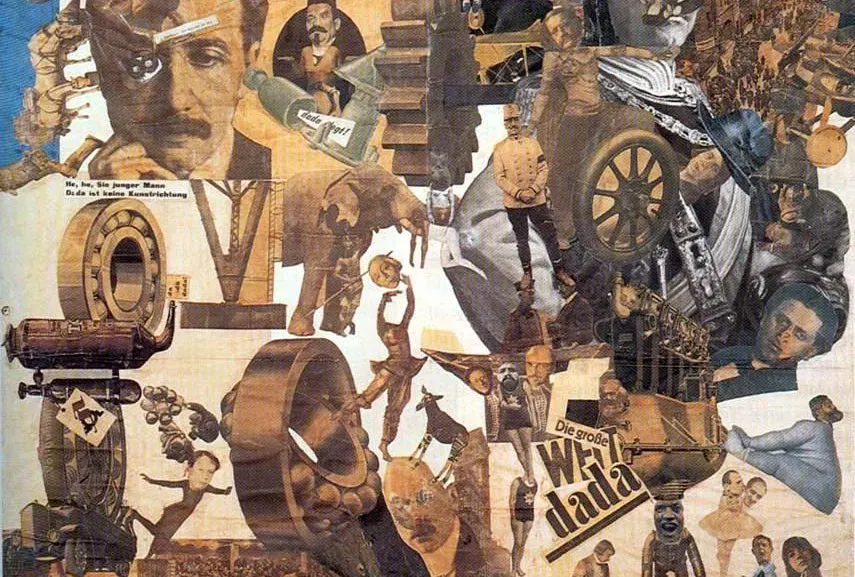
您可以看到艺术形式是如何从在画布上粘贴带有颜料和铅笔画的剪报发展到仅通过安排照片的剪裁来制作的。
System Details
以下是 CLIP 和 PASTE 中使用的组件和过程的描述。
Keyphrase Extraction
与过去使用 KeyBERT [7] 从文本中提取关键字和短语的项目不同,我转而使用一个名为 Python Keyphrase Extraction (PKE) 的包。在对这两个软件包进行了一些试验后,我发现 PKE 似乎做得更好。例如,PKE 允许我为关键字(名词、形容词和动词)指定词性。
以下是两个系统的关键短语与从“企鹅滑雪下雪山”中提取的分数的比较。
KeyBERT
penguins skiing snowy, 0.9217
penguins skiing, 0.8879
skiing snowy, 0.6593
skiing snowy mountain, 0.643
penguins, 0.6079PKE
penguins skiing, 0.5
snowy mountain, 0.5
尽管 KeyBERT 提出了更多候选关键词,但其中一些关键词,如“企鹅滑雪雪地”是荒谬的。然而,PKE 系统似乎用两个同等权重的关键词“企鹅滑雪”和“雪山”抓住了提示的要点。
您可以在此处查看我用于提取关键短语的 Python 代码。[0]
Finding Source Images
正如我在概述中提到的,我从 Wikimedia Commons 和 OpenImages 数据集收集了拼贴画的图像。两个来源都在知识共享署名共享类似开源许可下发布他们的图像。
为了在 Wikimedia Commons 中搜索图像,我使用了位于 https://commons.wikimedia.org/w/api.php 的 API。[0]
这是设置搜索参数的 Python 代码。
s = requests.Session()
url = "https://commons.wikimedia.org/w/api.php"
params = {
"action": "query",
"generator": "images",
"prop": "imageinfo",
"gimlimit": 500,
"titles": keyphrases,
"iiprop": "url|dimensions",
"format": "json"
}
results = s.get(url=url, params=params)当结果回来时,我根据它们的尺寸过滤图像。我保留 512×512 或更大尺寸的图像。
为了在 OpenImages 数据集中搜索图片,我使用 CLIP 文本编码器来比较来自关键短语的嵌入与来自数据集中描述的嵌入。如果您想获得有关此过程的更多信息,可以在此处阅读我关于搜索外观设计专利的文章中的详细信息。[0]
获得图像集合后,我通过 CLIP 图像编码器运行它们,以将它们与整个提示的嵌入进行比较。以下是来自 Wikimedia Commons 和 OpenImages 的热门照片。

Image Segmentation
我使用了一个名为 GRoIE 的 AI 图像分割模型,它代表 Generic Region of Interest Extractor [5]。该系统由 Leonardo Rossi 等人开发。在意大利帕尔马大学。 GRoIE 将在给定输入图像的情况下提取和标记任何可辨别的前景对象。对于它找到的每个对象,它都会创建一个定义对象形状的蒙版图像。
请注意,GRoIE 模型通常会在每个输入图像中找到并提取多个对象。例如,在这张照片中,它发现并隔离了两只企鹅。



