原文标题 :Feature Selection for Data Science: Simple Approaches
数据科学的特征选择:简单的方法
通过摆脱与我们的数据集无关的特征,我们可以创建更好的预测模型。
每个数据科学家都面临或将遇到这个问题;一个巨大的数据集,包含如此多的特征,他们甚至不知道从哪里开始。虽然有许多高级方法可用于为数据集选择最佳特征集合,但有时简单的方法可以为您的分析提供很好的基线,甚至是选择数据集最佳特征所需的唯一必要方法。

特征选择:为什么重要?
特征选择很重要,因为拥有包含太多特征的数据集可能会导致高计算成本以及使用冗余或不重要的属性来进行模型预测。通过摆脱与我们的数据集无关的特征,我们可以创建一个建立在强大基础上的更好的预测模型。虽然有使用机器学习算法进行特征选择的高级方法,但今天我想探索两种可以帮助指导任何分析方向的简单方法。
Dataset
我们今天将使用的数据集是来自 Kaggle.com 的学生表现数据集。该数据集中有 33 个特征,分别是:[0]
学校,性别,年龄,地址,famsize,Pstatus,Medu,Fedu,Mjob,Fjob,原因,监护人,旅行时间,学习时间,失败,schoolup,famsup,付费,活动,托儿所,更高,互联网,浪漫,famrel,空闲时间, 痛风, Dalc, Walc, 健康, 缺勤, G1, G2, G3
如果你还没有数过,这个数据集有 33 个不同的特征!让我们采取一些简单的方法来为我们挑选出最好的方法!
Preprocessing
Before diving in, we will want to do some preprocessing on the dataset. First, lets take a look at the dataset.
import pandas as pd
df = pd.read_csv('student_data.csv')
df.head()
从视觉上看,似乎有一些列本质上是分类的。在转换这些列之前,我们还想检查是否有任何缺失值。
#Checkign for null values -- False means no null values
df.isnull().values.any()运行此代码返回“False”,因此无需填写空值。
df.dtypes在上面的代码中输入显示了每一列的所有类型,它表明实际上有分类列需要转换为数值。 W 我创建了一个简单的映射函数,可以很快地为您完成这项工作。
#Function that converts the categorical to numerical through a dictionary.
def mapper(df_column):
map_dict = {}
for i, x in enumerate(df_column.unique()):
map_dict[x] = i
print(map_dict) #Print this out to see
df_column.replace(map_dict, inplace = True)
return df_column使用此功能,我们可以将所有对象列更改为数字。
def categorical_converter(df):
