原文标题 :Variable Reduction Techniques for Time Series
时间序列的变量缩减技术
L1 惩罚和置换特征分数

在预测建模中,结果仅与添加到模型中的输入一样好。在时间序列中,选择模型输入的主要问题是如何最好地表示一个序列的历史来预测它的未来。我们可以将一个系列分解为其基本组成部分:趋势、季节性和残差,但对于复杂的数据集,这可能很难完全正确。以太阳黑子数据集为例,该数据集可在 Kaggle 上获得公共领域许可。它测量自 1700 年代以来每月观察到的太阳黑子,当线性分解为上述组件时,如下所示:[0]
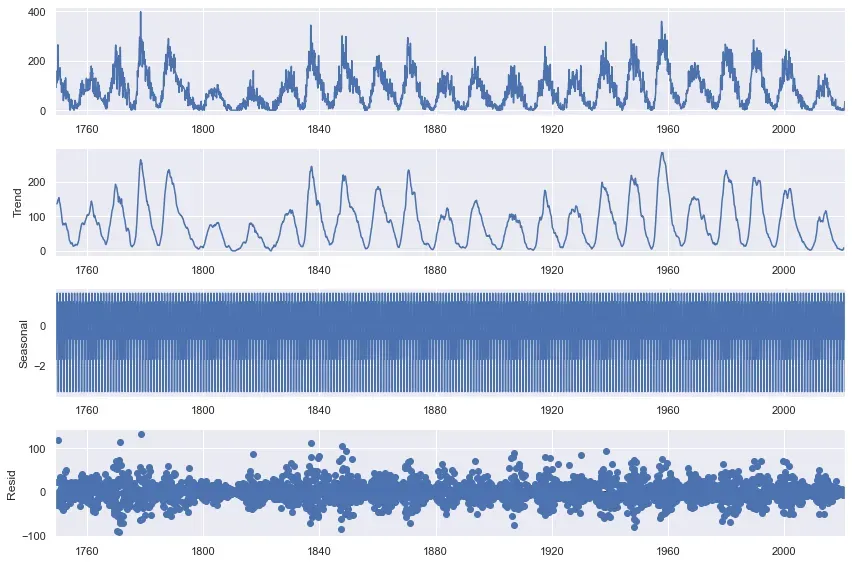
上图显示了原始系列,这很好。然而,第二张图显示了它的“趋势”,但它看起来不像是我见过的趋势,也不是可以轻松建模的趋势。第三张图更糟糕,以一种几乎无法解释的方式显示“季节性”。诚然,这是一个大序列,更复杂的分解可能更合适,但重点仍然存在:在尝试预测该序列时,决定纳入哪些因素并不容易。
一种选择是添加我们认为可能相关的任何内容,然后,使用 L1 正则化或类似于递归特征消除的技术,我们将变量范围缩小到最重要的子集。这就是本示例中所做的,您可以在 Github 上找到它或阅读文档。我们将使用 scalecast 包进行时间序列分析。如果你觉得有趣,请在 GitHub 上给它一个星。 ELI5 包还用于特征重要性评分和 scikit-learn 建模。[0][1][2][3][4][5][6]
准备和添加变量
首先,安装 scalecast 包:
pip install scalecast然后,我们创建 Forecaster 对象,它是一个模型包装器和结果容器:
df = pd.read_csv(
'Sunspots.csv',
index_col=0,
names=['Date','Target'],
header=0,
)
f = Forecaster(y=df['Target'],current_dates=df['Date'])Autoregressive Terms
在时间序列中,最有效的变量通常是序列自身的过去值(滞后)。为了评估该系列的历史记录,我们可能会发现统计上显着的滞后,通常使用自相关函数和偏自相关函数图。
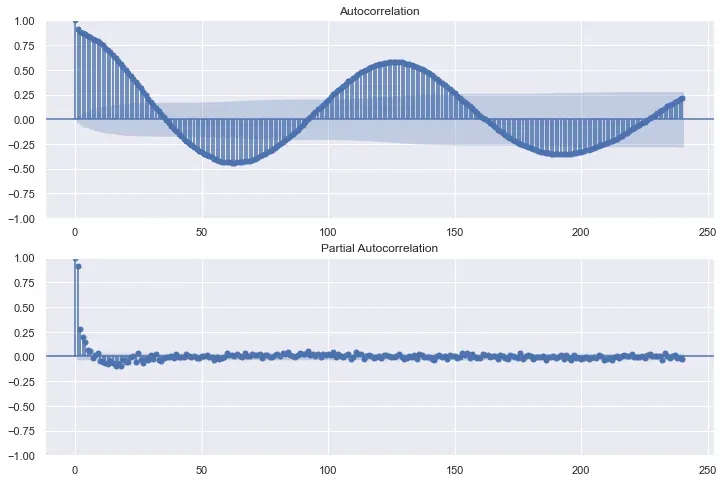
这些有趣的图表也揭示了数据集的周期性。他们揭示了在过去 15 年或更长时间内可能存在具有统计意义的术语。让我们添加前 120 个(10 年)的术语,以及过去 20 年之间相隔一年的术语。
f.add_ar_terms(120) # lags 1-120
f.add_AR_terms((20,12)) # yearly lags up to 20 yearsSeasonal Cycles