提取所有对象后,我再次通过 CLIP 运行它们,以将图像嵌入与提示中的嵌入进行比较。原始图像在上面,提取的图像在下面。以下是从前五张图片中截取的对象。

创建背景颜色渐变
我可以将图像剪裁与纯色(如白色或黑色)合成照片拼贴。但是为了增加对背景的兴趣,我编写了一个小 Python 代码来创建一个带有五个控制点的垂直颜色渐变。然后,我使用 CLIP 分析生成的图像,并使用 Pytorch 中的 Adam 优化器 [6] 反复调整颜色,以找到文本提示的最佳匹配。
我们提出了 Adam,这是一种有效的随机优化方法,它只需要一阶梯度,几乎不需要内存。该方法根据梯度的一阶矩和二阶矩的估计计算不同参数的个体自适应学习率; Adam 这个名字来源于自适应矩估计。 — Diederik Kingma 和 Jimmy Ba
如果您不会讲数学,Adam 方法会稍微调整参数,并注意每次迭代的结果是否改进以及改进了多少。它以不同的速率更改参数,具体取决于每个参数对改进结果的贡献程度。
这是在 25 个参数(红色、绿色和蓝色的 5 个控制点)上使用 CLIP 和 Adam 进行 100 次迭代后“企鹅滑雪下雪山”的结果梯度。
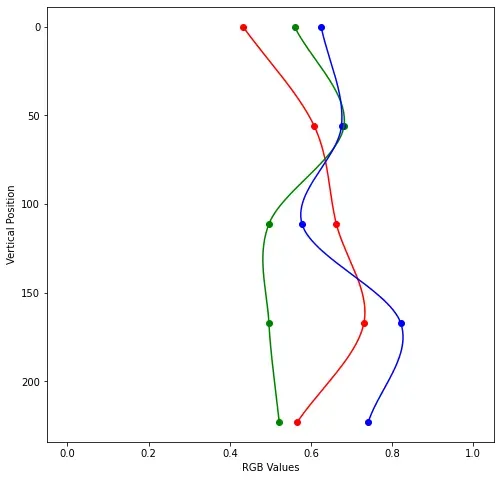

左边是参数值的图表,右边是生成的梯度图像。我不知道为什么它在中下部显示紫色,但它看起来棒极了!
以下是使用此方法的一些附加背景渐变。



如您所见,按照 CLIP 的指示,创建只有 15 个参数的图像可以具有合理的表现力。从文本生成颜色渐变的代码在这里。[0]
寻找最佳拼贴布局
一旦系统有了背景图像和剪裁,下一步就是有意义地排列对象。为此,我创建了 100 个随机对象放置变体,然后通过 CLIP 将它们全部运行,以查看哪种布局与文本提示最匹配。我按大小对剪切图像进行排序,将较大的图像放在背景中,将较小的图像放在前景中。这样做可以减少遮挡较小图片的机会。
这是三个随机布局的示例。



通过 CLIP 运行所有 100 个布局后,右侧的布局与“企鹅滑下雪山”最接近。它非常好,但它可以使用一些微调。
Optimizing the Layout
与创建背景渐变的方法类似,我再次使用 Adam 优化器调整对象位置以更好地匹配文本提示。这有效地反转了函数,允许优化器找到最佳解决方案。我使用了一个名为 Kornia [8] 的包,由 Edgar Riba 等人编写,它在 Pytorch 中执行数学上可微分的图像处理例程。
系统对对象的位置和渐变中的颜色进行微调,然后使用 CLIP 分析生成的图像。然后它会检查它是朝着更好的解决方案还是远离它。此循环重复 100 次以创建最终图像。
以下是“企鹅滑下雪山”的第一次、第 50 次和第 100 次迭代的布局。


你可以看到系统如何将企鹅的身体滑过人类滑雪者的头部和胸部,组织背景中的雪景图片,并调整颜色渐变以将紫色移动到图像的顶部。
这是“企鹅滑雪下雪山”的最终拼贴画。

好的,这很酷(哈,双关语)。因为拼贴是使用参数组装的,所以可以以各种尺寸渲染它,包括高分辨率。
请务必在附录中查看更多来自 CLIP 和 PASTE 的照片拼贴。
讨论和未来方向
CLIP 和 PASTE 系统似乎运行良好。请注意,它高度依赖于从 Wikimedia Commons 和 OpenImages 中找到合适的图像。如果它无法找到与提示中的单词匹配的图片,它将继续使用它找到的任何图像。
未来的改进将是在混合中添加图像缩放和旋转。如果要控制的参数更多,优化器可能会找到更好的布局。
源代码和 Colabs
这个项目的所有源代码都可以在 GitHub 上找到。我在 CC BY-SA 许可下发布了源代码。[0][1]
Acknowledgments
我要感谢 Jennifer Lim 对这个项目的帮助。
References
[1] A. Radford 等人的 CLIP,从自然语言监督中学习可迁移的视觉模型 (2021)[0]
[2] F. Boudin, PKE: An Open-Source Python-based Keyphrase Extraction Toolkit (2016), Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstrations[0]
[3] Wikimedia Commons (2004-present)[0]
[4] OpenImages (2020)[0]
[5] L. Rossi、A. Karimi 和 A. Prati 的 GRoIE,用于实例分割的新型感兴趣区域提取层 (2020)[0]
[6] D. P. Kingma 和 J. Lei Ba,Adam:一种随机优化方法(2015 年),2015 年国际学习表示会议[0]
[7] M. Grootendorst,KeyBERT:使用 BERT 进行最小关键字提取 (2020)[0]
[8] E. Riba、D. Mishkin、D. Ponsa、E. Rublee 和 G. Bradski、Kornia:PyTorch 的开源可微计算机视觉库(2020 年),计算机视觉应用冬季会议[0]
Appendix
以下是使用 CLIP 和 PASTE 创建照片拼贴的一些示例。
波士顿天际线上的烟花

吹着萨克斯管的铜管乐队中的哈巴狗

与蝴蝶一起奔跑的抽象人
这个只使用了两个图像剪切。

要无限制地访问 Medium 上的所有文章,请以每月 5 美元的价格成为会员。非会员每个月只能阅读三个锁定的故事。[0]
文章出处登录后可见!