for i in df.select_dtypes(include=['object']):
mapper(df[i])
return dfcategorical_converter(df)
方法 1:评估特征的相关性
如果两个或多个特征高度相关,这可能意味着它们都以相同的方式解释因变量。这引出了从模型中删除其中一个特征的理由。如果您不确定要删除哪个功能,您始终可以考虑构建两个模型,一个具有每个功能。要获取相关矩阵,只需在数据框上调用 .corr
df.corr()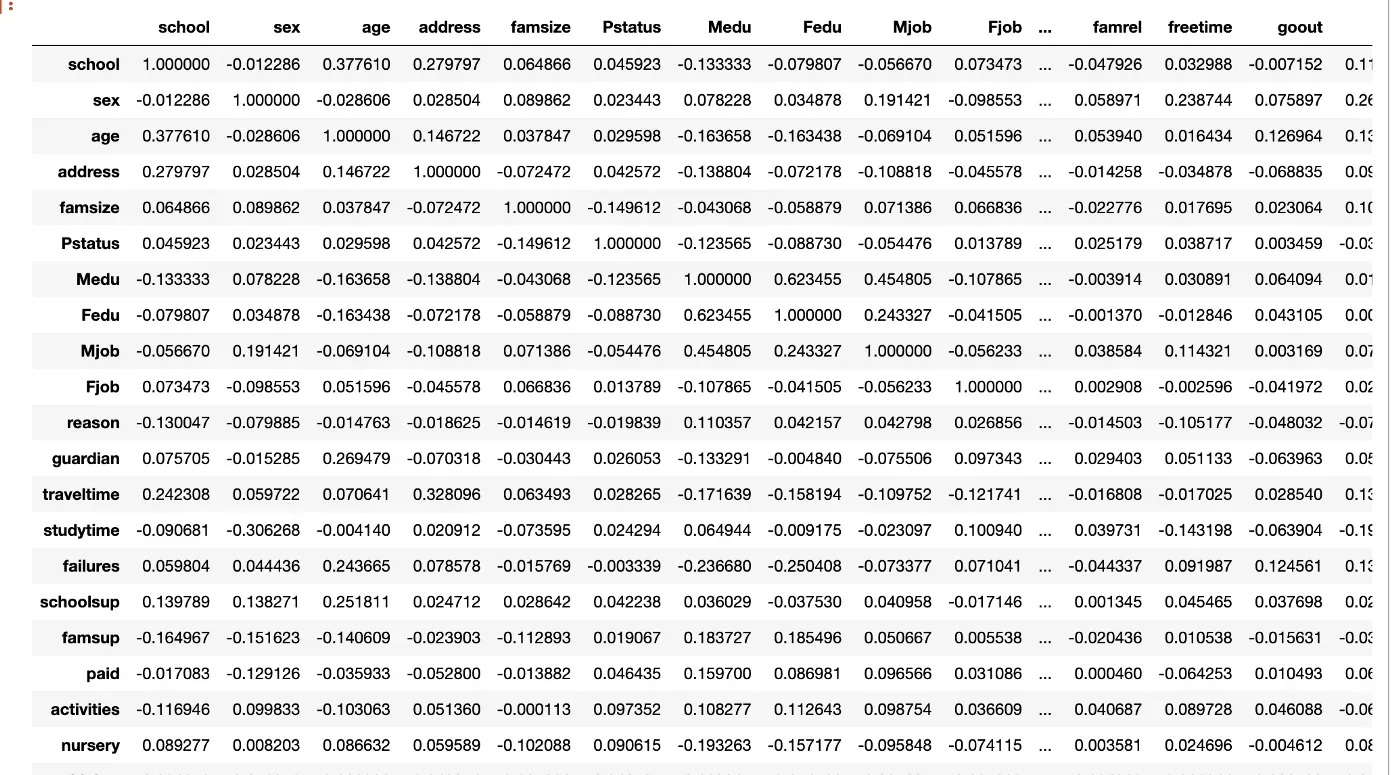
显然,有了这么多的特征,相关矩阵将是巨大的。
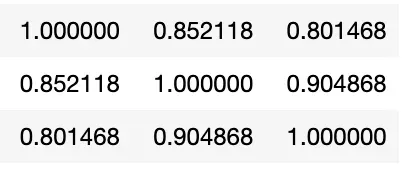
特征 G1、G2 和 G3 具有高度相关性,因此我们希望从数据集中删除其中两个特征。我删除了 G2 和 G3。此外,我将我的 X 数据设置为等于 G1 之外的所有列,这些列成为我的 Y 数据。
df.drop(['G2','G3'], axis=1, inplace=True)
X = df.drop(['G1'], axis=1)
Y = df['G1']方法二:移除低方差的特征
应考虑从数据集中删除任何具有低方差的特征。为什么?首先,让我们考虑一下。如果我想比较谁是更好的学生,并且两个学生每个月都上相同的课程,那么学生之间的“课程”特征几乎没有差异,这将归因于为什么一个学生会比另一个学生表现更好。当一个特征变得接近恒定时,我们可以保持该特征恒定并将其从数据集中删除(与往常一样,这取决于!)。为此,我们将使用 Scikit 学习特征选择库中的 VarianceThreshold()。
from sklearn.feature_selection import VarianceThreshold以下代码将创建一个方差阈值对象,然后将转换我们的 X 数据并返回给定的最佳特征。
vthresh = VarianceThreshold(threshold=.05)selector = vthresh.fit(X)selected = vthresh.get_support()X = X.loc[:, selected]
运行此代码会返回一个包含 9 个特征的 X 数据框!
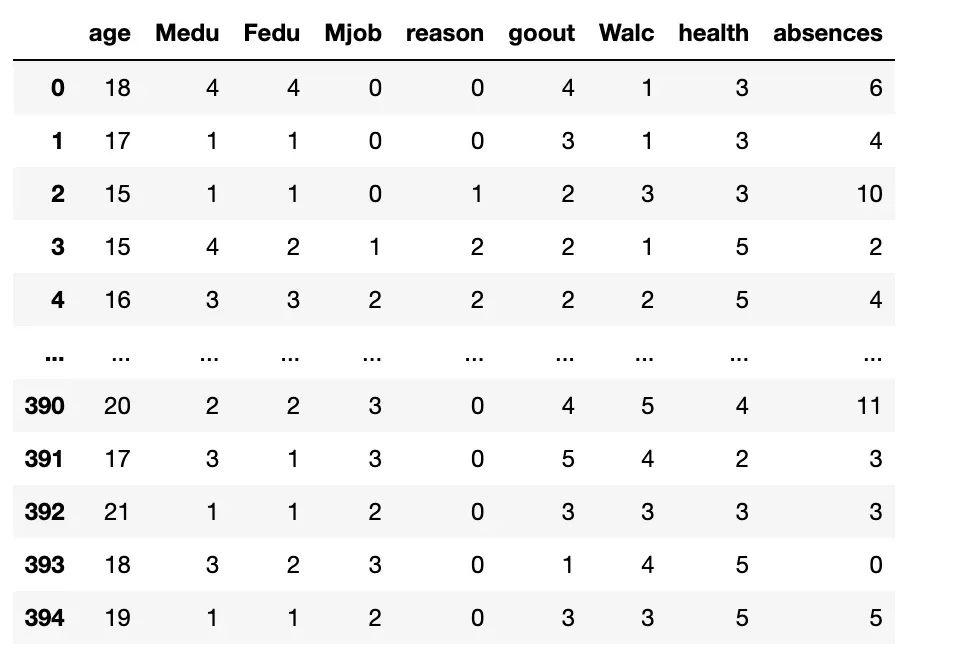
选择的功能是:
年龄、Medu(母亲的教育)、Fedu(父亲的教育)、Mjob(母亲的工作)、原因、痛风、Walc、荒地和缺勤。
虽然这些可能不是我们结束的最终功能,但这让我们初步了解可能影响学生成绩的因素。我们能够通过仅查看相关性和方差来做到这一点!这两种简单的初步方法允许将数据集从 33 个特征减少到 10 个(不能忘记 Y!),现在我们可以开始使用较小的数据集构建模型!
如果你喜欢今天的阅读,请给我一个关注,让我知道你是否希望我探索另一个主题(这真的比你想象的更能帮助我)!此外,请在 LinkedIn 上添加我,或随时与我们联系!谢谢阅读![0]
Citations
学生表现数据集 – CC0:公共领域,已获准供公众使用,作者放弃所有权利,没有版权限制。[0][1]
文章出处登录后可见!