通常,每月间隔数据的季节性将包括每月和每季度的波动。然而,在这个例子中,我们试图预测一种不符合覆盖在我们日常生活中的公历的自然现象。这个系列展示的周期是高度不规则的,也是不一致的。根据维基百科,“太阳周期通常持续大约 11 年,从不到 10 年到超过 12 年不等。”[0]
尽管如此,我们仍然可以添加每月和每季度的季节性,以及长达 20 年的每 1 年周期。这当然是矫枉过正,但这就是为什么我们将使用变量减少技术来过滤这些添加的特征中哪些可能是噪声,哪些是信号。所有这些季节性术语都使用傅立叶变换。[0]
f.add_seasonal_regressors('month','quarter',raw=False,sincos=True)
# 12-month cycles from 12 to 288 months
for i in np.arange(12,289,12):
f.add_cycle(i)Trends
对于趋势,我们可以保持简单。我们添加了年份变量,以及一个名为“t”的变量,该变量将从 1 到每个观察的系列长度,也称为时间趋势。
f.add_time_trend()
f.add_seasonal_regressors('year')添加所有这些变量后,我们剩下 184 个预测变量。数据集的大小为 3,265。有时,要针对的大量变量是数据集大小的平方根(在本例中约为 57),但对此没有硬性规定。无论哪种方式,我们添加的所有功能都不太可能有助于预测(而且很难确切知道哪些功能会和不会)。在其他条件相同的情况下,更简洁的模型、输入更少的模型更可取。
Eliminate Variables
使用 L1 正则化消除
我们探索的第一个技术是一种简单而常见的技术:使用 lasso 回归模型的 L1 正则化。 L1 正则化为线性模型中的回归量添加了一个惩罚 (alpha),因此其成本函数可以写为:
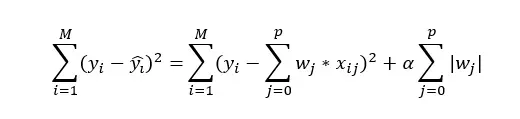
其中 x 是变量,p 是变量总数,w 是给定变量的系数,M 是观察总数。通俗地说,每个系数的权重都会改变一个 alpha 因子,该因子是根据最优化模型以进行预测的方式设置的。在这个框架下,线性模型中最不重要的变量会被正则化,并且它们的系数获得值为 0。我们在分析中运行这个模型并检查哪些变量的系数权重为 0;没有成为我们简化子集的变量。 alpha 参数是通过对数据的验证切片进行网格搜索来设置的,并且默认情况下会缩放所有输入,这在使用此技术时是必要的。
f.reduce_Xvars(
method = 'l1',
overwrite = False,
dynamic_testing = False,
)
lasso_reduced_vars = f.reduced_Xvars[:]在我们的数据集中,这将变量从 184 减少到 34。这是一个相当大的下降!
使用置换特征重要性消除
下一个消除技术更复杂,涉及来自 ELI5 的置换特征重要性 (PFI)。 PFI 背后的想法是使用样本外数据训练和评分任何 scikit-learn 估计器,但在每次评分迭代时,打乱单个特征的值,使它们是随机的。这对模型中的每个输入重复多次。然后,测量算法在单个输入被随机化时的平均准确度变化,并且在特征重要性排名中,对模型准确度影响最大的特征得分更高。它是一种与提供给它的特定算法无关的技术,这使得它可以推广到许多模型类。它的缺点包括它会逐个测试每个变量,因此在评估特征时会错过变量之间的交互。出于同样的原因,彼此高度相关的两个变量可能各自获得较低的重要性分数,即使它们对模型都很重要。这在时间序列中经常发生,这就是为什么 scalecast 在决定下一个将被丢弃的特征之前对原始分数进行调整的原因。请参阅文档。[0]
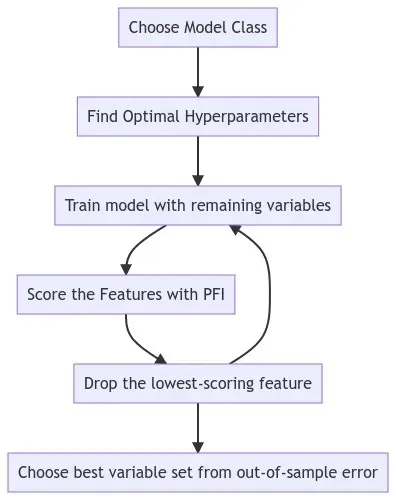
结合 PFI 进行特征消除,我们使用以下过程:
- 使用完整的变量集训练给定的模型类,并使用对样本外验证数据切片的网格搜索来调整其超参数
- 使用步骤 1 中的最佳超参数重新训练模型并监控数据验证切片上的错误
- 使用 PFI 对特征进行评分
- 删除得分最低的特征
- 从步骤 2 开始重复,直到除一定数量的变量之外的所有变量都已删除
- 选择在验证数据上返回最低错误的简化变量集
为了加快评估速度(因为这是一种迭代且计算量大的技术),我们可以使用非动态测试过程,这意味着错误度量相当于一步预测的平均值,并且除了平方根值之外都停止一次的值 (57) 已被删除。在代码中,它看起来像:
f.reduce_Xvars(
method = "pfi",
estimator = "mlr",
keep_at_least = "sqrt",
grid_search = True,
dynamic_testing = False,
overwrite=False,
)同样,由于 ELI5 集成的灵活性,任何 scikit-learn 估计器都可以在这个过程中使用。上面的代码使用了多元线性回归,但我们也探索了 k 近邻、梯度提升树和支持向量机。如果我们选择使用它们,还有许多其他模型可用。我们可以通过检查删除每个变量后获得的样本外误差来绘制结果:
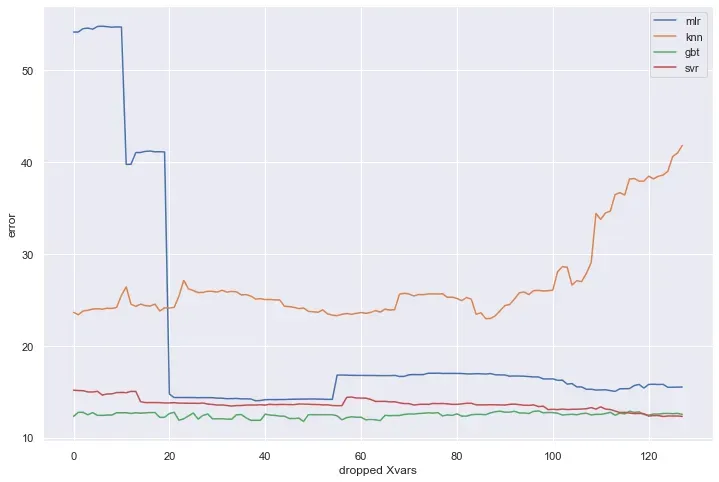
对于所有这些估计器,误差最初减小,然后一旦丢弃太多变量,误差就会增加,除了 SVR 一直减小到最后。总体而言,GBT 和 SVR 估计器表现最好,GBT 略好于 SVR。下面列出了每个找到的变量的最佳数量:
the mlr model chose 146 variables
the knn model chose 98 variables
the gbt model chose 136 variables
the svr model chose 61 variablesValidate Selection
这些变量子集如何泛化?
由于 GBT 模型类通常在验证数据集上表现最好,我们可以使用我们从探索的各种技术中找到的每个变量子集重新训练这个模型类。根据这些结果,我们将根据在单独的样本外数据集(即测试集)上的性能评估我们认为哪些是最好的减少变量集。这一次,我们动态测试模型,以更好地了解它们在整个样本外期间的表现(在整个示例中,我们在验证集和测试集中使用了 120 个观察值):
selected_model = "gbt"
hp = results[selected_model][3]
f.set_estimator(selected_model)
f.manual_forecast(**hp, Xvars="all", call_me=selected_model + "_all_vars")
f.manual_forecast(
**hp, Xvars=lasso_reduced_vars, call_me=selected_model + "_l1_reduced_vars"
)
f.manual_forecast(
**hp, Xvars=mlr_reduced_vars, call_me=selected_model + "pfi-mlr_reduced_vars"
)
f.manual_forecast(
**hp, Xvars=knn_reduced_vars, call_me=selected_model + "pfi-knn_reduced_vars"
)
f.manual_forecast(
**hp, Xvars=gbt_reduced_vars, call_me=selected_model + "pfi-gbt_reduced_vars"
)
f.manual_forecast(
**hp, Xvars=svr_reduced_vars, call_me=selected_model + "pfi-svr_reduced_vars"
)
export_results(f)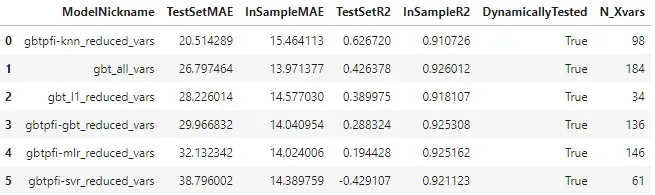
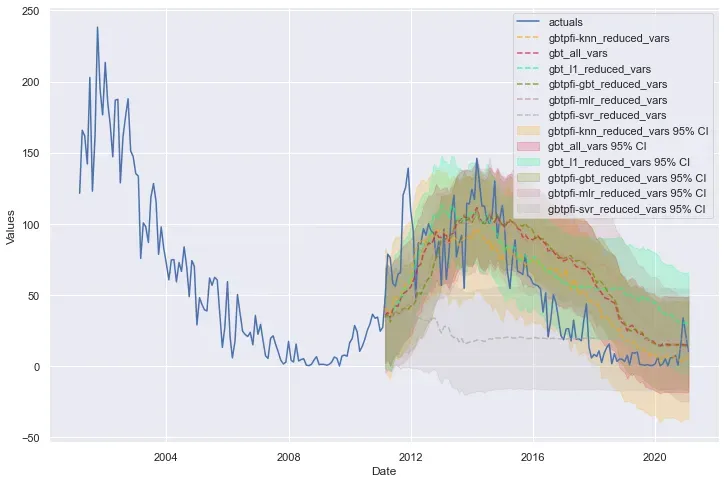
检查这些结果的主要收获是,尽管具有 GBT 的 136 个特征的简化数据集在验证集上得分最高,但具有 98 个特征的 k 近邻模型的简化变量集在测试集上表现最好,表明减少的变量子集可以从一个模型类中获得并成功地集成到另一个模型类中。如果我们愿意,我们可以保存该减少的数据集以用于未来的预测任务:
Xvars_df = f.export_Xvars_df()
Xvars_df.set_index("DATE",inplace=True)
reduced_dataset = Xvars_df[knn_reduced_vars]哪些变量最常被丢弃?
最后,一个有趣的练习是查看在所探索的每种技术中哪些变量最常被丢弃。我们可以编写一些代码来做到这一点,这就是我们得到的:
pd.options.display.max_rows = None
all_xvars = f.get_regressor_names()
final_dropped = pd.DataFrame({"Var": all_xvars})
for i, v in f.export("model_summaries").iterrows():
model = v["ModelNickname"]
Xvars = v["Xvars"]
dropped_vars = [x for x in f.get_regressor_names() if x not in Xvars]
if not dropped_vars:
continue
tmp_dropped = pd.DataFrame(
{"Var": dropped_vars, f"dropped in {model}": [1] * len(dropped_vars)}
)
final_dropped = final_dropped.merge(tmp_dropped, on="Var", how="left").fillna(0)
final_dropped["total times dropped"] = final_dropped.iloc[:, 1:].sum(axis=1)
final_dropped = final_dropped.loc[final_dropped["total times dropped"] > 0]
final_dropped = final_dropped.sort_values("total times dropped", ascending=False)
final_dropped = final_dropped.reset_index(drop=True)
final_dropped.iloc[:, 1:] = final_dropped.iloc[:, 1:].astype(int)
final_dropped最常丢弃的变量:
- quartercos (all 5 techniques)
- AR86 (all 5 techniques)
- AR46 (all 5 techniques)
我们的季度季节性变量中的一个(但不是两者)每次都被丢弃,以及第 86 和第 46 系列滞后。这部分分析还有许多其他有趣的见解。查看文章开头链接的笔记本以获取完整结果。
Conclusion
变量选择是时间序列模型优化的重要组成部分,但要知道在任何给定模型中包含哪些变量最重要并不总是那么容易。在这个例子中,我们向模型中添加了比我们认为必要的更多的变量,并探索了使用 lasso 估计器和 L1 正则化的变量减少,以及使用四个 scikit-learn 模型类和利用排列特征重要性的迭代特征消除。查看 Github 上的 scalecast,如果你觉得有趣,请给它一个星![0]
文章出处登录后可见!